はじめに
駆け出しエンジニアのみなさん、ポートフォリオ作りに悩んでいませんか??
アイデア出しからサービス設計、技術選定にデザイン・実装、さらには運用などなど...
個人開発(ポートフォリオ作り)にはこのように乗り越えるべき壁がいくつも存在していて、それなりのものをちゃんと作ろうとするとかなり大変です。
特に初めてポートフォリオを作るような駆け出しエンジニアの場合、最初のアイデア出しの段階で挫折してしまう人も少なからずいるでしょう。
(何を隠そう、かつての自分もそうでした。)
一方で、そんな個人開発に悩める人たちを救うべく世の中には先人たちが残した素晴らしい技術記事がたくさん存在しています。
例えば
といったQiita上でかなり有名な記事。
また、サービスリリース直後に宣伝も兼ねてそのサービスに関する技術記事を書いてくださる方もたくさんいます。
(しかも最近はどんな書籍や動画で学習したか?なども書いてくださっているんです!)
- ほぼ独学・未経験者がモダンな技術でポートフォリオを作ってみた【Rails / Nuxt.js / Docker / AWS / Terraform / CircleCI】
- ポートフォリオとして、絵本読み聞かせ記録のWebアプリを作成しました。【Laravel / Docker / AWS / CircleCI】
- フロントエンド弱者がNuxt.js + TypeScript + Firebaseで個人開発に挑戦してみました。
ただ残念なことに、駆け出しエンジニアの大半はこれらの技術記事の存在を知らないままポートフォリオ作りにチャレンジしようとしています。
それって少しもったいなくないですか?
こういった記事を事前に見ておいたら手間が省ける場面も数多く存在するでしょうし、またポートフォリオ作りで挫折する人ももっと減るのではないでしょうか?
ふむ。
ならば
- 個人開発に関する技術記事"のみ"が集まっていて
- プログラミング言語、ライブラリ、フレームワークなどのカテゴリでそれらの技術記事を検索でき
- (ついでに)見つけた有益記事はブックマークしていつでも見返すことができる
そんな全個人開発者にとって夢のようなアプリがあったら物凄く重宝するのではないだろうか
こんな妄想の元で開発したのが、個人開発のための技術記事データベースサービス「TechFinder」です。
アプリ名:TechFinder

▼サービスURL
https://techfinder.dev
▼GitHub URL
https://github.com/youliangdao/techfinder
サービス概要と使い方
TechFinderは必要最小限の機能しかない超シンプルなアプリです。
そのため初見で何ができるのかすぐ理解できるでしょう。
が、念のため使い方を簡単に説明しておきます。
①コア機能(カテゴリ絞り込み・ブックマーク+α)
基本的には以下のように「検索したいカテゴリをタップして自分に合った記事を調べていく」という使い方になっています。
またログインしていただくことで気に入った記事をブックマークしたり、いいね・コメントもつけれるようになっています。
| カテゴリ絞り込み | ブックマーク・いいね | コメント |
|---|---|---|
 |
 |
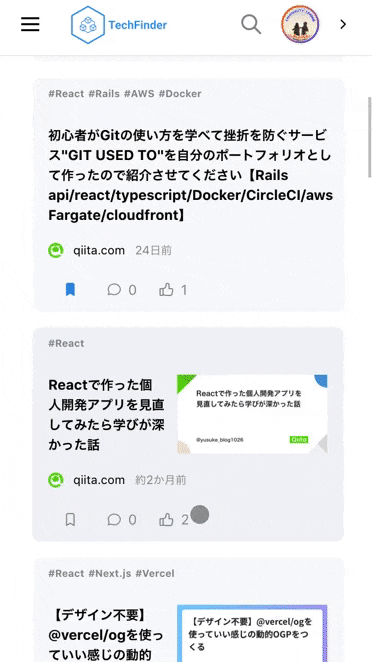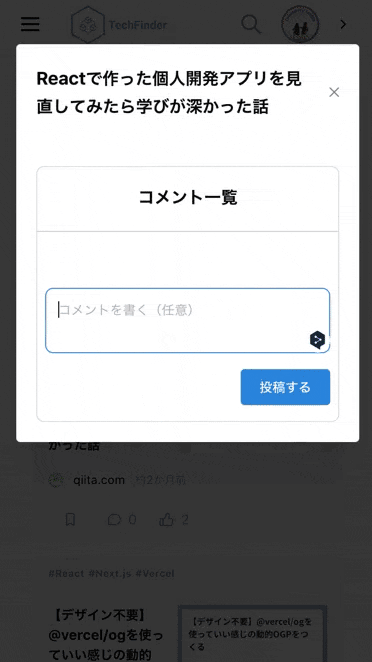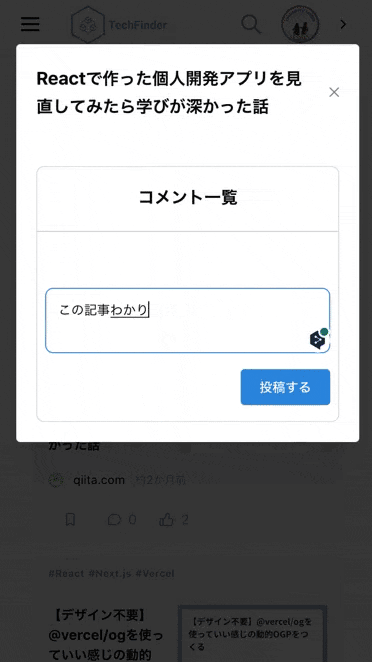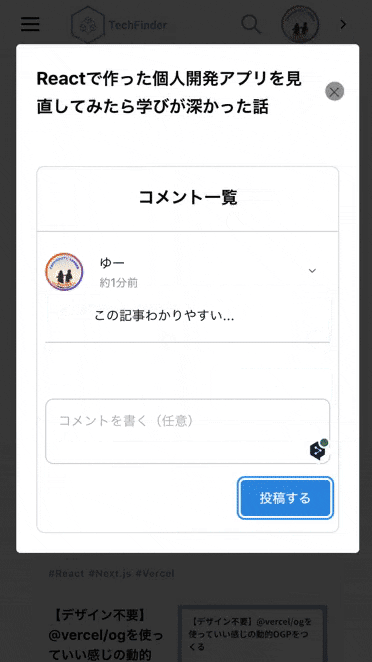 |
| カテゴリアイコンをタップすることで、そのカテゴリに紐付いた記事一覧が表示されます。 | 記事右下の各種ボタンをタップすることで、ブックマークといいねができます (ログインユーザー限定) | コメントボタンをタップすると、モーダルが立ち上がり各記事についたコメントを閲覧できたり、コメントの投稿・編集・削除ができます。(ログインユーザー限定) |
カテゴリーに関してはカテゴリ一覧画面からキーワードを入力することで検索できるようになっています。
さらに
- 「そもそも個人開発がどんなものかすらわからない...」
- 「言語やライブラリ、フレームワークをあまりよく知らない...」
といった方もいらっしゃるかと思いますので、個人開発のフェーズ・技術のジャンルごとにも記事を閲覧できるようにしています。
| カテゴリ検索 | フェーズごとの絞り込み |
|---|---|
 |
 |
| キーワードを入力することで、お好きなカテゴリを検索できます。 | 個人開発の各フェーズ、そして技術ジャンルごとに記事を絞り込むことができるようになっています。 |
②ユーザー機能
先述した通り、「ブックマーク」「いいね」「コメント」はログインユーザーのみが利用できる機能で、またそれらの記事は各ユーザーのマイページ上でのみ管理できるようになっています。
また肝心のログイン方法についてですが、新規登録時の手間を減らしたいといった理由からGoogleログインのみとなっています。
パスワード再設定の実装も不要ですし、Firebase Authを使えば特に設定なしに非常に簡単な実装でGoogleログインが実装できました。
(こちらは後述の3-2. IDaaSを用いたソーシャルログインで詳しく触れます。)
【補足】
こう書くと「ログイン方式は1つでいいのか?」という質問が来そうですが、「必要がないなら1つで良い」と個人的には思っています。
というのも、認証方式は増やすのは簡単ですが減らすのは容易ではないからです。
なので「Twitter連携を前提にしたアプリケーションを作りたい...」等の限定的な要件がない限りは、ほぼ全員がアカウントを所持しているGoogleログインで良いと個人的には思っています。
ただTwitterAPI有料化のようにGoogleログインが何かしらの理由で使えなくなるような事態に備え、リカバリー機能の実装はしておいた方が良いかと思います。(自分はまだ未実装ですが😅)
| ログイン | マイページ上で記事を管理 |
|---|---|
 |
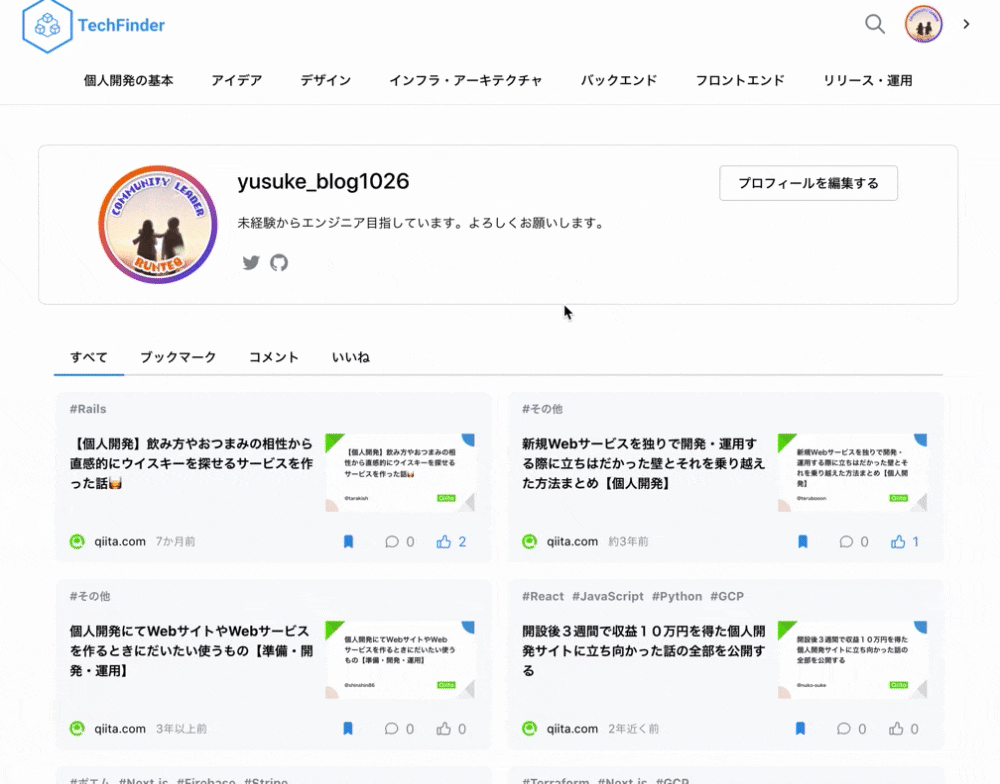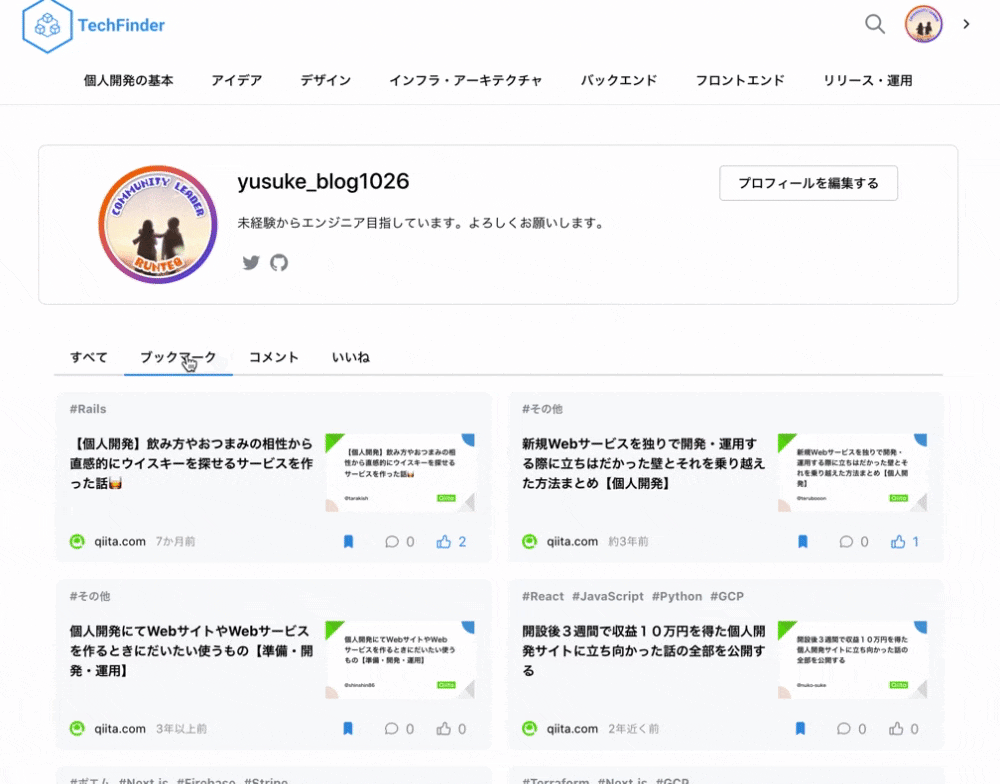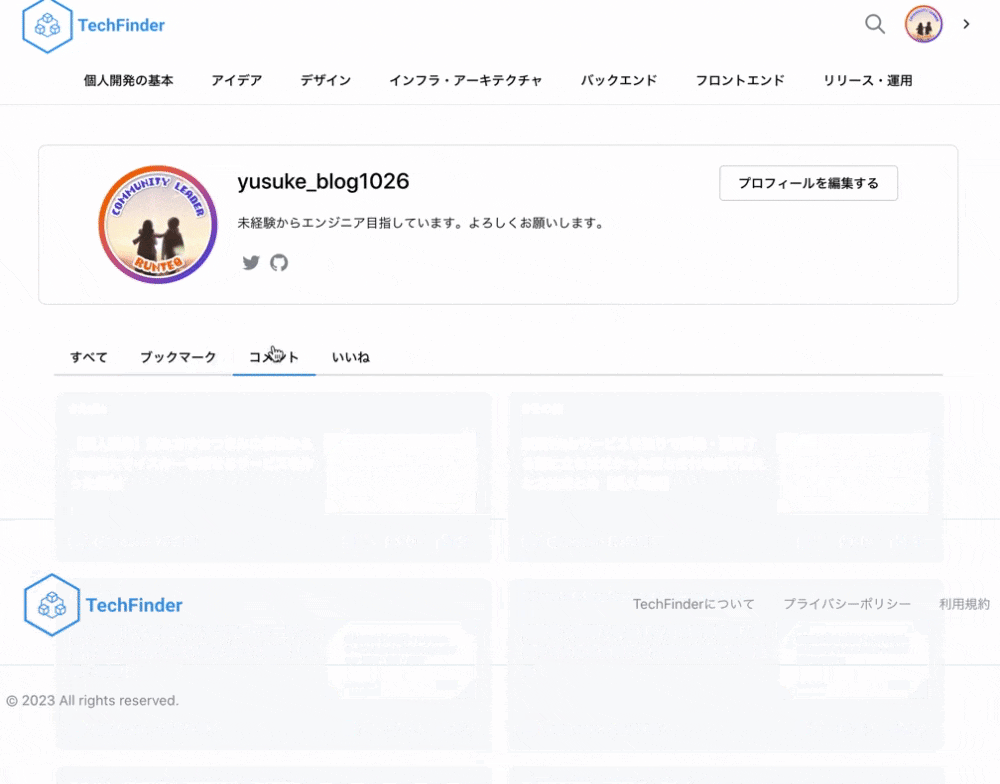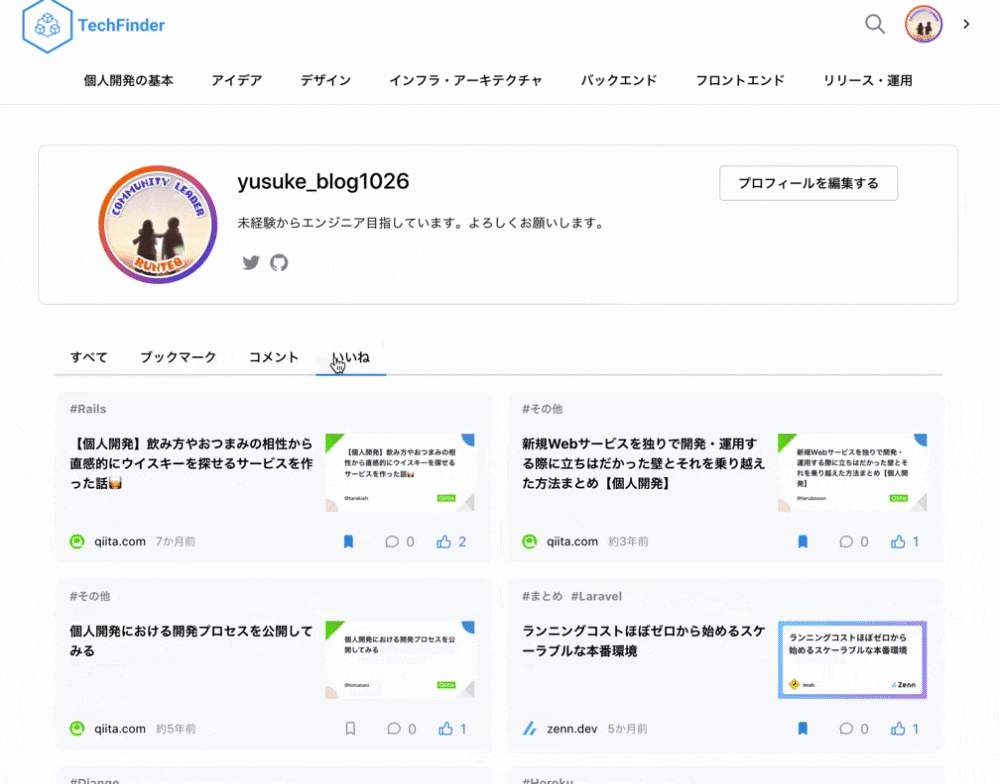 |
| ログインボタンを押すと、モーダルが立ち上がりGoogleログインが可能になります。 | マイページ上でブックマークやいいねした記事を管理することができます。 |
工夫した点
次に工夫した点ですが、以下の3つになります。
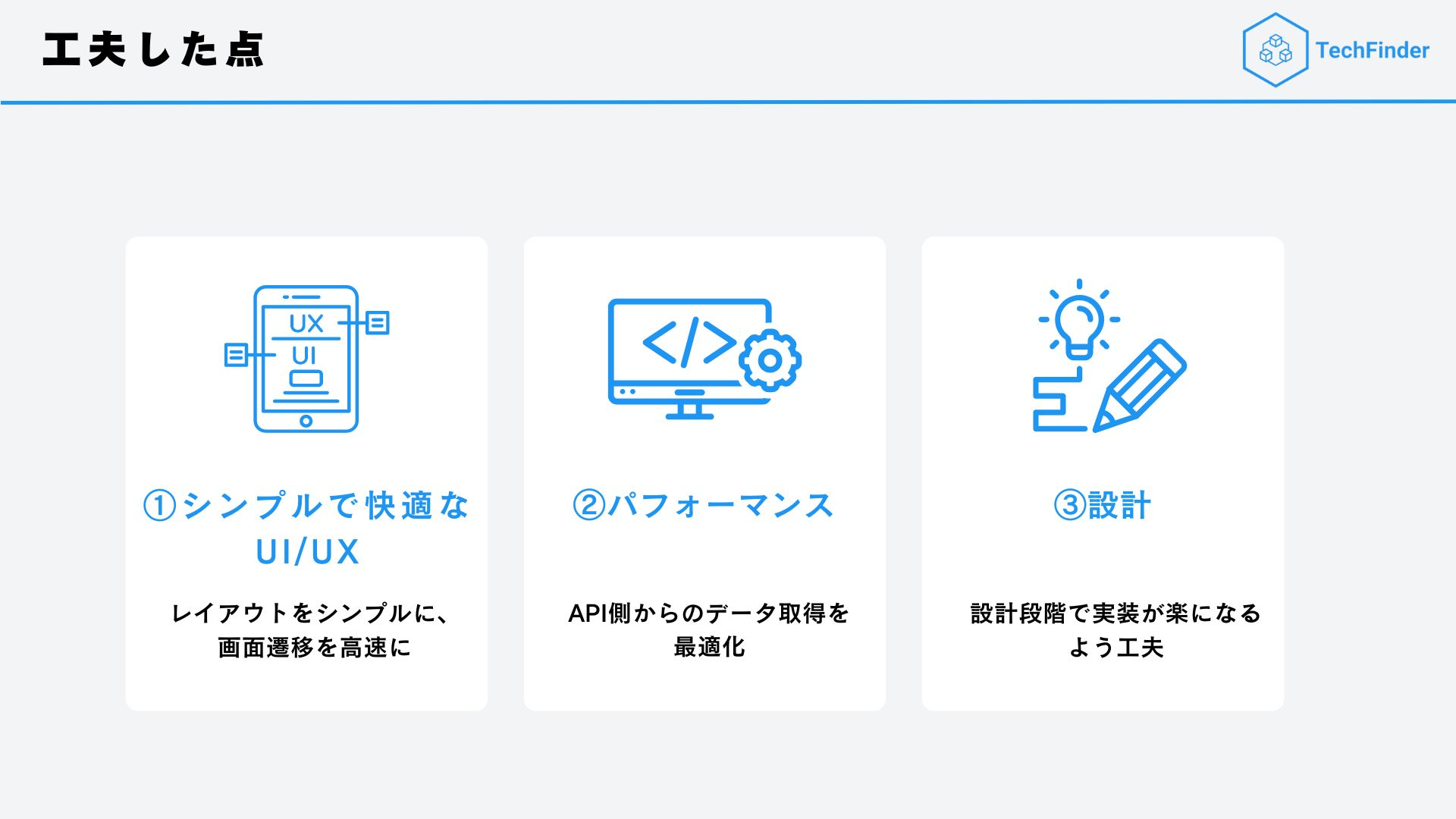
1. シンプルで快適なUI/UX
まず意識したのが、「シンプルなUI」と「快適なユーザー体験」です。
具体的には必要最小限の機能のみを実装することで、技術系サイトにありがちなごちゃごちゃ感を無くしました。
他にも
カテゴリはできる限りアイコンを表示するようにし、初学者の方でも検索しやすいようにした- 技術記事は鮮度や「どのくらいの人に読まれているか?」が重要なため、ただ記事を羅列するだけでなく
投稿日時や人気順でソートできるようにした
といった工夫をしました。
| カテゴリをアイコン表示 | 投稿日時・人気順にソート可能 |
|---|---|
 |
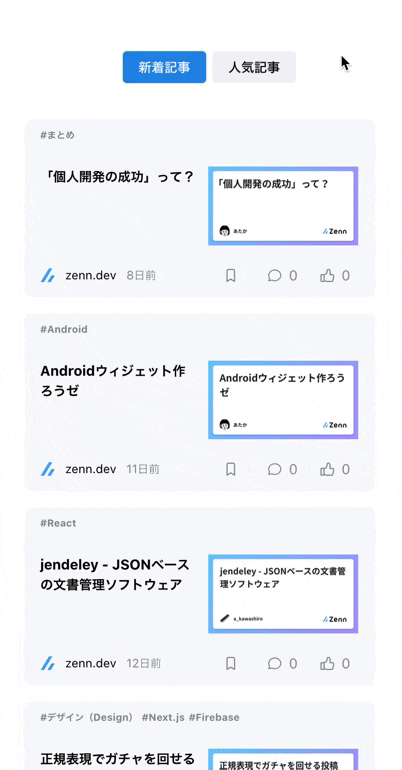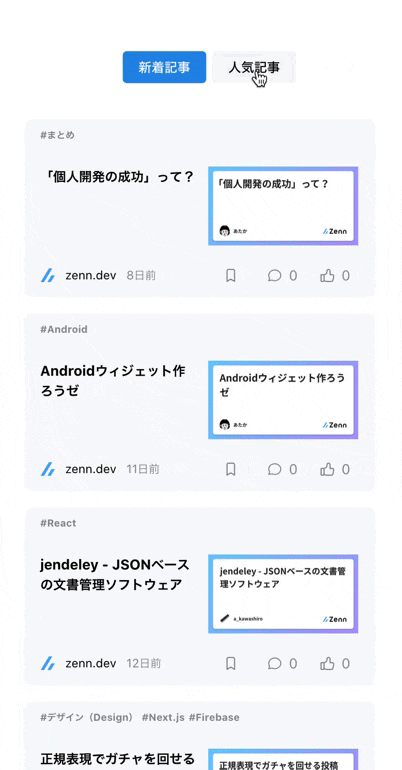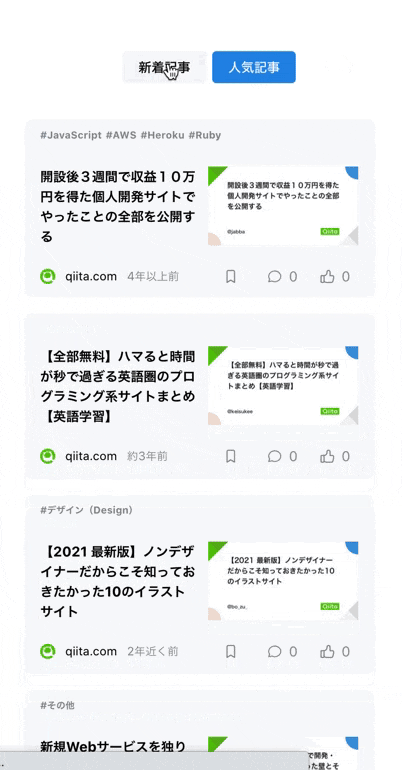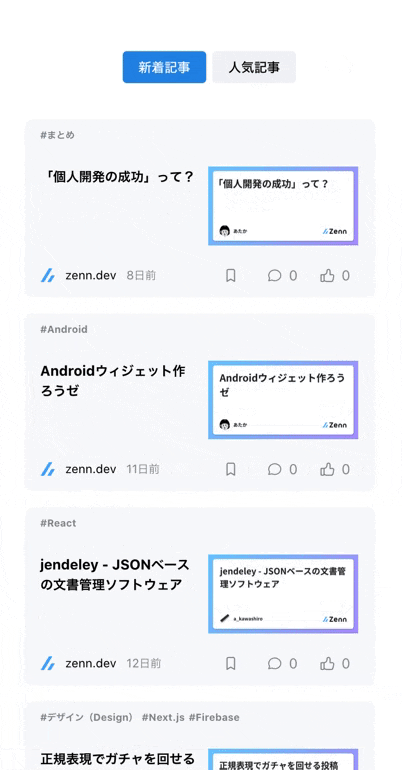 |
| カテゴリは極力アイコン表示することで、ユーザーが直感的に絞り込めるようにしました | 記事は新着順や人気順に並び替えられるようにしました |
次にカテゴリをタップしてどんどん関連カテゴリの記事を閲覧できるようにしたかったため、高速に画面遷移できるCSR前提のSPA(シングルページアプリケーション)を採用しました。
2. パフォーマンス
次にパフォーマンス面に関してですが、非同期状態管理ライブラリの1つである「TanStack Query」を用いることでAPI側からのデータ取得を最適化し、以下の2つを実現させました。
▼TanStack Query公式ドキュメント

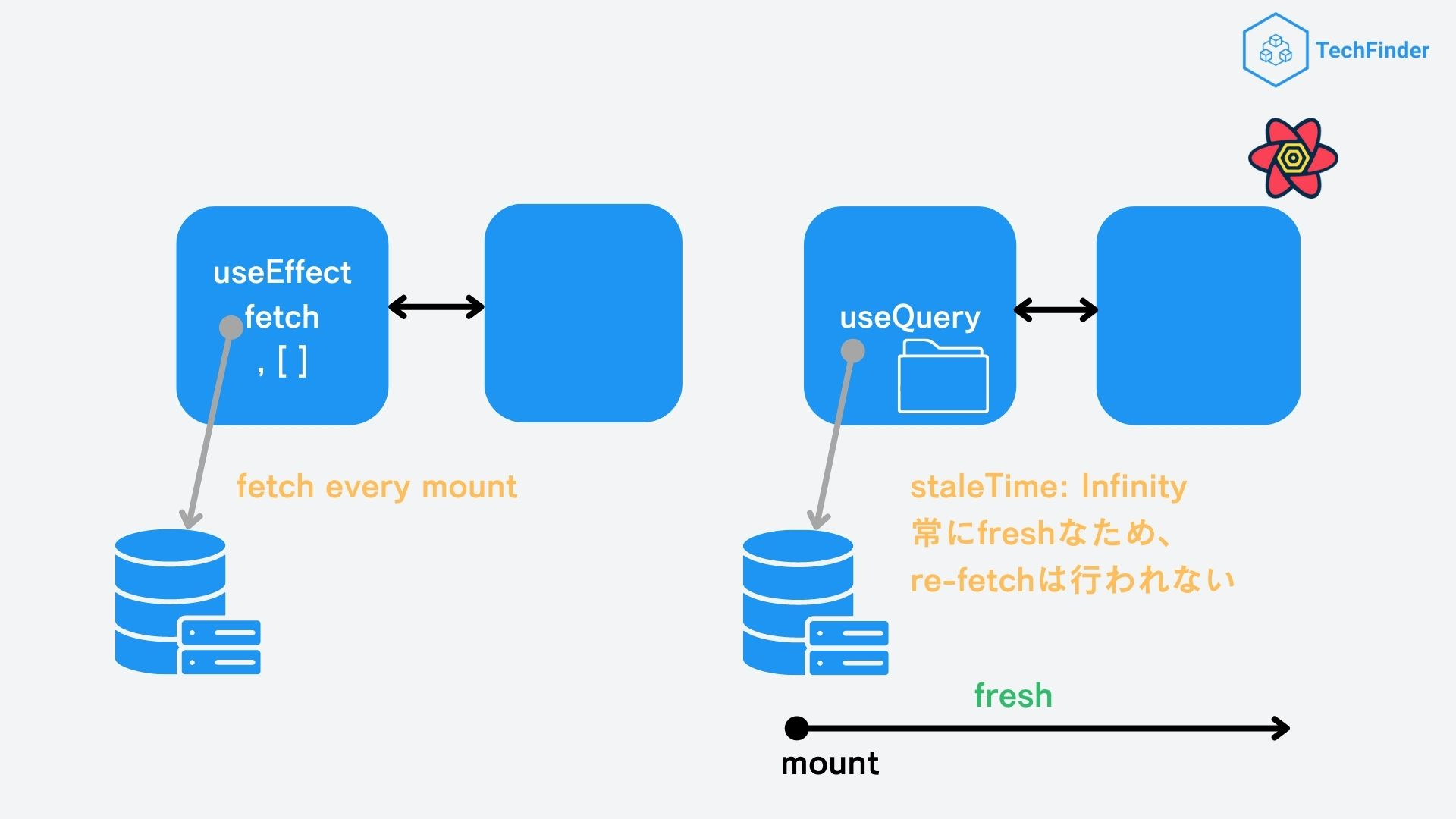
2-1. Fetch回数の最適化
まずはFetch回数(データ取得回数)の最適化です。
通常Reactでアプリケーション開発を行う場合、API側からのデータ取得にはuseEffectを用いた以下のようなコードを書くことが多いかと思います。
import axios from "axios"
const ClassicalFetch = () => {
const [loading, setLoading] = useState(false)
const [error, setError] = useState()
const [data, setData]= useState()
useEffect(() => {
setLoading(true)
const fetchTodos = () => {
axios.get("https://jsonplaceholder.typicode.com/todos").then(res => {
setData(data)
setLoading(false)
}).catch((err) => {
setError(err.message)
setLoading(false)
})
}
fetchTodos()
}, [])
if(isLoading){
return "loading..."
}
if(error){
return "error!"
}
return // 省略
}
これをTanStack Queryに置き換えると...
import axios from "axios"
import { useQuery } from '@tanstack/react-query'
const WithReactQuery = () => {
const { isLoading, error, data } = useQuery(['todos'], () => axios.get('https://jsonplaceholder.typicode.com/todos'))
if(isLoading){
return "loading..."
}
if(error){
return "error!"
}
return // 省略
}
非常に簡潔に書けるようになりました。
このようにTanStack Queryを用いることで、非同期の状態管理を快適に行えるようになります。
これが最も基本的なTanStack Queryの使い方のひとつです。
今回はこれを少し応用して「キャッシュの永続化」を行いました。
そもそもTanStack QueryにはAPIから返ってきたデータをしばらくの間、Cacheという場所に保持してくれる機能があります。
これにより同じリクエストをしたときには、Cacheに保持していたデータを取り出して使うことができ、サーバーにいちいちデータを取得しに行くより、はるかに早いスピードでデータを表示できるようになります。
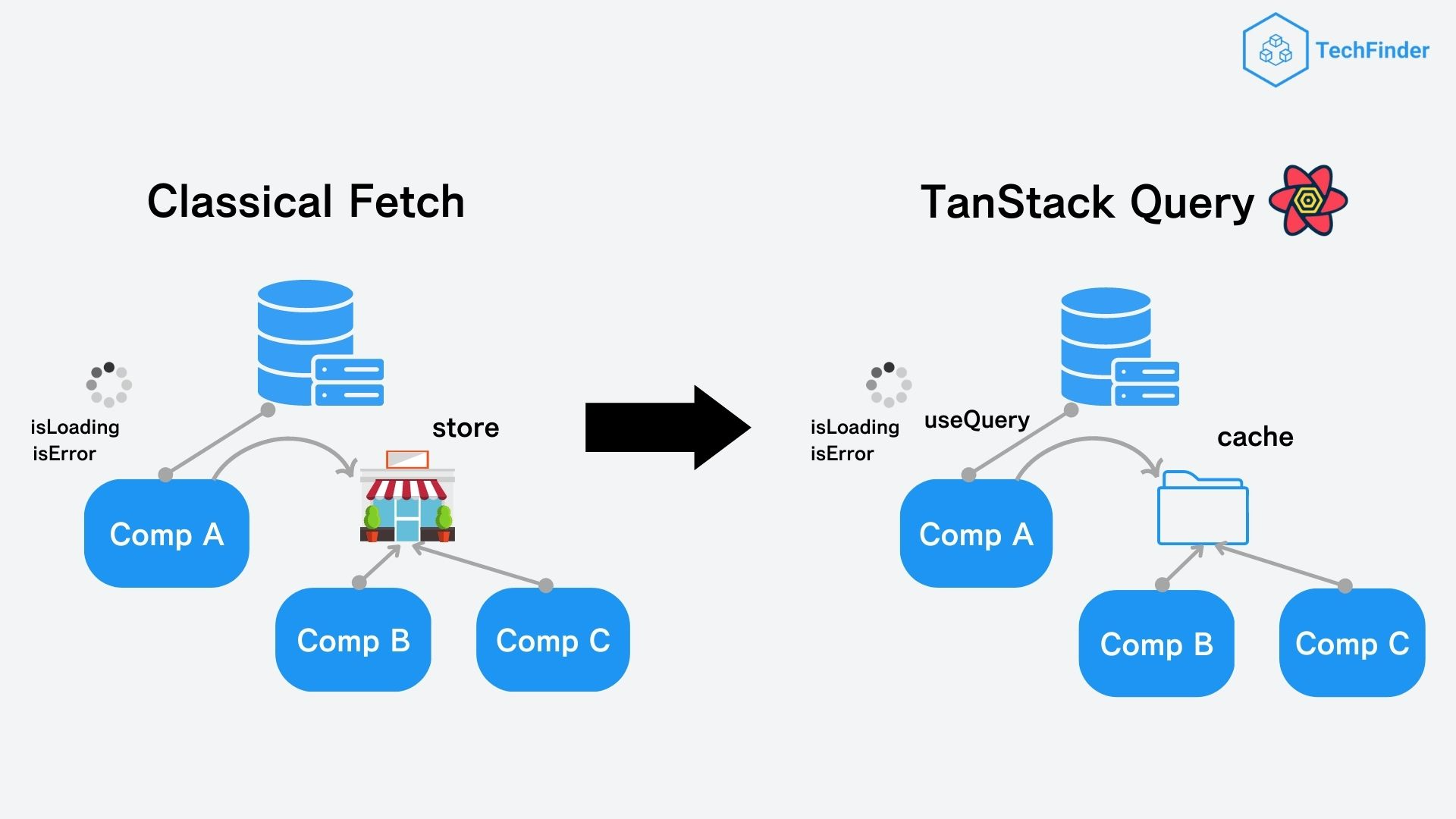
そして、TanStack QueryはこのCacheの状態をコントロールするためのオプションもいくつか用意してくれています。
今回は「staleTime」と呼ばれるオプションを用いて、APIエンドポイントごとにキャッシュ再検証のタイミングを調整することにしました。
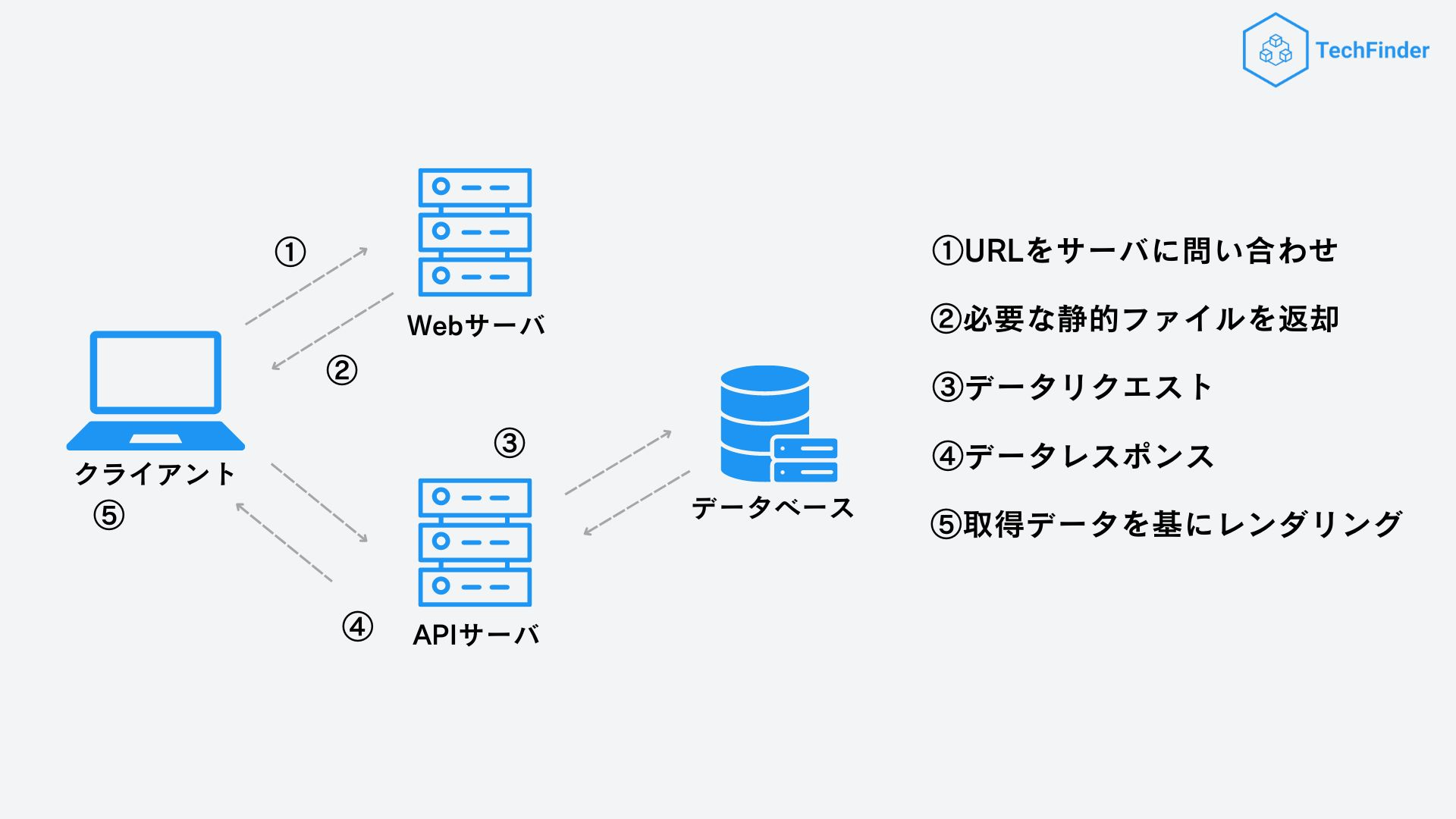
TechFinderでは、記事データの処理方式は基本的に以下の通りになっています。
- エンドユーザー側からは書き換え不可能
- 3日に1回バッチ処理を走らせて、更新をかける(記事本来のいいね数の更新・記事の追加)
- 管理画面での手動更新(今後実装予定)
ここから分かる通り、基本的にエンドユーザー側では記事データのリアルタイム性がほとんど必要ないため、記事データ取得に用いるエンドポイントは基本的にstaleTimeをinfinityにしてキャッシュデータを常にfreshに保つようにしました。
// 省略
const { status, data } = useQuery<Article[], Error>({
queryKey: ['articles', params.tab],
queryFn: getArticles,
staleTime: Infinity,
onError: (error) =>
alert(`記事情報の取得に失敗しました。\n${error.message}`),
});
// 省略
こうすることで、データ取得をコンポーネントの初回マウント時のみに限定することができ、大幅なFetch回数の削減に成功しました。
2-2. Better UX by Stale While Revalidate
次にHTTPキャッシュ無効化戦略である「Stale While Revalidate」を用いてUXの向上を図りました。
そもそも「Stale While Revalidateってなんぞや?」って方も多いと思いますので、簡単に説明しておきます。
「Stale While Revalidate」とは「キャッシュの再検証中に古いレスポンスデータを表示させておくことで、クライアント側から見ると常に最新のデータが表示されているよう認識させる」というキャッシュ戦略のひとつになります。
詳細は、以下のドキュメントなどに書かれていますのでここでは割愛させていただきます。
これにより、通常だとマウントのたびにデータ取得中の表示としてローディングアイコンなどを表示させる必要があったところが、TanStack Queryだとローディングアイコンが表示されるのは初回リクエスト時のみで後はマウントのたびに古いキャッシュデータを表示させられるようになります。
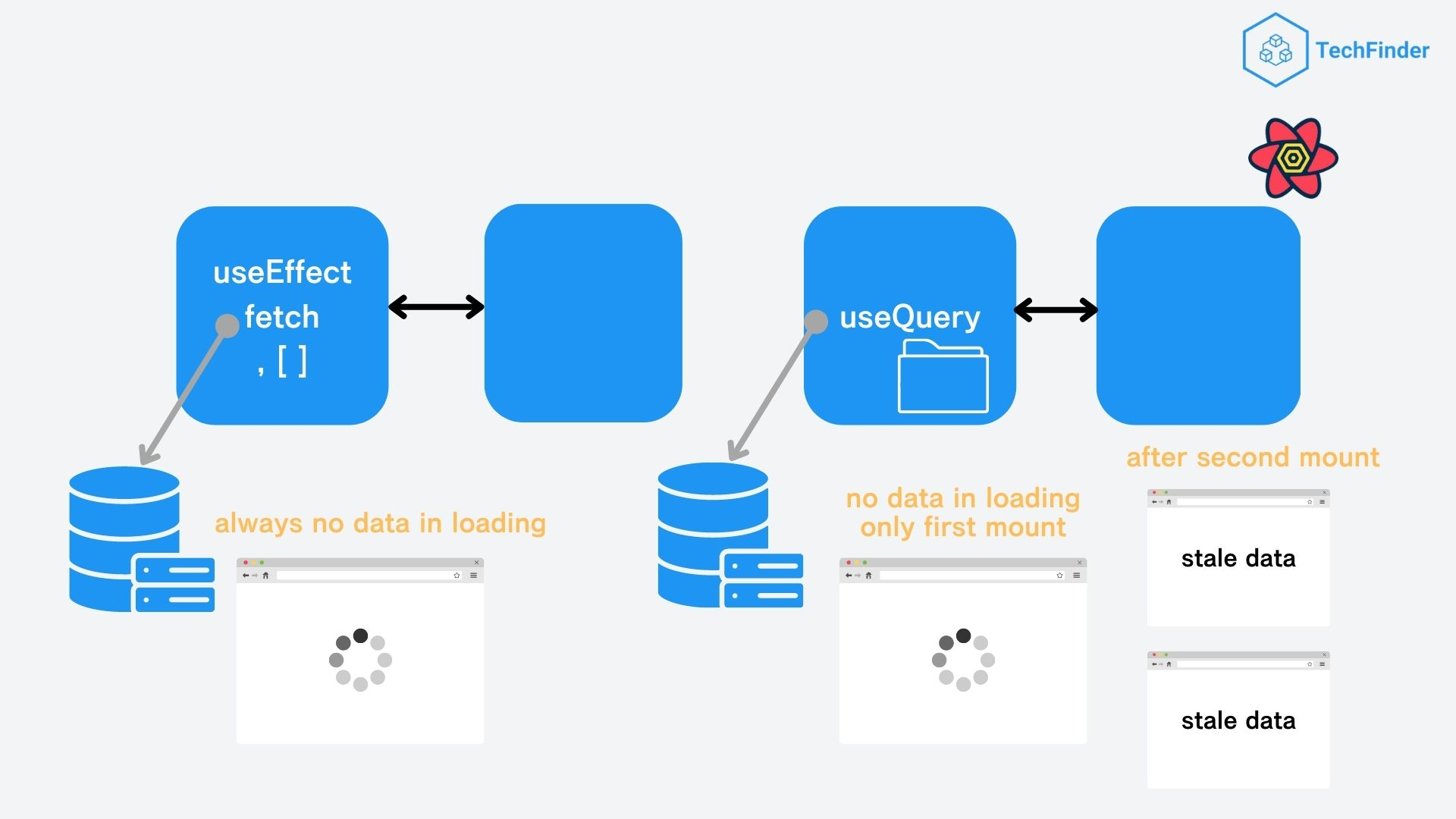
左よりも右のほうがユーザー体験が良いことは一目瞭然でしょう。
3. 設計
最後に、今回はリリースまでの日数が限られていたため、設計段階でもいくつか工夫をしました。
3-1. コンポーネント設計
まず1つ目が「コンポーネント設計」です。
Figma上でワイヤーフレームを作成するのと同時にそれらをコンポーネントの階層構造にまで落とし込みました。
具体的にはまず以下のようにコンポーネントの階層構造を赤の点線で表現し、コメントでコンポーネント名とpropsを書いていきました。


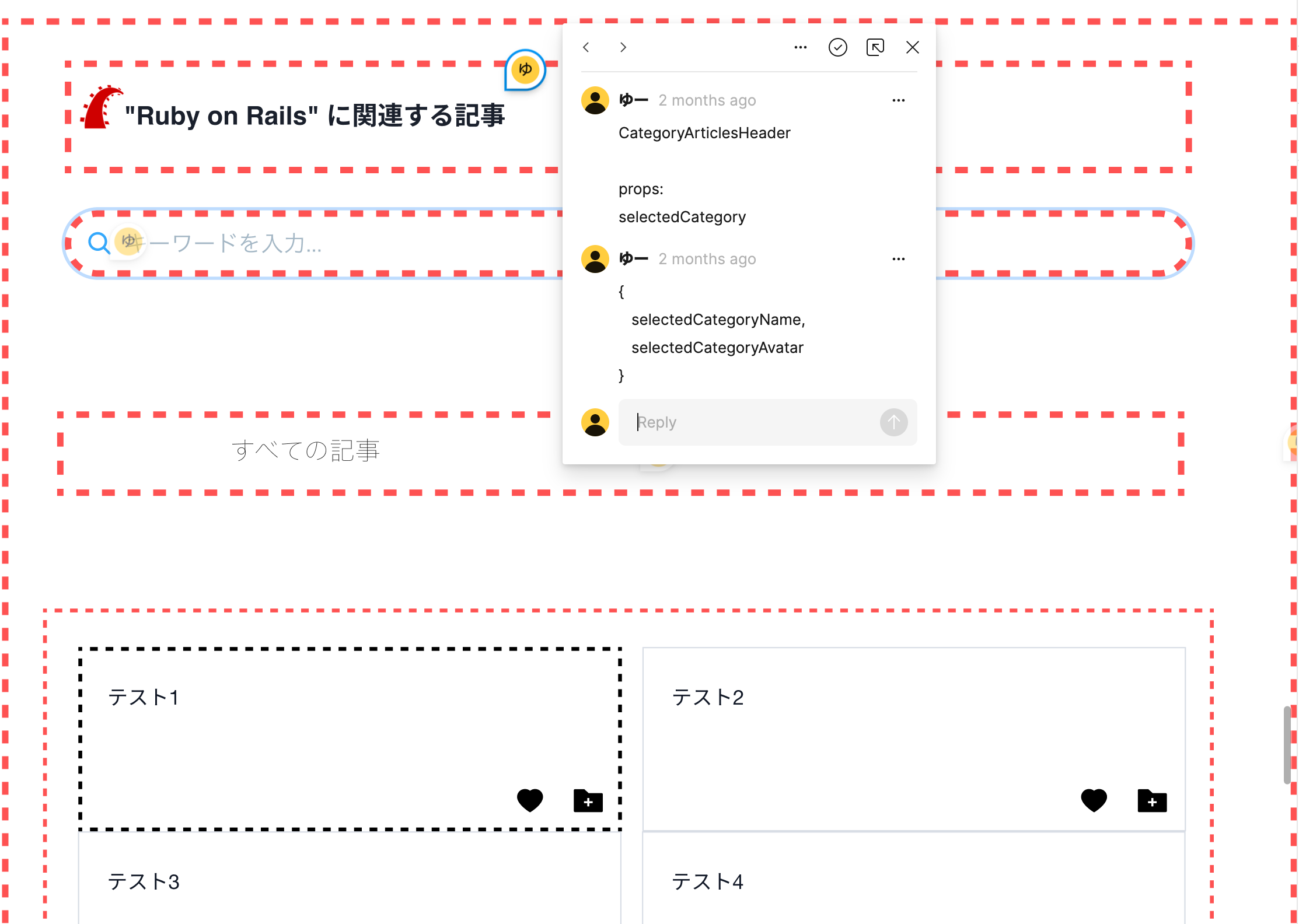
さらにこれらをよりわかりやすく整理するため、Notion上で再び階層構造に書き出していきました。
(以下の図は最終的な階層構造になっているためprops以外にもstateが定義されていますが、本来はこの段階ではstateは定義していません。)

この段階では「Reactの流儀」にのっとってあくまで「Presentationalなコンポーネント」(スタイリングにのみ責務を持たせたコンポーネント)だけを定義していっています。
▼Reactの流儀
そして、上記のNotion上に落とし込む作業が終わったら最後にstateを定義し、配置場所を決めていきます。
この時に意識したのは以下の2点です。
-
必要最小限のstateになるよう定義。
- 例えば検索文字列でフィルタしたカテゴリ一覧はstateにはなり得ません。これは検索文字列ともとのカテゴリ一覧を組み合わせることで算出することが可能だからです。
-
stateはできる限り共通の親コンポーネントで定義
- 例外的にページを跨いで横断的に利用されるstate(例えばログインユーザーの情報)やバケツリレーが発生し得るstateに関しては
グローバルなstateとしてReduxのstoreに格納しました。 - またAPI側から取得してきたデータに関してもcacheを利用できるようにするため、
server stateとして完全に別物として扱うようにしました
- 例外的にページを跨いで横断的に利用されるstate(例えばログインユーザーの情報)やバケツリレーが発生し得るstateに関しては
これらの作業を行うことで、実装前段階で「再利用な可能なコンポーネントはどれか?」「stateはどこに定義すれば良いか?」「propsとして何を受け渡せば良いか?」がはっきりし、実装がスムーズに行えるようになりました。
【補足】
これらのコンポーネント設計については、以下の記事を参考にしました。
FigmaやNotionを使った設計作業というのは完全にこちらをパクらせていただいております。
コンポーネント設計に興味ある方はぜひこちらの記事も参考にしてみてください。
3-2. IDaaSを用いたソーシャルログイン
次にユーザー体験・実装コスト・セキュリティ面などを考慮し、ログイン機能の実装にはFirebase Authを用いたソーシャルログインを採用しました。

まず通常のSPAアプリケーションでログイン機能を実装するとなると、選択肢はJWTもしくはセッションを用いた認証になるかと思います。
ただどちらも一長一短があり、セキュリティについての詳しい知識も要求されるためできれば避けたいなぁと考えていました。
また
- 登録手続きが面倒だと離脱率が上がる可能性がある
- 脆弱性をカバーできるほどの実装力や知識がない
という理由からパスワード認証もできれば採用したくないと考えていました。
「こんなわがままな要望を叶えてくれる素晴らしい認証サービス、どこかに転がっていないかなぁ〜」
そんなことを考えていた矢先、以下の書籍や記事に出会い「Firebase Auth(IDaaS)いいじゃん!!」となり、ログイン機能の実装に用いることにしました。
具体的な実装方法については割愛させていただきますが、設計する上でいくつか押さえておいた方が良い点がありましたので簡単にご紹介しておきます。
(一応実装の流れとしては以下のようなイメージです。)
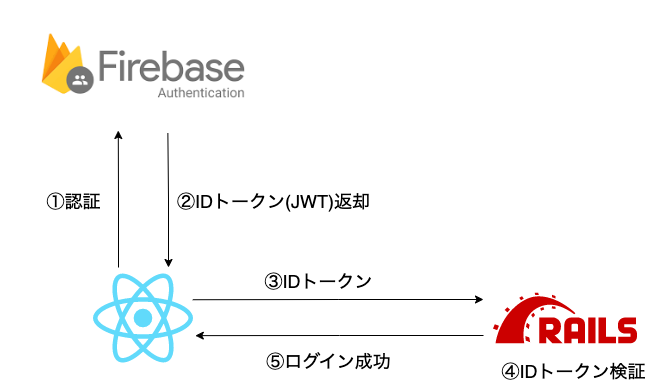
まずひとつ目が、「Firebase AdminSDKがRubyをサポートしてくれていない」という点です。
現状(2023年2月9日時点)だとAdmin SDKは
- Node
- Java
- Python
- C#
にしか対応しておらず、Rubyを用いてIDトークンを検証する(上の図でいうと④)には少し工夫が必要になります。
今回は「サードパーティJWTライブラリを用いて認証部分を自前で実装する」という手法を取りました。
次に重要な点が「その自前での検証方法が複雑で大変」という点です。
やることとしては以下のドキュメントを読んで実装していくだけなのですが、これがまぁ大変でした。
▼Firebase公式ドキュメント
今回はざっくり以下のような流れで沿って実装しました。
- JWTトークンをデコード
- トークン情報のフォーマットチェック
- トークンが正しい秘密鍵から作られていることを確認
ここでひとつ気をつけなければいけないのは、署名検証(上記のステップ3)には公開鍵を取得する必要があり、そのためにはトークンを予め1度デコードしておく必要があるという点です。
そのため実際のデコードに入る前に、一度(検証をスキップした)デコードを挟む必要があります。
つまり実際の実装手順としては
1回目は署名検証に必要な公開鍵識別子(kid)の取得のため、検証なしでJWTトークンをデコードする。これにより自分の署名検証に必要な公開鍵を特定し、Googleから取得する- 2回目のデコード(検証あり)
- トークン情報のフォーマットチェック
- トークンが正しい秘密鍵から作られていることを確認
という順序で行う必要がありました。
他にも色々と実装方法はありそうですが、個人的にはこちらの流れが1番しっくりきました。
【補足】
今回は紙面の都合上、Firebase Authを用いたログイン機能実装の詳細については説明を割愛させていただきました。
そのため「もう少し詳しい実装内容が知りたいんだけど!?」という方もおそらくたくさんいらっしゃることでしょう。
そこで、今回私が実装する際に実際に参考にした記事を以下に挙げておきました。興味ある方はぜひ参考にしてください。
-
Rails編 - Rails + Next.js + Firebase V9 Authentication で認証付きのCRUDアプリを作る
- 個人的にはこちらの記事が一番まとまっていて分かりやすかったです。
- 特にトークン検証の実装の説明が本当に分かりやすい...バックエンドにRubyを使用していてAdmin SDKが利用できない場合はまずはこちらの記事を参考にすると良いでしょう
- またフロント側のコードも載っていますので、Firebaseを使った認証機能を実装したことない人でも参考になるかと思います。
-
RubyでFirebaseのidトークンを認証に使ってみる
- こちらも自前での検証コードが書いてあって非常に参考になりました。ただ若干説明が薄い気がするので「JWTが何なのか?」くらいは知っておく必要がありそうです
-
Rails API×Firebase authの場合、Railsは何をすべきなのかを考えた【設計編】
- 実装の全体の流れをつかみたい人はこちらの記事がおすすめです。
主な使用技術
主な使用技術は以下の通りです。
フロントエンド
- React 18.2.0
- TypeScript 4.6.4
- TailwindCSS 3.2.4
- Mantine 5.8.2
その他の主要なライブラリ
- vite 3.2.3
- react-router-dom 6.5.0
- react-helmet-async 1.3.0
- zod 3.20.2
- axios 1.2.1
- date-fns 2.29.3
- @reduxjs/toolkit 1.9.1
- @tanstack/react-query 4.22.0
- @tabler/icons 1.116.1
- eslint 8.28.0
- prettier 2.7.1
- msw 0.49.2
- husky 8.0.2
- lint-staged 13.0.3
技術選定理由
設計面の工夫でも話しましたが、今回はリリースまでの日数が限られていたので「"使い慣れていて"かつ"実装スピードを上げられる"」ライブラリを中心に選びました。
まずメインとしては「React+TypeScript+Mantine+TailwindCSS」の構成を採用しました。
React+TypeScriptは使い慣れているという理由から、Mantineに関してはコンポーネントの数が膨大かつ便利なHooksが予め準備されている(特にform系があるのが最高)という理由から高速で実装できるであろうということで選びました。
この見立て通りMantineは必要になるであろうコンポーネントがだいたい用意されいて、尚且つドキュメントも(MUIと違って)読みやすかったため非常に助かりました。
▼Mantine公式ドキュメント
TailwindCSSはbulletproof-reactでも言及されていますが、zero-runtime CSSによるパフォーマンス向上(どこまで効果あるのか知らない)、そしてMantineとの相性が良いこと(内部の隠蔽されたclassNameへアクセスでき、細かなスタイリングの調整が可能)、さらにそもそもJS非依存によりコンポーネントライブラリとの相性が良いということで採用しました。
If your application is expected to have frequent updates that might affect performance, consider switching from runtime styling solutions (Chakra UI, emotion, styled-components that generate styles during runtime) to zero runtime styling solutions (tailwind, linaria, vanilla-extract, CSS modules which generate styles during build time).
(拙訳)
アプリケーションの更新が頻繁にあり、パフォーマンスに影響を与える可能性がある場合、ランタイム・スタイリング・ソリューション(Chakra UI、emotion、ランタイム中にスタイルを生成するstyled-components)から、ゼロランタイム・スタイリング・ソリューション(tailwind、linux、vanilla-extract、構築中にスタイルを生成するCSS modules)への切り替えを検討します。
▼bulletproof-react
まぁあとは単純に実装スピードも上げられますしね。
その他のライブラリに関しても、いくつか抜粋して理由を述べておきます
-
Vite
- CRAと比べると圧倒的に速い...速すぎる
- やはりノーバンドルというのは偉大
- 開発サーバーの起動時間は短いに越したことないので、採用して本当によかった
- CRAの未来はいかに?
-
zod
- 何かと話題になりつつあるのでとりあえず入れてみた
- Mantineのform系APIとも併用できたので使いやすかったです
- そんなに凝ったバリデーションをかけているわけではないので、騒がれている理由がそこまで分からず...
- たぶん自分が使いこなせていないだけなので今後ちゃんと勉強していきたい
-
Redux(Redux Toolkit)
- 使ったことがあるという単純な理由でRedux(Redux Toolkit)を採用
- データの一方通行的な流れはわかりやすくて好きです
- 実装の後半では時間なかったのでとりあえず脳死でstoreぶち込みマンと化していました←
- contextと比べると「Provider地獄を避けられる」「レンダリングを勝手に最適化してくれる」「拡張機能が使える」あたりが利点かなと思いました
- ただそこまで大規模なアプリケーションではない場合、「使うのはどうなのかな〜」と思ったり。
-
eslint & prettier
- コードの品質を保つためには必須です。
- VSCodeと連携させて、ファイル保存時に自動整形が効くよう設定しました
- またeslintはpluginをいくつか入れてカスタマイズしています
- 特にeslint-plugin-simple-sortやeslint-plugin-unused-importあたりはimportを勝手にきれいにしてくれるので使ってて気持ちよかったです
-
msw
- バックエンド側の実装が整備されていない段階でもフロント側の実装を進められるようにするために採用
- ただViteとの相性が若干悪い(requireが使えないことが原因)
-
husky & linst-staged
- pre-commit時にリントチェックとフォーマッタを走らせるようにし、バグを生みにくく統一されたコードを生成できるようにしました
バックエンド
- Rails 6.1.6(APIモード)
- Ruby 3.0.4
その他の主要なgem
- rack-cors
- jwt
- aws-sdk
- jsonapi-serializer
- faraday
- nokogiri
- seed_fu
技術選定理由
こちらもフロント側とほぼ同じ理由(使い慣れている+実装速度)です。
取り立てて説明する必要がないgemばかりですが、JSONシリアライザは少し説明を加えておきます。
今回JSONシリアライザとしてはjsonapi-serializerを使用しました。
これによりJSON::APIフォーマット形式でバックエンド-フロントエンド間でデータをやりとりできるようにしています。
ひとつ注意点としましては、フロントエンド 側にも同様のライブラリが存在していてバックエンド側のjsonデータをデシリアライズすることが可能なのですが、こちらを利用してもデシリアライズ結果には型が付与されないようになっています。
そのため、型安全なコードをフロント側で書きたい場合はデシリアライズ前のレスポンスデータと後のpropsとして受け渡すために整形したデータの型をそれぞれ「手動で」定義する必要があります😅
これだと型安全と言えるかどうか少し怪しいので、厳密なコードを書きたい場合はあまり使わない方が良いでしょう。
(↓この辺りをうまく使いこなそうとすると自前で関数などを定義する必要があるので大変そう...)
他にもトークン検証用のコードを書く必要があったのでjwtを使用、またAPIクライアントとしてはfaradayを利用しています。
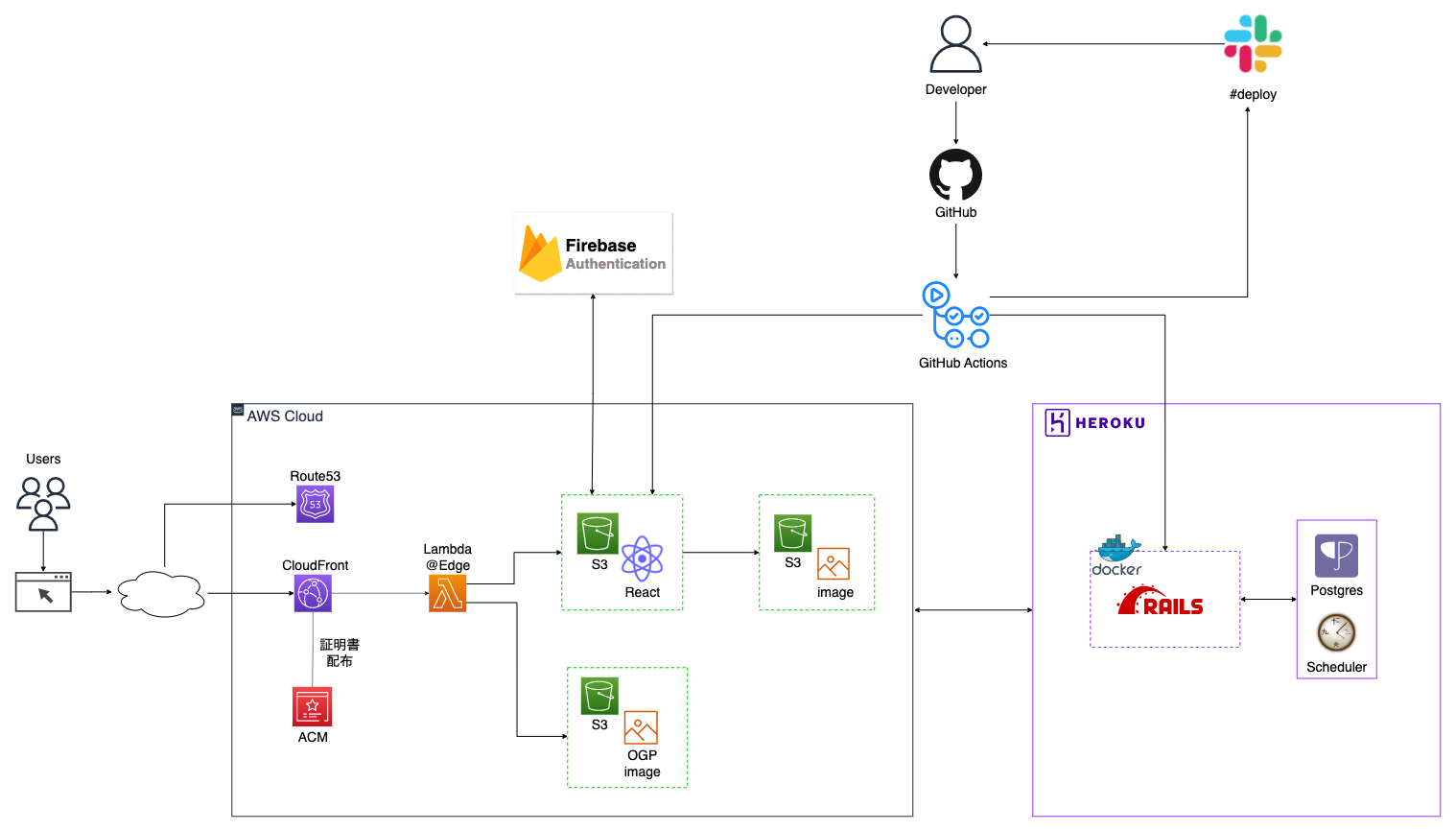
インフラ・開発環境
インフラ構成、開発環境は以下の通りになっています。
- インフラ
- heroku
- AWS(Route53, CloudFront, S3, Certificate Manager, Lambda@Edge)
- GitHub Actions
- 開発環境
- Docker
- docker-compose(Rails, Puma, Postgres)
- その他
- Firebase Authentication
- Qiita API
技術選定理由
いくつかポイントがありますので、簡単にご紹介させていただきます。
まず1つ目のポイントは、「GitHub Actionsを用いた自動デプロイ(+自動テスト)に対応させた点」です。
具体的には、プルリクエスト作成時にフロントエンド・バックエンドともにリントチェックやテストを行うようにし、それが通ったらmainブランチへのpush・mergeをトリガーにそれぞれherokuとS3へデプロイするよう設定しています。
これにより手動でのデプロイが必要なくなり、開発速度が格段に上がりました。
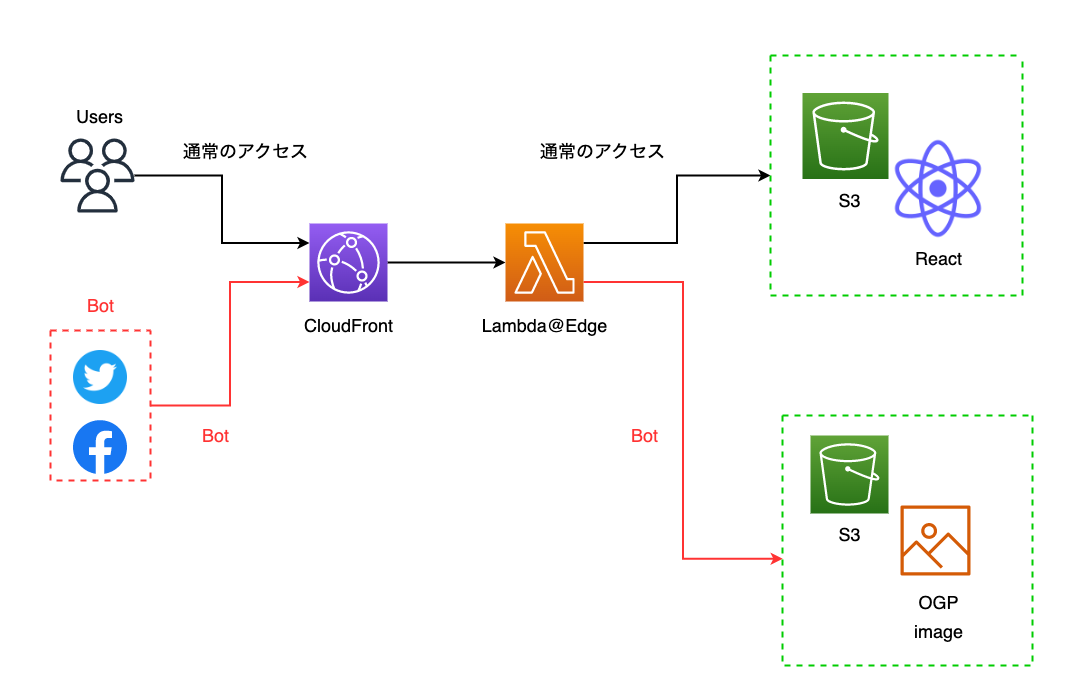
2つ目のポイントとしては、「Lambda@Edge を使ったOGPへの対応」です。
前提としてSPA では、単一の Web ページがあたかもページ遷移するかのようにコンテンツの切り替えが行われ、それらのコンテンツ切り替えは、ブラウザ上で JavaScript によって処理されています。
しかし、SNS などでシェアされた際に OGP を表示したい場合は、一手間必要です。
なぜなら URL を投稿された際にクローリングする Twitter や Facebook などの各クローラは JavaScript を解釈しないため動的に OGP を返すことができないからです。
この動的なOGPに対応させるための方法はいくつかありますが(そもそもSSRさせるとか...)、今回はフロント側はS3+CloudFrontという構成を取っていたため、Lambda@Edge を使って User-Agent で bot かどうか判断し、HTML を返すというお決まりの手法を取りました。
実装の詳細について知りたい方は以下の記事をご覧ください。
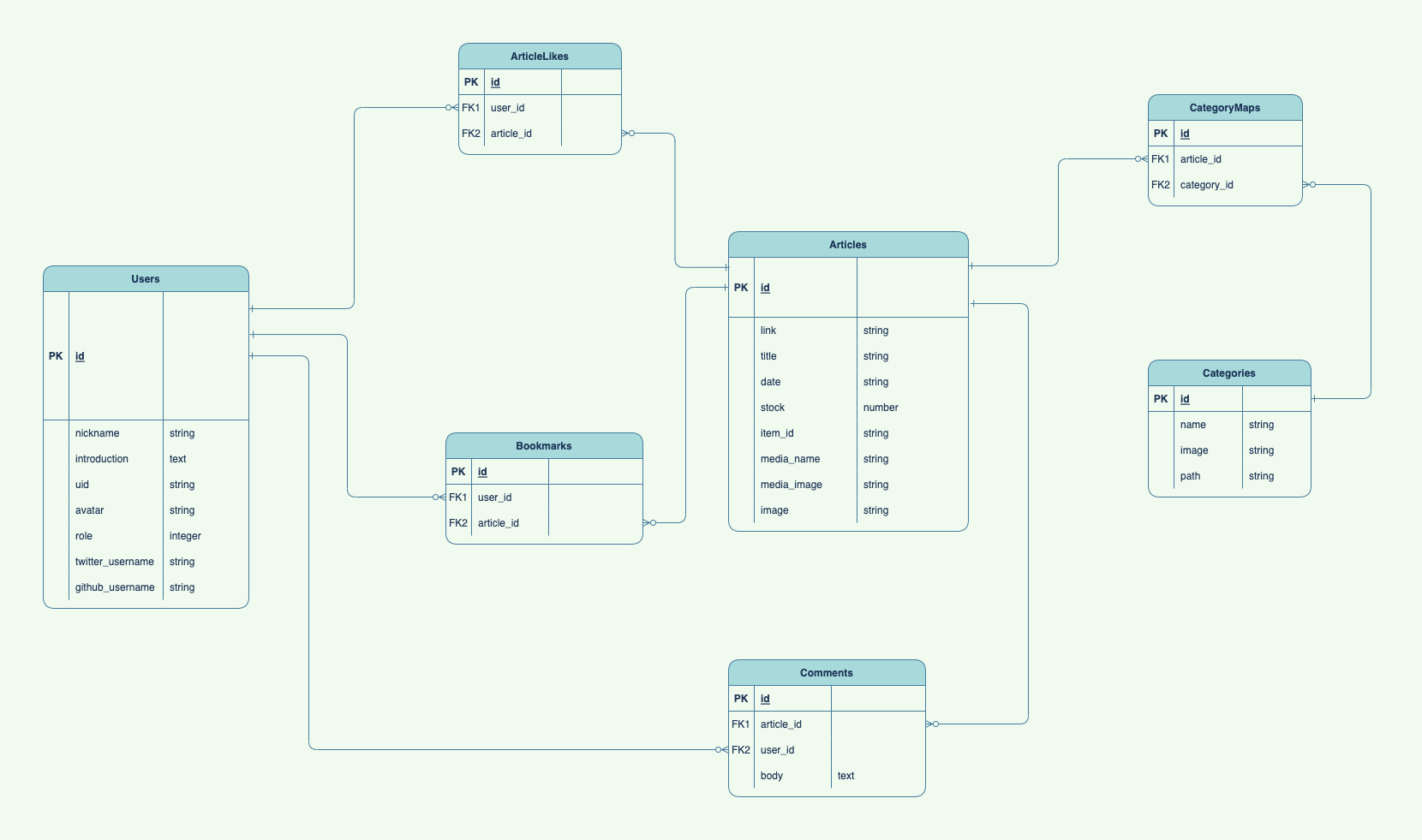
ER図
ER図は以下の通りです。
作成期間
全体の作成期間は約2ヶ月、内訳としてはスクール内でのMVPリリースまでが約1ヶ月、本リリースまでが約1ヶ月となっています。
開発時間は平日は平均して5h、休日は7hほど費やしました。
①MVPリリースまで(2022年12月〜2023年1月11日)
MVPリリースまではおおよそ以下のような工程を踏んで開発を行いました。
-
企画
-
要件定義・スケジュール作成
-
設計
- ワイヤーフレーム作成
- コンポーネント設計
- データベース設計
-
開発環境構築
- フロント側はViteを使用
- バックエンド側はローカル環境と本番環境での差異をできる限り減らし、かつ自動デプロイを可能にするためDockerを利用
-
Rails側をHerokuに、React側をAWS(CloudFront + S3)にデプロイ
- Herokuは慣れていたため(コスト面が致命的なのでそのうち移行する予定)
- CloudFront+S3はOGPへの対応のしやすさを考えて。
-
GitHub Actionsを用いたCI/CDパイプラインを構築
- Circle CIはレイオフがあったり、最近ではセキュリティインシデントも発生していたため採用を見送りました
-
各機能の実装
- フロントエンド→バックエンドの流れで実装
- MSWを利用し、バックエンド側の実装を待つことなくフロント側の実装を先に終わらせた
「MVPリリースまでをいかに素早く行えるか?」が今回の開発の肝だったので、精神的かつ時間的余裕がある開発し始めの時期に先述のライブラリを導入したり、デプロイの自動化といった準備をしっかりと行いました。
また設計面においても(先述の通り)いくつか工夫をして、スムーズに開発に移行できるようにしました
これにより後半だんだん時間がなくなっていく中でも、比較的落ち着いて色々な問題に対処することができたような気がします。
②本リリースまで(2023年1月11日〜2月9日)
MVPリリース後から本リリースまでは以下の流れで進めました。
だいたいこちらの記事に書いてあることをやっただけです。
-
独自ドメインの取得と対応
- 通知がひどかったので、お名前.comではなくGoogle Domainsで取得しました
- Route53を用いて独自ドメインでのアクセスも可能にしました
-
利用規約・プライバシーポリシー・Aboutページ等の設定
- 利用規約やプライバシーポリシーの作成にはKIYACというサービスを用いました
-
Google Analyticsの導入
-
titelタグ・メタディスクリプションの設定
- react-helmet-asyncというライブラリを用いました
-
OGPの設定
-
MVPリリースでいただいたユーザーの声を聞いて、一部機能を追加+改善
-
Twitterで告知+Qiitaの執筆
【個人開発】
— ゆー (@yusuke_blog1026) February 10, 2023
個人開発に役立つ技術記事を簡単に検索・閲覧できるサービス「TechFinder」をリリースしました!https://t.co/NX2y2Z2XFW
特にポートフォリオ作りに悩んでいる #駆け出しエンジニア の皆さんに重宝するサービスとなってますので、ぜひ利用してみてください〜👏 pic.twitter.com/zuRD4Ra6Ff
他にも
- Sentlyに代表される外形監視ツールの導入
- 運用コストを抑えるためのインフラ移行(Heroku→FlyやCloud Run)
- 画像配信の最適化
- パフォーマンスチューニング
- Next.jsへリプレースしSSG+CSRの構成にし、データフェッチをしない箇所はビルド時に生成することで表示速度を速くする
- コンポーネントのメモ化を含めたリファクタリング
といったことも行いたかったのですが、時間の都合上今回は見送らさせていただきました。
今後のTechFinderについて
課題点や今後実装したい点については以下の通りです。
-
ユーザーが継続して利用したくなる仕組みがブックマーク以外にない
ブックマーク機能くらいしかユーザーが継続して使いたくなる仕組みが存在していないため、もっと使いたくなる仕組みが必要だなぁと感じています。
(ブックマーク管理をもう少し充実させて、SNS上でシェアしたり外部サイトの記事も追加できる機能とかあったら便利かも?と思っています。) -
継続的なデータの更新・追加
現状Qiita・Zenn・はてブからデータを収集しているのですが、
はてブのデータはカテゴリがQiitaやZennほどちゃんと紐づいていないため(プログラミング言語やフレームワークの具体的なカテゴリ名が記載されていないケースがほとんど)カテゴリとの紐付けは手動で行っています。
これだと継続的に運用していくのは(モチベーション面から)かなり厳しいと考えているので、何かしら対策を打つ必要があるなぁと感じています。 -
認証周りの機能追加
退会機能やリカバリー機能がまだ未実装ですので、時間を見つけ次第早急に対応していきたいと思っています。
-
「本リリースまで」であげたツールの導入・インフラ移行・パフォーマンスチューニング
特に「インフラの移行」と「外形監視ツールの導入」は運用面を考えると必須ですので、早急に対応していきたいと考えています。
-
テストコードの追加
当たり前ですが現状テストコードがほとんど書けていない状態ですので、順次追加していくつもりです。
最後に
今回初めてちゃんとしたサービスを1から作ってみたのですが(今まではお遊び感覚でしか作ったことがなかった笑)、思いの外楽しかったです。
特にMVPリリースまでの間は常に時間との勝負だったため、緊張感が凄く本当に貴重な経験ができたなぁと感じています。
(この期間は朝起きてから寝るまでほぼアプリの実装や設計について考えていた気がします...まさに〆切駆動。)
また本サービスはプログラミングスクールRUNTEQが主催する「BATTLE OF RUNTEQ」へのエントリーが決まっています。
👑🔥BATTLE OF RUNTEQ Vol.3🔥👑
— らんてくん@RUNTEQプログラミングスクール (@_RUNTEQ_) January 17, 2023
ファイナリストのWebアプリを紹介していくぞ~🎉
今日は稲井 友亮さんの【TechFinder】✨
個人開発に役立つ技術記事を、カテゴリ別に整理したデータベースサービスなんだぞ✨
▽★詳細★▽https://t.co/Do0fOosuEH#RUNTEQ #エンジニア転職 #エンジニア #バトラン pic.twitter.com/rB50hP5gBG
お時間ある方はぜひ当日の2/11(土)に足を運んでいただけると幸いです。
本記事が少しでも皆さんの参考になれば嬉しいです。
最後までご覧いただき本当にありがとうございました🙇♂️
【追記:2023年2月11日】
上記に記載しました「WebアプリバトルイベントBATTLE OF RUNTEQ」にて、本サービスは見事「最優秀賞」を獲得することができました!!
当日足を運んでくださった皆様、Twitterなどで暖かいお言葉をくれた皆様、そして何よりイベントの準備や運営をしてくださったスタッフ並びに審査員の皆様、本当にありがとうございました🙇♂️🙇♂️
審査員の方々から頂いた言葉などを元に、今後もサービスをよりブラッシュアップさせていければと思います。
👑🔥BATTLE OF RUNTEQ Vol.3🔥👑
— らんてくん@RUNTEQプログラミングスクール (@_RUNTEQ_) February 11, 2023
最優秀賞は 稲井 友亮さん【TechFinder】🎉
おめでとうございます!だぞ✨
これからも、素敵なサービスをみんなに届けて欲しいぞ✨#RUNTEQ #バトラン #エンジニア #エンジニア転職 pic.twitter.com/6xrBUrEKTr