はじめに
10月14日、「Oracle AI Data Platform(AIDP)」の一般提供が開始されました。(プレスリリース)
AIDPは、OCI上でデータの収集・管理・分析・AI活用を一元的に行える統合データ基盤です。
データレイク、カタログ、ノートブック、アクセス制御などを備え、組織全体のデータを統合的に扱うことができます。
Oracle AI Database や Oracle Generative AI Service と連携することで、
AIによる高度な検索・分析・生成を実現するAIデータ基盤として機能します。
今回は、Autonomous Database(ADB) のデータを外部ソースとしてAIDPに外部カタログを作成し、AIDP上のデータと結合してSQL/Pythonで参照する手順を試してみます。
(例として、ADBに注文明細テーブル、AIDPに商品マスタを配置し、それらを結合して注文内容を確認します。)
参考
- Qiita:Oracle AI Data Platform(AIDP) がリリースされたので作成してみてみた
- ドキュメント:Get Started with Oracle AI Data Platform
手順
以下のような手順で進めます。
| 手順 | 内容 | 目的 |
|---|---|---|
| 0 | 事前準備 | ADW(ADB)を準備し、連携先のテーブルを用意 |
| 1 | AIDPの構築 | OCI上でAIDPインスタンスを作成 |
| 2 | カタログを作成 | データを格納する論理コンテナを設定 ・Master catalog ・標準カタログ ・外部カタログ |
| 3 | クラスタを作成 | Spark処理用のCompute環境を用意 |
| 4 | ノートブックを作成 | 分析用のインタラクティブ環境を作成 |
| 5 | SQLで試す | AIDPとADBのデータを結合して参照 |
| 6 | Pythonで試す | PySparkを使って同様の処理を実装 |
0. 事前準備
今回はAutonomous Database (ADW)のデータを連携先として利用するので、事前に作成しておきます。
以下のチュートリアルをご参考にしてください。
https://oracle-japan.github.io/ocitutorials/adb/adb101-provisioning/
今回は、ADBに「orders_items」表を入れておきます。(この後、AIDP内に「product」表を作成し、データを結合して参照してみます。)
※テストデータは、APEXのサンプルデータセット「顧客オーダー」の2つの表を利用しました。
1. AIDPの構築
ハンバーガーメニューから、「アナリティクスとAI」>「AIデータ・プラットフォーム」をクリックします。
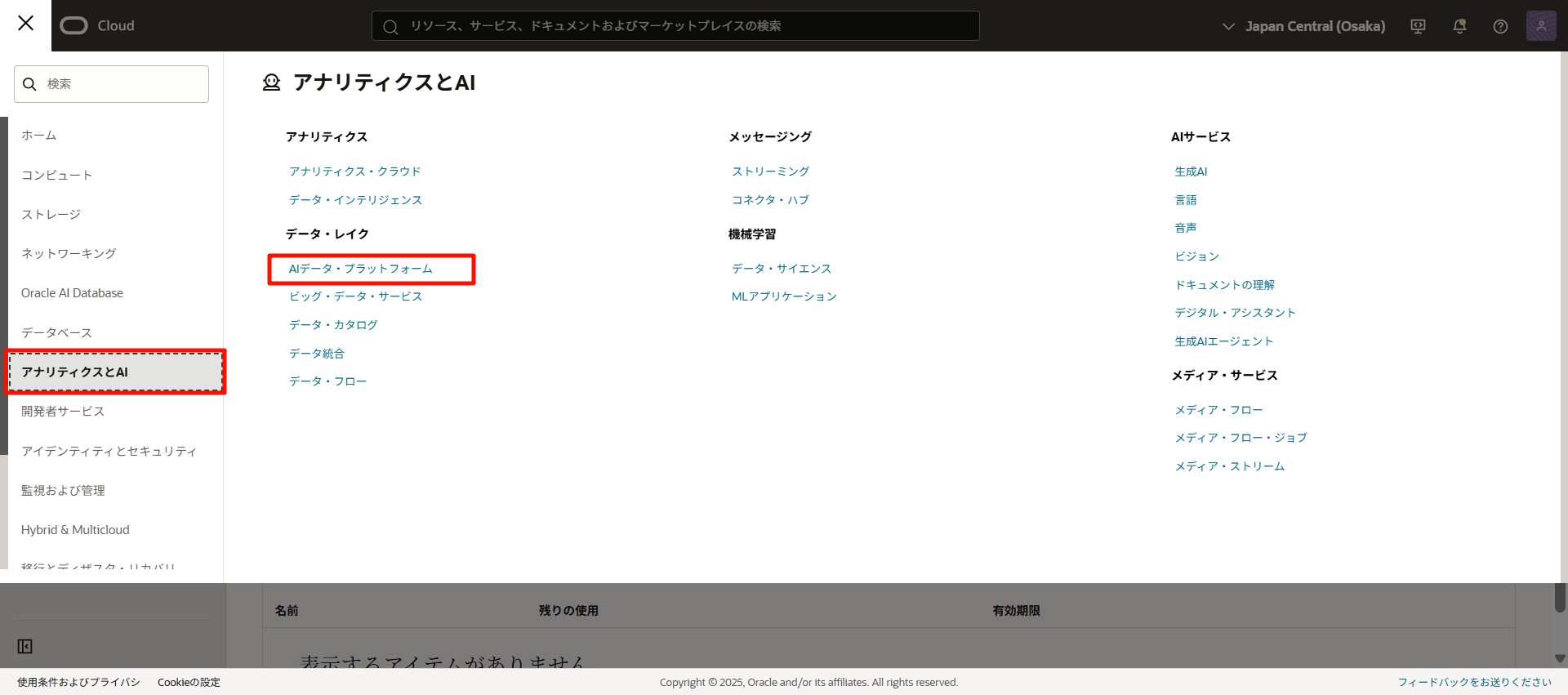
「Create AI Data Platform」をクリックします。
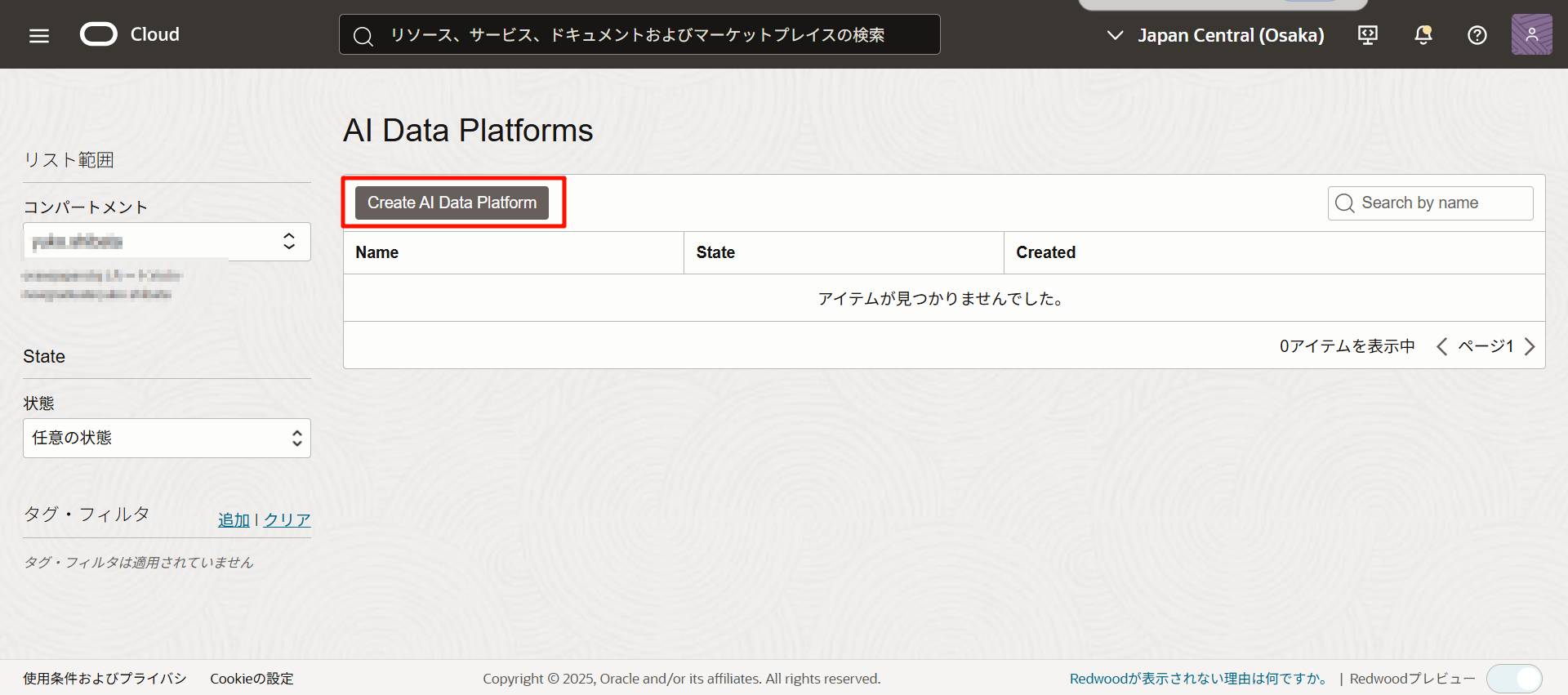
クリックすると、必要なすべてのIAMポリシーが設定されているかチェックが行われます。
(infoマークが出て、チェックが終わると作成画面に遷移します。)
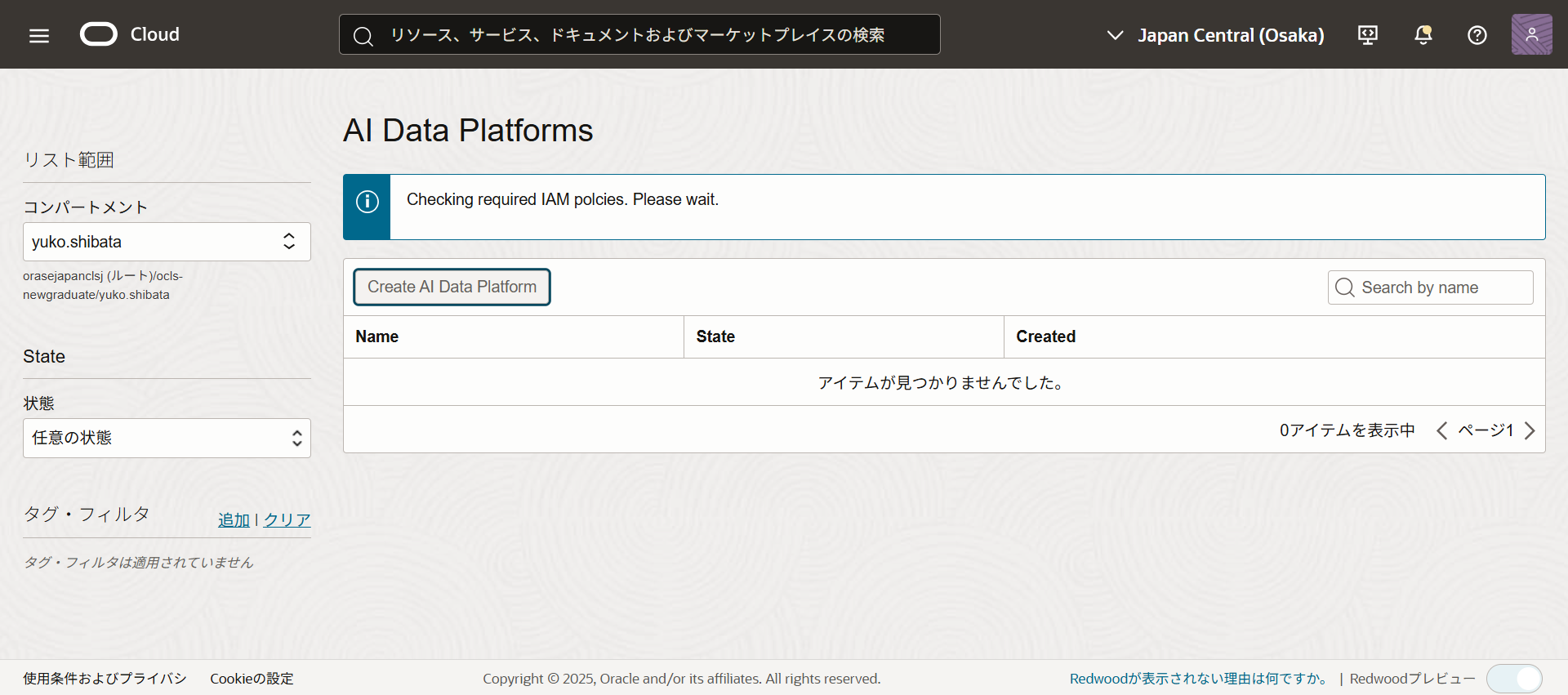
以下を入力します。
- AIDPインスタンスの名前と説明
- AIDPワークスペースの名前と説明
「ポリシーの追加」から以下のいずれかを選択します。
- Standard:テナント レベルでアクセス設定を広範囲に適用します。
- Advance:コンパートメント レベルできめ細かなアクセスを構成できます。
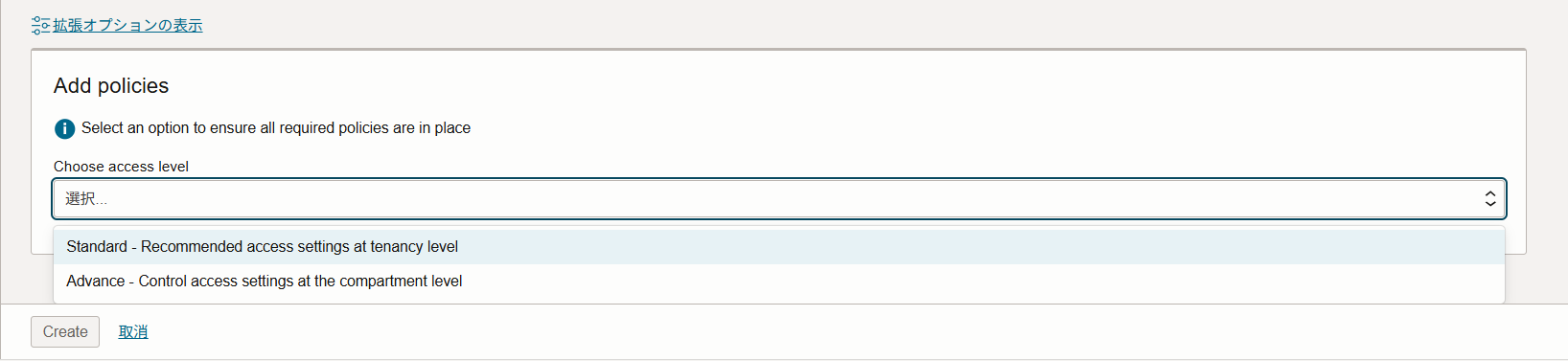
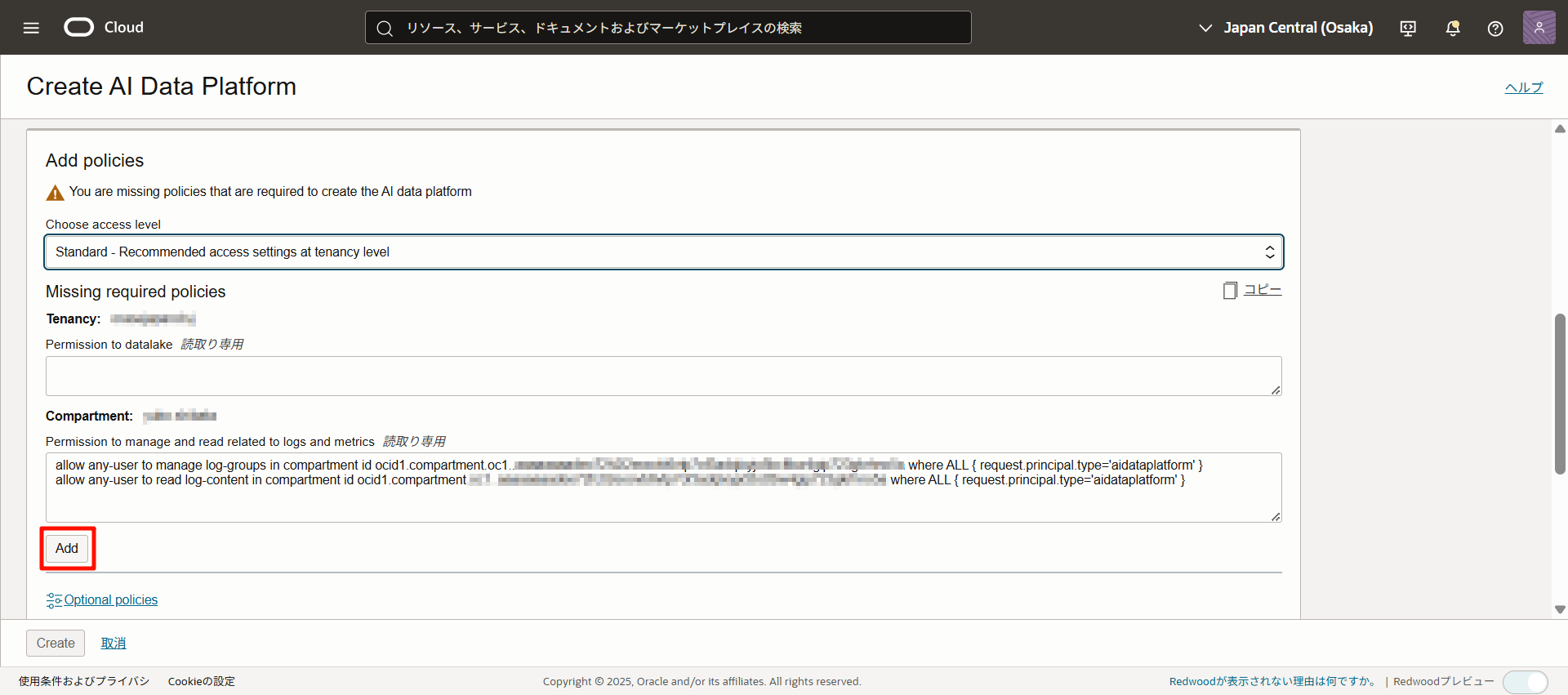
選択すると、不足しているポリシーがある場合はポリシーが表示されます。
内容を確認して、「Add」をクリックします。無事追加されると「Policies added」と表示されます。
「Optional policies」をクリックすると、任意で追加するポリシーが表示されるので必要に応じて追加します。
詳細はこちらを確認します:IAM Policies for Oracle AI Data Platform
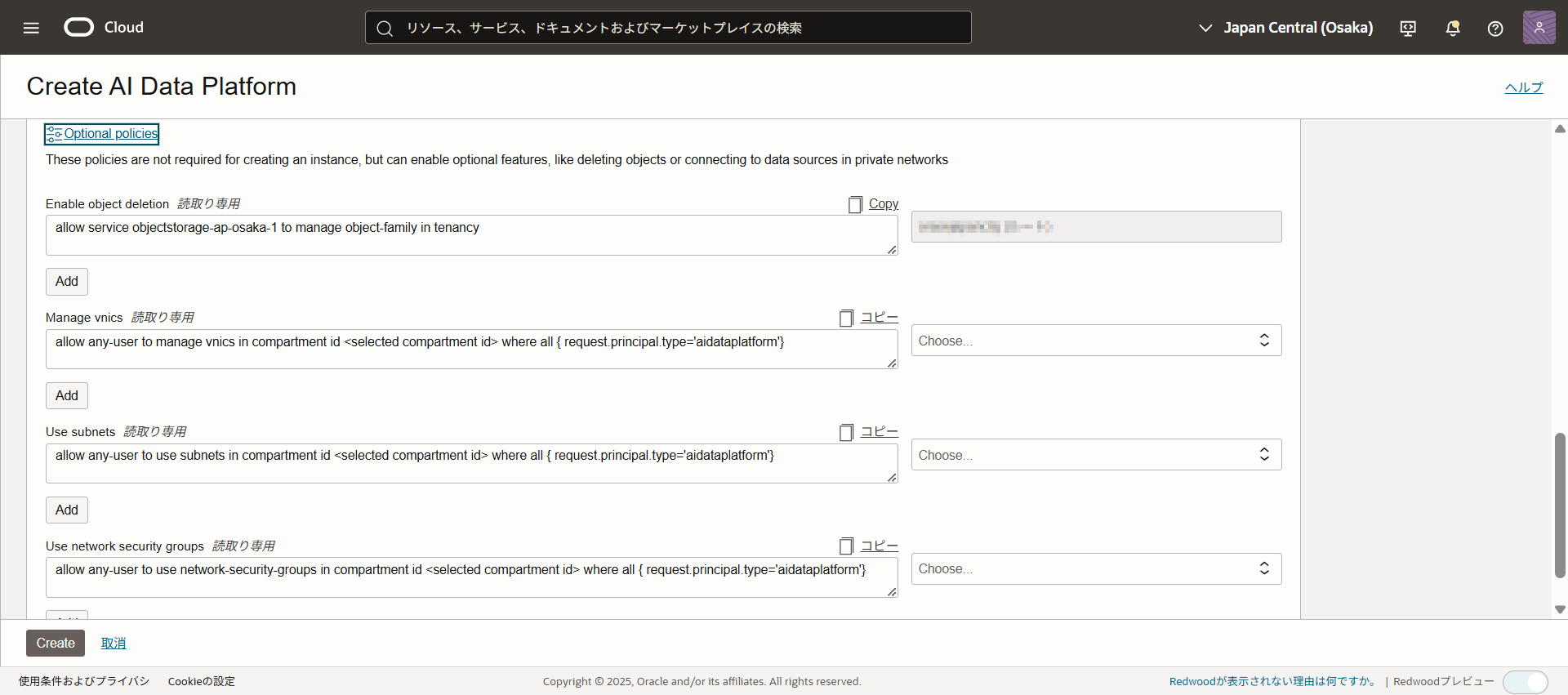
ポリシーが確認できたら「Create」をクリックします。
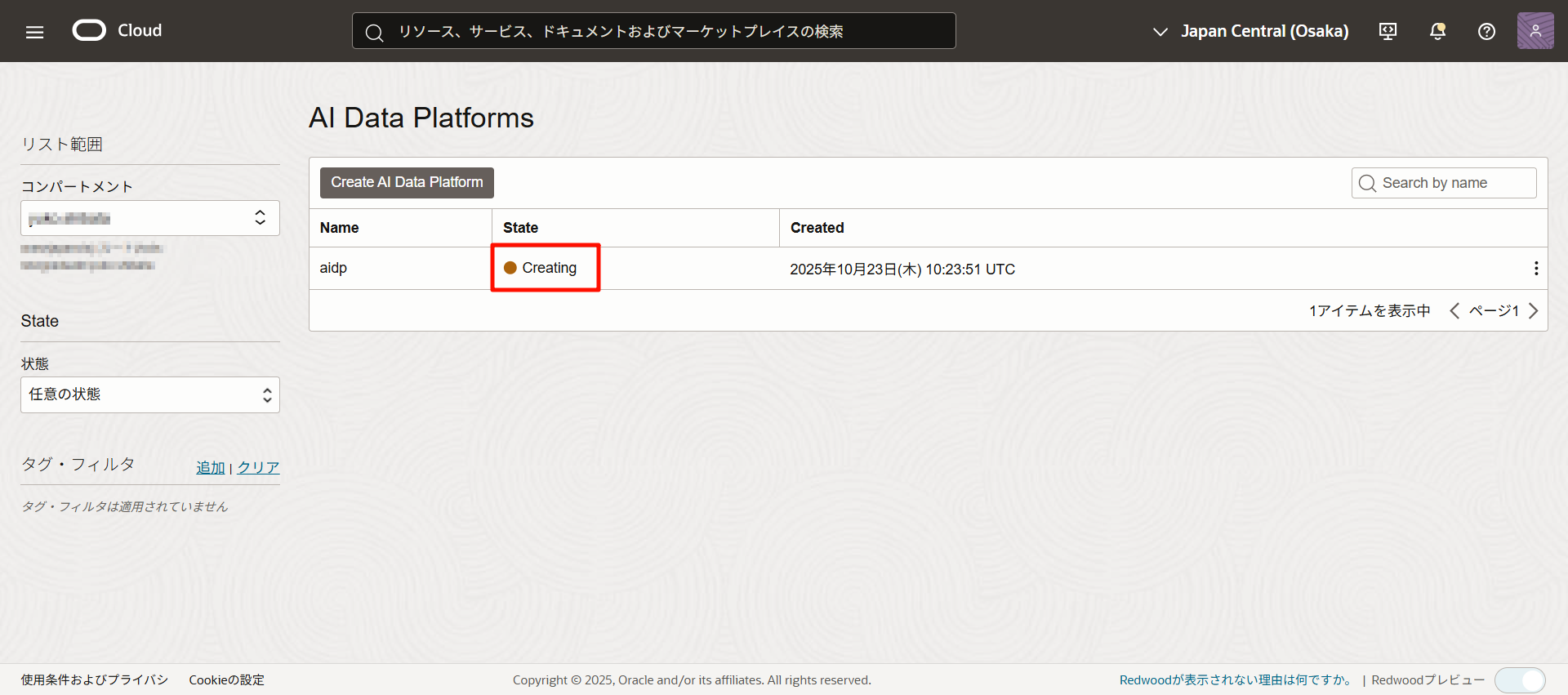
約10分程度で作成が完了しました。
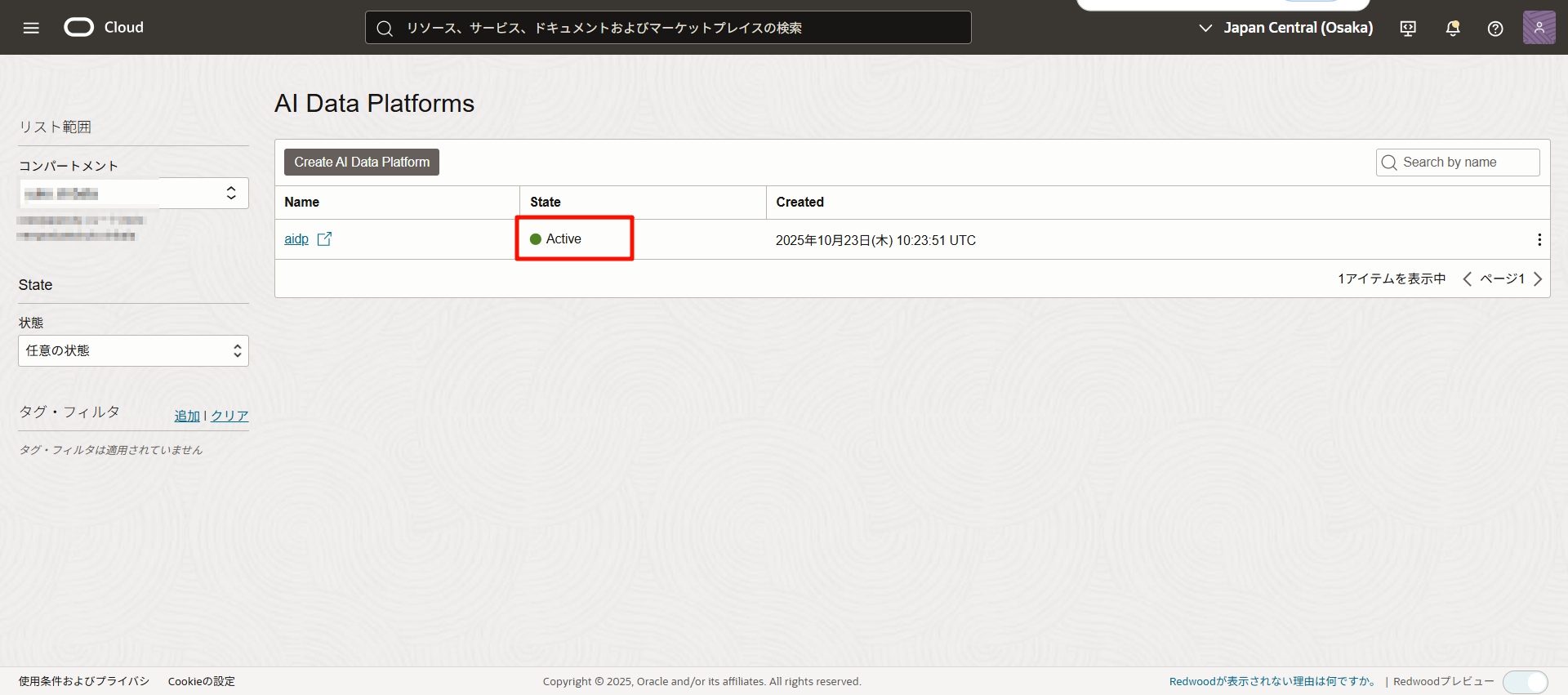
AIDPのコンソールにアクセスする
アクセスするインスタンス名をクリックします。
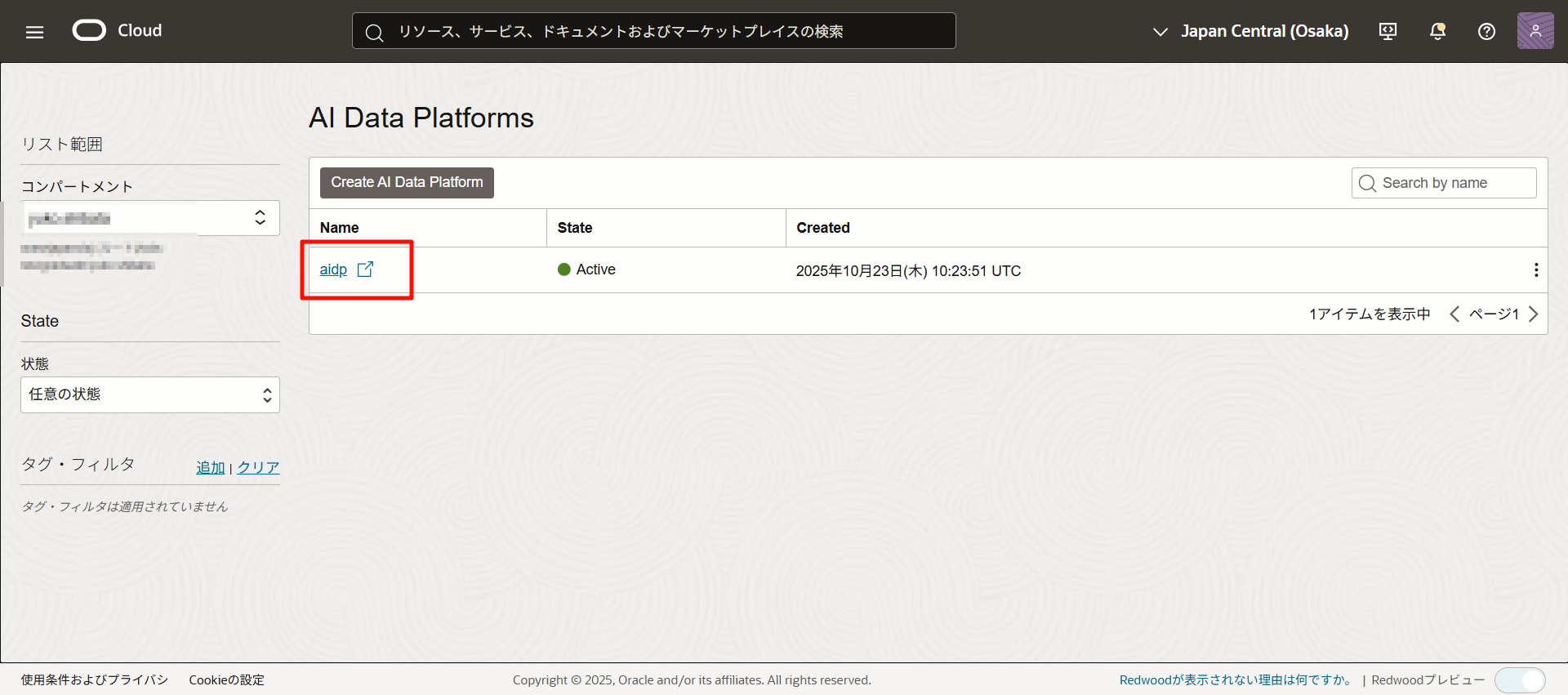
アクセスできました!
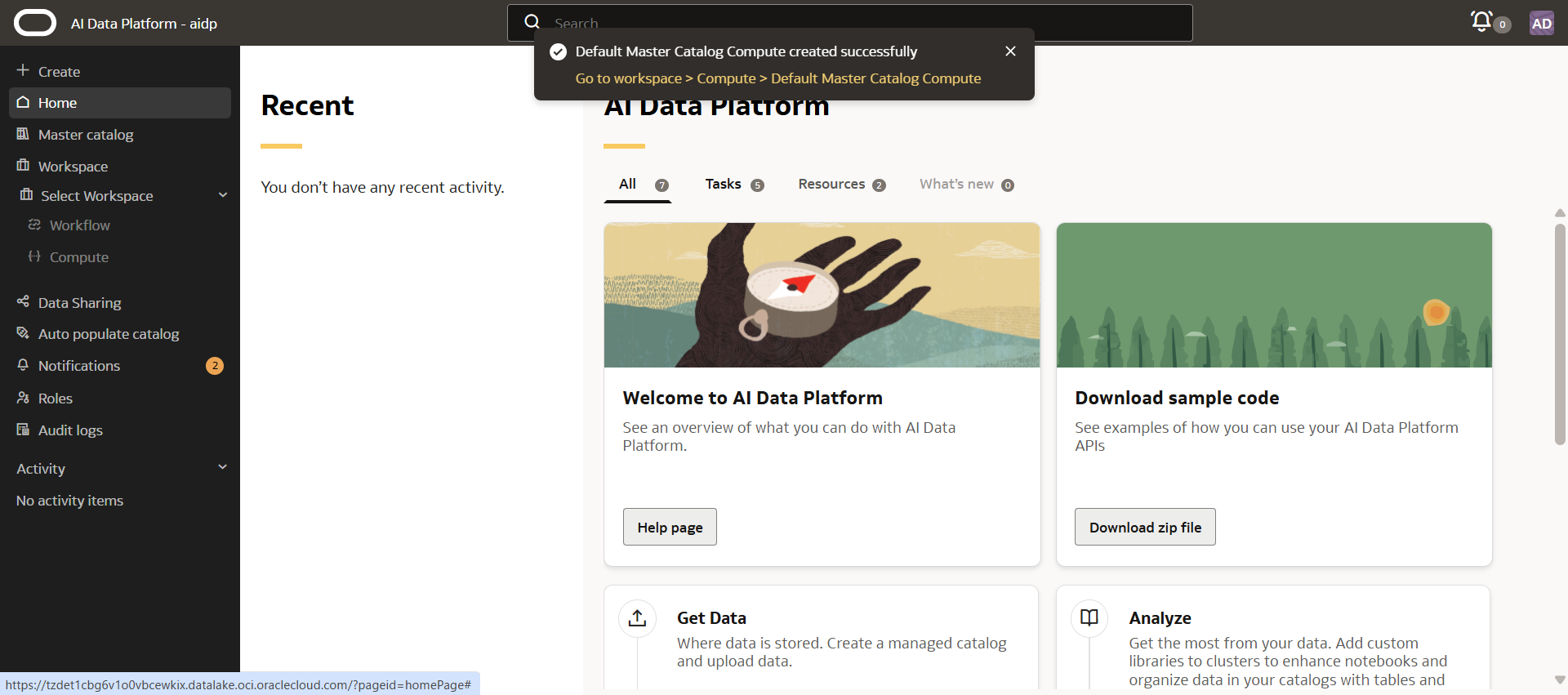
URLからアクセスする場合、URLの形式は以下のとおりです。
https://<hash>.datalake.oci.oraclecloud.com/#?&tenant=<<tenant_name>>&domain=<<domain_name>>
AI Data Platform インスタンスの URL を他のユーザーと共有できます。
アクセスするには、AIデータ・プラットフォームIAMポリシーのUSE権限以上が必要です。
2. カタログを作成する
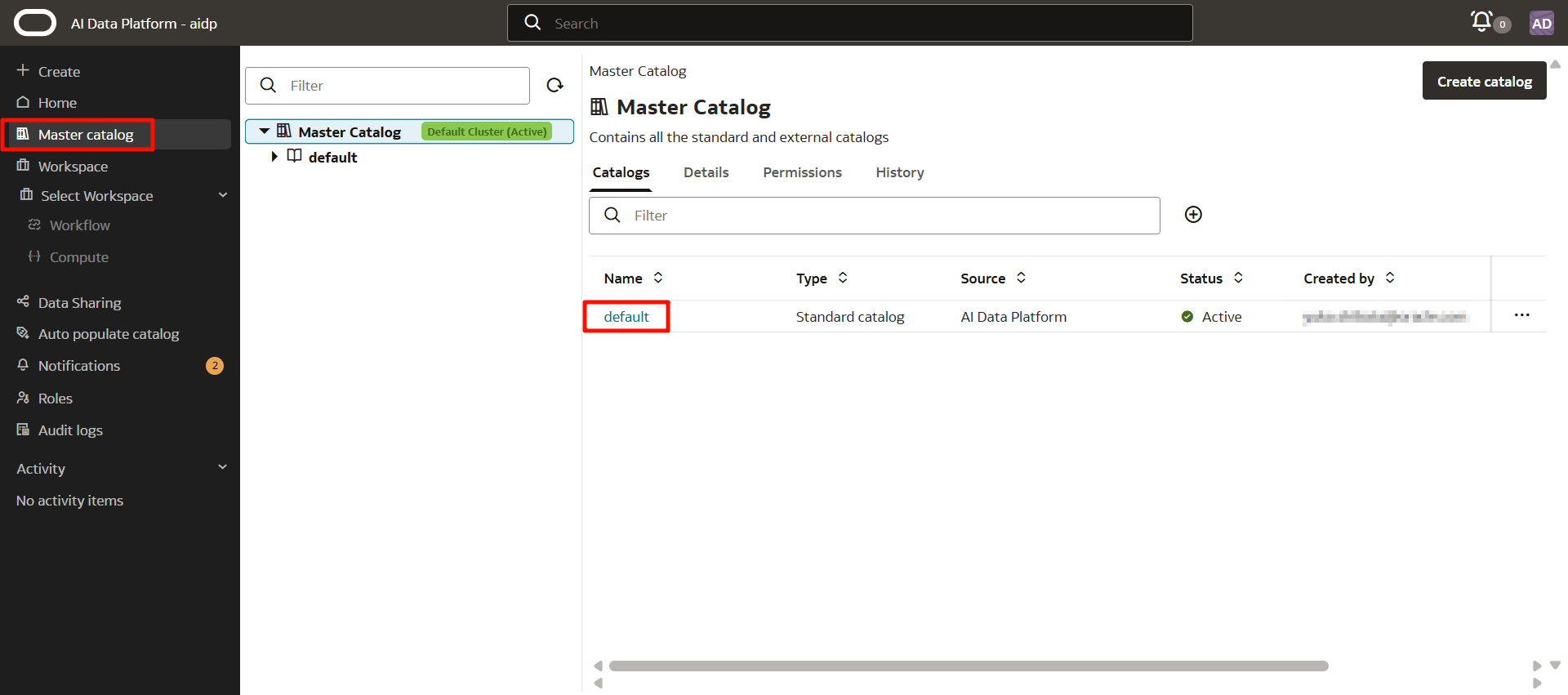
2-1. マスターカタログ
マスターカタログ(Master Catalog) は、データとメタデータを一元的に管理するための最上位のエンティティです。この後作成する標準カタログ(Standard Catalog) と 外部カタログ(External Catalog) の両方を格納するコンテナの役割を持ちます。
OCI Object Storage、Autonomous Data Warehouse(ADW)、Kafka などにあるデータを対象としてカタログを作成できます。
-
標準カタログ(Standard catalog):AIDP内のスキーマ(データベース)のための論理的なコンテナです。スキーマ内にテーブル、ビュー、ボリュームを作成できます。標準カタログは、すべての子オブジェクト(テーブルやビューなど)のメタデータのライフサイクル(作成・更新・削除など)を管理します。
-
外部カタログ(External catalog):Autonomous Data Warehouse や Kafka などの外部データソースを基盤とするカタログのことです。外部カタログの場合、メタデータは外部ソースから同期され、
catalog_name.schema_name.table_nameのような形式で外部ソース上のデータを問い合わせることができます。外部カタログのメタデータのライフサイクル(作成・更新・削除など)は外部ソース側で管理されており、マスターカタログ(Master Catalog) はそのメタデータのコピーを保持します。
デフォルトで「default」というマスターカタログが用意されています。
2-2. 標準カタログの作成
AIDP内のデータに対する標準カタログを作成します。
「Create Catalog」をクリックします。
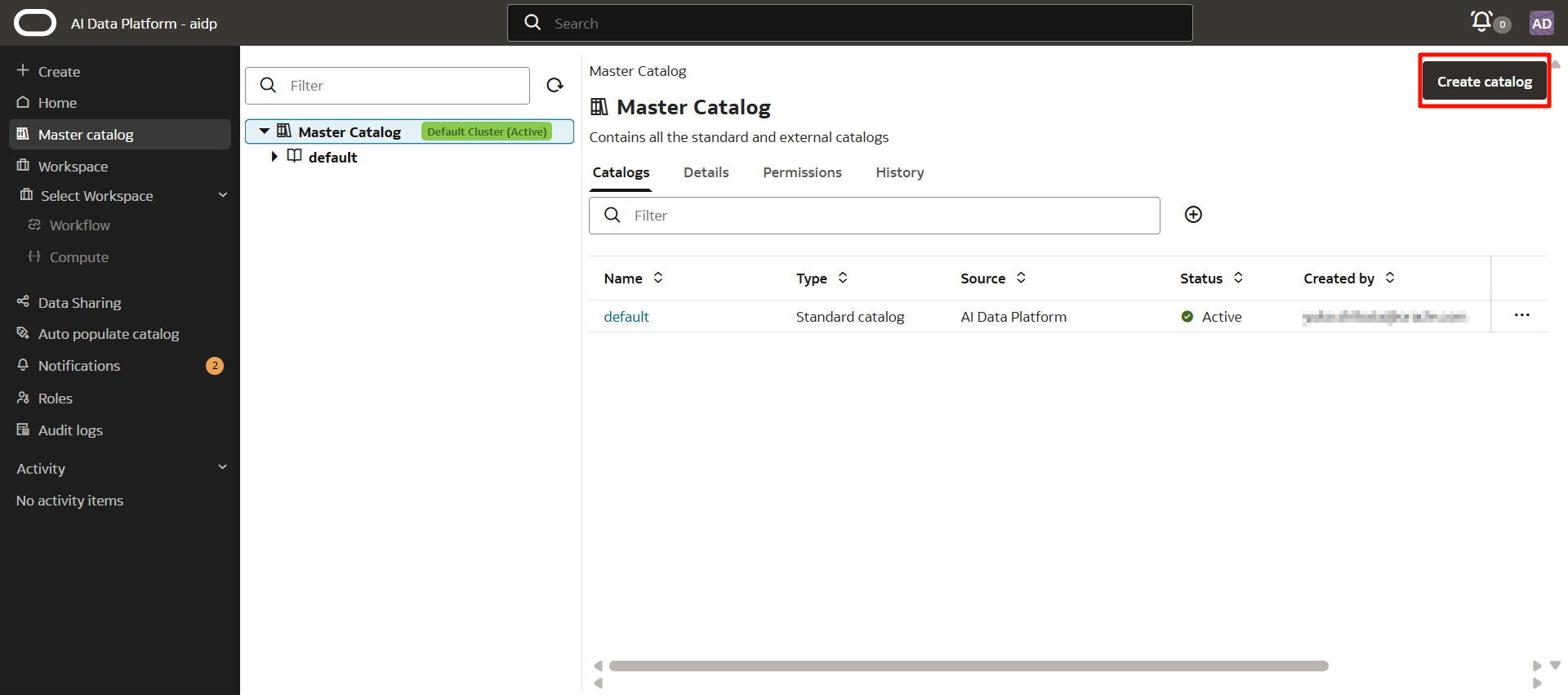
次のとおり入力します。「Create」を押します。
- Catalog name:任意(ここではstandard_catalog)
- Catalog type:Standard Catalog
- Compartment:任意
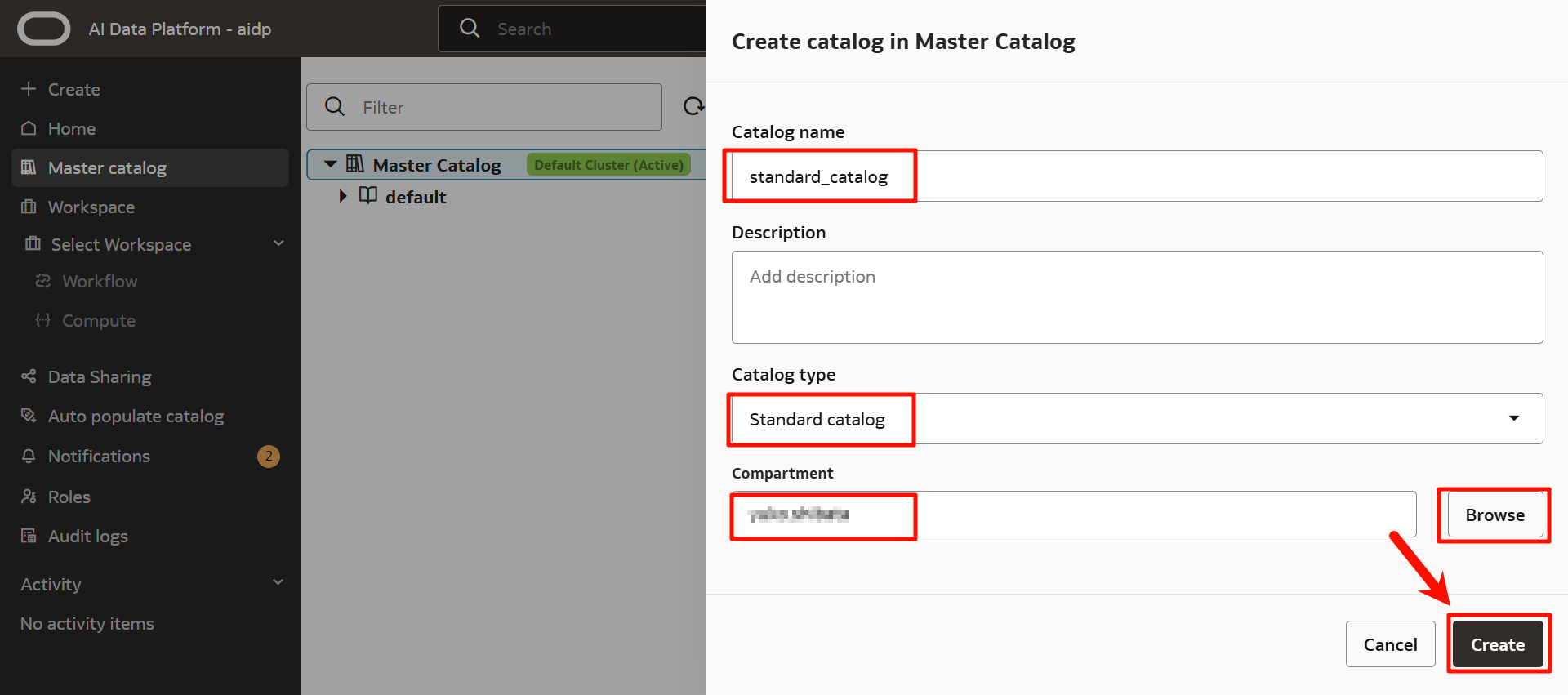
作成した標準カタログをクリックします。
「Create schema」をクリックして、スキーマを作成します。
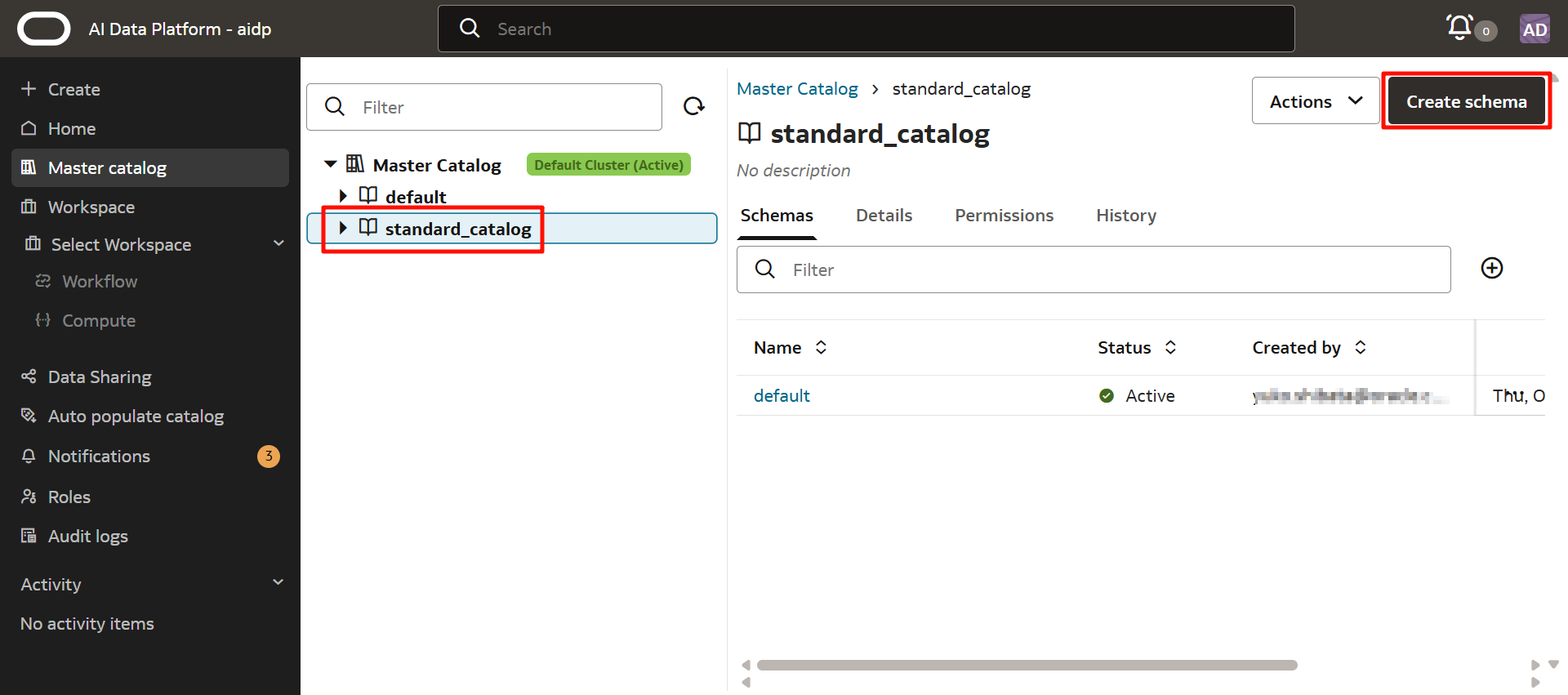
以下のとおり入力します。「Create」をクリックします。
- Schema Name:任意(ここではproduction)
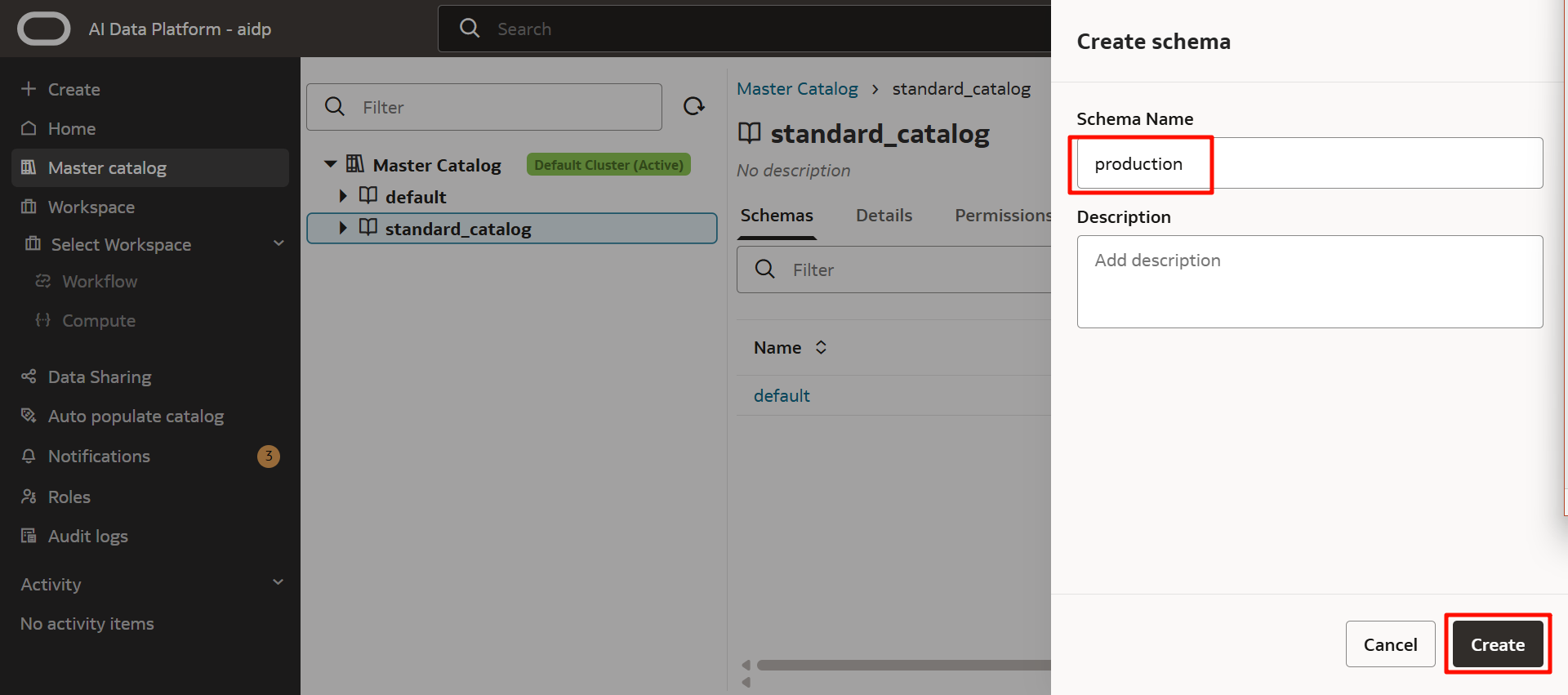
スキーマが出来ました。スキーマ名をクリックします。
「Create table」をクリックして、表を作成します。
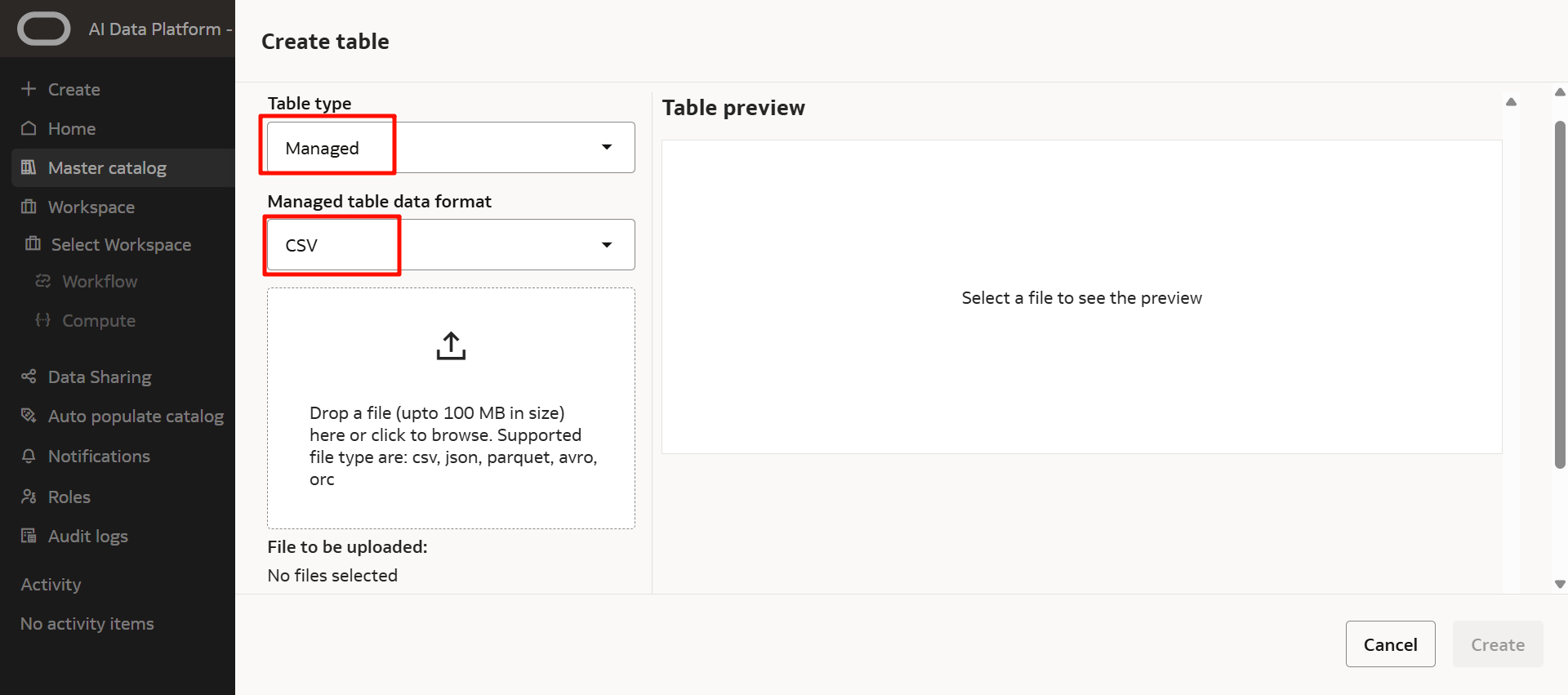
次のとおり入力します。
- Table type *¹:Managed
- Managed table data format *²:任意(ここではCSV)
*¹ 表タイプ(Table type) は、Managed もしくはExternalから選択します。
-
管理テーブル(Managed Tables)
管理テーブルは、AI Data Platform 内に保存されるデータの構造を定義するもので、AI Data Platform のユーザーのみがアクセスできます。管理テーブルを削除すると、テーブル定義だけでなく、そのテーブルに格納されているデータも削除されます。 -
外部テーブル(External Tables)
外部テーブルは、Oracle AI Data Platform によって管理されていない場所に保存されているデータに対して構造を定義するものです。
AI Data Platform 上で外部テーブルを作成すると、そのメタデータのライフサイクル(作成・更新・削除)は AI Data Platform によって管理されます。
外部テーブルを削除しても、削除されるのはテーブル定義のみであり、参照している実データ自体は削除されません。
*² 管理テーブル(Managed Tables)でサポートされている形式は以下のとおりです。
- CSV
- JSON
- Avro
- Parquet
- ORC
- Delta
AIDP内に保管するデータをアップロードします。
「Preview tables」をクリックして、アップロードするデータを確認することができます。
テーブル名を確認して、「Create」をクリックします。
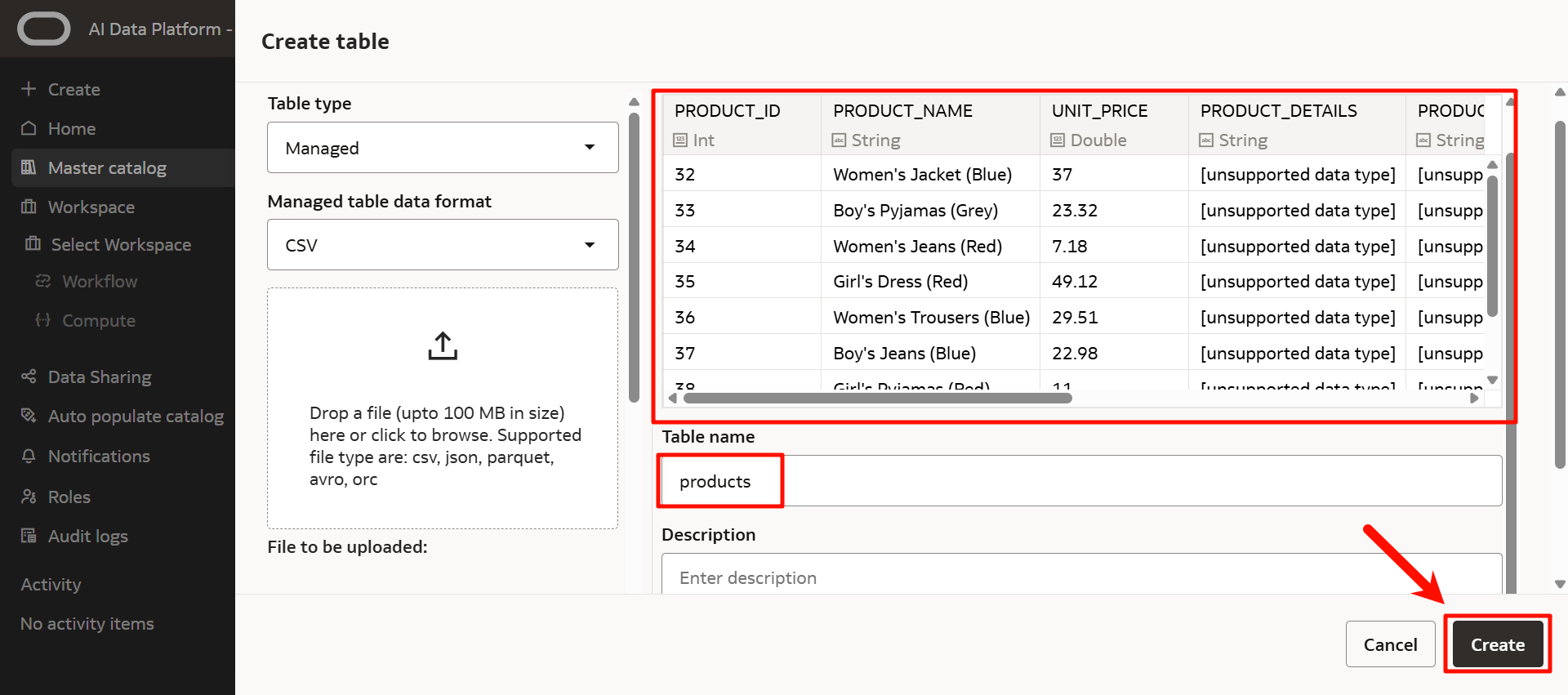
テーブルが作成できました。
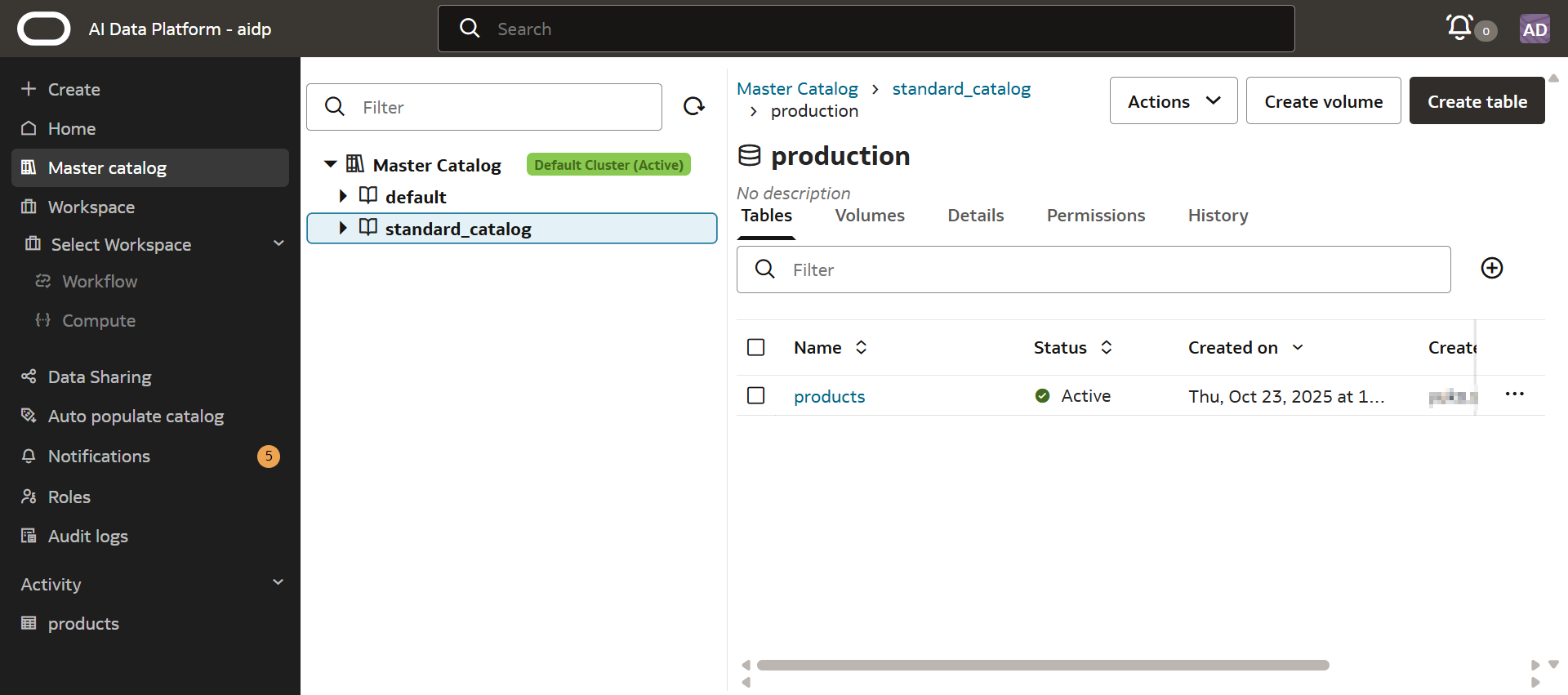
管理テーブルのデータをObject Storageにて確認する
AIDPを作成すると、インスタンスを作成した同じコンパートメントと同じコンパートメントにいくつかのバケットが作成されます。
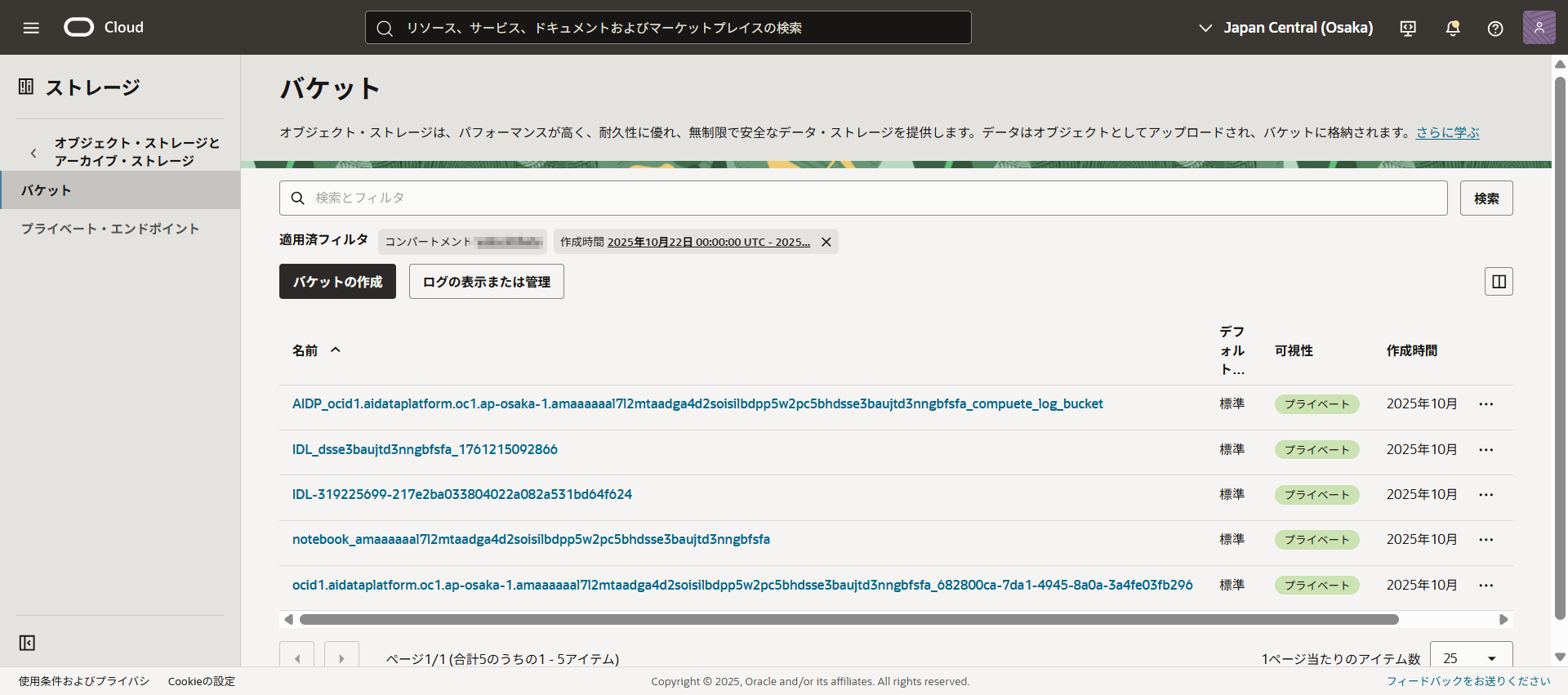
管理テーブルとしてアップロードしたデータはこちらに保存されていました。
2-3. 外部カタログの作成
続いて、Autonomous Database (ADW)を対象に外部カタログを作成します。
「Create catalog」をクリックします。
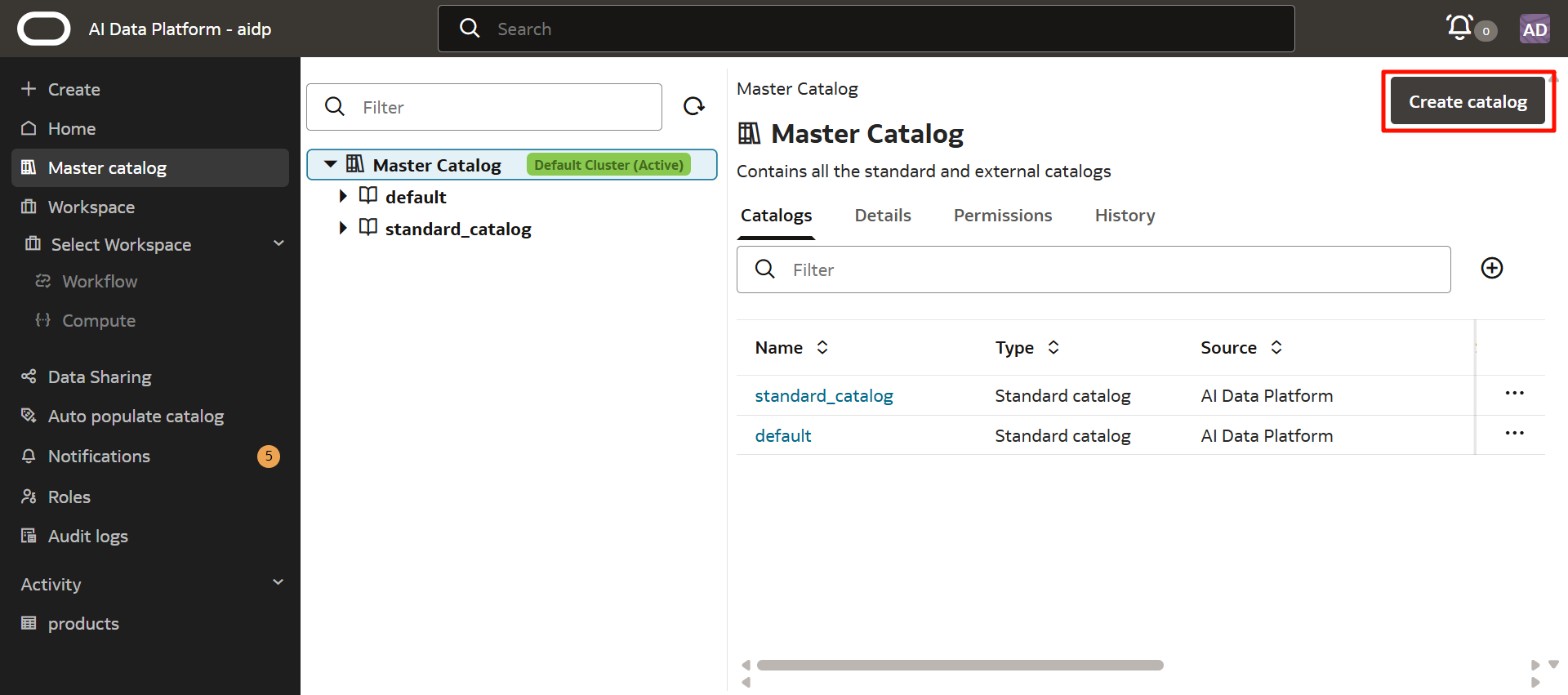
以下のとおり入力します。
- Catalog name:任意(ここではadw_catalog)
- Catalog type:External catalog
- External source type:Oracle Autonomous Data Warehouse
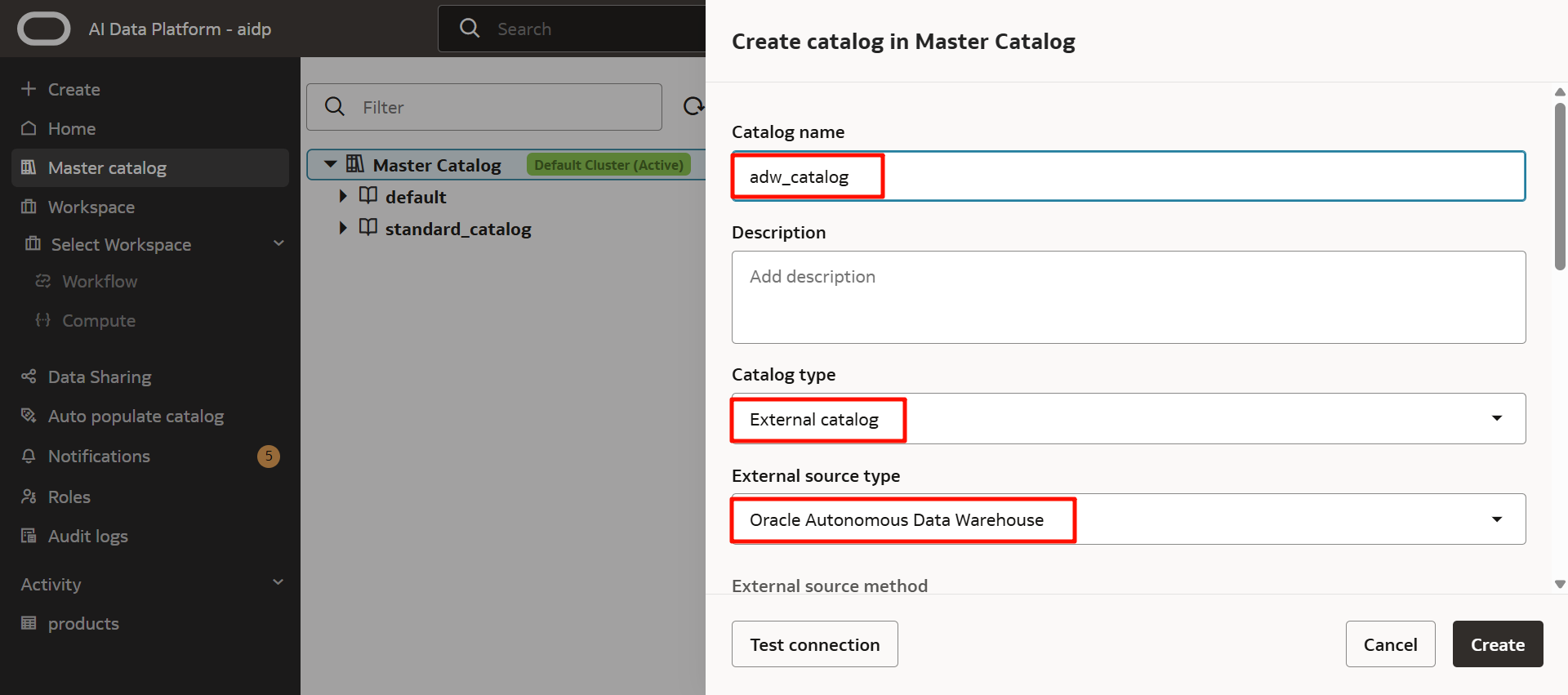
外部ソースは、Autonomous Data Warehouse、Autonomous Transaction Processing、Oracle Databaseから選択できます。
(Kafkaは近日リリース予定:2025年10月末時点)
Oracle Databaseの3つのいずれかを選択した場合は、ウォレットファイルもしくはインスタンスの選択から設定可能です。
事前準備で用意した対象のADWを選択します。
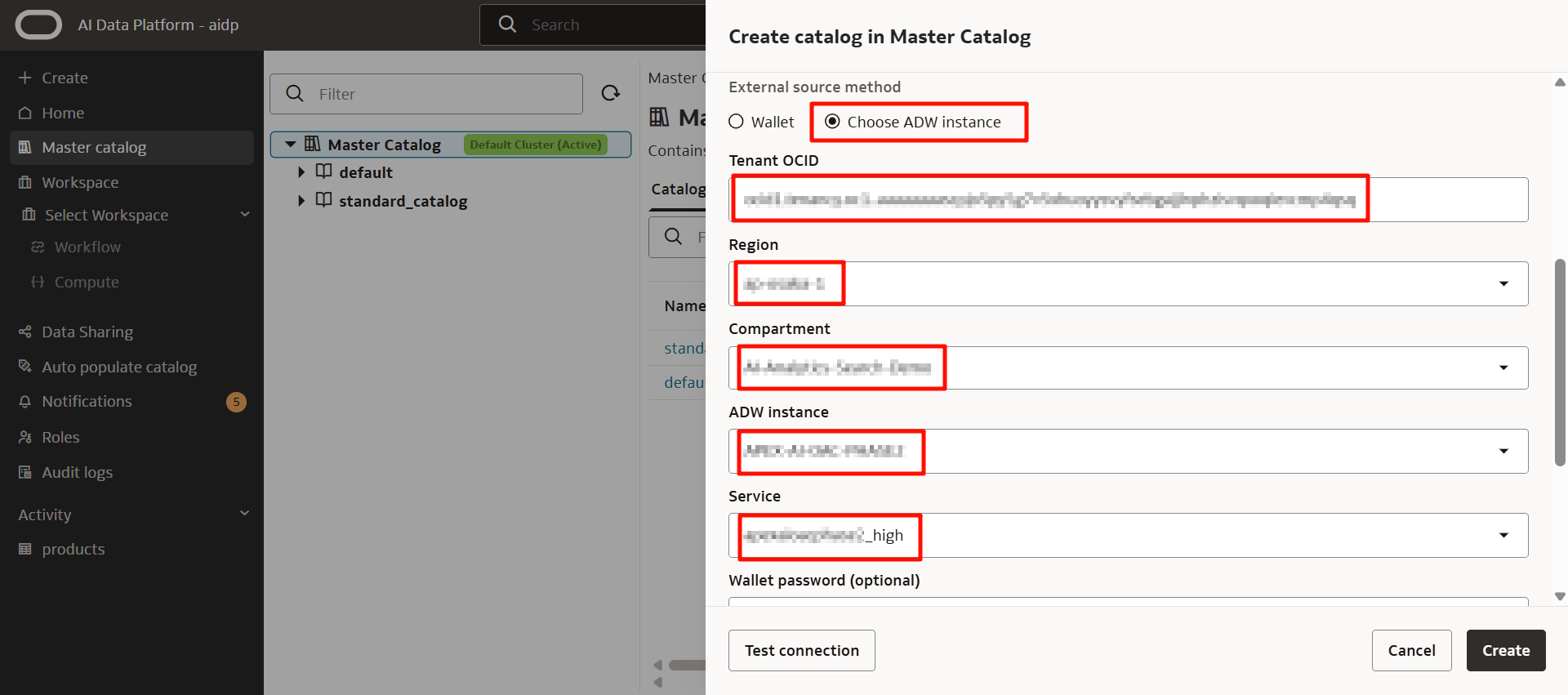
ユーザー名とパスワードを入力したら、「Create」をクリックします。
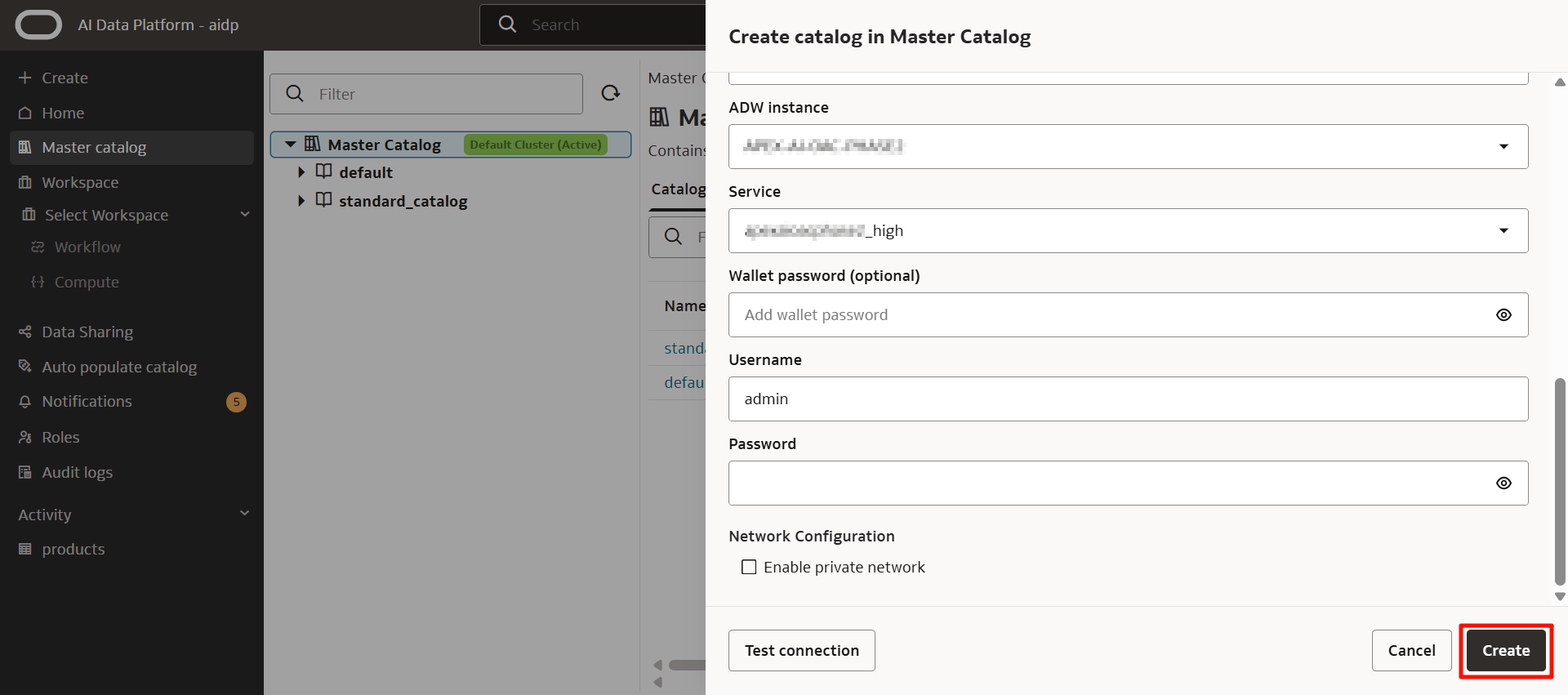
数秒経つと、この画面に戻り、Creatingと表示されます。
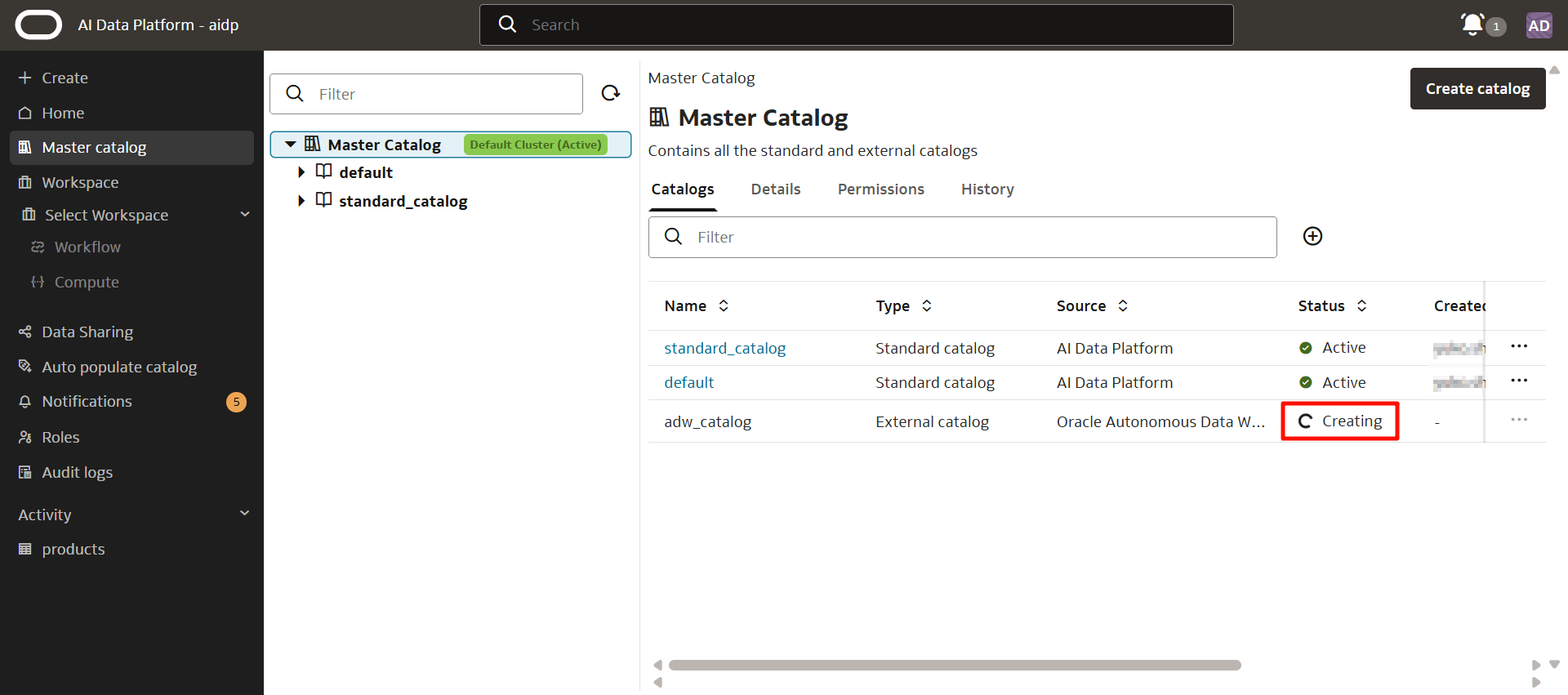
十数秒待つと、正常に作成されたとポップアップが表示され、ステータスが「Active」になりました。
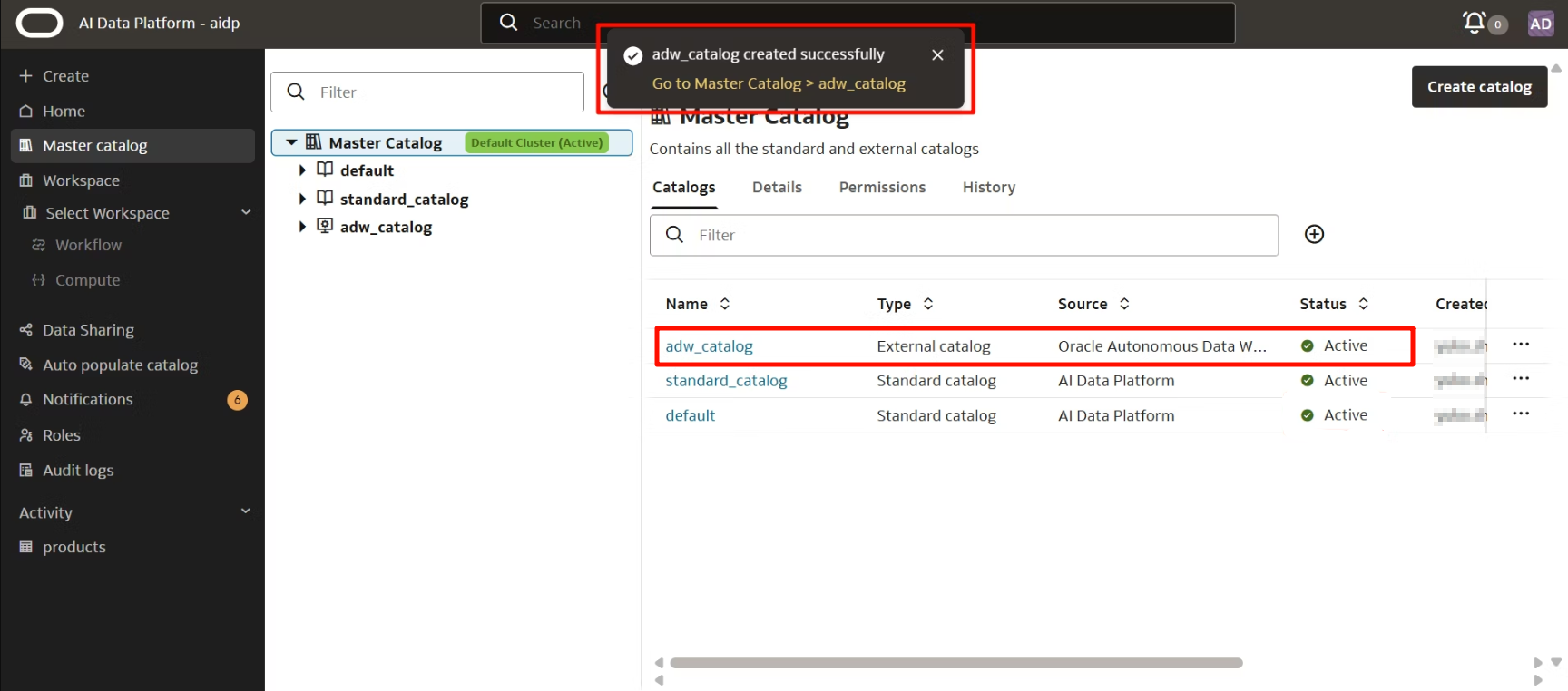
カタログの準備が完了しました。
3. クラスタを作成する
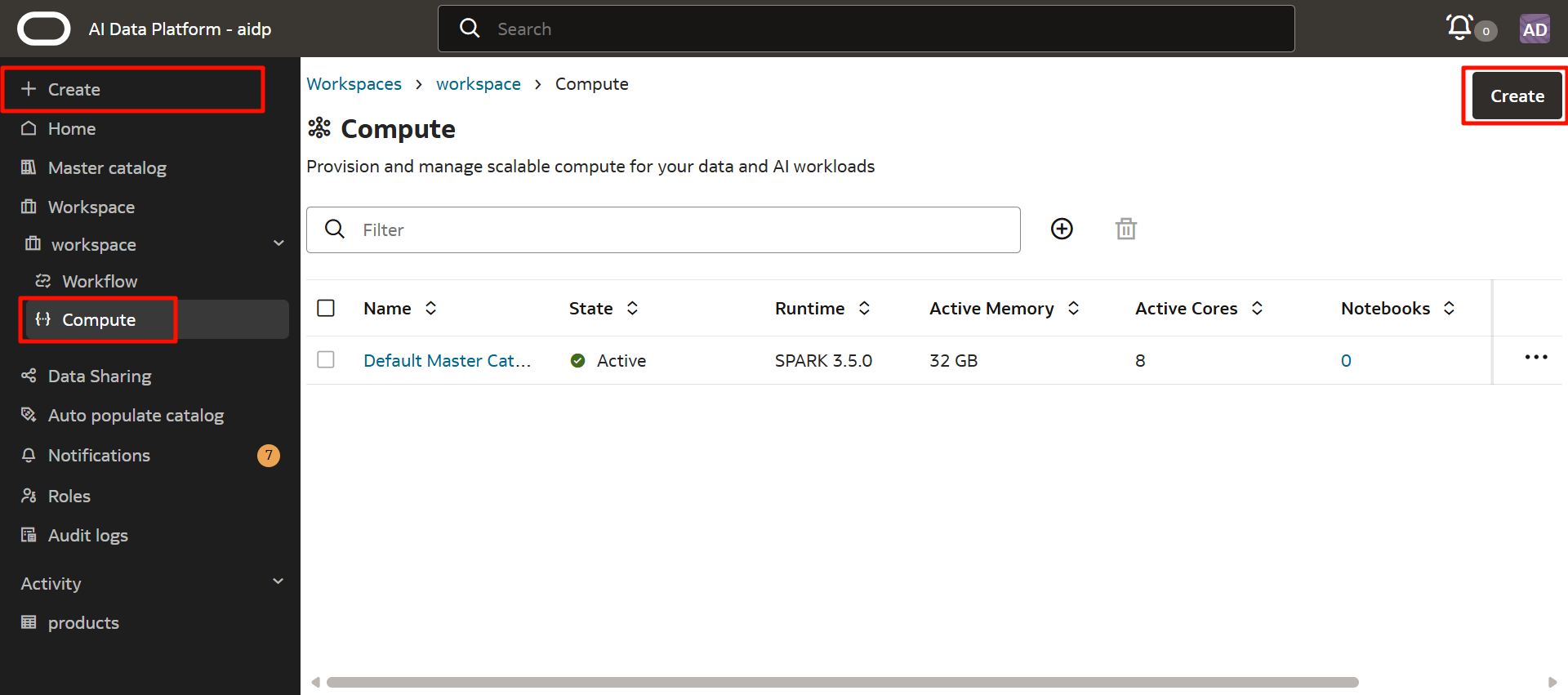
左メニューの「Workspace」から作成したワークスペース名をクリックします。
「Compute」をクリックして、「Create」からコンピュート・クラスタを作成します。
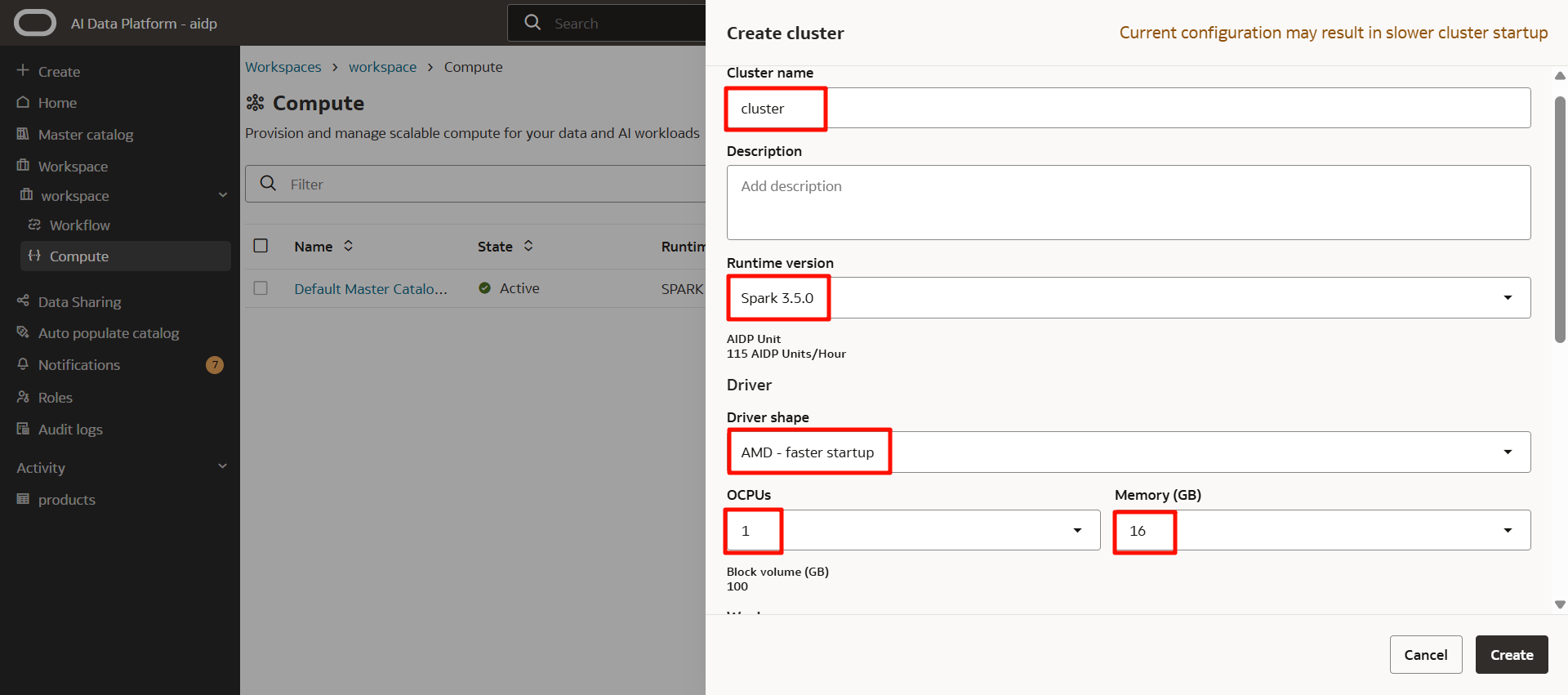
以下のとおり入力します。
- Cluster name:任意(ここでは
cluster) - Runtime version:
Spark 3.5.0(2025年10月末時点このバージョンのみ選択可) - Driver shape *³:AMD
- OCPUs:
1(最小) - Memory(GB):
16(最小)
*³ AMD、INTEL、NVIDIA GPU、ARMから選択可です。
続いて以下を入力します。
- Worker shape *³:AMD
- OCPUs:
1(最小) - Memory(GB):
16(最小) - Set number of workers:
Static amount(固定値)orAutoscale(自動スケール) - (
Autoscaleの場合)クラスターをスケールできるワーカーの最小数・最大数 - Run duration:
Forever(一定時間操作が行われなかった場合にクラスターの実行を停止する場合は、アイドル時間を分単位で入力します。)
「Create」をクリックします。
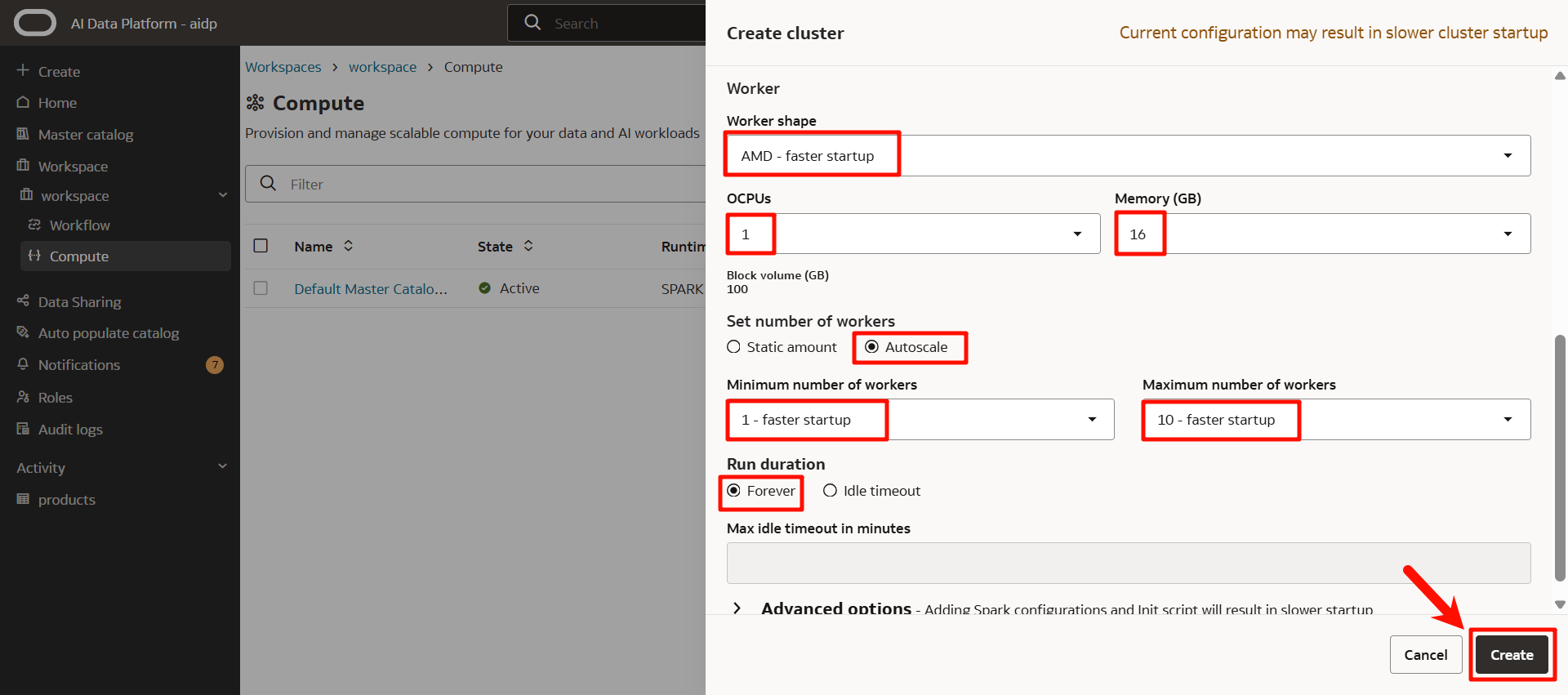
ステータスが「Accepted」>「Creating」になります。
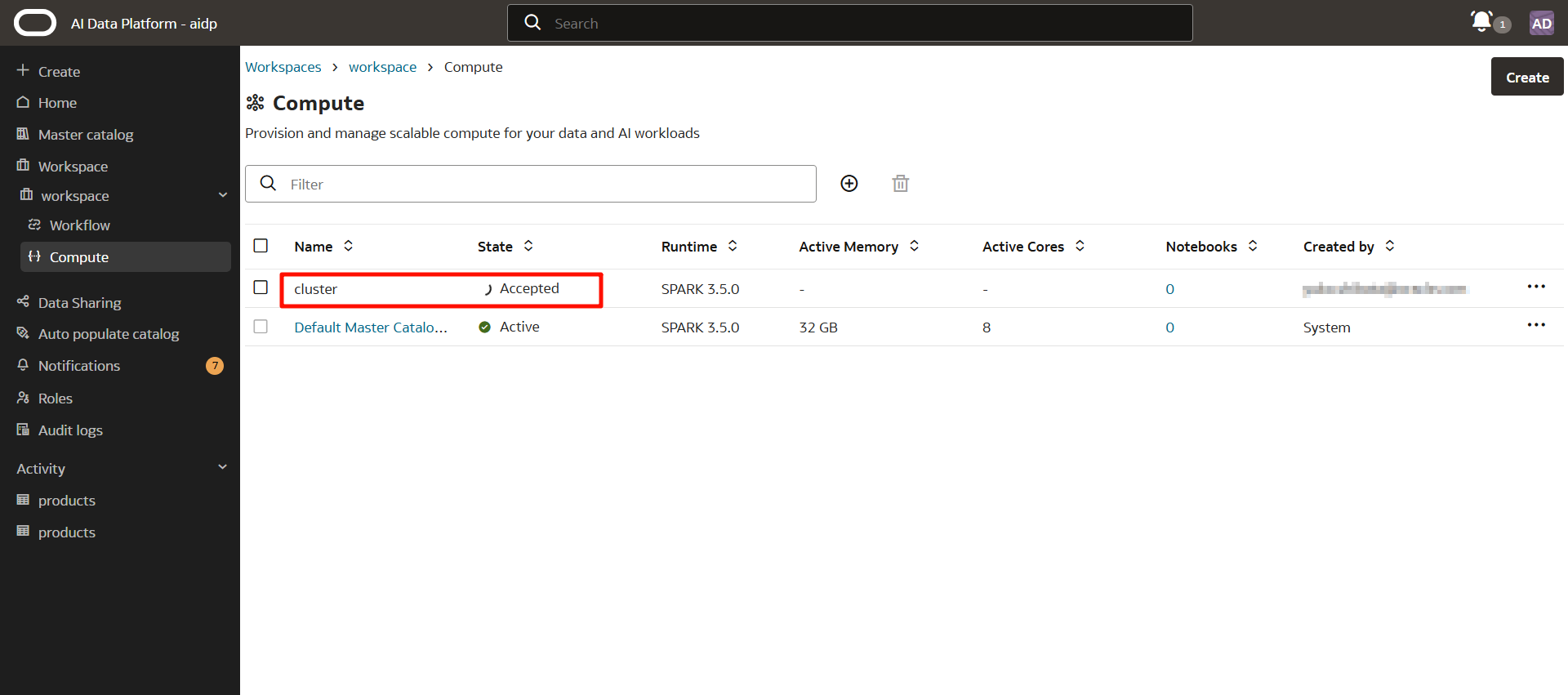
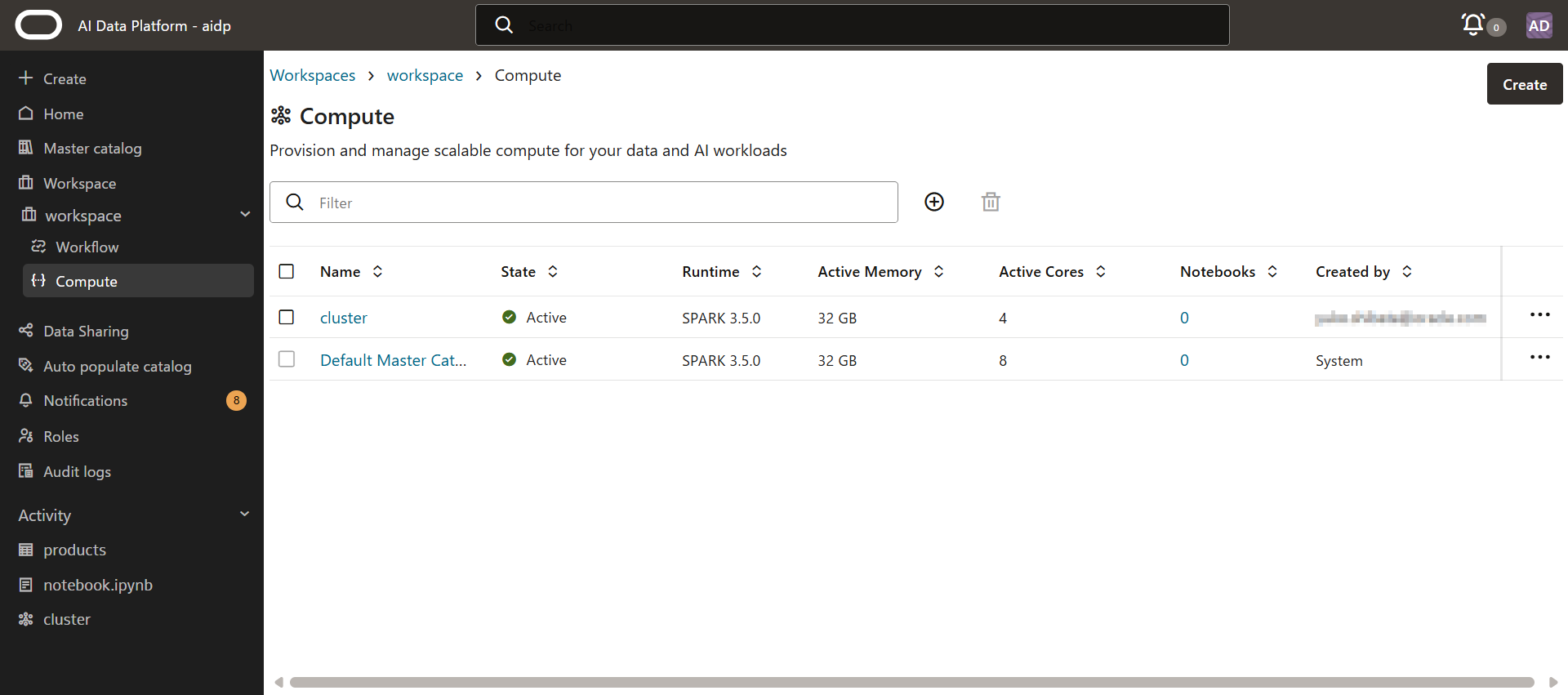
10-20分後、クラスタが「Active」になり作成が完了しました。
4. ノートブックを作成する
AIDPでは、直感的に操作できるマネージドのノートブック環境が用意されています。
ノードブックを作成し、AIDP内のデータを検証したり、コードの開発をインタラクティブに行う基盤として利用できます。
現在(2025年10月末時点)AIDPのノートブックでは、PythonとSQLがサポートされています。
また、.ipynb ファイル(Jupyter Notebook 形式)をワークスペースにインポートすることが可能です。(現在、ノートブックのエクスポート機能はサポートされていません。)
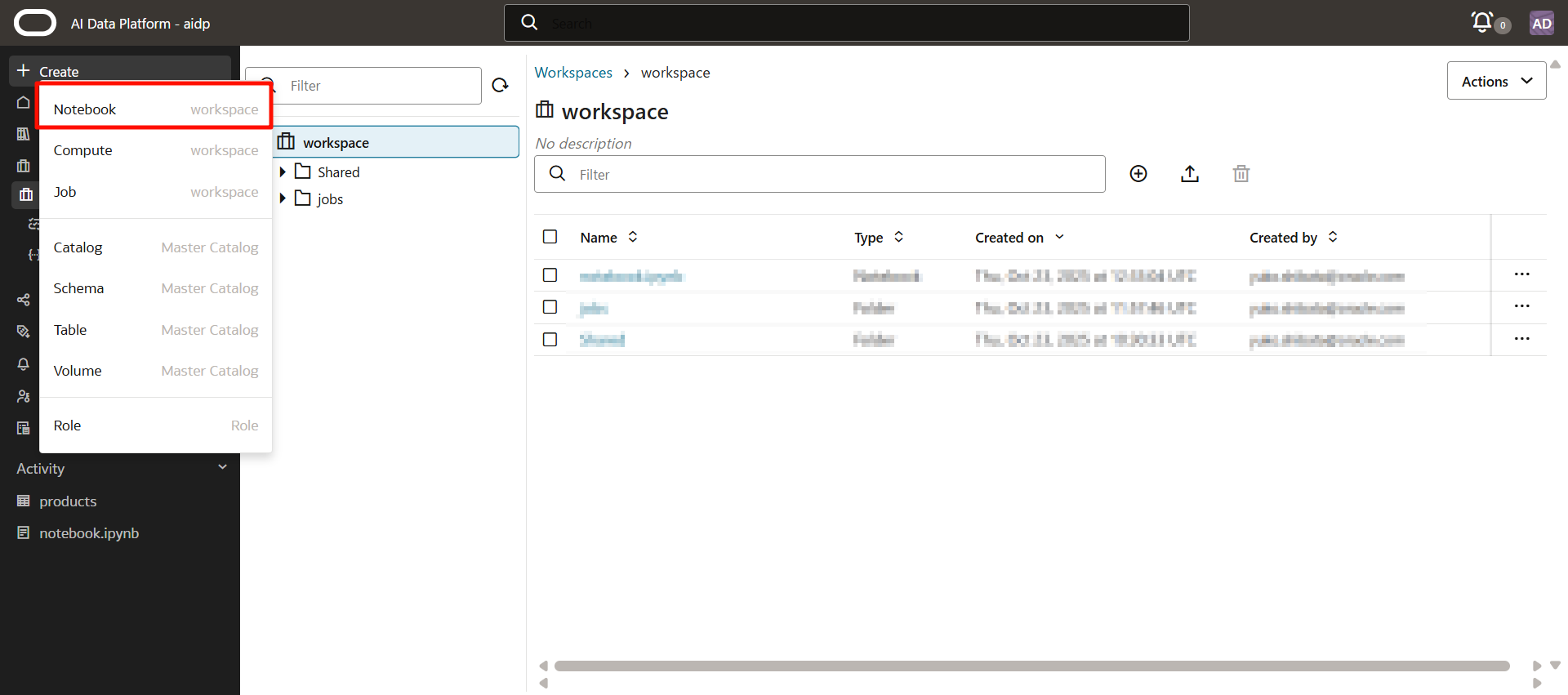
左メニューから「Create」>「Notebook」を選択します。
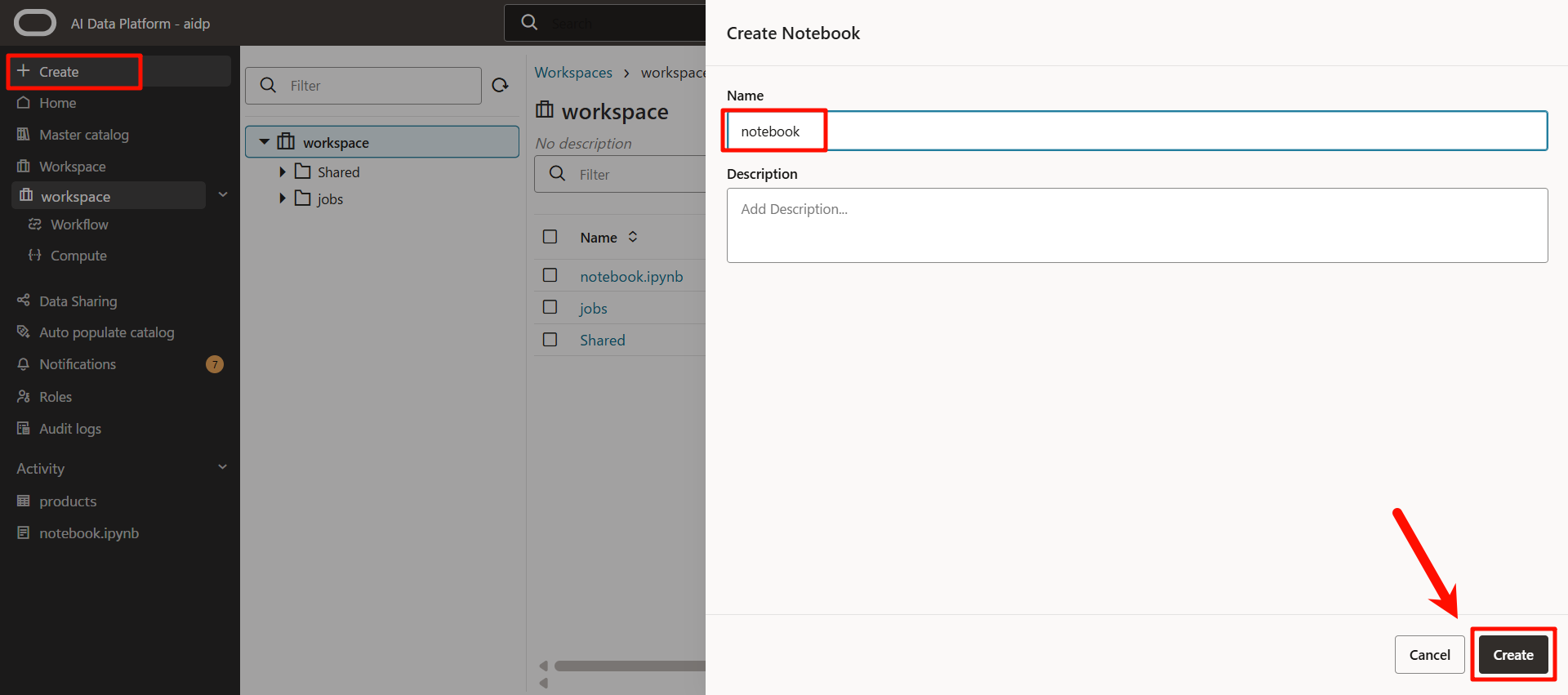
任意の名前を入力して、「Create」をクリックします。
5. SQLで試す
作成したノートブックをクリックします。
「Cluster」から先程作成したクラスターを選択します。
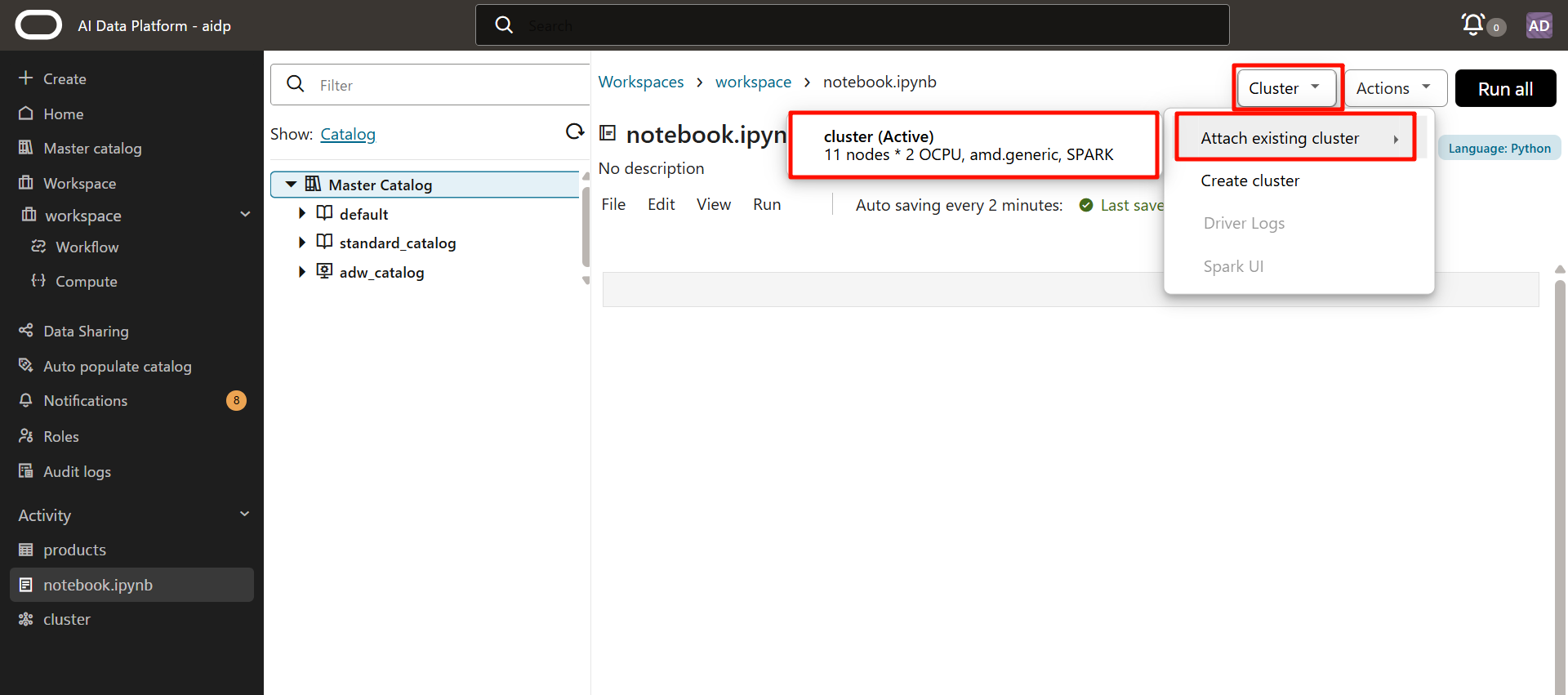
「Attaching」>から「Active」になりました。
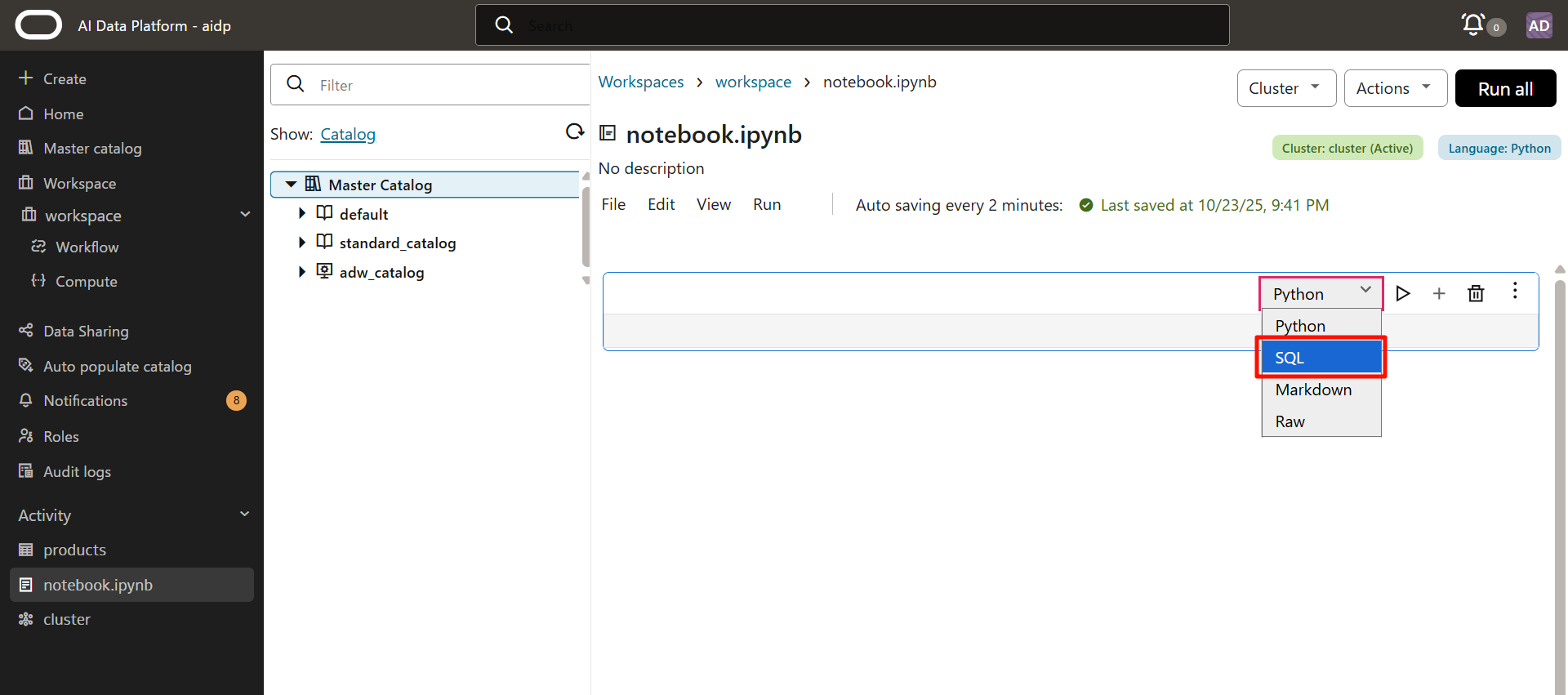
SQLを選択します。
まずは標準カタログの表を確認してみました。
テーブル名は以下の形式で指定します。
catalog_name.schema_name.table_name
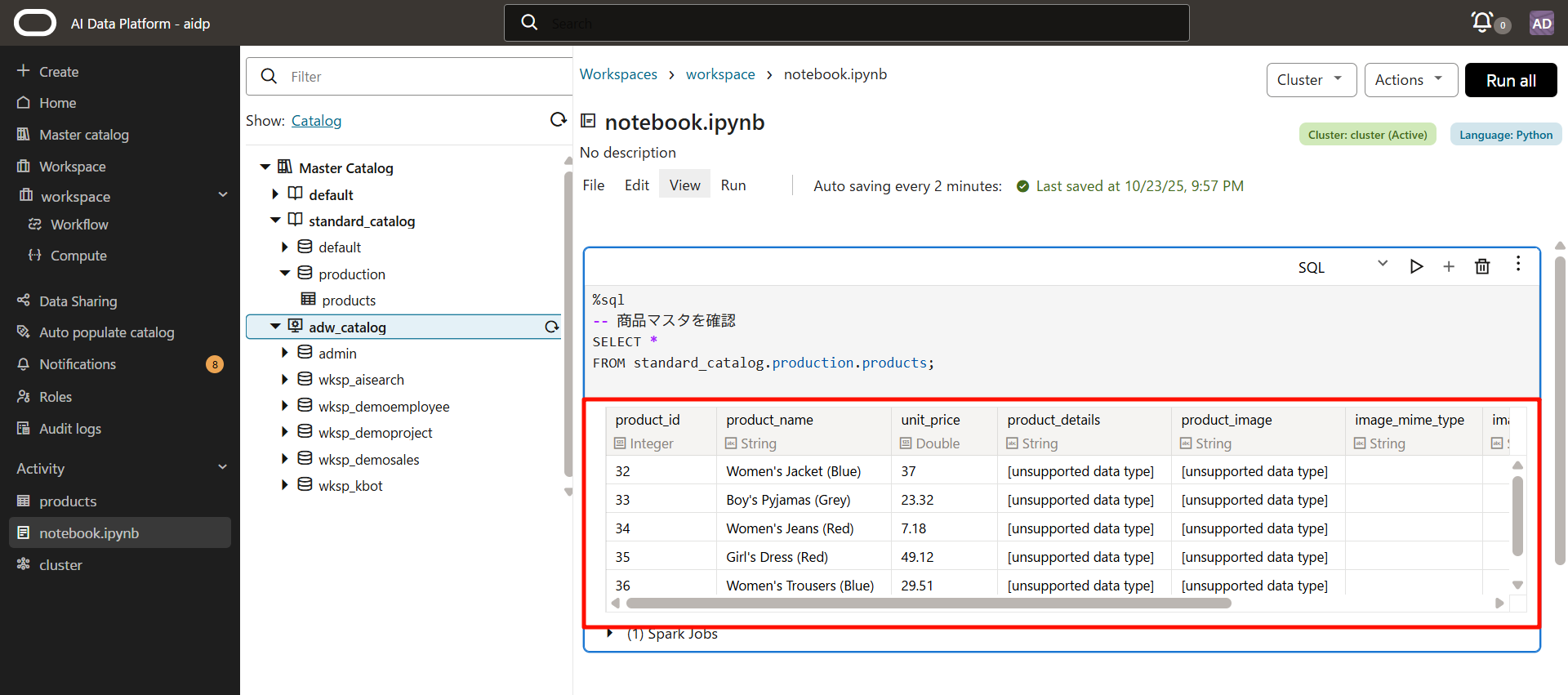
外部カタログ内のADWのテーブルも確認できました。
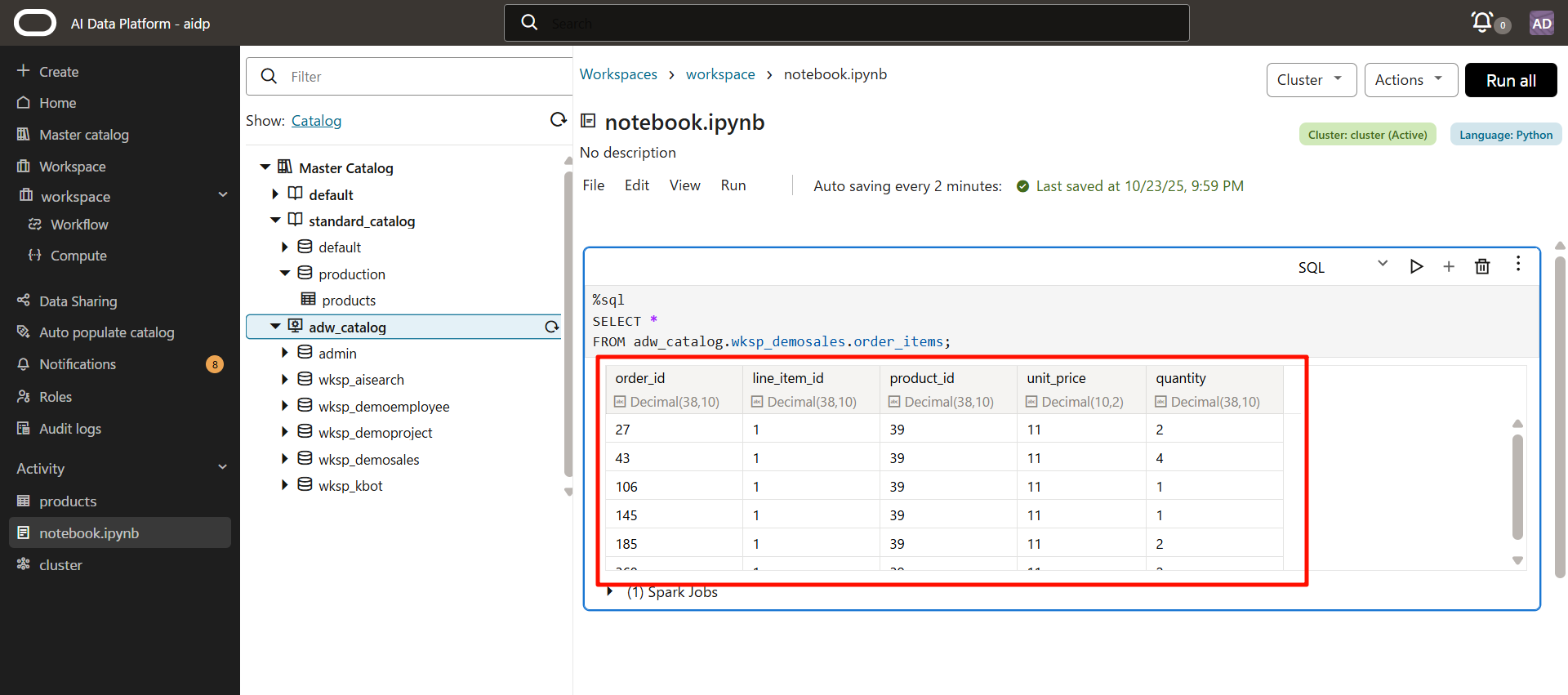
ADW上の注文明細テーブルと、AIDPの標準カタログに登録した商品マスタを結合して、商品名や単価を含む注文の内容を確認することができました。
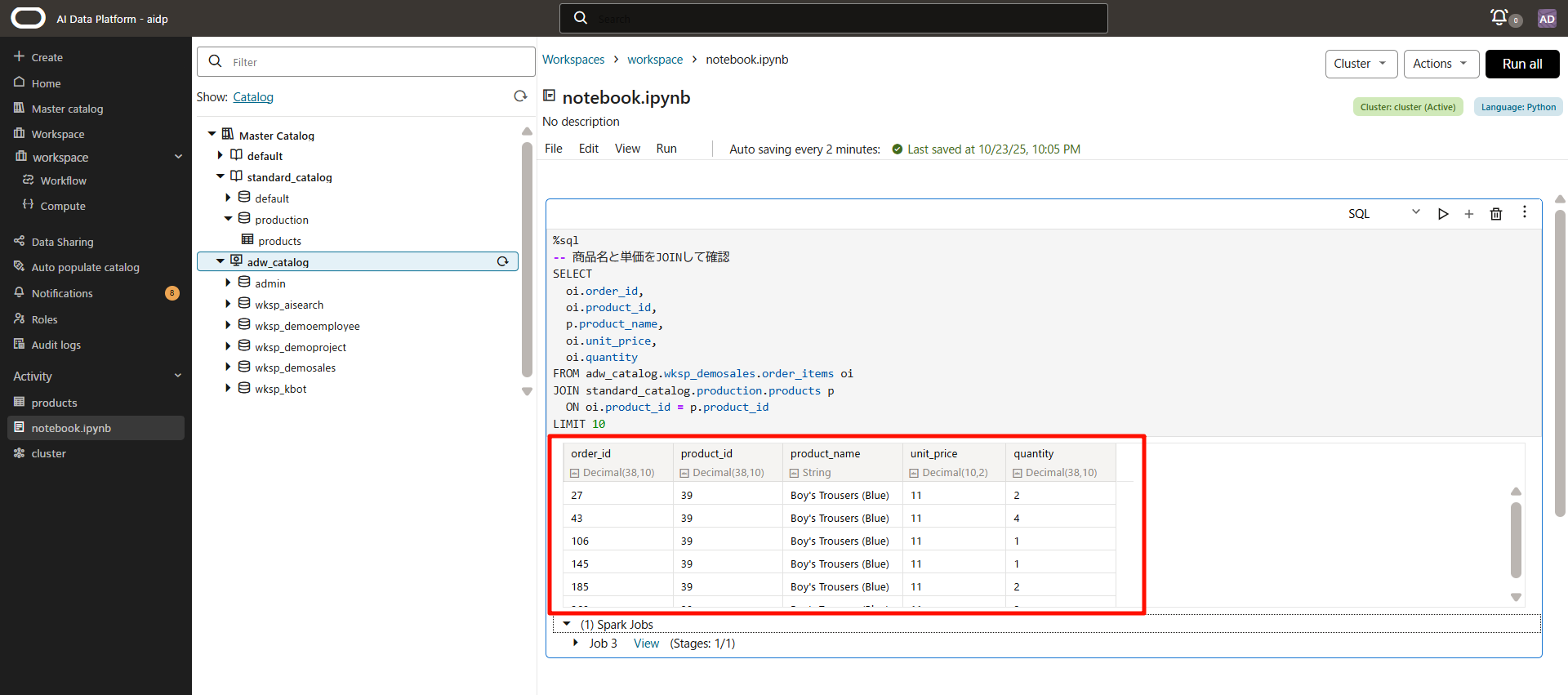
6. Pythonで試す
同様に、二つの表から集計して「商品別の売上合計」をPythonで表示してみます。
このコードでは、ADW上の order_items テーブルと、AIDP内の products テーブルをJOINし、「単価 × 数量」で売上金額を算出した上で、商品ごとに集計しています。
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum as spark_sum
# ====== テーブルを読み込み ======
order_items_df = spark.table("adw_catalog.wksp_demosales.order_items")
products_df = spark.table("standard_catalog.production.products")
# ====== JOIN ======
joined_df = order_items_df.alias("oi").join(
products_df.alias("p"),
col("oi.product_id") == col("p.product_id"),
how="inner"
)
# ====== 売上金額を計算(oi.unit_price × oi.quantity) ======
sales_df = joined_df.withColumn(
"total_sales",
col("oi.unit_price") * col("oi.quantity")
)
# ====== 商品別に集計 ======
product_sales = (
sales_df.groupBy(col("p.product_name"))
.agg(
spark_sum(col("oi.quantity")).alias("total_quantity"),
spark_sum(col("total_sales")).alias("total_sales")
)
.orderBy(col("total_sales").desc())
)
# ====== 結果を表示 ======
display(product_sales)
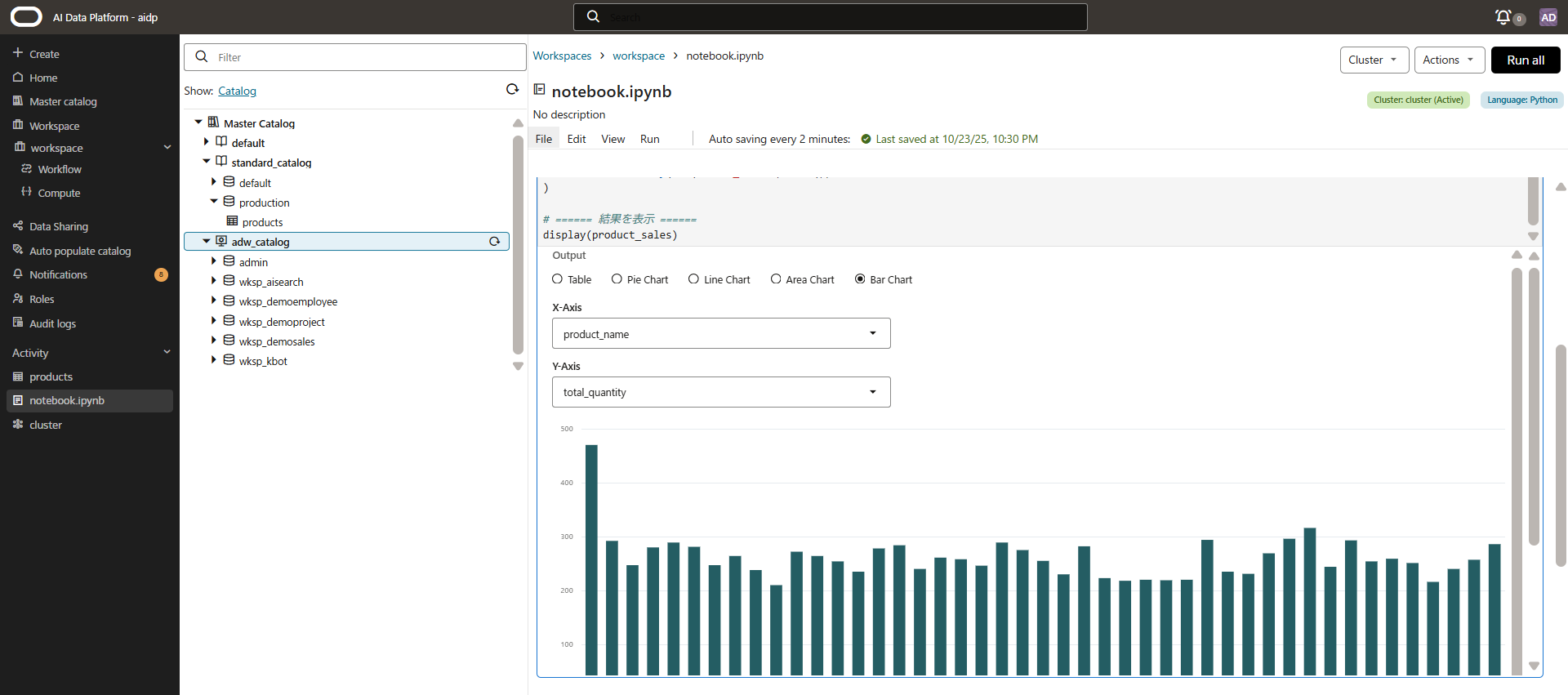
無事表示出来ました!
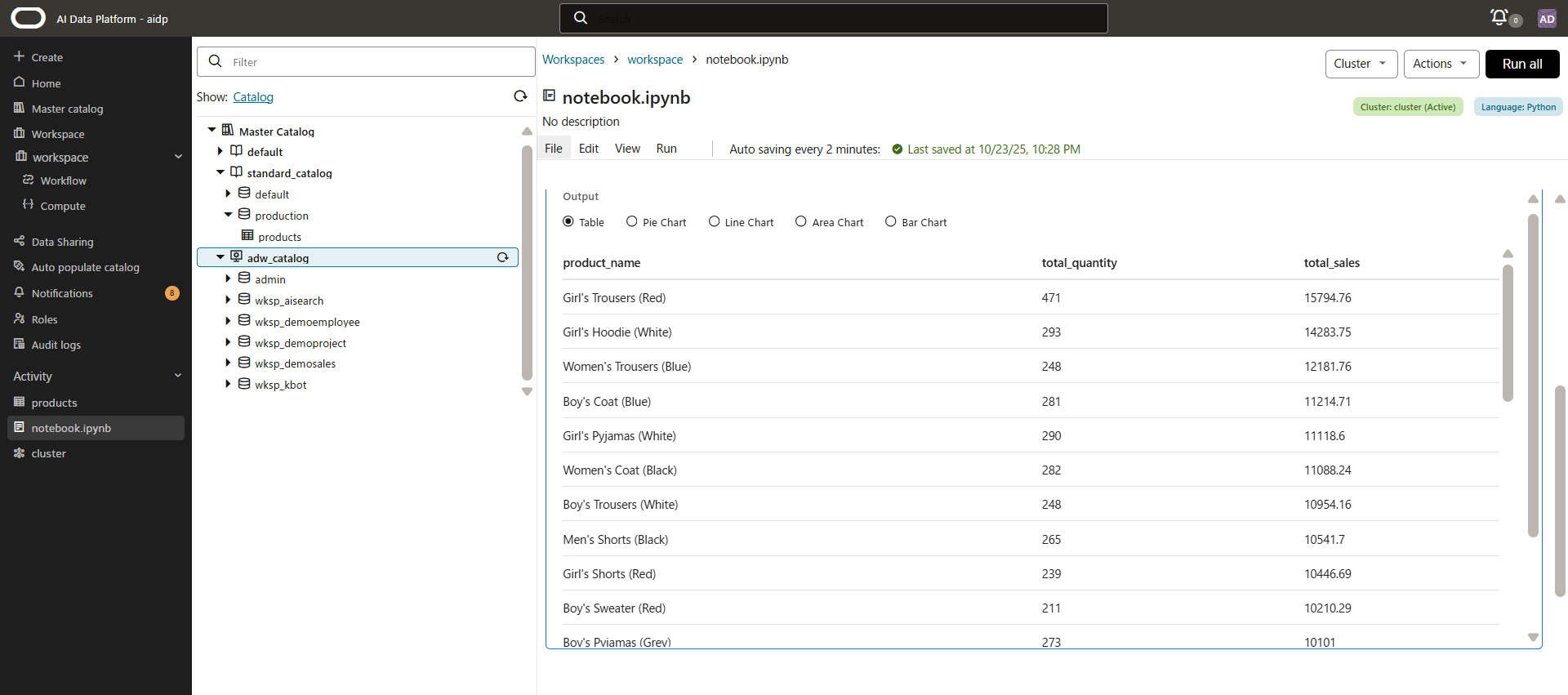
x軸y軸を選択して、結果をグラフで表示できます。
おわりに
今回は、Oracle AI Data Platform(AIDP)を使って、
OCI上のデータとAutonomous Database(ADB)のデータを結合・分析できることを検証しました。
AIDPでは、データレイクやカタログを通じてデータ資産を一元管理できるだけでなく、
ノートブック環境やSparkクラスターを活用することで、
分析からAIモデル構築までを同じ基盤上で行うことができます。
AIDPがOCI上でのAI活用をどのように加速できるのか、引き続き検証していきたいです。