背景
何となく競馬×気機械学習に興味がわいた。
参考にしたサイトにはスクレピングしてほしい内容がされていなかった。
競馬には馬や騎手などの情報は重要だが、レース環境(ダートか芝か、天気は晴れか雨かなど)によって順番が変化すると考えられる。
今回何となく取り組んでみたので備忘録としてまとめる。
html,scc,BeautifulSoupなどの概要説明は省かせていただきます。
あくまでも使い方の確認で。
競馬サイト(netkeiba.com)リンクを対象にしました。
また、スクリプトする内容は赤枠の項目です。
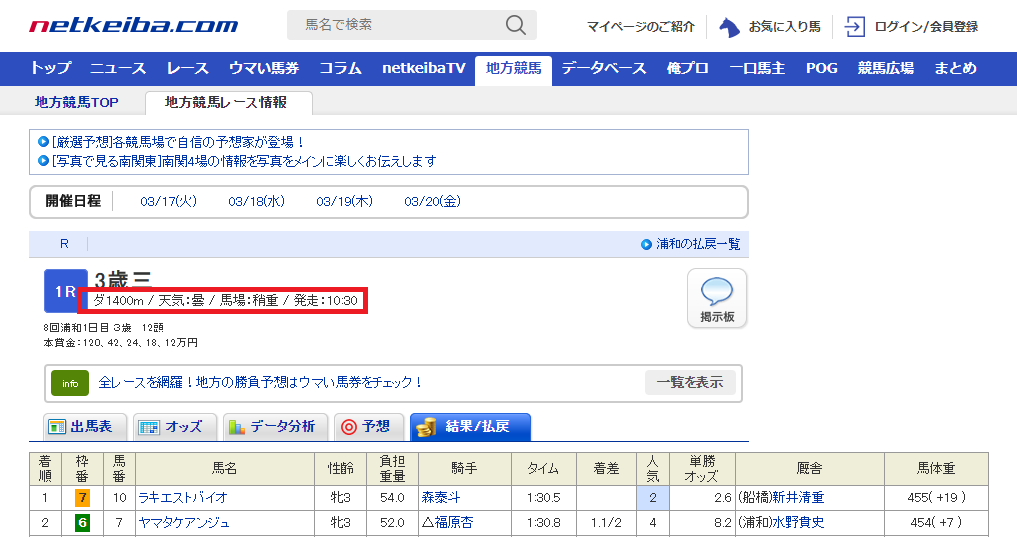
ターゲットを確認
上記の四角で囲んだ内容がどの要素に該当するのかを確認します。
chromeであれば、
右端のメニュー → その他のツール → ディベロッパー ツール
を選択すると、ウェブページの構想を確認できます。

サンプルコード
抽出したい文字列がspan要素に入っているので直接アクセスします。
抽出方法はいくつかあり、以下のサンプルコードは遠回りかもしれません。
# HTMLをダウンロード
import requests
# BeautifulSoupで情報を取得
from bs4 import BeautifulSoup
# URLを指定
r = requests.get("https://nar.netkeiba.com/?pid=race&id=p201942100701")
# HTMLとパーサ(読み取り方式)を指定
soup = BeautifulSoup(r.content, "html.parser")
# htmlからspan要素を抽出
tags = soup.find_all('span')
print(tags)
""" 見やすいように改行
[<span>マイページのご紹介</span>, <span>お気に入り馬</span>, \
<span>ログイン/会員登録</span>, <span>(s)ログイン</span>, \
<span>(s)無料会員登録</span>, <span>(s)ログアウト</span>, \
<span>ダ1400m / 天気:曇 / 馬場:稍重 / 発走:10:30</span>, \
<span>7</span>, <span>6</span>, <span>4</span>, <span>8</span>, \
<span>3</span>, <span>1</span>, <span>2</span>, <span>8</span>, \
<span>6</span>, <span>5</span>, <span>7</span>, <span>5</span>]
"""
# 内包表記 抽出する際に"天気"は不変であるので条件指定
names = [t.text for t in tags if "天気" in t.text]
print(names)
"""
['ダ1400m\xa0/\xa0天気:曇\xa0/\xa0馬場:稍重\xa0/\xa0発走:10:30']
"""
# "\xa0/\xa0" で区切ればOK
weather_ = names[0].split('\xa0/\xa0')
print(weather_)
"""
['ダ1400m', '天気:曇', '馬場:稍重', '発走:10:30']
"""
おまけ メイン情報を取得
@akihiro199630 様のスクレイピングコードが勉強になったので、
勉強させていただきました。
競馬サイトをクローリング&スクレイピングしてみた その1
の記事のコードを参考にしました。
import requests
import lxml.html
import csv
# URLを指定
URL = "https://nar.netkeiba.com/?pid=race&id=p201942100701"
r = requests.get(URL)
r.encoding = r.apparent_encoding #文字化けを防止
html = lxml.html.fromstring(r.text) #取得した文字列データ
rlt = [] #結果
# HTML文字列からHtmlElement型に変換
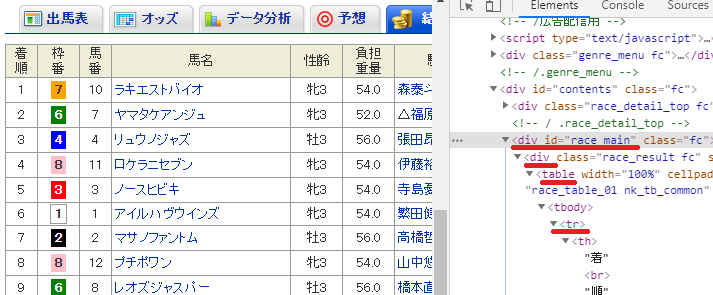
# [(div id="race_main")→(div class)→(table width)→(tr)] →(td)に情報が詰まっている
for h in html.cssselect('#race_main > div > table > tr'):#スクレイピング箇所をCSSセレクタで指定
#Element番号を取得
h_1 = h
#Element番号のテキスト内容を取得
h_2 = h_1.text_content()
#改行("\n")をもとに分割する
h_3 = h_2.split("\n")
#内包表記 空の要素を駆逐する 空文字を除く
h_4 = [tag for tag in h_3 if tag != '']
#1位にはタイムが記録されない
if len(h_4) != 13:
#強引に加える必要がある 8番目に0
h_4.insert(8,0)
#リストに行のデータ(リストを追加)
rlt.append(h_4)
# 抽出結果
print("h_1",h_1)
"""
h_1 <Element tr at 0x1c35a3d53b8>
"""
print("h_2",h_2)
"""
12
5
5
スーパークルーズ
牡3
56.0
秋元耕成
1:34.2
7
12
459
(浦和)冨田敏男
469( +1 )
"""
print("h_3",h_3)
"""見やすいように改行
h_3 ['', '12', '5', '5', 'スーパークルーズ', '', '牡3', '56.0', '秋元耕成', \
'1:34.2', '7', '12', '459', '(浦和)冨田敏男', '469( +1 )', '']
"""
print("h_4", h_4)
"""
h_4 ['12', '5', '5', 'スーパークルーズ', '牡3', '56.0', '秋元耕成', '1:34.2', '7', '12', '459', '(浦和)冨田敏男', '469( +1 )']
"""
# CSVファイルに保存
with open("result.csv", 'w', newline='') as f:
wrt = csv.writer(f)
wrt.writerow(rlt.pop(0)) #1行目 項目 writerow
wrt.writerows(rlt) #抽出結果 writerows
おまけ レースした日付
レースした馬の過去の成績をニューラルネットワークに反映させたいときに、
レースした前の日の直近のデータが必要となる。
この点を考慮しないと、レースした日以降の成績を反映してしまう。
そこで対象としたサイトのレースの日を取得する簡単なコードを書いたのでまとめる。
# URLを指定
URL = "https://nar.netkeiba.com/?pid=race&id=p201942100701"
# 年月日が大事 レース日から過去に遡る必要があるから
# URLを全て分割して=p移行 201942100701 → 2019 42 1007 01
# 2019 42 1007 01 → 年 ?(競馬会場番号?) 月日 レース番号
# URLから年月日の12桁(201942100701)を抽出
url_12_ymd = URL[-12:]
print(url_12_ymd)
# 201942100701
url_12_y = url_12_ymd[:4]
print(url_12_y)
# 2019
url_12_md = url_12_ymd[6:10]
print(url_12_md)
# 1007
url_12_race = url_12_ymd[10:]
print(url_12_race)
# 01
今後の流れ
必要な情報は抽出できたので、ダ(ダート)や雲、稍重などを数値化かして、ニューラルネットワークにぶち込めばいいのかな。
やる気があれば、今後も続けたいですね。
参考にしたサイト(※)ではレース環境以外の重要な情報を取得できているので、
サイト内のコードに上記のコートを統合させれば、うまくいくかな。
参考サイト
@akihiro199630 スクレイピングに多く取り組んでいる方です。神です。
Pythonクローリング&スクレイピング 第1章まとめ
Pythonクローリング&スクレイピング 第4章まとめ
【Scrapy】抜き出したURLを修正・加工する