はじめに
先にまとめた「Pythonクローリング&スクレイピング[増補改訂版]―データ収集・解析のための実践開発ガイドー」加藤耕太・著 の第2章までの知識の実践として、Pythonを利用した競馬のレース結果のクローリング・スクレイピングを行う。なおコードに関しては同書P71のサンプルコードを大いに参考にしている。
今回クローリング・スクレイピングの対象とするのは競馬情報サイトnetkeibaの地方競馬カテゴリの上部からリンクされているここ数日の開催の結果表である(数日たったら消えるっぽい?コードを書いている途中で気づいた…)
環境についてはWindows10のAtomで書いたコードを、WSL上のUbuntu18.04からPython3.7.3を用いて実行している
やること
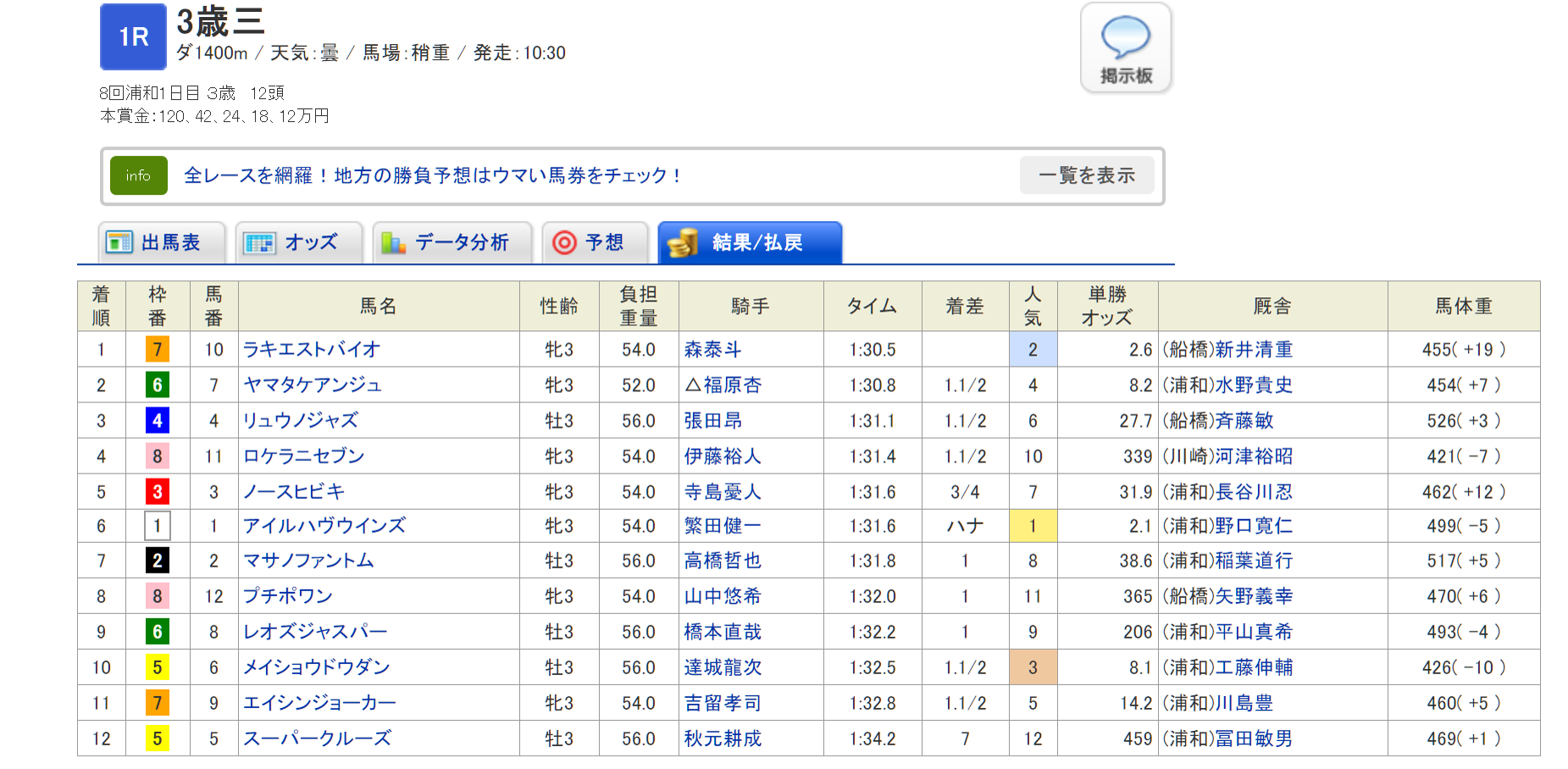
- 上の結果表(8回浦和1日目1R3歳三)から各行を取り出してCSV形式で保存する
実装した機能
- コマンドライン引数で入力したURLのWebページを取得(クローリング)
- 取得結果をパースして欲しい部分のみを切り出す(スクレイピング)
- スクレイピングしたデータをCSVに出力
実際のコードと実行結果
keiba_scraping.py
import sys
import requests
import lxml.html
import re
import csv
def main(argv):
url = argv[1] #コマンドライン引数からURLを取得
html = fetch(url) #URLのWebページを取得
result = scrape(html) #取得したWebページから欲しい部分のみを切り出す
save('result.csv',result) #切り出した結果をCSVに保存する
def fetch(url :str):
r = requests.get(url) #urlのWebページを保存する
r.encoding = r.apparent_encoding #文字化けを防ぐためにencodingの値をappearent_encodingで判定した値に変更する
return r.text #取得データを文字列で返す
def scrape(html: str):
html = lxml.html.fromstring(html) #fetch()での取得結果をパース
result = [] #スクレイピング結果を格納
for h in html.cssselect('#race_main > div > table > tr'):#スクレイピング箇所をCSSセレクタで指定
column = ((",".join(h.text_content().split("\n"))).lstrip(",").rstrip(",")).split(",")
#text_content()はcssselectでマッチした部分のテキストを改行文字で連結して返すので、
#splitを使って改行文字で分割して、その結果をカンマ区切りでjoinする。
#前と後ろに余計な空白とカンマが入っている(tdじゃなくてtrまでのセレクタをしていした分の空文字が入っちゃってる?ようわからん)ので、
#splitで空白を、lstrip,rstripでカンマを削除してさらにそれをカンマで区切ってリストにしている
column.pop(4) if column[4] == "" else None #1行目以外、馬名と性齢の間に空文字が入っちゃってるので取り出す
result.append(column) #リストに行のデータ(リストを追加)
return result #結果を返す
def save(file_path, result):
with open(file_path, 'w', newline='') as f: #ファイルに書き込む
writer = csv.writer(f) #ファイルオブジェクトを引数に指定する
writer.writerow(result.pop(0)) #一行目のフィールド名を書き込む
writer.writerows(result) #残りの行を書き込む
if __name__ == '__main__':
main(sys.argv)
実行してCSVを表示すると…
$ python keiba_scraping.py 'https://nar.netkeiba.com/?pid=race&id=p201942100701'
$ cat result.csv

念の為、Googleスプレッドシートでも確認
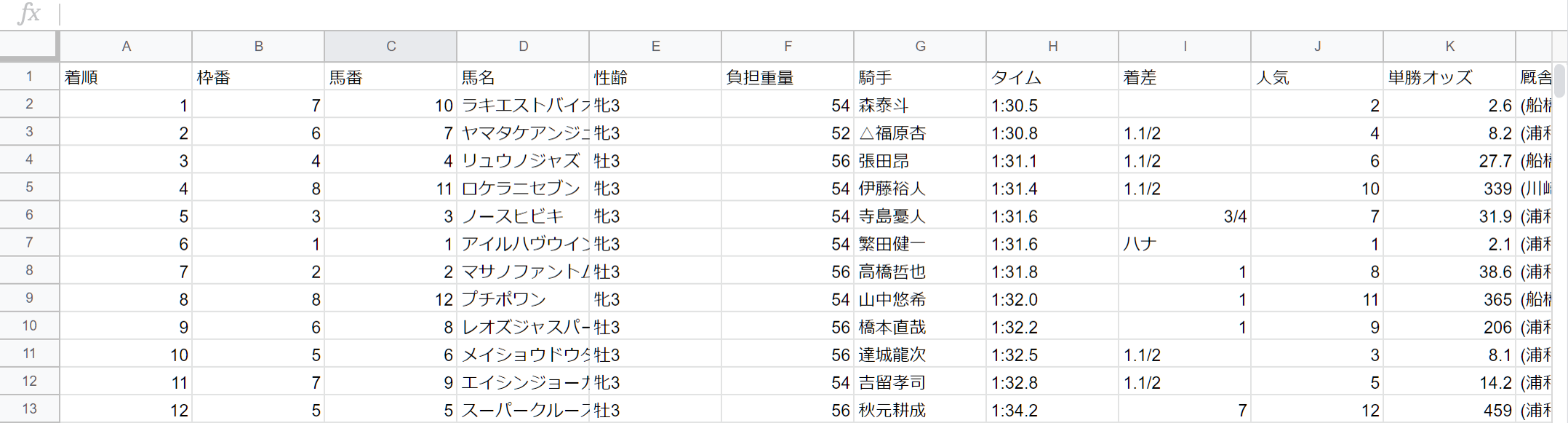
行・列ともに同じ内容が表示されています
同じページ構造の他のレースでも試してみると…
$ python keiba_scraping.py 'https://nar.netkeiba.com/?pid=race&id=c201930100812'
$ cat result.csv
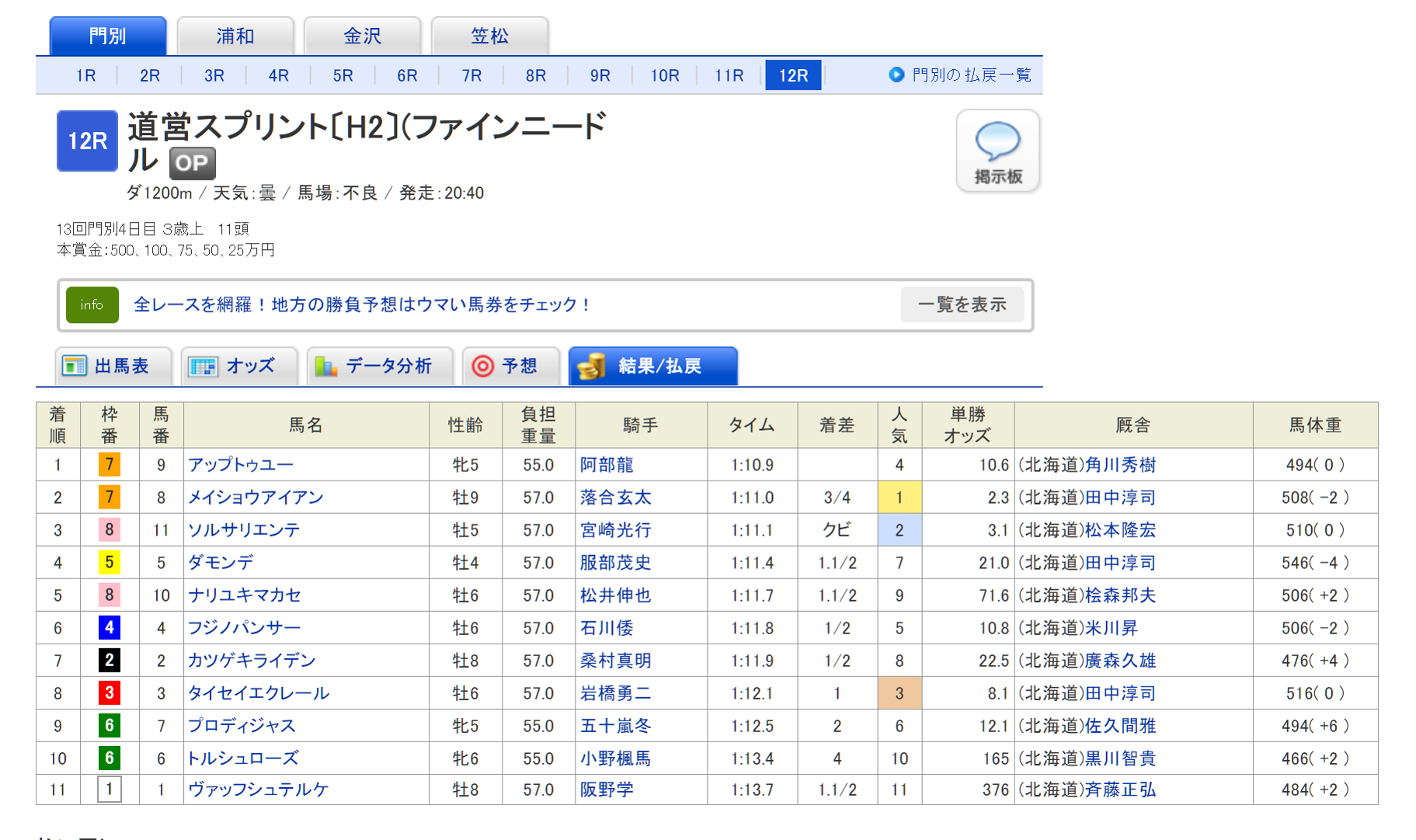
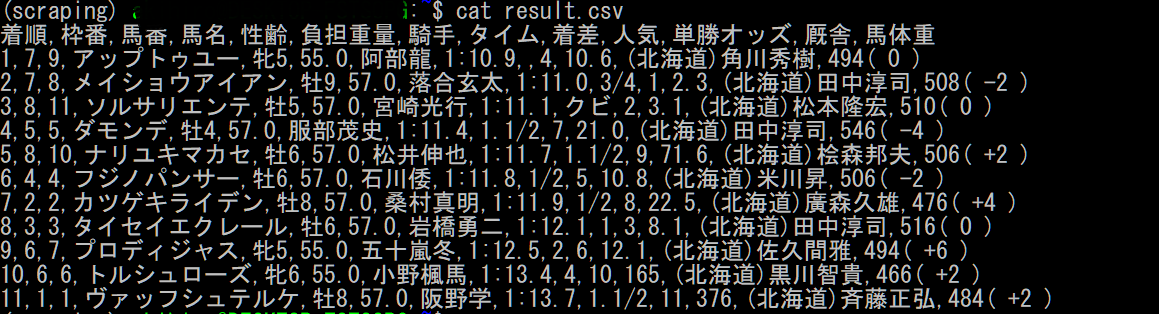
きちんとレース結果が取得されています~~(1着馬を買うかどうか悩んでいるうちに、投票締め切られていたのが悔やまれる)~~
苦労した点
tbody
スクレイピング部分をするためのCSSセレクタは、Chromeの検証ツールを使ってCopy→Copy selecterでお手軽にコピーしたのだが、ブラウザが実際のソースにはない
というタグを