はじめに
現在作りたいと思っているWebアプリがあって、そのためにはある分野のWeb上のデータを自動で収集してくる必要があるため、「Pythonクローリング&スクレイピング[増補改訂版]
―データ収集・解析のための実践開発ガイドー」加藤耕太・著を購入した。
自分はアウトプット不精なのでこの本を読み進めながら内容をまとめてQiitaに公開していくことにする。
並行してFlaskフレームワークでのWebアプリ開発についてもアウトプットしていけたらと考えている。
サブPCを購入したのでサンプルプログラムはSourceTreeでも使ってメインとサブで共有して行く予定。
第1章 クローリング・スクレイピングとは何か
クローラ
Web上のページの情報を取得するためプログラム。
高速でデータを取得することができるので、使用の際は相手側のサーバへの負荷を考えないといけない。
クローリング
Webページのハイパーリンクをたどって次々にWebページをダウンロードする作業。
スクレイピング
ダウンロードしたWebページから必要な情報を抜き出す作業。
Linuxの環境構築
といった概要の説明があったところで、Pythonを使ったクローリング・スクレイピングの前に、Wgetというツールを使ったデータの取得を行うため、Linuxの環境構築が必要となるのだが
注釈に
Windows Subsystem for Linux(WSL)を使っている方は、これでUbuntu 18.04を動かしても良いでしょう。ただし本書では検証を行っていないため不具合などが発生してもサポートできません。
とありましたのでじゃあWSLでやってやるか、ということでMicrosoft Storeからダウンロード。
↑WSLでUbuntu18.04を動かしている様子
こちらのサイトを参考にして日本語化。結構時間がかかるので注意。
WSLのUbuntu環境を日本語化する:Tech TIPS
Wgetでクローリング
といったところでWgetを使ってWebサイトをクローリングする項目へ
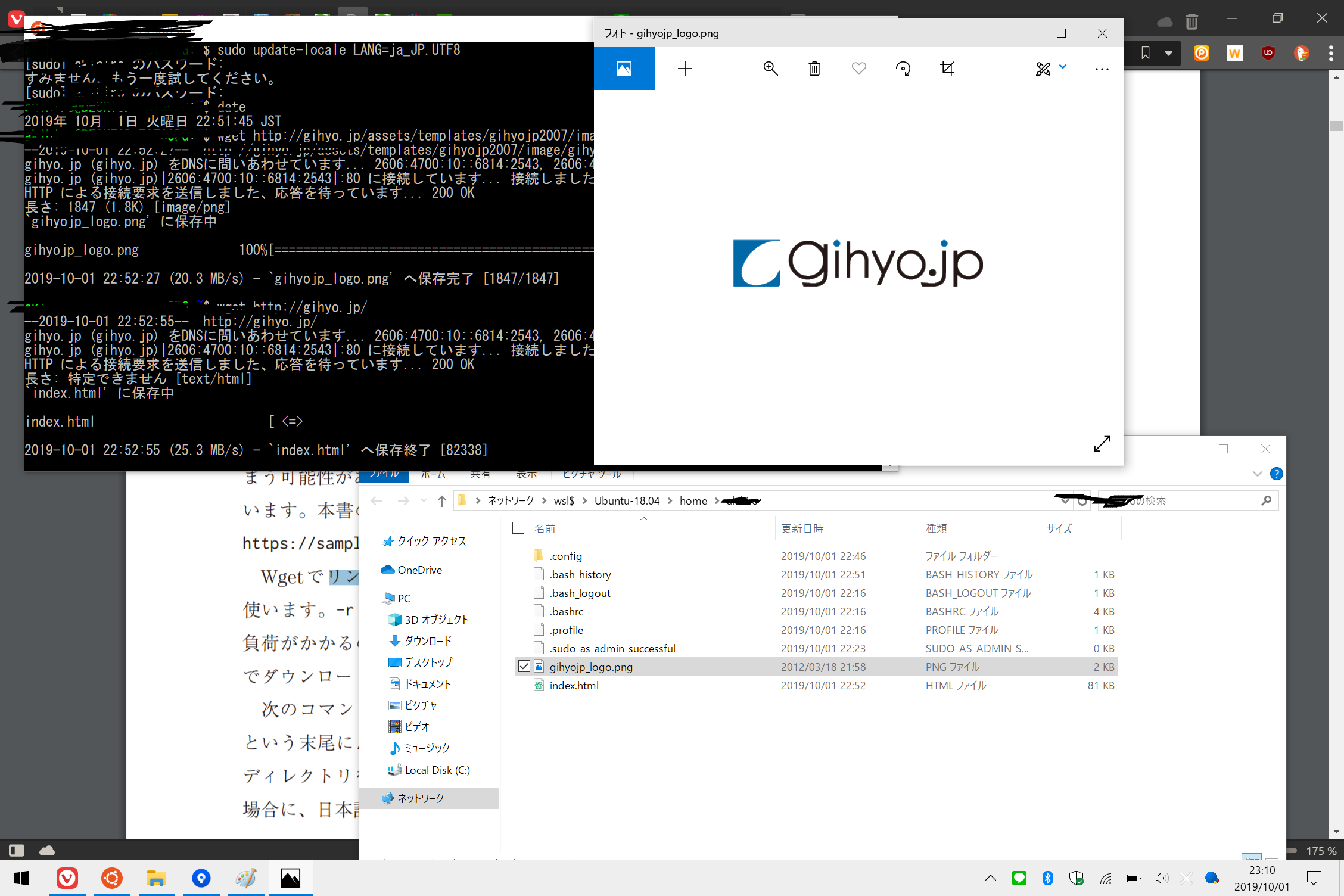
まず最初はこの本の版元の技術評論社からロゴ画像とトップページのデータを取得するというもの。
$ wget <URL>
で取得が可能
取得データについては↓
WindowsからLinuxファイルへのアクセスが可能に ~「Windows 10 19H1」におけるWSLの改善
を参考にし explorer.exe .コマンドでカレントディレクトリをWindowsのエクスプローラーで開いて、きちんと保存されていることを確認。
wget -r --no-parent -w 1 -l 1 --restrict-file-names=nocontrol <URL>
でページ内のリンクを辿って再帰的にクローリング
オプションの意味は以下の通り
- -rオプション→再帰的なクローリングの指定
- -lオプション→リンクをたどる深さ
- -w→ダウンロードをする間隔(秒)
- --no-parent → 親ディレクトリをクローリングしない
- --restrict-file-names=nocontrol→URLに日本語が含まれる
場合に、日本語のファイル名で保存
sudo apt install tree
して
tree <URL>
で↑でクローリングしたサイトのディレクトリ構造を表示
実際のサイトと比べるときちんとリンク1つ辿ってクローリングされてることがわかる
Unixコマンドの基礎知識
標準ストリーム→標準入力・標準出力・標準エラー出力
パイプ(|)→ 〇〇コマンド XXXX | △△コマンド XXXX 〇〇コマンドの標準出力を△△コマンドの標準入力に渡している例
-
catコマンド→引数で与えたファイルを出力する
cat ファイル名
-
grepコマンド→引数で与えた文字列や正規表現にマッチする行を抜き出す
- 例:
cat ファイル名 | grep 文字列or正規表現パターン→catの引数のファイルからgrepの引数にマッチしたものを出力する
- 例:
-
cutコマンド→指定した文字列で区切られたテキストの列の一部を取り出す
- 例:
cat ファイル名 | cut -d , -f 1,2→catの引数のファイルから , で区切られた1,2列を出力する
- 例:
-
sedコマンド→引数で検索する文字列と置換する文字列を指定すると、前者を後者に置き換えて出力する
- 例:
cat ファイル | sed 's/A/B/g'→catの引数のファイルのAをBに置き換えて出力する
gは一行で複数マッチしてもすべて置き換えるというオプション
- 例:
-
wcコマンド→文字数や行数を数えるコマンド
- 例:
cat ファイル名 | wc -l→ファイルの行数を数える(-lオプション)
- 例:
ここまでのまとめ
Unixコマンドだけでもクローリング・スクレイピングができるが、複雑なスクレイピングに対応するには汎用的なプログラミング言語の力が必要…
というところでいよいよPythonを使ったクローリング・スクレイピングへ