今更ながら私がVisiting Scholarでやっていた研究を日本語版で投稿します。
この内容は約2年前(2017年9月)のMediumを日本語訳した内容です。
Githubのソースコードはコチラです。
Fully Convolutional Refined Auto-Encoding Generative Adversarial Networks for 3D Multi Object Scenes

-Special thanks to Christopher Choy and Prof. Silvio Savarese, and Stanford Vision and Learning Lab.
Introduction
GAN(Generative Adversarial Networks)やVAE(Variational Auto-Encoder)を活用した生成モデルは、ディープラーニングやコンピュータービジョンの領域で非常に注目されているテーマの一つである。これらの生成モデルは、高品質の生成を可能にするだけでなく、表現学習や特徴量抽出、さらには潜在空間を活用した認識タスクなどへの応用可能性を秘めている。
特に今回は3Dマルチオブジェクトの生成モデルに注目した。3Dマルチオブジェクトの生成モデルは、多様な新規の3Dオブジェクトを生成でき、かつ、オブジェクト種類、形状やレイアウトを潜在空間として表現することができる。このような3Dマルチオブジェクトの生成モデルは、AR/VR,グラフィクスの領域で極めて重要なタスクになると考えられる。
ただ、3Dの生成モデルはいまだに発展途上である。(2年後の今はRGBD->3Dや、3D Completionなどのタスクで活用されるようになってきました。) 単一オブジェクトの基本的な生成モデル[1][2] はあるが、マルチオブジェクトはない。
そこで、本研究では、End to Endで新規のGANsアーキテクチャを活用して、3Dマルチオブジェクトの生成モデルに取り組んだ。
Dataset
正解のVoxelデータとして、SUNCG Datasetを活用した[3]。
SUNCGデータセットを、以下のように変更した。
- 240x144x240から80x48x80に圧縮。
- カメラアングルによるトリミングを削除。
- Empty以外のクラスが10000voxel以上存在するシーンのみを抽出。
結果、12のクラスをもつ185K以上のシーンが集まった。
12クラス:empty, ceiling, floor, wall, window, chair, bed, sofa, table, tvs, furn, objs

このデータセットは平均92%のVoxelがEmptyクラスであり、非常にスパースである。さらに、リビング、風呂場、寝室、ダイニング、ガレージ等シーンの種類は多種多様であるため、非常に難易度の高いデータセットとなっている。
Models
ネットワーク構造
今回のネットワーク構造は、Fully Convolutional Refined Auto-Encoding Generative Adversarial Networksである。3DGAN[1], alphaGAN[4], SimGAN[5]を参考にしている。そして、Fully Convolutional Layerとマルチオブジェクトの分類が生成モデルとしては新規の構造となる。
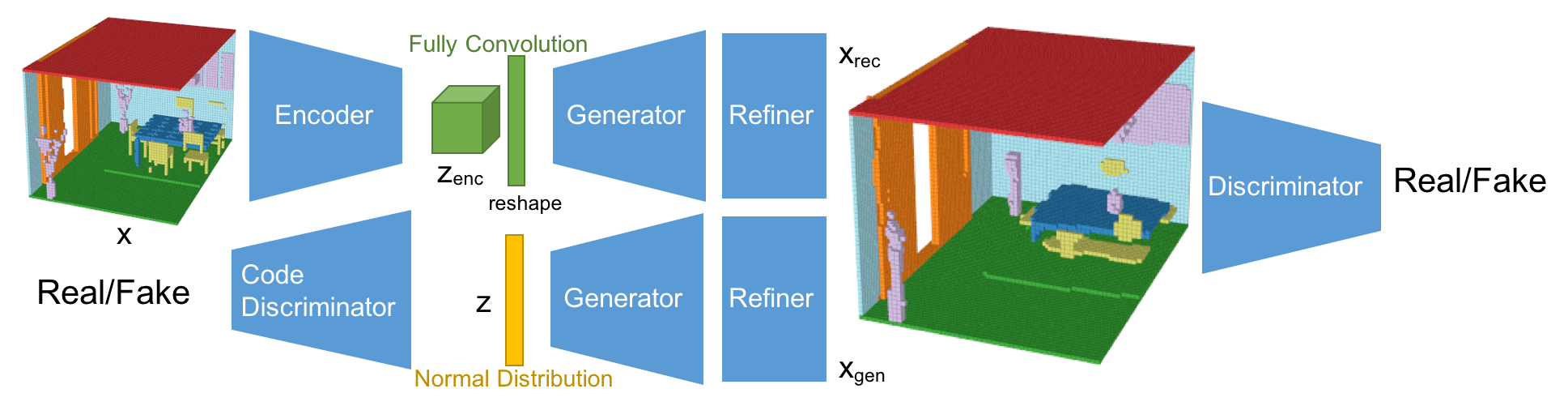
このネットワークは、VAEとGANの構造を混合させている。VAEで使われるKLダイバージェンスロスは、alphaGANの構造のように、code discriminatorとしてAAE(Adversarial Auto-Encoder)構造に置き換えている[4]。 加えて、生成されたシーンはRefinerによってより綺麗な形になるようにしている[5]。 今回、潜在空間は5x3x5x16としており、これはFully Convolutional Layerによって算出されている。Fully Convolution構造は、セマンティックセグメンテーションのタスクで使われるように、特徴量をより厳密に取り出すことができる。結果として、Fully Convolution構造は再構成の性能を向上させている。また、AAE構造は、分布への制約条件を緩め、分布をより潜在的に扱うことができるようになり、再構成と生成の性能を向上させることができている。また、Refinerはオブジェクトの形状をスムーズにして、よりリアルな見た目にする効果がある。

-Encoder
Encoderの基本構造は3DGAN[1]のDiscriminatorネットワークを踏襲している。最後のレイヤーが1x1x1のFully Convolution層のところが違いである。
-Generator
Generatorの基本構造も同様に3DGAN[1]の構造。最後のレイヤーが12チャンネルになっており、Softmaxで活性化されている。また、最初の潜在空間は展開させている。
-Discriminator
Discriminatorの基本構造も同様に3DGAN[1]の構造。ただ、活性化の前にはLayer Normalizationを活用している。
-Code Discriminator
潜在空間の分布を判定するCode discriminatorは、alphaGAN[4]と同様の構造で、750次元の2層の隠れ層を持つ。
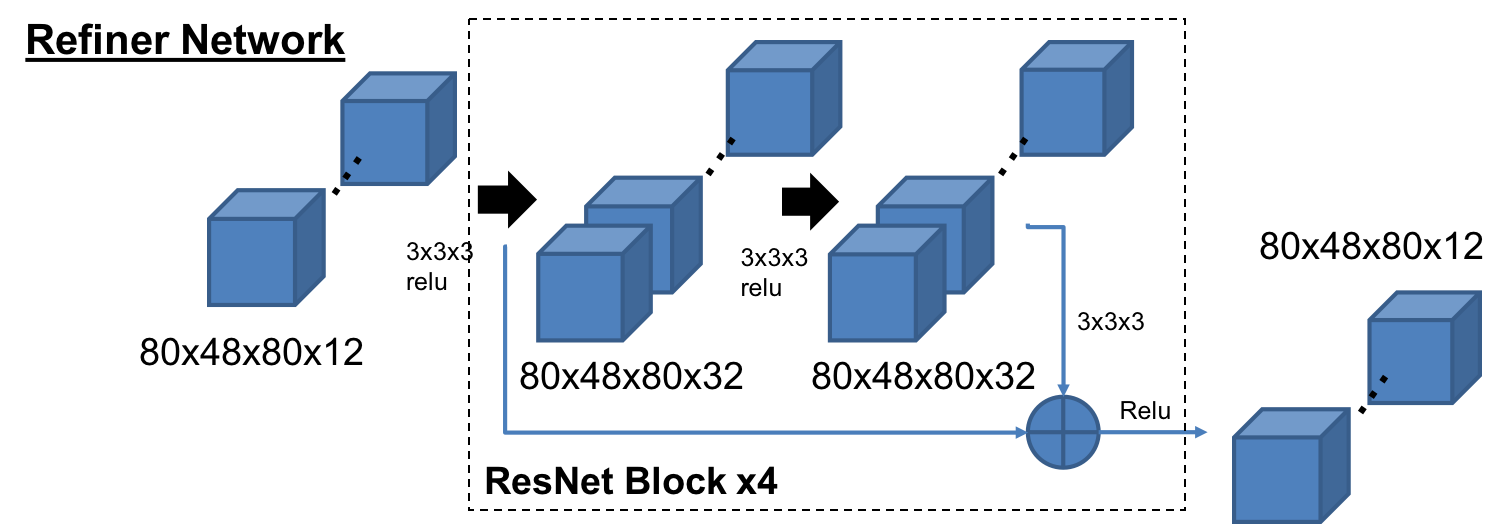
-Refiner
RefinerはSimGAN[5]の構造をベースにしており、4つのResNetブロックで構成されている。メモリーの負荷を減らすため、チャネル数は32にしている。
Loss Functions
ロス関数は、基本的には再構成のロス(Reconstruction Loss)、生成されたオブジェクトのGANロス(GAN Loss)、AAE構造の分布に対するGANロス(Distribution GAN Loss)で構成されている。
-
Reconstruction loss
は小さいオブジェクトのロスを埋もれさせないため、バッチごとのオブジェクトの専有率で正規化された重みである。
はスパースな空間でPositiveなVoxel(1)のロスの重みを調整するハイパーパラメータである。
-
GAN loss
-
Distribution GAN loss





Optimization
各ネットワーク構造ごとに以下のロス関数を使って学習する。
-
Encoder
-
Generator and Refiner
-
Discriminator
-
Code Discriminator
は再構成ロスの重み。




Experiments
それぞれのネットワーク構造に置いて、OptimizerにAdamを使い、Learning Rateは0.0001とした。まず、Refinerなして75000 iterationトレーニングを行い、その後Refienerを追加し、さらに25000 iterationを実行した。初めのトレーニングはバッチサイズ20、Refiner込みのトレーニングはバッチサイズ8とした。また、GPUにはNVIDIA GeForce GTX TITAN Xを活用した。
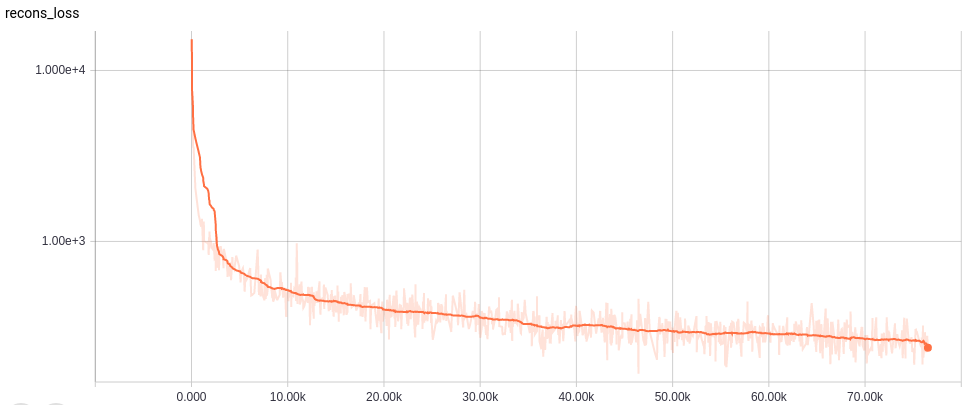
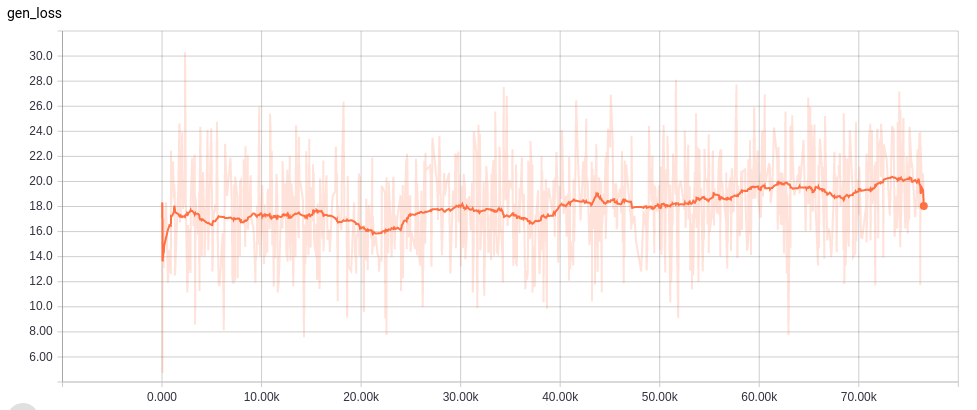
Learning curves
各ネットワークの学習カーブは以下。
Visualization
-Reconstruction
Encoder、Generator、Refinerを活用して再構成したシーンの結果を以下に示す。
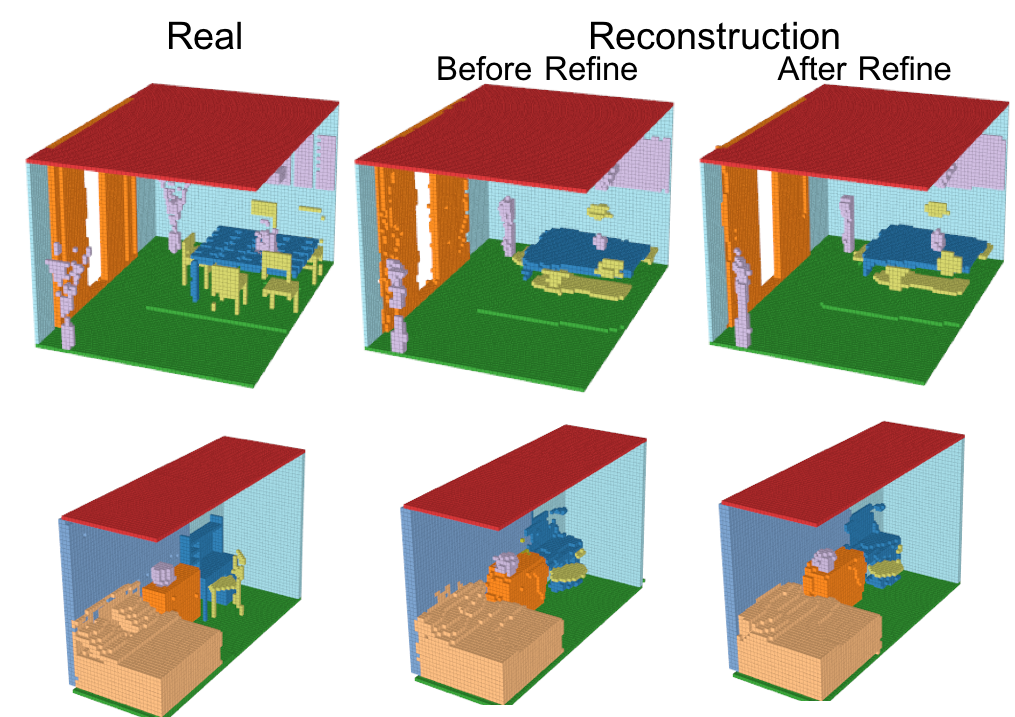
小さいオブジェクトは消えてしまっているものの、多くのVoxelは再構成されている。さらに、Refinerによってよりリアルなシーンに再構成されている。IoUとmAPを使った定量評価は後述する。
-Generation from normal distribution
GeneratorとRefinerを活用した標準分布からの生成の結果を以下に示す。
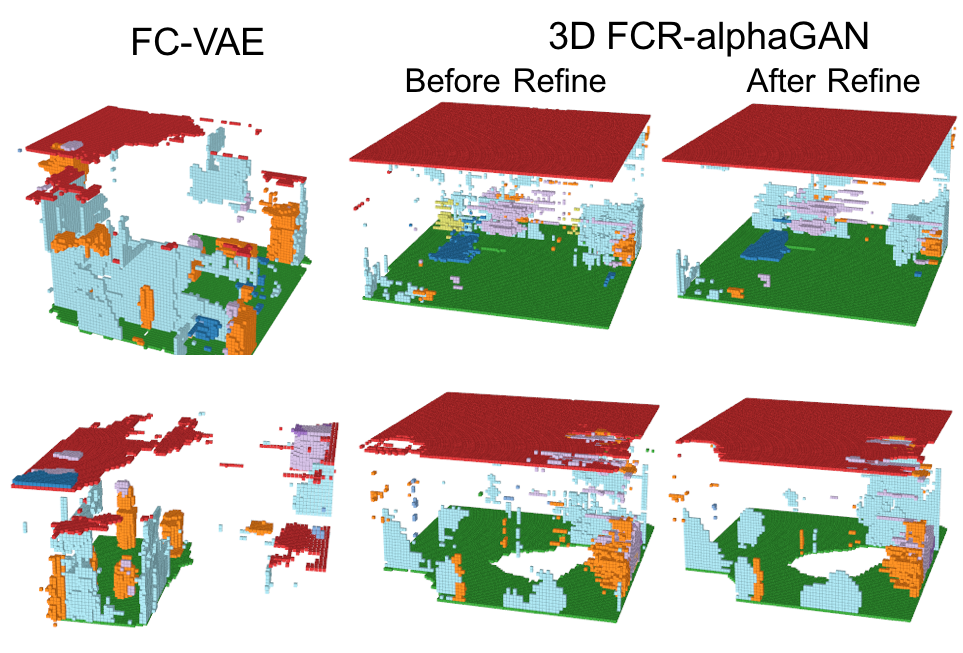
このように、FCR-alphaGANの構造は、通常のFully Convolutional VAEに比べて生成のクオリティが上がっているが、その表現能力は十分とは言えない。これは、Encoderにより生成される分布が、標準分布に分散できていないこと、データセットのスパース性やマルチオブジェクトにより、非常に複雑な潜在空間が想定されることが考えられる。潜在空間をレイアウトとオブジェクトに分離することでこの問題を解決できるかもしれない。
Reconstruction Performance
再構成の定量的な評価を以下に示す。
-Intersection over Union(IoU)
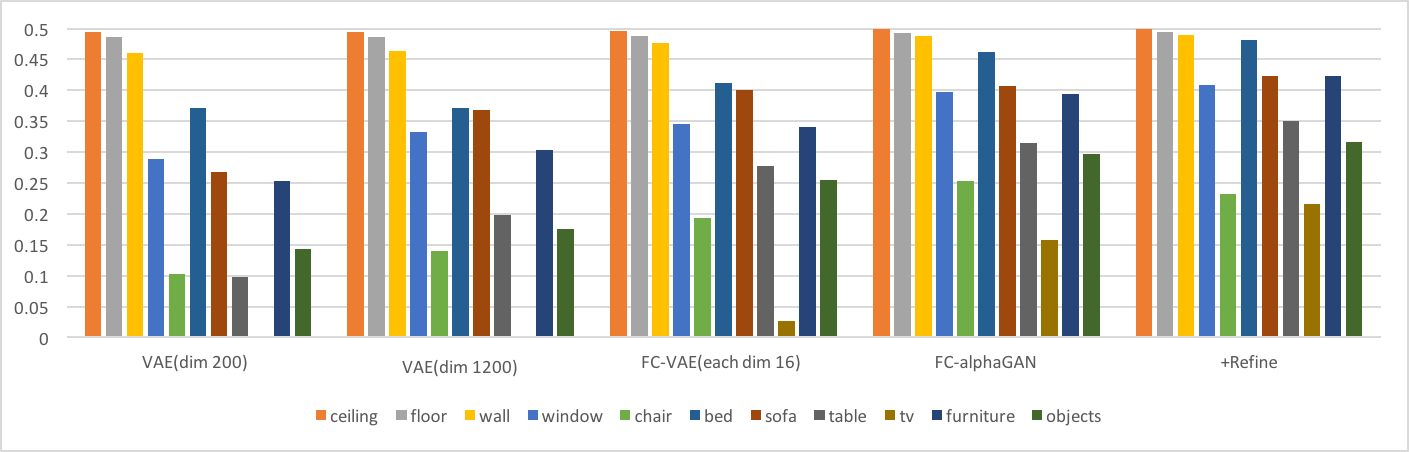
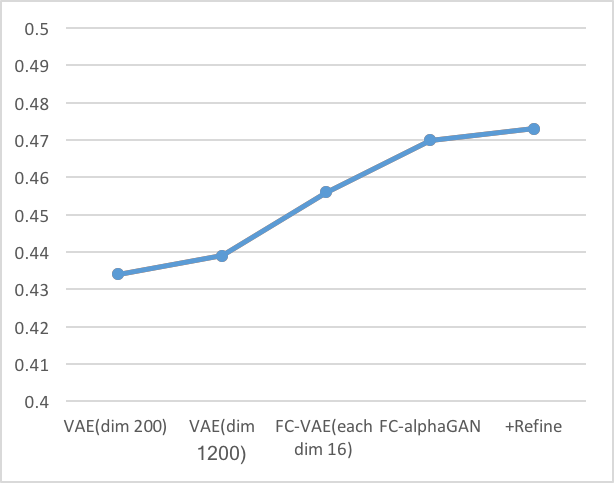
以下の棒グラフは、それぞれのクラスのIoU性能を示す。折れ線グラフはオーバーオールでの結果である。(IoUの定義は[6]参照)
-mean Average Precision(mAP)
IoUと同様にmAPの棒グラフと折れ線グラフを以下に示す。
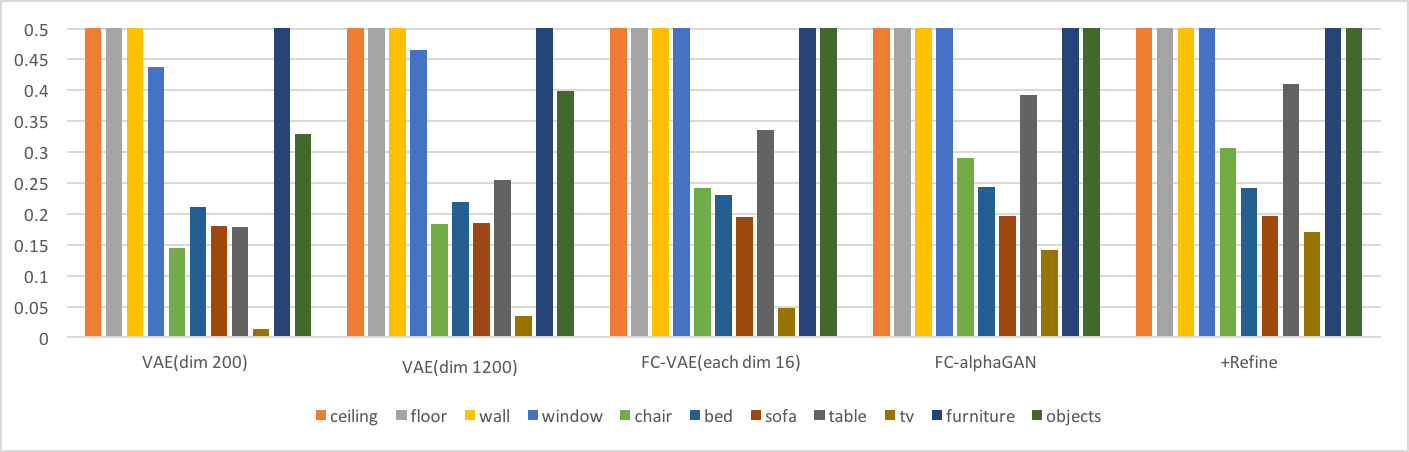
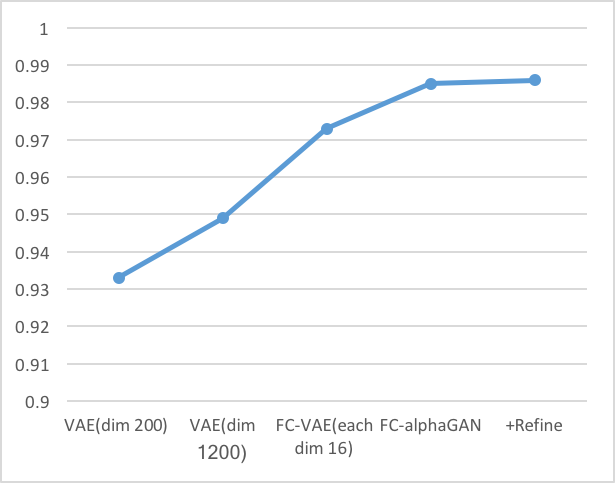
これらの結果より以下の考察ができる。
- 同じ潜在空間の次元数を持つVAE(dim1200)とFC-VAE(each dim16)の比較からわかるように、Fully Convolutionは再構成性能を向上させている。
- AlphaGAN構造が再構成性能の向上に貢献している。
Evaluations
Interpolation
Interpolation(潜在空間の遷移)の結果を以下に示す。(遷移のgif画像はトップに示している)
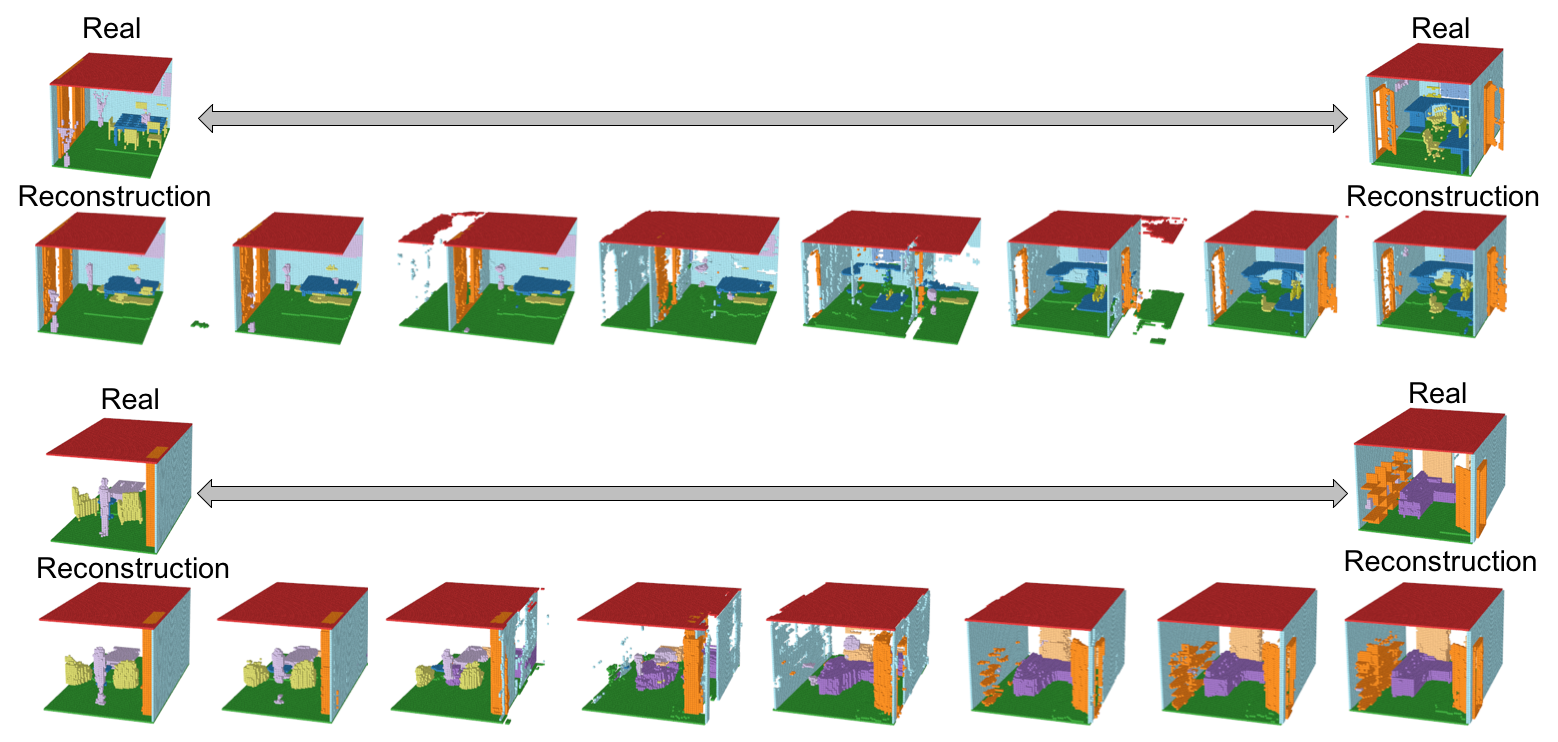
シーン間の潜在空間の遷移は、流れるように移行している。ただし、遷移間のシーンも意味のあるシーンとして保たれておらず、シーンが破壊されてしまっているため、本来期待したManifoldが作られているとは言い難い。マルチオブジェクトの難易度の高さが見て取れる。
Interpretation of latent space
以下に、エンコーダーによりエンコードされた200サンプルを、SVDにより2Dマップしたグラフを示す。プロットのグレースケールは、各シーンの重心座標をSVDにより1Dに落とした数値を示している。左がFully Convolution、右が1200次元の通常のVAEベクトルである。
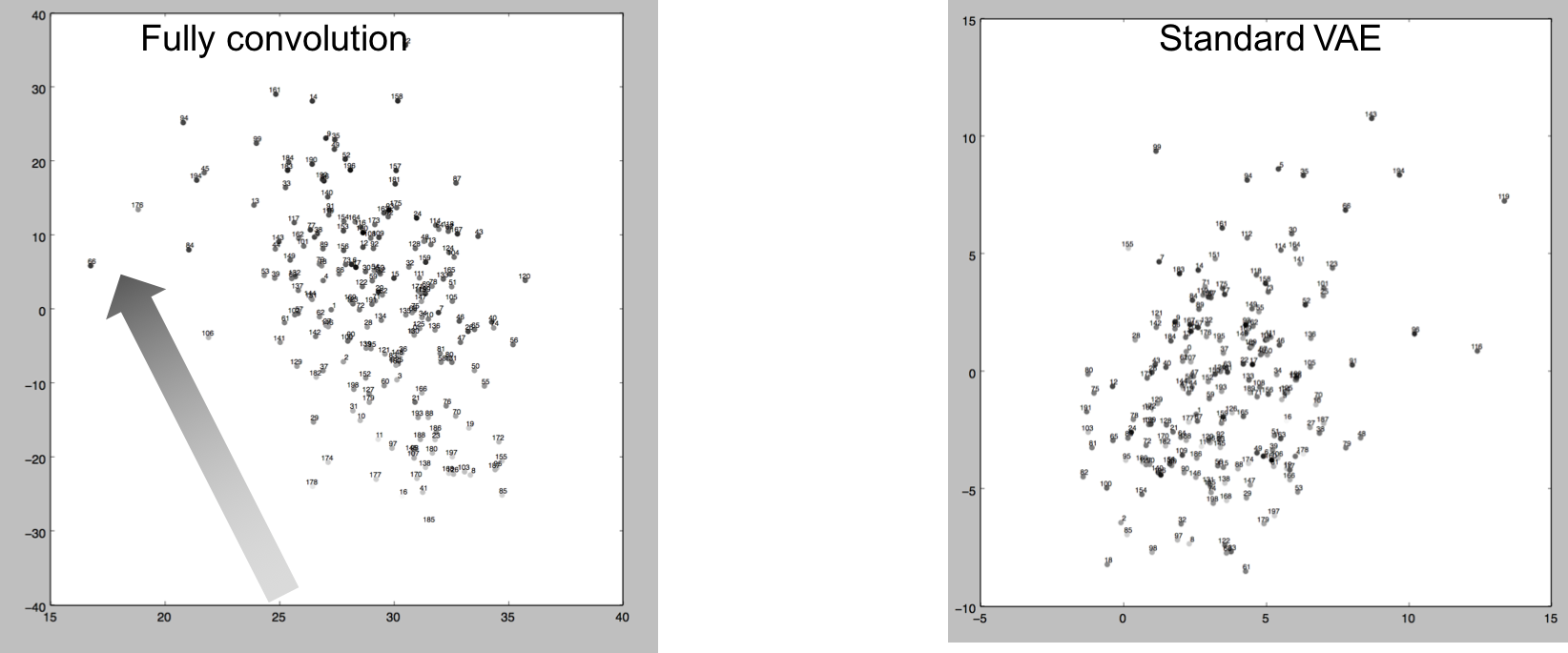
Fully Convolutionによる分布は、重心座標の1Dエンべディングに習って、右下から左上へ繊維していることがわかる。これは、Fully Convlution構造による潜在空間が通常のVAEと比べて空間的な意味合いに関係付けられていることを意味している。
以下の図は、5x3x5の潜在空間の各次元の影響を表現している。個々の次元に標準分布のノイズを与えて、それが生成されたシーンへ及ぼす影響を、赤色の濃度で表現している。
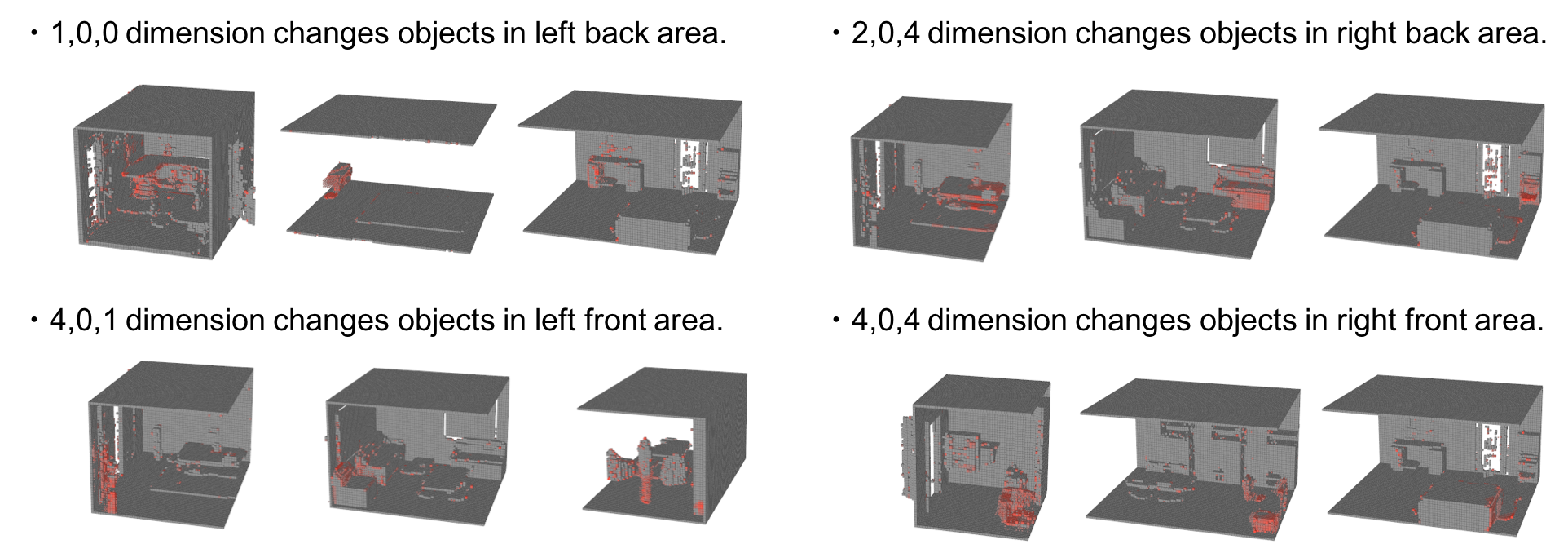
この結果より、潜在空間の各次元が生成されるシーンの特定の位置に集中して変化させていることを意味しており、Fully Convolution構造が空間的な情報を潜在空間に表現していることを示している。
Suggestions of future work
-Revise the dataset
前述した通り、このデータセットは非常にスパースで、たくさんのシーンの種類が存在している。床や小さい構造は様々な位置に配置されており、椅子の足のような小さいパーツはダウンサイジングによって破壊されている。これらは潜在空間の予測を非常に難しくしている。
そのため、さらなる精度向上のためには、オブジェクトのポジションの調整や、種類の限定、ダウンサイジングの方法の変更など、データセットを再考することが必要と考えられる。
-Redefine the latent space
今回は、潜在空間を形状やオブジェクトの位置など全ての情報を含む1つの空間として定義した。そのため、いくつかの小さいオブジェクトは生成モデルでは消えてしまうことも多く、たくさんのリアリティに欠けるオブジェクトが生成された。これを解決するために、レイアウトと各オブジェクトの情報を潜在空間として分割するなど、潜在空間の再定義が重要と考えられる。ただし、1つのオブジェクトクラスの中でも、1つのシーンに複数のオブジェクト種類があったり、オブジェクトの個数の増減を考慮する必要が出てくるため、クラス間の文脈の考慮も必要であると考えられ、課題である。
References
[1]Jiajun Wu, Chengkai Zhang, Tianfan Xue, William T. Freeman, Joshua B. Tenenbaum; Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling; arXiv:1610.07584v1
[2]Andrew Brock, Theodore Lim, J.M. Ritchie, Nick Weston; Generative and Discriminative Voxel Modeling with Convolutional Neural Networks; arXiv:1608.04236v2
[3]Shuran Song, Fisher Yu, Andy Zeng, Angel X. Chang, Manolis Savva, Thomas Funkhouser; Semantic Scene Completion from a Single Depth Image; arXiv:1611.08974v1
[4]Mihaela Rosca, Balaji Lakshminarayanan, David Warde-Farley, Shakir Mohamed; Variational Approaches for Auto-Encoding Generative Adversarial Networks; arXiv:1706.04987v1
[5]Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda Wang, Russ Webb; Learning from Simulated and Unsupervised Images through Adversarial Training; arXiv:1612.07828v1
[6]Christopher B. Choy, Danfei Xu, JunYoung Gwak, Kevin Chen, Silvio Savarese; 3D-R2N2: A Unified Approach for Single and
Multi-view 3D Object Reconstruction; arXiv:1604.00449v1
以上でした。
2016~2017年当時、DCGANが有名になり、mode collapseの問題がいまだ大きな課題で、毎日のようにGAN関連論文が出て手法がアップデートされていました。GANへの理解も乏しい中で、色々あって3Dのマルチオブジェクトの生成モデルというテーマに挑戦したのですが、想像していた以上に難易度が高く、後から思い返すと「こうしておけばよかった」と後悔することも多いのです。(初めはノイズしか生成されてこなくて、どうしようかと思っていました。) この研究はまだまだ課題も多く、志半ばで終了してしまいましたが、GANや生成モデルについて実践的で最高の経験でした。