この記事は、NTTコミュニケーションズ Advent Calendar 2019の22日目の記事です。
昨日は @kanatakita さんの記事、アプリケーションのリリースに必要な会議を倒したい話 でした。
はじめに
こんにちは、NTTコミュニケーションズのSkyWayチームに所属しているyuki uchidaです。
本記事は、BERTを理解しながら自分のツイートを可視化してみるハンズオンに続いて『可視化したい』シリーズ第二弾です。
プライベートでSpotifyのAPIを叩いていたところ、個人的な興味範囲であるリコメンドシステムに絡めて面白そうな可視化ができそうだと思ったため、この記事を書いています。
何をする記事?
Spotifyは業界最高峰のリコメンドシステムを提供していますが、そのリコメンド結果に疑問を持つことも多くあります。
今回、この記事では納得感のあるリコメンドを行うため、Spotifyの関連アーティストからネットワーク図を作って次に聞く曲の決定支援をします。(リコメンドの一種と言えるかもしれません)
pythonのコードも合わせて乗っけているため、自分でやってみたいと感じた方はぜひ試してみてください!!
Spotifyのリコメンドシステム
Spotifyでは、既に非常に精度の良いリコメンドシステムが実装されています。曲のテンポやジャンルなど、非常に多くの情報を使った上でリコメンドがなされています。
どれだけ多くの情報を使っているかはSpotify APIで取得できる情報を調べてみるとよくわかります。
Spotifyの76,000曲の属性データを分析した結果、J-RockはRockというよりむしろPunkだった
Spotifyのレコメンドロジックについて語り尽くす
Spotifyでは、以下のようにプレイリストからオススメの曲をリコメンドしてくれたり、好きそうなアーティストをプレイリストにしてくれたりします。
Spotifyは本当に素晴らしいリコメンドシステムを有しており、私はSpotifyのおかげで音楽が好きになりました。
オススメされる曲の多くが自分の感性に非常にマッチしていて、Spotifyがオススメしてくれる曲で一日過ごせるくらいにはSpotifyが好きです。一生課金します。
リコメンドシステムの精度指標
確かにSpotifyのリコメンドは優秀です。しかし、『どうしてこの曲をオススメしてきたか?』という疑問に答えられるようなシステムになっているわけではありません。そのため、Spotifyに限った話ではなく、今ある多くのリコメンドシステムは、『どうしてこの曲なのかはわからないけど結果的に好きな曲だった』となりがちなのです。
リコメンドシステムにおける議論
多くのリコメンドシステムにおいて、精度指標として、accuracyが使われることが多いです。
しかし、accuracyのみを精度指標とすることには議論が必要です。
Charu C Aggarwaは『リコメンデーションシステム』で、「accuracy(精度)だけでなく、diversity(多様性)、serendipity(意外性)、Novelty(新規性)などの指標からも評価するべき」と述べています。
リコメンドシステムにおいては、accracyのみを精度指標にしてしまうと、リコメンドするものが有名なものに限られてしまって面白みに欠けるという問題が産まれてしまいます。そのため、他の指標を使うことも重要です。
リコメンドシステムの最近の流れ
最近では、accuracyではなくupliftを精度指標とすることでリコメンドの精度を高めたという論文も発表されました。
リコメンドの精度指標は数多くあり、非常に興味深い議論が多くなされています。
以下の記事ではUplift-based Evaluation and Optimization of Recommendersという論文をわかりやすく解説しているので、ぜひ参考にしてください。(こちらのメディアでもたまに記事を書いています)
そのリコメンド、本当に効果ありますか?accuracyではなくupliftで学習することでリコメンドは進化する。
現在Spotifyで提供されているリコメンドシステムは、どのような精度指標が用いられているかわからないため、今回は、アーティストの関連度から、多様性を求めてリコメンドをしてもらうか、好きなタイプのアーティストを深掘りしていくか自身で決定できるようにしたいと思います。
アーティストの関連度をネットワーク図として表現し、自身が聴いてる曲をプロットする
アーティストの関連度から、多様性を求めてリコメンドをしてもらうか、好きなタイプのアーティストを深掘りしていくか自身で決定できるようにするため、ネットワーク図と自身の聴いているアーティストをプロットしたものを用意します。
SpotifyAPIを使って関連アーティストをdigってネットワーク図を構築する
まずは必要なライブラリのimportを行います。
import pandas as pd
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import json
import networkx as nx
import matplotlib.pyplot as plt
次に、SpotifyAPIに接続するためのインスタンスを生成し、spotifyという変数に格納します。
client_id = 'XXXXXXXXXXXXXXX'
client_secret = 'XXXXXXXXXXXXXXX'
client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret)
spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
以下のSpotifyのトップチャートから、人気な邦楽リストをcsvとしてダウンロードしてきましょう!
https://spotifycharts.com/regional/jp/weekly/latest
そしてそのcsvを読み込みます。
top_records = pd.read_csv("regional-jp-weekly-latest.csv", header=1)
top_artists = top_records["Artist"].unique()
ここからはpandasのDataFrame整形のための処理のため、流して読んでください
artist_info_list = []
for artist in top_artists:
artist_info_list.append(spotify.search(q='artist:' + artist, type='artist'))
artist_info_list = [artist_info['artists']['items'] for artist_info in artist_info_list]
artist_info_list = [artist_info[0] for artist_info in artist_info_list if len(artist_info) > 0]
## 情報がないものはスキップ
artist_info_df = pd.DataFrame(artist_info_list)
artist_info_df = artist_info_df[['genres','id','name','popularity','type']]
followers = [artist_info_record['followers']['total'] for artist_info_record in artist_info_list]
artist_info_df['followers'] = followers
artist_info_df
csvを読み込んで整形した後、SpotifyAPIを用いて、関連アーティストをdigって行きます。再帰関数として実装して、何回digるかを決定します。今回は5回digります。これでもデータ量としては万を軽く越えるため、ご注意ください。
related_artist_info = []
digged_artist_ids = []
def dig(parent_id,parent_name,limit,i):
digged_artist_ids.append(parent_id)
# print(parent_name)
if len(related_artist_info) % 1000 == 0:
print(len(related_artist_info))
related_artists = spotify.artist_related_artists(parent_id)
for artist_info in related_artists['artists']:
artist_info['parent_id'] = parent_id
artist_info['parent_name'] = parent_name
related_artist_info.append(artist_info)
if i < limit:
if artist_info['id'] in digged_artist_ids:
pass
else:
dig(artist_info['id'],artist_info['name'],limit,i+1)
for parent_id,parent_name in zip(artist_info_df['id'],artist_info_df['name']):
dig(parent_id,parent_name,limit=6,i=1)
related_artist_df = pd.DataFrame(related_artist_info)
related_artist_df = related_artist_df[['genres','id','name','popularity','type','parent_id','parent_name']]
followers = [artist_info_record['followers']['total'] for artist_info_record in related_artist_info]
related_artist_df['followers'] = followers
related_artist_df
## 親アーティストのparent_idをnullに
artist_info_df['parent_id'] = None
artist_info_df['parent_name'] = None
merge_df = pd.concat([artist_info_df,related_artist_df],sort=False)
ここで、ネットワーク図を作るために、関連アーティストとして出てきたアーティストのペアを作成しておきます。
graph_tuple = []
for network in merge_df[['name','parent_name']].values:
graph_tuple.append(tuple(network))
では次に、自身が聴いているアーティスト群を用意しましょう。
Spotifyと接続するためのインスタンスに、usernameとplaylist_idを与えてあげます。
import sys
import pprint
import spotipy
import spotify_token as st
client_id = 'XXXXXXXXXXXx'
client_secret = 'XXXXXXXXXXX'
client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret)
spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
username = "XXXXXXXXX"
playlist_name = "XXXXXXXXXXXX"
my_tracks = spotify.user_playlist(username, playlist_id=playlist_name, fields=None)
my_track_list = [track['track'] for track in my_tracks['tracks']['items'] ]
my_track_df1 = pd.DataFrame(my_track_list)
my_track_df1['artists'] = [artists[0]['name'] for artists in my_track_df1['artists']]
ここから、ネットワーク図を作るために、networkxというライブラリを用いて行きます。
おそらく、現在graph_tupleに格納されている関連アーティストのペアは、非常にデータ数が多く、まともに表示できないと思われるので、関連アーティストが少ないアーティストに関しては枝切りしていきます。また、その中で自身が聴いているアーティストに関しては枝切りしないようにしておきましょう。ここは実行にかなり時間がかかるため、数分ほど待ちましょう
G = nx.Graph()
G.add_nodes_from(merge_df['name'].unique())
G.add_edges_from(tuple(graph_tuple))
like_artists_name = set(track_df['artists'].unique())
for i in range(3,1,-1):
remove_nodes = G.degree()
if i == 1:
print(remove_nodes)
remove_node_names = [node[0] for node in remove_nodes if node[1] < 15*i]
## 自分のプレイリストに入ってるアーティストは消さない
remove_node_names = set(remove_node_names) - like_artists_name
G.remove_nodes_from(remove_node_names)
# グラフの構築
# G = nx.karate_club_graph()
G = nx.Graph()
G.add_nodes_from(merge_df['name'].unique())
G.add_edges_from(tuple(graph_tuple))
like_artists_name = set(track_df['artists'].unique())
for i in range(3,1,-1):
remove_nodes = G.degree()
if i == 1:
print(remove_nodes)
remove_node_names = [node[0] for node in remove_nodes if node[1] < 10*i]
## 自分のプレイリストに入ってるアーティストは消さない
remove_node_names = set(remove_node_names) - like_artists_name
G.remove_nodes_from(remove_node_names)
## 1以下のやつは中心から離れ過ぎてしまっている可能性が高いので削除
remove_nodes = G.degree()
remove_node_names = [node[0] for node in remove_nodes if node[1] <= 3]
G.remove_nodes_from(remove_node_names)
# レイアウトの取得
pos = nx.spring_layout(G)
pr = nx.pagerank(G)
# 可視化
plt.figure(figsize=(100, 100))
# nx.draw_networkx_edges(G, pos)
nx.draw_networkx_nodes(G, pos, node_size=[75000*v for v in pr.values()], node_color=list(pr.values()), cmap=plt.cm.Reds)
# nx.convert_node_labels_to_integers(G, first_label=0, ordering='default', label_attribute=None)
add_artists_nodes = G.degree()
add_artists_names = [node[0] for node in add_artists_nodes]
like_artists_nodes = set(add_artists_names) & like_artists_name
nx.draw_networkx_nodes(G,pos,
nodelist=like_artists_nodes,
node_color='b',
node_size=1500,
label=like_artists_nodes,
alpha=0.5)
labels = {}
for node in G.degree():
labels[node[0]] = node[0]
nx.draw_networkx_labels(G, pos,font_size=10)
# nx.draw_networkx_labels(G, pos, labels, font_size=8)
plt.savefig('figure.png',format = 'png', dpi=300)
plt.show()
プロット結果を使って次に聴く曲の決定
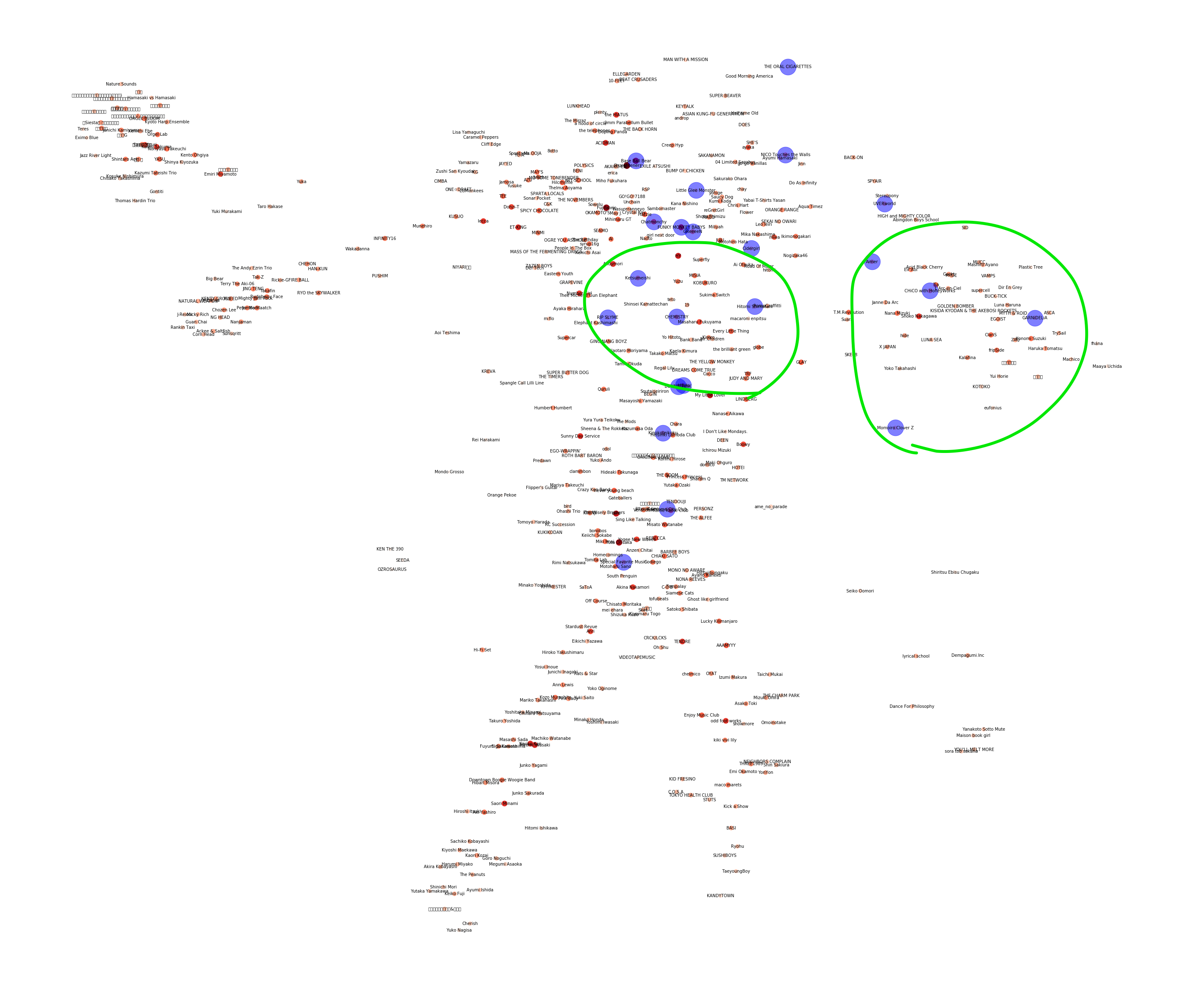
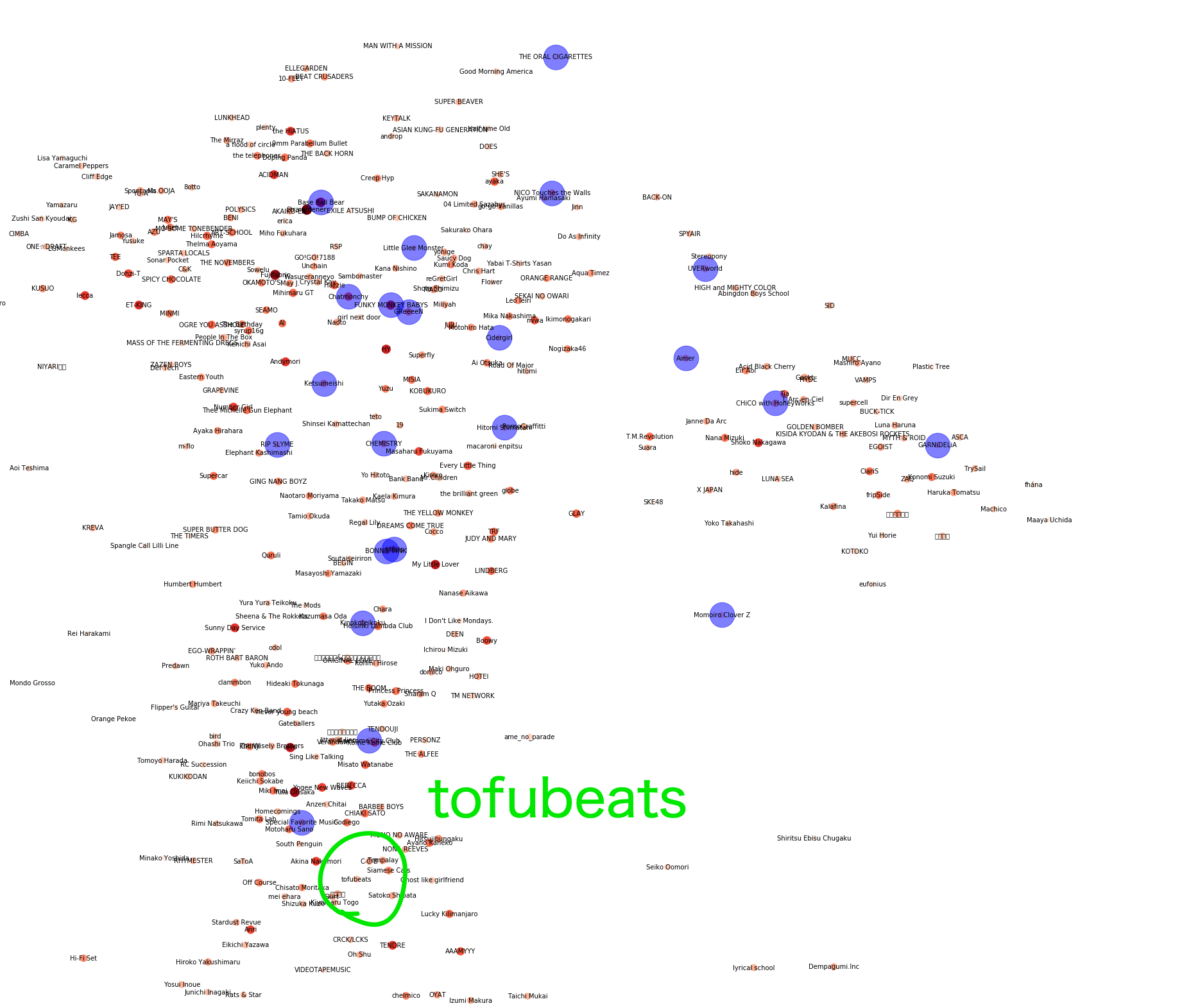
今回、トップチャートからdigったアーティストのネットワーク図と、自身のプレイリストをプロットしたものは以下のようになりました。この図をみると、どのようなアーティストが同じような場所にあり、自分がどのアーティストを聴いているかがよくわかりますね!!!!

私は基本的にSpotifyがオススメした曲を聴いてプレイリストに追加するという流れが多いため、この図から、右上の方に位置しているアーティストをよく聴いていることがわかります。
その中から、わかりやすいアーティスト群をピックアップして見てみましょう。
今回、『わかりやすくて面白いなー』と感じた二つの領域(アーティスト群)を紹介します。
まず、左のアーティスト群はこのように表示されています。
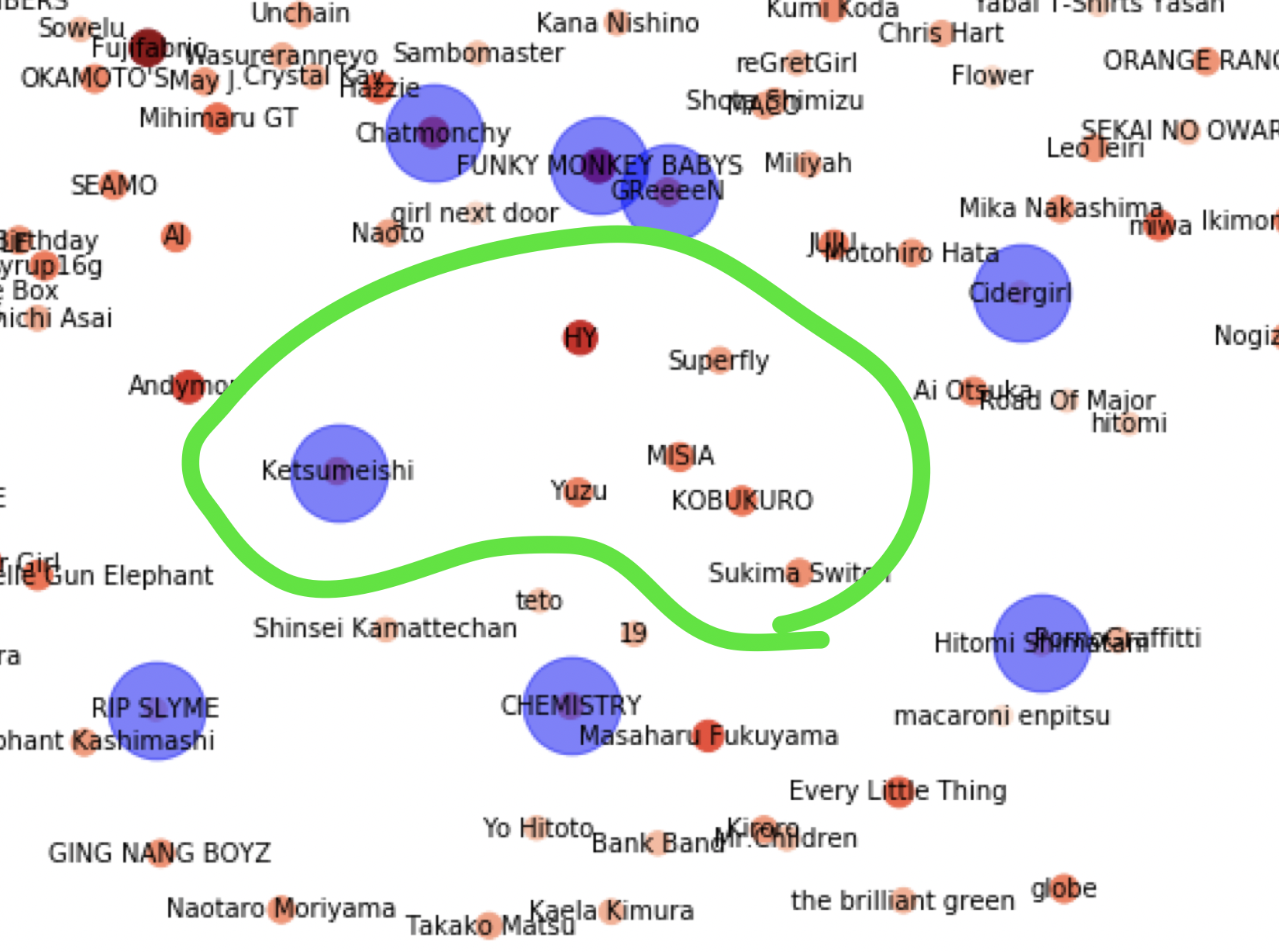
ゆずやコブクロ、ケツメイシが同じような場所にあるのはすごく納得感がありますね。僕はこの辺りのアーティストが好きなことはプロット結果からわかっているので、この辺りのアーティストを埋めるようにオススメするのがいちばん分かりやすいリコメンドだと思います。
また、右側のアーティスト群はこのようになっています。

この辺りは女性アーティストが集まっているように見えますね。
また、その中でもアニソン系が集まっていそうです。(Craris/EGOIST/fripsideなど)
僕はこの辺りのアーティストを少しだけ聴いているため、周辺のアーティストをオススメすると良いかもしれません。
まとめ
このように、アーティスト群をネットワーク図として表示することで、自身がどのようなタイプのアーティストが好きなのかよく分かります。
また、ネットワーク図を参照することで次どのようなアーティストを聞くかの決断を支援することができます。
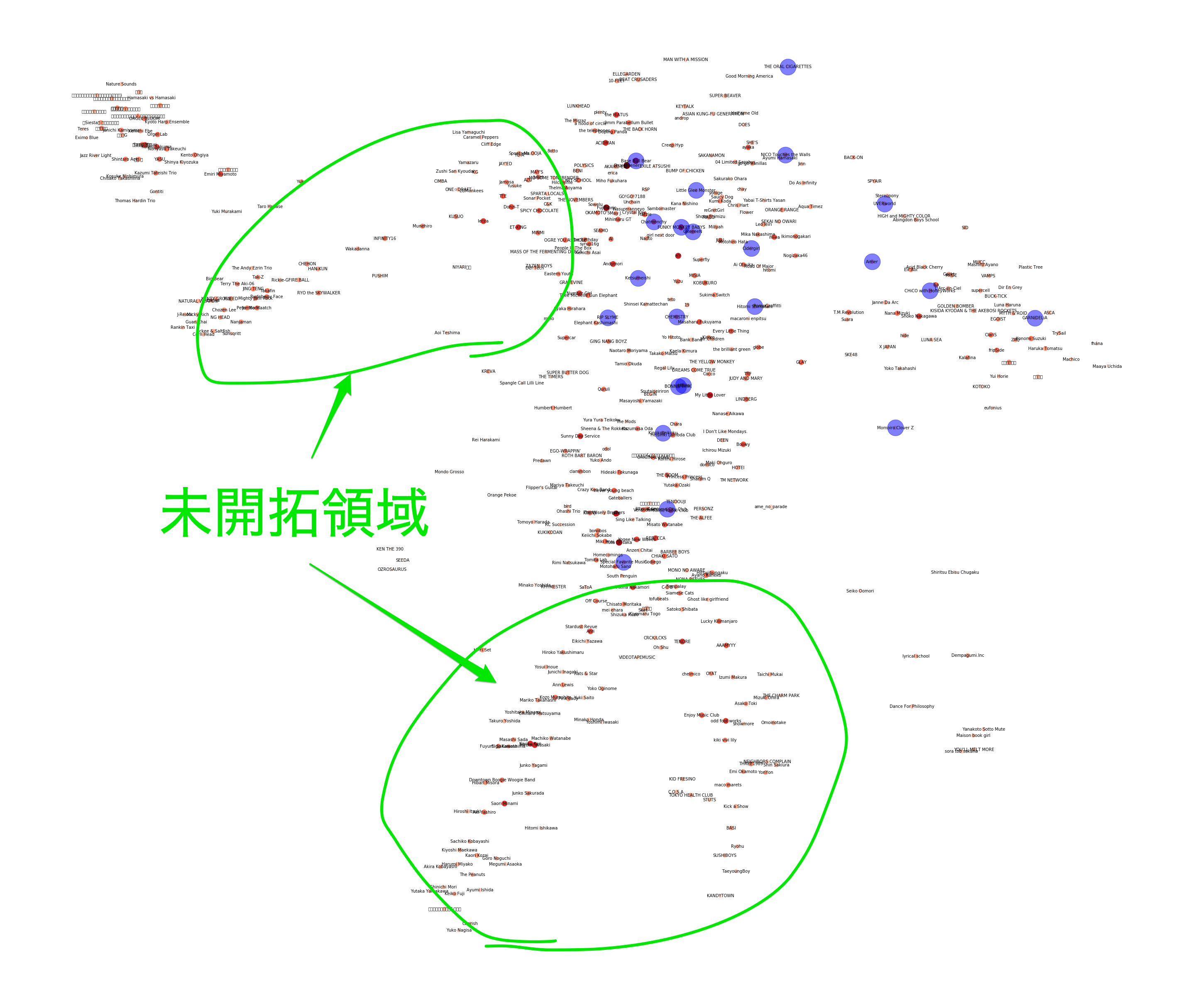
ネットワーク図では、左側の領域や下の領域は一切聴いていない未開拓領域です。自分が好きなタイプのアーティストを深掘りしていくのも面白いですが、このように多様性を求めて全く聴いていないアーティストを聴いてみるのも楽しいですね。
とりあえず、自分の好きなアーティストに近く、未開拓領域の方向に位置しているアーティスト として、今回はtofubeatsさんを聴いてみようかと思います。
個人的に実装したいもの
リコメンドでは、『自身がどのようなアーティストを聞きたいか』ではなく、『自身が好きそうなアーティスト』をオススメされるため、受動的なシステムになっていることが多いです。
しかし、このようにネットワーク図を用いたリコメンドでは、『多様性を求めて未開拓領域に進むのか』『好きなタイプのアーティスト深掘りしていくのか』ということを自分で決められます。
こういった、アシスト寄りのリコメンドシステムがあっても良いのではないかと思いました。
次は、このネットワーク図を用いて実際にリコメンドシステムを提供できるようにシステム構築を頑張ってみます。(Chrome拡張か、webアプリで)
完成したらぜひご利用ください!!
それではこの辺りで僕の記事は終わりにします。
明日は、 @__kaname__ さんの記事です。お楽しみに!