この記事は、NTTコミュニケーションズ Advent Calendar 2019の13日目の記事です。
昨日は @nitky さんの記事、俺たちは雰囲気で脅威インテリジェンスを扱っている でした。
はじめに
こんにちは、NTTコミュニケーションズのSkyWayチームに所属しているyuki uchidaです。
本記事では、最近Google検索にも適用されたという、自然言語処理に用いられる言語モデルBERTを使って自分のツイートを可視化してみる記事です。
出来るだけ多くの人に試して頂けるように、ハンズオン形式で書いていきますので、興味が湧いた方は是非試してみてください。
BERTって何?
BERTとは、2018年にGoogleから発表された自然言語モデルのことで、多くの自然言語タスクにおいてインパクトのある精度を叩き出しました。この精度が驚異的であったため、自然言語処理界隈では大きく知名度を得ました。
(ちなみに、自然言語処理界隈では、2014年にWord2Vecという自然言語モデルが発表され、大きく騒がれましたが、こちらもGoogle発の論文です。)
このBERTの詳細に関しては、既に多くの方が解説して下さっているため、いくつかリンクを貼っておきます。
汎用言語表現モデルBERTを日本語で動かす(PyTorch)
汎用言語表現モデルBERTの内部動作を解明してみる
今回は、このBERTを使って何が出来るのか?ということを直感的に理解するため、以下のサイトを開いてみましょう!
このサイトは、huggingfaceが提供しているtransformers(旧pytorch-pretrained-bert)というライブラリをオンラインで試す事ができます。
今回は、BERTと同じ言語モデルである、gpt を選択してデモを行ってみましょう。
選択すると、以下のような、文章が入力できるWordのような画面に切り替わります。
この状態で、何か文章を入力したのち、tabボタンを押してみましょう。
そうすると文章が三つ候補として表示される事がわかるかと思います。この文章を選択すると文章に追加されていきます。
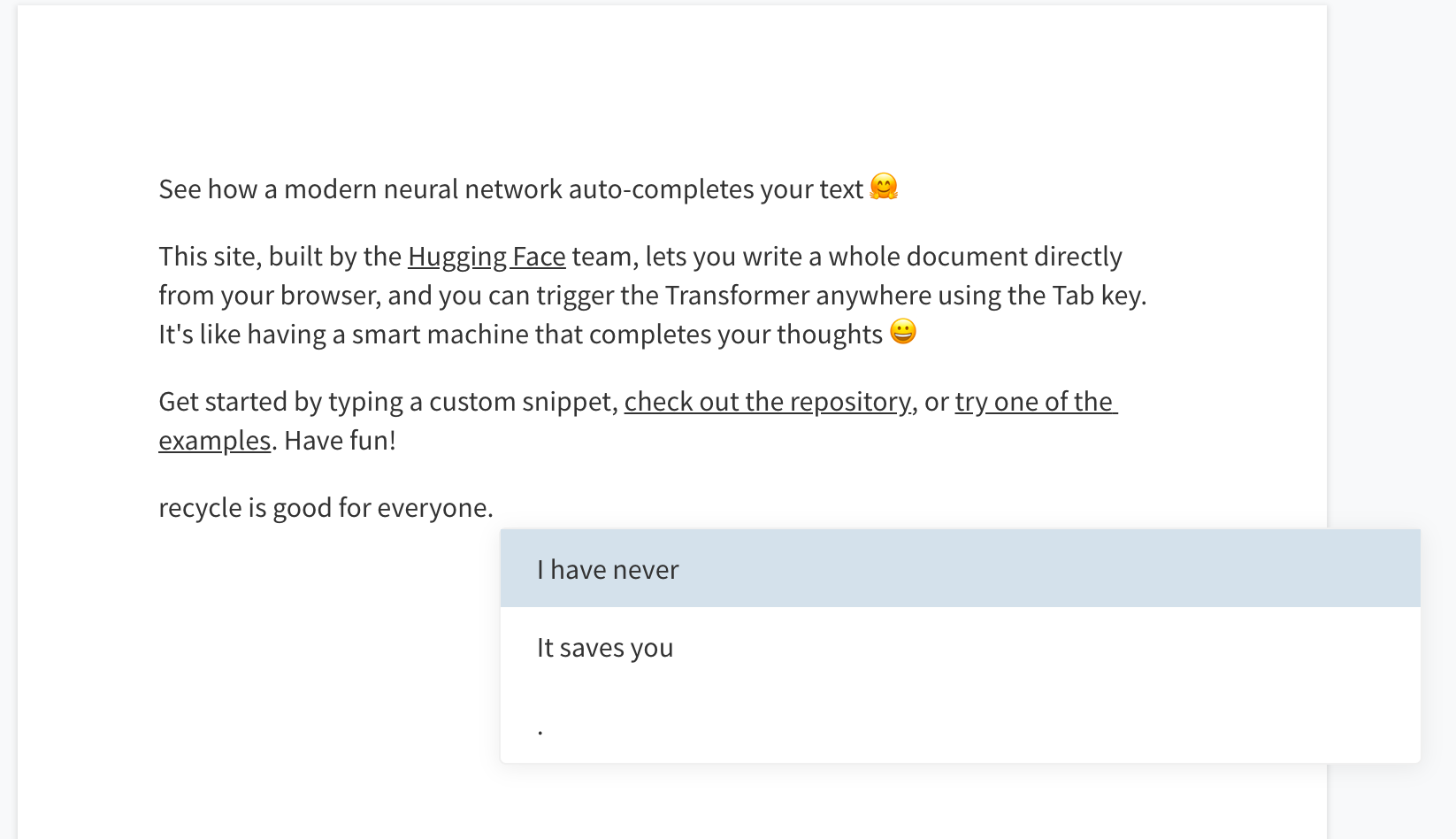
このデモは、文章生成 を試せるものです。
文章生成は自然言語処理界隈では長く研究されてきた技術です。自然言語モデルを用いて、テキスト情報を上手くコンピューターに理解させられるようになった事で、このように自然な文章生成ができるようになりました。
このまま、何回か文章生成をしてみると、なかなか面白い結果になります。
I have never met anyone who did not find it useful or useful for others . It was originally released as an open source project
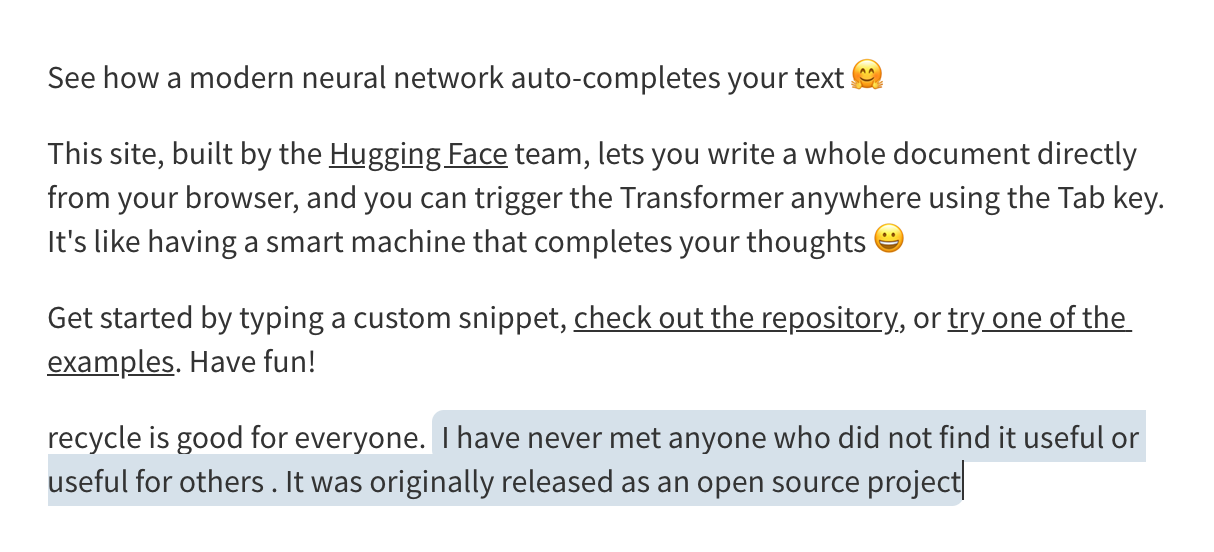
(伝わりそうで伝わらない文章ですね(笑)
今回このデモサイトで選択したのはGPTというモデルですが、この後継となるGPT2というモデルは、提唱元のOpenAIが悪用を懸念し、一時期モデルを非公開にしていました。(現在は公開され、デモサイトで試すこともできます)
Techcrunch: OpenAIは非常に優れたテキストジェネレータを開発したが、そのままリリースするのは危険すぎると考えている
このように、より良い自然言語モデルは、多くの自然言語処理のタスクの精度を向上させます。
transformersのインストール
pytorch-pretrained-bertからtransformersへと名前を変えた、huggingfaceのライブラリを使用します。
先ほど使ったデモサイトは、このtransformersのオンラインデモになります。
こちらのライブラリを用いることで、pytorch(or tensorflow)と組み合わせて簡単にBERTを呼び出すことができます。
今回のハンズオンでは、transformersではなくpytorchを使用してBERTを呼び出すことにします。
まだpytorchとtransformersをインストールしていない方は以下のコマンドでインストールしましょう。
pip install torch torchvision
pip install transformers
BERTの英語学習済みモデルを使って、隠れている単語をズバリ当ててみる
今回は、日本語に対応しているBERTモデルを引っ張ってきます。
英語でよければ特に準備は必要なく、以下のコードで読み込む事ができます。
model = BertForMasked.from_pretrained('bert-base-uncased')
日本語学習済みモデルを使うには、少し手間がかかる為、一度日本語学習済みモデルを使う前に、簡単に呼び出せるBERTの英語学習済みモデルを使ってみましょう。
まずは、必要なライブラリをimportします。test.pyを作り、以下のように記述しましょう。
import torch
from transformers import BertTokenizer, BertForMaskedLM
import numpy as np
次に、簡単な英語の文章をなんでもいいので設定しましょう。
text = "How many lakes are there in Japan."
では、BERT専用の分かち書きツールBertTokenizerを使って単語分割を行いましょう。
以下のコードを貼り付けましょう。
単語ごとに分割する分かち書きは、コンピューターがどこで単語ごとに区切れるかどうか判断するために必要な処理になります。
(英語では基本的にスペースで区切るだけで単語ごとに分割する事ができます。)
(注: 先頭と末尾を[CLS] [SEP]で囲うようにしましょう。)
## ライブラリをimportする段階で、BertTokenizerも合わせて読み込んでいる
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
tokenized_text = tokenizer.tokenize(text)
tokenized_text.insert(0, "[CLS]")
tokenized_text.append("[SEP]")
# ['[CLS]', 'how', 'many', 'lakes', 'are', 'there', 'in', 'japan', '.', '[SEP]']
これによって、単語ごとに分割する事ができました。
次に隠したい単語を選んでください。BERTはその単語をズバリ当ててみせるでしょう。
今回、私はareを隠してみたいと思います。この単語を[MASK]に置き換える処理を記述しましょう。
masked_index = 4
tokenized_text[masked_index] = '[MASK]'
# ['[CLS]', 'how', 'many', 'lakes', '[MASK]', 'there', 'in', 'japan', '.', '[SEP]']
これにより、areは見事**[MASK]**に置き換わりました。これでここにある単語が何かわからなくなりました。
では、BERTにこのテキストを与え、**[MASK]**となっている単語を予測してもらいましょう!!!
## テキストのままBERTに渡すのではなく、辞書で変換し、idになった状態にする。
tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
tokens_tensor = torch.tensor([tokens])
## BERTを読み込む。ここで少し時間がかかるかもしれない
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
model.eval()
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
## masked_indexとなっている部分の単語の予測結果を取り出し、その予測結果top5を出す
_, predict_indexes = torch.topk(predictions[0, masked_index], k=5)
predict_tokens = tokenizer.convert_ids_to_tokens(predict_indexes.tolist())
print(predict_tokens)
# ['are', 'were', 'lie', 'out', 'is']
結果、隠された単語を予測した結果、TOP5が['are', 'were', 'lie', 'out', 'is']となりました。この結果からわかるように、BERTは隠された単語をズバリ当てる事ができました。 凄いですね!
今回は、BertForMaskedLMを使い、隠された単語を予測してみました。他にも簡単に試せるものとして以下のようなものがあります。ぜひ試してみてください。
- BertForNextSentencePrediction
- BertForSequenceClassification
- BertForTokenClassification
- BertForQuestionAnswering
BERTの日本語学習済みモデルを引っ張ってくる
それでは、ここからが本番です。
自分のツイートをBERTを使って、どのようなタイプのツイートをしているか可視化してみます
まず、日本語に対応しているBERTを準備します。
本来、BERTの事前学習も自前で行いたいところですが、BERTは学習に非常に時間がかかってしまいます。
そこで、学習済みモデルを配布してくれている、京都大学黒橋・河原研究室様のHPにアクセスしてモデルをダウンロードしましょう。
BERTの学習には30日程度かかってしまうようなので、このように公開していただけると気軽に試せるので本当にありがたいですね・・・
30 epoch (1GPU (GeForce GTX 1080 Tiを利用)で1epochに約1日かかるのでpretrainingに約30日)
ダウンロードしてきたファイルを解凍し、pythonファイルと同様の場所に置きましょう。(以下のようにbertフォルダを作ってそこに格納すると良いです)
import torch
from transformers import BertTokenizer, BertModel, BertForMaskedLM
import numpy as np
model = BertModel.from_pretrained('bert/Japanese_L-12_H-768_A-12_E-30_BPE_transformers')
bert_tokenizer = BertTokenizer("bert/Japanese_L-12_H-768_A-12_E-30_BPE_transformers/vocab.txt",
do_lower_case=False, do_basic_tokenize=False)
ここで、一度BERTのモデルが使えるかどうか、試してみましょう。
日本語対応BERTで隠れている単語をズバリ当ててみる
先ほど行ったコードをそのまま流用したいところなのですが、今回は英語ではなく日本語を扱うため、BertTokenizerによる分かち書きができません。(単語をidに置きかえる辞書機能は使うので、上記のように、一応読み込みます)
今回はJumanを用いて分かち書きを行い、単語分割を行いましょう。
jumanを扱うためにはpip installが必要なため、以下のコマンドを打ち、インストールします
pip install pyknp
インストールができたので、このJumanを用いてわかち書きをして単語分割をしましょう。
対象とする文章は、英語で行った時と同様に、僕は友達とサッカーをすることが好きだとします。
from pyknp import Juman
jumanpp = Juman()
text = "僕は友達とサッカーをすることが好きだ"
result = jumanpp.analysis(text)
tokenized_text = [mrph.midasi for mrph in result.mrph_list()]
# ['僕', 'は', '友達', 'と', 'サッカー', 'を', 'する', 'こと', 'が', '好きだ']
ここからは英語版と同様の処理で予測を行います。
tokenized_text.insert(0, '[CLS]')
tokenized_text.append('[SEP]')
masked_index = 5
tokenized_text[masked_index] = '[MASK]'
print(tokenized_text)
# ['[CLS]', '僕', 'は', '友達', 'と', '[MASK]', 'を', 'する', 'こと', 'が', '好きだ', '[SEP]']
tokens = bert_tokenizer.convert_tokens_to_ids(tokenized_text)
tokens_tensor = torch.tensor([tokens])
model.eval()
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
_, predict_indexes = torch.topk(predictions[0, masked_index], k=5)
predict_tokens = bert_tokenizer.convert_ids_to_tokens(predict_indexes.tolist())
print(predict_tokens)
# ['話', '仕事', 'キス', 'ゲーム', 'サッカー']
日本語版BERTで"僕は友達とサッカーをすることが好きだ"のサッカーを隠して予測してみたところ。['話', '仕事', 'キス', 'ゲーム', 'サッカー']となりました。
サッカーが1位ではありませんでしたが、他の答えも正しいと感じる事ができますね。
ここで日本語版BERTを動くことを確認できました。
自分のツイートの準備
それでは、可視化するためのツイートを準備します。
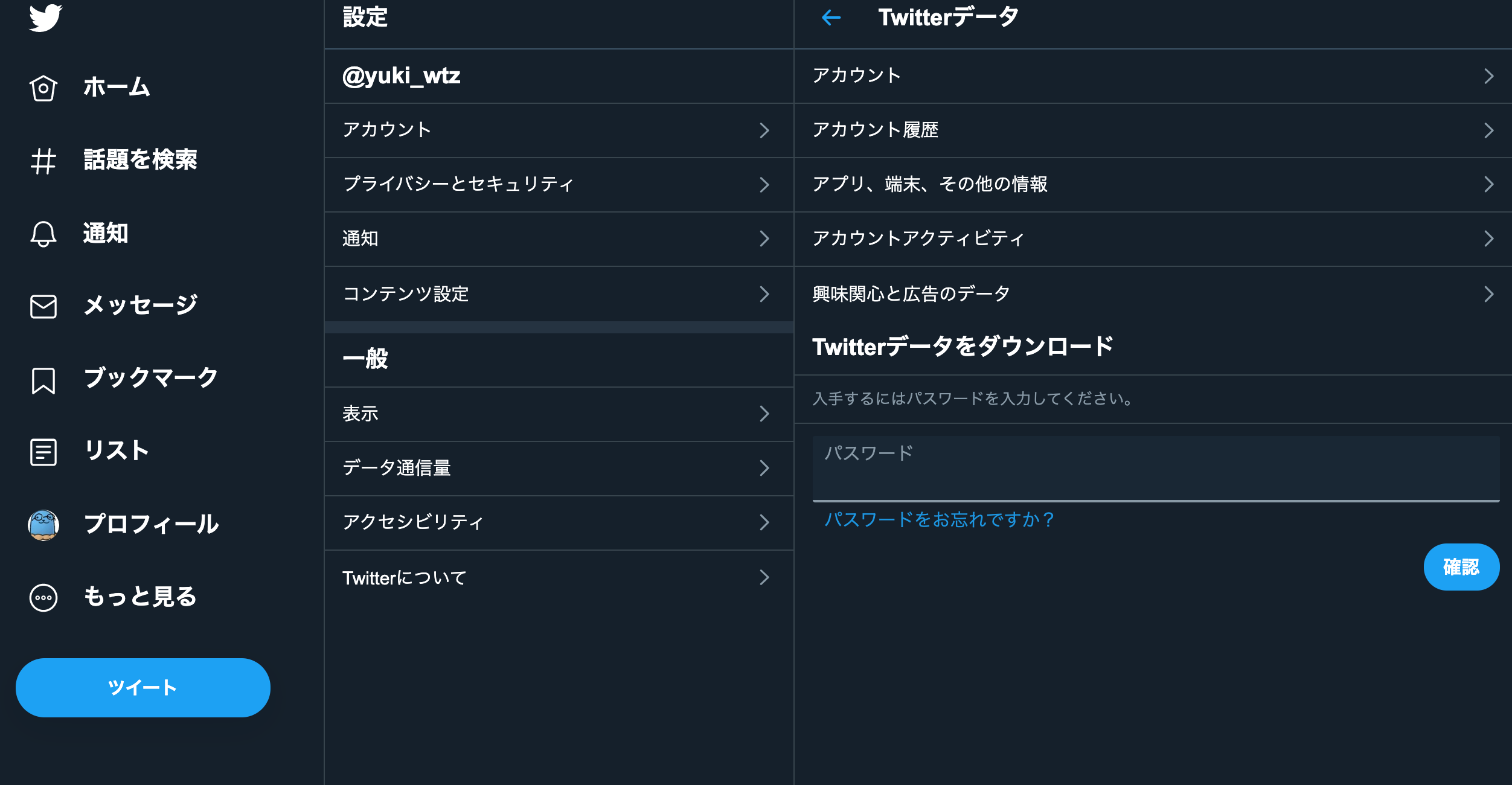
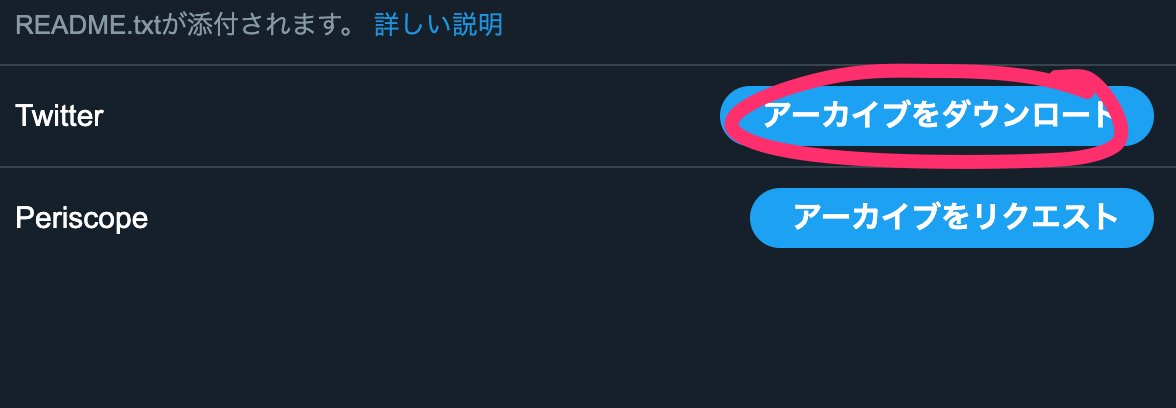
以下のページにアクセスして、Twitterデータ をクリックしてください。
https://twitter.com/settings/account
以下のような画面なったら、パスワードを入力した後、アーカイブをリクエストを押してください。
準備が完了し、メールがくるとアーカイブをダウンロードに変化し、ダウンロードできるようになります。
ダウンロードが完了したら、解凍して中身を確認しましょう。以下のように。大量のJavascriptファイルと、tweet.jsが存在すればOKです。

自分のツイートのcsvへの変換
現在のツイート履歴は、全てtweet.jsに格納されており、少々扱いずらいため、csvに変換しましょう。
以下のサイトでtweet.jsをcsvに変換する事ができます。
ただし、このサイト内に記述されているように、このツールを使うのに不安がある方は別の方法でcsvに変換しましょう。
Twitterデータの tweet.js を読み込んで全ツイート履歴を表示するツール「tweet.js loader」を作った


CSV出力ボタンをクリックし、CSVをダウンロードしましょう。
csvへの変換が完了し、ダウンロードできたらOKです。(tweets.csvという名前にしておきましょう)
ツイートを文章ベクトルに変換する
それでは、BERTをでこのtweets.csvのツイートを文章ベクトルに変換します。
文章ベクトルとは、その文章をベクトル化したものです。
BERTが変換した文章ベクトルを可視化ツールに注ぎ込む事で、どのようなツイートが発言されているのかを確認してみましょう。
import pandas as pd
import re
tweets_df = pd.read_csv("./tweets.csv")
tweets_df["text"] = tweets_df["text"].astype(str) #一応文字列にしておく
## 文章ベクトル変換後にその結果を格納するための配列と、元のツイートを保存しておくための配列を宣言する
vectors = []
tweets = []
for tweet in tweets_df["text"]:
tweet = re.sub('\n', " ", tweet) #改行文字のの削除
strip_tweet = re.sub(r'[︰-@]', "", tweet) #全角記号の削除
try:
if len(strip_tweet) > 3: #単語数が少なすぎると適切なベクトルが得られない可能性があるため
vector = compute_vector(
strip_tweet, model, bert_tokenizer, juman_tokenizer)
vectors.append(vector)
tweets.append(tweet)
except Exception as e:
continue
## 文章ベクトルに変換したものをtsvにおく。(可視化ツールがtsvを要求してくるのでtsvにする)
pd.DataFrame(tweets).to_csv('./tweets_text.tsv', index=False, header=None))
pd.DataFrame(vectors).to_csv('./tweets_vector.tsv', sep='\t', index=False, header=None))
ここに出てくるcompute_vectorは、BERTモデルを用いて文章ベクトルに変換する処理です。
def compute_vector(text, model, bert_tokenizer, juman_tokenizer):
use_model = model
tokens = juman_tokenizer.tokenize(text)
bert_tokens = bert_tokenizer.tokenize(" ".join(tokens))
ids = bert_tokenizer.convert_tokens_to_ids(
["[CLS]"] + bert_tokens[:126] + ["[SEP]"])
tokens_tensor = torch.tensor(ids).reshape(1, -1)
use_model.eval()
with torch.no_grad():
all_encoder_layers, _ = use_model(tokens_tensor)
pooling_layer = -2
embedding = all_encoder_layers[0][pooling_layer].numpy()
# embedding = all_encoder_layers[0].numpy()
# return np.mean(embedding, axis=0)
return embedding
この処理によって保存されたファイルを確認してみると、文章ベクトルがtab区切りで保存されているtweets_vector.tsvと、元のツイートが保存されているtweets_text.tsvが存在しているはずです。

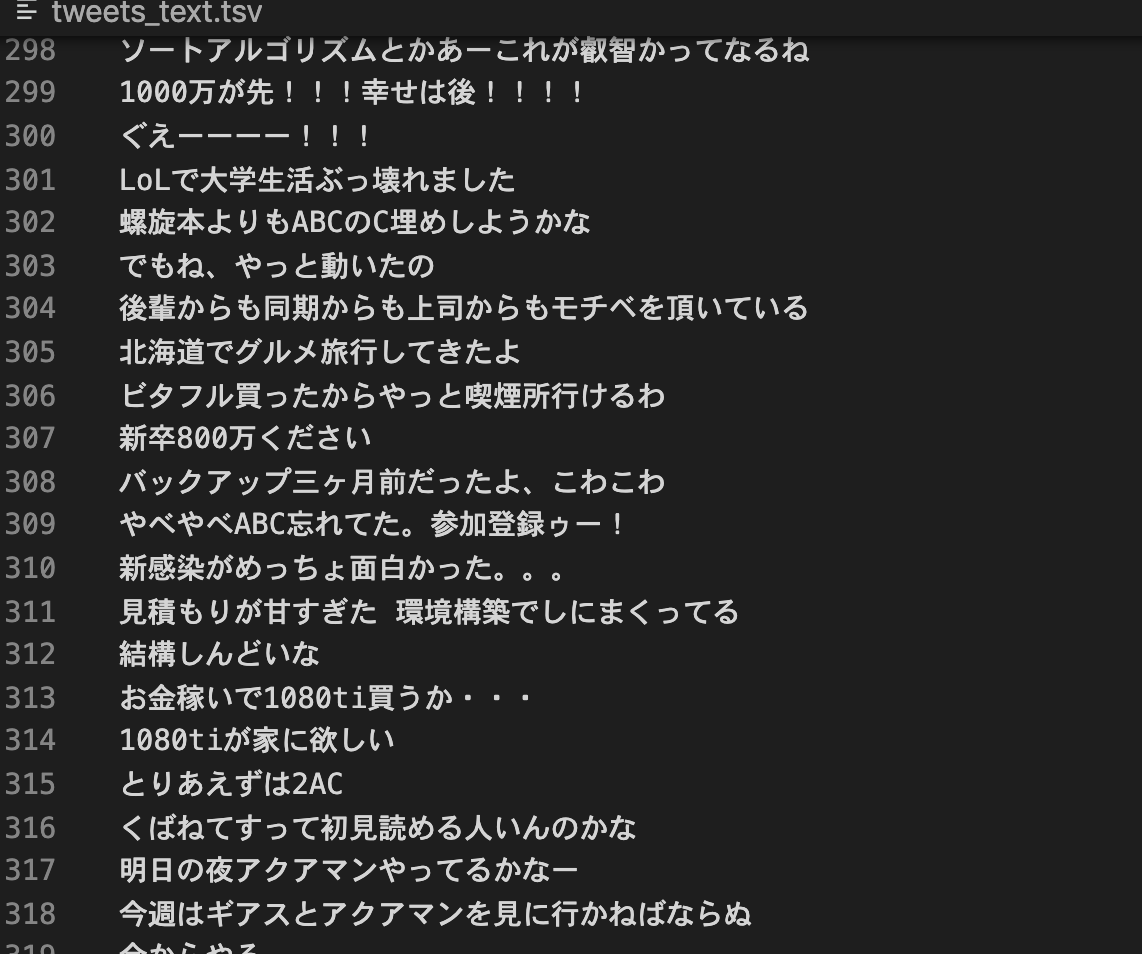
可視化してみる
これで可視化のための準備が完了しました。
EmbeddingProjectorを用いて、この文章ベクトルらを可視化してみましょう!!!!!
アクセスすると、以下のようにWord2Vecの単語の分布が表示されているはずです。
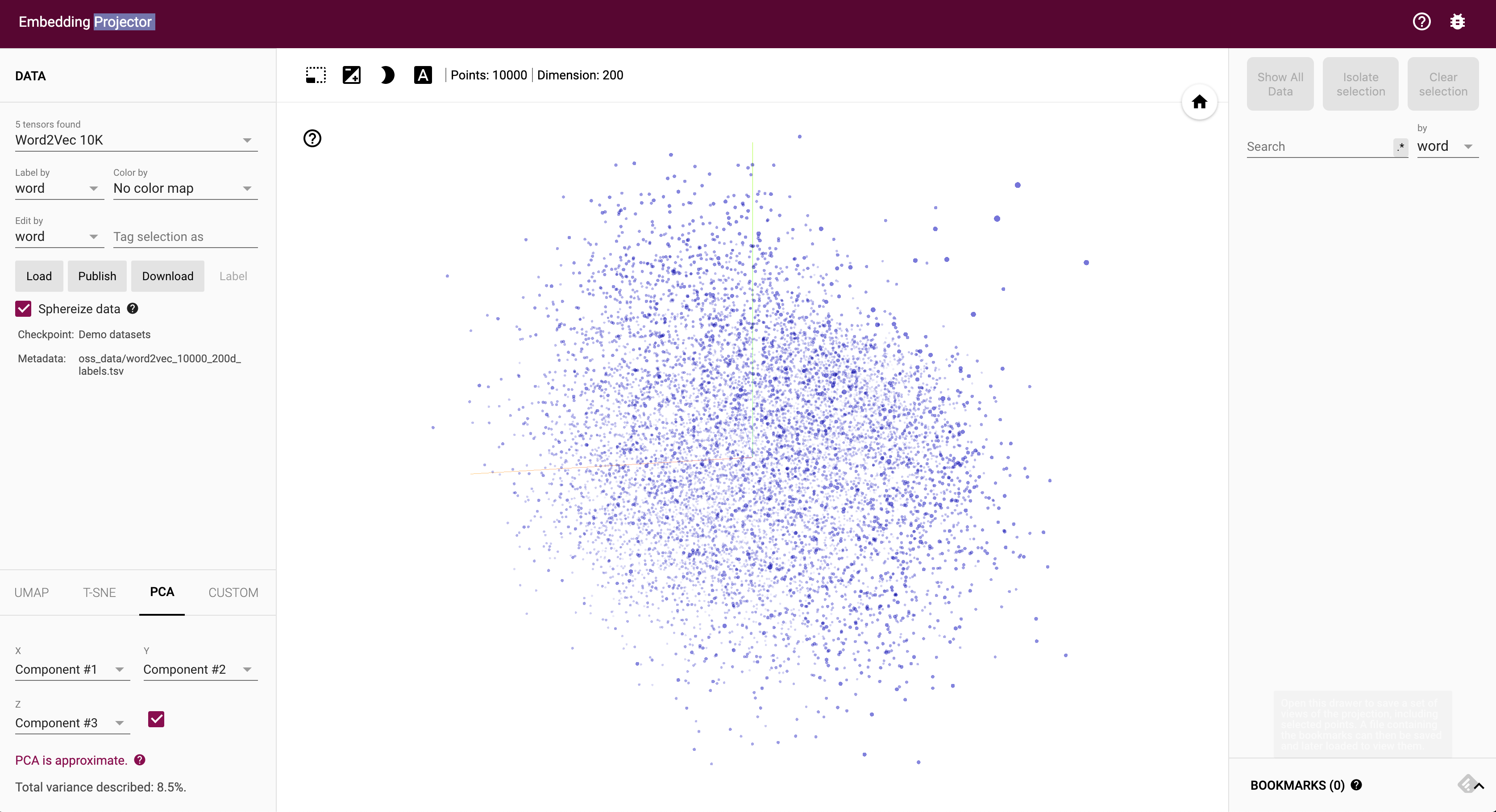
今回は、自分のツイートの分布がみたいので、先ほど生成したtweets_vector.tsvとtweets_text.tsvをデータソースにしましょう。
Loadボタンを押し、一つ目にtweets_vector.tsv、二つ目にtweets_text.tsvを選択して下さい。

これで自分のツイートが可視化できているはずです。
BERTによって変換された文章ベクトルは、本来であれば768次元のため、このように3次元上に表示することはできませんが、PCA(次元圧縮手法の一つ)を自動で行ってくれるため、以下のように表示されます。次元圧縮はPCAだけでなく、T-SNEやUMAPなども選択する事ができます。
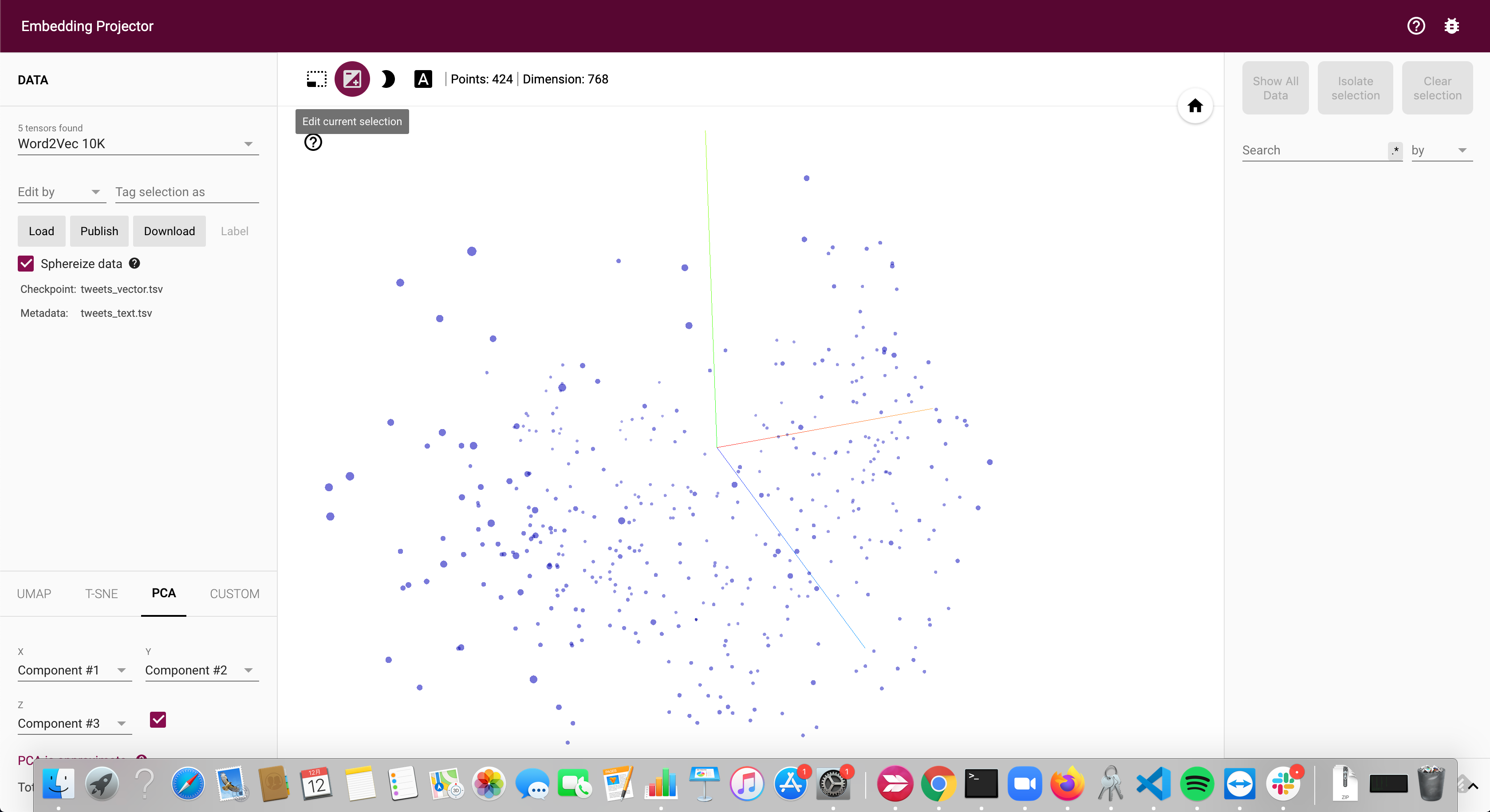
何か一つの点を選択すると、その文章と似た文章を表示してくれます。今回は類似度TOP10を表示しています。

勉強や論文などにまつわる文章が似た文章として選出されています!!文章の類似度がそこそこうまく算出できていそうですね。
二次元に落とし込んだ場合はこのような分布になります。

本来768次元のものを無理やり2,3次元に落とし込んでいるため、ハッキリと分布が分かれる訳ではありません。
PCAをした結果、上位2位で25%の説明率、3位で30%、10位まで使ってやっと50%だったため、このことからも納得できる結果になりました。
まとめ
今回は、BERTを理解しながら自分のツイートを可視化してみるハンズオン でした。
自身のツイートの分布を可視化することで、自身がどのようなツイートをしているのかがある程度わかるようになります。僕の例でいうと、かなりプログラミングとネガティブなツイートに偏っていて、『客観的にみたらこういう人なんだ・・・』という事がわかりました。
sentence pieceを使用する時間がなかったのが心残りなので、またsentence pieceを使用した記事をあげようかと思います。
自然言語処理は目でわかりやすい結果が出ないことも多いですが、可視化してみると新たな発見を与えてくれます。今回の記事を面白いと感じた方は、ぜひ自身のツイートで試してみて頂ければ幸いです。
また、twitterをフォローをしていただくと自然言語処理やリコメンドシステムについて呟いていたり、記事を書いていたりします。
それではこの辺りで僕の記事は終わりにします。
明日は、@Mahitoさんの記事です。お楽しみに!