こんにちは、 NTTコミュニケーションズ Advent Calendar 2019 の 21 日目の記事です。
昨日は @yuto_k2c さんの Pulumi SDKとGoogle Cloud SDKを組み合わせてみる でした。個人的に Pulumi は気になっているもののさわれてないソフトウェアの一つだったのでこの機会に自分も触りたいと思いました!
今回は アプリケーションのリリースに必要な会議体を倒したい話 という題で、現在自分のチームが行っている取り組みについて書きます。利用している技術の話というより、課題に対して何を考えて取り組んでいるかといった類の話になるためご留意下さい。
背景
弊社は Enterprise Cloud (以下 ECL) というパブリッククラウドサービスを提供しています。
本サービスを提供するために様々なアプリケーションが開発・運用されており、2016年にリリースされてから今でも機能の改善や拡張が行われています。
最近では Wasabi というオブジェクトストレージサービス が ECL のメニューとして新しくリリースされました。
アプリケーションのリリースについて、弊部署では以下の図のようなプロセスを必要としています。(各会議名は仮称です)
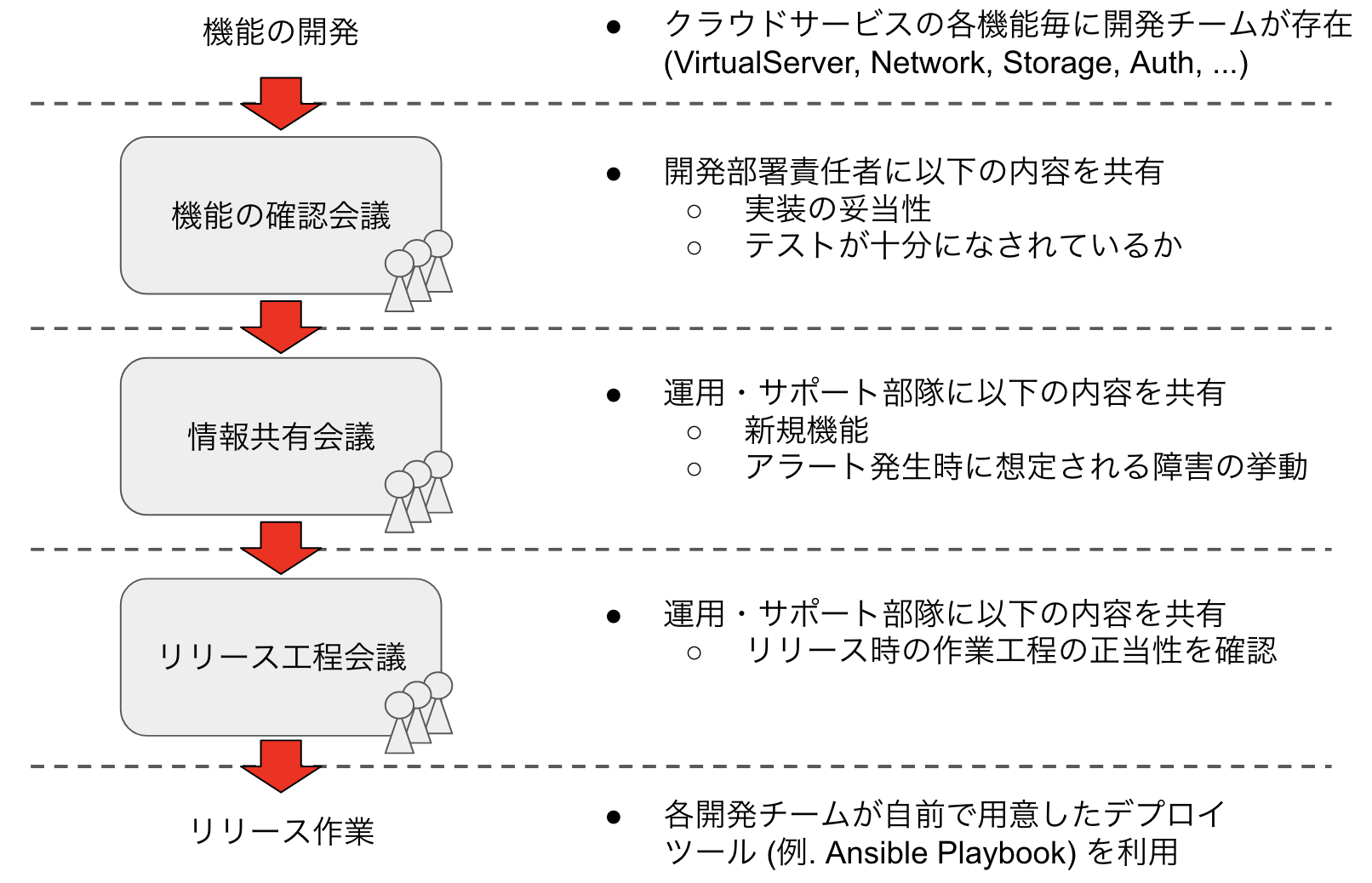
これらの会議はそれぞれ異なる観点でリリース対象のアプリケーションを見ることで、事前に大規模な障害を防ぐことを目的としています。実際に弊社で大規模障害と定めている障害はここ二年程ありません。
しかし、当リリースプロセスには明らかに欠点があるということが皆さんも分かると思います。それは リリースプロセスの遷移に要する会議がボトルネックとなりリリースが円滑に行えない ことです。現状、リリース対象のアプリケーションがどんな規模であれ原則これらの会議を通すことになっています。これによりアプリケーションの開発者はアプリケーションの開発以外に注力せざるを得なくなり、結果としてリリースサイクルが遅くなってしまっています。
SRE チームの結成 / 現状の取り組み
リリースの際に開発者にかかる負荷を無くすため、ECL のアプリケーションの開発を行っているメンバーを元に昨年 SRE チームを結成しました。
SRE は一般的に、エラーバジェットに収まる程度の品質を維持しつつ高速なリリースサイクルを実現する手法を指すと自分は理解しています。
ただ私達は "現状より高速なリリースサイクルを実現する" ことを最初の目的として定めました。リリースの際に開発チームにかかる負担を小さくするために "会議体の代わりにソフトウェアの自動評価によってアプリケーションの信頼性を担保する" ことが可能な基盤を GCP 上に構築し、SRE チームにて運用しています。当基盤を KUJIRA と呼んでいます。なお、 KUJIRA は GCP 上に構築する事が前提であるため、ECL のコントローラ (C-Planeからの通信を受け取るアプリケーション) が動作することを想定しています。
KUJIRA の特徴として以下があります。
- アプリケーションの実行基盤を GKE とすることで、開発チームの手掌範囲をコンテナレイヤへ引き上げる
- ステートは全て GCP のマネージドなサービス (例. Cloud SQL) にて管理することで、運用負担を削減する
- ステージング環境や本番環境へのアプリケーションのリリースには SRE チームの用意したデプロイフローを利用することで、開発チームがリリース工程の責務を負わない形にする
この取り組みにより、以下の会議をシステムに置き換えることが可能であると考えています。
-
リリース工程会議(リリースプロセスが妥当であるか判断する会議) -> 全開発チームで共通のデプロイ用パイプラインを SRE チームが用意し、統一されたリリースプロセスでリリースを行う。- デプロイ用パイプラインのテンプレートのみを
リリース工程会議で審議することで、全開発チームのリリース工程の信頼性を担保
- デプロイ用パイプラインのテンプレートのみを

KUJIRA の構想については Google の主催する Google Cloud で実践する DevOps というイベントでも紹介しました。
- https://lp.google-mkto.com/rs/248-TPC-286/images/20181206_Google_Cloud_DevOps_seminar.pdf (P.95-138)
Blue/Green Deployment の採用
私たちは上記の KUJIRA において、Kubernetes リソースのデプロイ戦略として Blue/Green Deployment を採用し、以下の手順で Spinnaker からアプリケーションのリリースを自動で実施しています。
- 新バージョンのアプリケーション Pod (図中緑色)をデプロイ
- 新バージョンのアプリケーション Pod に対して正常性確認
- 正常性確認結果に応じて
- OK なら、新バージョンのアプリケーション Pod を現用系に組み込み(図中水色に昇格)
- NG なら、新バージョンのアプリケーション Pod を削除

Blue/Green Deployment中にある正常性確認のステージにて開発者の用意したシナリオテストを新バージョンのアプリケーションに対して実行します。これにより、従来 リリース工程会議 で見ていた環境固有のバグ (本番環境の IAM 設定ミス、接続先名のtypo等) を取り除きます。
(もちろん、 CI によるアプリケーションの単一/統合テストや QA チームによる試験は別途行います)
デプロイ戦略の一つとして最近各所で Canary Release が話題に上がりますが、私たちはこれを採用しませんでした。
Canary Release はユーザトラフィックを徐々に新バージョンのPodに振り分けるデプロイ戦略です。これにより、バージョンアップ起因の障害発生時においても影響を最小限にすることが可能です。
しかしながら、Canary Release の性質上、上記で述べた "環境固有のバグ" の発生時において少なからずユーザ影響が出てしまいます。SRE としては事前にエラーバジェットを用意することである程度のユーザ影響を許容する取り組みを行いたいですが、そのために必要な SLO はアプリケーションのことを熟知しないと策定出来ないものです。
私たちは "会議体の代わりにソフトウェアの自動評価によってアプリケーションの信頼性を担保する" ことをひとまずの目的としているため、SLOの策定/SLIの取得/エラーバジェットの用意 といった作業は今の段階では手がつけられないと判断しました。そのためデプロイ戦略においても Canary Release ではなく Blue/Green Deployment を採用し、ユーザトラフィックではなくテスト用トラフィックを用いた環境固有バグの確認を行っています。
Blue/Green Deployment の内部動作については、過去に NTT Engineer Festa #3 という NTT グループ内で定期的に行われている勉強会にて自分が発表しました。登壇資料は以下になります。
絶対に決壊しない川作り
上記で述べた Blue/Green Deployment により、リリース時にシナリオテストが実行されることでアプリケーションが本番環境で動作することが担保されます。また、シナリオテストが失敗した際においても本番環境に影響なく切り戻る仕組みとなっています。
私達はこのデプロイを実現するデプロイフローを実装する際、当デプロイフローを "川" と見立て、「絶対に決壊しない川作り」と呼んでいます。以下の図はデプロイフローを "川" に見立てたイメージ図です。図中の ❌ で示されているような "川の決壊" がなく、必ず 正常終了 か 切り戻し に流れ着くことが、 リリース工程会議 をシステムに置き換えるための必須要件となります。

私達の Blue/Green Deployment の仕組みにより、アプリのバグや外部結合要因等のアプリ起因の問題については "川" の決壊なく川の下流のどちらかに必ず流れ着きます。しかしながら、1 バージョンしか存在し得ない Kubernetes リソース定義を誤って更新してしまった場合、現状の Blue/Green Deployment だと "川" が決壊する恐れがあります。
具体例として、Ingress リソースの metadata.annotations['kubernetes.io/ingress.global-static-ip-name'] (GCP の GIP 名を指定する箇所) の値が書き換わってしまった場合が挙げられます。この場合、誤った変更のあるマニフェストを Kubernetes に適用した時点で外部からアプリケーションへの疎通性がなくなりサービス断が発生してしまいます。
この辺りのパラメータは普段触らないため問題ないだろうと思う方も居ると思いますが (自分もそうでした) 、この問題は実際にステージング環境にて発生した事象です。マニフェストファイルを管理している Git リポジトリのブランチ運用が煩雑であった結果、metadata.annotations['kubernetes.io/ingress.global-static-ip-name'] に過去の GIP 名を指定したマニフェストを Kubernetes に適用してしまいサービス断が発生しました。
この辺りは "運用で対処" という選択肢もなくはないと思います。ただ、私達がやりたいことが "リリース工程会議 をなくす" ことであるため、「やっぱり川が決壊しうるんだったら会議をやらなきゃダメじゃん」となってしまわないためには当問題をシステム的に発生させないようにする必要があると考えました。
ここからは現状検討中の事項となりますが、私達は当問題をシステム的に発生させないようにするために Open Policy Agent (OPA) が利用できると考えています。OPA は汎用的な Policy Engine であり、Rego というポリシ記述言語により 「ユーザ X がオペレーション Y をリソース Z に対して実行可能/不可能」 といったポリシを定義することができます。
Kubernetes のリソース適用時に OPA でポリシ制御するための実装として Gatekeeper というソフトウェアがあります。これを用いてマニフェストのうち変更不可なフィールドをユーザ定義することで、上記で述べた問題を解決し、"絶対に決壊しない川" が完成すると考えています。
(絶対に といいつつ物事に絶対は無く、現状決壊しうるケースとしてユーザ定義された変更不可なフィールドに漏れがあった場合が挙げられます。ただ、分かっていないことを想像することは出来ないのと、リリース工程会議 でも結局想定外の事象は起こりうるよね という整理で、リリース工程会議 の廃止を推し進めています)
これからの取り組み
上記の取り組みによりリリースに必要な会議の数が減り、リリースの際に開発チームにかかる負担が軽くなると考えています。しかしながら依然として以下の会議が必要となっていることが課題であると認識しています。
-
機能の確認会議(アプリケーションの新規実装部分が妥当であるか判定する会議) -
情報共有会議(運用・サポートを行う部門に対する情報共有)
現状、SRE チームの取り組みとして 上記で述べた "リリース工程会議 をなくす" こと が完了していないため、その先の話である上記の課題の解決法はまだチームの共通認識として定まっていません。そのため、これらの問題をどのように解くかについて、現状の私見として以下にまとめます。
機能の確認会議 をどうやめるか
機能の確認会議 はリリースしたい新規機能の説明や当機能の実装及びテスト項目を開発部署の責任者に共有するための会議です。また、当会議にて新規機能のリリース要求の承認を行うことで、当リリース起因の障害が発生した場合の責任を部署の責任者に委譲するといった目的もあります。
自分はこの会議を完全に無くすことは出来ないと考えています。しかしながら、リリース内容がバグフィックス程度のものであってもメジャーバージョンアップ等の大きなものであっても同じ人に対して同じ手順でこの会議をしている現状を見ると、工夫のしようはあると感じます。
1つは、リリース内容のレベルに応じて誰に対して会議を実施するかを分けることです。例えば、他のアプリケーションに関係しない程度の機能改修であれば開発チームの上長から承認されれば良いという形にすれば、対象アプリケーションの背景の説明を省くなど現状よりラフな形での 機能の確認会議 にすることが可能なのかなと思います。
また、SRE の考え方である SLIの取得/SLOの策定/エラーバジェットの用意 を適切に行うことで、エラーバジェットの範囲内であれば承認を得ることすらせずにリリースすることが可能ではないかと考えています。ただこれを実現するためには、開発者及び責任者にある程度の障害 (可用性の低下) を許容する といった意識付けを行うことが必ず必要になります。そのため、部署内に対する SRE の取り組みに関する啓蒙活動を継続的に行おうと思っています。
上記の取り組みのうち、特に SLO の策定は SRE の人が該当アプリケーションを深く理解しないと決められないものです。そのため、開発チームに少人数 (1,2 人) の SRE チームメンバを割り当てて開発チームと密接に関わることが必要なのかなと考えています。またアプリケーションの継続的な改善のために一定の間隔で SLO の再策定を行うことも必要です。メルカリさんの、 3 ヶ月に一度 SLO を再策定しなければならないことを OPA を用いてシステム化するという以下の事例はとても参考になりました。(SRE の話題でメルカリさんにはいつもお世話になっています・・!)
情報共有会議 をどうやめるか
情報共有会議 は開発チームと別部門にある運用・サポートチームに対しリリース対象のアプリケーションの機能についての情報共有を行います。
KUJIRA は SRE チームが運用するため当会議は必要なさそうに思えますが、そうはいかなそうだということが見えています。運用・サポートチームはお客様の問い合わせに対する回答を行うことが業務の一つとなるため、新規機能が実装された際はそれを認知する必要があります。また、運用・サポートチームは ECL にて障害が発生した際にはお客様周知を行うため、"何のアラートが発生したら何が起きているか" の共有を両チーム間で行うことが必要になります。これらのために開発チームが KUJIRA を利用した際においても現状のままでは 情報共有会議 は必要だろうと予想しています。
逆に、運用・サポートチームと開発チーム間の情報に乖離が無ければ 情報共有会議 は要らないでしょう。それを実現するために自分は以下の2通りの方法を思いつきました。
1つは、運用・サポートチームが該当アプリケーションのドキュメントを熟知していれば良いという考えです。しかしながらこの方法は、運用・サポートチームが自分が実装したわけでは無いアプリケーションを詳細に知る必要があるという障壁だけでなく、開発者がアプリケーションに関するドキュメントを事細かに記述し随時整備しなければならないといった障壁も存在します。「最初はこの方法でやってきたが、徐々に無理を感じたため 情報共有会議 という場を設けた」というストーリーも考えられるほどですし、現実的な解では無いと自分は思っています。
もう1つは、運用・サポートチームと SRE チームを同じにしてしまうという方法です。[機能の確認会議 をどうやめるか](#機能の確認会議 をどうやめるか) の節で述べたように SRE の人は今後開発チームと密に関わることが必要となるため、SRE チームが 「基盤運用とお客様のサポートを行う」のに適しているように思えます。ただこの方法では、現状の SRE の業務に加えて割り込みの業務も発生するため、果たして SRE チームが SRE の営みに注力できるのかといった点に怪しさを感じています。
この課題に対して自分はこれだという解決策を持てていないです。どのように皆さんはこの課題を解決しているのか、ぜひ教えていただきたいです。
まとめ
我々が SRE の考え方を参考に "現状より高速なリリースサイクルを実現する" ために取り組んでいることや考え方について述べました。また、これからの取り組み では現状自分が考えうる理想かつ実現可能そうなリリースプロセスについてを述べました。
これらの話 (特にこれからの取り組みで述べた内容) は荒削りな箇所があると思います。もし当記事を読んでくださった方に「こうやったほうがいいんじゃない?」であったり「似たような問題をこうやって解いたぜ!」といった意見や疑問点等があれば、ぜひ当記事のコメントに書いていただけると嬉しいです。
また Twitter をやっているので、そちらからの意見も待っています!
明日は @yuki_uchida さんの記事です!