日本でも音楽ストリーミングサービスのSpotifyを使っている人が多いと思いますが、そのSpotifyは配信している音楽に関するデータをWeb APIを通して公開しています。このAPIを使って様々な情報が取れるのですが、今日は以下のAPIを使って、音楽のジャンルに関するデータ分析をExploratoryを使ってしてみたいと思います。(他のAPIはこちらを参照)
これらのAPIを組み合わせて、Spotifyからジャンル毎に1000曲ずつ取ってきて、それぞれの曲の属性データをもとに、ジャンル同士の類似性を調べてみます。
事前準備
Spotifyのアカウントの作成
SpotifyのAPIを使うには、先にSpotifyのディベロッパー・ダッシュボードでデベロッパー・アカウントを作成しておく必要があります。登録が終わったら、クライアントIDとシークレットをメモしておきましょう。詳細はこちらにメモしておいたので興味のある人はどうぞ。
spotifyrパッケージのインストール
実はspotifyrというRからSpotifyのREST APIを使いやすくするRパッケージがあるので、そちらを先にExploratoryにインストールしておきます。こちらに詳細のステップをまとめておきましたので、興味のある人は参考にして下さい。
ただ、このパッケージでは曲のジャンルを取ってきたり、ジャンルごとに曲をとってくることがサポートされていないので、その部分は直接SpotifyのREST APIを呼ぶことになります。
Spotifyからデータをインポートする
では早速Spotifyからデータを取得し始めましょう。
まずはジャンルの情報を取ってきます。
ジャンル情報をインポート
Exploratoryでは、データフレームを返すRスクリプトを直接データソースとすることができるので、今回はそちらを使います。
画面左のデータフレームの隣にある、プラスのボタンをクリックし、”Rスクリプト”をメニューから選びます。
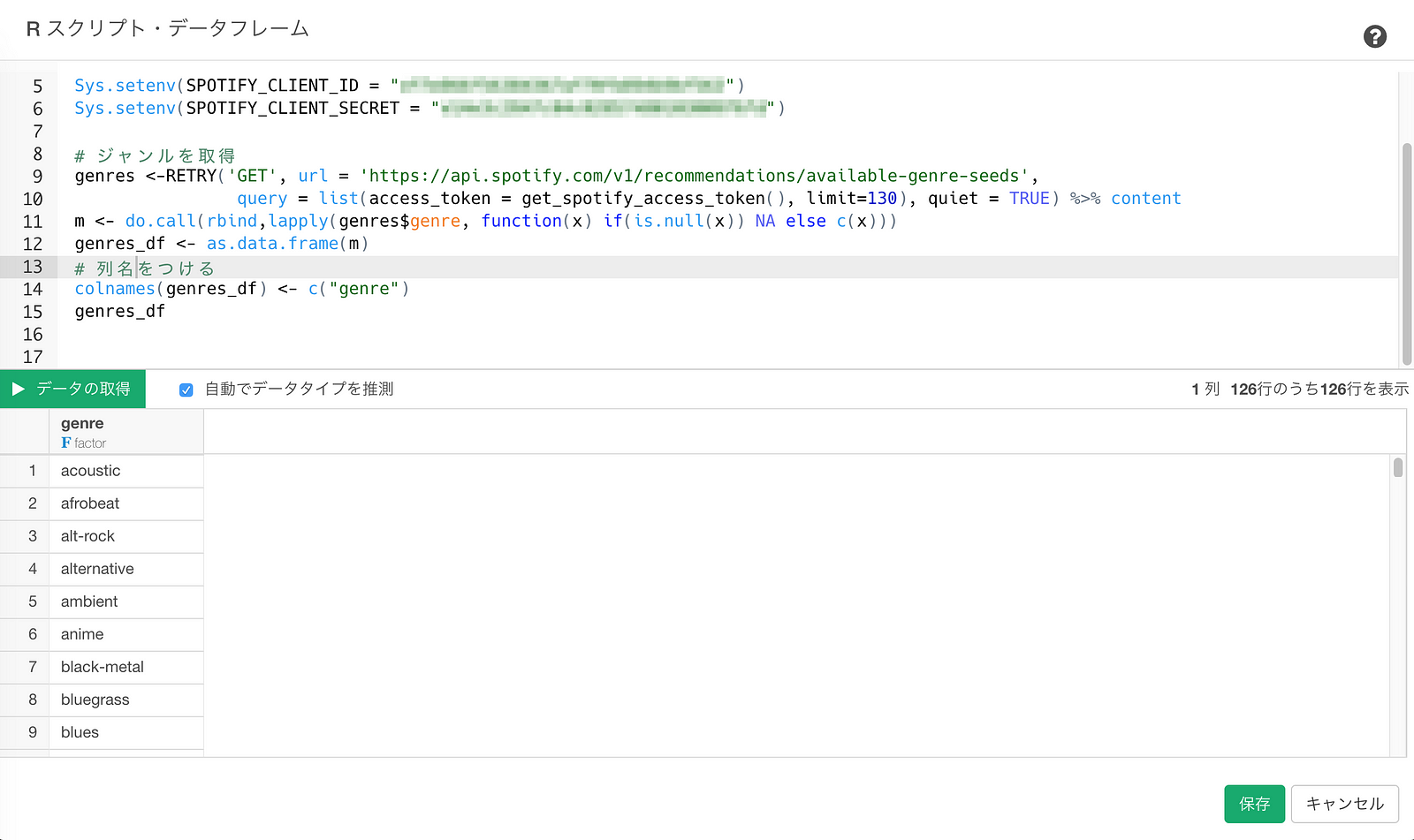
以下がジャンルの情報を取ってくるスクリプトになります。
# 必要なlibraryを読み込んでおく
library(spotifyr)
library(httr)
library(purrr)
# SpotifyのAPIを使うための認証情報を設定する
Sys.setenv(SPOTIFY_CLIENT_ID = "YOUR_CLIENT_ID"
Sys.setenv(SPOTIFY_CLIENT_SECRET = "YOUR_SECRET"
# ジャンルを取得
# https://api.spotify.com/v1/recommendations/available-genre-seeds のエンドポイントを使う。
# 取得した結果をデータフレームにする
m <- do.call(rbind,lapply(genres$genre, function(x) if(is.null(x)) NA else c(x)))
genres_df <- as.data.frame(m)
# 列名をつける
colnames(genres_df) <- c("genre")
genres_df
メインはrecommendations/available-genre-seedsというAPIを呼ぶ部分です。
Rの中でREST
APIを使うには、httrというRパッケージが便利です。その中のRETRYという関数を使って上記のAPIを呼んでいます。
スクリプトが入力できたら、データの取得ボタンをクリックします。
すると126件のジャンルが取得できました。
ジャンル毎に1000曲をインポート
次に先ほどとったジャンル毎に1,000曲づつデータをインポートしてみます。先ほどのスクリプトに以下のように追加します。
# 必要なlibraryを読み込んでおく
library(spotifyr)
library(httr)
library(purrr)
# SpotifyのAPIを使うための認証情報を設定する
Sys.setenv(SPOTIFY_CLIENT_ID = "YOUR_CLIENT_ID")
Sys.setenv(SPOTIFY_CLIENT_SECRET = "YOUR_SECRET")
# ジャンルを取得
# https://api.spotify.com/v1/recommendations/available-genre-seeds のエンドポイントを使う。
genres <- RETRY('GET', url = 'https://api.spotify.com/v1/recommendations/available-genre-seeds', query = list(access_token = get_spotify_access_token(), limit=130), quiet = TRUE) %>% content()
# 取得した結果をデータフレームにする
m <- do.call(rbind,lapply(genres$genre, function(x) if(is.null(x)) NA else c(x)))
genres_df <- as.data.frame(m)
# 列名をつける
colnames(genres_df) <- c("genre")
# ジャンル毎に1000曲取ってくるにはサーチのAPIを使う。
# https://api.spotify.com/v1/searchというエンドポイントを指定
get_genre_track <- function(genre){
track_check <- RETRY('GET', url = paste0("https://api.spotify.com/v1/search?query=genre%3A",genre), query = list(type="track",limit = 50, offset = 0, access_token = get_spotify_access_token()), quiet = TRUE) %>% content()
#ジャンル毎に1000曲とる
track_count <- 1000
# 一回あたりのSpotifyのAPI Callで取得できる上限は50件なので
# 分割してデータをとる。
num_loops <- ceiling(track_count / 50)
numoffset <- 0
# APIを呼ぶ際に、offsetを使うと欲しいデータを分割して取れるので
# offsetをずらしながら最後までデータをとる
track_df <- map_df(1:ceiling(num_loops), function(this_loop) {
res <- RETRY('GET', url = paste0("https://api.spotify.com/v1/search?query=genre%3A",genre), query = list(type="track",limit = 50, offset = numoffset, access_token = get_spotify_access_token()), quiet = TRUE) %>% content()
numoffset <<- numoffset + 50
# 結果をデータフレームにまとめる
df <- map_df(1:length(res$tracks$items), function(this_row) {
tryCatch({
this_track <- res$tracks$items[[this_row]]
track_uri <- this_track$id
name <- this_track$name
genre <- genre
list(track_uri = track_uri, name = name, genre = genre)
}, error = function(e){
NULL
})
})
})
}
# ジャンルのデータフレームを基にして、曲を一つのデータフレームにまとめる
tracks_df <- lapply(genres_df$genre, get_genre_track) %>% bind_rows()
tracks_df
スクリプトが入力できたら、さっきと同じように”データの取得”ボタンを押すと、各ジャンル毎に1,000曲のデータが取得できました。
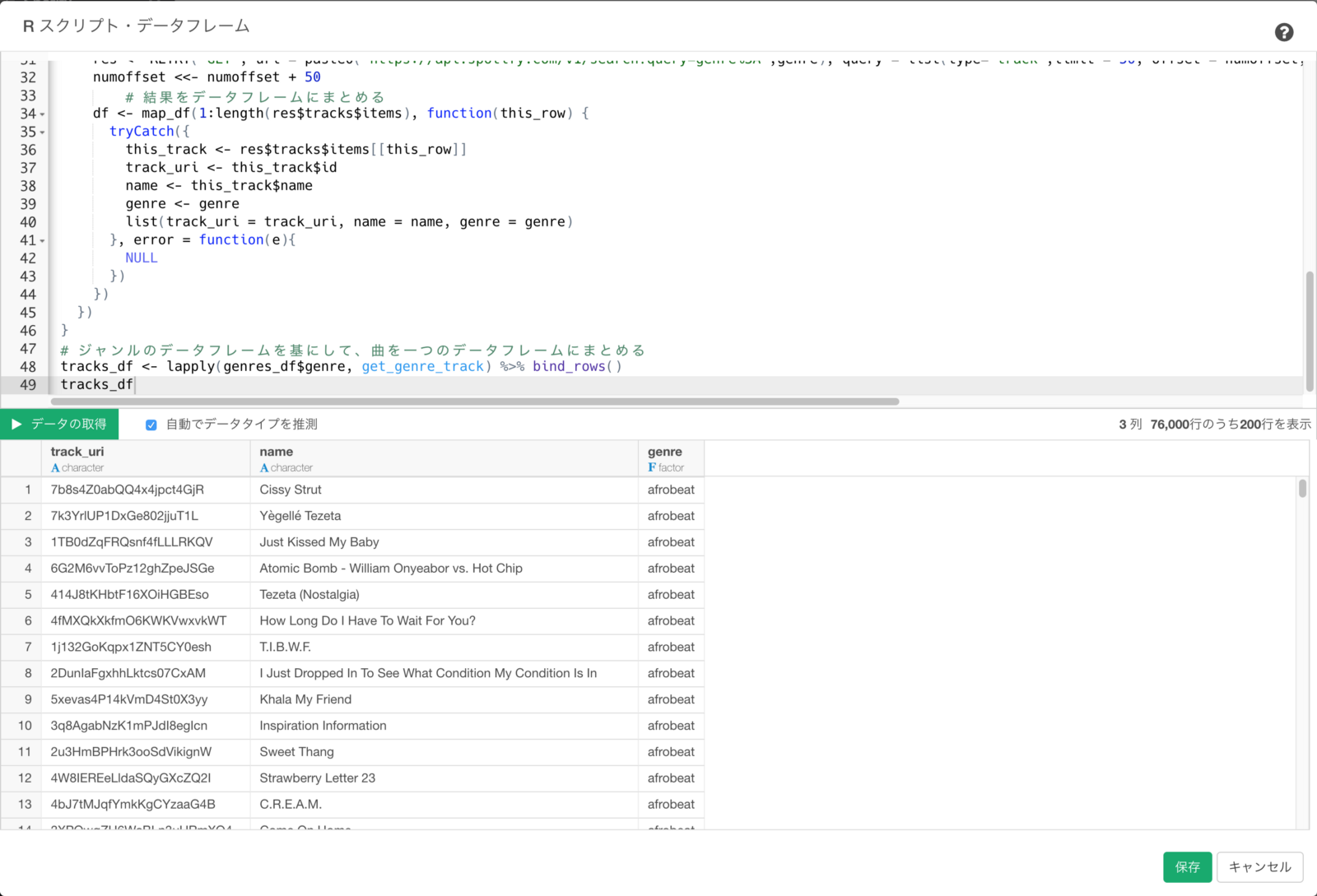
返ってきたデータ数が76,000行しかないのは、(ジャンルが126個なので、126,000行のはず?)、philippines-opmやpop-filmなどの、そもそも登録をされている曲が一つもないジャンルがあるのが理由です。
それぞれの曲の属性データをインポート
最後に、それぞれの曲の属性データを取り込みましょう。ちなみに以下の属性がとれます。
danceability
danceability(踊りやすさ)は、テンポ、リズムの安定性、ビートの強さ、全体的な規則性などの音楽要素の組み合わせに基づいて、ダンスのための曲であるかを示します。0.0の値は、最も踊りずらいことを、1.0は、最も踊りやすいことを示します。
energy
エネルギーは、0.0から1.0の指標で、強度およびアクティブ度を表します。一般的には、エネルギッシュなトラックは、速く、音が大きく、騒々しい感じがします。例えば、デスメタルは高いエネルギーを持っていますが、バッハのプレリュードは低い値になります。この属性に寄与する知覚的属性は、ダイナミックレンジ、聴覚が感じる音量、音色、開始時点のレート、および一般的なエントロピーを含みます。
loudness
ラウドネスは、曲の全体的な音量をデシベル(dB)で表したものです。値は曲全体で平均化され、他の曲との相対的なラウドネスを比較するのに役立ちます。値の典型的な範囲は-60から0dbです。
speechiness
スピーチは、曲の中で話された単語の存在を検出します。録音(例えば、トークショー、オーディオブック、詩)のように、音声が占める割合が大きくなるほど、値は1.0に近くなります。0.66を超える値は、ほぼ完全に発声された単語で構成されている曲を表します。0.33と0.66の間の値は、ラップ音楽などのセクションまたはレイヤーのいずれかで、音楽とスピーチの両方を含む可能性がある曲を表します。0.33未満の値は、音楽やその他の非音声のような曲を表す可能性がかなり高いことを示します。
acousticness
曲がアコースティックかどうかを示す0.0から1.0の指標です。 1.0は曲がアコースティックであるということが高いということを意味します。
instrumentalness
曲にボーカルがないかどうかを予測します。この指標では、 “オー(Ooh)”とか
“アー(aah)”の音は楽器の出した音として扱われます。ラップや話し言葉はボーカルとして扱われます。インストゥルメンタルネスの値が1.0に近いほど、曲にはボーカル・コンテンツが含まれていない可能性が高くなります。
0.5を超える値は、インストゥルメンタルの曲が通常示す値ですが、値が1.0に近づくほど信頼度が高くなります。
liveness
録音中に聴衆が存在したかを検出します。この値が高いほど、曲がライブで実行された可能性が高くなります。値が0.8を超えると、曲がライブである可能性が高くなります。
valence
曲が伝える音楽のポジティブ性を表す0.0から1.0の尺度。この指数の高い値の曲はより陽性(例えば、幸せ、陽気、陶酔)であり、低い指数の曲はより陰性となります(例えば、悲しい、落ち込んだ、怒る)。
tempo
曲の全体的な推定テンポ。1分あたりのビート(BPM)。音楽用語では、テンポは、ある曲のスピードまたはペースであり、平均ビート期間から導出されます。
こちらの曲の属性データはspotifyrというRパッケージの中にある、get_track_audio_featuresという関数を呼ぶだけで取ってこれます。
先ほどのスクリプトの最後に以下のように追加します。
# 必要なlibraryを読み込んでおく
library(spotifyr)
library(httr)
library(purrr)
# SpotifyのAPIを使うための認証情報を設定する
Sys.setenv(SPOTIFY_CLIENT_ID = "YOUR_CLIENT_ID")
Sys.setenv(SPOTIFY_CLIENT_SECRET = "YOUR_SECRET")
# ジャンルを取得
# https://api.spotify.com/v1/recommendations/available-genre-seeds のエンドポイントを使う。
genres <- RETRY('GET', url = 'https://api.spotify.com/v1/recommendations/available-genre-seeds', query = list(access_token = get_spotify_access_token(), limit=130), quiet = TRUE) %>% content()
# 取得した結果をデータフレームにする
m <- do.call(rbind,lapply(genres$genre, function(x) if(is.null(x)) NA else c(x)))
genres_df <- as.data.frame(m)
# 列名をつける
colnames(genres_df) <- c("genre")
# ジャンル毎に1000曲取ってくるにはサーチのAPIを使う。
# https://api.spotify.com/v1/searchというエンドポイントを指定
get_genre_track <- function(genre){
track_check <- RETRY('GET', url = paste0("https://api.spotify.com/v1/search?query=genre%3A",genre), query = list(type="track",limit = 50, offset = 0, access_token = get_spotify_access_token()), quiet = TRUE) %>% content()
#ジャンル毎に1000曲とる
track_count <- 1000
# 一回あたりのSpotifyのAPI Callで取得できる上限は50件なので
# 分割してデータをとる。
num_loops <- ceiling(track_count / 50)
numoffset <- 0
# APIを呼ぶ際に、offsetを使うと欲しいデータを分割して取れるので
# offsetをずらしながら最後までデータをとる
track_df <- map_df(1:ceiling(num_loops), function(this_loop) {
res <- RETRY('GET', url = paste0("https://api.spotify.com/v1/search?query=genre%3A",genre), query = list(type="track",limit = 50, offset = numoffset, access_token = get_spotify_access_token()), quiet = TRUE) %>% content()
numoffset <<- numoffset + 50
# 結果をデータフレームにまとめる
df <- map_df(1:length(res$tracks$items), function(this_row) {
tryCatch({
this_track <- res$tracks$items[[this_row]]
track_uri <- this_track$id
name <- this_track$name
genre <- genre
list(track_uri = track_uri, name = name, genre = genre)
}, error = function(e){
NULL
})
})
})
}
# ジャンルのデータフレームを基にして、曲を一つのデータフレームにまとめる
tracks_df <- lapply(genres_df$genre, get_genre_track) %>% bind_rows()
# 曲の属性情報を取得
# https://api.spotify.com/v1/audio-features/がエンドポイントだが
# spotifyrのget_track_audio_featuresという関数がそれ用に用意されているので
# ここではそれを使う
features_df <- tracks_df %>% spotifyr::get_track_audio_features()
# Genre情報が落ちてしまっているのでtrack_dfから取ってくる
result <- features_df %>% left_join(tracks_df, by = c("track_uri" = "track_uri"))
result
追加できたら、もう一度、”データの取得”ボタンを押します。
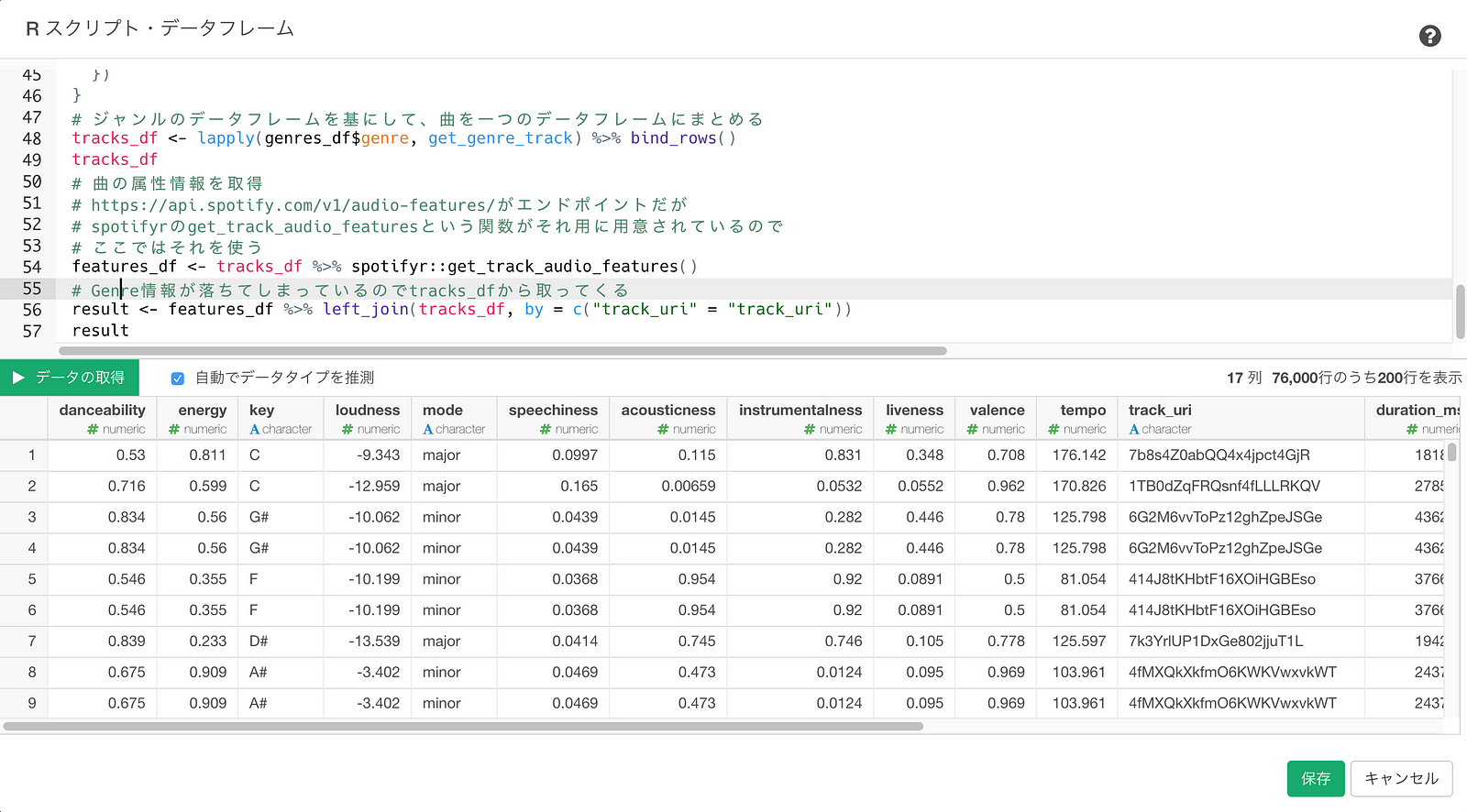
無事に曲の属性データが返ってきているのが確認できたので、”保存”ボタンを押してデータフレームとして保存します。
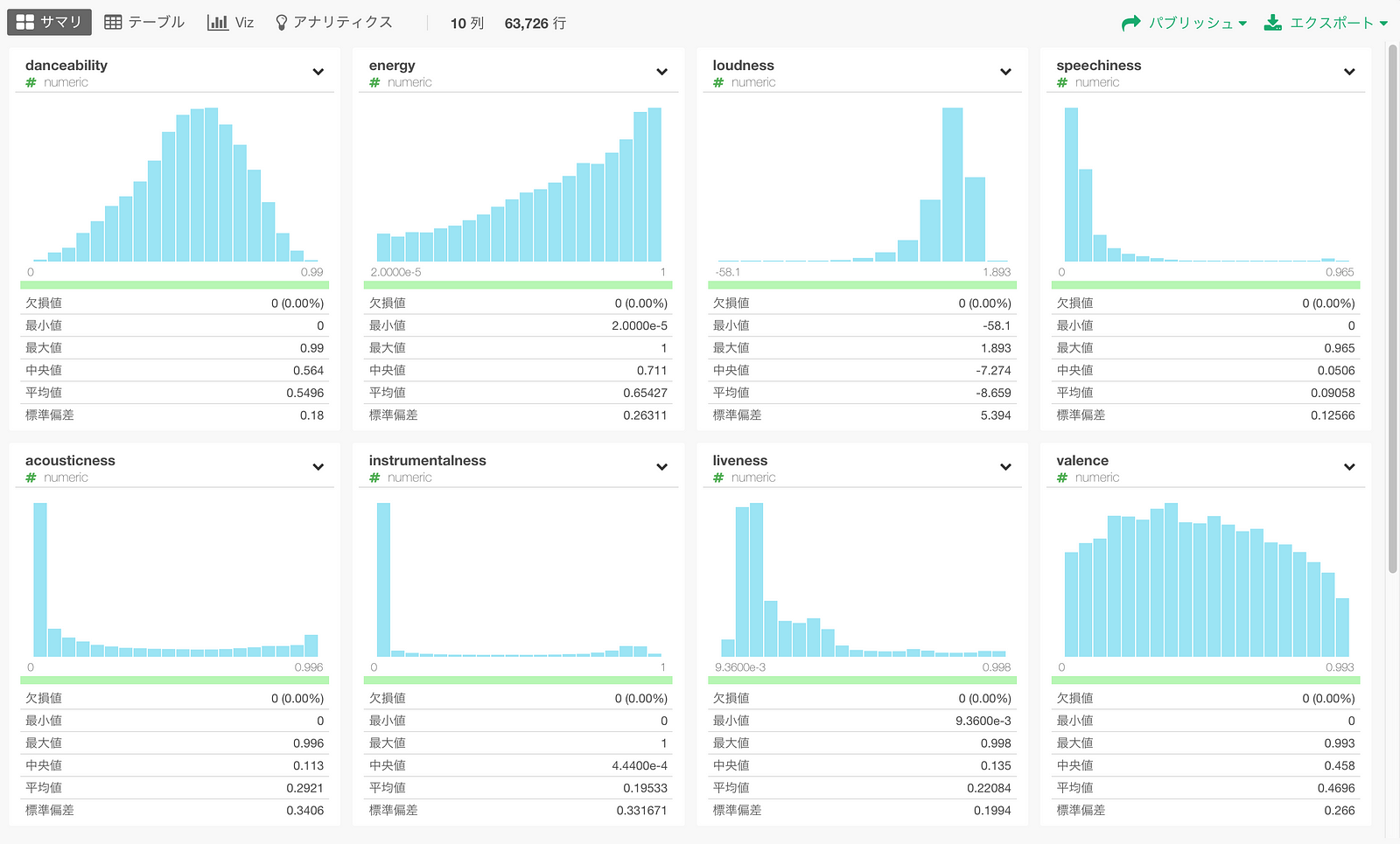
まずはサマリビューで曲属性の分布を簡単に見ることが出来ます。
danceabilityのように正規分布のようなものもあれば、speechnessのようにほとんどのデータが値の小さい方に偏っているようなものもあります。
属性データのジャンルごとの分布
energyの分布
さて、では早速Spotifyからインポートした曲の属性データを使ってジャンルを分析してみましょう。下の箱ひげ図はenergyの分布をジャンル毎に見たものです。
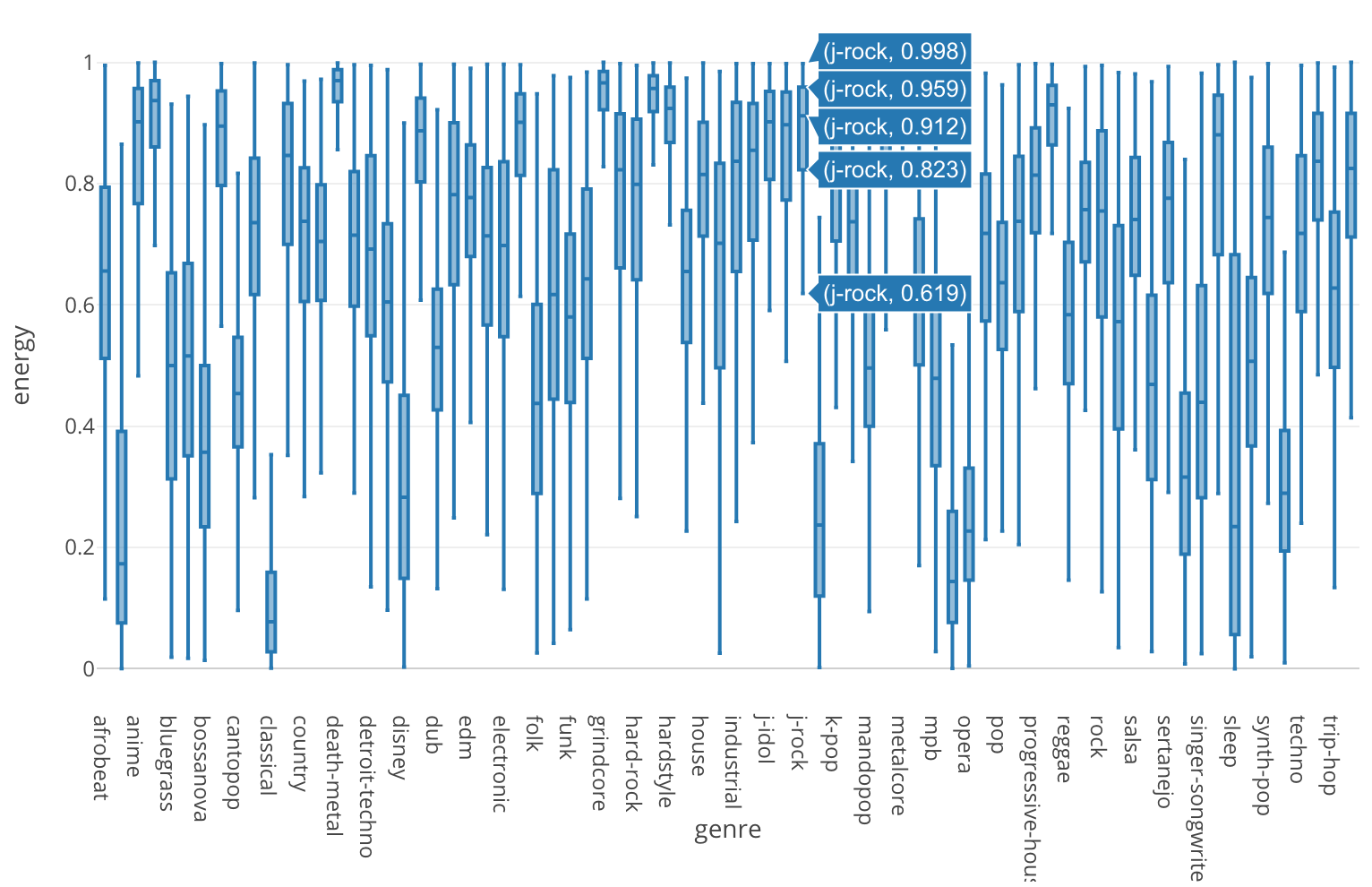
例えばJ-Rockという日本のロックのジャンルがありますが、そこに含まれる1000曲のエネルギー度に関する分布は他に比べてかなり高い方にあるのが分かります。
一つ一つ見ていてもきりがないので、一度、属性同士の相関を見てみましょう。
属性同士の相関
アナリティクスビューに行き、タイプに列ごとの相関をえらびます。
”変数の列”で以下の属性の列を選択します。
- danceability
- energy
- loudness
- speechiness
- acousticness
- instrumentalness
- liveness
- valence
- tempo
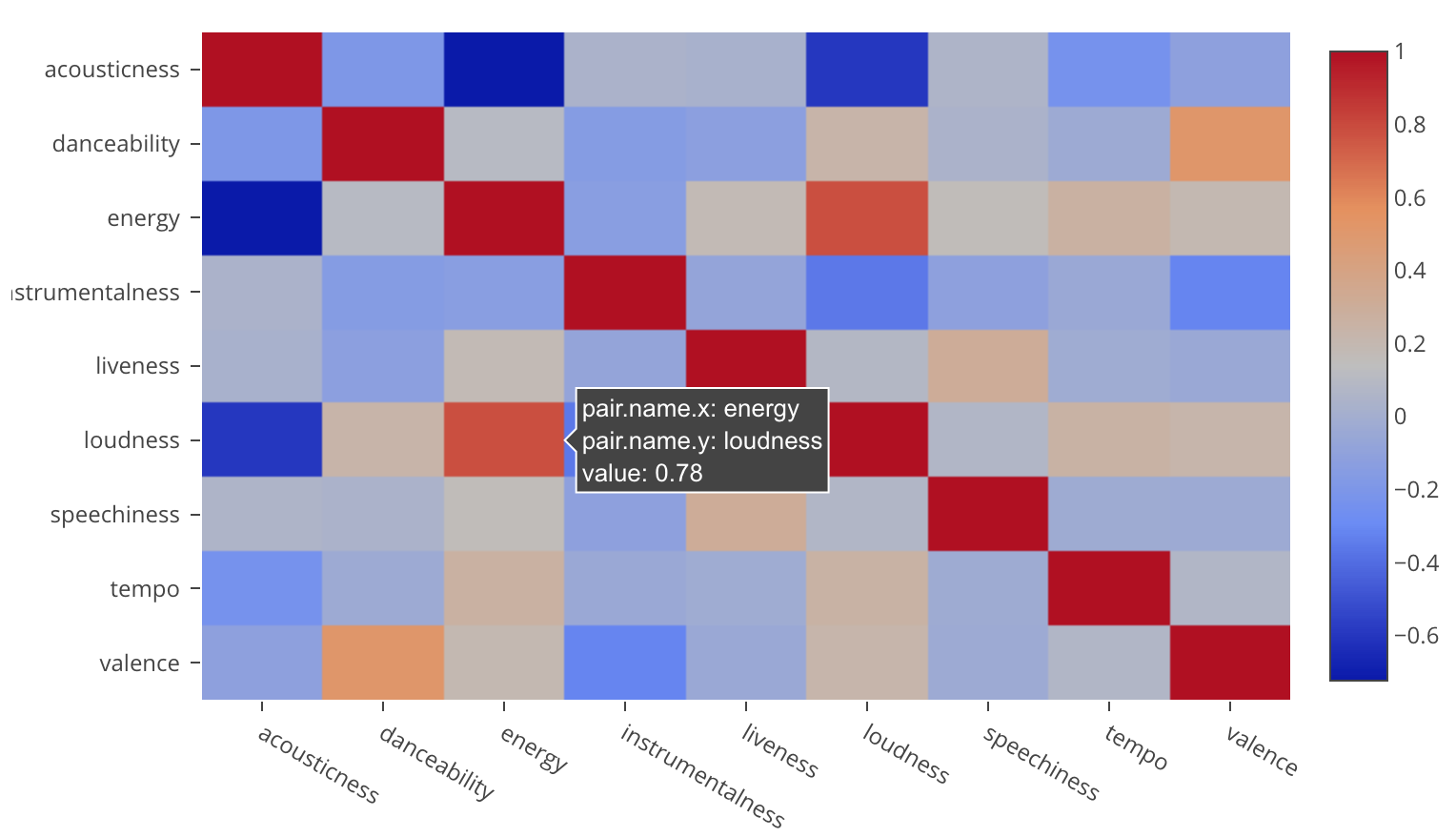
そして実行ボタンを押して相関行列のタブに行くと、energyとloudnessに正の関係があるのが分かります。(赤い色が濃いほど正の相関が強い)
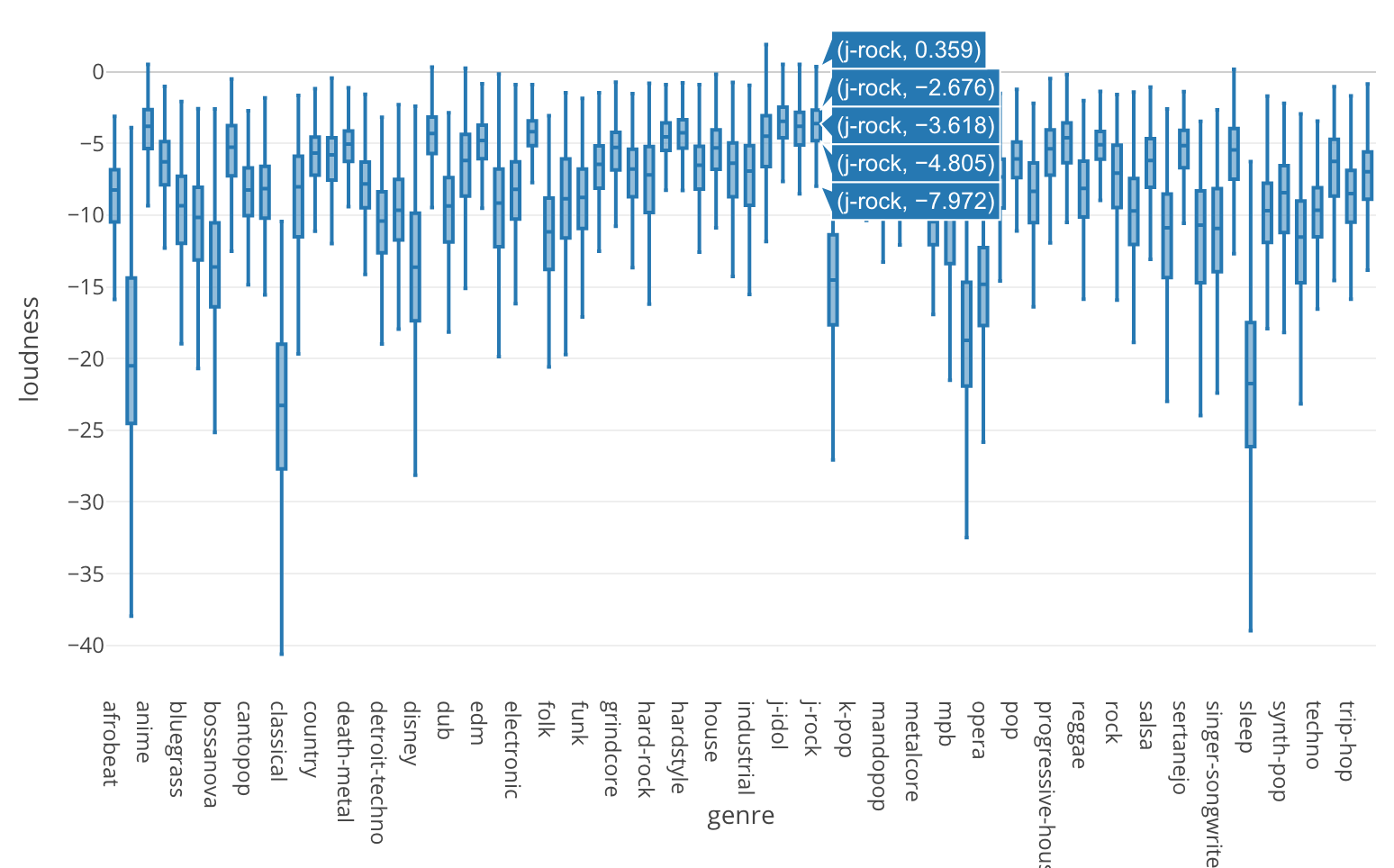
では先ほどの箱ひげ図を、energyから相関があることが分かったloudnessに変えてみましょう。
J-Rockはloudnessでも上位にあるのが分かります。
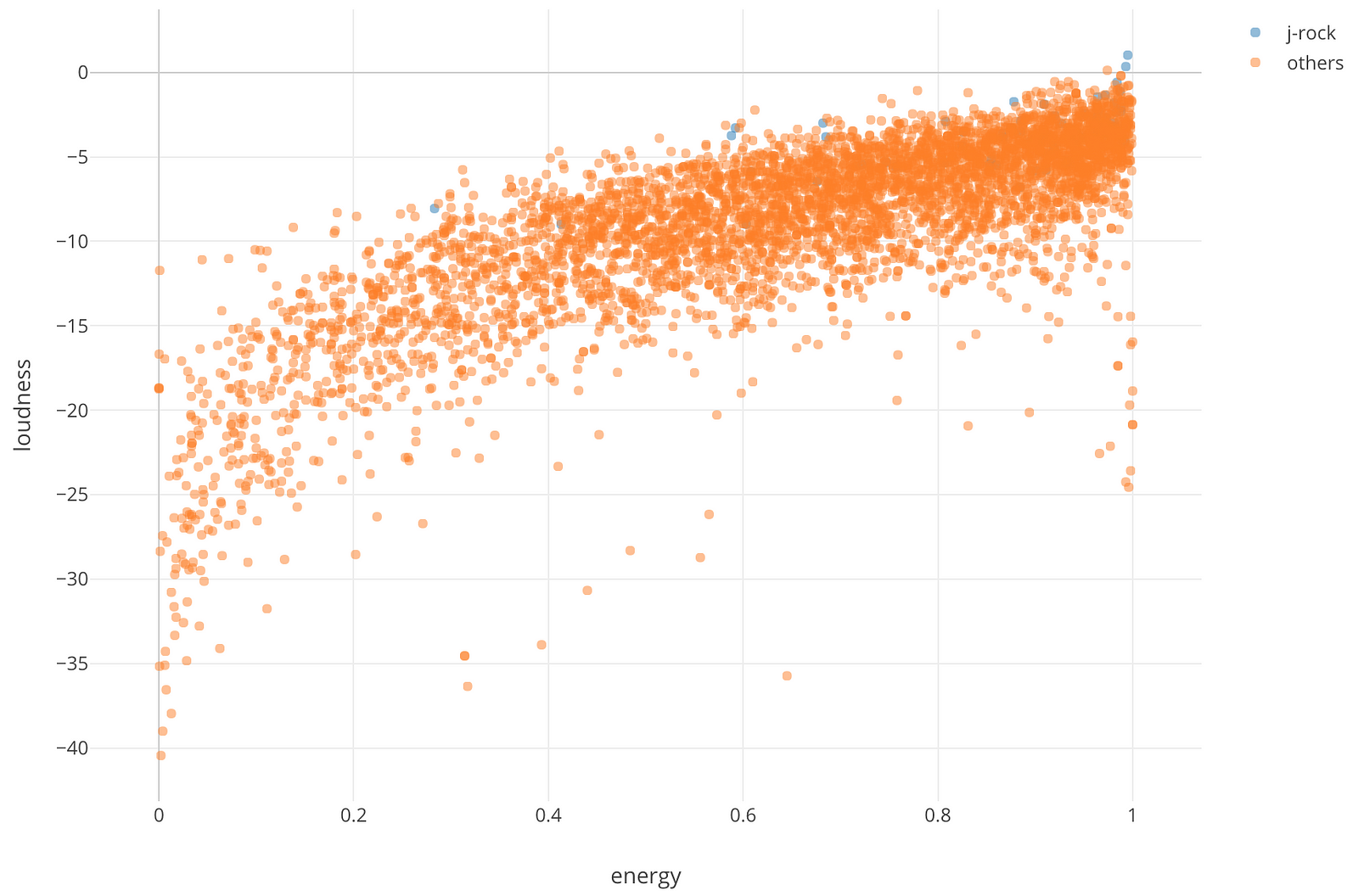
J-Rockは別のロックのカテゴリーであるRock、Hard-Rockと比べても、Loudness、Energyの属性で高いスコアを出している曲が多いようです。
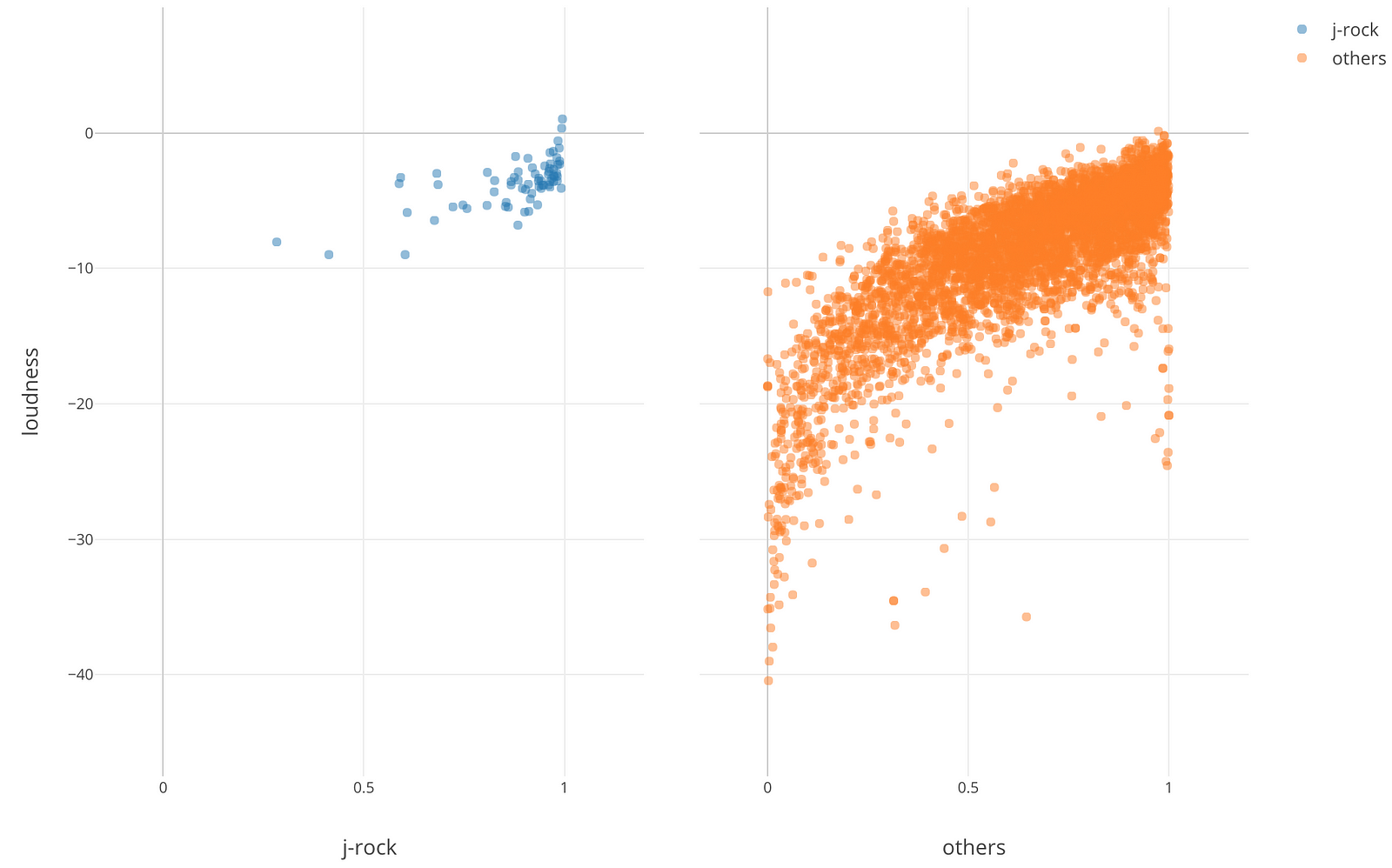
散布図でX軸にEnergyを、Y軸にLoudnessを割り当ててみると、確かにEnergyとLoudnessの値の両方大きい、右上のほうにJ-Rockの青色の点があることが確認できました。
J-Rockとその他のジャンルを横に並べて見ると、J-Rockが右上に多く集まっているのが分かります。
それではJ-RockはRock、Hard-Rockと比べてどういった違いがあるのでしょうか。このデータにある全ての属性からそのヒントを導き出したいと思います。
9つほどの属性があるのでそれらを一つ一つ見いくのは時間がかかりそうなので、ここでは、まずPCA(主成分分析)という次元削減によく使われる統計のアルゴリズムを使って調べてみましょう。
J-Rockの分析 — PCA (主成分分析)
Exploratoryでは、アナリティクスビューの下で主成分分析のアルゴリズムに簡単にアクセスすることができます。
”変数の列”で以下の属性の列を選択します。
- danceability
- energy
- loudness
- speechiness
- acousticness
- instrumentalness
- liveness
- valence
- tempo

そして実行ボタンを押して、Biplotのタブに行くと、以下のようなチャートが見られます。
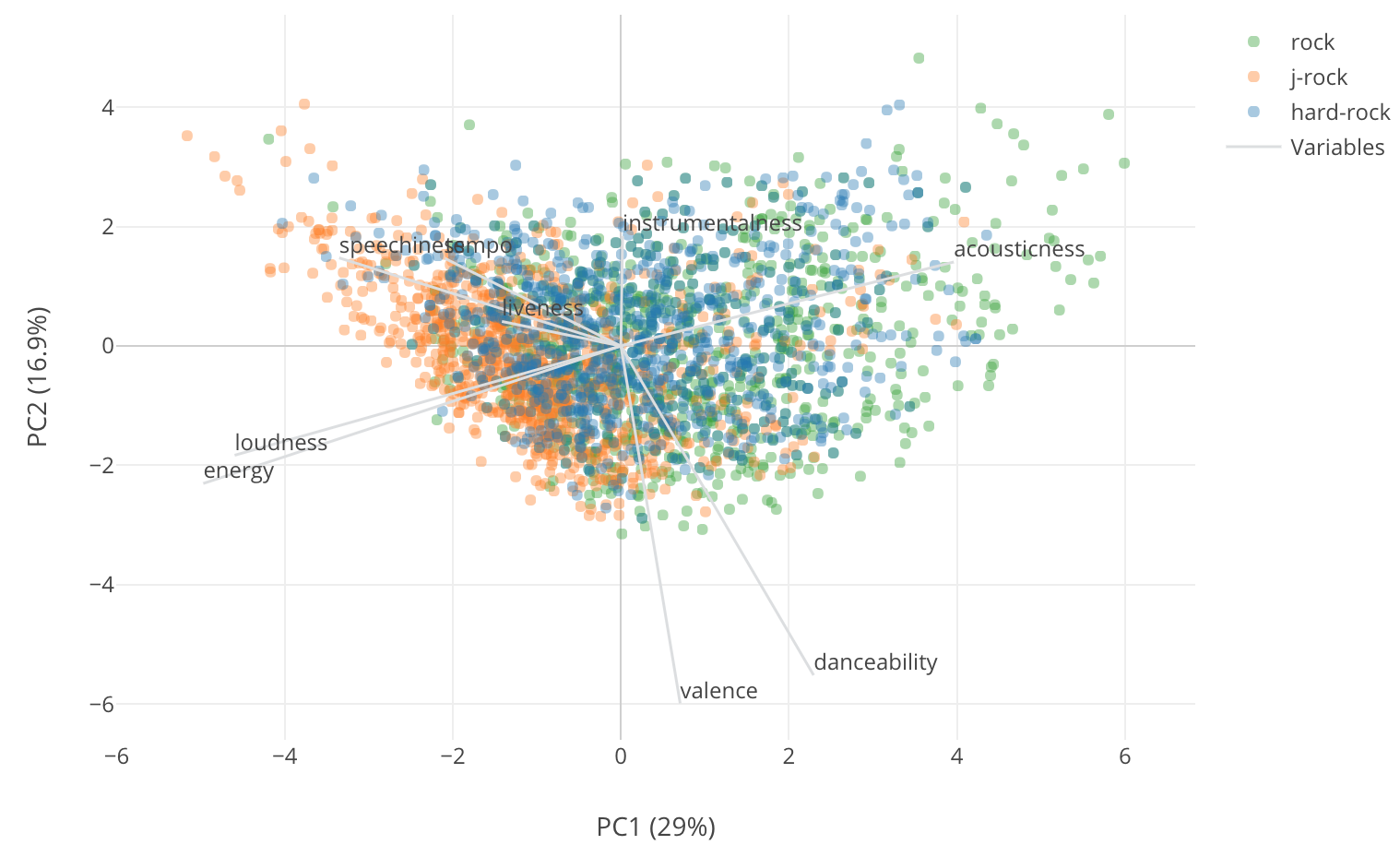
このチャートでは、それぞれの曲が点として2次元の散布図の上に表されています。このX軸とY軸は、もともとあった9つの次元(9つの音楽の属性)を、もとの情報量をなるべく失わないように、2つの次元に削減することで導き出された架空の次元です。
そして同じ散布図の上にもとの9つの属性がそれぞれ灰色の線となって表されています。この灰色の線がXとYの軸に対する意味を与えます。灰色の線をもとに説明するなら、PC1というX軸は負のほうに振れるとLoudness、Energy、Speechinessの値が高くなることを意味し、正の方に振れるとAcousticの値が高くなるということを意味します。つまり、このX軸は曲のうるささ、もしくは静かさを表しているとも言えます。
また、PC2というY軸は負の方向に行くとValence、Danceabilityが高くなり、逆に正の方向に行くと、Instrumentalnessが高くなるとということで、これは曲の持つ感情などを表していると言えるかもしれません。
さて、ここで見たいのはJ-RockがRockやHard-Rockと比べてどう違うのかです。このチャートでは色がジャンルを表し、オレンジがJ-Rockです。
ここで明らかにわかるのはJ-Rockの曲の多くが他の二つのジャンルの曲に比べてものすごくX軸の負の方向に振れているということです。つまり、J-RockはLoudness、Energey、Speechinessという属性が他に比べて高いというのが分かります。
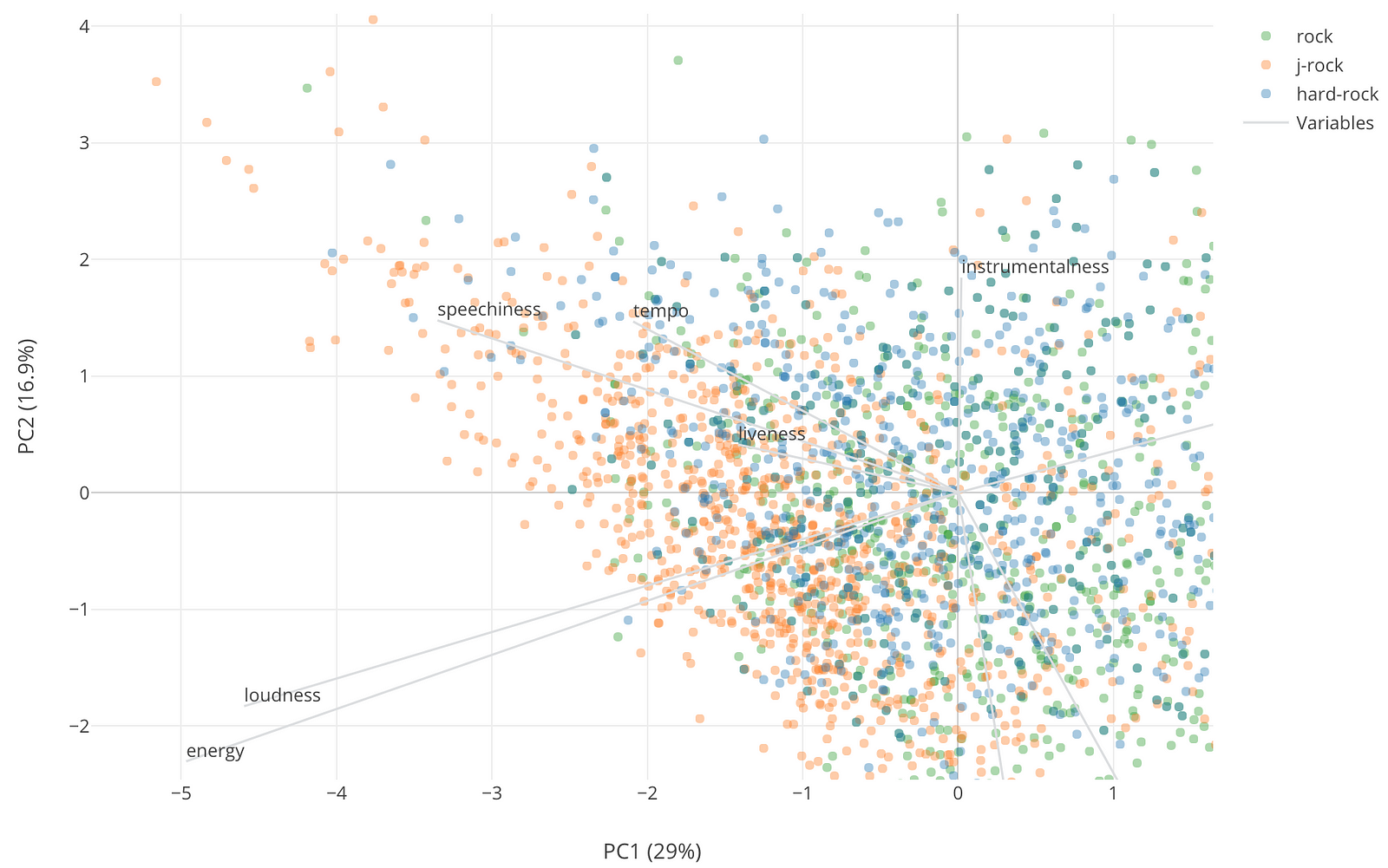
それに比べて、ある意味予想はできていたことですが、Rock(緑)はAcousticの方向にふれているのが分かります。
J-Rockと似ているジャンルは?
J-RockはRockやHard-Rockと以外に違う性質を持っていることが分かりました。それではJ-Rockにより近い性質を持つジャンルというのはあるのでしょうか?
この質問に答えるために、距離のアルゴリズムを使ってジャンル毎の距離を計算した上で、類似性を調べてみましょう。
まずは各属性の値を正規化して同じスケールに揃えます。ここでは、Exploratory Rパッケージのnormalizeという関数を使います。
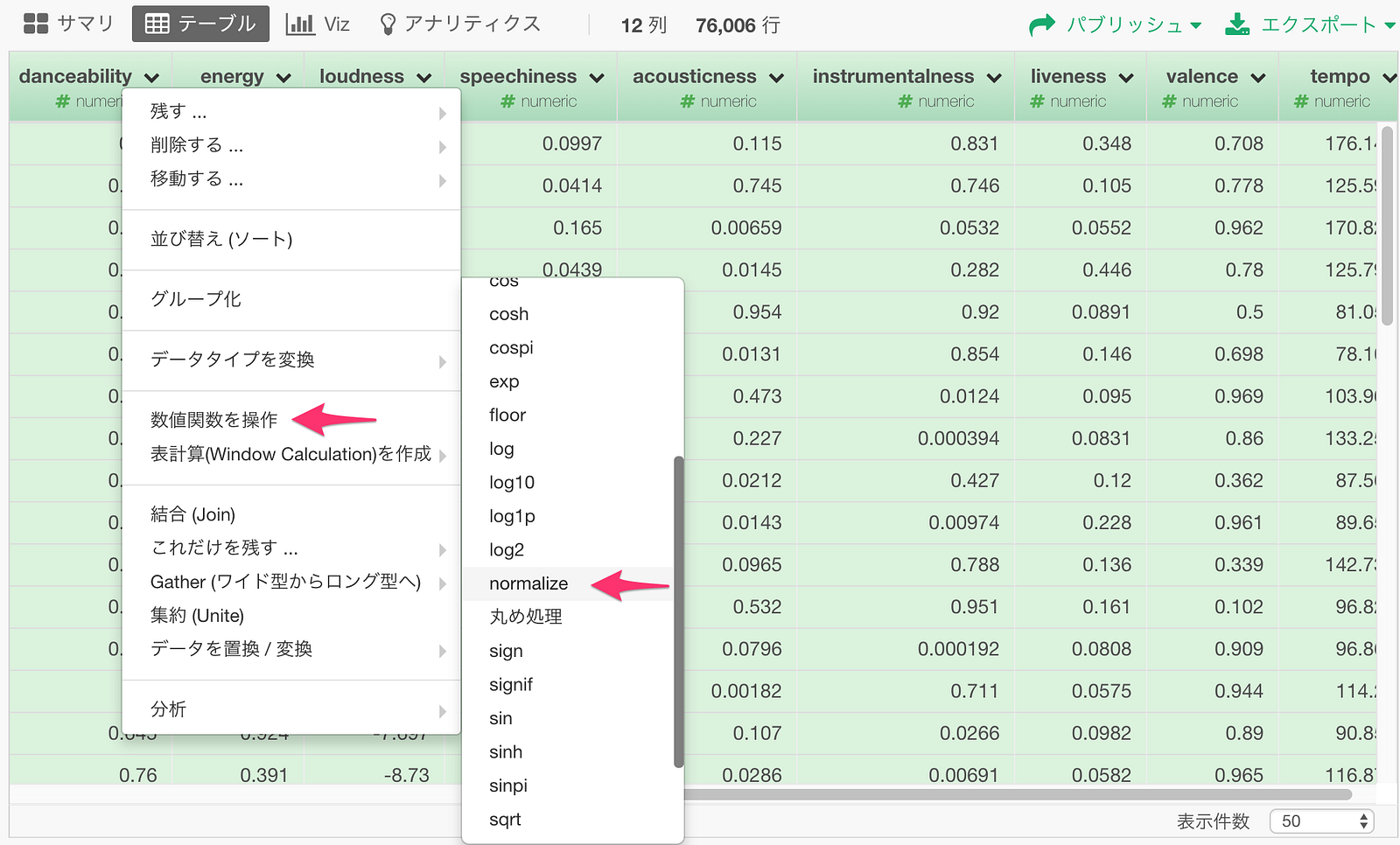
一つ一つの列に対してやるとめんどくさいので、いっぺんに全ての属性の列に対してやってしまいましょう。danceabilityからtempoまでをCommandキーをクリックしながら選択し、列ヘッダーメニューから”数値関数を操作”
-> “normalize”を選びます。
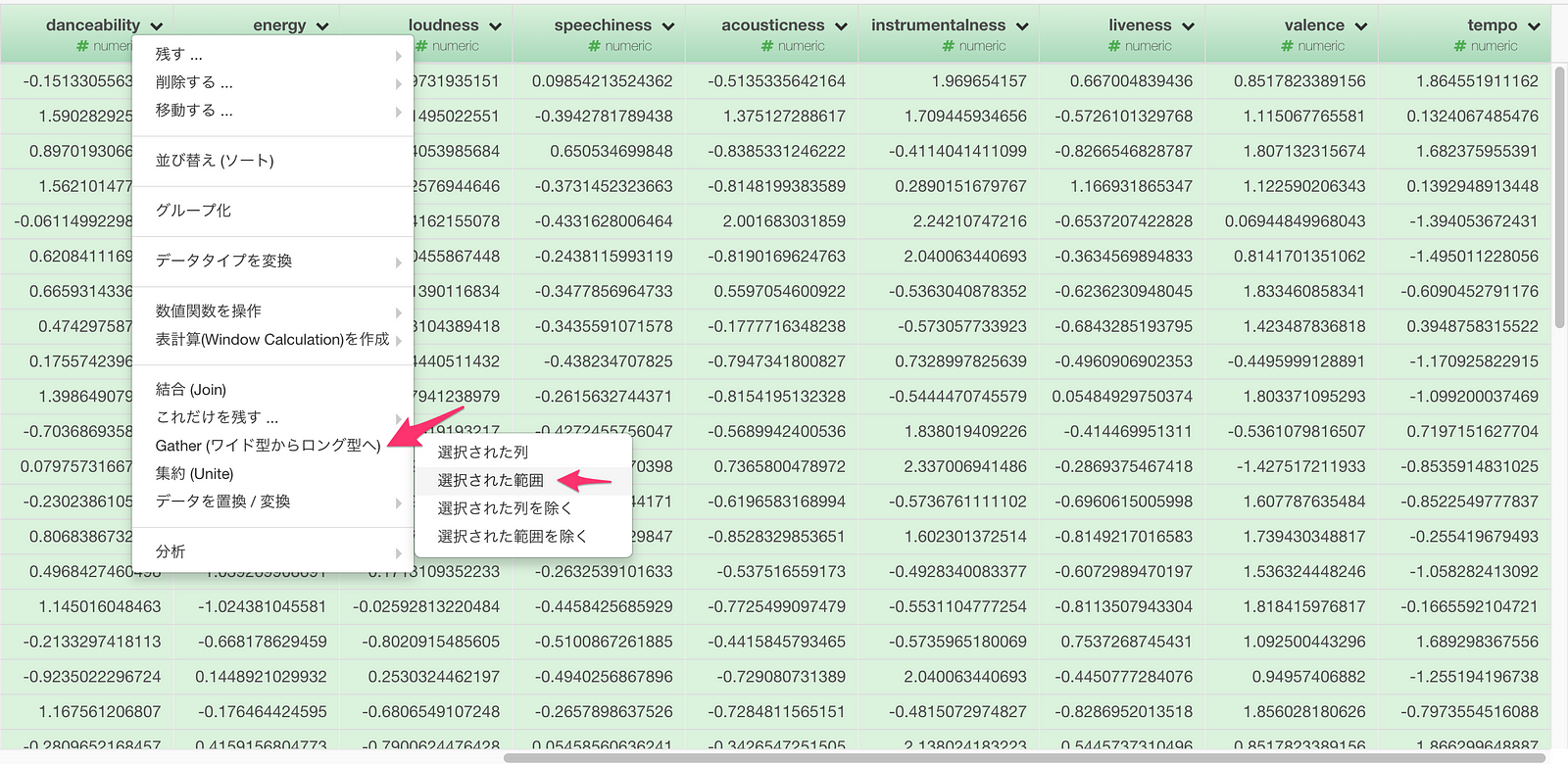
次に、ジャンル毎の距離を計算するには、データを一度、属性がキー列に、その値がバリュー列に入るロング(縦長)型にする必要があります。
属性列をCommand キーを押しながらクリックして選択して、列ヘッダーメニューからGather (ワイド型からロング型)を選びます。
すると、以下のようにロング(縦長)のデータフレームになりました。
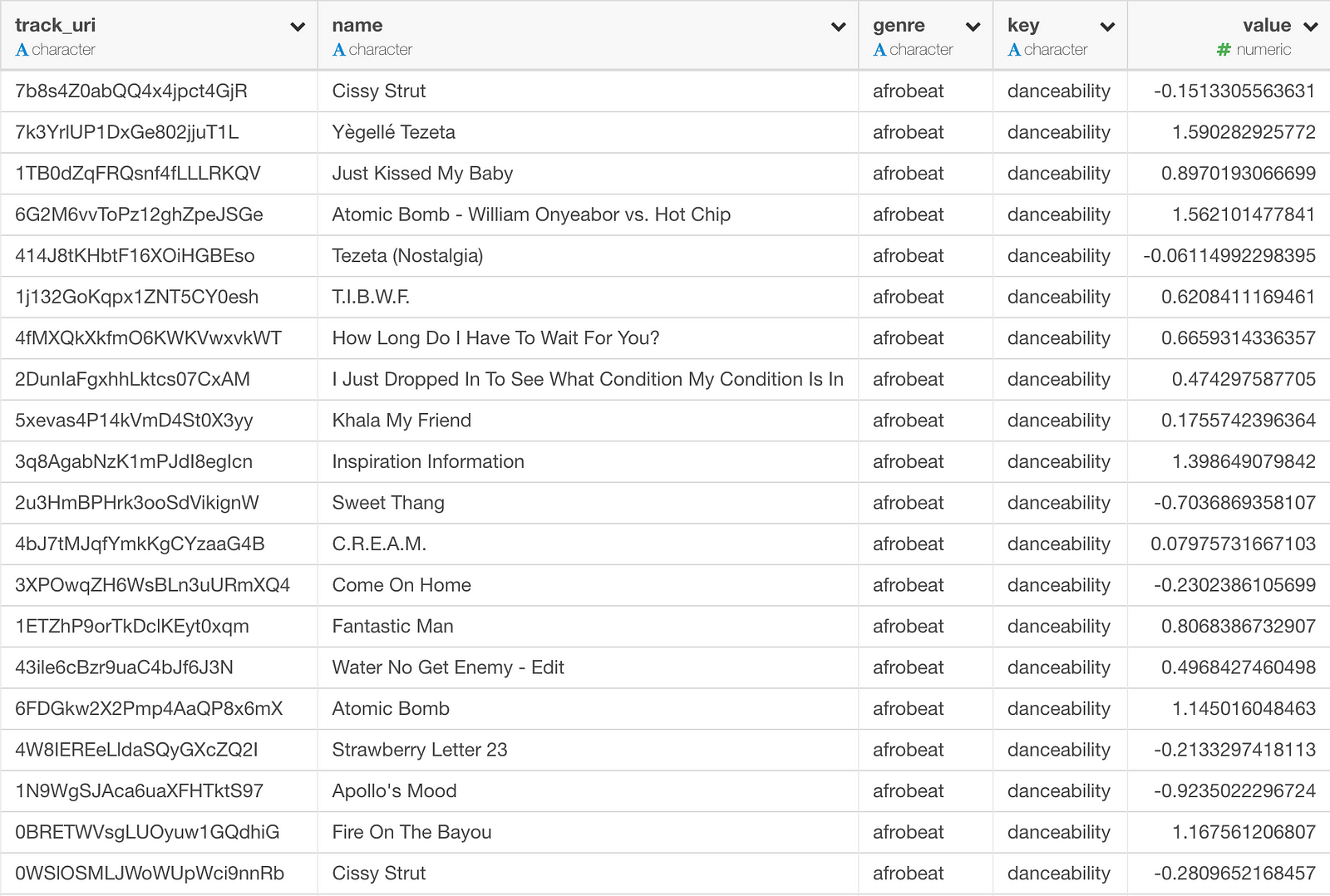
これで、距離のアルゴリズムを使うためのデータの準備ができました。
アナリティクスビューに行き、タイプにカテゴリーごとの距離
を選び、カテゴリーにgenre列を、メジャーの計算単位に各属性のキーの入ったkey列を、そしてメジャーに属性の値の入ったvalue
列を指定します。集計関数としては**平均(AVG)**を指定します。
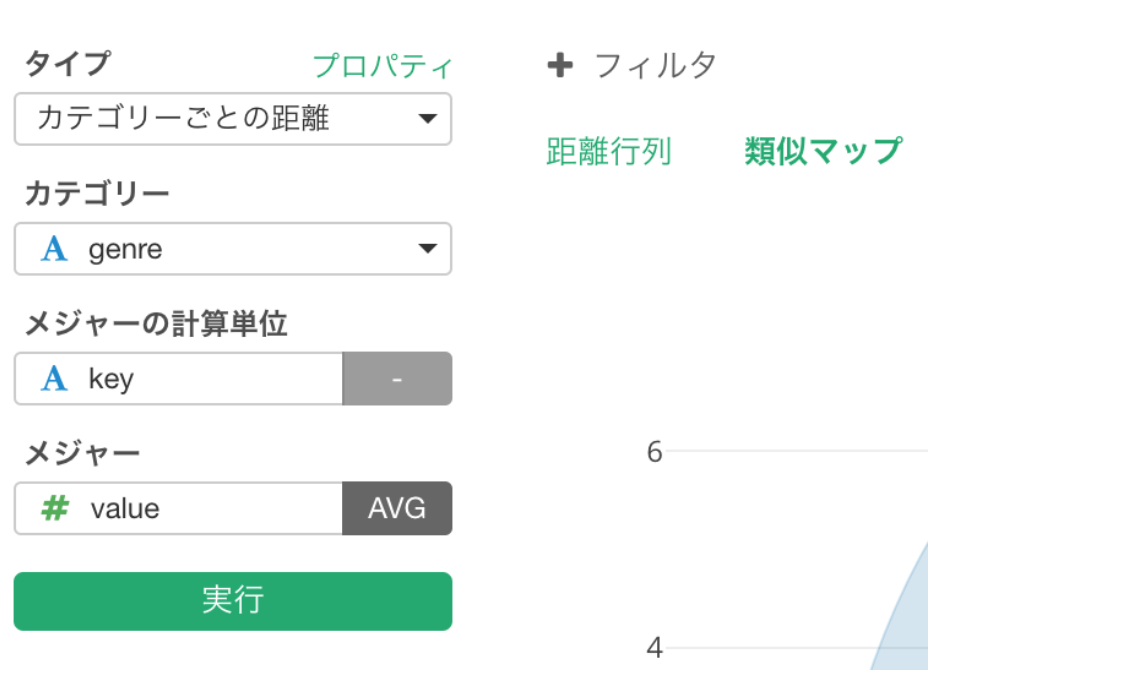
実行ボタンを押すと、以下のような結果が出てきます。
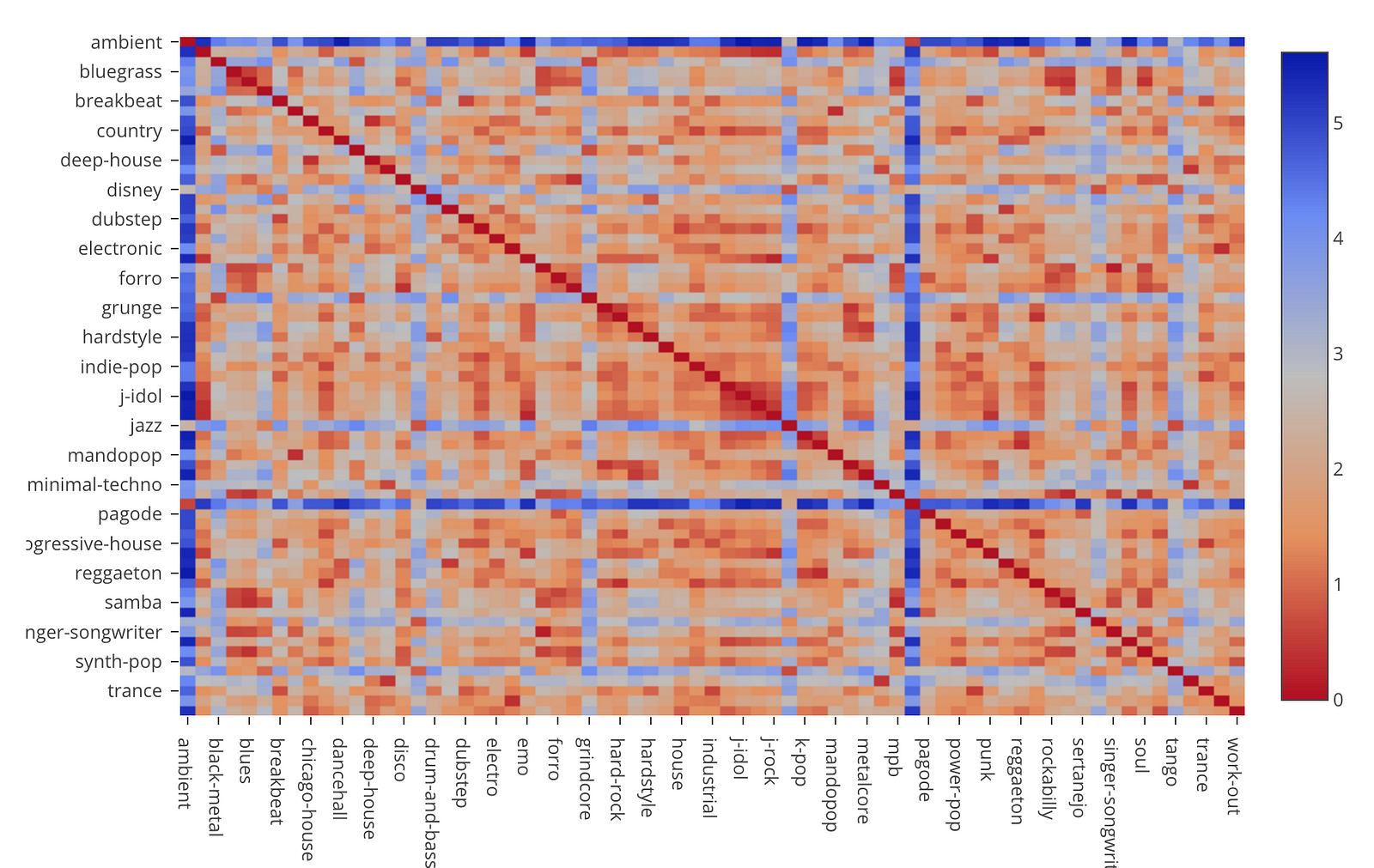
これは、それぞれのジャンルの組み合わせ毎の距離をヒートマップで表したものですが、それよりも、この情報をMDS(Multi-Dimensional Scaling / 多次元尺度構成法)というアルゴリズムを使って2次元空間に表したほうが全体的な関係性がひと目で分かります。
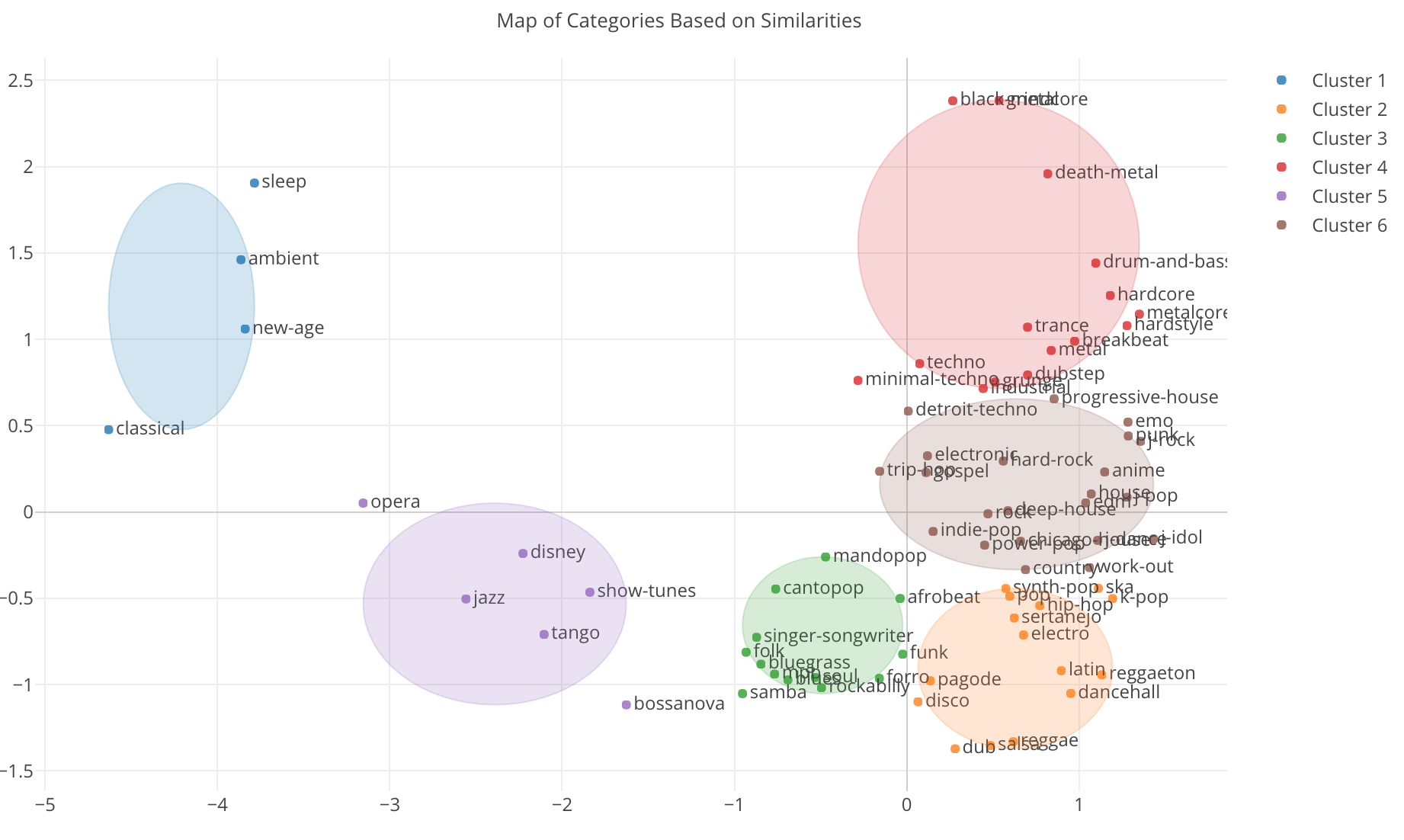
これは、類似マップというタブに行くことで以下のようなチャートとして見えます。
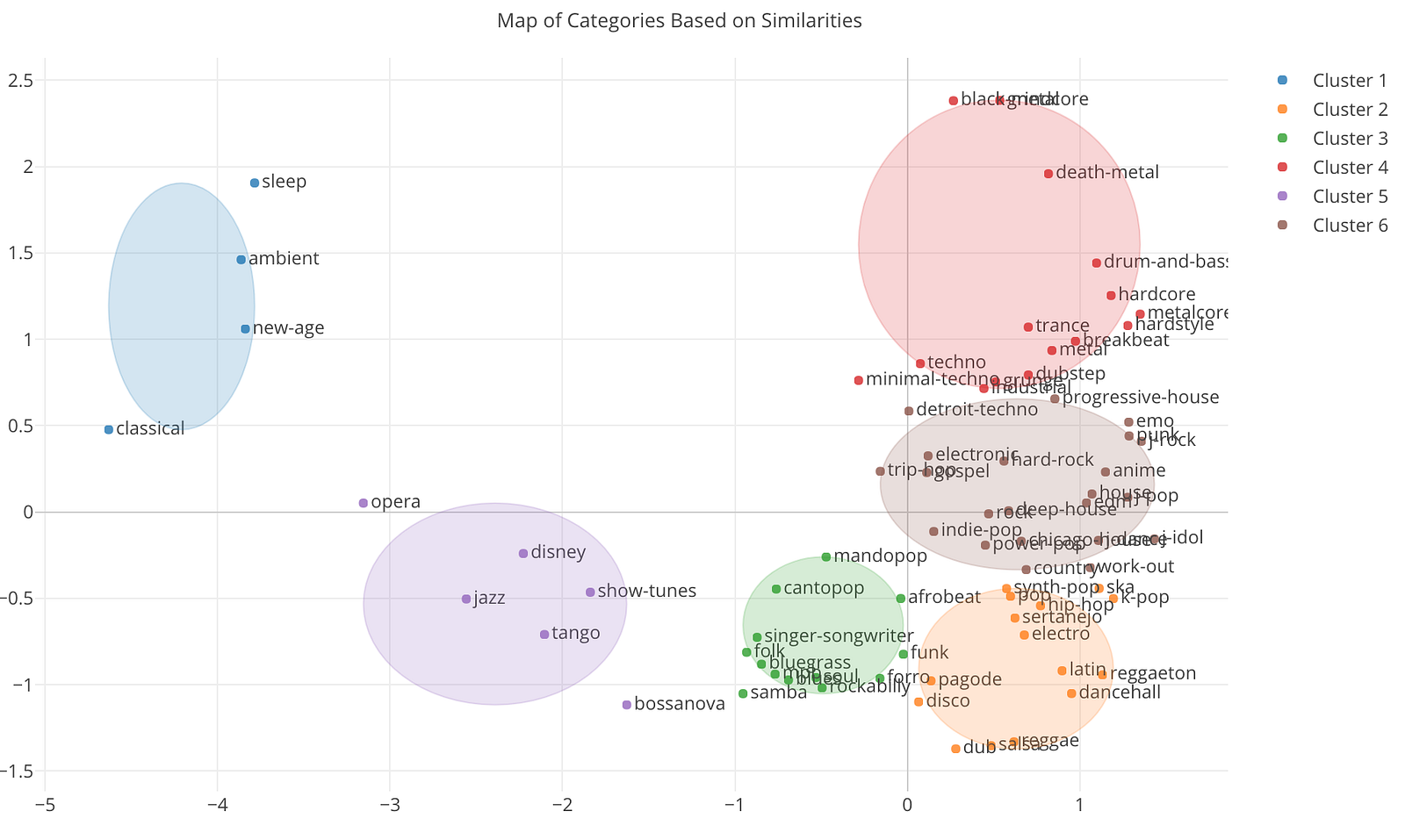
ちなみに、こちらはクラスターの数を6個になるようにプロパティで設定しています。
左から青、紫、緑、オレンジ、茶色、赤の6つのクラスタが表示されました。青のグループにはclassical(クラッシック)、ambient(アンビエント)、sleepといった眠くなりそうな音楽のジャンルがまとまっています。
レゲー系の音楽が右下の方に集まっているのも分かります。dub、dancehall、reggae、reggaetonといった具合です。この近くにはSalsa(サルサ)やLatin(ラテン)もあるので、この辺のジャンルは同じカリビアンということで、曲の特徴も似ているのでしょう。
この他にも結構いい感じにジャンルがまとまっています。
さてここで、私が知りたかったのはJ-Rockと似ている他のジャンルですが、これは茶色のグループの右端の方にあります。下はズームインしたものです。
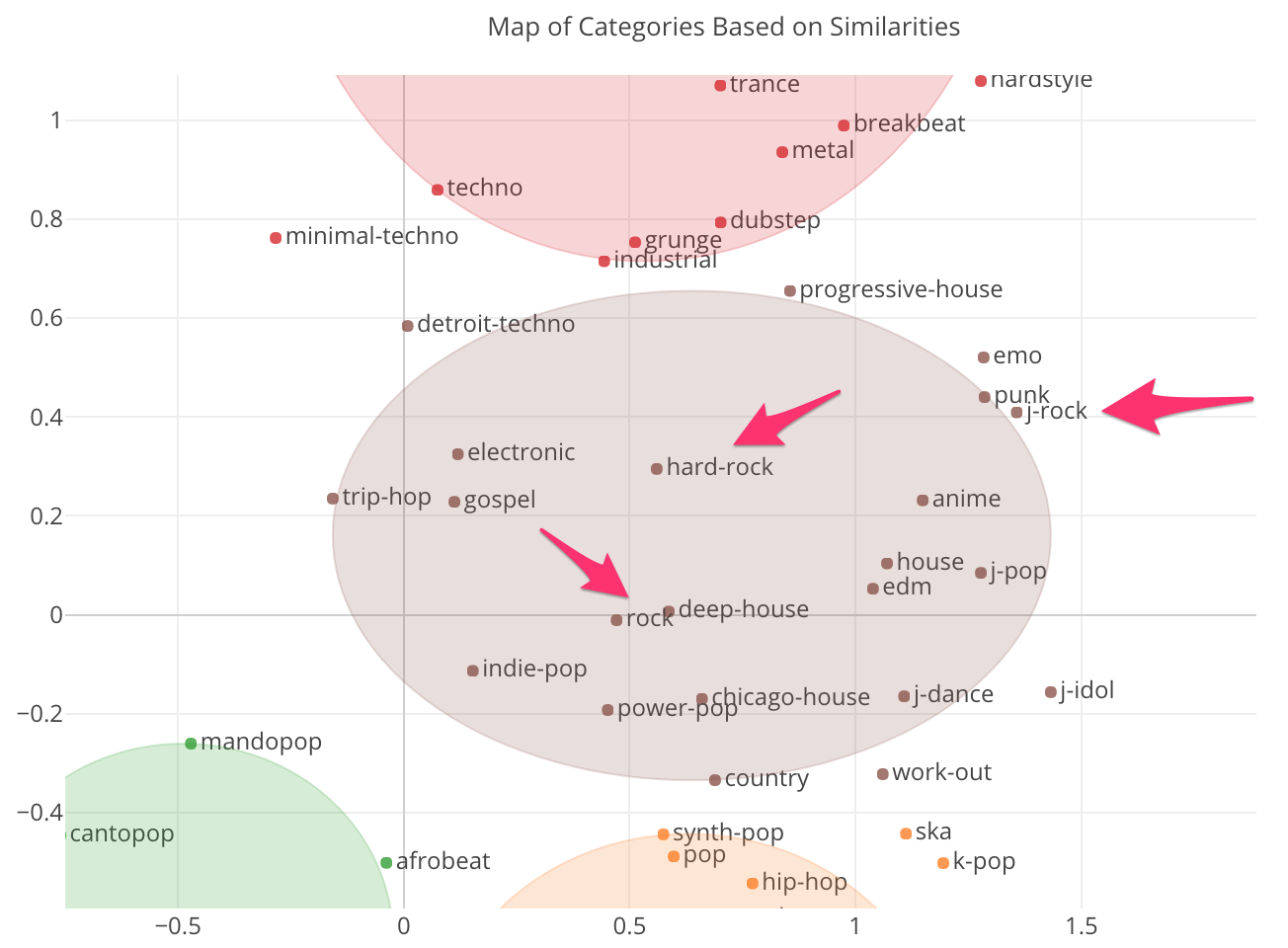
そして、一番近いところにいるのはPunk(パンク)で、その次はEMO(エモーショナル・ロック)です。J-Rockとは単純に日本のロックと言うよりも、もっとパンク・ロックやエモーショナル・ロックに近いものということですね。
ちなみに、J-Rockをあまり知らないという方のために、こちらにSpotifyのJ-Rockのプレイリストがあります。
まとめ
今回は、SpotifyのAPIを使って、ジャンル毎に曲とその属性データをインポートし、ジャンル毎の類似性を分析してみました。
そして、J-Rockがロックやハード・ロックというよりも、むしろパンク・ロックやエモーショナル・ロックに近いということがわかりました。
何となく知っているつもりだった音楽のジャンルも、こういった曲の属性データを使って改めて分析すると、全体像が効率的に浮かび上がってくるのでおもしろいですね。
まだExploratory Desktopをお持ちでない場合は、こちらから30日間無料でお試しいただけます。
データサイエンスを本格的に学んでみたいという方へ
この6月に、Exploratory社がシリコンバレーで行っているトレーニングプログラムを日本向けにした、データサイエンス・ブートキャンプが東京で行われます。データサイエンスの手法を基礎から体系的に、プログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に、参加を検討してみてください。