📝 概要
| 項目 | 内容 |
|---|---|
| 所要時間 | 約1時間 |
| メインサービス | AWS Glue DataBrew, Amazon S3 |
| 学べること | ノーコードでのデータクレンジング、データ品質改善、変換処理の基礎 |
| 想定費用 | 約300円(※データ量・実行回数により変動します) |
⚠️ 注意:以下のリソースを削除し忘れると課金が継続します。
- AWS Glue DataBrew
- Amazon S3バケット内のデータ
🎯 課題内容
ECサイトのレビューデータに対して、AWS Glue DataBrewを使用してノーコードでデータクレンジングと加工を行います。データ品質の問題を特定し、分析可能な状態に整形していきます。
データの課題
提供されるレビューデータ(handson_reviews_data.csv)には以下のような品質問題が含まれています:
- 重複したレビューID
- 商品タイトル、商品カテゴリー、レビュータイトル、レビュー本文の前後に不要な空白を含むテキストがある
- 評価値(
star_rating)が範囲外の可能性(範囲:1-5) - 商品カテゴリー名が正規化できていない(小文字に統一する必要がある)
📊 アーキテクチャ図
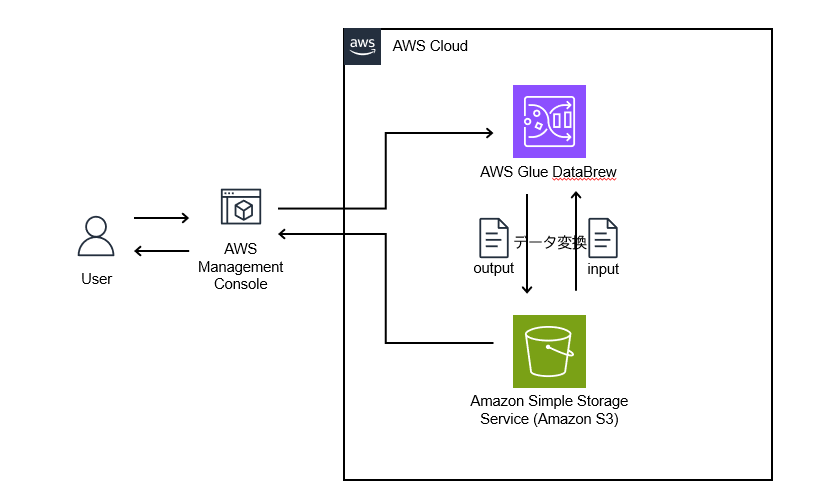
🔧 実装機能
- S3バケットにレビューデータをアップロード
- Glue DataBrewでデータセットを作成し、データプロファイルを実行
- データ品質の問題を可視化・特定
- レシピを作成してデータクレンジング・変換を実行
- 重複したレビューIDの削除
- 商品タイトル、商品カテゴリー、レビュータイトル、レビュー本文の前後に不要な空白削除
- 範囲外の評価値(
star_rating)を削除(範囲:1-5) - 商品カテゴリーの正規化
- ジョブを実行して加工済みデータをS3に出力
- 結果の検証
💡 実装のヒント
DataBrewのプロジェクトとジョブの違い
- プロジェクト: データの探索とレシピ(変換手順)の作成に使用します。インタラクティブなセッションで、変換の結果をすぐに確認できます。
- ジョブ: 作成したレシピを実際のデータセット全体に適用して、結果をS3に出力します。本番運用での定期実行に使用します。
開発フローは「プロジェクトでレシピ作成 → ジョブで本番実行」となります。
データプロファイルの活用方法
DataBrewのデータプロファイル機能を使うと、以下の情報が自動で分析されます:
- 各カラムのデータ型と統計情報
- 欠損値の割合
- ユニーク値の数
- 値の分布(ヒストグラム)
- 異常値の検出
この情報を基に、どのようなクレンジングが必要か判断しましょう。
よく使う変換レシピ
DataBrewには250以上の組み込み変換があります。このハンズオンでよく使うものは:
- REMOVE_DUPLICATES: 重複行の削除
- DELETE_MISSING_VALUES: 欠損値を含む行の削除
- FILL_WITH_VALUE: 欠損値を特定の値で埋める
- TRIM: 文字列の前後の空白を削除
- CHANGE_DATA_TYPE: データ型の変更
- FILTER_VALUES: 条件に基づく行のフィルタリング
- CREATE_COLUMN: 新しいカラムの作成
✅ 完成後のチェックポイント
- S3バケットにCSVファイルがアップロードされている
- DataBrewでデータセットが作成され、データが正しく読み込まれている
- データプロファイルジョブが実行され、品質問題が特定できている
- レシピに最低4つ以上の変換ステップが含まれている
- ジョブが成功し、加工済みデータがS3の出力先に保存されている
- 出力データに重複などがないことを確認できている
- 元データと比較して、行数・データ品質が改善されていることを確認できている
🧰 使用資材
サンプルデータ(オリジナルで作成しても良いですが、こちらのサンプルを使用しても構いません。):handson_reviews_data.csv
このハンズオンでは handson_reviews_data.csv を使用します。
こちらのリンク先のデータをコピーし、handson_reviews_data.csv という名前でファイルを作成して、S3にアップロードしてください。
※ダウンロードし、解凍してからご使用ください。

データ構造:
-
marketplace: マーケットプレイス(JP) -
customer_id: 顧客ID -
gender: 性別(M/W) -
age: 年齢 -
review_id: レビューID -
product_id: 商品ID -
product_parent: 商品親ID -
product_title: 商品名 -
product_category: 商品カテゴリ -
star_rating: 評価(1-5の整数) -
helpful_votes: 役立った投票数 -
total_votes: 総投票数 -
vine: Vineプログラム(Y/N) -
verified_purchase: 購入確認済み(Y/N) -
review_headline: レビュータイトル -
review_body: レビュー本文 -
review_date: レビュー日付
含まれるデータ品質問題:
- 重複したレビューID
- 商品タイトル、商品カテゴリー、レビュータイトル、レビュー本文の前後に不要な空白を含むテキストがある
- 評価値(
star_rating)が範囲外の可能性(範囲:1-5) - 商品カテゴリー名が正規化できていない(小文字に統一する必要がある)
🔗 リファレンスリンク
🛠️ 解答・構築手順(クリックで開く)
解答と構築手順を見る
✅ ステップ1:S3バケットの作成とデータアップロード
- AWSマネジメントコンソールにログイン
- S3サービスを開く
- 「バケットを作成」をクリック
- バケット名:
glue-databrew-handson-<your-name>-<random>(グローバルでユニークな名前) - リージョン:任意(東京リージョン推奨:ap-northeast-1)
- その他の設定はデフォルトのまま
- バケット名:
- 作成したバケット内に以下のフォルダ構造を作成:
-
input/- 元データ格納用 -
output/- 加工済みデータ出力用
-
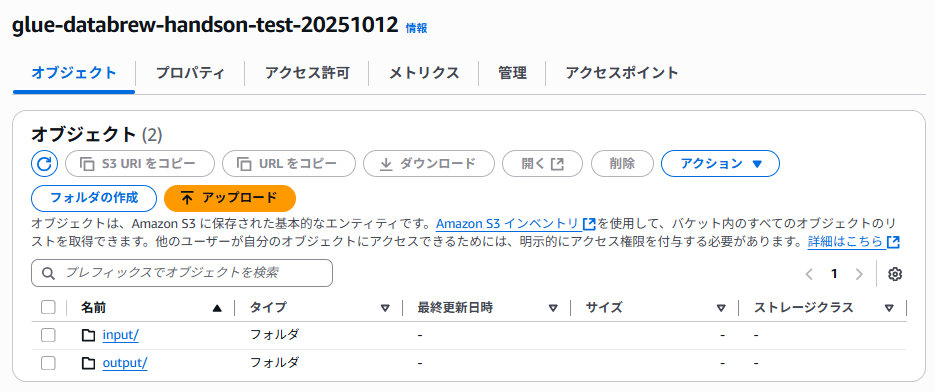
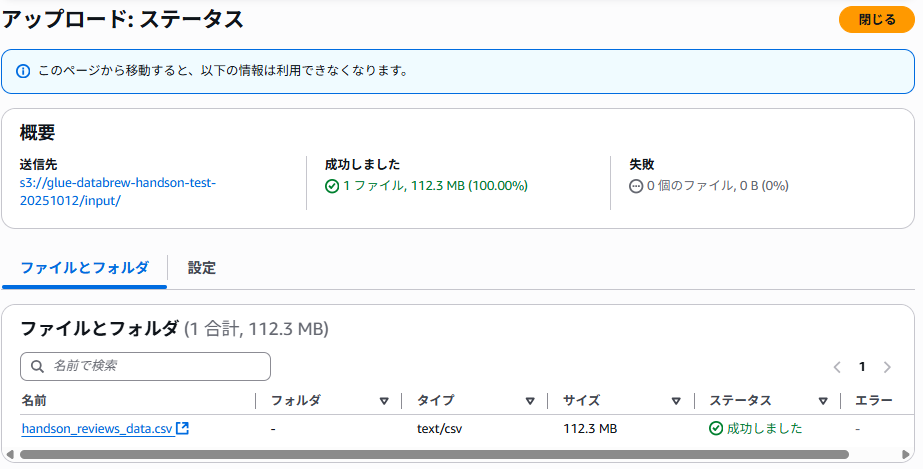
-
handson_reviews_data.csvをinput/フォルダにアップロード
✅ ステップ2:IAMポリシーとIAMロールの作成
- IAM サービスを開く
- 「ロール」→「ロールを作成」
- 信頼されたエンティティタイプ:AWSのサービス
- ユースケース:DataBrew を選択
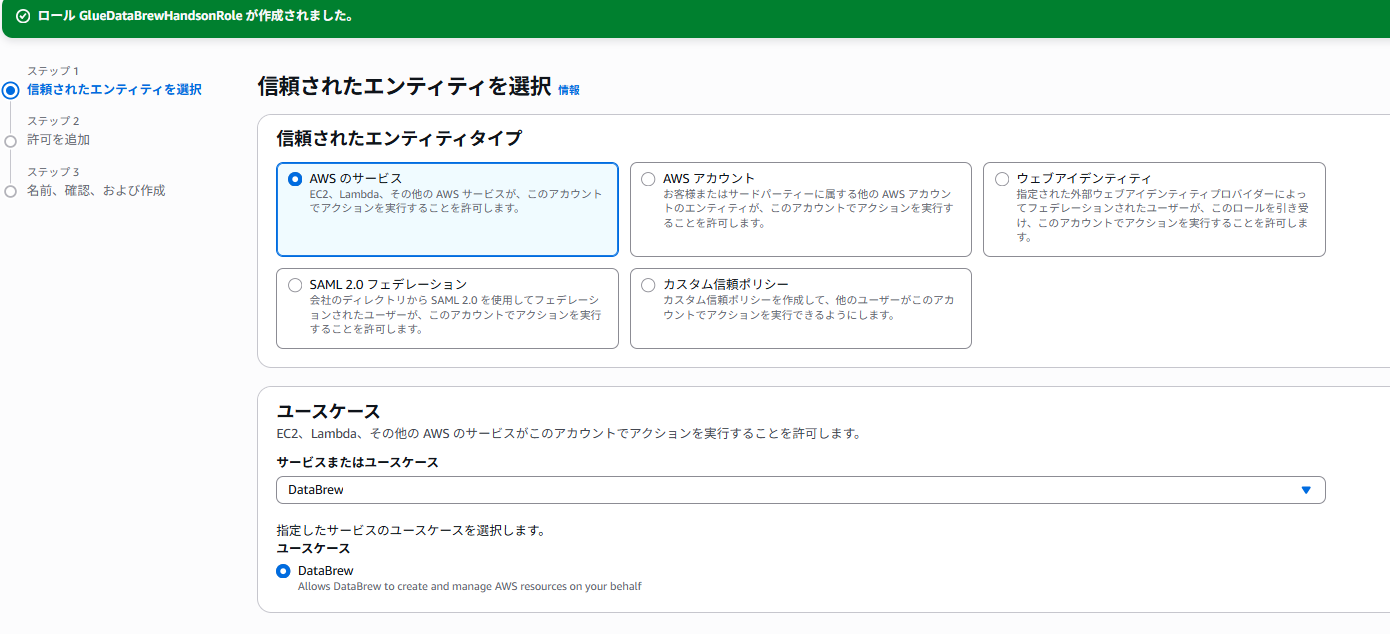
- 許可ポリシー:
AWSGlueDataBrewServiceRole-
AmazonS3FullAccess(本番環境では必要最小限の権限に絞ること)
- ロール名:
GlueDataBrewHandsonRole - 「ロールを作成」をクリック
✅ ステップ3:DataBrewでデータセットを作成
- AWSマネジメントコンソールで AWS Glue DataBrew を開く
- 左メニューから「データセット」を選択
- 「新しいデータセットの接続」をクリック
- データセット設定:
- データセット名:
reviews-dataset - 「新しいデータセットへの接続」を選択
- データレイク/データストア: Amazon S3 Buckets
- S3一覧より自身の作成したバケットより
handson_reviews_data.csvを選択
- データセット名:
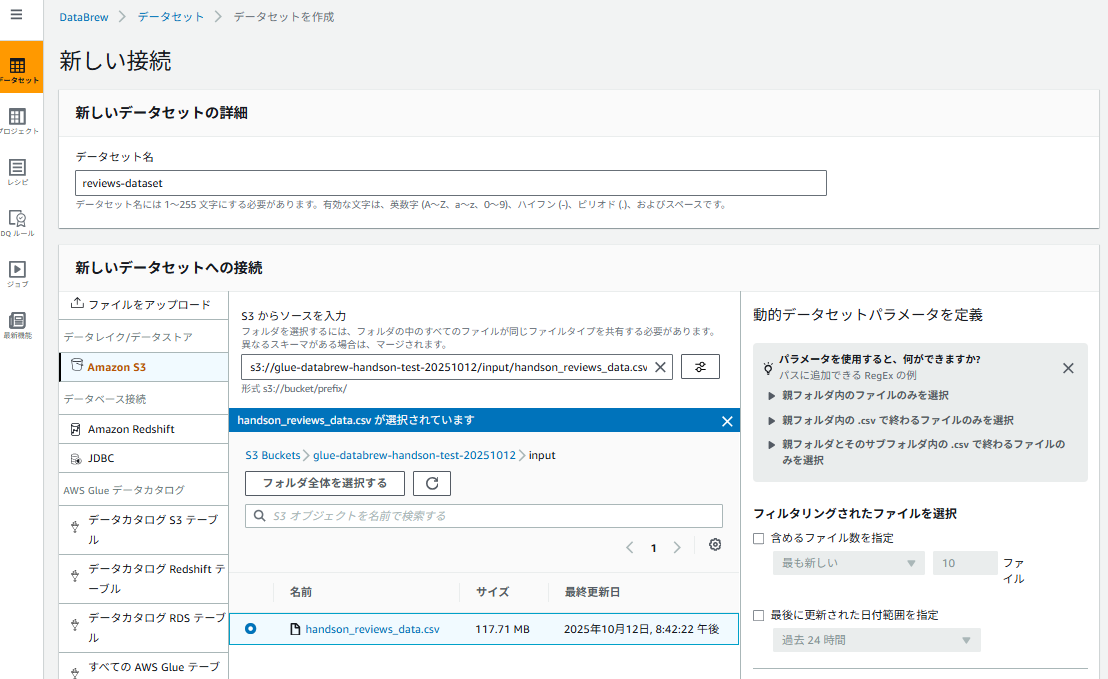
- 追加したファイルのタイプ: CSV
- CSV 区切り記号: カンマ(,)
- 列ヘッダー値: 最初の行をヘッダーとして扱う
- 「データセットを作成」をクリック
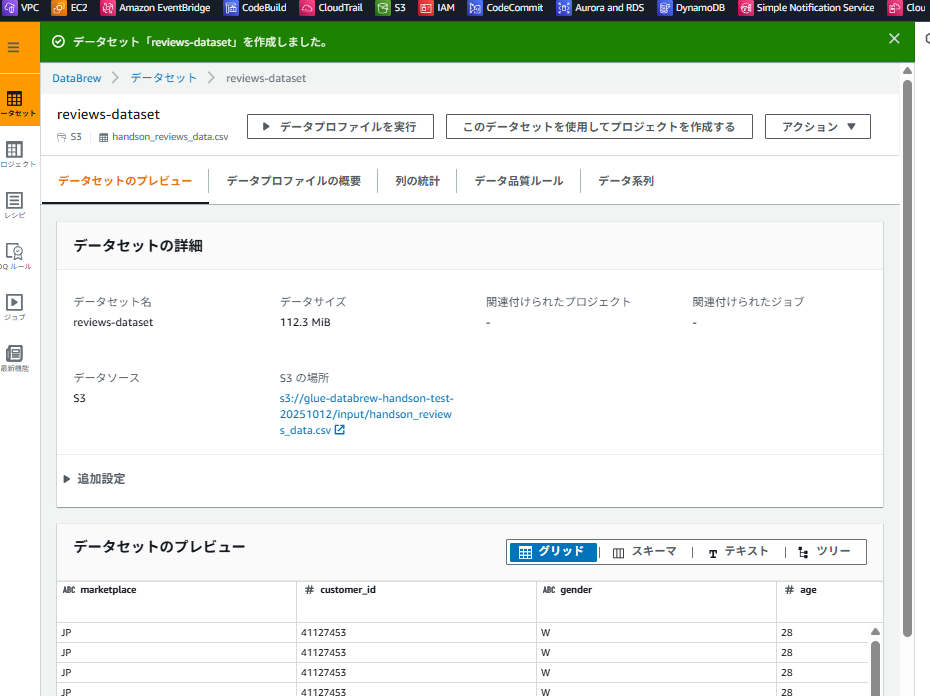
✅ ステップ4:データプロファイルジョブの実行
- 作成したデータセット「reviews-dataset」を選択
- 画面上部の「データプロファイルを実行」をクリック
- プロファイルジョブの設定:
- ジョブ名:
reviews-profile-job - ジョブ実行サンプル: 完全なデータセット
- ジョブ出力設定:
- S3の場所:
s3://自身の作成したS3バケット名/output/profile/※参照を押下して「output」ファイルを選択後、「profile/」を追記
- S3の場所:
- 許可: 先ほど作成した
GlueDataBrewHandsonRoleを選択
- ジョブ名:
- 「ジョブを作成し実行する」をクリック
- ジョブが完了するまで数分待機(ステータスが「Succeeded」になるまで)
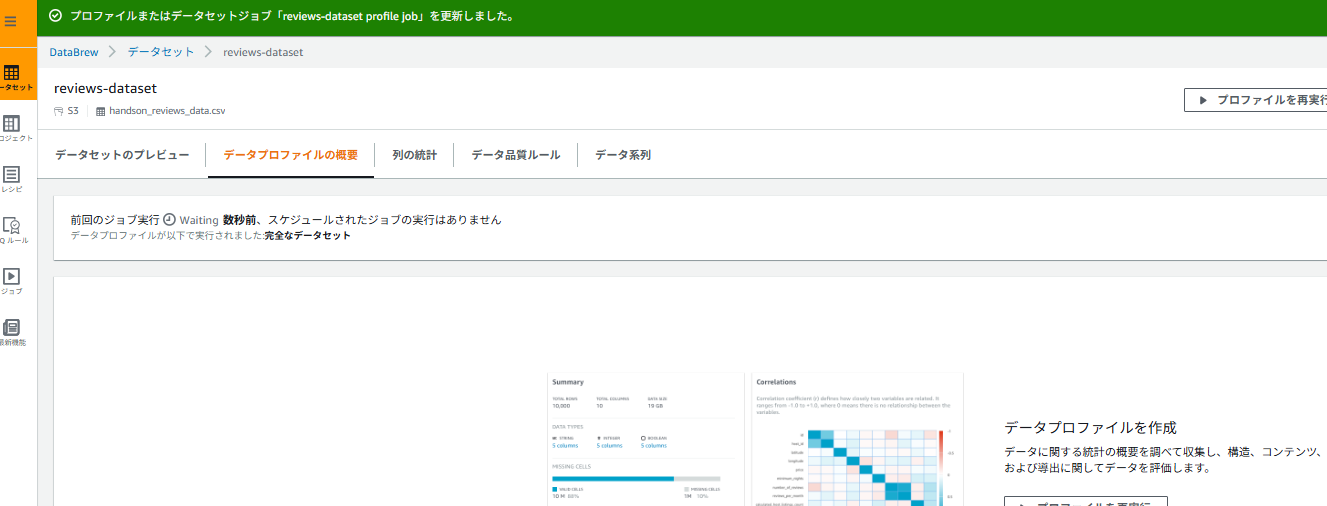
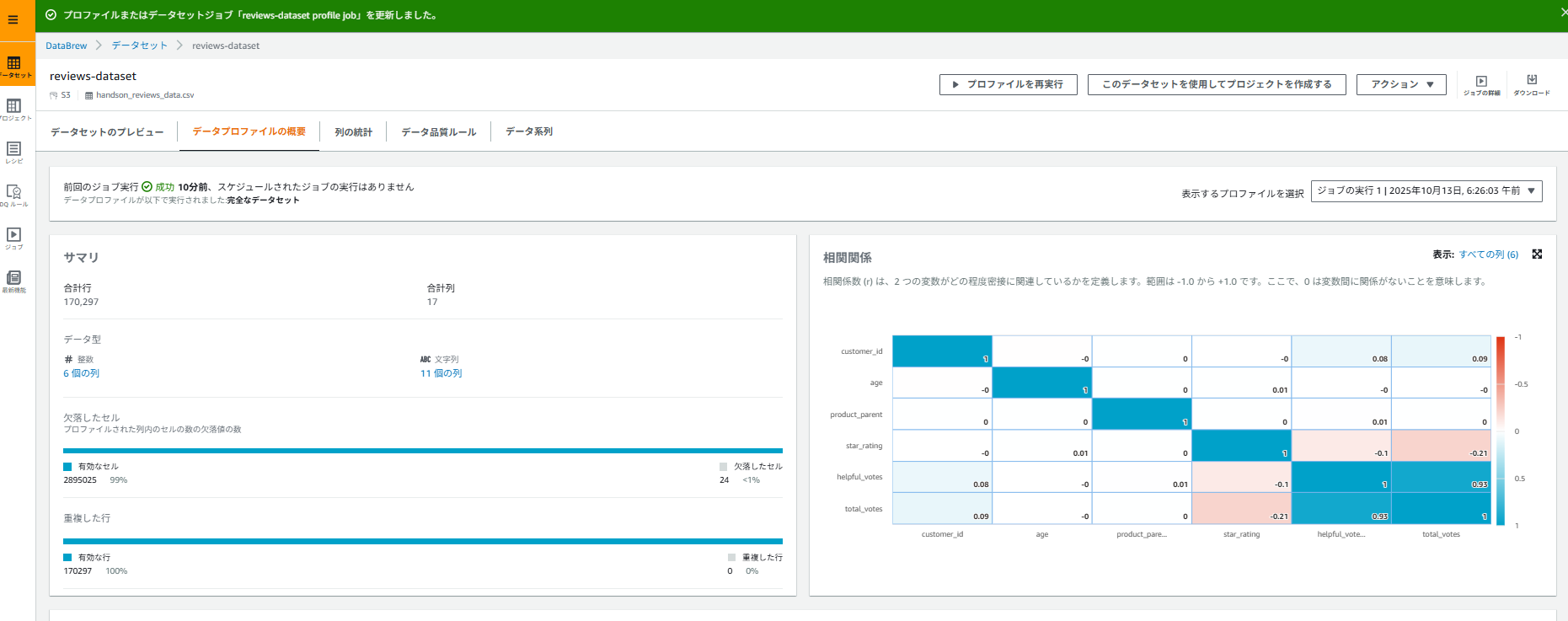
確認ポイント:
- 各カラムの欠損値の割合
-
star_ratingカラムの値の分布(1-5以外の値があるか) -
review_dateカラムのフォーマット
✅ ステップ5:プロジェクトの作成とレシピ開発
- 左メニューから「プロジェクト」を選択
- 「プロジェクトを作成」をクリック
- プロジェクト設定:
- プロジェクト名:
reviews-cleaning-project - レシピ名:
reviews-cleaning-project-recipe - データセットを選択
reviews-dataset(作成済みのデータセット) - IAM role:
GlueDataBrewHandsonRole
- プロジェクト名:
- 「プロジェクトを作成」をクリック
- プロジェクトが開き、インタラクティブなデータ編集画面が表示されます
✅ ステップ6:データクレンジングレシピの作成
以下の順序で変換ステップを追加していきます。各ステップは画面右上の「Recipe」パネルに記録されます。
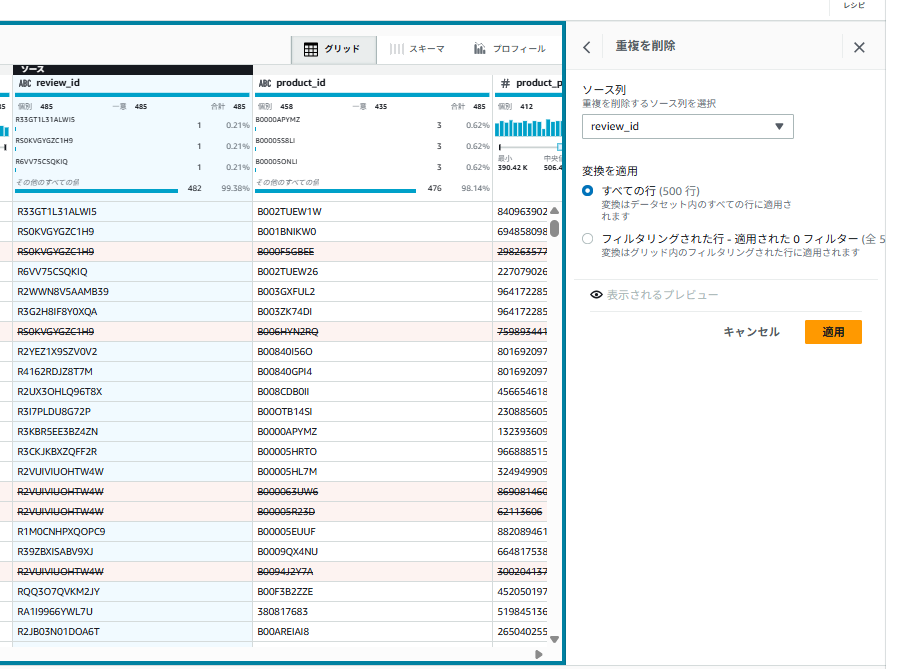
6-1. 重複行の削除
- 画面上部のツールバーから「重複」>「列内の重複した値を削除する」を選択
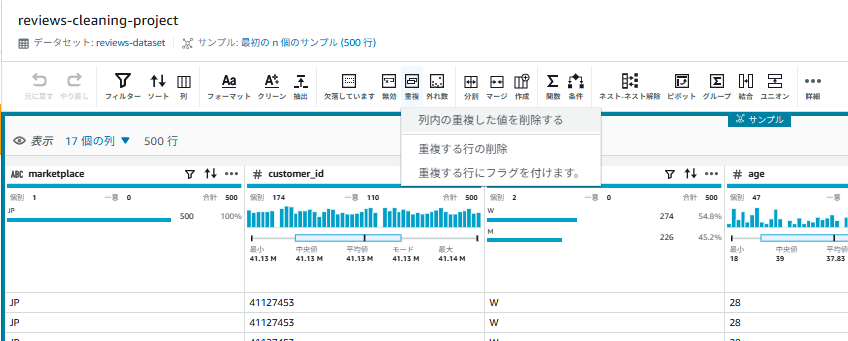
- 画面右側のソース列:「review_id」
- 変換を適用:すべての行
- 「変更のプレビュー」をクリックし、変更内容を確認する
- 「適用」をクリック
6-2. 空白のトリミング
-
product_titleカラムをクリック - 「…(3点リーダー)」の列アクションより「クリーン」→「連続する空白」を選択
- 削除する値を指定します:「ホワイトスペース」,「先頭と末尾のスペース」
- 「変更のプレビュー」をクリックし、変更内容を確認し、「適用」をクリック
- 同様に
product_category,review_headline,review_bodyカラムにも適用
※元データのcsvファイルには以下のようにproduct_title ,product_category, review_headline, review_bodyのデータの先頭と末尾に空白が存在しています。

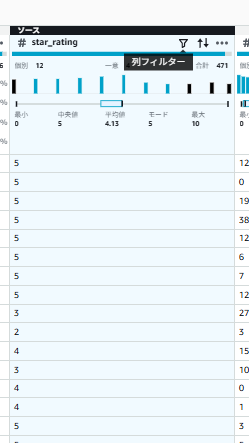
6-3. 評価値の範囲チェックと修正
-
star_ratingカラムの横の「列フィルター」ボタンをクリック
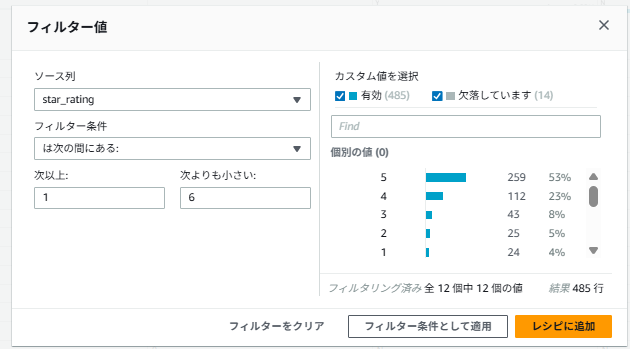
- フィルター値を設定する
- ソース列: star_rating
- フィルター条件: 「は次の間にある:」
- 次以上: 1 次よりも小さい: 6
- 「レシピに追加」をクリック
- 画面右側の「適用」をクリック
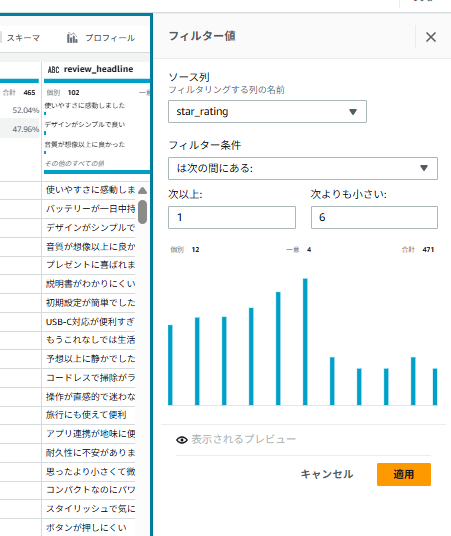
6-4. カテゴリの正規化(大文字小文字統一)
-
product_categoryカラムをクリック - 「…(3点リーダー)」の列アクションより「フォーマット」→ 「小文字に変更」をクリック
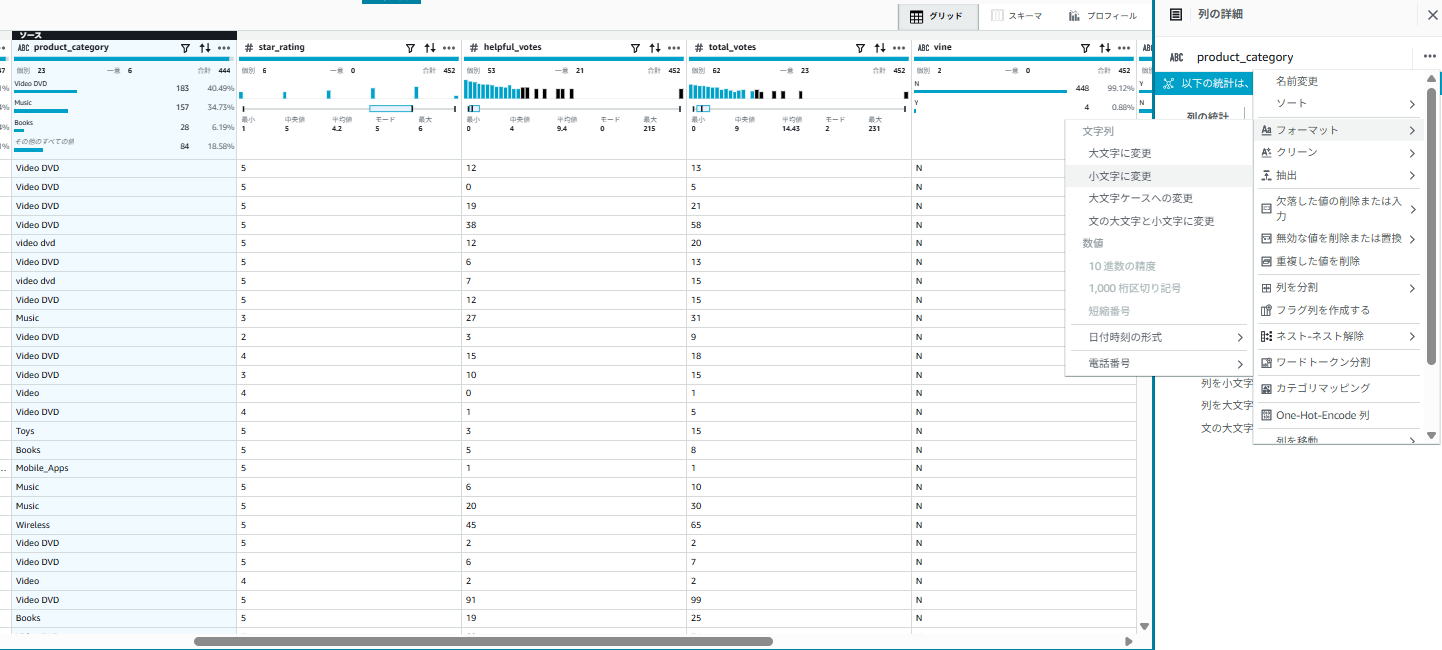
- 「変更のプレビュー」をクリックし、変更内容を確認し、「適用」をクリック
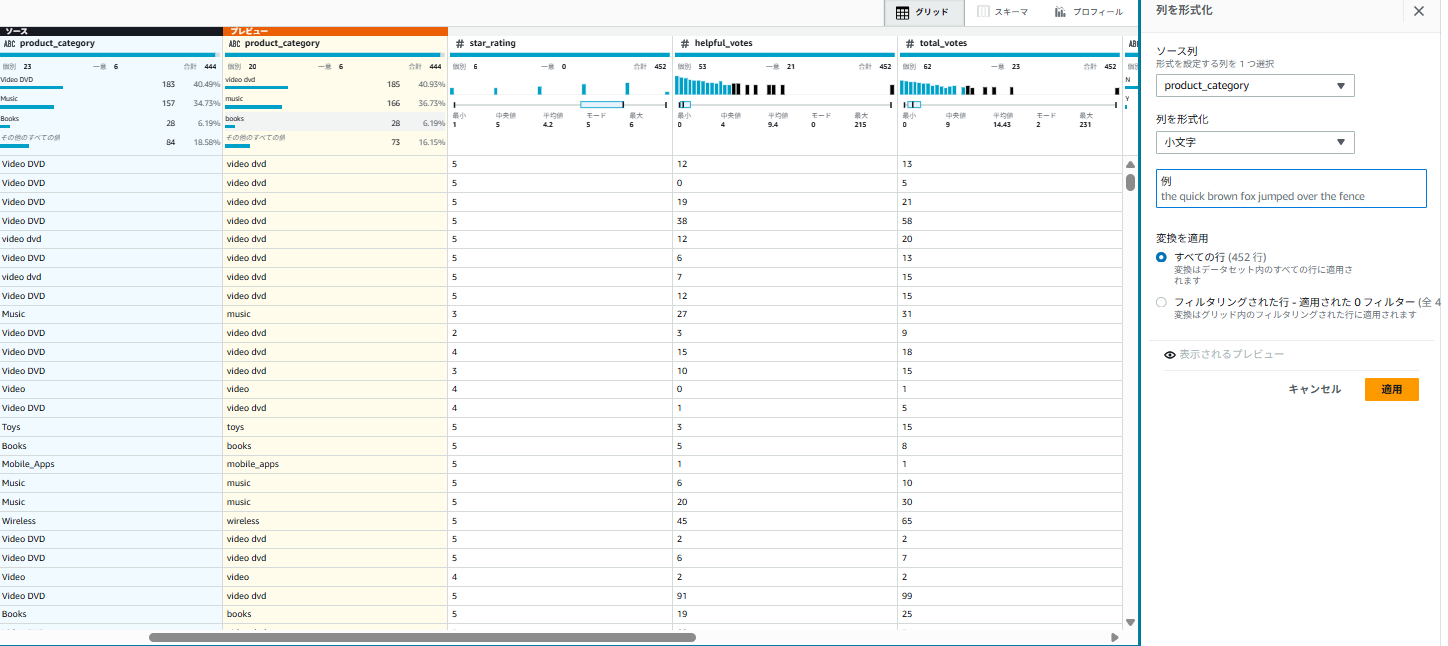
✅ ステップ7:レシピの保存
- 画面右上の「Recipe」パネルを確認
- 「発行」をクリック(ポップアップ上でも「発行」をクリック)
- Recipe name:
reviews-cleaning-project-recipe - 画面右上の「ジョブを作成」をクリック
✅ ステップ8:ジョブの作成と実行
- 左メニューから「ジョブ」を選択
- 「ジョブを作成」をクリック
- ジョブ設定:
- ジョブ名:
reviews-cleaning-job - ジョブタイプ:(下記作成したデータセットとレシピが選択されていることを確認する)
- 関連付けられたデータセット:
reviews-dataset - 関連付けられたレシピ:
reviews-cleaning-project-recipe
- 関連付けられたデータセット:
- ジョブ名:
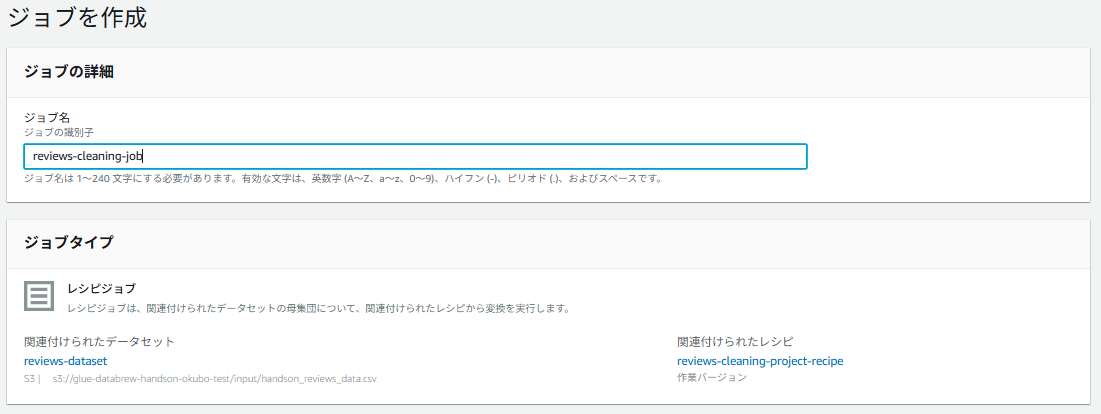
- 出力:
- 出力先: AmazonS3
- S3の場所:s3://自身の作成したS3バケット名/output/cleaned/※参照を押下して「output」ファイルを選択後、「cleaned/」を追記- ファイルタイプ: CSV
- 区切り記号: カンマ(,)
- 圧縮: None
- アドバンストジョブ設定:
- ユニットの最大数: 2
- 許可:
GlueDataBrewHandsonRole
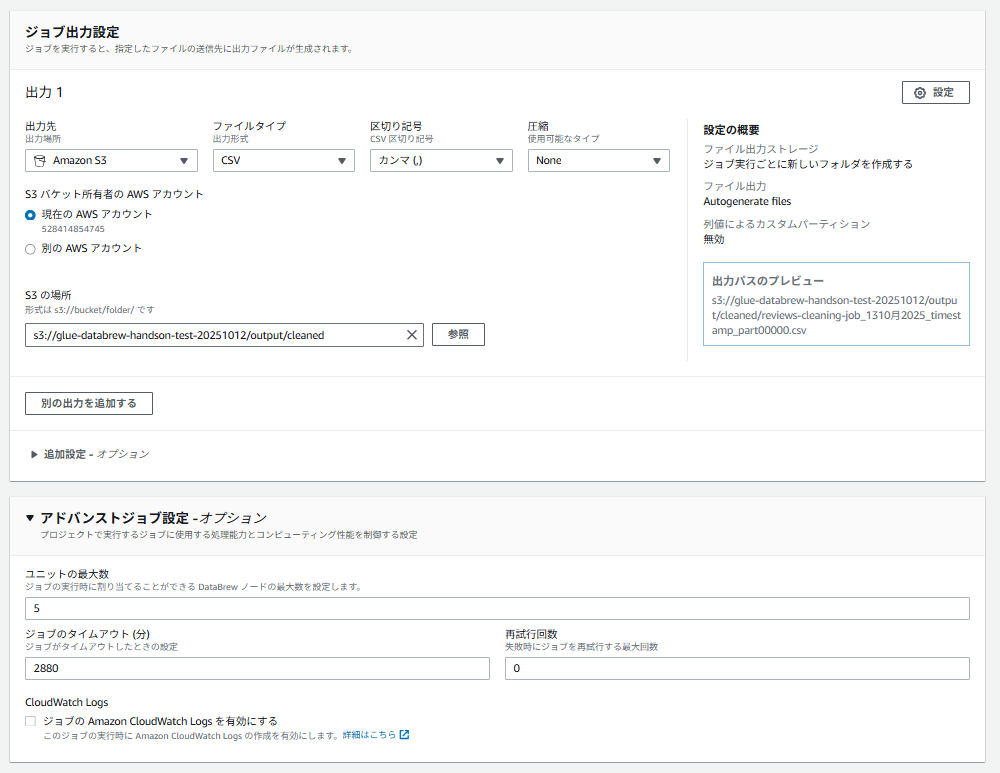
- 「ジョブを作成し実行する」をクリック
- ジョブのステータスを確認(「Succeeded」になるまで数分待機)
✅ ステップ9:結果の確認
- S3コンソールを開く
-
s3://your-bucket-name/output/cleaned/に移動 - 出力されたCSVファイルをダウンロード
- ローカルでファイルを開いて確認:
- 「review_id」カラムの重複が削除されているか
- 「product_title」,「product_category」,「review_headline」,「review_body」カラムの空白がトリミングされているか
- 「star_rating」カラムの評価値が1-5の範囲か
- 「product_category」カラムの正規化ができているか(小文字に統一)
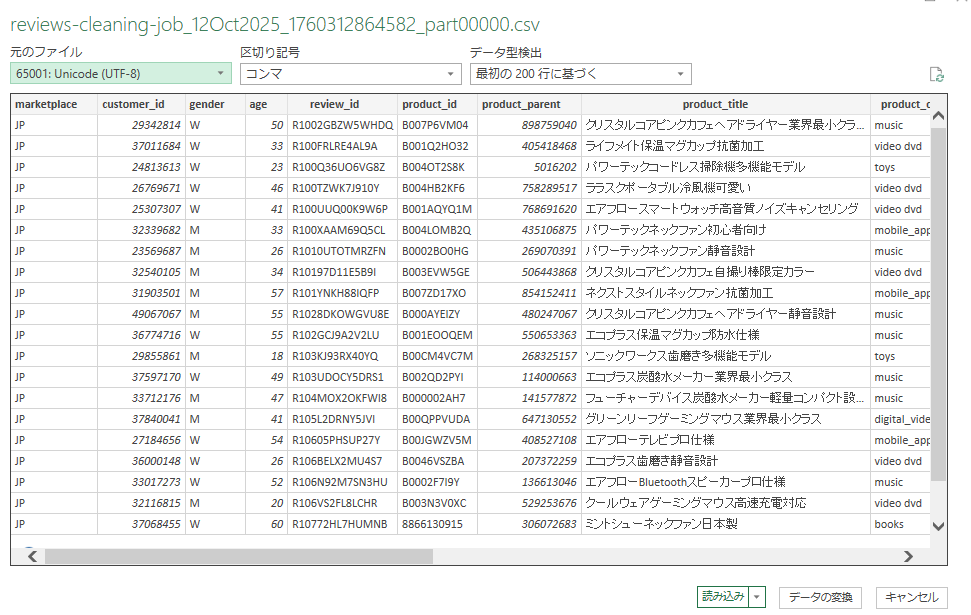
※Excelで開いて文字化けしてしまう場合は以下画像の通り「データ」→「テキストまたはCSVから」でインポートすると
文字化けせず確認できます。
🧹 片付け(リソース削除)
-
DataBrewジョブの削除
- 「Jobs」→ 作成したジョブを選択 → 「Delete」
-
DataBrewプロジェクトの削除
- 「Projects」→ 作成したプロジェクトを選択 → 「Delete」
-
DataBrewデータセットの削除
- 「Datasets」→ 作成したデータセットを選択 → 「Delete」
-
DataBrewレシピの削除(オプション)
- 「Recipes」→ 作成したレシピを選択 → 「Delete」
-
S3バケットの削除
- S3コンソール → バケットを選択 → 「空にする」→「削除」
- 注意:バケット内のすべてのオブジェクトを削除してから、バケット自体を削除
-
IAMロールの削除
- IAMコンソール → 「ロール」→
GlueDataBrewHandsonRoleを削除
- IAMコンソール → 「ロール」→
🏁 おつかれさまでした!
この課題では AWS Glue DataBrew を使用して、ノーコードでのデータクレンジングと加工スキルを習得しました。DataBrewは以下のような場面で非常に有効です:
- データアナリストやビジネスユーザーがコードを書かずにデータ準備を実行
- 機械学習の前処理として、学習用データのクレンジング
- データパイプラインでの定期的なデータ変換処理
- データ品質の継続的な監視と改善
🎉 これでDataBrewの基礎は完璧です!実際のプロジェクトでも活用していきましょう!