はじめに
KerasはTheano,TensorFlowベースの深層学習ラッパーライブラリです.Theano,TensorFlowのおかげでだいぶ深層学習にとっつきやすくなってきたものの,まだまだアルゴリズムをガリガリ書いていくのが大変.ということで,ネットワーク構造をかなりシンプルに書けるようにしたライブラリがKerasです.Keras自体の概要についてはid:aidiaryさんの記事が大変参考になりました.
Kerasの基本サンプルとして,MNISTの分類は非常にたくさん見かけるのですが,RNNを使ったシンプルなサンプルはあまり見つけられませんでした(Kerasの公式にRNNを用いた映画の感情分類のサンプルはあるのですがいかんせん最初に扱うには複雑すぎました).そのため今回は,LSTMにsin波を学習させて予測するという簡単なサンプルを通じて,KerasのRNN実装を試します.なお,TensorFlowを用いたRNN実装は以前こちらに記事を書いたので,興味のある方はそちらをごらんください.
2017.11.20追記
今回はわかりやすさ重視でsin波の予測を行なっていますが,もう少し複雑な時系列データを扱って見たかったため,Python】QRNNでカオス時系列データ予測【Keras】という記事を作成しました.
インストール
KerasはバックエンドとしてTheanoとTensorflowの両方が使え,Kerasで書かれたプログラムはまったく修正せずにバックエンドをいつでも切り替えられる(注意点はいくつかあるようです)のですが,今回はTensorFlowをバックエンドとする方法を試します.
事前にTensorFlowをインストールしていることを前提とします.
Kerasのインストールは,普通にpipを使って
pip install keras
でもいいですし,
ソースをgit cloneしてきてから,
python setup.py install
でも良いです.
TensorFlowをバックエンドとする場合,設定ファイル~/.keras/keras.jsonを以下のように書き換えます(kerasのドキュメント参照.keras.jsonは,最初にkerasを起動(importする等)することで生成されます).
# before
{
"image_dim_ordering": "th",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "theano"
}
# after
{
"image_dim_ordering": "th",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
デフォルトのバックエンドはTheano担っていますが,上記の書き換えによって,
import keras
した際に,
Using TensorFlow backend.
と表示されるはずです.
KerasのLSTMでsin波を予測してみる.
データ作成
まず,データを作ります.データ作成はyuyakatoさんの,RNNにsin波を学習させて予測してみた記事を参考にさせてもらいました.
import pandas as pd
import numpy as np
import math
import random
%matplotlib inline
random.seed(0)
# 乱数の係数
random_factor = 0.05
# サイクルあたりのステップ数
steps_per_cycle = 80
# 生成するサイクル数
number_of_cycles = 50
df = pd.DataFrame(np.arange(steps_per_cycle * number_of_cycles + 1), columns=["t"])
df["sin_t"] = df.t.apply(lambda x: math.sin(x * (2 * math.pi / steps_per_cycle)+ random.uniform(-1.0, +1.0) * random_factor))
df[["sin_t"]].head(steps_per_cycle * 2).plot()
以下の様にノイズありのsin波を作ります.
続いて,これを訓練データ,テストデータに分類し,100ステップ分の入力Xがあった際の出力yが101ステップ目になる様なデータセットを作ります.
def _load_data(data, n_prev = 100):
"""
data should be pd.DataFrame()
"""
docX, docY = [], []
for i in range(len(data)-n_prev):
docX.append(data.iloc[i:i+n_prev].as_matrix())
docY.append(data.iloc[i+n_prev].as_matrix())
alsX = np.array(docX)
alsY = np.array(docY)
return alsX, alsY
def train_test_split(df, test_size=0.1, n_prev = 100):
"""
This just splits data to training and testing parts
"""
ntrn = round(len(df) * (1 - test_size))
ntrn = int(ntrn)
X_train, y_train = _load_data(df.iloc[0:ntrn], n_prev)
X_test, y_test = _load_data(df.iloc[ntrn:], n_prev)
return (X_train, y_train), (X_test, y_test)
length_of_sequences = 100
(X_train, y_train), (X_test, y_test) = train_test_split(df[["sin_t"]], n_prev =length_of_sequences)
モデル作成
データセットが出来たところで,いよいよKerasを使ってネットワーク構成を書きます.
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
in_out_neurons = 1
hidden_neurons = 300
model = Sequential()
model.add(LSTM(hidden_neurons, batch_input_shape=(None, length_of_sequences, in_out_neurons), return_sequences=False))
model.add(Dense(in_out_neurons))
model.add(Activation("linear"))
model.compile(loss="mean_squared_error", optimizer="rmsprop")
model.fit(X_train, y_train, batch_size=600, nb_epoch=15, validation_split=0.05)
これだけです.上記の様に,ニューラルネットの構造はmodelにさまざまなレイヤをadd()することで構築できます.上の例では,(, 100, 1)のtensorを持った入力を300個のLSTM中間層に投げ,それを1個の出力層に集約し,linear活性化関数を掛け合わせています.
ちなみに,LSTMは入力のTensorが (batch_size, input_length, in_data_length) という3次元のShapeになります.出力は
- return_sequences=True -> (batch_size, input_length, out_data_length)
- return_sequences=False -> (batch_size, out_data_length)
というShapeです.
modelのコンパイル時に,誤差関数(例では平均二乗誤差),最適化アルゴリズム(例ではRMSprop)を指定します.誤差関数にはもちろん交差エントロピーも使えますし,最適化アルゴリズムは基本的なSGDからAdam,RMSpropまで一通りそろっています.
学習はfit()で行い,訓練データと教師データ,バッチサイズ,エポックサイズ,バリデーションデータとして訓練データの何%を使用するかを指定できます.
また,
# early stopping
early_stopping = EarlyStopping(monitor='val_loss', patience=2)
model.fit(X_train, y_train, batch_size=600, nb_epoch=15, validation_split=0.05, callbacks=[early_stopping])
のように収束判定コールバックを指定することで,収束したら自動的にループが止まるようにすることもできます.
Train on 3325 samples, validate on 176 samples
Epoch 1/15
3325/3325 [==============================] - 17s - loss: 0.0051 - val_loss: 0.0048
Epoch 2/15
1200/3325 [=========>....................] - ETA: 10s - loss: 0.0041
学習を始めると,上記の様にバーで学習時間の予測や,各エポックの学習にかかった時間,訓練データのloss/accuracy、バリデーションデータのloss/accuracyといった学習の進捗を表示してくれます(便利!).
予測
学習データを用いた予測は,
predicted = model.predict(X_test)
のように,predict()を用いて行います.
今回の例では,
dataf = pd.DataFrame(predicted[:200])
dataf.columns = ["predict"]
dataf["input"] = y_test[:200]
dataf.plot(figsize=(15, 5))
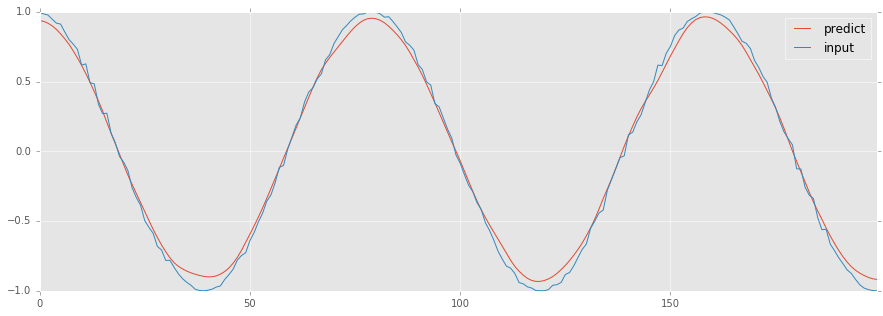
のような予測結果になりました.
Kerasでは,モデルの可視化にも対応しており,pygraphvis等を使って簡単にモデルを可視化してくれます.今回はjupyterを使っていたので, IPython.display.SVGを使って,
from IPython.display import SVG
from keras.utils.visualize_util import model_to_dot, plot
SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))
と書くことで,以下のようなモデル図を生成してくれます(pipでpydotの,homebrew等でgraphvizのインストールをする必要があります).
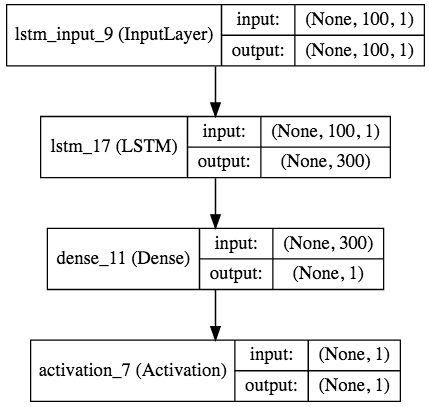
おわりに
以上のように,Kerasを使うとモデル作成のコードを非常に簡潔に書くことができます.今後もKerasを使ってもう少し複雑なモデルを試してみます.
参考文献
- Keras公式(http://keras.io/)
- 人工知能に関する断創録 (http://aidiary.hatenablog.com/entry/20160328/1459174455)
- RNNにsin波を学習させて予測してみた(http://qiita.com/yuyakato/items/ab38064ca215e8750865)
- kerasにモデルの視覚化をしてもらおう!! (http://ket-30.hatenablog.com/entry/keras/graph)