0. ざっくり言うと
- TensorFlowで簡単なRNN(Recurrent Neural Network)を実装した。
- RNNを使い、sin波を学習させて、
sin(t)からsin(t+1)(次ステップ)を予測させた。 - RNNの出力結果を連鎖させて、
sin(t+n)(複数ステップ)の予測を実現できた。 - RNNのセルにはLSTM(Long Short-Term Memory)を使った。
2016年5月27日追記:
続編『RNNにsin波を学習させて予測してみた:ハイパーパラメータ調整編』を書きました。
1. TensorFlow、RNN、LSTMについて
ざっくり割愛します。TensorFlowのチュートリアルや、そこから参照されている記事などが参考になると思います。
- Recurrent Neural Networks
- Understanding LSTM Networks -- colah's blog
- LSTMネットワークの概要 - Qiita(上記記事の翻訳)
2. 学習データの準備
1サイクル50ステップのsin波を100サイクル、合計5,000ステップ分生成し、学習データとしました。
また、学習データとして、ノイズなし、ノイズありの2種類を用意しました。
学習データはsin(t)(時刻tにおけるsin値)とsin(t+1)(時刻t+1におけるsin値)のペアで構成されています。
学習データの生成の詳細については、ipynbファイル(IPython Notebook)を残していますので、そちらを参照ください。(余談ですが、GitHubでipynbファイルがプレビューされて驚きました)
2.1. ノイズなし
2.2. ノイズあり
3. 学習・予測
今回は1つのコードで学習と予測を行っています。ソースコードは文末の付録に示します。
3.1. 処理の流れ
学習、予測の流れは以下の通り。
- 学習データを用いて学習
- 初期データ(学習データの先頭部分)を用いて
sin(t+1)を予測 - 予測した
sin(t+1)を用いてsin(t+2)を予測 - 3の繰り返し
3.2. ネットワーク構成
「入力層 - 隠れ層 - RNNセル - 出力層」というネットワークを使用しました。
また、RNNセルにはLSTMを使用しました。
3.3. ハイパーパラメータ
学習、予測に用いたハイパーパラメータは以下の通り。
| 変数名 | 意味 | 値 |
|---|---|---|
| num_of_input_nodes | 入力層のノード数 | 1 ノード |
| num_of_hidden_nodes | 隠れ層のノード数 | 2 ノード |
| num_of_output_nodes | 出力層のノード数 | 1 ノード |
| length_of_sequences | RNNのシーケンス長 | 50 ステップ |
| num_of_training_epochs | 学習の繰り返し回数 | 2,000 回 |
| length_of_initial_sequences | 初期データのシーケンス長 | 50 ステップ |
| num_of_prediction_epochs | 予測の繰り返し回数 | 100 回 |
| size_of_mini_batch | ミニバッチあたりのサンプル数 | 100 サンプル |
| learning_rate | 学習率 | 0.1 |
| forget_bias | (よく分かっていません) | 1.0 (デフォルト値) |
4. 予測結果
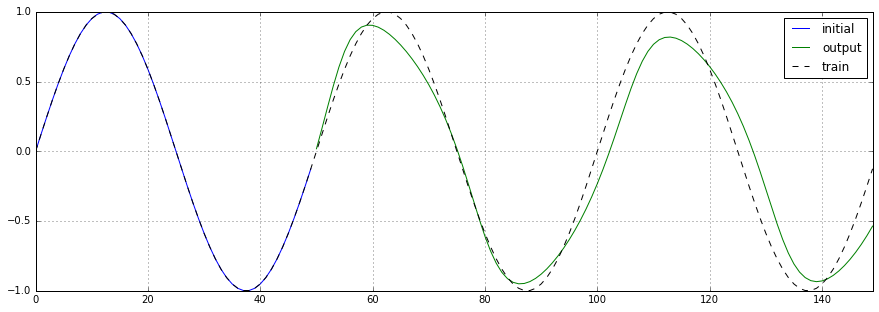
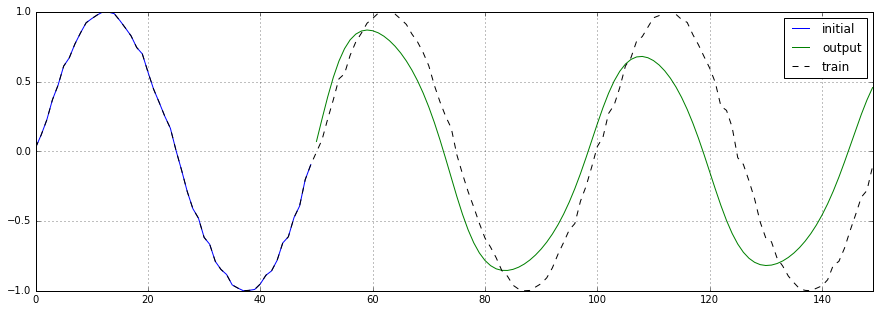
予測結果をプロットした図を以下にに示します。凡例は以下の通りです。
- 黒の点線: 学習データ
- 青の実線: 初期データ
- 緑の実線: 予測データ
4.1. ノイズなし
それっぽい波形が出力されています。全体的に振幅が浅く、頂点が歪み、周波数が少し低くなっています。
具体的な値はbasic/output.ipynbを参照ください。
4.2. ノイズあり
ノイズなしの場合よりもさらに振幅が浅く、周波数は少し高くなっています。また、学習データに含まれていたノイズ成分が減っているように見えます。
具体的な値はnoised/output.ipynbを参照ください。
5. 今後の予定
ネットワーク構成やハイパーパラメータを変化させてみて、どんな予測結果になるかを試してみたいと思っています。
2016年5月27日追記:
続編『RNNにsin波を学習させて予測してみた:ハイパーパラメータ調整編』を書きました。
付録: ソースコード
ノイズなし版のソースコードを以下に示します。ノイズあり版のソースコードはGitHubを参照ください。
ノイズなし版とノイズあり版は、入力ファイル名が違うだけです。
- ノイズなし版: basic/rnn.py(以下に示すコード)
- ノイズあり版: noised/rnn.py
import tensorflow as tf
from tensorflow.models.rnn import rnn, rnn_cell
import numpy as np
import random
def make_mini_batch(train_data, size_of_mini_batch, length_of_sequences):
inputs = np.empty(0)
outputs = np.empty(0)
for _ in range(size_of_mini_batch):
index = random.randint(0, len(train_data) - length_of_sequences)
part = train_data[index:index + length_of_sequences]
inputs = np.append(inputs, part[:, 0])
outputs = np.append(outputs, part[-1, 1])
inputs = inputs.reshape(-1, length_of_sequences, 1)
outputs = outputs.reshape(-1, 1)
return (inputs, outputs)
def make_prediction_initial(train_data, index, length_of_sequences):
return train_data[index:index + length_of_sequences, 0]
train_data_path = "../train_data/normal.npy"
num_of_input_nodes = 1
num_of_hidden_nodes = 2
num_of_output_nodes = 1
length_of_sequences = 50
num_of_training_epochs = 2000
length_of_initial_sequences = 50
num_of_prediction_epochs = 100
size_of_mini_batch = 100
learning_rate = 0.1
forget_bias = 1.0
print("train_data_path = %s" % train_data_path)
print("num_of_input_nodes = %d" % num_of_input_nodes)
print("num_of_hidden_nodes = %d" % num_of_hidden_nodes)
print("num_of_output_nodes = %d" % num_of_output_nodes)
print("length_of_sequences = %d" % length_of_sequences)
print("num_of_training_epochs = %d" % num_of_training_epochs)
print("length_of_initial_sequences = %d" % length_of_initial_sequences)
print("num_of_prediction_epochs = %d" % num_of_prediction_epochs)
print("size_of_mini_batch = %d" % size_of_mini_batch)
print("learning_rate = %f" % learning_rate)
print("forget_bias = %f" % forget_bias)
train_data = np.load(train_data_path)
print("train_data:", train_data)
# 乱数シードを固定する。
random.seed(0)
np.random.seed(0)
tf.set_random_seed(0)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
with tf.Graph().as_default():
input_ph = tf.placeholder(tf.float32, [None, length_of_sequences, num_of_input_nodes], name="input")
supervisor_ph = tf.placeholder(tf.float32, [None, num_of_output_nodes], name="supervisor")
istate_ph = tf.placeholder(tf.float32, [None, num_of_hidden_nodes * 2], name="istate") # 1セルあたり2つの値を必要とする。
with tf.name_scope("inference") as scope:
weight1_var = tf.Variable(tf.truncated_normal([num_of_input_nodes, num_of_hidden_nodes], stddev=0.1), name="weight1")
weight2_var = tf.Variable(tf.truncated_normal([num_of_hidden_nodes, num_of_output_nodes], stddev=0.1), name="weight2")
bias1_var = tf.Variable(tf.truncated_normal([num_of_hidden_nodes], stddev=0.1), name="bias1")
bias2_var = tf.Variable(tf.truncated_normal([num_of_output_nodes], stddev=0.1), name="bias2")
in1 = tf.transpose(input_ph, [1, 0, 2]) # (batch, sequence, data) -> (sequence, batch, data)
in2 = tf.reshape(in1, [-1, num_of_input_nodes]) # (sequence, batch, data) -> (sequence * batch, data)
in3 = tf.matmul(in2, weight1_var) + bias1_var
in4 = tf.split(0, length_of_sequences, in3) # sequence * (batch, data)
cell = rnn_cell.BasicLSTMCell(num_of_hidden_nodes, forget_bias=forget_bias)
rnn_output, states_op = rnn.rnn(cell, in4, initial_state=istate_ph)
output_op = tf.matmul(rnn_output[-1], weight2_var) + bias2_var
with tf.name_scope("loss") as scope:
square_error = tf.reduce_mean(tf.square(output_op - supervisor_ph))
loss_op = square_error
tf.scalar_summary("loss", loss_op)
with tf.name_scope("training") as scope:
training_op = optimizer.minimize(loss_op)
summary_op = tf.merge_all_summaries()
init = tf.initialize_all_variables()
with tf.Session() as sess:
saver = tf.train.Saver()
summary_writer = tf.train.SummaryWriter("data", graph=sess.graph)
sess.run(init)
for epoch in range(num_of_training_epochs):
inputs, supervisors = make_mini_batch(train_data, size_of_mini_batch, length_of_sequences)
train_dict = {
input_ph: inputs,
supervisor_ph: supervisors,
istate_ph: np.zeros((size_of_mini_batch, num_of_hidden_nodes * 2)),
}
sess.run(training_op, feed_dict=train_dict)
if (epoch + 1) % 10 == 0:
summary_str, train_loss = sess.run([summary_op, loss_op], feed_dict=train_dict)
summary_writer.add_summary(summary_str, epoch)
print("train#%d, train loss: %e" % (epoch + 1, train_loss))
inputs = make_prediction_initial(train_data, 0, length_of_initial_sequences)
outputs = np.empty(0)
states = np.zeros((num_of_hidden_nodes * 2)),
print("initial:", inputs)
np.save("initial.npy", inputs)
for epoch in range(num_of_prediction_epochs):
pred_dict = {
input_ph: inputs.reshape((1, length_of_sequences, 1)),
istate_ph: states,
}
output, states = sess.run([output_op, states_op], feed_dict=pred_dict)
print("prediction#%d, output: %f" % (epoch + 1, output))
inputs = np.delete(inputs, 0)
inputs = np.append(inputs, output)
outputs = np.append(outputs, output)
print("outputs:", outputs)
np.save("output.npy", outputs)
saver.save(sess, "data/model")