先日行われたTensorFlow Dev Summit 2018の「Machine Learning in JavaScript」で、Webブラウザ上で実行可能な機械学習ライブラリとしてTensorFlow.jsが公開されました。
そこで、素振りがてらにこんなものを作ってみました。
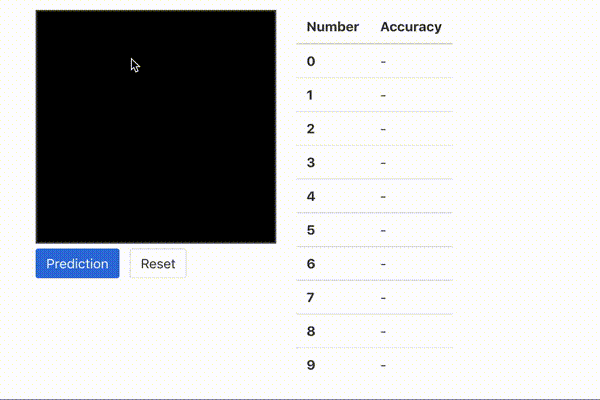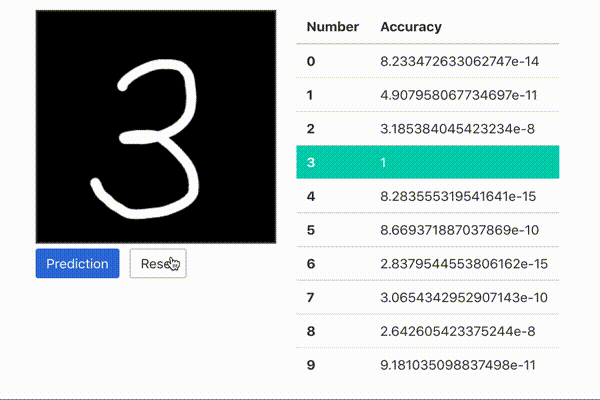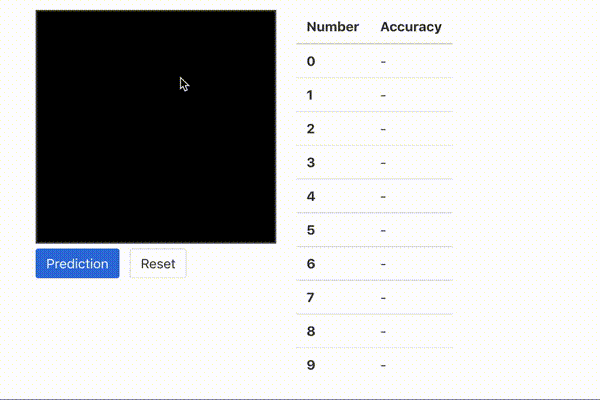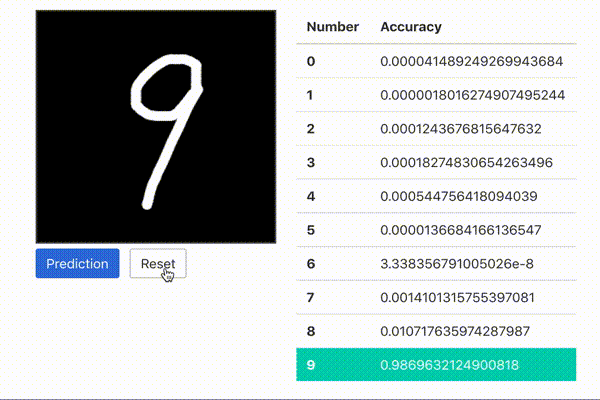
これは、手書き数字識別のトレーニング済モデルをTensorFlow.jsで読み込むことで、Webブラウザ上で書いた数字が0~9のどれかを予測しています。
主なフロー
- TensorFlow or Kerasで学習済みモデルを作成
-
tensorflowjs_converterでTensorFlow.jsで読み込める形に変換 - TensorFlow.jsで変換済モデルを読み込んで推論を実行
今回はKerasを使用した方法を紹介していますが、TensorFlowの場合も同様なフローになります。
具体的には、1で出力するファイルがHDF5→SavedModelに変わり、2のtensorflowjs_converterに与える引数が変わります。詳細はこちらに記載されています。
サンプルコード
-
Google Colaboratory
- 学習済みモデル作成 〜 TensorFlow.jsで読み込める形式へ変換
- Step1, 2に該当
-
Github
- 変換後の学習済みモデルを使用した推論
- Step3に該当
- 実行する場合はWeb Server for Chromeなどのローカルサーバーを使用してください
- webpackもなにも使っていないので旧ブラウザでは動かない可能性があります
サンプルコードで使用しているTensorFlow.jsのversionは0.8.0です。
今回はこれらのコードを元に解説をしていきます。
Step1. TensorFlow or Kerasで学習済みモデルを作成
Colaboratoryを使ってさくっと学習する
Colaboratoryってなに?
Google Colaboratoryとは、Googleが提供している無料でGPU環境が使えるJupyter Notebookという神のようなサービスです。
Python環境や各種機械学習フレームワークもプリインストールされているので、面倒な環境構築をすべてすっとばせる上にGPUを使った高速な学習を行えるということで、使わない手はないですね。
Notebookの準備
今回、学習済モデルの準備から変換まで(Step1, 2)の部分を共有Documentとして公開してあるので、これをColaboratoryで開いて左上のPLAYGROUND で開くをクリックすれば自分のドキュメントとして自由に操作できるようになります。
ちなみに、
ランタイム > すべてのセルを実行
とすれば、変換後のモデルがDLされるのでいっきにStep3へスキップできます。
学習用プログラムの準備
MNISTの学習プログラムの書き方は本旨ではないので、Kerasのサンプルコードのうちのmnist_cnn.pyを使用することにとします。
これは畳み込みニューラルネット(CNN)で数字認識をしており、認識率99%超えのモデルを手に入れることが出来ます。
ただし、提供されているコードには学習済モデルを保存する処理が含まれていないので、
model.save('mnist_cnn_model.h5')
を処理の最後に追加することで、学習済モデルをHDF5形式で保存することができます。
その後に
!python3 mnist_cnn.py
をすることでトレーニング&学習済みモデルの吐き出しが完了します。
Step2. tensorflowjs_converterでTensorFlow.jsで読み込める形に変換
Step1に続き、Colaboratoryで作業を続けます。
まずはtensorflowjs_converterを手に入れます。
!pip3 install tensorflowjs
そして以下のコマンドを使用することで、先程の学習済みモデルをTensorFlow.jsで読み込み可能なファイル形式に変換を行います。
!tensorflowjs_converter --input_format keras mnist_cnn_model.h5 model
すると、modelディレクトリ下に以下のようなファイル達が吐き出されているので、次のStepで読み込めるようディレクトリごとDLします。
group1-shard1of1 group2-shard1of1 group3-shard1of2 group3-shard2of2 group4-shard1of1 model.json
以上、とっても簡単ですね!
(おまけ) なんかファイル増えてない?
これはtensorflowjs_converterが、元のモデルを4MB以下のchunkファイルに細かく分割してやることで、モデル自体がブラウザにキャッシュされるようにしてくれているからです。
じゃあ全てのファイルを取得するようにコードを書く必要があるのかというとそんなことはなく、TensorFlow.jsから読み込むファイルはmodel.jsのみです。
実際にNetworkタブでどのようにモデルを取得しているかを見てみると、model.jsonにリクエストした後にその他のファイル達の取得が追加で行われていることがわかります。

なぜこのような挙動になるかというと、このmodel.js内に先程のファイル達のPathが以下のように記述されており、これを元に必要となる各種ファイルを取得してくれているためです。
❯ cat model.json | jq ".weightsManifest[].paths"
[
"group1-shard1of1"
]
[
"group2-shard1of1"
]
[
"group3-shard1of2",
"group3-shard2of2"
]
[
"group4-shard1of1"
]
Step3. TensorFlow.jsで変換済モデルを読み込んで推論を実行
TensorFlow.jsを入手
npmを使用する場合は
npm install @tensorflow/tfjs or yarn add @tensorflow/tfjs
CDN版を使用する場合は
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@0.8.0"></script>
でそれぞれInstallすることが出来ます。
変換済の学習済みモデルを読み込む
変換済みモデルを読み込む場合は、tf.loadModel()を使用すればOKです。
ただし、これはPromiseを返す非同期メソッドなので、実際には以下のように使用します。
async function loadPretrainedModel() {
const model = await tf.loadModel(/* model.jsonのPath */);
// do something
}
// or
tf.loadModel(/* model.jsonのPath */);
.then(model => /* do something */);
Input用のtf.Tensorオブジェクトを作成
学習済みモデルを使用して推論を行う場合には、使用するモデルに合った形のInputを与える必要があります。
今回作成したモデルのInputは[batchSize, width, height, colorChannels]で、
- 学習で使用したMNISTは、28×28のグレースケール画像
- 1枚の画像のみが推論対象
なので、[1, 28, 28, 1]の形に変換してあげれば大丈夫ですね。
今回のプログラムでは、canvasに書かれた文字をモデルのInputにあうtf.Tensorオブジェクトに変換する必要があります。
実際のフローとしては、
- canvasのデータを28×28にリサイズ
- リサイズ後のcanvasをImageDataオブジェクトとして取得し、グレースケール変換
- ImageDataオブジェクトを
tf.Tensorオブジェクトに変換 - 0~255で表現されているのを255で割ってあげて0~1に正規化する
- 入力は1枚のみなので、batchSizeを1とする
という処理を行う必要があります。
なお、3の処理についてはtf.fromPixelsというimageDataとcolorChannelを渡すだけでtf.Tensorオブジェクトに変換してくれるという便利なものを標準で用意してくれているのでこちらを使用してあげるのが良いでしょう。
(当然3~5の処理として、ImageData.dataをグレースケールの配列にし、tf.Tensorオブジェクトへ変換。その後正規化を行った後にtf.reshape([1, 28, 28, 1])とする方法でもOKです。こちらのほうが正攻法かもしれないですね。)
推論を実行する
ここまで出来たらあとは簡単で、先程作成したinputをmodel.predict()に渡してあげればOKです。
const prediction = model.predict(/* input tensor object */);
ちなみに、tf.Tensorオブジェクトから通常の配列としてデータを取り出す場合はdataSync()を使用することで取り出すことができます。
(追記)tf.tidyを使用してGPUメモリを開放する
不要なtf.Tensorオブジェクトは適宜cleanupしてあげないと、メモリリークの温床となってしまいます。
ので、不要なtensorオブジェクトの開放を行う必要があるのですが、tf.tidyを使ってあげることで計算過程の中間tensorオブジェクトのcleanupを自動で行ってくれます。便利!!
(こちらのissueを頂いて知りました。ありがとうございます。)
計測してみた
せっかくなので実際に今回のプログラムで、tf.tidyの有り無しでどのような差があるか計測をしてみました。
tfjsによってどれだけメモリが行われているかはtf.memory()にて確認することができます。
0~9までの数字を連続でPredictionし、各Predictionのタイミングでメモリの状態を測定しています。
tf.tidy無し
0. {unreliable: false, numTensors: 32, numDataBuffers: 22, numBytes: 9605380}
1. {unreliable: false, numTensors: 38, numDataBuffers: 26, numBytes: 9611696}
2. {unreliable: false, numTensors: 44, numDataBuffers: 30, numBytes: 9618012}
3. {unreliable: false, numTensors: 50, numDataBuffers: 34, numBytes: 9624328}
4. {unreliable: false, numTensors: 56, numDataBuffers: 38, numBytes: 9630644}
5. {unreliable: false, numTensors: 62, numDataBuffers: 42, numBytes: 9636960}
6. {unreliable: false, numTensors: 68, numDataBuffers: 46, numBytes: 9643276}
7. {unreliable: false, numTensors: 74, numDataBuffers: 50, numBytes: 9649592}
8. {unreliable: false, numTensors: 80, numDataBuffers: 54, numBytes: 9655908}
9. {unreliable: false, numTensors: 86, numDataBuffers: 58, numBytes: 9662224}
tf.tidy有り
0. {unreliable: false, numTensors: 26, numDataBuffers: 18, numBytes: 9599064}
1. {unreliable: false, numTensors: 26, numDataBuffers: 18, numBytes: 9599064}
2. {unreliable: false, numTensors: 26, numDataBuffers: 18, numBytes: 9599064}
3. {unreliable: false, numTensors: 26, numDataBuffers: 18, numBytes: 9599064}
4. {unreliable: false, numTensors: 26, numDataBuffers: 18, numBytes: 9599064}
5. {unreliable: false, numTensors: 26, numDataBuffers: 18, numBytes: 9599064}
6. {unreliable: false, numTensors: 26, numDataBuffers: 18, numBytes: 9599064}
7. {unreliable: false, numTensors: 26, numDataBuffers: 18, numBytes: 9599064}
8. {unreliable: false, numTensors: 26, numDataBuffers: 18, numBytes: 9599064}
9. {unreliable: false, numTensors: 26, numDataBuffers: 18, numBytes: 9599064}
たしかにtf.tidyを使用しないと、使用されるメモリが増加し続けてしまっていることが確認できましたね。
今回のようなシンプルなデモであれば、よっぽどでない限りはメモリリークは起こらないとは思いますが、
不要なメモリはどんどん開放するに限るので、忘れずにtf.tidyを使っていくことをおすすめします。
まとめ
MNISTにかぎらず、学習済みモデルがあれば推論部分をクライアントサイドだけで完結させることが出来ました。
これを活用すれば、新たに推論用のAPIサーバを用意する必要もないですし、サーバーへデータを送信する必要もないので、プライベートなデータの分類だったり、ちょっとしたツールに埋め込むみたいな用途にも使えるかもしれないですね。
今回は学習済みモデルを用いた推論の方法を紹介しましたが、TensorFlow.jsのみでモデルの構築から学習までさせることも可能です。
TensorFlow.js公式サイトで色々なデモが公開されているので、興味が湧いた方はとりあえず触って遊んでみると楽しいですよ!!
(エイプリルフールネタで話題になった、Gboard 物理手書きバージョンもTensorFlow.jsを使って実現しているようですね。)