前回の続きです.
目次
Lambdaの作成
・kvsConsumerTrigger
・kvsConsumerGoogleSTT
・transcriptGet
終わりに
Lambdaの作成
kvsConsumerTrigger
このLambdaを作っていきます↓
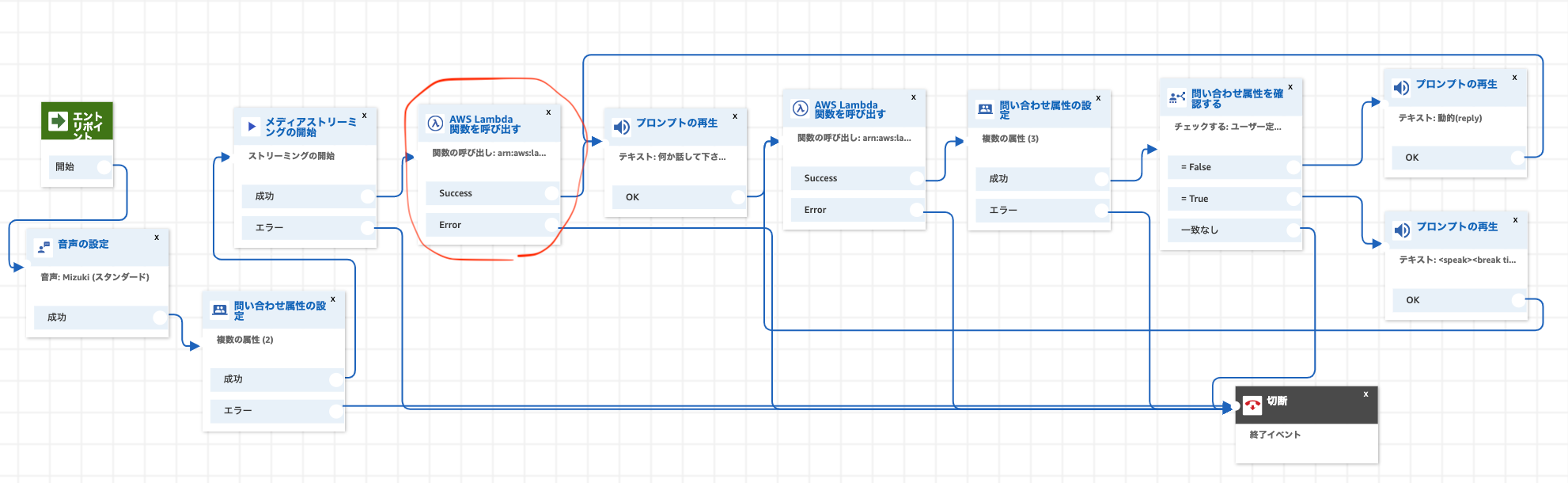
完全なコードはこちら↓
const AWS = require('aws-sdk');
const lambda = new AWS.Lambda();
exports.handler = async (event, context, callback) => {
let payload;
payload = {
streamARN: event.Details.ContactData.MediaStreams.Customer.Audio.StreamARN,
startFragmentNum: event.Details.ContactData.MediaStreams.Customer.Audio.StartFragmentNumber,
connectContactId: event.Details.ContactData.ContactId,
phoneNumber: event.Details.ContactData.CustomerEndpoint.Address,
saveCallRecording: event.Details.ContactData.Attributes.saveCallRecording === "false" ? false : true,
};
const params = {
'FunctionName': process.env.INVOKE_LAMBDA_NAME,
'InvocationType': "Event", //非同期
'Payload': JSON.stringify(payload)
};
try {
const callLambda = await lambda.invoke(params).promise();
console.log(callLambda);
}catch(err){
console.log(err);
throw new Error(err);
}
return { lambdaResult:"Success" };
};
このLambdaは, Connectから受けとったパラメータをもとに, 別のLambdaを非同期に呼び出しています。
Lambdaの環境変数INVOKE_LAMBDA_NAMEに, 呼び出すLambda名を入力して下さい。
(例: kvsConsumerGoogleSTT)
payloadの中身は以下のようになっています↓
streamARN: KVSに保存されている音声ストリームの名前
startFragmentNum: 録音データ開始のフラグメント番号
connectContactId: 1電話に1つ割り当てられるID
phoneNumber: 顧客の電話番号
saveCallRecording: s3に音声ファイルを保存するかどうかのフラグ
kvsConsumerGoogleSTT
先程のkvsConsumerTriggerから呼び出されるLambdaを作ります。
注意
このLambdaは, aws環境でコードを書いて, 動かす事はできません。ローカル環境で, gradleによって, ビルドしてできたzipファイルをLambdaにアップロードする事で動かせます。
ローカル環境
- java8
- gradle6.6以上
- SpeechToTextを有効化したjson形式のサービスアカウントキー (例:
credentials.json)
私の環境です↓
// java -version
openjdk version "1.8.0_265"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_265-b01)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.265-b01, mixed mode)
// gradle -v
------------------------------------------------------------
Gradle 6.6.1
------------------------------------------------------------
Build time: 2020-08-25 16:29:12 UTC
Revision: f2d1fb54a951d8b11d25748e4711bec8d128d7e3
Kotlin: 1.3.72
Groovy: 2.5.12
Ant: Apache Ant(TM) version 1.10.8 compiled on May 10 2020
JVM: 1.8.0_265 (AdoptOpenJDK 25.265-b01)
OS: Mac OS X 10.16 x86_64
Lambdaにアップロードする手順
- gitをクローンするか, 1からjavaプロジェクトを作ります。1から作る方は, build.gradleやフォルダ構成などは, gitを参考にして下さい。
-
kvsConsumerGoogleSTT/src/resources/にcredentials.jsonを配置します。 - プロジェクトのルートディレクトリにいる状態で,
$ gradle buildを実行します。 -
kvsConsumerGoogleSTT/build/ditributions/kvsConsumerGoogleSTT.zipが作成されるので, このzipをLambdaにアップロードします。
Lambda設定
- java8でLambdaを作成します。
- RuntimeSettingのHandlerに, 作成したハンドラーを設定します。
(例:com.amazonaws.kvstranscribestreaming.KVSTranscribeStreamingLambda::handleRequest)
環境変数の設定
-
GOOGLE_APPLICATION_CREDENTIALSにcredentials.jsonと設定 -
REGION: 自分のAWS環境のregionを設定 (例:ap-northeast-1) -
RECORDINGS_BUCKET_NAME: 音声ファイルを保存するs3のバケット名を設定。保存する場合は, 設定した名前でバケットを作っておいて下さい。(例:amazon-connect-audio-bucket) -
RECORDINGS_KEY_PREFIX: 音声ファイル名の先頭に付ける単語を設定。例えば,recordings/と設定しておくと, recordingsフォルダの配下に音声ファイルは保存されます。 -
RECORDINGS_PUBLIC_READ_ACL: URLを知っていれば, 誰でもアクセスできるようにするかどうかのフラグです。(例:TRUE) -
START_SELECTOR_TYPE:NOWかFRAGMENT_NUMBERを指定できます。NOWにした場合, リアルタイムに音声を取得します。FRAGMENT_NUMBERの場合, メディアストリーミングを開始した直後からの音声を取得します。FRAGMENT_NUMBERの場合は, リアルタイムに文字起こしできないので,NOWにしましょう。 -
TRANSCRIPT_TABLE_NAME: 文字起こしを書き込むDynamoのテーブル名を設定。 -
LIMITDAY_OF_TTL: データが追加されてから, 何日後にそのデータを自動削除するかを指定します。これは, DynamoのTTLという機能を利用しています。これを使う事で, Dynamoの容量を節約する事ができます。(例:3)
Dynamo作成
プライマリキーにString型のContactId, ソートキーにNumber型のReplyCountを設定し, テーブルを作成
s3作成
環境変数で設定したバケット名でバケットを作成
それでは, コードを説明していきます!
完全なコードはこちらを参考にして下さい。
重要な部分だけ説明していきます↓
public class KVSTranscribeStreamingLambda implements RequestHandler<TranscriptionRequest, String> {
// Environment Variable
private static final Regions REGION = Regions.fromName(System.getenv("REGION"));
private static final String RECORDINGS_BUCKET_NAME = System.getenv("RECORDINGS_BUCKET_NAME");
private static final String RECORDINGS_KEY_PREFIX = System.getenv("RECORDINGS_KEY_PREFIX");
private static final boolean RECORDINGS_PUBLIC_READ_ACL = Boolean.parseBoolean(System.getenv("RECORDINGS_PUBLIC_READ_ACL"));
private static final String START_SELECTOR_TYPE = System.getenv("START_SELECTOR_TYPE");
private static final String TRANSCRIPT_TABLE_NAME = System.getenv("TRANSCRIPT_TABLE_NAME");
private static final int LIMITDAY_OF_TTL = Integer.parseInt(System.getenv("LIMITDAY_OF_TTL"));
private static final Logger logger = LoggerFactory.getLogger(KVSTranscribeStreamingLambda.class);
public static final MetricsUtil metricsUtil = new MetricsUtil(AmazonCloudWatchClientBuilder.defaultClient());
private static final DateFormat DATE_FORMAT = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSSZ");
// SegmentWriter saves Transcription segments to DynamoDB
private TranscribedSegmentWriter fromCustomerSegmentWriter = null;
// Number of replies
private int replyCount = 1;
/**
* Handler function for the Lambda
*
* @param request
* @param context
* @return
*/
@Override
public String handleRequest(TranscriptionRequest request, Context context) {
logger.info("received request: " + request.toString());
logger.info("received context: " + context.toString());
try {
// create a SegmentWriter to be able to save off transcription results
AmazonDynamoDBClientBuilder builder = AmazonDynamoDBClientBuilder.standard();
builder.setRegion(REGION.getName());
fromCustomerSegmentWriter = new TranscribedSegmentWriter(request.getConnectContactId(), new DynamoDB(builder.build()));
// Start Google Speech to Text
startKVSToTranscribeStreaming(request.getStreamARN(), request.getStartFragmentNum(), request.getConnectContactId(), request.getSaveCallRecording(), request.getPhoneNumber());
return "{ \"result\": \"Success\" }";
} catch (Exception e) {
logger.error("KVS to Transcribe Streaming failed with: ", e);
return "{ \"result\": \"Failed\" }";
}
}
/**
* Get the audio stream from KVS and transcribe it with GoogleSpeechToText.
*
* @param streamARN
* @param startFragmentNum
* @param contactId
* @throws Exception
*/
private void startKVSToTranscribeStreaming(String streamARN, String startFragmentNum, String contactId,Optional<Boolean> saveCallRecording, String phoneNumber) throws Exception {
String streamName = streamARN.substring(streamARN.indexOf("/") + 1, streamARN.lastIndexOf("/"));
KVSStreamTrackObject kvsStreamTrackObjectFromCustomer = getKVSStreamTrackObject(streamName, startFragmentNum, KVSUtils.TrackName.AUDIO_FROM_CUSTOMER.getName(), contactId);
// Parameters required to get the audio stream from KVS
StreamingMkvReader streamingMkvReader = kvsStreamTrackObjectFromCustomer.getStreamingMkvReader();
FragmentMetadataVisitor fragmentVisitor = kvsStreamTrackObjectFromCustomer.getFragmentVisitor();
KVSContactTagProcessor tagProcessor = kvsStreamTrackObjectFromCustomer.getTagProcessor();
int CHUNK_SIZE_IN_KB = 4;
String track = kvsStreamTrackObjectFromCustomer.getTrackName();
// Get audio file link to save to s3
String audio_file_path = URLEncoder.encode(kvsStreamTrackObjectFromCustomer.getSaveAudioFilePath().toString().replace(".raw", ".wav").replace("/tmp/", ""), "UTF-8");
String audio_file_link = "https://" + RECORDINGS_BUCKET_NAME + ".s3-ap-northeast-1.amazonaws.com/"+ RECORDINGS_KEY_PREFIX + audio_file_path;
logger.info(String.format("phoneNumber: %s\n", phoneNumber));
logger.info(String.format("audioFileLink: %s\n", audio_file_link));
logger.info(String.format("replyCount: %d\n", replyCount));
ResponseObserver<StreamingRecognizeResponse> responseObserver = null;
// Google Speech to Text Streaming
try (SpeechClient client = SpeechClient.create()) {
ClientStream<StreamingRecognizeRequest> clientStream;
// response handler
responseObserver =
new ResponseObserver<StreamingRecognizeResponse>() {
public void onStart(StreamController controller) {
logger.info(String.format("GoogleSTT Start"));
replyCount = 1;
}
public void onResponse(StreamingRecognizeResponse response) {
logger.info("===response===");
System.out.println(response);
StreamingRecognitionResult result = response.getResultsList().get(0);
SpeechRecognitionAlternative alternative = result.getAlternativesList().get(0);
String transcript_segment = alternative.getTranscript();
float confidence = alternative.getConfidence();
logger.info(String.format("Transctipt : %s\n", transcript_segment));
logger.info(String.format("Confidence : %f\n", confidence));
if(result.getIsFinal()){
fromCustomerSegmentWriter.writeToDynamoDB(transcript_segment, phoneNumber, TRANSCRIPT_TABLE_NAME, replyCount, audio_file_link, LIMITDAY_OF_TTL);
replyCount++;
}
}
public void onComplete() {
logger.info(String.format("GoogleSTT Complete"));
}
public void onError(Throwable t) {
logger.error(String.format("GoogleSTT Error : %s\n", t));
}
};
clientStream = client.streamingRecognizeCallable().splitCall(responseObserver);
// request parameter
RecognitionConfig recognitionConfig =
RecognitionConfig.newBuilder()
.setEncoding(RecognitionConfig.AudioEncoding.LINEAR16)
.setLanguageCode("ja-JP")
.setSampleRateHertz(8000) // great for phone voice
.setEnableAutomaticPunctuation(true)
.setUseEnhanced(true) // use enhanced model
.build();
StreamingRecognitionConfig streamingRecognitionConfig =
StreamingRecognitionConfig.newBuilder()
.setConfig(recognitionConfig)
.setSingleUtterance(false)
.build();
StreamingRecognizeRequest request_google =
StreamingRecognizeRequest.newBuilder()
.setStreamingConfig(streamingRecognitionConfig)
.build();
// Send configuration request
clientStream.send(request_google);
// Get audio stream and send request to Google STT
while (true) {
// Get audio stream
ByteBuffer audioBuffer = KVSUtils.getByteBufferFromStream(streamingMkvReader, fragmentVisitor,
tagProcessor, contactId, CHUNK_SIZE_IN_KB, track);
if (audioBuffer.remaining() > 0) {
byte[] audioBytes = new byte[audioBuffer.remaining()];
audioBuffer.get(audioBytes);
// send request to Google STT
request_google = StreamingRecognizeRequest.newBuilder()
.setAudioContent(ByteString.copyFrom(audioBytes)).build();
clientStream.send(request_google);
// Write audio stream to outputStream
kvsStreamTrackObjectFromCustomer.getOutputStream().write(audioBytes);
} else {
break;
}
}
responseObserver.onComplete();
} catch (Exception e) {
logger.info(String.format("Error KVS or GoogleSTT : %s\n", e));
}
try {
// save wav file to s3
closeFileAndUploadRawAudio(kvsStreamTrackObjectFromCustomer,contactId,saveCallRecording);
}catch(IOException e){
logger.info(String.format("Error closeFile and UploadRawAudio: %s\n", e));
}
}
}
このLambdaは, KVSから音声ストリームを取得し, GoogleSTTにリクエストを投げて, リアルタイムに文字起こしをします。KVSの音声ストリームが無くなる(電話を切った直後)と, 今までの音声データをwavファイルに変換し, s3に保存します。
では, 細かく見ていきましょう!
private static final Regions REGION = Regions.fromName(System.getenv("REGION"));
private static final String RECORDINGS_BUCKET_NAME = System.getenv("RECORDINGS_BUCKET_NAME");
private static final String RECORDINGS_KEY_PREFIX = System.getenv("RECORDINGS_KEY_PREFIX");
private static final boolean RECORDINGS_PUBLIC_READ_ACL = Boolean.parseBoolean(System.getenv("RECORDINGS_PUBLIC_READ_ACL"));
private static final String START_SELECTOR_TYPE = System.getenv("START_SELECTOR_TYPE");
private static final String TRANSCRIPT_TABLE_NAME = System.getenv("TRANSCRIPT_TABLE_NAME");
private static final int LIMITDAY_OF_TTL = Integer.parseInt(System.getenv("LIMITDAY_OF_TTL"));
変数を, Lambdaの環境変数から設定しています。
public String handleRequest(TranscriptionRequest request, Context context) {
logger.info("received request: " + request.toString());
logger.info("received context: " + context.toString());
try {
// create a SegmentWriter to be able to save off transcription results
AmazonDynamoDBClientBuilder builder = AmazonDynamoDBClientBuilder.standard();
builder.setRegion(REGION.getName());
fromCustomerSegmentWriter = new TranscribedSegmentWriter(request.getConnectContactId(), new DynamoDB(builder.build()));
// Start Google Speech to Text
startKVSToTranscribeStreaming(request.getStreamARN(), request.getStartFragmentNum(), request.getConnectContactId(), request.getSaveCallRecording(), request.getPhoneNumber());
return "{ \"result\": \"Success\" }";
} catch (Exception e) {
logger.error("KVS to Transcribe Streaming failed with: ", e);
return "{ \"result\": \"Failed\" }";
}
}
この関数は, エントリーポイントです。requestに, kvsConsumerTriggerからの引数が格納されています。受け取る引数を増やしたい場合などは, TranscriptionRequest.java を改良して下さい。
コード内容としては, 書き込む用のDynamoのインスタンスを生成した後に, startKVSToTranscribeStreaming()を呼び出して, 文字起こしを始めます。
private void startKVSToTranscribeStreaming(String streamARN, String startFragmentNum, String contactId,Optional<Boolean> saveCallRecording, String phoneNumber) throws Exception {
String streamName = streamARN.substring(streamARN.indexOf("/") + 1, streamARN.lastIndexOf("/"));
KVSStreamTrackObject kvsStreamTrackObjectFromCustomer = getKVSStreamTrackObject(streamName, startFragmentNum, KVSUtils.TrackName.AUDIO_FROM_CUSTOMER.getName(), contactId);
// Parameters required to get the audio stream from KVS
StreamingMkvReader streamingMkvReader = kvsStreamTrackObjectFromCustomer.getStreamingMkvReader();
FragmentMetadataVisitor fragmentVisitor = kvsStreamTrackObjectFromCustomer.getFragmentVisitor();
KVSContactTagProcessor tagProcessor = kvsStreamTrackObjectFromCustomer.getTagProcessor();
int CHUNK_SIZE_IN_KB = 4;
String track = kvsStreamTrackObjectFromCustomer.getTrackName();
ここでは, KVSから音声を取得するのに必要な処理を行います。まず, getKVSStreamTrackObject()を呼び出し, 音声ストリームを保持するインスタンスを生成します。この時, KVSからメディアコンテントを取得するGetMediaAPIを叩いています。
そして, 音声ストリームを取得する際に必要なパラメータを設定します。詳しくはコードを読むか, こちらを参考にして下さい。
String audio_file_path = URLEncoder.encode(kvsStreamTrackObjectFromCustomer.getSaveAudioFilePath().toString().replace(".raw", ".wav").replace("/tmp/", ""), "UTF-8");
String audio_file_link = "https://" + RECORDINGS_BUCKET_NAME + ".s3-ap-northeast-1.amazonaws.com/"+ RECORDINGS_KEY_PREFIX + audio_file_path;
音声ファイルのリンクを取得します。
try (SpeechClient client = SpeechClient.create()) {
ClientStream<StreamingRecognizeRequest> clientStream;
responseObserver =
new ResponseObserver<StreamingRecognizeResponse>() {
public void onStart(StreamController controller) {
logger.info(String.format("GoogleSTT Start"));
replyCount = 1;
}
public void onResponse(StreamingRecognizeResponse response) {
logger.info("===response===");
System.out.println(response);
StreamingRecognitionResult result = response.getResultsList().get(0);
SpeechRecognitionAlternative alternative = result.getAlternativesList().get(0);
String transcript_segment = alternative.getTranscript();
float confidence = alternative.getConfidence();
logger.info(String.format("Transctipt : %s\n", transcript_segment));
logger.info(String.format("Confidence : %f\n", confidence));
// IsFinalが真なら
if(result.getIsFinal()){
fromCustomerSegmentWriter.writeToDynamoDB(transcript_segment, phoneNumber, TRANSCRIPT_TABLE_NAME, replyCount, audio_file_link, LIMITDAY_OF_TTL);
replyCount++;
}
}
public void onComplete() {
logger.info(String.format("GoogleSTT Complete"));
}
public void onError(Throwable t) {
logger.error(String.format("GoogleSTT Error : %s\n", t));
}
};
GoogleSTTを実行するクライアントを生成した後に, レスポンスが返ってきた時の処理を定義しています。onResponse()に注目して下さい。文字起こし結果がここに返ってきます。GoogleSTTは, 文字起こしが中間結果か最終結果かを表すフラグIsFinalも返します。これが真の場合, Dynamoに文字起こしを書き込んでいます。また, Dynamoに書き込んだ後にreplyCountをインクリメントしています。(書き込んだら,1回返答がされた事を意味するため)
GoogleSTTのレスポンスについて詳しく知りたい方は, これらを参考にすると良いでしょう。
- https://cloud.google.com/speech-to-text/docs/reference/rpc/google.cloud.speech.v1?hl=ja#streamingrecognizeresponse
- https://cloud.google.com/speech-to-text/docs/basics?hl=ja
// request parameter
RecognitionConfig recognitionConfig =
RecognitionConfig.newBuilder()
.setEncoding(RecognitionConfig.AudioEncoding.LINEAR16)
.setLanguageCode("ja-JP")
.setSampleRateHertz(8000) // great for phone voice
.setEnableAutomaticPunctuation(true)
.setUseEnhanced(true) // use enhanced model
.build();
StreamingRecognitionConfig streamingRecognitionConfig =
StreamingRecognitionConfig.newBuilder()
.setConfig(recognitionConfig)
.setSingleUtterance(false)
.build();
StreamingRecognizeRequest request_google =
StreamingRecognizeRequest.newBuilder()
.setStreamingConfig(streamingRecognitionConfig)
.build();
// Send configuration request
clientStream.send(request_google);
GoogleSTTの設定リクエストを送っています。
注意点として, SampleRateHertzは8000にした方が良いです。電話音声に適しています。
// Get audio stream and send request to Google STT
while (true) {
// Get audio stream
ByteBuffer audioBuffer = KVSUtils.getByteBufferFromStream(streamingMkvReader, fragmentVisitor,
tagProcessor, contactId, CHUNK_SIZE_IN_KB, track);
if (audioBuffer.remaining() > 0) {
byte[] audioBytes = new byte[audioBuffer.remaining()];
audioBuffer.get(audioBytes);
// send request to Google STT
request_google = StreamingRecognizeRequest.newBuilder()
.setAudioContent(ByteString.copyFrom(audioBytes)).build();
clientStream.send(request_google);
// Write audio stream to outputStream
kvsStreamTrackObjectFromCustomer.getOutputStream().write(audioBytes);
} else {
break;
}
}
音声ストリームをgetByteBufferFromStream()で取得し, GoogleSTTにリクエストしています。さらに, 音声ファイルを作成するためにOutputStreamに音声データを書き込んでいます。
while文は, audioBufferが無くなれば抜けることができます。つまり, 電話が切れて, audioBufferが無くなった時にループを抜ける事ができます。
try {
// save wav file to s3
closeFileAndUploadRawAudio(kvsStreamTrackObjectFromCustomer,contactId,saveCallRecording);
}catch(IOException e){
logger.info(String.format("Error closeFile and UploadRawAudio: %s\n", e));
}
音声ファイルをwavファイルとしてs3に保存しています。
以上が, kvsConsumerGoogleSTTの説明になります。
色々説明しましたが, コードを読んで理解した方が良いと思うので, じっくり読んでみて下さい。
補足
-
Lambdaのメモリサイズは, 1000MB以上に設定しておくと安心です。低すぎると, メモリ不足によるエラーが起きる場合があります。また, メモリサイズによって, Lambdaが起動してから, GoogleSTTが開始されるまでの時間が結構変わるので, 注意して下さい。おそらく, GetMediaによるものだと思います。
-
このLambdaは, 無限に文字起こしするようなコードになっています。ですが, Lambdaは最大15分までしか起動しないので, 注意して下さい。「文字起こし結果を書き込んだら, 一旦Lambdaを終了して, また起動する」みたいな方法で回避する事もできます。
-
もしかすると, 音声の問題で, プログラムは正常に動いているが, GoogleSTTが文字起こしを返してくれない可能性があるかもしれません。その場合は, GoogleSTTのリクエスト方法を変えて試して下さい。
例えば, 「setSingleUtterance(true)にして, レスポンスが返ってきたら, 再リクエストをしてGoogleSTTを再開する」みたいな方法があります。
参考
KVSの音声取得, Dynamoの書き込み, s3への保存などは, こちらを参考にしました.
GoogleSTTの部分は, こちらを参考にしました.
transcriptGet
このLambdaを作っていきます↓
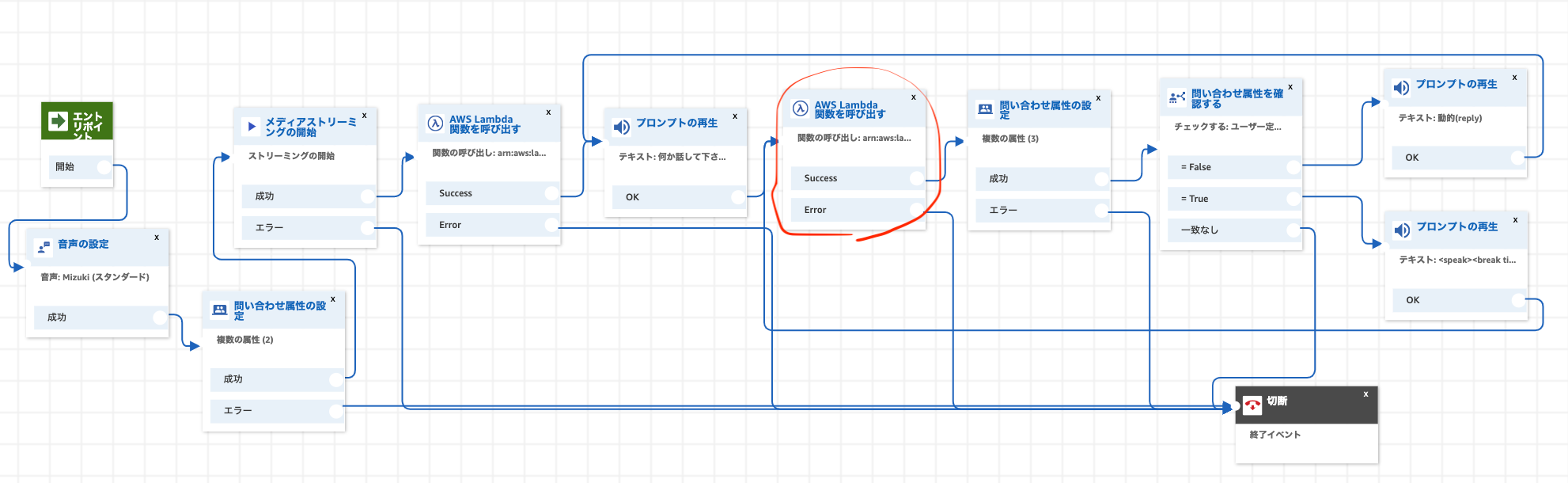
完全なコードはこちら↓
import boto3
import json
import os
from boto3.dynamodb.conditions import Key
dynamodb = boto3.resource('dynamodb')
def lambda_handler(event, context):
# AmazonConnectから受け取ったevent
contactId = event['Details']['ContactData']['ContactId']
replyCount = int(event['Details']['ContactData']['Attributes']['replyCount'])
# 環境変数
table_name = os.environ['TABLE_NAME']
# 取得したいレコードのキー
partition_key = { "ContactId":contactId , "ReplyCount":replyCount }
dynamotable = dynamodb.Table(table_name)
try:
# 指定したキーのレコードを取得
response = dynamotable.get_item(Key=partition_key)
reply = response["Item"]["Transcript"]
except KeyError as e:
# 該当するキーが無い時
return { "reply":"エラー", "isKeyError": "True", "replyCount":replyCount }
except:
raise
return { "reply":reply, "isKeyError": "False", "replyCount":replyCount+1 }
このLambdaは, ContactIdとReplyCountをキーにして, Dynamoから特定のレコードを取得します。
取得できた場合は, isKeyErrorをFalseにして, replyCountをインクリメントして返します。(返答が1回された事を意味するので, 返答回数を増やしています)
該当するキーが存在しない場合は, isKeyErrorをTrueにして, replyCountはそのままで返します。(文字起こし結果がまだDynamoに書き込まれていない場合です)
それ以外の場合は, エラーを吐かせます。
Lambdaの環境変数TABLE_NAMEには, 文字起こしを書き込むDynamoのテーブル名を設定しておいて下さい。
終わりに
最後は, 問い合わせフローで, 作成したLambdaを設定をして, 取得した電話番号をその問い合わせフローに割り当てましょう。
以上で完成です。
これを応用すれば, 音声ボットが作れるでしょう。
興味のある方は, ぜひやってみて下さい!