この記事はQiita LLM・LLM活用 Advent Calendar 2024の7日目の記事です。
ここではQwen2-VLを例に、画像に対するBounding Boxを入力や出力に含む対話生成の例を見ていきます。
なおこの記事中における「理解」は、バウンディングボックスの概念が伝わるのみならず、テキストで表現されたバウンディングボックスの座標が画像中の正確な座標と結びつくことを意図しています。
VLMがBounding Boxを理解できる理由
一部のVLMは訓練時に明示的にBounding Boxが含まれたテキストでの学習を行っています。
Bounding Boxを明示的に学習しているVLMの例としては、LLaVA 1.5やQwen-VL (Qwen2-VL含む)、Fuyu-8Bが挙げられます。日本語特化モデルならLLaVA 1.5の学習に倣っているllava-calm2-siglipがBounding Boxの学習を行っています。
モデルがBounding Boxの座標をきちんと理解するにはその座標と画像中の位置のハードな結びつきの理解が必須ですので、逆に明示的に学習していないVLMにはBounding Boxを与えたところで、その概念の理解はできたとて座標としては微妙にずれた応答をしても仕方ありません。
具体的なテキスト形式|Qwen2-VLの場合
具体的にどういうタスクを行っているか、そのプロンプト・出力の形式がどうなっているかは各モデルの論文中などに記載があります。
例えばQwen2-VLでのBounding Boxの入力形式は、画像の縦横サイズをそれぞれ1000として正規化した上で、(left,top),(right,bottom)の形のテキストで表現します。そしてモデルがその数値をBounding Boxであると捉えやすくなるように専用のspecial token <|box_start|>と<|box_end|>で修飾します。さらにBounding Boxに結びつくオブジェクトのテキストも<|object_ref_start|>と<|object_ref_end|>で修飾します。special tokenはそれぞれ1トークンずつですが、座標部分は普通のsubwordで表現されます。
結果として次の形になります。
... <|object_ref_start|>{{OBJECT_NAME}}<|object_ref_end|><|box_start|>({{left}},{{top}}),({{right}},{{bottom}})<|box_end|> ...
タスクとしてはBounding Boxに基づく画像説明だったり、OCRだったりを学習させているようです。
論文中の具体例1。学習中に青い部分を正しく生成するよう学習させています。

引用元: Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
逆にBounding Boxを聞きたいオブジェクトはシングルクォートで囲むのがマナーのようです。
論文中の具体例2。モデルとの対話の例。下側の画像はBounding Box図示のために見せられているだけでQwen2-VLの出力はテキストだけです。一応。

引用元: Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
ちなみにQwen-VLとQwen2-VLではspecial tokenが違うので注意してください。
実際にやってみる
ここではQwen/Qwen2-VL-7B-Instruct-GPTQ-Int4を使っています。
ケース1
画像右上のほうのnegativeというラベルに対するBounding Boxを当ててみます。
入力画像

狙うのはここです。
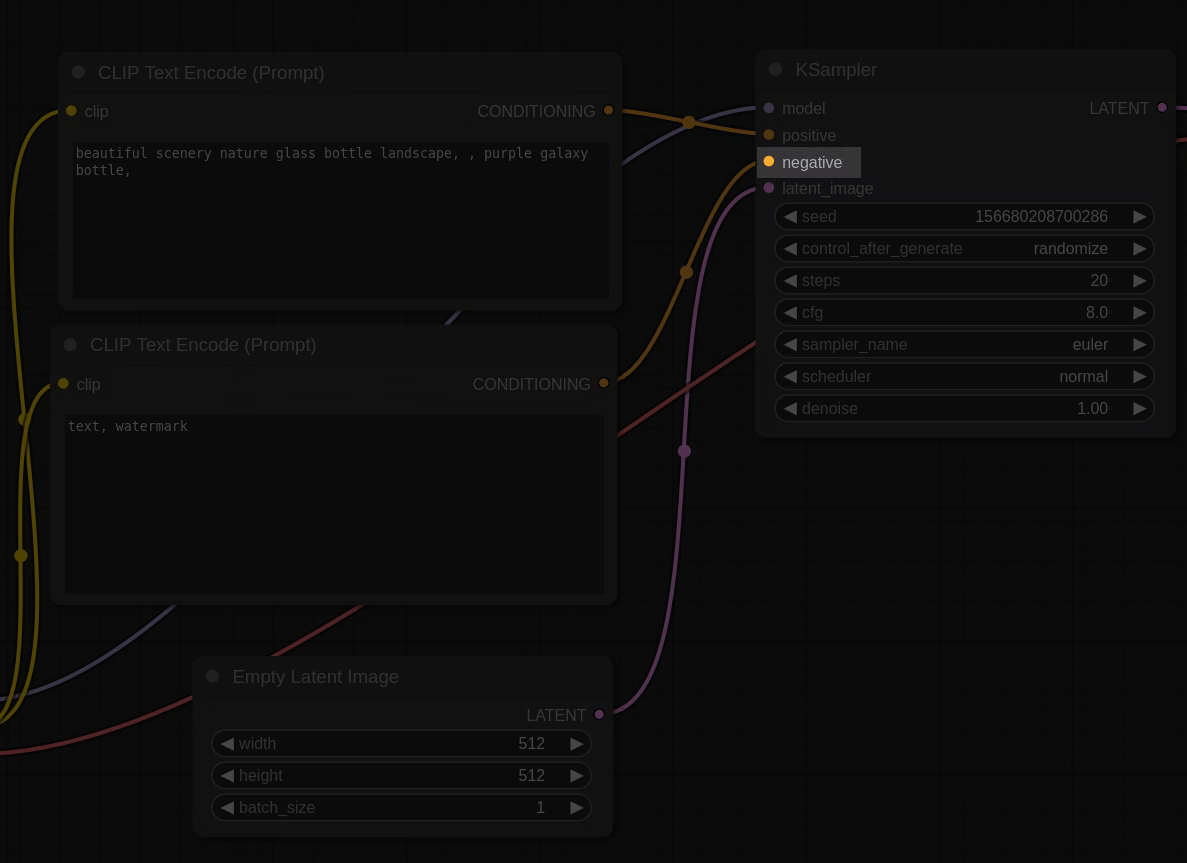
入力の準備:
# processor = transformers.AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct-GPTQ-Int4")
OBJECT = "negative written in KSample block"
messages = [
{
"role": "user",
"content": [
{ "type": "image", "image": "file:///path/to/image.png" },
{
"type": "text",
"text": f"Detect the bounding box of '{OBJECT}'."
},
],
},
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = qwen_vl_utils.process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt").to("cuda")
入力テキスト全体
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<|vision_start|><|image_pad|><|vision_end|>Detect the bounding box of 'negative written in KSample block'.<|im_end|>
<|im_start|>assistant
応答:
The bounding box for the text "negative" in the KSampler block is:
- Top-left corner: (x: 650, y: 150)
- Bottom-right corner: (x: 670, y: 170)<|im_end|>
・・・いきなり出鼻をくじかれました。まず出力が期待するフォーマットと違います。さらに図示してみると思いっきりずれてます。

ケース2
途中まで無理やり出力を固定して期待するフォーマットに合わせてみます。
OBJECT = "negative written in KSample block"
messages = [
{
"role": "user",
"content": [
{ "type": "image", "image": "file:///path/to/image.png" },
{
"type": "text",
"text": f"Detect the bounding box of '{OBJECT}'."
},
],
},
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# ----------- ここが大事 -----------
text += f"<|object_ref_start|>{OBJECT}<|object_ref_end|><|box_start|>"
# ----------- /ここが大事 -----------
image_inputs, video_inputs = qwen_vl_utils.process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt").to("cuda")
入力テキスト全体
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<|vision_start|><|image_pad|><|vision_end|>Detect the bounding box of 'negative written in KSample block'.<|im_end|>
<|im_start|>assistant
<|object_ref_start|>negative written in KSample block<|object_ref_end|><|box_start|>
応答
(655,171),(705,201)<|box_end|><|im_end|>
図示
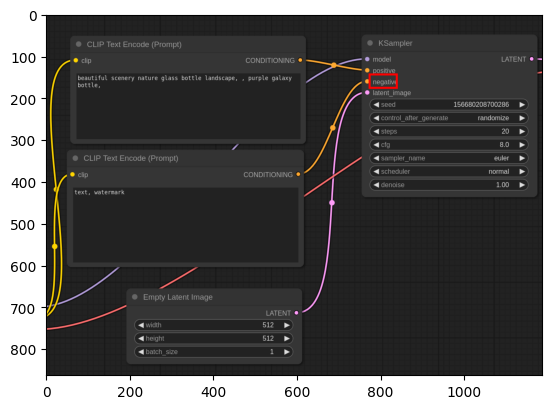
今度はばっちりです。学習時と同じフォーマットに合わせるのが板。
ケース3
Systemプロンプトでフォーマットを誘導してみます。出力の先頭指定は外します。
OBJECT = "negative written in KSample block"
messages = [
{
"role": "system",
"content": "You are a helpful assistant. When output a bounding box of the object in the image, the bounding box should start with <|box_start|> and end with <|box_end|>."
},
{
"role": "user",
"content": [
{ "type": "image", "image": "file:///path/to/image.png" },
{
"type": "text",
"text": f"Detect the bounding box of '{OBJECT}'."
},
],
},
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# text += f"<|object_ref_start|>{OBJECT}<|object_ref_end|><|box_start|>" # 今回は先頭指定なし
image_inputs, video_inputs = qwen_vl_utils.process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt").to("cuda")
入力テキスト全体
<|im_start|>system
You are a helpful assistant. When output a bounding box of the object in the image, the bounding box should start with <|box_start|> and end with <|box_end|>.<|im_end|>
<|im_start|>user
<|vision_start|><|image_pad|><|vision_end|>Detect the bounding box of 'negative written in KSample block'.<|im_end|>
<|im_start|>assistant
応答
<|object_ref_start|>negative written in KSample block<|object_ref_end|><|box_start|>(655,175),(705,205)<|box_end|><|im_end|>
図示
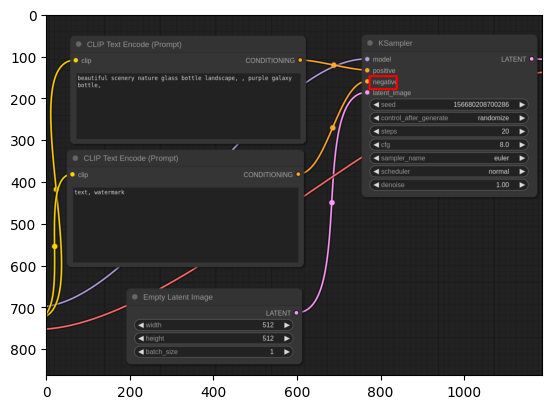
普通に期待するフォーマットそのものが出てくるようになりました。座標は先程のケースとはわずかに違うものの、これも正しいと言って良さそうな範疇です。
ケース4
逆に入力でBounding Boxを与えます。狙うのは画像右上のseedのところの値です。
messages = [
{
"role": "user",
"content": [
{ "type": "image", "image": "file:///path/to/image.png" },
{
"type": "text",
"text": "What is written in <|object_ref_start|>the bounding box<|object_ref_end|><|box_start|>(819,228),(955,265)<|box_end|>?",
},
],
},
]
図示。入力で意図するBounding Boxを右上赤枠で示していますが、実際にQwen2-VLに与える画像は先程までと同様この赤枠が描かれていない画像を入力しています。

応答
The bounding box contains the text "156680208700286".
入力側で与えられたBounding Boxテキストの指し示す座標も理解できています。
ケース5
マルチターンです。ケース3同様special tokenの誘導はsystemプロンプトで行い、先頭出力の固定化は行っていません。
モデルからの応答に続いて追加の質問を何度も繰り返しています。
入力画像

最初の質問の用意
messages = [
{
"role": "system",
"content": "You are a helpful assistant. When output a bounding box of the object in the image, the bounding box should start with <|box_start|> and end with <|box_end|>."
},
{
"role": "user",
"content": [
{ "type": "image", "image": "file:///path/to/img.png" },
{
"type": "text",
"text": "How many cards are there in the image?"
},
],
},
}
入力テキスト全体(マルチターン開始時)
<|im_start|>system
You are a helpful assistant. When output a bounding box of the object in the image, the bounding box should start with <|box_start|> and end with <|box_end|>.<|im_end|>
<|im_start|>user
<|vision_start|><|image_pad|><|vision_end|>How many cards are there in the image?<|im_end|>
<|im_start|>assistant
各ターンの質問・応答結果です。直前の応答に続けて新しい質問をくっつけて応答生成を繰り返しています。質問側も当然<|im_end|>で毎回終わりますがこのテーブルではオミットしてます。
途中からずっと隣の座標を聞き続けているので同じ質問が続きます。
| 質問/応答 | テキスト |
|---|---|
| 質問 | How many cards are there in the image? |
| 応答 | There are seven cards in the image.<|im_end|> |
| 質問 | Detect the boundary box of the right most card. |
| 応答 | <|object_ref_start|>the right most card<|object_ref_end|><|box_start|>(725,271),(951,775)<|box_end|><|im_end|> |
| 質問 | Detect the boundary box of the next card. |
| 応答 | <|object_ref_start|>the next card<|object_ref_end|><|box_start|>(635,241),(775,703)<|box_end|><|im_end|> |
| 質問 | Detect the boundary box of the next card. |
| 応答 | <|object_ref_start|>the next card<|object_ref_end|><|box_start|>(535,225),(655,693)<|box_end|><|im_end|> |
| 質問 | Detect the boundary box of the next card. |
| 応答 | <|object_ref_start|>the next card<|object_ref_end|><|box_start|>(425,225),(535,693)<|box_end|><|im_end|> |
| 質問 | Detect the boundary box of the next card. |
| 応答 | <|object_ref_start|>the next card<|object_ref_end|><|box_start|>(297,241),(425,707)<|box_end|><|im_end|> |
| 質問 | Detect the boundary box of the next card. |
| 応答 | <|object_ref_start|>the next card<|object_ref_end|><|box_start|>(165,241),(297,747)<|box_end|><|im_end|> |
| 質問 | Detect the boundary box of the next card. |
| 応答 | <|object_ref_start|>the next card<|object_ref_end|><|box_start|>(31,271),(165,779)<|box_end|><|im_end|> |
図示

実のところ入力画像の暗くなってる領域には下部中央の1枚やら対戦相手側の手札やらデッキやらがあるので正確には7枚ではない・・・のですがそれは置いておいてかなりうまくいっています。
VLMはBounding Boxを理解している!
Limitation
残念ながらまだ完璧な精度というわけではなく、やってみた例を見ても分かるかと思いますが入力依存の傾向がかなりあります。
ここではプロンプトの違いの例だけしか出していませんが、他にも試してみた感じ入力画像のサイズにもかなり影響されます。サイズが大きすぎても小さすぎても失敗に繋がりやすくなり、いい感じにリサイズするとうまく行くというケースにいくつか遭遇しました。これはBounding Boxを用いる場合に限らず、他の種の質問応答でも同じような傾向です。
また、一つの応答内に複数のBounding Boxを出力させようとしても失敗しがちになりました。上の例でマルチターンで応答させているのはそういう事情もあります。無印Qwen-VLの論文を見る感じ学習データには複数Bounding BoxのケースもあるようですしQwen2-VLでも同様の学習は行われていると思いますが、もしかしたら複数出現より単独出現の事例数の方がずっと多いとかはあるのかもしれません。
このように正直まだ厄介な性質はあるものの、うまくコントロールすれば現状でもかなり面白い結果が得られそうでもあり、今後に期待大です。
それとこの記事では定量的な評価は一切できていません。VLMのオブジェクト認識の具体的な性能周りは自分はよく知らないというのが情けないものの正直なところです。実際のところBounding Boxが欲しいだけなら素直にOpen-Vocabulary Object Detectionモデルを使うほうがよさそうな感じはあるのでわざわざVLMを使うなら出力としてよりは入力としてBounding Boxを使ったり、あるいはすごく複雑な出力がほしいケースで使いたい気がしますが、画像処理ガチ勢の皆様方このあたりどうなんでしょうか・・・