はじめに
一家に一台 Kubernetes クラスタがある時代がやってきました。Z Lab Advent Calendar 2018 の 1日目 では、@superbrothers がインスタ映えするクラスタの作り方を記事にしていました。そこで今度はより実践的に Kubernetes クラスタで自宅サーバを組もうと思った場合、どのような構成になるかを紹介します。
はじめに その2
最初の会社に入社して、最初のボーナスで買ったのは自宅サーバ用に VIA C3 がオンボードで乗った Mini-ITX のマザーボードだったことを思い出す今日この頃。途中で Transmeta の Efficeon だったり、Pentium M だったり、 Mac mini に移行したり色々移り変わりはあったものの、自宅サーバを始めた頃のデータをそのまま引き継いで今にいたります。
直近の構成は Intel NUC のメモリ 16GB / Ubuntu Trusty のシングルホストで Docker でした。アプリケーション (Docker コンテナ) のデプロイには Ansible を使っていました。この構成で今まで自宅サーバで運用していた諸処の問題が解決するにいたり、 コンテナ素晴らしいな! と認識したものです。そこで今度はそれをクラスターで運用して、さらにコンテナのメリットを享受したくなったのでした。
基本方針
- 全てを Kubernetes / コンテナで管理する。
- ネットワークと電源の冗長化は諦める。(それ以外は冗長化する)
ステートフルなアプリケーション、Kubernetes それ自体を含めて Kubernetes で管理したいと思います。クラスタの運用は全て kubectl コマンドで!
と、言っても、自分の技術的な未熟のせいで結局この基本方針の対象外としたものは以下になります。
- クラスターそれ自体の
Manifestの置き場- クラスターが壊れた時の復旧ができないので、GitHub のプライベートレポジトリです…。
- ルーター
- 自作して
kubeletでサービスを管理すれば行けそう。 - とりあえずルータの監視は Prometheus と連携したい。
- 自作して
- 自宅ネットワークの DHCP サーバ
- これも Kubernetes 上に乗っけることは可能なんじゃ?と思わなくもないですが、既存のネットワークをいじるのが面倒なので、ルーター付属のものを使ってます。
- スイッチングハブ
- 自作するのも現実的ではないので。
他にもある気がしますが、とりあえず思いつくものは以上。
物理構成
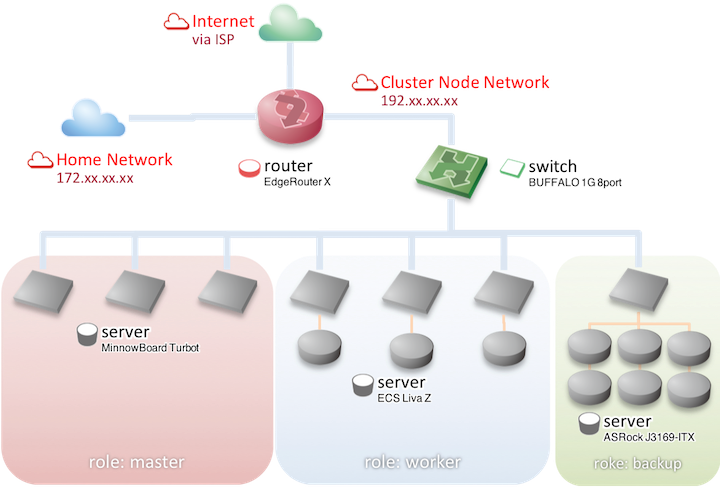
Kubernetes クラスタ自体は、Kubernetes のコントロールプレーンを配置するノード 3 台と、通常のワーカーノード 3 台、バックアップ用途の NFS+ZFS 専用ノード 1 台の計 7 台構成です。VM とかは介さず、ベアメタル。
概要は以下。
- マスターロールノード (Container Linux by CoreOS stable)
- Minnowboard Turbot
- WesternDigital SSD Green 120GB
- ワーカーロールノード (Container Linux by CoreOS stable)
- ECS Liva Z
- DDR3 SO-DIMM PC3-12800 16GB (8GB x 2)
- WesternDigital SSD Blue 250GB
- INTEL SSD 525 Series mSATA 120GB
- バックアップロールノード (Ubuntu 18.04)
- ASRock J3160-ITX
- DDR3 SO-DIMM PC3-12800 8GB (4GB x 2)
- WesternDigital SSD Green 120GB
- WesternDigital Red 6TB x 3
- WesternDigital Blue 6TB x 3
マスターロールノード
そもそも自分がなぜ Kubernetes を自宅で飼ってみようと思ったかというと、きっかけは以下のツイートでした。
It's alive! My home Kubernetes cluster is alive! pic.twitter.com/BH4P6ysbJJ
— Ian Lewis (@IanMLewis) 2016年12月23日
ここで使われている SoC が Minnowboard Turbot というボードである、ということを知ると、一瞬考えたのちに、6枚発注してました。結局、後々、他に良いボードがあること や、ワーカーに使うにはいささか貧弱であるということが発覚したため、とりあえずマスターノード用途に使うことにしました。
また、マスターノードは etcd を飼う計画であるため、ストレージには SSD を利用しています。

ワーカーロールノード
ECS の Liva Z, Pentium N4200 モデル にメモリ 16GB、そして内臓の eMMC で容量に問題が出たため M.2 2242 接続の SSD 120GB を増設して /var/lib/docker にマウントしてあります。また、Rook でデプロイした Ceph の osd を飼うノードを兼任するために、USB 3.0 接続の SSD も追加しました。Ceph を飼うには少し CPU のスペックが足りない感じがしなくはないです。

バックアップロールノード
全てのデータを Ceph on Rook on Kubernetes で管理しても良いのですが、このうちどれかが壊れたら全てのデータが飛ぶんじゃないかと言う恐れから、バックアップ用途にディスクをHDD6台, システム用に SSD 1台積んだノードを追加しました。

WesternDigital の Red 6TB x3, Blue 6TB x3 で raidz2 の構成で 21TB です。Kubernetes からは NFS で接続します。使っているマザーボードは ASRock の J3160-ITX なので SATA の口が微妙に足りないため PCIe 2.0 to SATA III 3 port のアダプタカードで拡張してあります。
ミドルウェア
Kubernetes
何はともあれ Kubernetes です。自宅クラスターで起動しているプロセスは全て Kubernetes で管理されています。が、この自宅クラスターを管理している Kubernetes 自体も Kubernetes で管理されています。現時点での構成はこんな感じ。
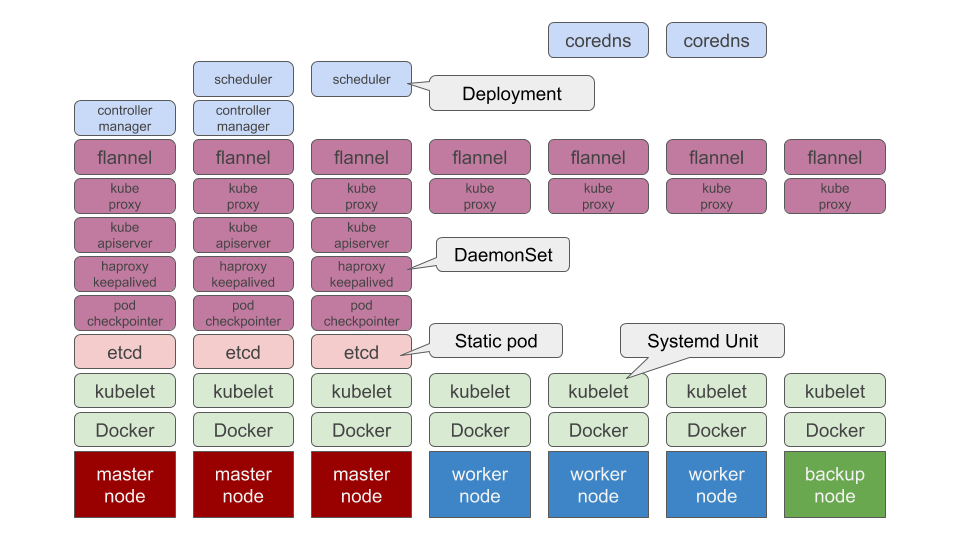
すみません、図を描いてて気づきました。Docker と kubelet は systemd で管理されてますね。それ以外だと etcd が Static pod、kube-apiserver がマスターロールノード上で DaemonSet で起動、HAProxy/Keepalived で冗長化されています。kube-controller-manager や kube-scheduler、CoreDNS といったどこで起動してても構わないプロセスは Deployment としてデプロイされています。
ちなみにデプロイ方法は、自前のスクリプト です。
kube-system はこちら。
$ k get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7fbd6fbf45-6f5xf 1/1 Running 0 2d5h
coredns-7fbd6fbf45-bbt6d 1/1 Running 0 9d
etcd-192.168.1.111 1/1 Running 0 42d
etcd-192.168.1.112 1/1 Running 0 42d
etcd-192.168.1.113 1/1 Running 0 42d
kube-apiserver-ncfxr 1/1 Running 0 42d
kube-apiserver-t5p87 1/1 Running 0 42d
kube-apiserver-whsf9 1/1 Running 0 42d
kube-controller-manager-68cd59c45f-2h9kt 1/1 Running 1 42d
kube-controller-manager-68cd59c45f-cjzxv 1/1 Running 0 42d
kube-dns-autoscaler-65659d5f76-sk4tt 1/1 Running 0 2d5h
kube-flannel-ds-d25kd 1/1 Running 0 14d
kube-flannel-ds-hbnzw 1/1 Running 0 14d
kube-flannel-ds-mp4g9 1/1 Running 1 14d
kube-flannel-ds-ssw24 1/1 Running 0 14d
kube-flannel-ds-zb6ht 1/1 Running 0 14d
kube-flannel-ds-zftd5 1/1 Running 0 14d
kube-flannel-ds-zhgpl 1/1 Running 0 14d
kube-keepalived-4jg94 2/2 Running 0 42d
kube-keepalived-5ppxx 2/2 Running 0 42d
kube-keepalived-db7v6 2/2 Running 0 42d
kube-proxy-8kwqp 1/1 Running 1 14d
kube-proxy-d4b6r 1/1 Running 0 42d
kube-proxy-frj2n 1/1 Running 0 42d
kube-proxy-h8j2t 1/1 Running 0 42d
kube-proxy-n855q 1/1 Running 0 42d
kube-proxy-sn57r 1/1 Running 0 42d
kube-proxy-sp2pm 1/1 Running 0 42d
kube-scheduler-76798585f7-7z6hg 1/1 Running 1 42d
kube-scheduler-76798585f7-bd7bj 1/1 Running 0 42d
pod-checkpointer-9l4n2 1/1 Running 0 42d
pod-checkpointer-9l4n2-192.168.1.113 1/1 Running 0 42d
pod-checkpointer-bcmsr 1/1 Running 0 42d
pod-checkpointer-bcmsr-192.168.1.112 1/1 Running 0 42d
pod-checkpointer-qqk68 1/1 Running 0 42d
pod-checkpointer-qqk68-192.168.1.111 1/1 Running 0 42d
Ceph
Ceph は Rook でデプロイしてます。もう、だんだん面倒になって来たので簡単に cluster manifest を載せます。
---
apiVersion: ceph.rook.io/v1beta1
kind: Cluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
dashboard:
enabled: true
placement:
osd:
tolerations:
- effect: NoSchedule
operator: Exists
dataDirHostPath: /var/lib/rook-ceph
serviceAccount: rook-ceph-cluster
mon:
count: 3
allowMultiplePerNode: true
network:
# toggle to use hostNetwork
hostNetwork: false
storage:
useAllNodes: false
useAllDevices: false
storeConfig:
storeType: bluestore
databaseSizeMB: 1024
journalSizeMB: 1024
nodes:
- name: "192.168.1.131"
resources:
limits:
cpu: "500m"
memory: "2048Mi"
requests:
cpu: "500m"
memory: "1024Mi"
devices:
- name: "sdb"
- name: "192.168.1.133"
resources:
limits:
cpu: "500m"
memory: "2048Mi"
requests:
cpu: "500m"
memory: "1024Mi"
devices:
- name: "sdb"
- name: "192.168.1.132"
resources:
limits:
cpu: "500m"
memory: "2048Mi"
requests:
cpu: "500m"
memory: "1024Mi"
devices:
- name: "sdb"
最初、resources.limits.memory を 1024Mi で運用していたのですが、妙に不安定で、2048Mi にしてからなんとか安定した感じです。ちゃんとリソースプランニングしないとダメですな!
あと、Rook のログを見てて思ったのだが、device の名前はもしかしたら /dev/disk/by-id/ とかでも指定できそうであった。
NFS
gcr.io/google_containers/volume-nfs:0.8 のコンテナイメージを利用。バックアップロールのノードにディスク六本まとめた raidz2 構成のストレージをマウントした DaemonSet を起動しています。
バックアップ方法は、
- 毎晩 Ceph のファイルシステムから
rsyncするCronJobを起動。 - 手作業で
zfs snapshot
おわりに
とりあえずこんなな感じで、自宅でまあまあ安定して運用できる Kubernetes クラスタの作り方を紹介しました。実際に Ceph の C の字もわからないで運用始めると、安定どころかデータをクラッシュしまくるので、だれか Ceph の運用方法教えてください。
このエントリは、弊社 Z Lab のメンバーによる Z Lab Advent Calendar 2018 の5日目として業務時間中に書きました。6日目は @ysakashita の担当です。