クラウドのマネージドサービスが楽でいいよなぁと思いながら CentOS 7 + PostgreSQL 10 のサーバー3台で pacemaker を使ったクラスタを作成してみます
TL;DR
Vagrant で試すためのファイルが https://github.com/yteraoka/postgresql10-pacemaker にあります
改善点など issue や PR をお願いします
$ git clone https://github.com/yteraoka/postgresql10-pacemaker.git
$ cd postgresql10-pacemaker
$ ssh-keygen -t rsa -b 2048 -P "" id_rsa
$ vagrant up
3台起動したら db1 にログインします
$ vagrant ssh db1
init.sh を実行するとクラスタが作成されます
$ bash /vagrant/init.sh
GoCardless の Postmortem
今日たまたま Nuzzel (最近のお気に入りアプリです) で Incident review: API and Dashboard outage on 10 October 2017 という記事に出会いました
GoCardless というサイトで今年10月10日に発生した PostgreSQL クラスタのインシデントに対する postmortem です
この記事で作成するものとほぼ同じ構成のクラスタで発生したインシデントで大変興味深い
Master のディスクアレイで3本のディスク同時故障ってホントかよって思わなくもないが、私もファームウエアの問題でバタバタHDDが止まってRAID6が停止した経験があるからな・・・
Master のファイルシステムにアクセスできなくなった影響で Sync Standby のプロセスが一部クラッシュし、再起動してしまった影響で Master への昇格がうまくいかなかったようだ。それでも Master をシャットダウンすれば残りの2台でなんとかクラスタ組んだまま復旧できそうなものだがうまくいかなかったらしい
そして、今は以前から検討していた Zero-downtime upgrade が可能な構成になっているそうだ。Youtube (Zero-downtime Postgres Upgrades) にプレゼンが公開されている
手前に pgBouncer を入れて、切替時に一瞬 pgBouncer で待たせるっぽい
最近 pgBouncer の事例をちょいちょい耳にしますね、PostgreSQL への接続数を減らす効果もある一方、server side prepared statement が使えなくなるデメリットも有る
GitLab EE の例 ではどこで使われるかわからない、クラウドかもしれないしということでか repmgrd + Consul + pgBouncer でした
Zero-downtime つながりでこれもリンクをはっておこう Near-Zero Downtime Automated Upgrades of PostgreSQL Clusters in Cloud
構成説明
やっとこの記事の本題へ
- 3台の CentOS 7 サーバー
- PGDG の YUM Repository から PostgreSQL 10.x をインストール
- Resource Agent は PostgreSQL 10 対応のために GitHub から最新のものを取得
- 3台がそれぞれ Master、Sync Standby、ASync Standby となる
- Master が Master 用 VIP をもつ
- Sync Standby が Replica 用 VIP をもつ(ReadOnly アクセス用)
- Standby が2台とも Down している場合は Master がこれも持つ
- Replication Slot は使用しない
- failover 時に新 Master に slot が存在せず(replicateされない)、Slave が接続できない
- Slave が突然死ぬと Master に WAL が残り続けて困る?
- Archive Log は rsync over SSH で自分以外の2台へ送る
- Quorum、Stonith は無効
- replication traffic 用ネットワークを別途作らない(作っても良いけど)
図解
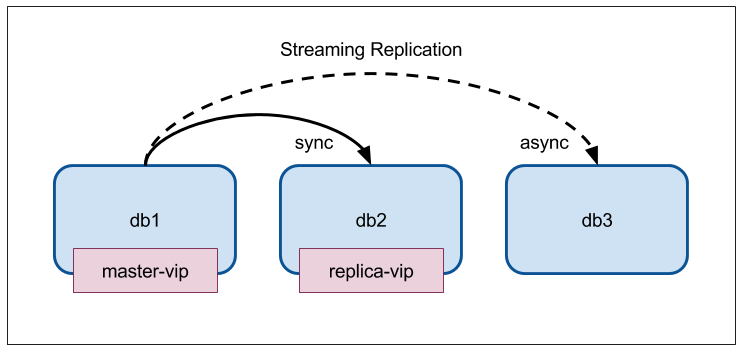
初期状態確認
[vagrant@db1 ~]$ sudo pcs status --full
Cluster name: pg10
Stack: corosync
Current DC: db2 (2) (version 1.1.16-12.el7_4.5-94ff4df) - partition with quorum
Last updated: Wed Dec 6 16:41:13 2017
Last change: Wed Dec 6 16:41:02 2017 by root via crm_attribute on db1
3 nodes configured
8 resources configured
Online: [ db1 (1) db2 (2) db3 (3) ]
Full list of resources:
master-vip (ocf::heartbeat:IPaddr2): Started db1
replica-vip (ocf::heartbeat:IPaddr2): Started db2
Clone Set: ping-clone [ping]
ping (ocf::pacemaker:ping): Started db1
ping (ocf::pacemaker:ping): Started db3
ping (ocf::pacemaker:ping): Started db2
Started: [ db1 db2 db3 ]
Master/Slave Set: pgsql-master [pgsql]
pgsql (ocf::heartbeat:pgsql10): Master db1
pgsql (ocf::heartbeat:pgsql10): Slave db3
pgsql (ocf::heartbeat:pgsql10): Slave db2
Masters: [ db1 ]
Slaves: [ db2 db3 ]
Node Attributes:
* Node db1 (1):
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 0000000005000098
+ pgsql-receiver-status : normal (master)
+ pgsql-status : PRI
+ pingd : 100
* Node db2 (2):
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-receiver-status : normal
+ pgsql-status : HS:sync
+ pingd : 100
* Node db3 (3):
+ master-pgsql : -INFINITY
+ pgsql-data-status : STREAMING|ASYNC
+ pgsql-receiver-status : normal
+ pgsql-status : HS:async
+ pingd : 100
Migration Summary:
* Node db1 (1):
* Node db3 (3):
* Node db2 (2):
PCSD Status:
db2: Online
db3: Online
db1: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[vagrant@db1 ~]$
db1 を止めてみる
VirtualBox マネージャから電源オフ
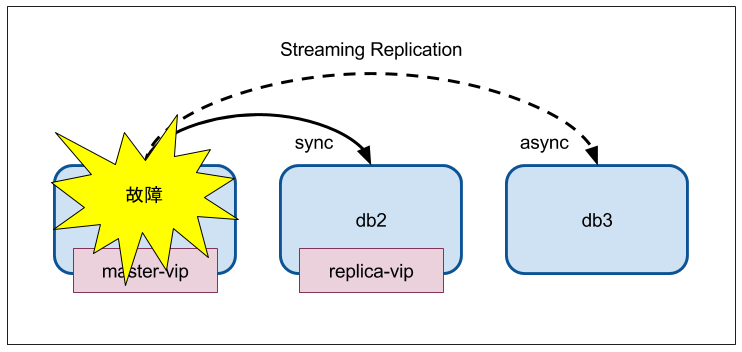
[vagrant@db2 ~]$ sudo pcs status --full
Cluster name: pg10
Stack: corosync
Current DC: db2 (2) (version 1.1.16-12.el7_4.5-94ff4df) - partition with quorum
Last updated: Wed Dec 6 16:45:30 2017
Last change: Wed Dec 6 16:45:15 2017 by root via crm_attribute on db2
3 nodes configured
8 resources configured
Online: [ db2 (2) db3 (3) ]
OFFLINE: [ db1 (1) ]
Full list of resources:
master-vip (ocf::heartbeat:IPaddr2): Started db2
replica-vip (ocf::heartbeat:IPaddr2): Started db3
Clone Set: ping-clone [ping]
ping (ocf::pacemaker:ping): Started db3
ping (ocf::pacemaker:ping): Started db2
ping (ocf::pacemaker:ping): Stopped
Started: [ db2 db3 ]
Stopped: [ db1 ]
Master/Slave Set: pgsql-master [pgsql]
pgsql (ocf::heartbeat:pgsql10): Slave db3
pgsql (ocf::heartbeat:pgsql10): Master db2
pgsql (ocf::heartbeat:pgsql10): Stopped
Masters: [ db2 ]
Slaves: [ db3 ]
Stopped: [ db1 ]
Node Attributes:
* Node db2 (2):
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 00000000062ACA00
+ pgsql-receiver-status : normal (master)
+ pgsql-status : PRI
+ pingd : 100
* Node db3 (3):
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-receiver-status : normal
+ pgsql-status : HS:sync
+ pingd : 100
Migration Summary:
* Node db3 (3):
* Node db2 (2):
PCSD Status:
db2: Online
db3: Online
db1: Offline
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[vagrant@db2 ~]$
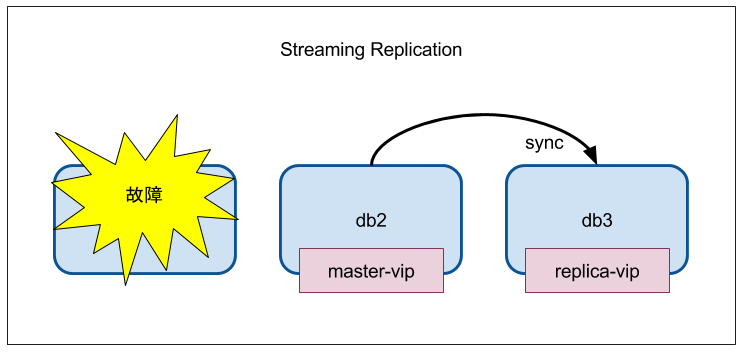
db1 復帰
起動させる
$ vagrant up db1
ホントは pg_basebackup からやりたいところだが、データが壊れていないこと前提でそのまま再度参加させてみる
異常終了後は起動しないように lock ファイルが残っているのでこれを削除
$ sudo rm /var/lib/pgsql/10/tmpdir/PGSQL.lock
起動させる
[vagrant@db2 ~]$ sudo pcs cluster start db1
db1: Starting Cluster...
[vagrant@db2 ~]$ sudo pcs status --full
Cluster name: pg10
Stack: corosync
Current DC: db2 (2) (version 1.1.16-12.el7_4.5-94ff4df) - partition with quorum
Last updated: Wed Dec 6 16:51:17 2017
Last change: Wed Dec 6 16:50:28 2017 by root via crm_attribute on db2
3 nodes configured
8 resources configured
Online: [ db1 (1) db2 (2) db3 (3) ]
Full list of resources:
master-vip (ocf::heartbeat:IPaddr2): Started db2
replica-vip (ocf::heartbeat:IPaddr2): Started db3
Clone Set: ping-clone [ping]
ping (ocf::pacemaker:ping): Started db1
ping (ocf::pacemaker:ping): Started db3
ping (ocf::pacemaker:ping): Started db2
Started: [ db1 db2 db3 ]
Master/Slave Set: pgsql-master [pgsql]
pgsql (ocf::heartbeat:pgsql10): Slave db1
pgsql (ocf::heartbeat:pgsql10): Slave db3
pgsql (ocf::heartbeat:pgsql10): Master db2
Masters: [ db2 ]
Slaves: [ db1 db3 ]
Node Attributes:
* Node db1 (1):
+ master-pgsql : -INFINITY
+ pgsql-data-status : STREAMING|ASYNC
+ pgsql-receiver-status : normal
+ pgsql-status : HS:async
+ pingd : 100
* Node db2 (2):
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 00000000062ACA00
+ pgsql-receiver-status : normal (master)
+ pgsql-status : PRI
+ pingd : 100
* Node db3 (3):
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-receiver-status : normal
+ pgsql-status : HS:sync
+ pingd : 100
Migration Summary:
* Node db1 (1):
* Node db3 (3):
* Node db2 (2):
PCSD Status:
db1: Online
db3: Online
db2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[vagrant@db2 ~]$
復帰した
12月7日がもうすぐ終わってしまうのでここまで。
そのうち続きを書くということで・・・