この記事は BrainPad AdventCalendar 2017 14日目のエントリーです。
ディープラーニングで日本語フォントを識別するおもちゃを作るまでの汗と涙の記録です。
はじめに

かなり昔の話ですが、8月に行われたMaker Faire Tokyoで「MSゴシック絶対許さんマン」というおもちゃを作って展示しました。
Maker Faire当日の様子などはブログにまとめたのですが、技術的な細かいことは書いてなかったのでこの場を借りてメモしておきたいと思います。
作ったもの
”フォント”の違いをディープラーニングで見分けるロボットアーム、“MSゴシック絶対許さんマン” を展示しました。
「なんかダサい」「仕事の文書っぽくて気分が下がる」と、何かと嫌われている “MSゴシック” のフォントを数あるフォントの中から自動識別し、アームで拾い上げて床に捨てます。ブレインパッドメンバー含めた計4名で趣味活動として作りました。「ナウい技術で超絶くだらないことをover killする」「”技術の無駄遣い感” を全面に押し出すこと」を目指しました。
「MSゴシック絶対許さんマン」がMSゴシックを識別して床に捨てている様子はこちらから見ることができます。
みんなの嫌われ者"MSゴシック"の #フォントかるた をディープラーニングで識別して床に捨てる #MSゴシック絶対許さんマン を #MakerFaireTokyo2017 で展示しました。 pic.twitter.com/mLvP1UXT3W
— 吉田勇太 / ysdyt (@yutatatatata) August 7, 2017
今回は、このロボットが動くまでのデータ作り・学習・推論やイベント会場でリアルタイムデモをする時に困った話などを書きたいと思います。
識別の流れ・構成
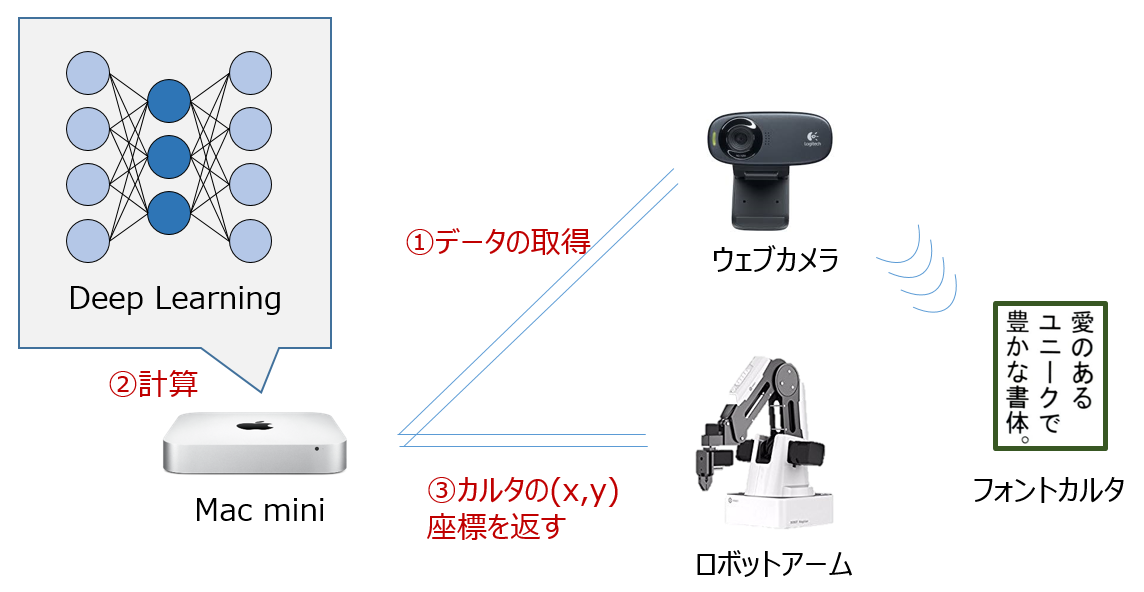
動作の流れとしては単純で、
- ウェブカメラで対象となるフォントカルタ(※) を撮影する
- Mac mini(ubuntu)にCNN学習済みモデルを置いておき、それを使って撮影したフォント対して推論を行う
- フォントカルタが"MSゴシック"だった場合、そのカルタがあるXY座標をロボットアームに送ってピックアップさせる
ということをしています。
(※)フォントかるたは同じテキストが48種類の異なるフォントで書かれたジョークカルタ。デザイナーさんなどに大人気。製作者の方に許可もいただき今回の学習用データに利用させていただきました。
データセット作成
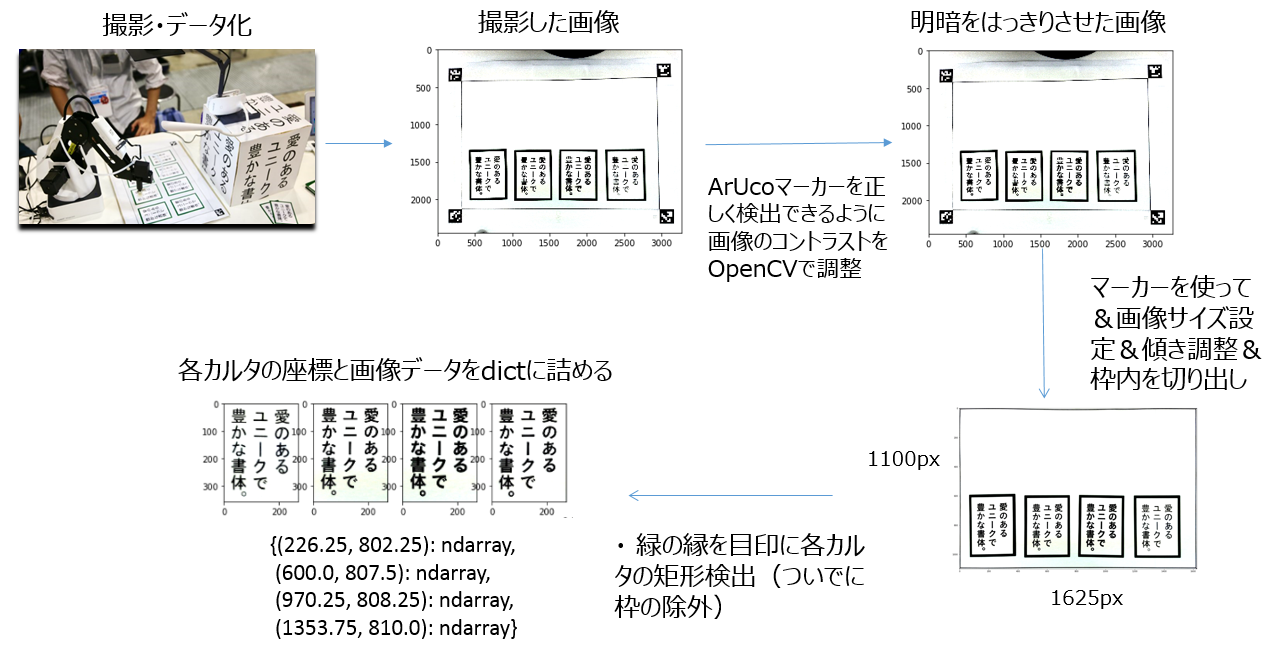
学習データとして都合の良さそうなフォントのデータセットが無かったため、今回はカルタを自前で撮影して学習データセットをいちから作成しました。
こんな感じで撮影していました。
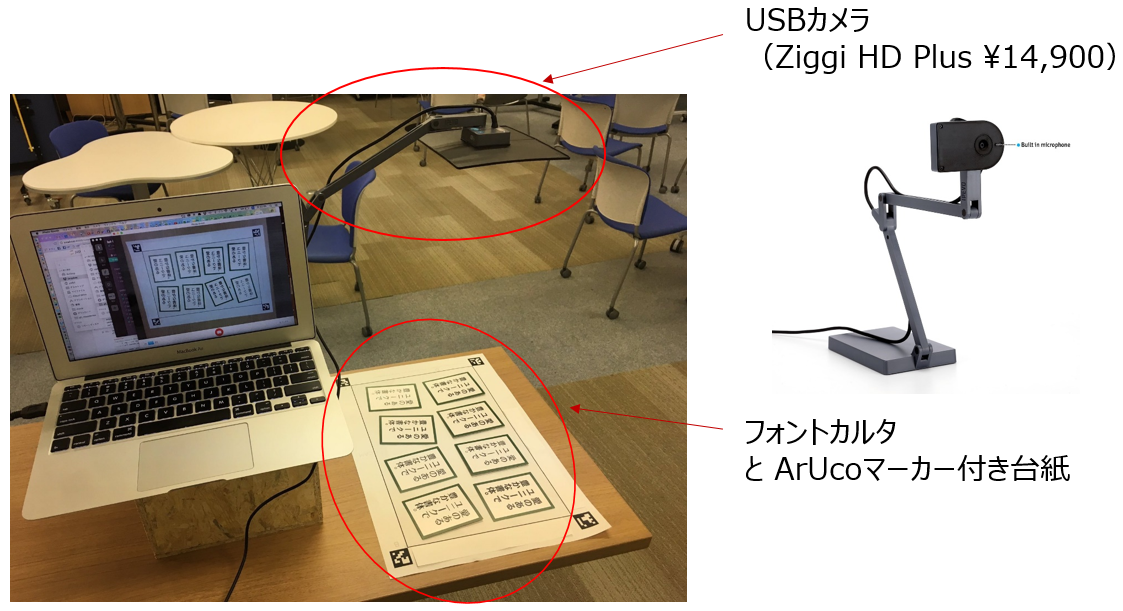
撮影してデータを作る
上記の写真のように、USBカメラを使ってひたすら「フォントかるた」の画像を撮影していきます。
フォントかるたを卓上カメラで撮影、全48フォントに対して1000枚/フォントづつデータ化しました。(train:validation:test = 700枚:200枚:100枚です)
基本的にはUSBカメラのシャッターをOpenCVでコントロールし、ループさせて連速撮影しています。ただし、連続撮影によってほとんど同一の画像が撮れ過ぎるのもマズイので、ある程度撮影が進んだらカードの向きを微妙に変えたり、スマホライトを光らせながらカルタの周りをぐるぐる回ったりするなどして照明環境を変えて光のノイズなどを意図的に入れました。
一方で、撮影環境があまりにも変わると同一クラスのデータとして利用できなくなってしまうので注意が必要です。きちんとした撮影環境などがない場所で撮影すると、「夜になり部屋が暗くなる」「夕日が差し込む」などもわりとクリティカルに影響してきます。
このあたりはひたすら地道な作業です。この作業で7月の休みが全部溶けました。。。
ArUcoマーカー?
画像を撮影しそれらをデータ化する時はArUcoマーカーが活躍してくれました。
ArUcoはBSDライセンスで配布されているOpenCVをベースにした軽量なARライブラリです。
- ArUco: a minimal library for Augmented Reality applications based on OpenCv | Aplicaciones de la Visión Artificial
- Detection of ArUco Markers
以下の様なQUコードのような2次元マーカが1024個まで同時に認識可能です(上記のリンク先の動画を見ると雰囲気がわかります)

今回は4つのArUcoマーカーを使って、ArUcoマーカーが存在している範囲内にカルタを設置します。
ArUcoマーカーを目印として、撮影した画像に変換をかけることで画像の大きさや傾きを補正して画像認識や加工をしやすくしています。
正解ラベル作成
以下の流れで撮影した画像から正解ラベル付きのデータセットを作成します。
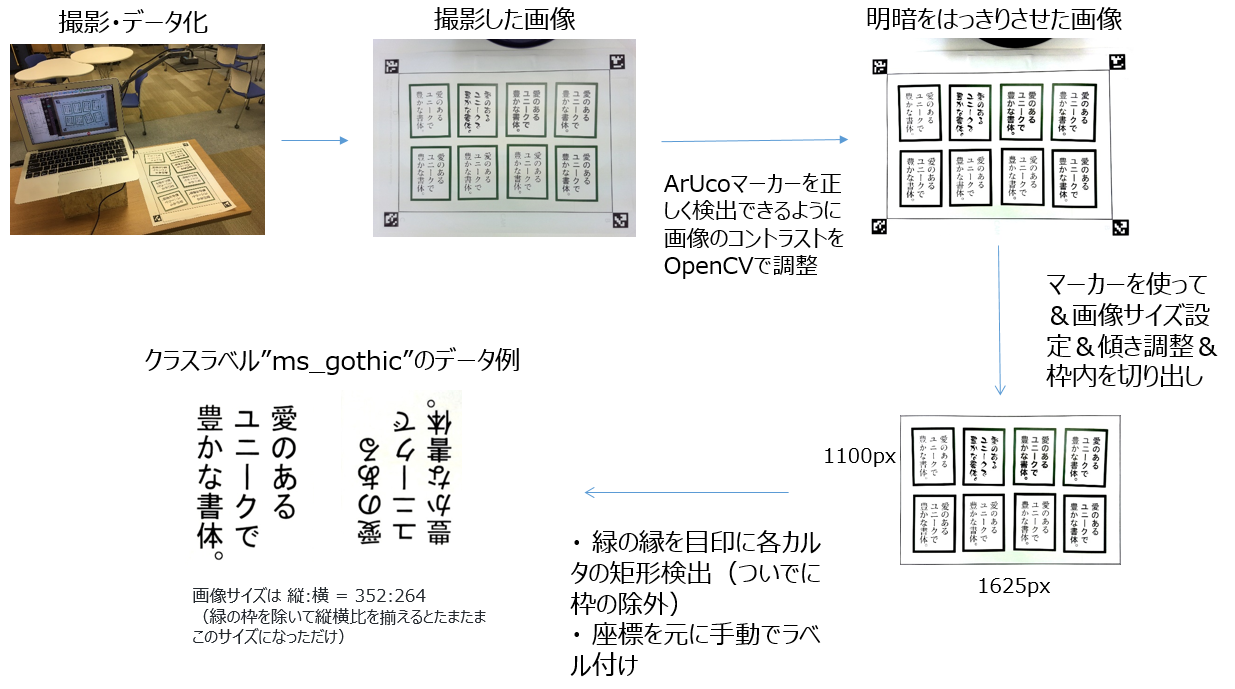
画像の前処理にあたるこの工程では、OpenCVを使って画像の輝度調節をしたり矩形検出したりして細かな画像編集のテクニックを多様しています。学習用の綺麗な画像を作るためにいろいろ試行錯誤し非常に勉強になった箇所でもあります。
最終的には上図左下のカルタ画像のように、学習に不必要な特徴となる緑の枠なども切り出しました。
データセットの半量は180度回転させた状態の画像も含む(加えて、data augumentationによってrotateやshiftした画像も含む)ため、推論時にはカルタの向きを問いません。
カルタを切り出す際の画像サイズは 縦:横 = 352:264 に統一しています(学習時はconvolutionしやすいように、resizeして320:240 にします)
モデルの学習
48フォント分の学習データに対して、3層の畳み込み層 + Spatial Pyramid Pooling(SPP)というPooling層を使って学習しています(kerasで実装)。ネットワーク構造の詳細はこちらのGitHubへ。
今回初めてSPPを使ってみましたが、かなりクリティカルに学習に良い影響を与えていて驚きました。SPPについてはこちらなどを参照。
モデルレイヤー全体の画像をこちらに貼っています。画像ではinputの画像サイズが(320, 240)となっていますが、実際の学習では可変サイズ(None, None)を学習するため、推論時には任意のサイズの画像を指定することができます。
batch_size = 32, steps_per_epoch = 150, validation_steps = 100, epochs = 200 で上記データセットを学習させたときのaccとlossの推移は以下です。
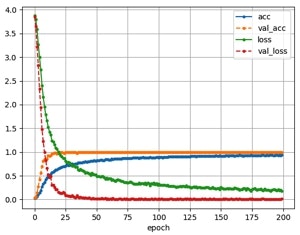
連射撮影のせいでtrainとvalidationの画像が似すぎている、かつ、validation画像にはaugumantationしていなかったので当てるのが簡単でvalidationのacc,lossの方が良い、という状況になってしまっていますがひとまず学習は出来ているようなので次へ進みます。
テストデータへの適応
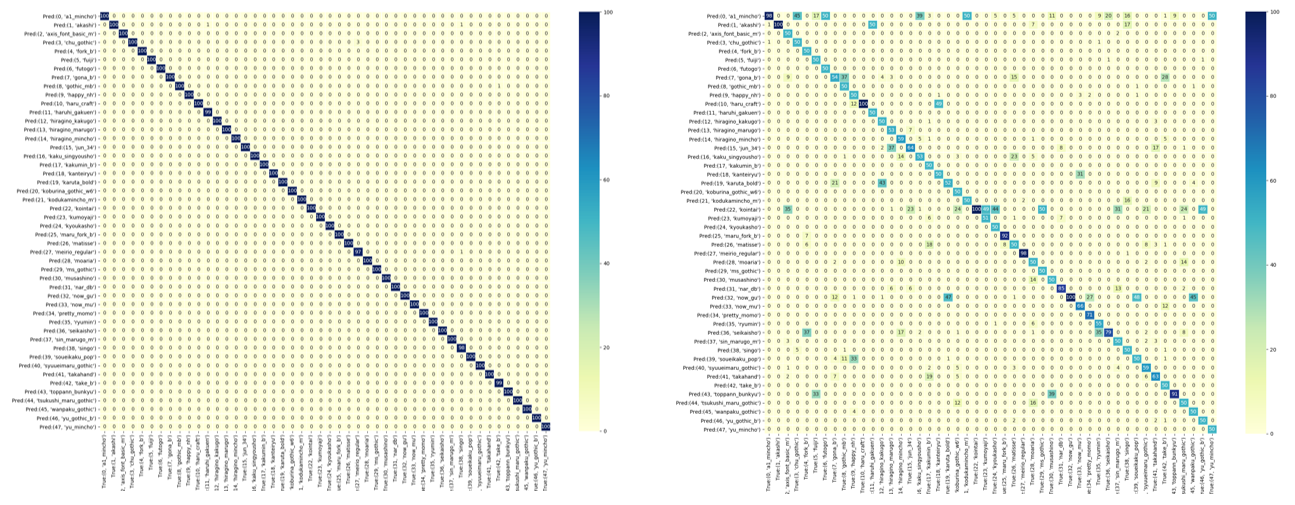
各クラス100枚づつ用意したテストデータに対して推論した結果の混同行列が下左です。
こちらもvalidationのときと同じく、test画像が学習データと似すぎているせいであまり見る意味のないテスト結果となっています。最高に汎化能力が無い感じがしますが、今回推論したい対象物は印刷文字(手書き文字とは違い、同一フォント中でのバリエーションは無い)なので汎化性能ナシ上等と自己暗示をかけてひとまず進みます。
(ちなみに、学習データセットに180度回転させた画像を含めずに学習を行ったモデルでテストデータに当てると右の推論結果になります。やっぱり汎化性能なしの気配...)
現場環境(イベント会場)でリアルタイムに推論する
推論の流れ
今回はイベント会場でリアルタイムにフォントを撮影→推論→結果をロボットアームに返す ということをしたいのでその流れも作らないといけません。
リアルタイムの推論は以下のようなフローで行いました。途中まではデータセットを作るための処理と同じです。
まず、イベントの現場環境でArUcoマーカーの領域内にあるカルタをカメラで撮影します。その後はデータセット作成のときと同じ流れでカルタの部分だけを認識し各カルタごとに画像を切り出します。切り出した画像データはカルタの中心座標(ArUcoマーカーからの相対位置で算出)と紐付けて持っておきます。
最後に、切り出した画像データに対して学習済みモデルで推論を行い、"MSゴシック"と判断された画像データの座標をロボットアームに送り、実際にピックアップさせにいきます。
ArUcoマーカー付きの紙の大きさの制限状、最大でカルタを8枚しかおけません。そのため一度で推論する対象もカルタ8枚分(8枚をsoftmaxで計算)となるので1秒かからず推論することができます。
現場デモの難しいところ
一応この流れでMSゴシックを捕まえに行くことはできますが、やはりリアル環境でデモを行うといろいろ問題がおこります。
会場の照明環境問題
当日の会場であったビックサイトではたくさんの強い照明器具が天井からぶら下がっていたためライトの反射が強く、テーブル上のカルタにも白飛び(フレア的な?)や影が多く現れていました。また反対に、見物の方がたくさん集まるとテーブルに人影が出来ます。それらは画像識別にとってはノイズとなるため実際に撮影した画像を推論させても全く当てられないということが起こりました。(汎化能力低いモデルには辛いシチュエーションです)
この問題には、光が強く当たっているときは人を立たせたりテーブル上に立体物を置いてわざと影を作り、人が集めリすぎると少しテーブルから離れてもらったりと地味な光影響のチューニングを行っていました。また、良い感じに画像が撮影されるまで(光のノイズがマシになるまで)ひたすら裏で撮影と推論を連続的に実行する処理も行っていました。何度も推論を行ううちに誤推定をする可能性もありましたが、画像が正しく取り込まれればほぼ百発百中で正しく推論してくれました(ギリギリの汎化性能はあったようです)。
ちびっこ問題
大人は遠巻きに展示を見てくれますが、ちびっこは動いているものをみると触ってしまうので何度かロボットアームがすごい音をたてて止まり肝を冷やしました。また、接触するとロボットアームの初期座標がズレてしまうので再度キャリブレーションするなどいろいろ大変です。デモをする時はちびっこ対策必要ですね(もちろんちびっこが怪我をしないような配慮は必須です!)
まとめ
ノリで作った深層学習で動くおもちゃでしたが、
- 学習データ作りが地獄
- 「光の影響(撮影環境の確保)」が最大の難関
という印象が一番強いです。熱い夏でした。
特に、学習データの綺麗さの追求、モデル精度の追求、汎化性能の追求などは目標から逆算して妥協点を決めておかないと(仕事ではないので無限に時間が使えることも相まって)間違いなく泥沼化します。
今回の場合も、「とにかくイベント当日に最低限ちゃんと動いてればええんや!」という低い目標だったので、上記の学習曲線や混同行列を見て何とも言えない気持ちになってもスルーする強い気持ちが大切です。(うまく動作してくれていたのはわりと運が良かったような。結果オーライでした。)
それでも、いろいろと非常に勉強になったしイベント当日は沢山の人に見てコメントを貰えたので楽しかったです!
一見して動作原理がわからない展示は、まるで魔法で動いているようにみえるのでかなりデモ映えします。イベントや広告、デジタルアートなどで深層学習で動く人目を引く展示物はこれからますます増えそうだなーと思いました。
関連リンク
-
https://github.com/ysdyt/MSgothicPolice - GitHub
- 本展示 "MSゴシック絶対ゆるさんマン"のソースコードです
-
「CNNは絵札のどの部分に注目してフォントを見分けているか」 – SlideShare
- 本展示ではロボットアームを動かすデモだけでなく、Grad-CAMという手法を用い、この学習ネットワークがフォントのどこを見て(どういった特徴量を重要視して)分類を行っているのかを可視化した説明展示も行いました。チームメンバーの@ywara93がchainerで実装しました。