読んで面白かったので勉強を兼ねて日本語化しました。ざっくりグーグル翻訳にかけてから、あまりにもヘンテコな日本語は直しました。(意訳も含む)(コメ印の注釈も入れています)
翻訳元記事はWILDMLが年の瀬12月31日に公開したものです。2017年に起こった人工知能・深層学習の素晴らしいまとめ記事です。
元記事では本文中にも沢山リンクを貼ってくれてますが、そこまで完コピすると大変だったので興味あるところは元記事を参照してみてください(挿入画像やyoutubeリンクのみコピペしました)
====================
強化学習がゲームで人間を打ち負かす
今年の最大の成功事例はおそらく世界最高の囲碁棋士を破る強化学習エージェントAlphaGoでした。探索領域が非常に大きいため碁は数年前からMachine Learningの対象外と考えられていましたが、この成果には驚きました!
AlphaGoの最初のバージョンは、人間の専門家からのトレーニングデータ(棋譜データ)を使用してブートストラップされ、セルフプレイとモンテカルロツリー検索の適応によってさらに改善されました。AlphaGo Zeroはさらに一歩前進し、人間の訓練データをまったく使わずに碁をスクラッチから学習し、AlphaGoの初期バージョンを簡単に打ち負かしました。今年末、我々はAlphaGo Zeroアルゴリズムのもう一つの一般化を見ました。AlphaZeroは碁とチェスと将棋をまったく同じ技術を使って習得しました。興味深いことに、これらのプログラムはプロ棋士でさえ驚くような動きをして、AlphaGoから棋士が学び、棋士が自分のプレイスタイルを調整するよう動機づけました。そういったことをもっと簡単にするため、DeepMindはAlphaGo Teachツールもリリースしました。

大きな進歩を遂げたゲームは碁だけではありませんでした。 CMUの研究者によって開発されたシステムであるLibratusは、20日間のヘッドアップ、ノーリミットテキサスホールデムトーナメントでトップのポーカープレーヤーを倒しました。 それよりも少し早く、チャールズ大学・チェコ工科大学・アルバータ大学の研究者によって開発されたシステムであるDeepStackが、プロのポーカープレイヤーに勝利しました。 ただし、注意点としてこれらのシステムは両方とも、複数人対戦のポーカーで勝利したわけではなく、(問題設定としては難易度がもっと簡単な)2人のプレーヤーの間でプレーされるHeads-upポーカーにおいて人間を倒したという点です。
強化学習の次のフロンティアは、複数人対戦のポーカーを含むより複雑なマルチプレーヤー対戦のゲームのようです。 DeepMindは積極的に研究環境をリリースし、"Starcraft 2"(ゲームの名前)における研究をしています。OpenAIは近い将来、完全な5対5ゲームでの競争を目指して、1対1の"Dota 2"(ゲームの名前)でまずは成功を収めました。
(クリックでYoutubeに飛びます)

進化アルゴリズム(Evolution Algorithms)の復活
教師あり学習の場合、バックプロパゲーションアルゴリズムを使用する勾配ベースのアプローチは非常にうまく機能しています。そして、それはすぐに変わることはないでしょう。しかし、強化学習領域ではEvolution Strategies; ES(進化戦略: 進化的アルゴリズムの一種)が復活しているようです。データは一般的に iid(independent and identically distributed :独立して、かつ同一に分布する)ではないので、誤差信号はより疎であり、探索の必要があるため、勾配に依存しないアルゴリズムは非常にうまくいきます。さらに、進化的アルゴリズムは計算能力を線型にスケールでき、非常に高速な並列訓練を可能にします。高価なGPUを必要とせず、安価なCPUで多数(通常は数百から数千)訓練することができます。
今年の初め、OpenAIの研究者は、Evolution StrategiesがDeep Q-Learningなどのスタンダードな強化学習アルゴリズムに匹敵するパフォーマンスを達成できることを実証しました。今年末にかけて、Uberのチームはブログ投稿と5つの研究論文を発表し、遺伝的アルゴリズムと新規性検索の可能性をさらに実証しました。彼らのアルゴリズムは、非常に単純な遺伝的アルゴリズムを使用し、かつ勾配情報を全く使わずに難しいAtari Gamesを学習することができます。 Frostbite(ゲームエンジンの名前)で遺伝的アルゴリズムで10,500点を出した動画があります。DQN・AC3(※)・およびESはこのゲームでのスコアが1,000未満でした。
おそらく我々はこの分野の話題を2018年にもっと見ることになるでしょう。
(※)A3Cの間違いっぽい
WaveNets、CNNs、そしてAttention Mechanisms
(Google Assistantにも導入された自律型モデルであるWaveNetに基づいた)Tacotron 2 text-to-speech systemは、非常によくできたオーディオサンプルを生成することができ、過去1年間で大幅な速度改善を見せています。 WaveNetは以前から機械翻訳分野にも適用され、それによってリカレントアーキテクチャのトレーニング時間が短縮されました。
機械学習のサブフィールドでは、トレーニングに時間がかかる高コストなリカレントアーキテクチャーからの移行が進んでいるようです。 研究者はリカレントやコンボリューションの手法を捨てて、より洗練された"アテンションメカニズム"を使用して、わずかなトレーニングコストでstate of the artな結果を達成しています。
深層学習フレームワーク元年
2017年を一言で言うなら、それはフレームワークの年になります。 FacebookはPyTorchと大きな飛躍を遂げました。 PyTorchは、Chainer同様、動的なグラフ構造を扱えるため、動的で再帰的な構造頻繁に処理しなければならない自然言語処理系の研究者が愛用しました。(動的で再帰的な構造の処理はTensorflowのような静的グラフフレームワークでは扱いが難しい)
Tensorflowは2017年にかなり流行りました。Tensorflow 1.0は安定した下位互換性のあるAPIを2月にリリースしました。現在、Tensorflowはバージョン1.4.1です。主なフレームワークに加えて、動的計算グラフ用のTensorflow Fold、データ入力パイプライン用のTensorflow Transform、DeepMindの高レベルSonnetライブラリなど、いくつかのTensorflowコンパニオンライブラリがリリースされました。 Tensorflowチームはまた、PyTorchの動的計算グラフと同様に機能する新しいeager実行モードを発表しました。
GoogleやFacebookに加えて、他の多くの企業がMachine Learningフレームワークを公開しました。
- AppleはCoreMLモバイルマシン学習ライブラリを発表しました。
- UberのチームがPyro(Deep Probabilistic Programming Language)をリリースしました。
- Amazonは、MXNetで利用可能な高レベルのAPIであるGluonを発表しました。
- Uberは社内で利用しているMichelangelo Machine Learningインフラストラクチャプラットフォームに関する詳細を発表しました。
フレームワークの数が増えてきたため、FacebookとMicrosoftは、フレームワークを跨いで深層学習モデルを共有するためにONNXオープンフォーマットを発表しました。 たとえば、モデルを1つのフレームワークでトレーニングしてから、別のフレームワークで展開することができるようになります。
汎用のDeep Learningフレームワークに加えて、次のような強化学習フレームワークも多数リリースされました。
- OpenAI Roboschoolは、ロボットシミュレーション用のオープンソースソフトウェアです。
- OpenAIベースラインは、強化学習アルゴリズムの高品質実装のセットです。
- Tensorflowエージェントには、Tensorflowを使用してRLエージェントをトレーニングするための最適化されたインフラストラクチャが含まれています。
- Unity MLエージェントを使用すると、研究者や開発者はUnity Editorを使用してゲームやシミュレーションを作成し、強化学習を使用してトレーニングすることができます。
- Nervana Coachでは、最先端の強化学習アルゴリズムを使用した実験が可能です。
- ゲーム研究のためのFacebookのELFプラットフォーム
- DeepMind Pycolabは、カスタマイズ可能なグリッドワールドのゲームエンジンです。
- Geek.ai MAgentは、多くのエージェントの強化学習のための研究プラットフォームです。
ディープラーニングをより使いやすくするという目標を達成するため、Googleのdeeplearn.jsやMIL WebDNNの実行フレームワークなど、Web用のフレームワークもいくつか用意されています。 しかし一方で、ある人気のフレームワークが亡くなってしまいました。 Theanoです。 開発者がTheanoのメーリングリストで1.0が最後のリリースになると報告しました。
学習教材
ディープラーニングと強化学習が普及するにつれて、2017年にそれらを学ぶオンラインレクチャー・ブートキャンプ・イベントが多数記録・公開されました。以下は私のお気に入りです:
- OpenAIとUC Berkeleyが共催したDeep RL Bootcampでは、強化学習の基礎と最先端の研究に関する講義が行われました。
- Stanfordの視覚認知のための畳み込みニューラルネットワークコースのSpring 2017バージョン。 コースのウェブサイトもチェックしてください。
- 2017年冬スタンフォードの自然言語処理とディープラーニングコース。 コースのウェブサイトもチェックしてください。
- スタンフォード大学のディープラーニング理論。
- Courseraのディープラーニングの専門分野
- モントリオールのDeep Learning and Reinforcement Summer School
- カリフォルニア大学バークレー校の深層強化学習秋2017コース。
- Tensorflow Dev Summitは、Deep Learningの基礎と関連するTensorflow APIに関する講演を行いました
いくつかの学会は、オンラインでconference talksを引き続き公開しています。 最先端の研究に追いつくために、NIPS 2017・ICLR 2017・EMNLP 2017の録画の一部を見ることができます。
研究者もarXivでチュートリアルとsurvey paperを公開しています。 私の今年のお気に入りのいくつかは次のとおりです:
- Deep Reinforcement Learning: An Overview
- A Brief Introduction to Machine Learning for Engineers
- Neural Machine Translation
- Neural Machine Translation and Sequence-to-sequence Models: A Tutorial
応用例: AI&医学
2017年は、深層学習によって医療問題を解決し人間の専門家を打ち負かすという多くの大胆な主張が見られました。 多くの誇大宣伝があり、本当のブレークスルーを理解するには医学的知識を持っていない人にとっては難しいことです。包括的なレビューとして私はLuke Oakden-Raynerの「The End of Human Doctors」というブログ記事をお勧めします。 ここでは、いくつかの発展項目について簡単に説明します。
今年のトップニュースの中には、スタンフォードのチームが皮膚がんの特定に皮膚科医と同程度の精度を示した深層学習アルゴリズムに関する詳細を発表しました(Nature記事を読むことができます)スタンフォード大学の別のチームは、シングルリードECG信号から心臓病専門医よりも精度良く不整脈(不整脈)を診断できるモデルを開発しました。

しかし過ちも少なくありませんでした。DeepMindとNHS(※)の取り組みでも多くの過ちが起きました。NIHは胸部X線データセットを科学コミュニティにリリースしましたが、より詳細な検証でこのデータセットは診断AIモデルのトレーニングにはあまり適していないことが判明しました。
※イギリスの国営医療サービス事業。患者の医療ニーズに対して公平なサービスを提供することを目的に1948年に設立された
応用例: Art & GANs
2017年に、より多くの注目を集めたのが、画像・音楽・スケッチ・ビデオの生成モデリングです。 NIPS 2017カンファレンスでは、今年初めて"Machine Learning for Creativity and Design"というワークショップが行われました。
最も人気のあるアプリケーションの中には、GoogleのQuickDrawがあります。GoldDrawはニューラルネットワークを使ってあなたが書いた"落書き"を認識します。
今年はGenerative Adversarial Networks(GANs)が大きな進歩を遂げました。 CycleGAN、DiscoGAN、StarGANなどの新モデルでは、顔を生成するなどの面白い結果が得られました。GANは高解像度画像を生成するのに困難を抱えていましたが、pix2pixHDなどの成果をみると解決への道筋はたっているように思えます。 GANは新しい絵筆になるのでしょうか?
(クリックでYoutubeに飛びます)

応用例: 自動運転
自動運転領域のビッグプレイヤー達は、ライドシェアアプリのUberとLyft・AlphabetのWaymo・Teslaです。 Uberは(人為的なミスではない)ソフトウェアエラーによってサンフランシスコでいくつかの赤信号を見落としてしまうなどのいくつかの失敗で1年を始めました。 その後、Uberは社内で使用されている車のビジュアライゼーションプラットフォームに関する詳細を共有しました。 12月、Uberの自家用車プログラムは200万マイル(※)を走行しました。
(※)約320万キロメートル、約日本100周分くらいっぽい...
Waymoはテストの詳細とシミュレーション技術についての詳細も発表しました。
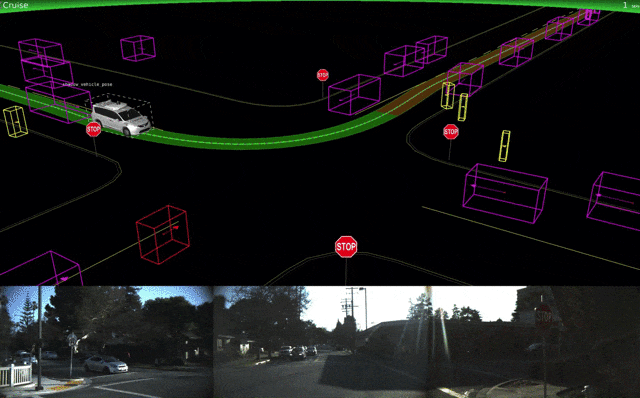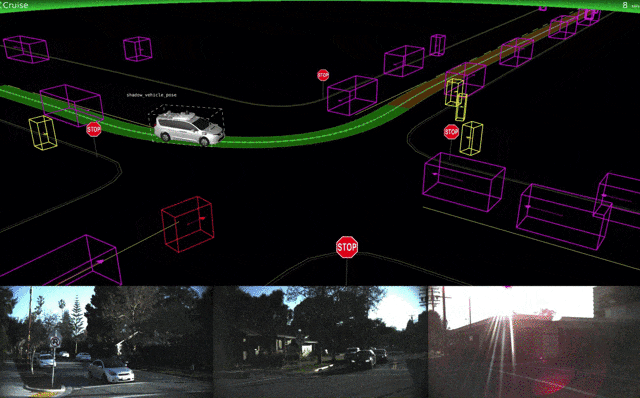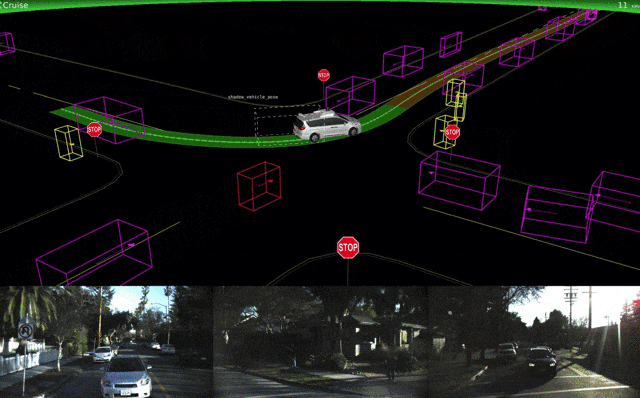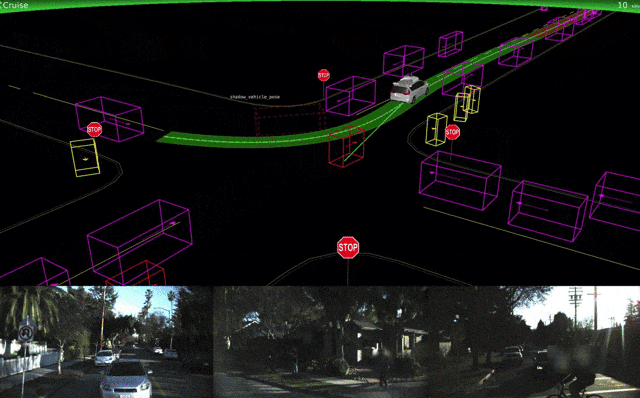
↑Waymoシミュレーションによる改良版車両ナビゲーション
Lyftは自律的な運転をハードウェアとソフトウェアの両方で構築していると発表しました。ボストンで初めての走行試験を現在進行しています。テスラオートパイロットの新着情報はあまりみません。この領域の新規参入はAppleで、ティム・クック氏はアップル社が自走車用のソフトウェアに取り組んでいることを発表し、アップルの研究者がarXivにマッピング関連の論文を発表しました。
応用例: Coolな研究プロジェクト
今年も数多くの面白いプロジェクトやデモが公開されました。もちろんすべてを紹介することは不可能ですが、今年目立っていた幾つかを以下に紹介します:
- Background removal with Deep Learning
- Creating Anime characters with Deep Learning
- Colorizing B&W Photos with Neural Networks
- Mario Kart (SNES) played by a neural network
- A Real-time Mario Kart 64 AI
- Spotting Forgeries using Deep Learning
- Edges to Cats
さらに研究面では、
- The Unsupervised Sentiment Neuron – Amazonのレビューのテキストの次の文字を予測するためだけに訓練されているにもかかわらず、優れた感情分析を行うシステム
- Learning to Communicate – エージェントが自身の言語を開発する研究
- The Case for Learning Index Structures – ニューラルネットを使用して、キャッシュ最適化されたBツリーを最高70%高速処理する一方で、実世界の複数のデータセットに対してメモリのオーダを節約します。
- Attention is All You Need
- Mask R-CNN – object instance segmentationのための一般的なフレームワーク
- Deep Image Prior for denoising, superresolution, and inpainting
データセット
教師あり学習に使用されるニューラルネットワークはデータを膨大に要求することでも悪名が知られています。 そのためオープンなデータセットは研究コミュニティにとって非常に重要な貢献です。 今年もいくつかのデータセットが登場しました:
- Youtube Bounding Boxes
- Google QuickDraw Data
- DeepMind Open Source Datasets
- Google Speech Commands Dataset
- Atomic Visual Actions
- Several updates to the Open Images data set
- Nsynth dataset of annotated musical notes
- Quora Question Pairs
ディープラーニング・再現性・錬金術
幾人かの研究者は学術論文の結果の再現性に関する懸念を提起し続けていました。 ディープラーニングのモデルは、膨大な数のハイパーパラメータに依存することが多く最適な結果を達成するために最適化する必要があります。 この最適化は非常に高コストになる可能性があり、GoogleやFacebookなどの企業だけがそれを行う余裕があります。 研究者は必ずしもコードを公開しているわけではなく、完成した論文に重要な細部を入れるのを忘れたり、わずかに異なる評価手順を使用したり、分割したデータセットのハイパーパラメータを繰り返し最適化することによってデータセットにオーバーフィットしてしまったりしています。 これにより再現性が大きな問題になります。 この問題に対して研究者は、強化学習を用いて、異なるコードベースから取られた同じアルゴリズムが、高い分散を伴って大きく異なる結果を出すことを示しました。

"Are GANs Created Equal? A Large-Scale Study"という論文の中で、研究者は高コストなハイパーパラメーター探索によってカリカリにチューニングされたGANは、より洗練されたアルゴリズムに勝ると報告しました。同様に、Neural Language ModelsにおけるState of the Artな精度の評価で、単純なLSTMアーキテクチャーであっても適切にパラメータ調整すると新しいモデルよりも優れていることを示しました。
NIPSトークでは、Ali Rahimiが最近のディープラーニングのアプローチを錬金術と比較し、より厳密な実験デザインを求めました。 ヤン・ルクンはそれを侮辱として受け取り、翌日すぐに反論しました。
カナダと中国で作られる人工知能
米国の移民政策が厳しくなるにつれて、企業はカナダをメインの海外オフィス開設場所とみているようです。 Googleはトロントに新しいオフィスを開設し、DeepMindはカナダのEdmontonに新しいオフィスを開設し、FacebookのAI ResearchはMontrealにも拡大しています。
中国も多くの注目を集めているもう一つの場所です。 多くの資本・大規模な人材・政府のデータがすぐに入手できるため、AIの開発や生産展開の面で米国と対峙しています。 Googleももうすぐ北京で新しいラボを開くと発表しました。
ハードウェア戦争: Nvidia, Intel, Google, Tesla
現代のディープラーニング技術は、最先端のモデルを訓練するために高価なGPUを必要とすることは有名です。 これまでのところではNVIDIAが優勢です。 NVIDIAは今年、Titan Vの新しいフラッグシップGPUを発表しました(ちなみにそれは金ピカカラーです)
しかし、競争が激化している GoogleのTPUは現在クラウドプラットフォーム上で利用可能になっており、IntelのNervanaは新しいチップセットを発表し、Teslaも独自のAIハードウェアで動いていると認めています。 Bitcoinマイニングを専門とする中国のハードウェアメーカーが人工知能向けGPU領域に参入する可能性もあります。
誇大宣伝と失敗
誇大宣伝には大きな責任があります。主要メディアは研究室や制作システムで実際に起こっていることとほとんど一致しないようなことを報道しました。IBM Watsonは過剰宣伝マーケティングのイメージキャラクターとなり、そして宣伝に見合う結果を提供できませんでした。今年、誰もがIBM Watsonを嫌っていましたが、それは医療分野で何度も失敗が起こったあとでは驚くことではありません。
最も誇大宣伝している話はおそらく、Facebookの「自身の言語を発明したAIを研究者がシャットダウンした」という話でしょう(私はこの記事にリンクを貼りません、ご自身でググってください)。もちろん、タイトルは真実から遠いものではありませんでした。起こったことは、ただ研究者が良い結果を得られそうになかった実験を中止したということです。
しかしそれは誇大宣伝の罪で有罪判決を言い渡しただけではありません。研究者もまた、この自然言語生成論文のように、実際の実験結果を反映していないタイトルや要約で境界線を越えてしまったのです。
目立った雇用や離脱
Courseraの共同設立者であり、Machine LearningのMOOC(オンライン授業)でも有名なAndrew Ngが今年数回にわたって報道されました。 Andrewは、3月にAIグループを率いていたBaiduを去り、新たに$150Mの資金を調達し、製造業界に焦点を当てた新しいスタートアップlanding.aiの設立を発表しました。 他のニュースでは、Gary MarcusがUberの人工知能研究所のディレクターを辞任したり、FacebookはSiriのNatural Language Understanding Chiefを雇った。いくつかの著名な研究者がOpenAIを離れ、新しいロボット会社を設立した。
アカデミアから科学者が業界に引き抜かれる傾向も続き、大学のラボは業界の巨人が提供する給料と競争できないと不平を言っています。
スタートアップの投資と買収
前年と同じように、AIのスタートアップエコシステムは、いくつかの注目度の高い買収によって活況を呈していました。
- Microsoft acquired deep learning startup Maluuba
- Google Cloud acquired Kaggle
- Softbank bought robot maker Boston Dynamics (Boston Dynamicsは機械学習をあまり使っていないことで有名)
- Facebook bought AI assistant startup Ozlo
- Samsung acquired Fluently to build out Bixby
そして大金を稼ぐ新しい会社も...
- Mythic raised $8.8 million to put AI on a chip
- Element AI, a platform for companies to build AI solutions, raised $102M
- Drive.ai raised $50M and added Andrew Ng to its board
- Graphcore raised $30M
- Appier raised a $33M Series C
- Prowler.io raised $13M
- Sophia Genetics raises $30 million to help doctors diagnose using AI and genomic data