【2020/2/6 追記】 1回の操作で録音可能な時間(デフォルト2秒)の変更について、追記をしました。
【2020/2/14 追記】 音を学習させて ブラウザ上のJavaScript のプログラムで制御してみた際の動画ツイートを追記しました
【2020/2/15 追記】 上記の JavaScript のプログラムでモデルを用いた音の判別のやり方について続きの記事を公開した話を追記しました
はじめに
昨年の 11月に、Facebook に情報の投稿をしたものの、全く試していなかった Google さんの Teachable Machine。
それを、ちょっと前に参加したもくもく会で、機械学習系の話題がでたときに試してみようと思い、軽く試してみました(この時試したのは、画像を対象にした機械学習)。
その時に、すごく簡単に「ブラウザ上で学習から推論まで行えた」のが印象に残り、また、試す過程で目にした「音声の機械学習」が気になったりもして、自宅に戻ってから音声を使うものを試しました。Teachable Machineで試した内容は
— you (@youtoy) February 1, 2020
カメラ撮影された3つの動作(1 手を振る、2 何もしない、3 手をグーにしてかざす)を取り込んで学習、その後カメラにうつった内容が3クラスのどれか判別するもの。
試せてはないけど、モデルのダウンロードや、特定言語で実装するときのサンプルコードもでてくる。 https://t.co/bB0UDiS4sO
この記事で扱う内容
今回の記事で扱うのは、その音声を用いた機械学習についてです。
具体的には、しゃべっている内容(マイクで取得した音声)からの特定のキーワードの検出になります。
音声を Teachable Machine で扱う
音声からのキーワード抽出を試した結果
まず、ブラウザ上でどのようなことが試せたか、ご覧ください。
こちらのツイートの動画は、ブラウザ上での学習でモデル作成をした後の段階、推論(音声からのキーワード検出)を行っているところです。
動画について軽く補足しておくと、動画の真ん中あたりに「Output」という書かれたところがあって、さらにその下には ・Background Noise ・Class2 ・Class3 ・Class4 ・Class5 という文字と、その横で長さが変わっている色つきのバーが表示されています。Teachable Machine を使うと、音声からの任意のキーワード検出ができてしまうのでは?
— you (@youtoy) February 1, 2020
と思って、試しに「Googleアシスタント、Alexa、Siri、Clova」のウェイクワードを音声から判別するものを作ってみました。
そうしたら、思いのほか簡単にサンプルができてしまった。
Teachable Machine すごいw pic.twitter.com/D8Lg1Y55Lw
そして、色つきのバーが横に伸びるのは、以下のような対応関係になっているのが分かります。
・Background Noise ⇒ 背景ノイズが入力されている(何もしゃべっていない)
・Class2 ⇒ 「OK Google」というキーワードを検出
・Class3 ⇒ 「Hey Siri」というキーワードを検出
・Class4 ⇒ 「Alexa」というキーワードを検出
・Class5 ⇒ 「ねぇClova」というキーワードを検出
これは、マイクからリアルタイムに入力される音声の中から、自分が Teachable Machine を使って学習させた4つのキーワード(4つのAIアシスタントのウェイクワード)が検出されたかどうか、を表示している形になります。
それでは、学習をどのように行ったか、という話を書いていきます。
ブラウザ上での Teachable Machine での音声の機械学習
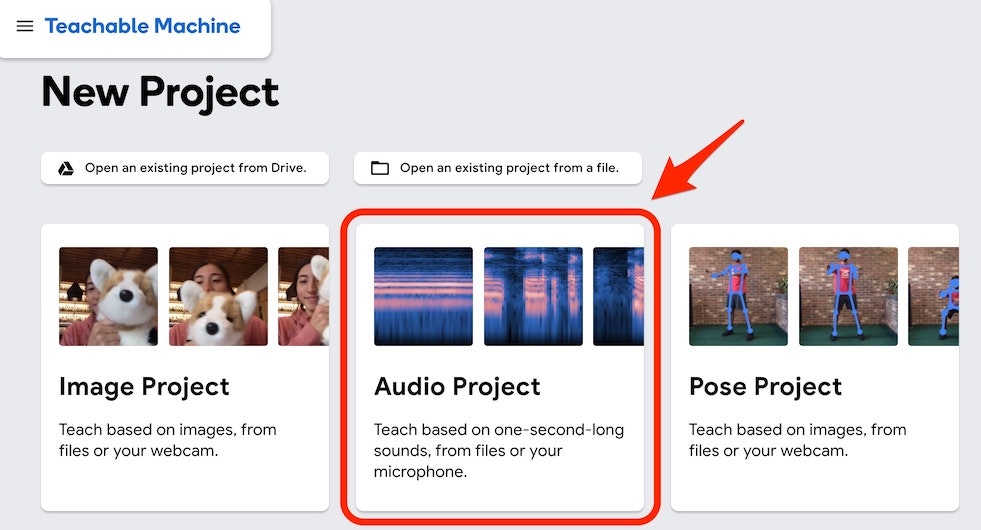
まず、Teachable Machine のプロジェクト選択のページで「Audio Project」を選択します。
そうすると以下の、左・真ん中・右の3つの部分におおまかに分かれたような画面が出てきます。
さらに、左側の部分には、以下の画像の赤い矢印で示した「Background Noise」、「Class2」「Add a Class」といった部分が縦に並んでいます。
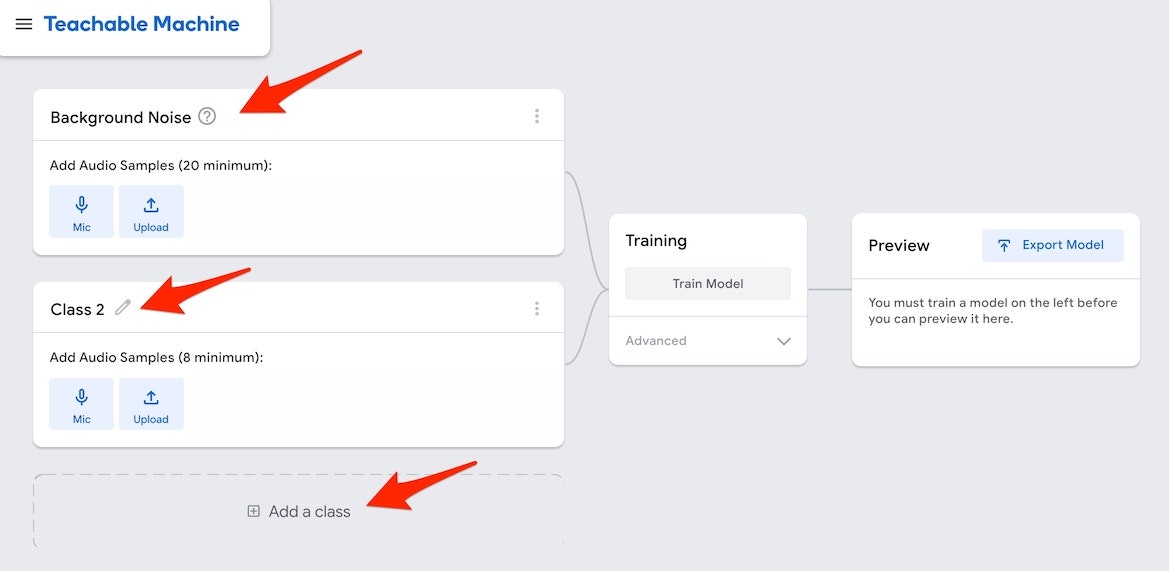
Background Noise
Background Noise については、下記の黒背景の部分の説明のとおり、
「最低20秒以上の、背景ノイズ」
を登録する部分のようです。また、この背景ノイズは削除・無効化はできない必須のデータとなるようです。
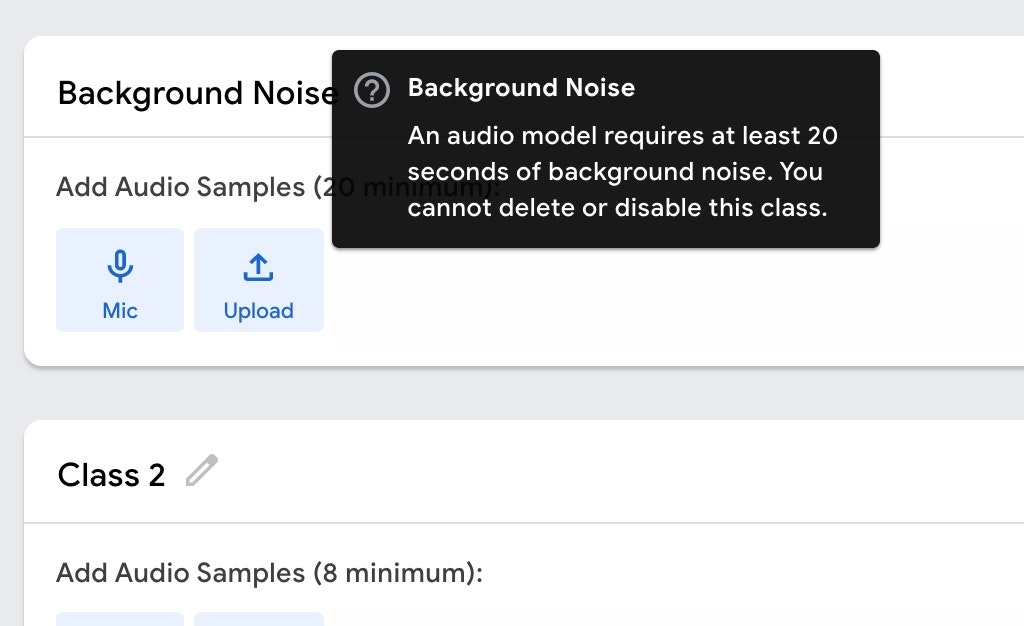
特殊なノイズがある環境下での音声認識をやる等といった話でなければ、「Micボタン」を押して、20秒以上の何もしゃべっていない状態の音を録音すれば良いかと思います。
「Micボタン」を押すと以下の画面になるので、設定はそのままで「Record 20 Seconds と書かれたボタン」を押して録音をします。
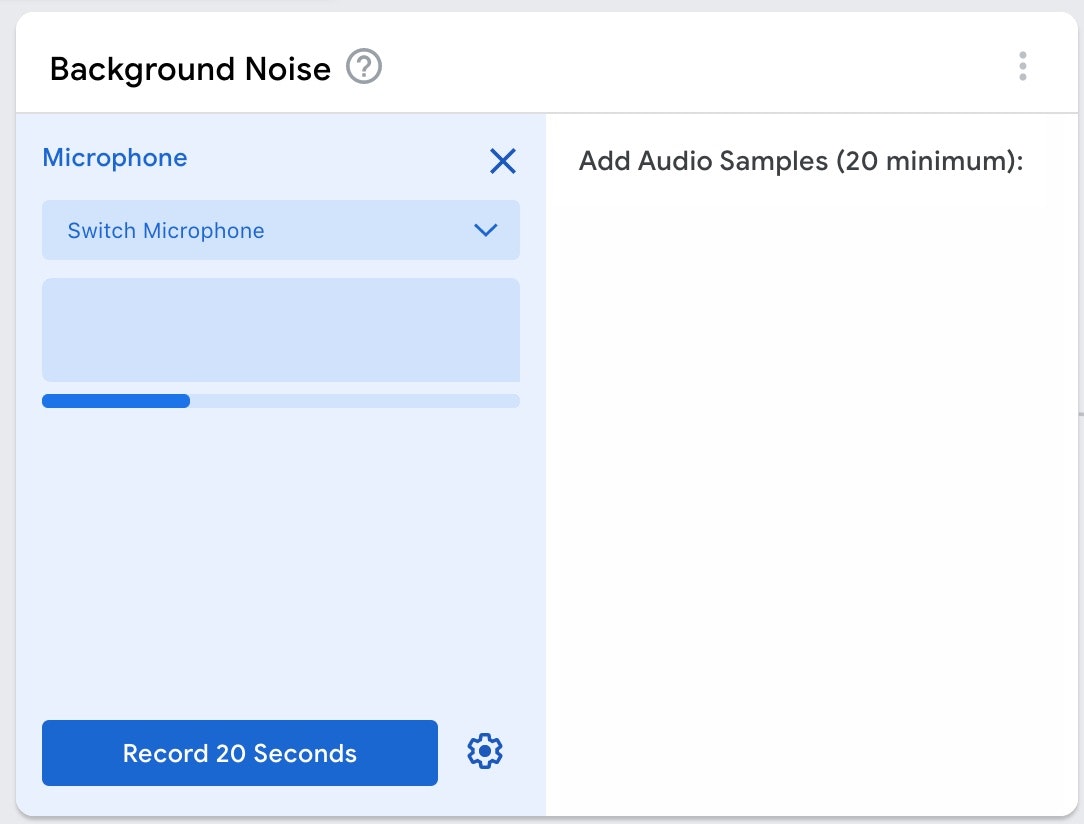
録音が終わると、以下のような画面になったかと思います。
以下の画像の赤い矢印で示した、「Extract Sample と書かれたボタン」を押してください。
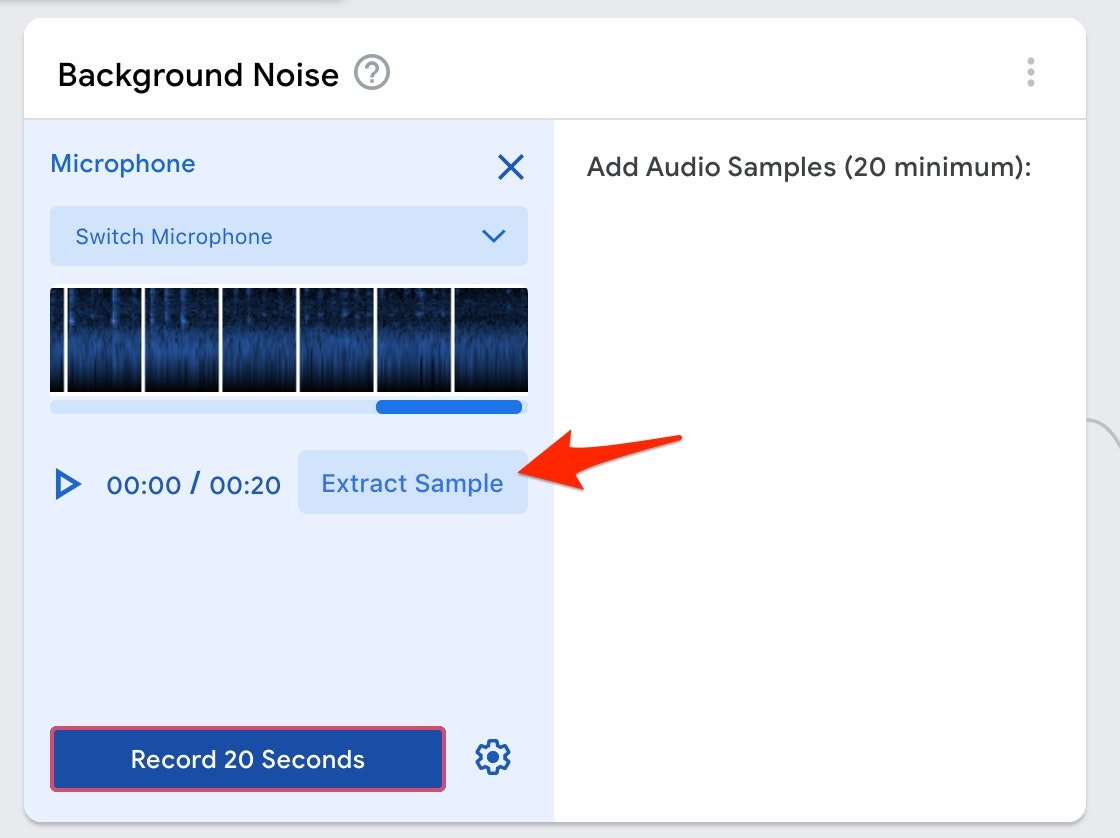
そうすると、以下の画面のように上記で白背景だった部分に音声データを1秒ずつ切り出したと思われるデータが並びます。
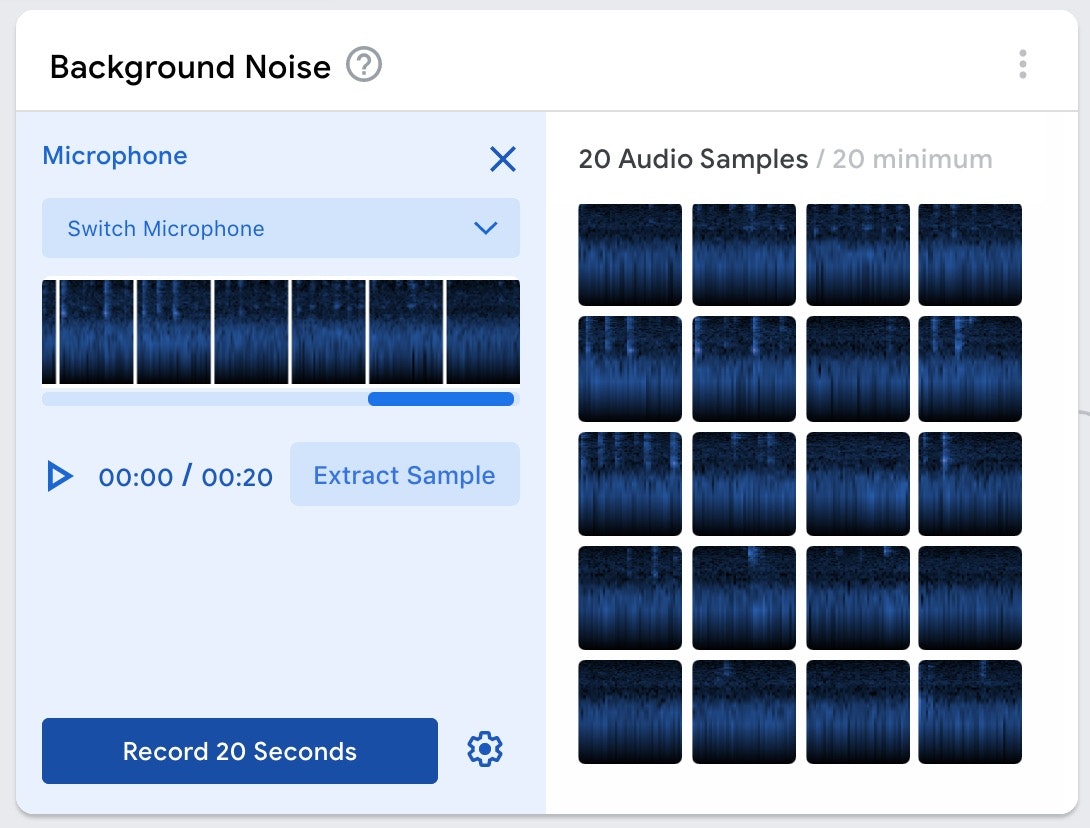
切り出された個々のデータをクリックすると、1秒分のデータの再生・削除ができるようです(以下の画像を参照)。
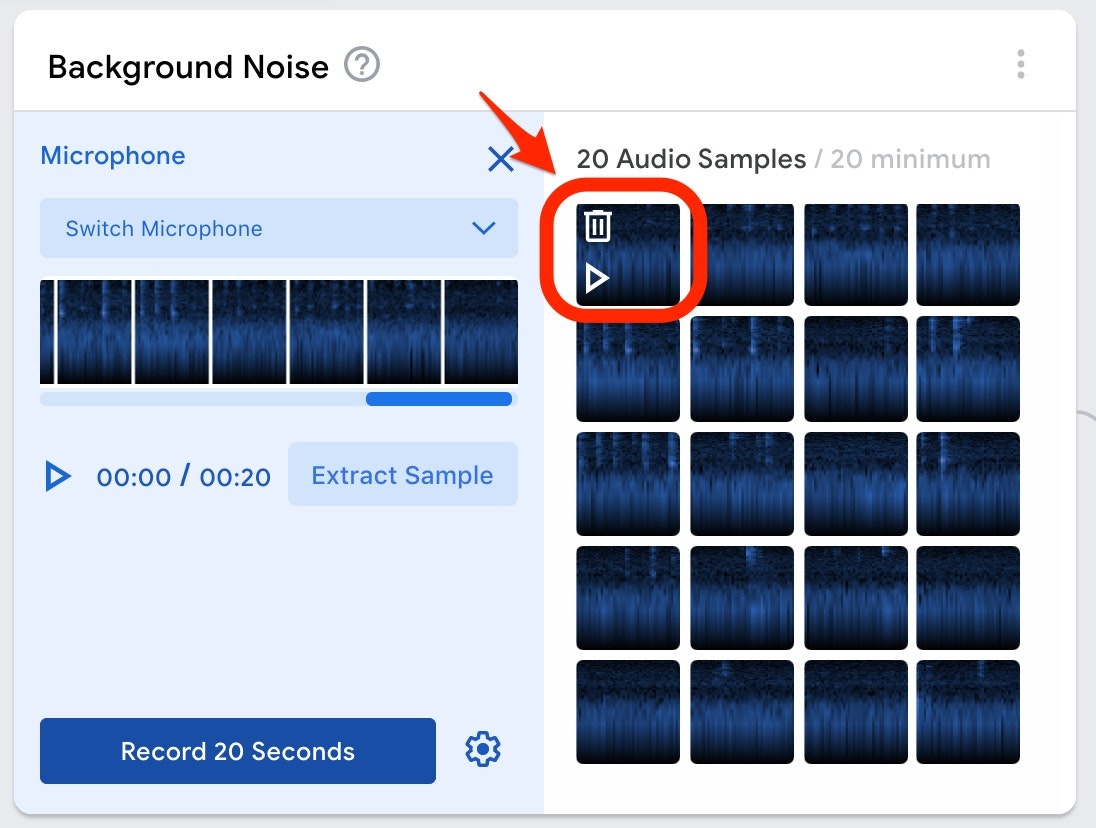
とりあえず、ここは特殊な背景ノイズを録音する意図もないので、ここで得られたデータ全てを利用することとします。
検出したい音声の入力 〜その1〜
それでは、検出をしたい音声(キーワード)を入力していきます。
以下の画像にある、Class2 のところに音声を入力していきます。以下の赤い矢印で示した部分から、Class2 という名前は変更もできるようですが、今回はそのまま使っていきます。
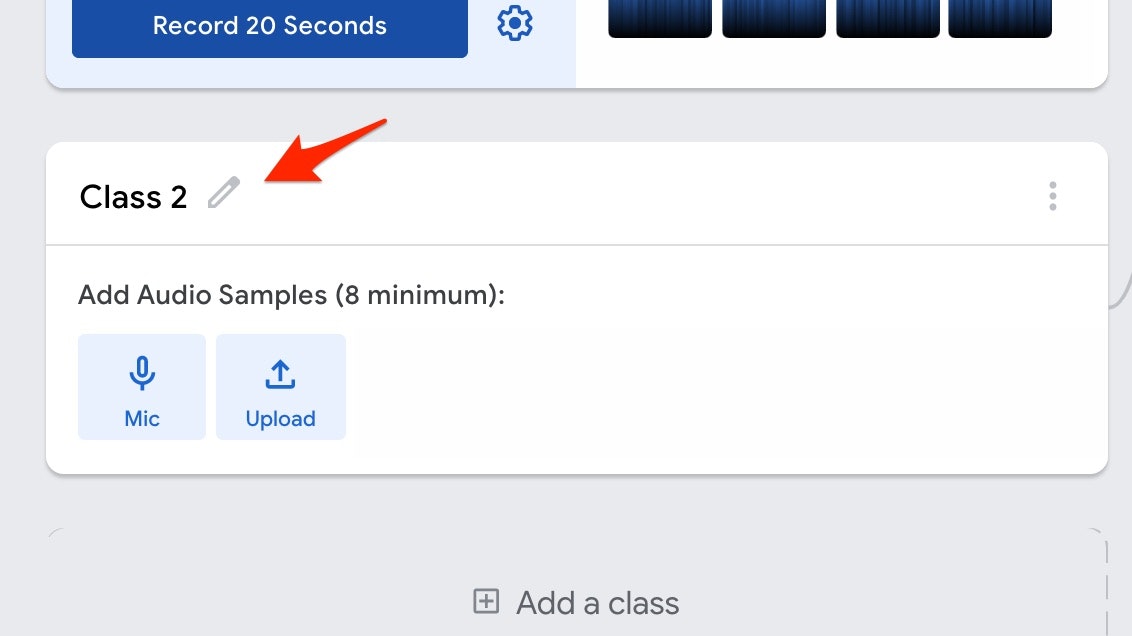
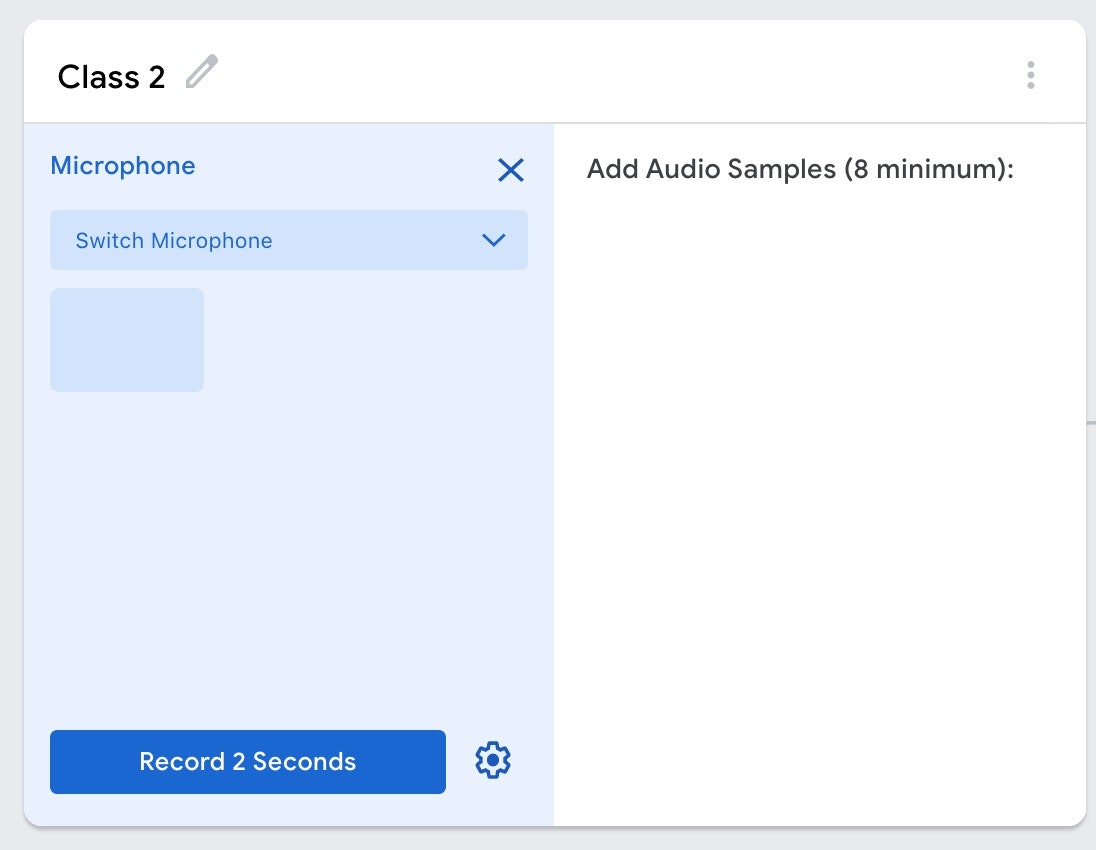
「Micボタン」を押すと、以下のような画面になります。
左下のボタン、右上の領域に書かれた内容を見てみると「2秒の音声を録音」して、「少なくとも8秒分以上のデータが必要」となるようです。
(【2020/2/6 追記】 デフォルトは2秒となっている録音時間を、設定から変更可能です)
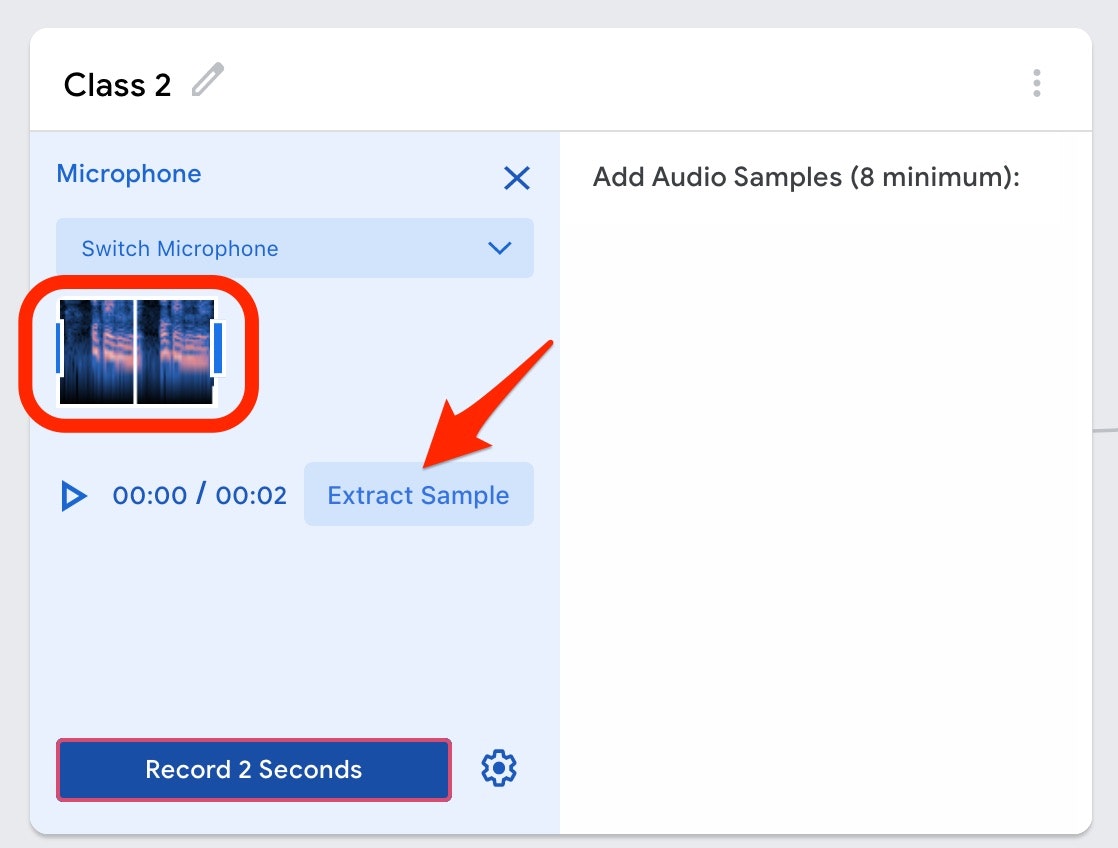
2秒分の音声を録音した後、以下の画像の赤い矢印の部分の「Extract Sample と書かれたボタン」を押すと、以下の画像の赤い枠で囲まれた部分(2秒分の音声データ)が右の領域にも表示された状態になります。
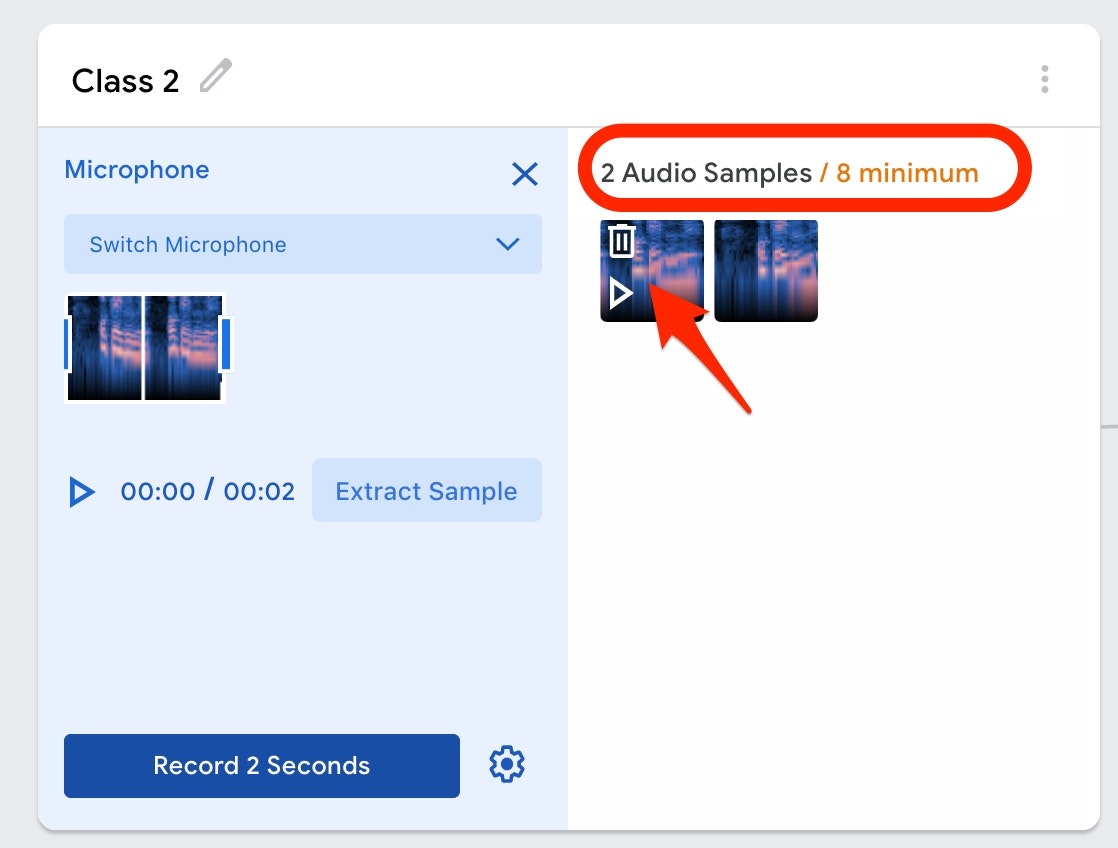
以下の画面の赤い枠で囲まれた部分を見ると、2つの音声サンプル(1秒分の音声データが2つ分)が登録された状態になったようです。以下の画像の赤い矢印で示した部分では、上記の「Background Noise」の登録の手順でもあったように、1秒分の音声データの再生や削除ができるようです。
この例では、「OK Google」としゃべるのを、2秒の間に2回行ってみています(1回の録音で、「OK Google」としゃべった1秒の音声が、2つ登録された状態になっています)。
そして、同じことをあと3回繰り返しました。その結果が、以下の画面です。
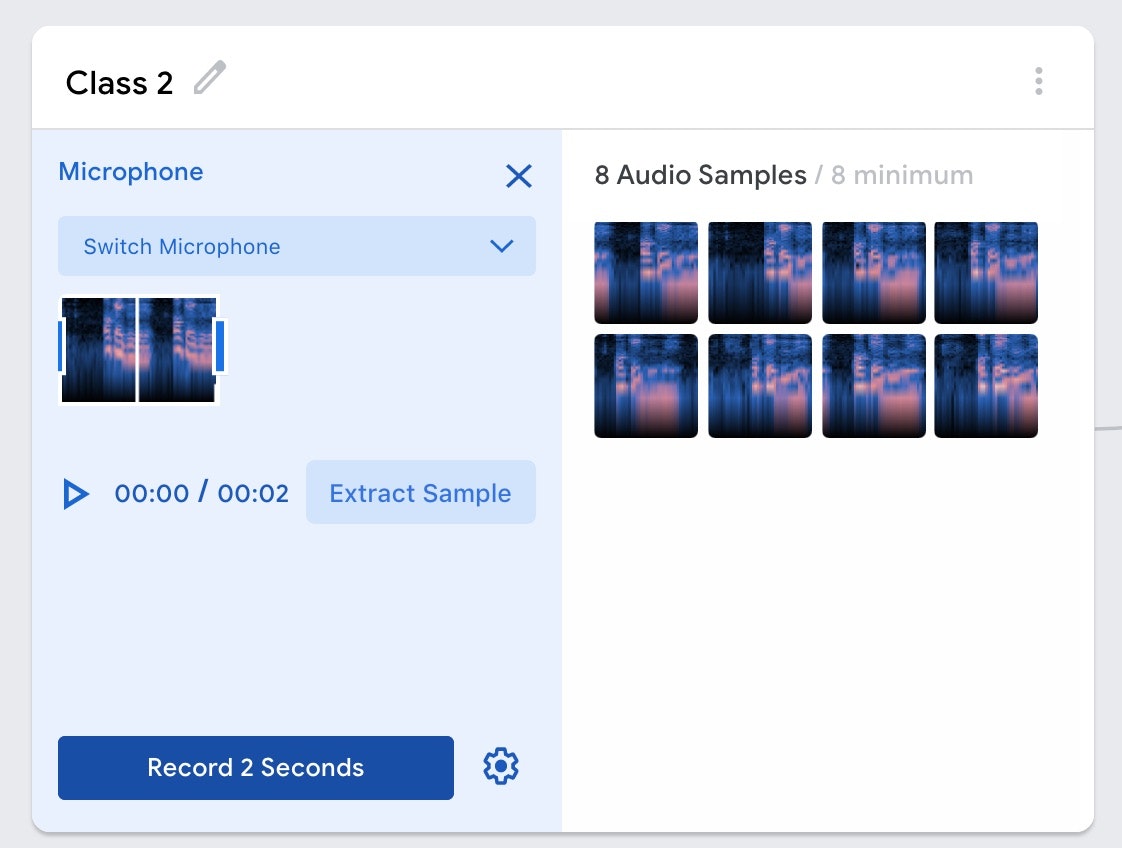
【2020/2/6 追記】 下記の手順で、1回で録音可能な時間(+ Micボタン押下後の録音開始までの待ち時間)を変更可能なようです)
・以下の赤い矢印で示した歯車アイコンを押下
 ・以下の赤い矢印で示した2箇所の数字で、「Micボタン押下後の録音開始までの待ち時間」と「1回で録音可能な時間」を設定
・以下の赤い矢印で示した2箇所の数字で、「Micボタン押下後の録音開始までの待ち時間」と「1回で録音可能な時間」を設定
 (↑ 設定変更の手順、ここまで)
(↑ 設定変更の手順、ここまで)
この状態で、以下で示した画面の真ん中あたりにある「Train Model と書かれたボタン」が、グレーアウトしていた状態だったのが青い色になります。
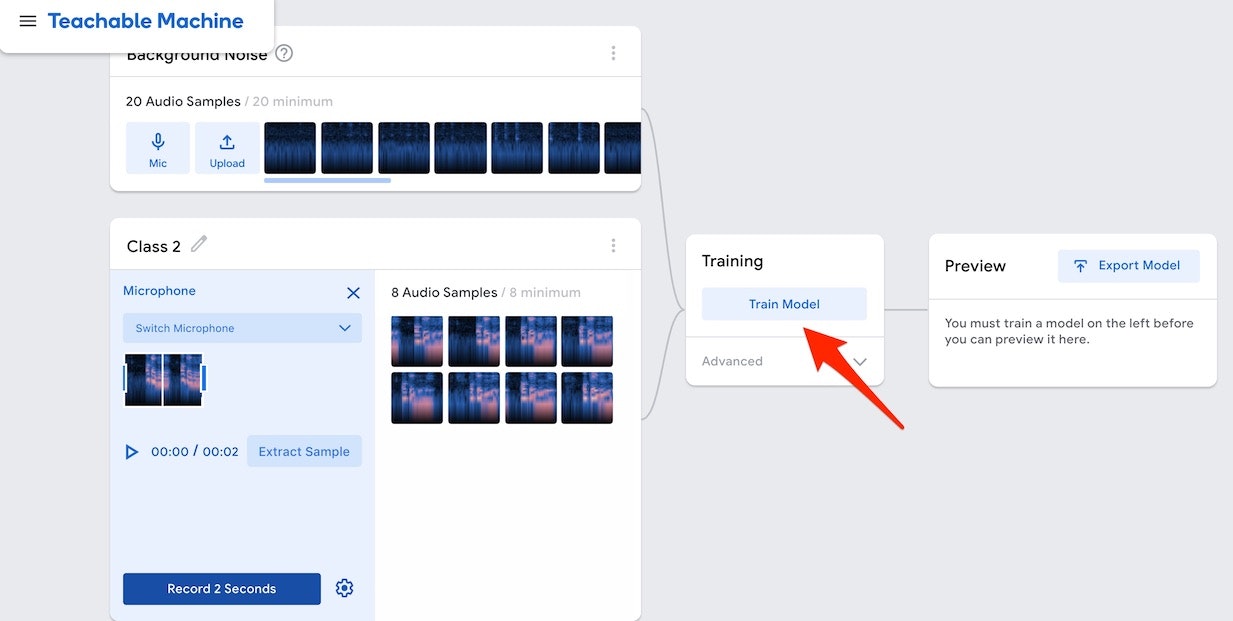
このボタンを押すと、録音した音声データから学習が行われて、推論を実行することができるようになります(今の状態では、「OK Google」というキーワードが検出されたかどうかが分かるだけ)。
今回は、複数のキーワードを検出する仕組みにしたいので、さらに音声データの追加を行っていきます。
検出したい音声の入力 〜その2 から その4〜
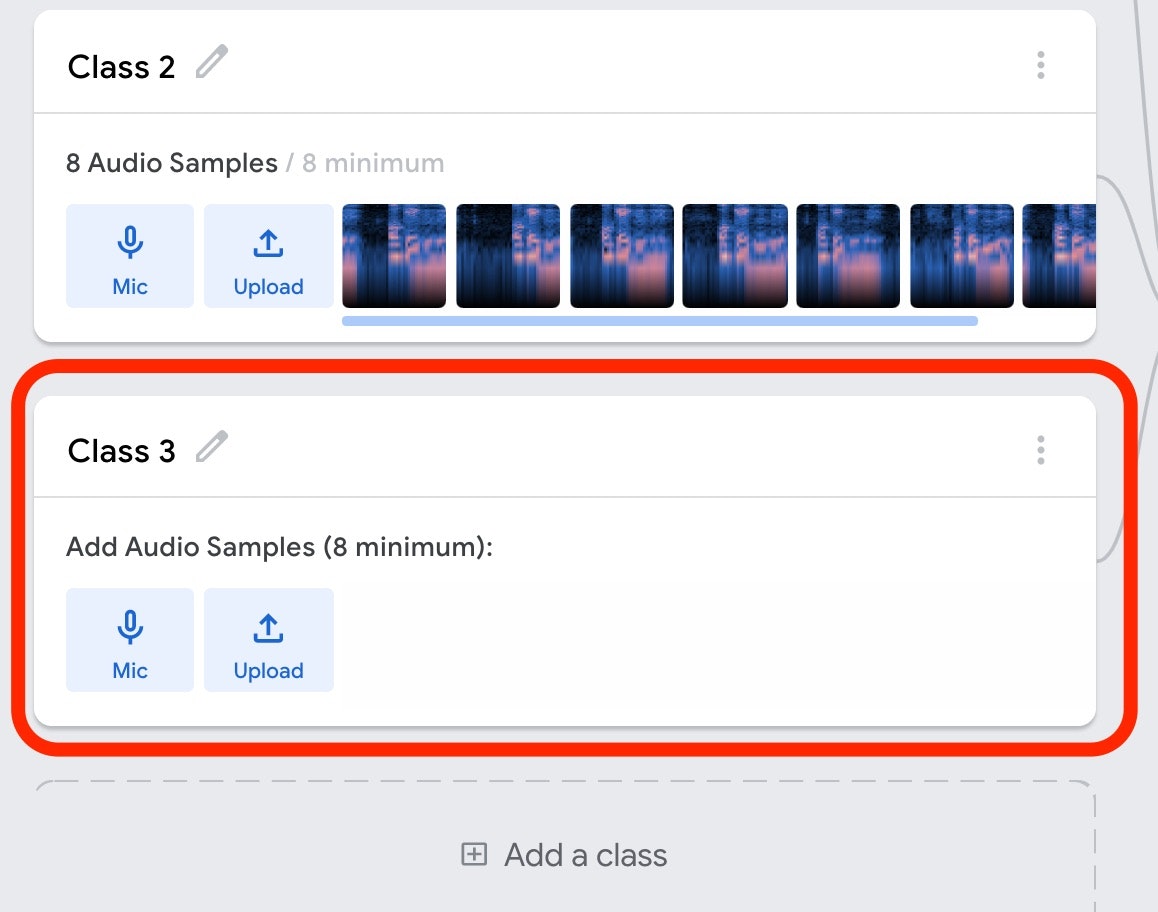
では、以下の画面の「Add a class と書かれたボタン」を押してみましょう。

そうすると、以下のように、上記の Class2 のデータを入力していく前の状態の部分が追加されるかと思います。後は、上記の Class2 で音声を入力していったのと同じ手順で、この Class3 でも異なるキーワードを入力していきます。
冒頭に動画で紹介した内容では、Class3 は「Hey Siri」というキーワードを入力しています。
最低でも、8秒分のデータを入力しましょう。
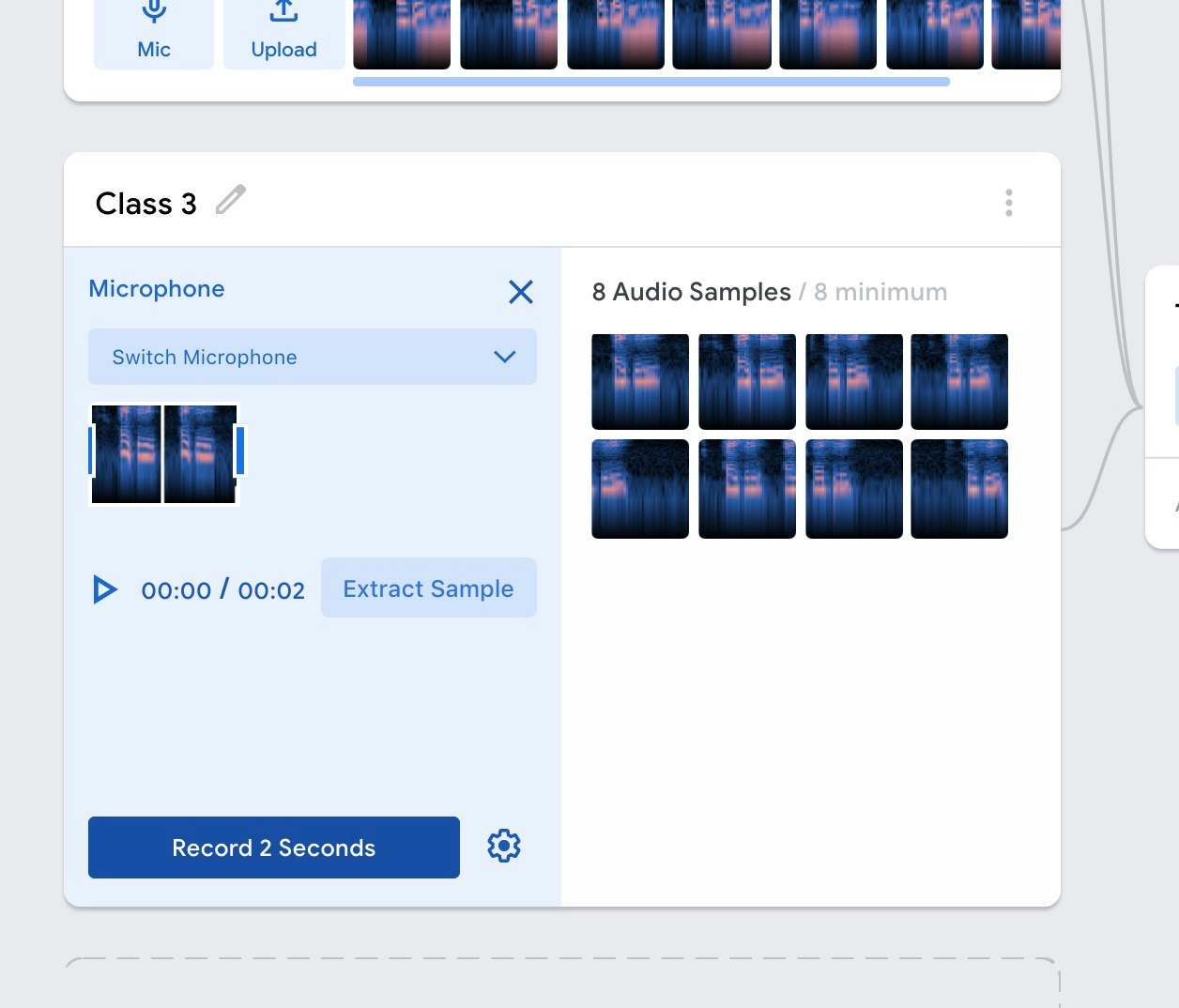
そして、さらに「Add a class と書かれたボタン」を押して Class4 と Class5 を追加し、それぞれ「Alexa」 と 「ねえ Clova」というキーワードをそれぞれ入力していきます。
これで、必要なデータが揃いました。
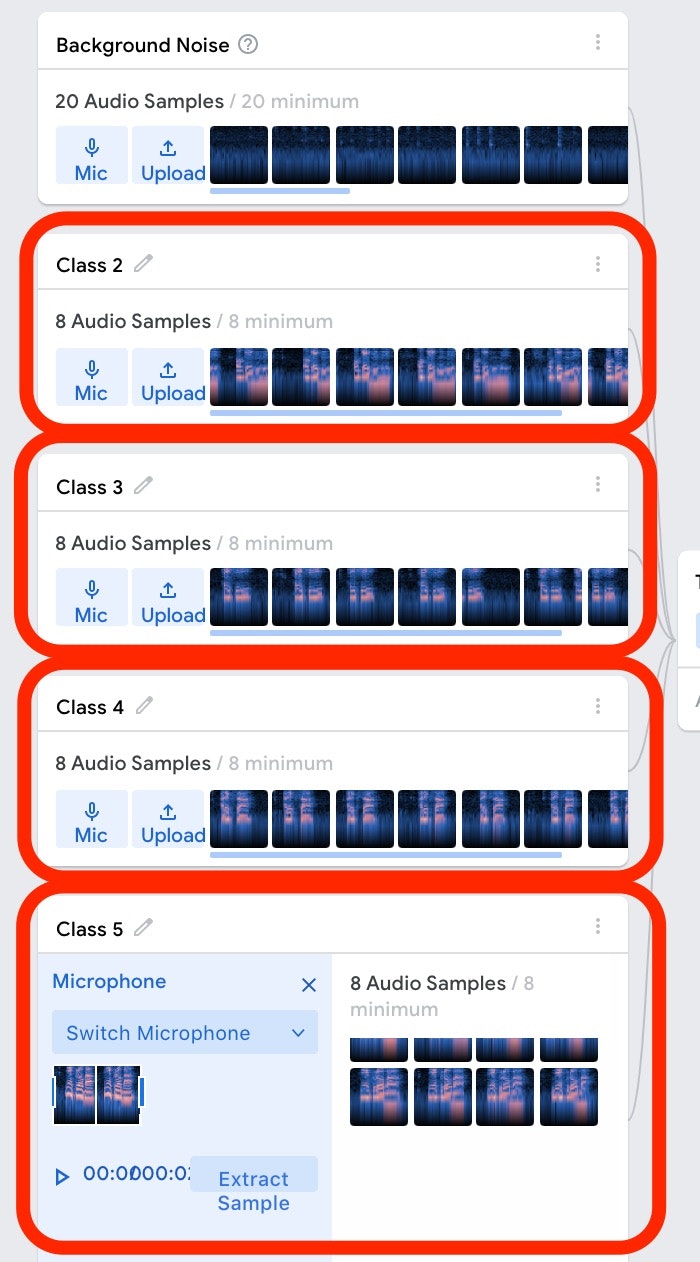
学習の実行
それでは、画面内の「Train Model と書かれたボタン」を押して、学習を行います。
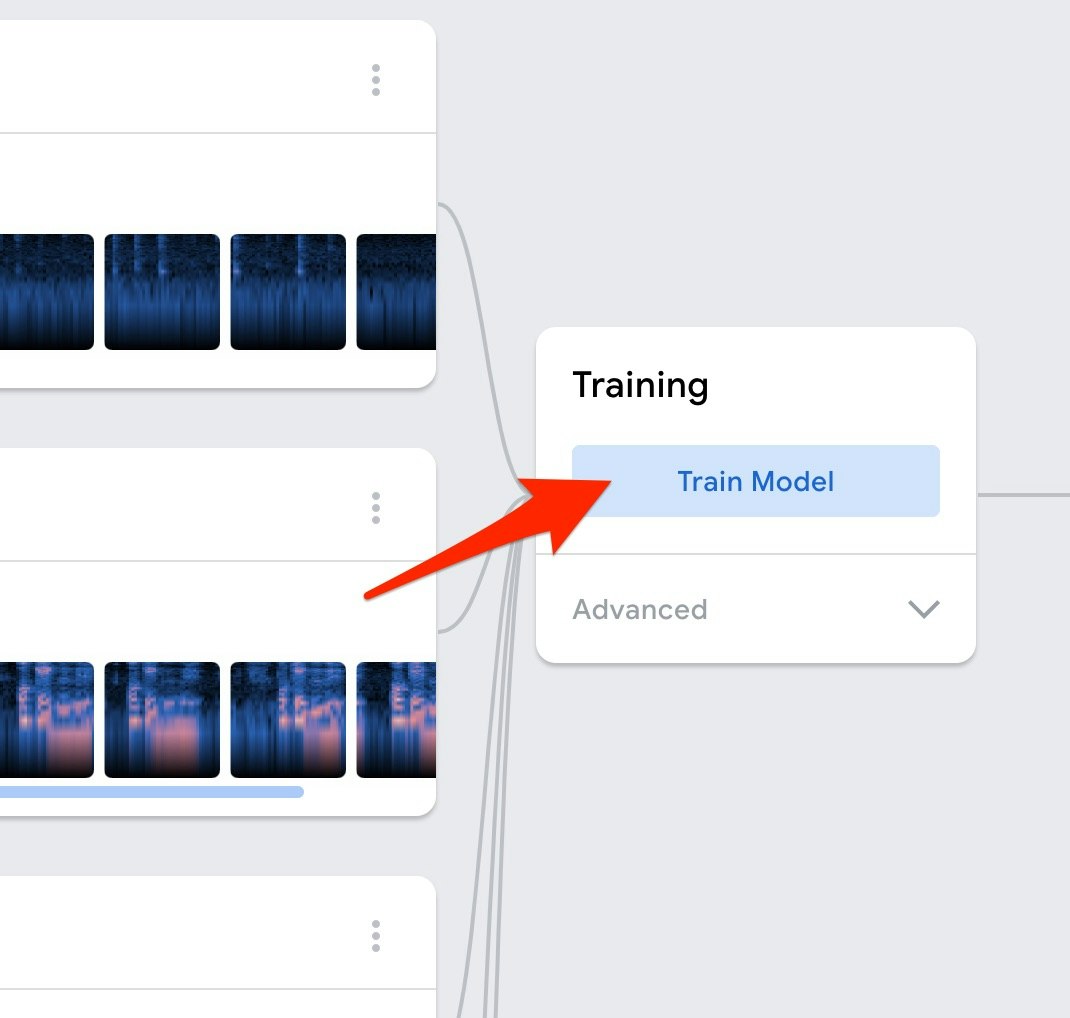
そうすると、以下の赤枠で示したようなメッセージがでたり、表示がされたりして学習が実行されていきます。
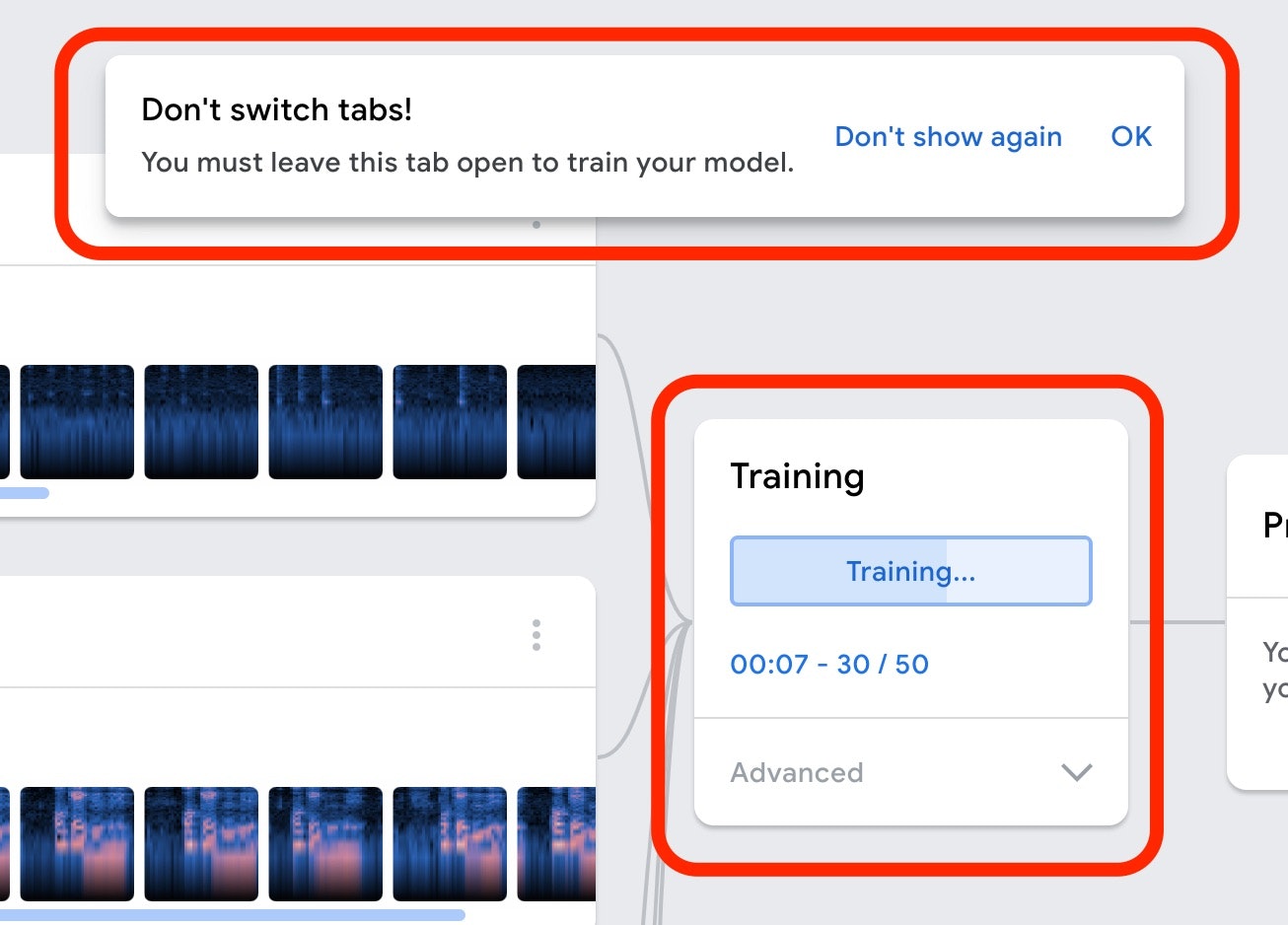
推論(キーワードの検出)
学習が終了すると、自動的に以下の画像のように、画面の右のほうでマイクから入力される音声からのキーワード検出が試せる部分が表示されます。
以下の画像は「OK Google」とマイクでしゃべった直後のキャプチャになります。
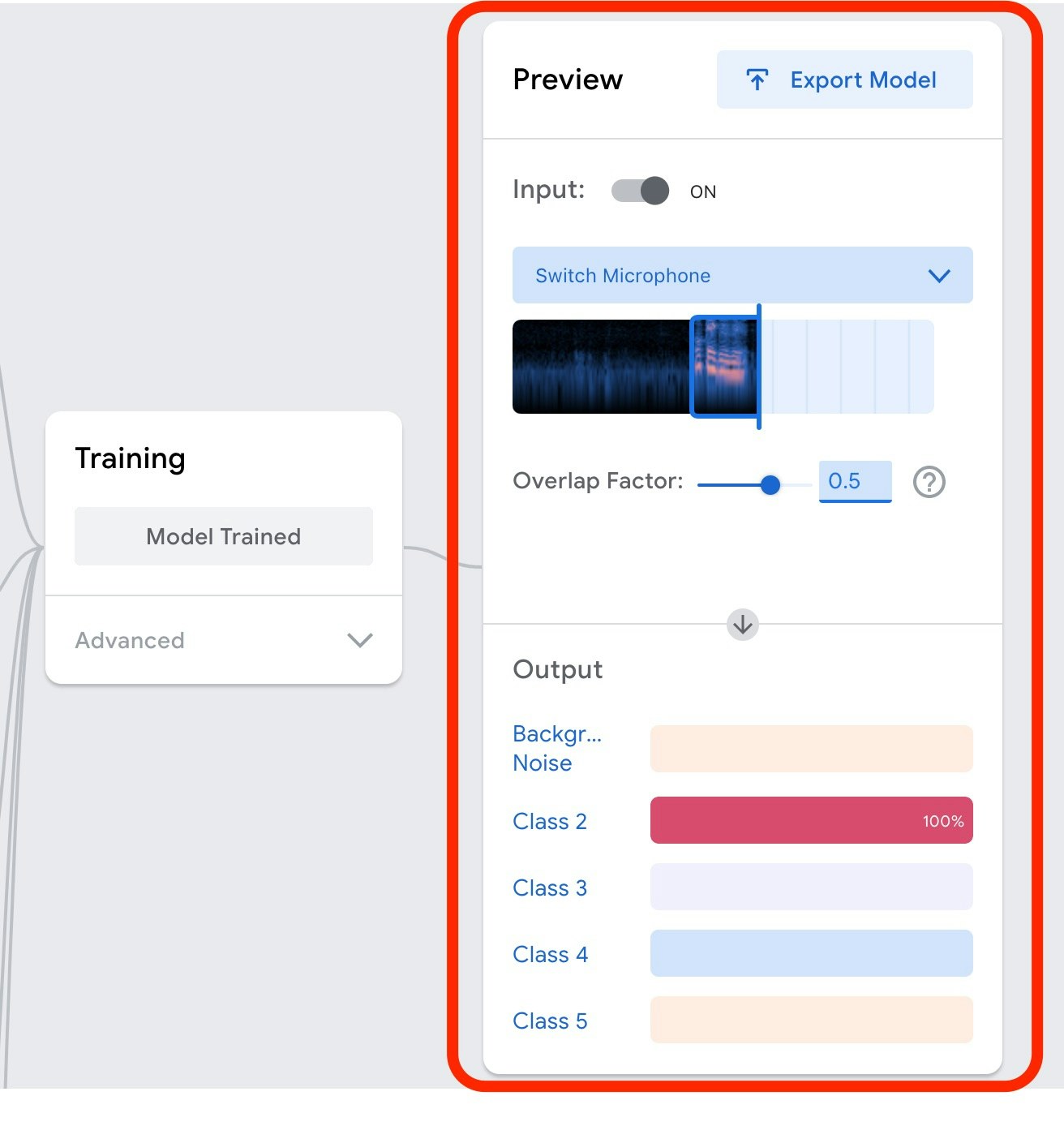
そのため、Class2 の部分の色つきのバーが横にのびています。
どうやら、入力された音声は
100%、「OK Google」としゃべっている(他の、Background Noise である可能性や、Class3 から Class5 で入力した音声の可能性はない)
と判断しているようです。
作成したモデルをプログラムで利用する
このブラウザ上で作成したモデルは、クラウドにホスティングしたり、ダウンロードしたりすることができるようです。
以下の「Export Model」というボタンを押してみます。
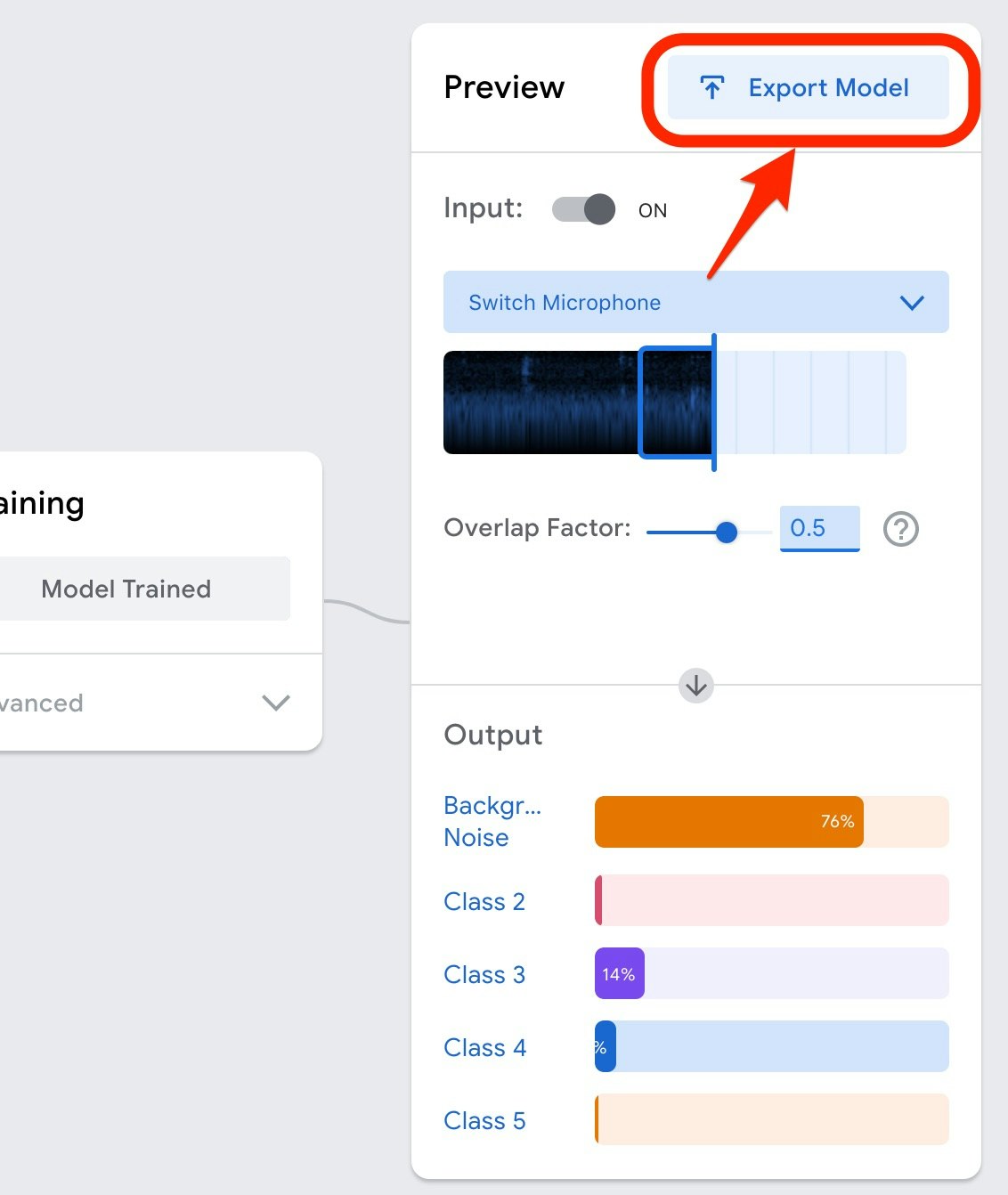
そうすると、以下のようなウィンドウが画面内に表示されます。
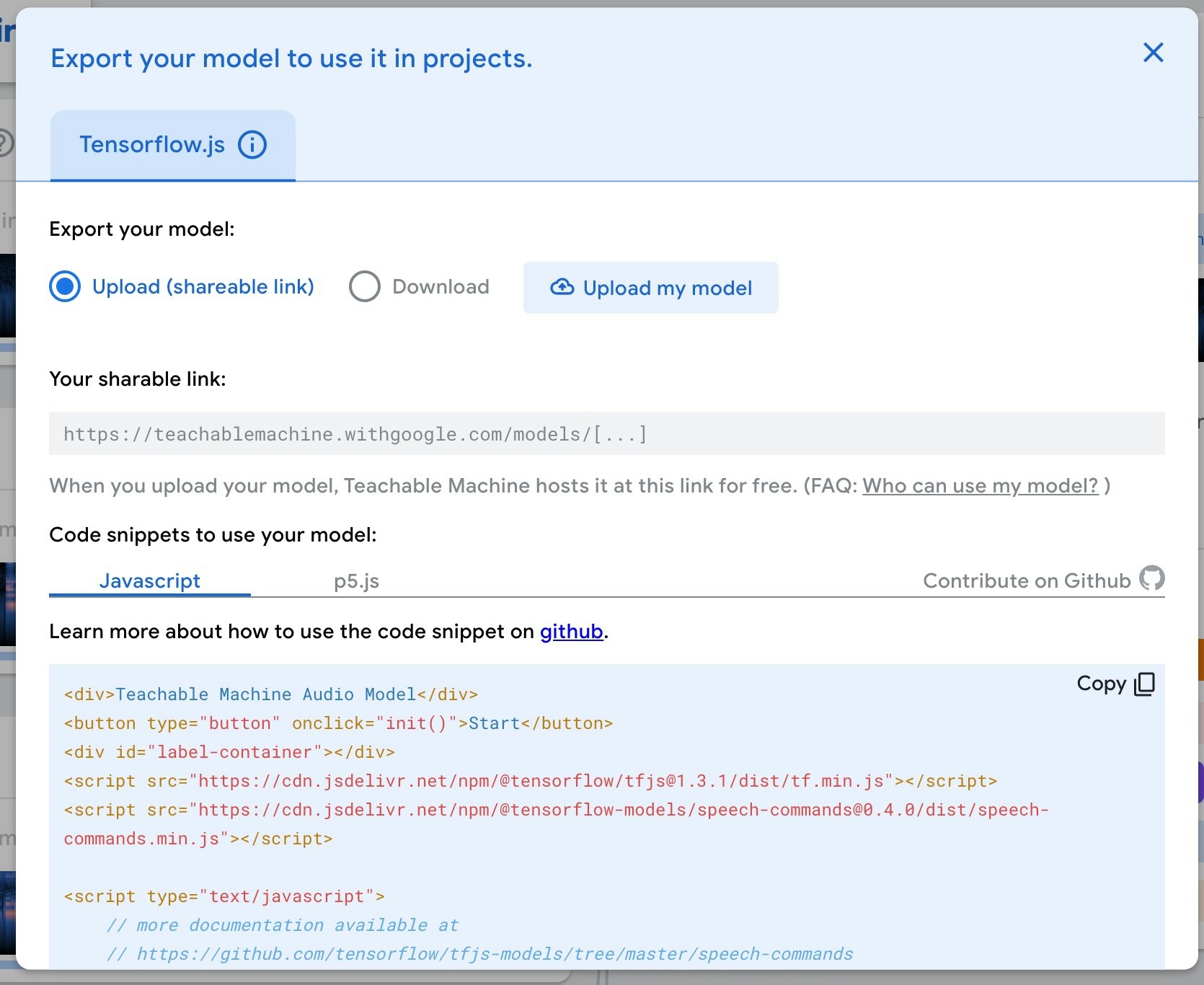
画面内の「Upload my model と書かれたボタン」を押すとモデルデータのアップロードが行われ、それが完了すると以下の赤枠で示したとおりアップロード先のモデルを参照するための URL が発行されます。
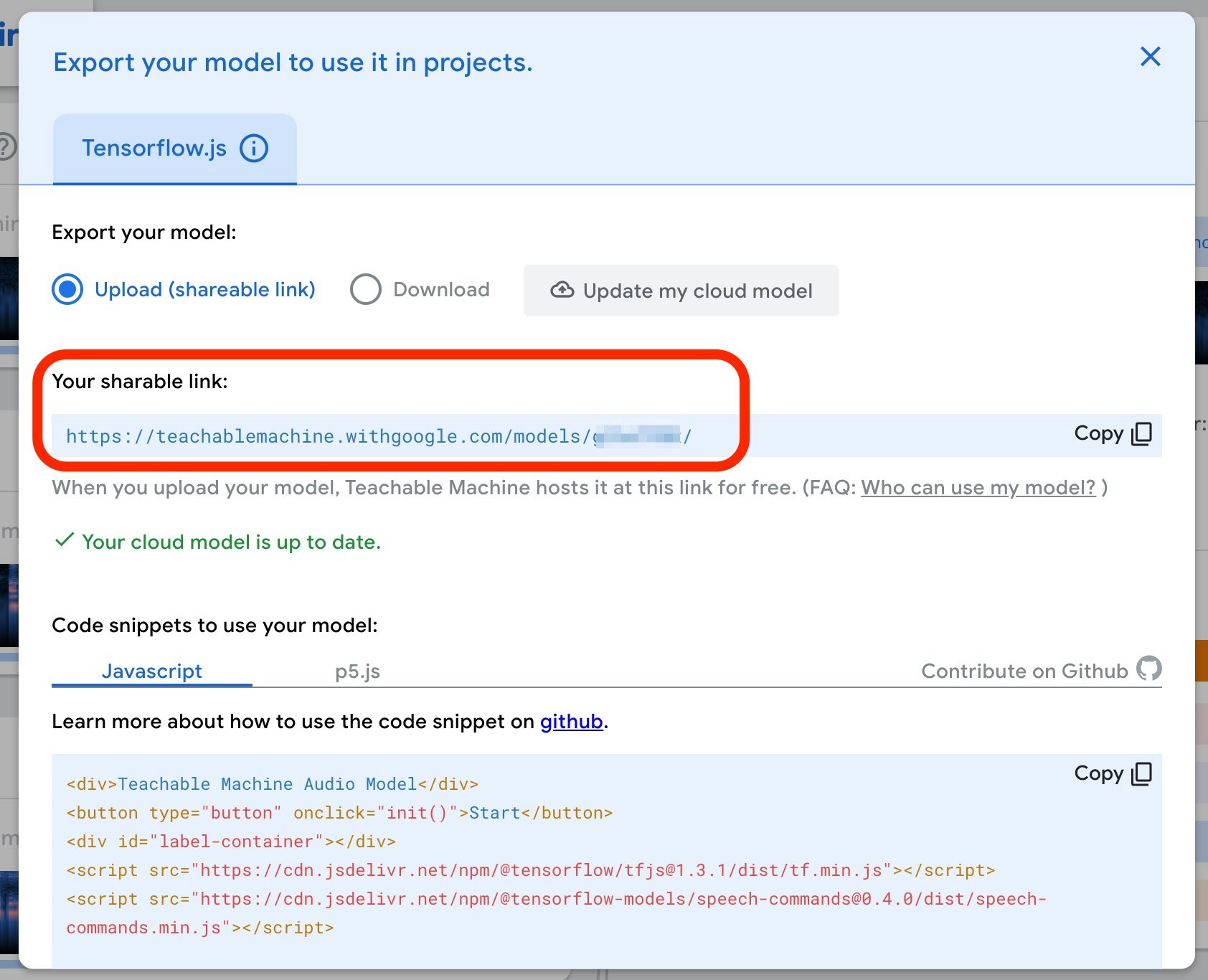
また、「Downloadボタン」を押すと、以下のような3つのデータが含まれたZIPファイルでダウンロードすることができます。
上記で、クラウドにアップロードしたり、PC へとダウンロードしたモデルは、自分が書いたプログラムで利用することができます。
それを実行するための簡単なサンプルについては、以下の赤枠や赤い矢印で示したとおり、「JavaScript」か「p5.js」のソースコードを選択して見ることができます。
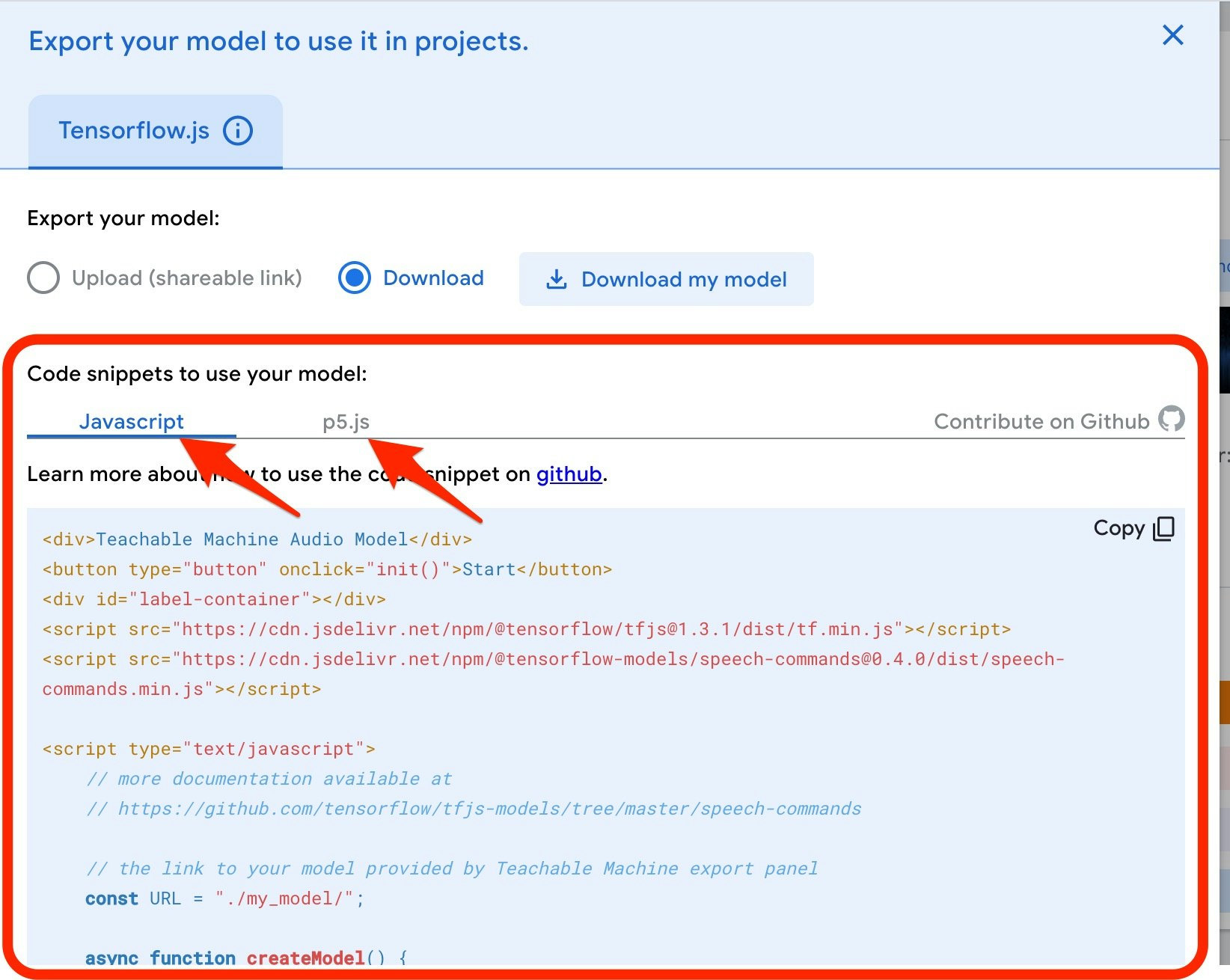
クラウドにアップロードした場合も、PC へダウンロードした場合も試してみましたが、サンプルのプログラムを少し書きかえたり等の追加対応をすることで、プログラムから利用することができました。
また、軽く確認してみたところ、モデルをダウンロードして行う場合はオフラインでの動作も可能なようでした。
おわりに
Teachable Machine を使うことで、ブラウザの上だけで以下の内容を簡単に試すことができました。
・音声の録音
・録音したデータを使った学習(モデルの作成)
・作成したモデルを使った推論(音声からのキーワード検出)
・作成したモデルのホスティングやダウンロード
録音できる時間の制約はあるので、認識できる音声に制約はできそうですが、簡単なキーワード検出くらいであれば比較的簡単に実現できそうです。
また、今回は音声データを最低限必要な8秒分ずつしか用意しませんでしたが、キーワード検出は高精度に行えていたようでした。
今後も、学習したモデルをプログラムで利用するものをきちんと試してみたり、これをうまく活用した使い道を考えてみたりできればと思います。
【2020/2/14 追記】 音を対象にしたモデル作成とJavaScriptでの利用( toio を制御)のデモ動画
タンバリンや卓上ベルの音を学習させてモデルを作成し、それらの音の違いでロボットトイの toio を制御するプログラムをJavaScriptで書いてみました(ブラウザ上でプログラムを動かし、toio との通信部分は Web Bluetooth API を利用)。
この前の実験の続き。
— you (@youtoy) February 13, 2020
音の種類によって #toio が異なるスピードで回転したり、前に動いたり。#toiotomo pic.twitter.com/U5QU2rLMFl
【2020/2/15 追記】 音を対象にしたモデル作成とJavaScriptでの利用( toio を制御)のやり方に関する Qiita の記事
上記のデモ動画の仕組みを作った話に関する Qiita の記事を公開しました。
●toio を音で制御してみた(Audio用の Teachable Machine でベルやタンバリンの音を機械学習) - Qiita
https://qiita.com/youtoy/items/37f70bb4ce630e6cbd92
【2020/10/7 追記】 音と声を利用したtoioの制御(Maker Faire Tokyo 2020 の出展にも利用)
10/3・4(土・日)に toio のコミュニティで Maker Faire Tokyo 2020 に出展して、その際に Teachable Machine を使った作品も展示の 1つに加えてました。
#MFTokyo2020 の #toiotomo のブースでは、実際の作品をいくつか展示しつつ、コミュニティメンバーの作品の動画展示も合わせて行う予定なのですが、
— you (@youtoy) September 30, 2020
その動画展示に関して自分も動画を出すために、過去の作品のいくつかを60秒くらいにまとめてみました。https://t.co/BESQ1qTy7n#toio pic.twitter.com/wb4wZMWJBt
#MFTokyo2020 の初日の会場にて、音の機械学習をやり直したら(会場のノイズ込みの学習データになるようにしたら)、
— you (@youtoy) October 4, 2020
2日目の会場では、昨日と別物であるかのように良い感じに動くようになった!#toio #toiotomo https://t.co/ejcn43IjIe pic.twitter.com/vXpTSq3Sd6
青いベルの音と緑のベルの音を機械学習で判別。地味に難しいことやってる#MFTokyo2020 #toio pic.twitter.com/fpqogGMZ5w
— ロボ先輩@3rd Factory (@3rd_factory_ro) October 4, 2020