【2020/2/16 追記】 2/15・16(土・日)に開催されたつくばのミニメーカーフェアに出展して、来場者の方に作品を試してもらった際の話やツイートを追加
【2020/2/25 追記】 楽器の違いではなく、同じ楽器での音階の違いを学習させて試した動画を追加掲載
はじめに
今月はじめに書いた以下の記事で取り上げた「音を対象とした Teachable Machine」に関する話で、別の要素と続きの両方の内容が含まれた記事です
●Teachable Machine を使った音声からの任意のキーワードの検出(ブラウザ上で機械学習) - Qiita
https://qiita.com/youtoy/items/9096836e5d77274500ea
別要素の部分は機械学習で学習させた対象が声から音になっているところで、続きになる部分というのは Teachable Machine で作成したモデルを JavaScript から扱うところです。
今回の記事の内容
概要とデモ動画
今回の記事では、音を対象とした機械学習によるモデル作成と、そのモデルを JavaScript のプログラムで用いる部分について書こうと思います。
以前書いた記事では、内容が異なる4パターンの音声(自分がしゃべった声)を学習させ、今回は 100円ショップで買ってきたタンバリンや卓上ベル等の 3つの音を学習させています。

音を鳴らすのに用いた物は 3つですが、卓上ベルに関しては鳴らし方を「普通に鳴らすのと、連打する形の 2パターン」を学習させたため、学習させた音の種類は 4つ(背景雑音も含めると 5つ)になります。
そして、作成したモデルを使ってロボットトイの toio を制御するプログラムをJavaScriptで書き、実際に動作させてみました(動作させた際の様子は下記のとおりです)。
プログラムはブラウザ上(Google Chrome)で動かしていて、toio と通信する部分の処理には [Web Bluetooth API](https://tkybpp.github.io/web-bluetooth-jp/) を用いています。この前の実験の続き。
— you (@youtoy) February 13, 2020
音の種類によって #toio が異なるスピードで回転したり、前に動いたり。#toiotomo pic.twitter.com/U5QU2rLMFl
なお今回の内容は、2/15・16(土・日)に開催されるイベント「Tsukuba Mini Maker Faire 2020」で、下記の「toio™で作ってみた!友の会」の展示ブースでの展示のために作ったものになります。

ソースコード等
未実装部分や整理されていない部分はありますが、ソースコード全体は以下から参照可能です。
(整理してからとか、仕上がってからとか、考えているとしばらく公開しない状態が続きそうな気がするため、公開してしまおうかと思います)
●API_Test/test02_c.html at master · yo-to/API_Test
https://github.com/yo-to/API_Test/blob/master/WebAPI/test10_test09_and_AudioRecognition/test02_c.html
上記のリポジトリは GitHub Pages の設定をしているので、下記の URL にアクセスするとお試しも可能です(試すためには toio が必要になりますが・・・)。
https://yo-to.github.io/API_Test/WebAPI/test10_test09_and_AudioRecognition/test02_c.html
補足などは、以下で書いていきます。
音で toio を制御するためにやったこと
音を Teachable Machine で学習させる
基本的な進め方は、冒頭でもご紹介した以下の記事で書いた流れと同じです。
●Teachable Machine を使った音声からの任意のキーワードの検出(ブラウザ上で機械学習) - Qiita
https://qiita.com/youtoy/items/9096836e5d77274500ea
上記との進め方の違いは「音を学習させる際に、自分が何かしゃべるのではなくタンバリンやベルを鳴らしたりした」こと、「録音時間の設定をデフォルトの 2秒から 10秒(または 15秒)に変更した」ことと、「各クラスの名称をデフォルトの名前(Class2、Class3 など)ではなく、タンバリンや銀ベルなどに変更した」ことくらいです。
また、最終的に選択した音のパターンは「タンバリンと2種類のベルの音(うち1種類は連打するかしないかの2パターン)」の 4パターンでしたが、学習させる過程では下記のような音の鳴らし方も学習させて区別できるか(十分な精度が得られそうか)を試していました。
- 人が聴くと音色が違う色違いの卓上ベル(形状は同じ)のそれぞれを単独で鳴らしたときの音色
- 同じく色違いの卓上ベルをそれぞれ単独で鳴らしたときと、同時に鳴らしたときの音色
- ハンドベル(銀ベルという名称にしているもの)を振るスピードを変えたときの音色
上記を採用しなかったのは、音源となるベルなどと PC本体の位置(マイクの位置)との位置関係などの条件が変わったときに誤認識がわりとでるように思われたり、うまく区別できかったりということが見られたりしたためです。もしかしたら、何か工夫をすると区別できるようになるかもしれないですが、特殊な対応を行うことなく実現できるものを採用したかったため、デモ動画で使っている内容を採用することとしました。
作成したモデルを JavaScript で動かす(まずはサンプルを動作させる)
モデルの作成を行った次のステップは、作成したモデルをプログラムから利用するステップです。
ブラウザ上で作成したモデルをダウンロードする際に、そのモデルを使うプログラムの例は JavaScript のプログラムと、p5.js を使ったプログラムが提示されます(以下の画像の赤と緑の矢印で示した部分のタブで切り替え)。
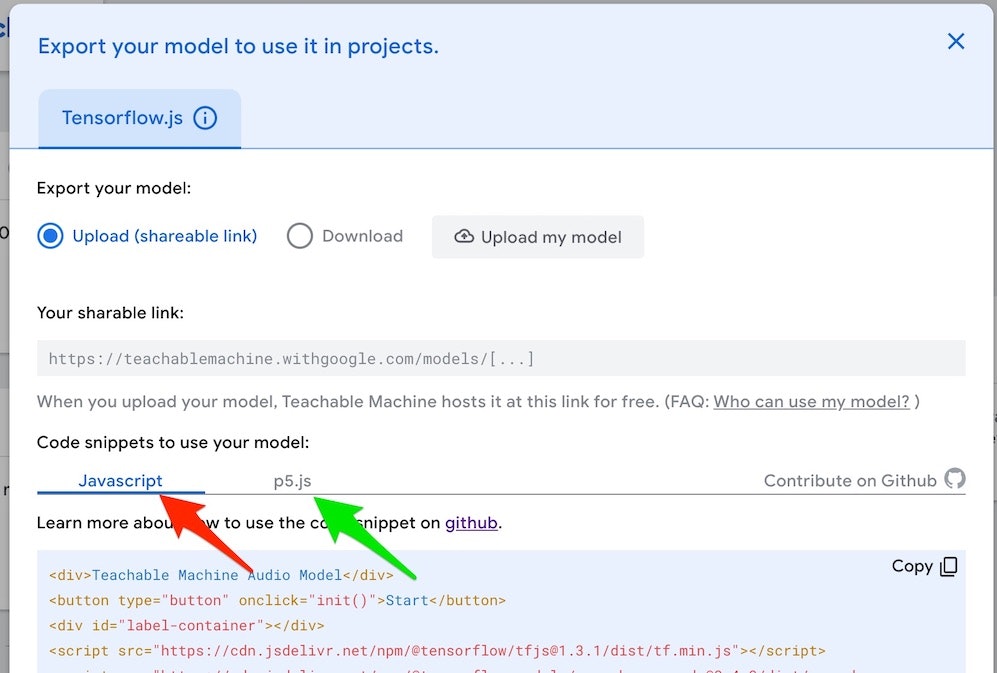
今回は、JavaScript のプログラムを採用しました。そして、まずはサンプルを自分の環境で動作させられるよう試しました。
サンプルプログラムは以下の URL でも閲覧できるようです。
●teachablemachine-community/libraries/audio at master · googlecreativelab/teachablemachine-community
https://github.com/googlecreativelab/teachablemachine-community/tree/master/libraries/audio
Sample snippet と書かれた部分に以下のプログラムが掲載されています。
<div>Teachable Machine Audio Model</div>
<button type='button' onclick='init()'>Start</button>
<div id='label-container'></div>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.3.1/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/speech-commands@0.4.0/dist/speech-commands.min.js"></script>
<script type="text/javascript">
// more documentation available at
// https://github.com/tensorflow/tfjs-models/tree/master/speech-commands
// the link to your model provided by Teachable Machine export panel
const URL = '{{URL}}';
async function createModel() {
const checkpointURL = URL + 'model.json'; // model topology
const metadataURL = URL + 'metadata.json'; // model metadata
const recognizer = speechCommands.create(
'BROWSER_FFT', // fourier transform type, not useful to change
undefined, // speech commands vocabulary feature, not useful for your models
checkpointURL,
metadataURL);
// check that model and metadata are loaded via HTTPS requests.
await recognizer.ensureModelLoaded();
return recognizer;
}
async function init() {
const recognizer = await createModel();
const classLabels = recognizer.wordLabels(); // get class labels
const labelContainer = document.getElementById('label-container');
for (let i = 0; i < classLabels.length; i++) {
labelContainer.appendChild(document.createElement('div'));
}
// listen() takes two arguments:
// 1. A callback function that is invoked anytime a word is recognized.
// 2. A configuration object with adjustable fields
recognizer.listen(result => {
const scores = result.scores; // probability of prediction for each class
// render the probability scores per class
for (let i = 0; i < classLabels.length; i++) {
const classPrediction = classLabels[i] + ': ' + result.scores[i].toFixed(2);
labelContainer.childNodes[i].innerHTML = classPrediction;
}
}, {
includeSpectrogram: true, // in case listen should return result.spectrogram
probabilityThreshold: 0.75,
invokeCallbackOnNoiseAndUnknown: true,
overlapFactor: 0.50 // probably want between 0.5 and 0.75. More info in README
});
// Stop the recognition in 5 seconds.
// setTimeout(() => recognizer.stopListening(), 5000);
}
</script>
変更する必要があるのは const URL = '{{URL}}'; の部分くらいで、こちらは、ご自身がブラウザ上で作成したモデルデータが置かれたフォルダを指定する箇所です。
Teachable Machine で作成したモデルは、ダウンロードするかクラウドに置くかを選択できるのですが、下記のように「Export your model:」の部分で「Upload(shareable link)」を選択してWeb上に置く形をとった場合は、その URL (以下の画像の赤枠で囲った部分)を指定してください。
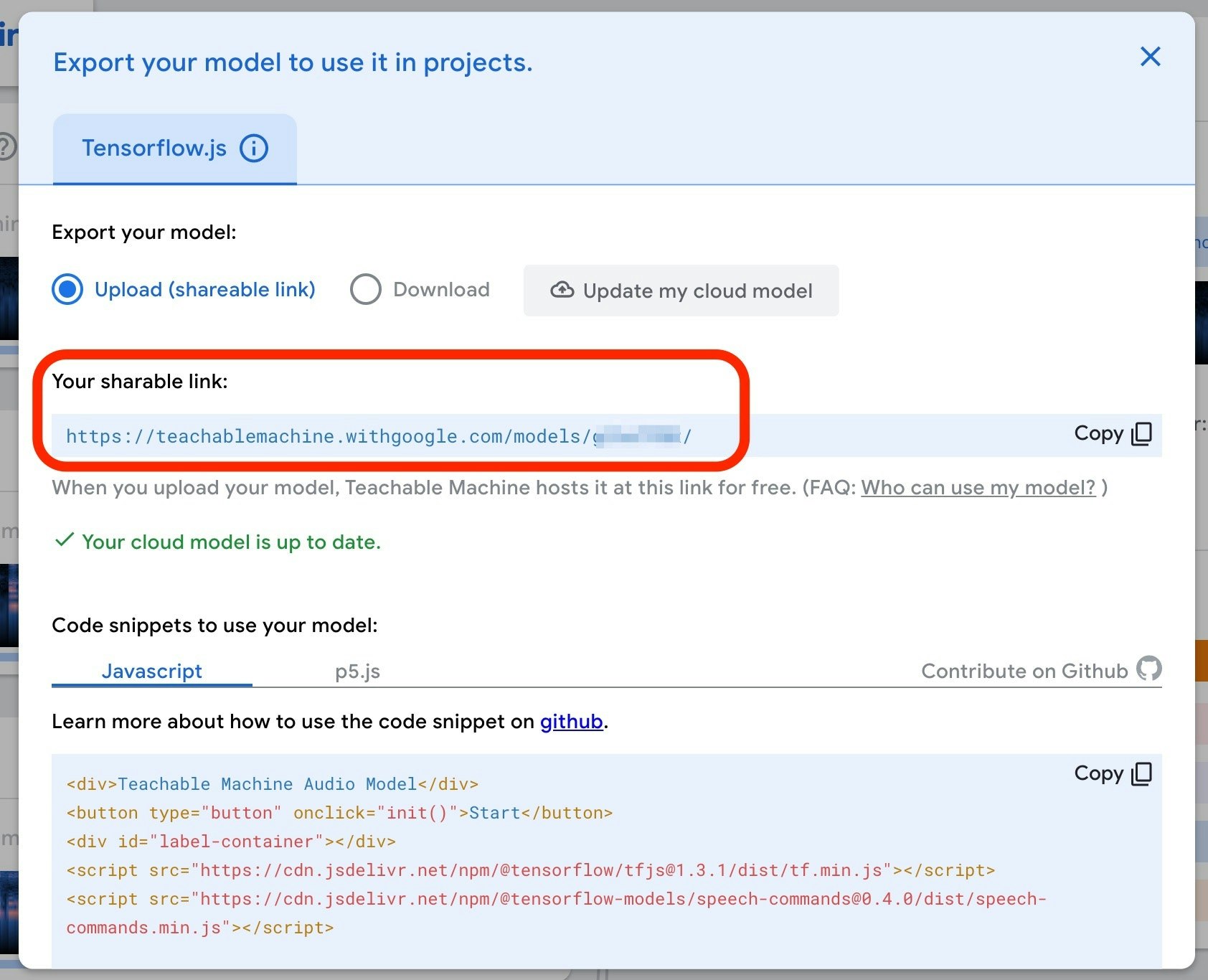
自分は、モデルをダウンロードするパターンも試してみたので、その話も書いておきます。
モデルをダウンロードした後、JavaScript のプログラムで当初は相対パスでの指定を行ったのですが、下記のエラーが出てしまいました・・・。
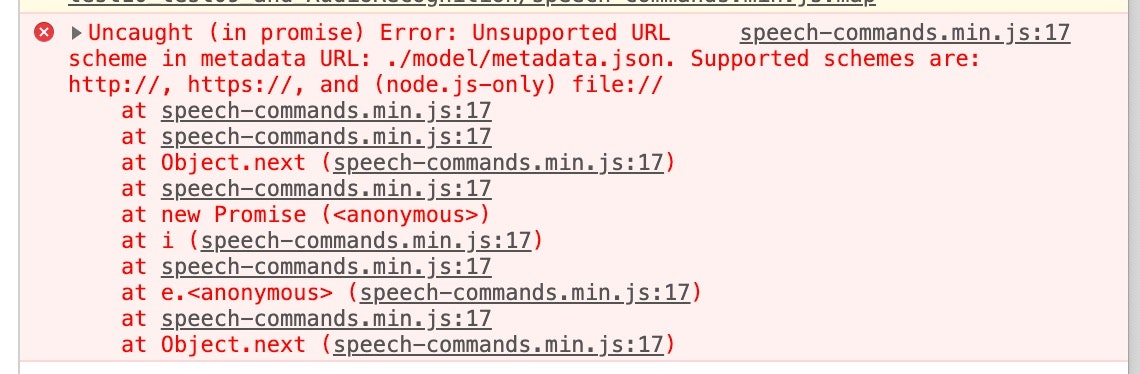
エラーメッセージを読むと、どうやらモデルの置かれたフォルダの指定は「http:// や https:// で始まる絶対パス(node.js の場合のみ file:// で始まる絶対パスも)」を記載する必要があるようです。
ローカルで開発をする場合で、モデルをローカルに置いている場合は、ローカルでサーバを立ち上げて絶対パスで指定するようにしてください(自分はお手軽に行える、ワンライナーでサーバを立ち上げる方法を使いました)。
サンプルを実行すると以下のようなシンプルな画面で、リアルタイムに認識した音が背景雑音かそれ以外の学習させた音かを表すスコアが表示されます。このとき、マイクの利用の許可を求めるポップアップが表示されますので、マイク利用を許可してください。

プログラムを動作せている状態で学習させた音を鳴らすと、表示されているスコアが変わるのが確認できます。
JavaScript のプログラムに toio を動かす処理などを加える
それでは、上記のサンプルにさらに手を加えて、toio を動かすための処理などを加えた下記のプログラムについて、Teachable Machine の処理の周りを説明します。基本的な方針として、元のプログラムはあまり改変せず作業量を最小限にする、という方向で作業しました。
●API_Test/test02_c.html at master · yo-to/API_Test
https://github.com/yo-to/API_Test/blob/master/WebAPI/test10_test09_and_AudioRecognition/test02_c.html
Teachable Machine の処理まわりで手を加えた部分は、基本的に関数「init()」の部分です。
実現したい内容は「特定の音が鳴ったときに toio を動かす処理を実行する」というものです。そのうちの「特定の音が鳴った」ことを特定する処理を加えていきます。
サンプルのプログラムは、一定の時間間隔でスコアを表示しており、下記の 127〜130行目の処理でスコアを更新していました。
for (let i = 0; i < classLabels.length; i++) {
const classPrediction = classLabels[i] + ": " + result.scores[i].toFixed(2);
labelContainer.childNodes[i].innerHTML = classPrediction;
}
この処理の直後に、算出されたスコアが最大のものを見つければ、どの音が鳴ったと推定されるか特定できそうです。具体的には以下のような処理を追加しました。
indexMax = result.scores.indexOf(Math.max(...result.scores)); // スコアが最大のもののインデックスを取得
count += 1;
console.log(indexMax + '番'); // スコアが最大のもののインデックスをデバッグ用に出力
if (count > 0) { // toio を動かす処理を毎回実行するか、X回に1回だけ動作させるようにするかを設定
count = 0;
switch (indexMax) {
case 0:
console.log('0番'); // 背景雑音
break;
case 1:
console.log('1番'); // タンバリンの音
controlMotor(cube1, motor_buf_01);
break;
case 2:
console.log('2番'); // 銀ベルの音
controlMotor(cube2, motor_buf_01);
break;
case 3:
console.log('3番'); // 青白の卓上ベルを普通に鳴らしたとき
controlMotor(cube1, motor_buf_02);
controlMotor(cube2, motor_buf_02);
break;
case 4:
console.log('4番'); // 青白の卓上ベルを連打して鳴らしたとき
controlMotor(cube1, motor_buf_03);
controlMotor(cube2, motor_buf_03);
break;
default:
console.log('default');
}
} else {
;
}
サンプルに実装されていた処理を見ると result.scores にどの音が鳴ったと推定されるかのスコアが格納されているようだったため、 indexMax = result.scores.indexOf(Math.max(...result.scores)); という処理で、スコアの配列の中で最大値となるインデックスを取り出しました。そして、背景雑音と 4つの音の 5つに対応したインデックス(0番から 4番までの 5つのインデックス)のどれであるかによって、 toio を動かすための関数「controlMotor」をパラメータを変えて呼び出しています。
上記のコメントにも書いたとおり「count」という変数は、この switch分で判定する処理を行うタイミングを、元のプログラムに手を入れることなく変更するために使っているものです。上記では、0 になっているので Teachable Machine のサンプルプログラムのスコア更新処理が行われるたびに、追加実装した判定処理が毎回実行されます。
GitHub のソースコードを見ると他にもいろいろ処理が書かれていますが、他の部分は「toio を制御する部分」と「 Web Speech API の SpeechSynthesis インターフェイスを使った音声合成処理を行う部分」になっています。今回は、この部分の説明は割愛します。
おわりに
今回、デモ動画の中の Teachable Machine で作成したモデルを JavaScript で処理し、音の認識を行う部分について記事で説明しました。
Web Bluetooth API を使った toio の制御(+Web Speech API の SpeechSynthesis インターフェイスによる音声合成処理)については説明を割愛しましたが、別途、それらについて説明した記事とを書ければと思います。
【2020/2/16 追記】 作った作品を試してもらって
2/15・16(土・日)に開催されたつくばのミニメーカーフェアで下記のブースで出展をして、こちらの作品を来場者の方に体験していただきました。
●toio™で作ってみた!友の会 – Tsukuba Mini Maker Faire 2020
小さい子でも楽しめる・子ども達が触りたくなる、というのを考えて作ったつもりではあるものの、試してもらうまでどんな反応が返ってくるかはドキドキでした。
最終的に、想定したよりも低年齢のお子さんから、大人の方までたくさんの方に楽しんでいただけました!(休みをとる暇がないくらいにw)
#TMMF2020 の1日目の振り返り(自分の作品を体験してもらったときの様子を見返したり、今日の展示のやり方を考えたり)をしてたら、来場していただいた方の様子を見て元気をもらえた!
— you (@youtoy) February 15, 2020
今日も M-01-08 の
toio™で作ってみた!友の会のブースです!
https://t.co/rn6NKOSJnN#toio #toiotomo pic.twitter.com/XUqmmMyaKY
#TMMF2020 の2日目も、昨日に引き続き、たくさんの方に体験いただけてます!
— you (@youtoy) February 16, 2020
また、小さい子にも使ってもらえるようにと考えて作品を作ったものの、試してもらうまではドキドキで、
そして、実際楽しんでもらえる様子をたくさん見られると、とても嬉しくなります。#toio #toiotomo pic.twitter.com/6stehxKcNc
また、展示ブースでの様子をツイートいただいていました。
GoogleのTeachable Machineを使ってベルやタンバリン等の音を機械学習してtoioを動かしてる。#youtoy #toio#TMMF2020 #teachablemachine pic.twitter.com/aat12tGcDe
— ロボ先輩@3rd Factory (@3rd_factory_ro) February 16, 2020
【2020/2/25 追記】 同じ楽器で音階違いのもの
先日、Tsukuba Mini Maker Faire 2020 の展示作品で使って、仕組みを記事にしていた、音で #toio を操作するやつ、
— you (@youtoy) February 24, 2020
その別バージョンで同じ楽器の音階違いでも似たことが実現できるか、試した動画です。
音階違いの音の機械学習、普通にできてしまいました。
https://t.co/AAJDyHgLk3#toiotomo pic.twitter.com/Szxa8gs0YL
【2020/10/7 追記】 音と声を混在させて利用 & Maker Faire Tokyo 2020 への出展
10/3・4(土・日)に toio のコミュニティで Maker Faire Tokyo 2020 に出展して、その際に Teachable Machine を使った作品も展示の 1つに加えてました。
#MFTokyo2020 の #toiotomo のブースでは、実際の作品をいくつか展示しつつ、コミュニティメンバーの作品の動画展示も合わせて行う予定なのですが、
— you (@youtoy) September 30, 2020
その動画展示に関して自分も動画を出すために、過去の作品のいくつかを60秒くらいにまとめてみました。https://t.co/BESQ1qTy7n#toio pic.twitter.com/wb4wZMWJBt
#MFTokyo2020 の初日の会場にて、音の機械学習をやり直したら(会場のノイズ込みの学習データになるようにしたら)、
— you (@youtoy) October 4, 2020
2日目の会場では、昨日と別物であるかのように良い感じに動くようになった!#toio #toiotomo https://t.co/ejcn43IjIe pic.twitter.com/vXpTSq3Sd6
青いベルの音と緑のベルの音を機械学習で判別。地味に難しいことやってる#MFTokyo2020 #toio pic.twitter.com/fpqogGMZ5w
— ロボ先輩@3rd Factory (@3rd_factory_ro) October 4, 2020