はじめに
この記事は、LM Studio を使ったローカルLLM に関する話です。
具体的には、届いたばかりの以下の MacBook Pro でローカルLLM をやるのに、この MacBook Pro で扱える今時点のモデルの情報を見てみた、というものです。モデルの情報元は LM Studio公式のページを見てみることにします。
これまでのローカルLLM で使っている PC
ちなみにローカルLLM はこれまでもやっていて、それらの VRAM は以下となっていました。今回の MacBook Pro はユニファイドメモリ 32GB のうち VRAM 24GBほどとなりそうです。
- Mac mini(M4チップ搭載モデル、メモリ 24GB): 16GB
- MacBook Air(M4チップ搭載モデル、メモリ 16GB): 8GB
- GMKtec EVO-X2(Ryzen AI Max+ 395・メモリ128GB搭載): 64GB や 96GB
モデルの情報を見ていく
上で書いたように、LM Studio公式のページでモデル情報を見ていきます。具体的には、以下のページです。
●Model Catalog - LM Studio
https://lmstudio.ai/models
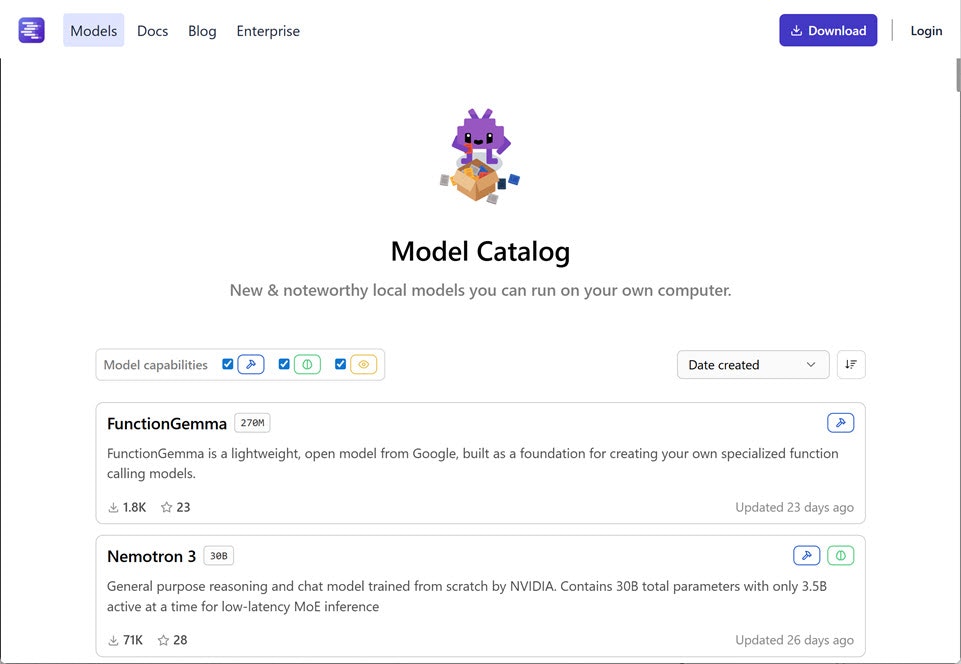
とりあえず、記事執筆時点での最新のものから見ていき、個人的に気になるモデルを列挙していきます。VRAM 24GB におさまるもので見ていきます。
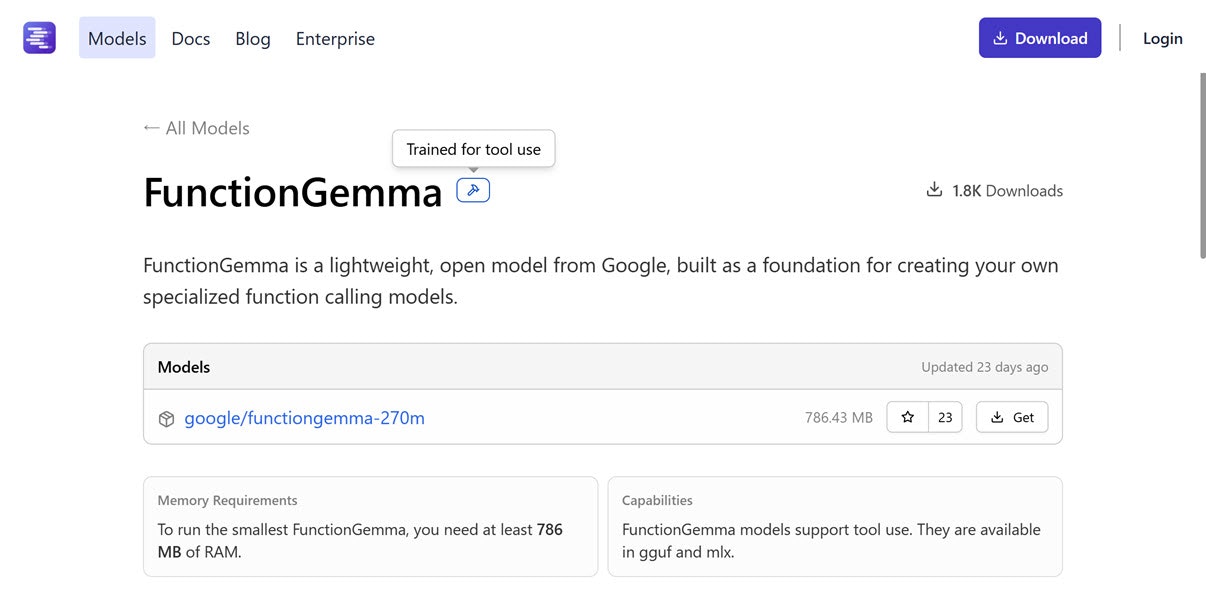
FunctionGemma: 786 MB以上の RAM、tool use対応
1つ目は、超軽量モデルで tool use/function calling にも対応したモデルです。パラメータ数は 270M です。
VRAM関連の部分で、以下のページの「Memory Requirements」という部分を見ると「To run the smallest FunctionGemma, you need at least 786 MB of RAM.」という内容が書かれています。
●functiongemma
https://lmstudio.ai/models/functiongemma
ちなみに直近で、VRAM 8GB の MacBook Air で試して、以下の記事を書いたりもしています。
- ローカルLLM: FunctionGemma + LM Studio の Tool Use を OpenAI Agents SDK(Node.js)で試す - Qiita
- ローカルLLM: FunctionGemma + LM Studio の Tool Use を Node.js で試す - Qiita
gpt-oss-safeguard-20b: 12 GB以上の RAM、tool use・reasoning対応
次は OpenAI の gpt-oss-safeguard の 20b のほうで(もう1つ 120b のものもあります)、必要な RAM などは以下となっています。
- パラメータ数: 20B
- 必要な RAM: 12 GB以上
- 対応機能
- tool use
- reasoning
●gpt-oss-safeguard
https://lmstudio.ai/models/gpt-oss-safeguard
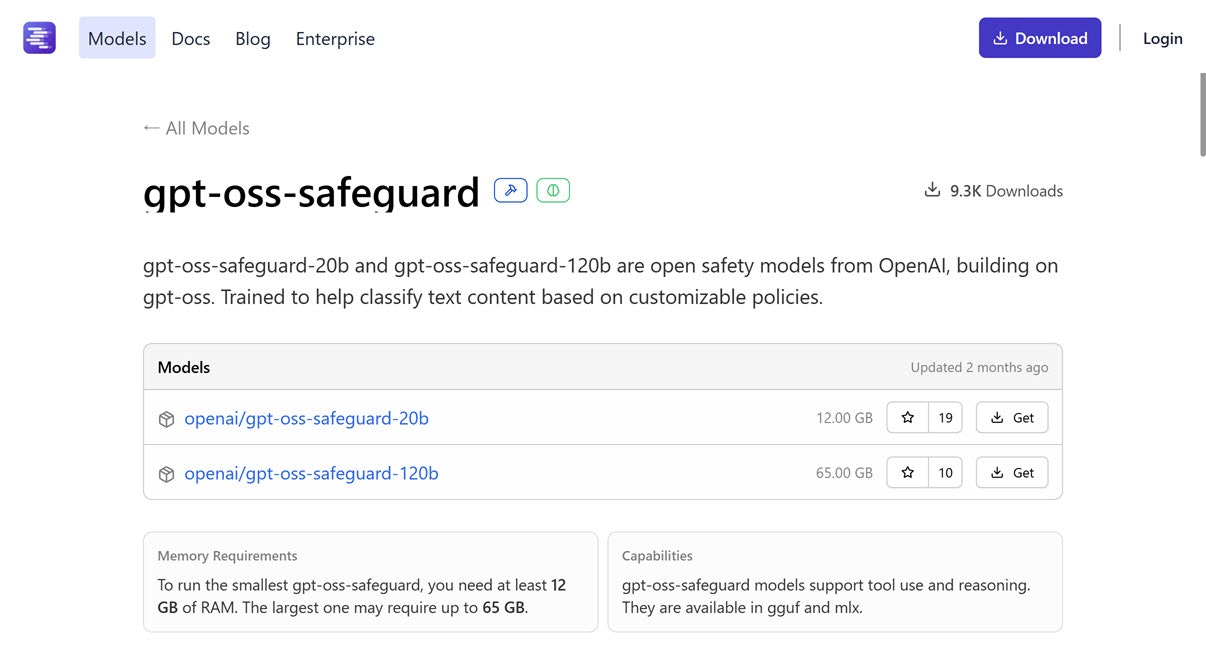
公式で「カスタムの安全性ポリシーに対応可能な安全性に関する新しいオープンリーズニングモデル(120b および 20b)」と書かれているモデルです。
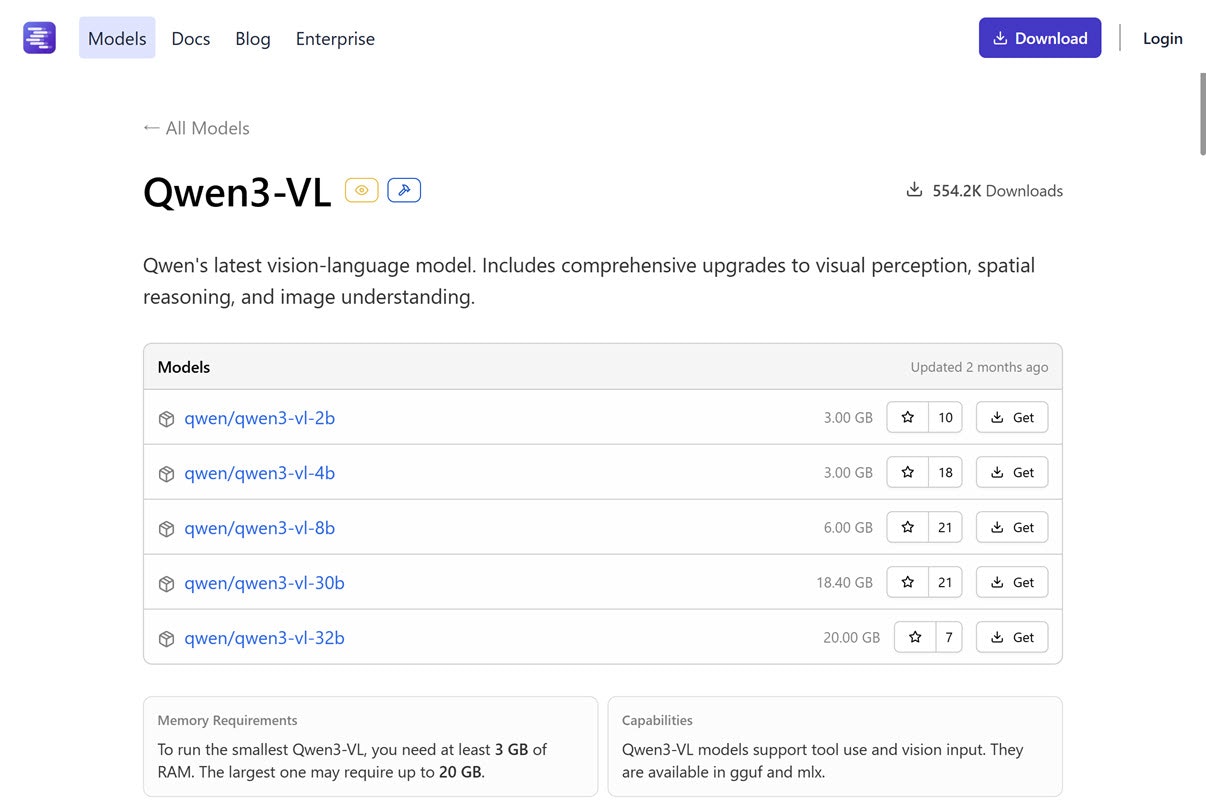
Qwen3-VL(2B~32B): 3 GB以上 ~ 20 GB以上の RAM、tool use・画像入力対応
次は Qwen3系で画像入力に対応したモデル「Qwen3-VL」です。tool use にも対応しています。
- 対応機能
- tool use
- 画像入力
パラメータ数違いのものがいくつかあり、VRAM 24GB で動かせるものは以下となるようです。
- パラメータ数: 2B
- 必要な RAM: 3 GB以上
- パラメータ数: 4B
- 必要な RAM: 3 GB以上
- パラメータ数: 8B
- 必要な RAM: 6 GB以上
- パラメータ数: 30B
- 必要な RAM: 18.40 GB以上
- パラメータ数: 32B
- 必要な RAM: 20 GB以上
●Qwen3-VL
https://lmstudio.ai/models/qwen3-vl
Qwen3(4B~30B): 2.3 GB以上 ~ 17.40 GB以上の RAM、tool use・reasoning対応
次も Qwen3系で「Qwen3」です。tool use にも対応していて、reasoning対応のモデルもあります。
- 対応機能
- tool use
- reasoning(※ モデル名に thinking がついているもの)
パラメータ数違いのものがいくつかあり、VRAM 24GB で動かせるものは以下となるようです。
- パラメータ数: 4B
- 必要な RAM: 2.3 GB以上
- パラメータ数: 30B
- 必要な RAM: 17.40 GB以上
●Qwen3
https://lmstudio.ai/models/qwen3
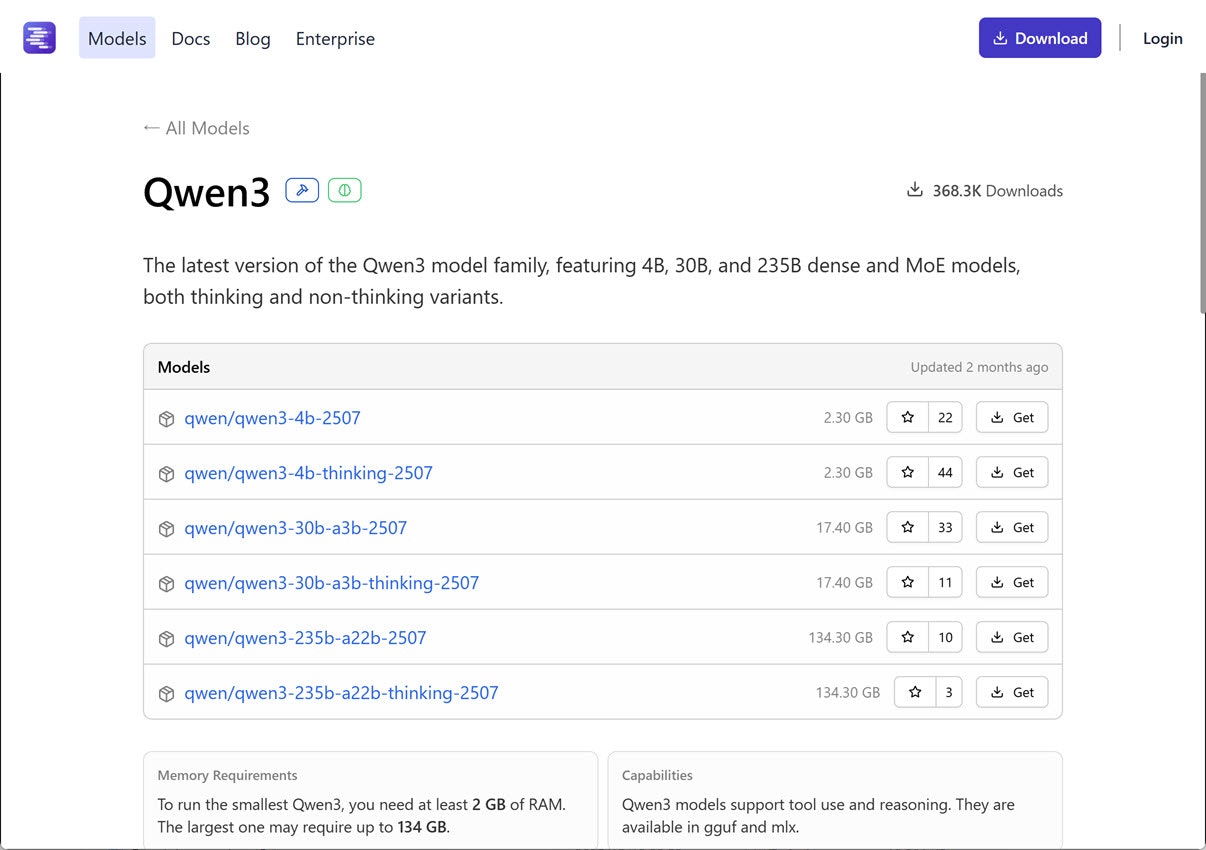
gpt-oss-20b: 12 GB以上の RAM、tool use・reasoning対応
次は OpenAI の gpt-oss の 20b のほうで(もう1つ 120b のものもあります)、必要な RAM などは以下となっています。
- パラメータ数: 20B
- 必要な RAM: 12 GB以上
- 対応機能
- tool use
- reasoning
●gpt-oss
https://lmstudio.ai/models/gpt-oss
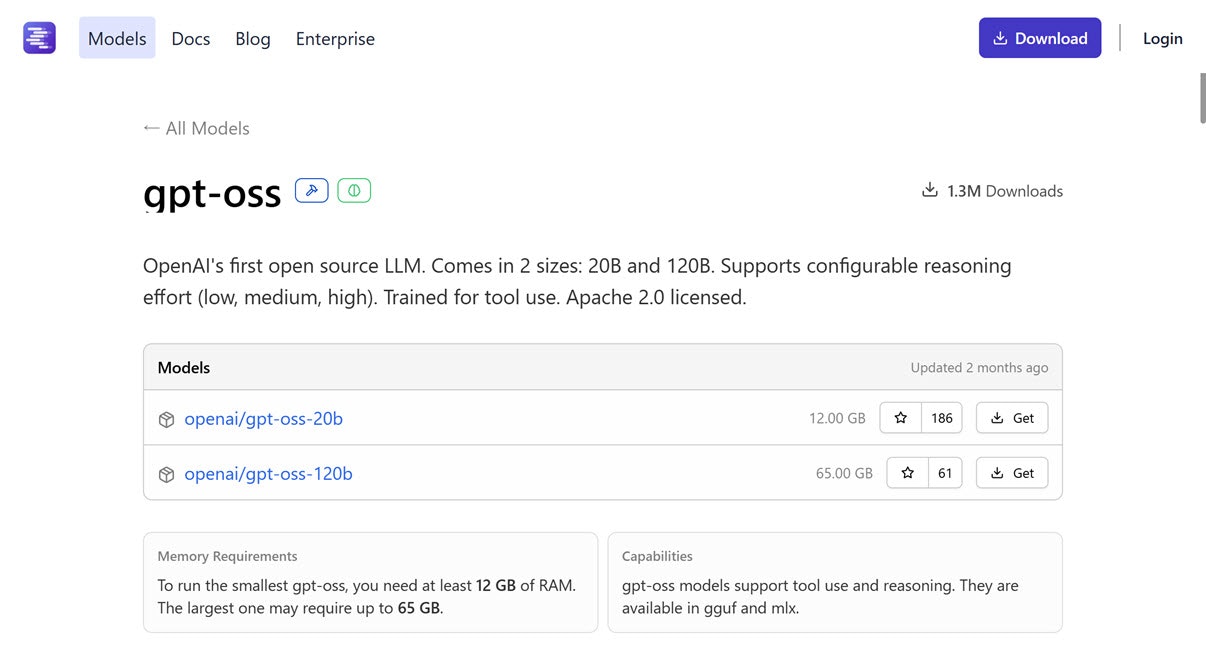
gemma-3n(e2b、e4b): 2.95 GB以上・4.24 GB以上の RAM、画像入力対応
次は Googleさんの Gemma系のモデル「gemma-3n」です。画像入力に対応しています。
- 対応機能
- 画像入力
e2b、e4b の 2種類があり、どちらも VRAM 24GB で動かせます。
- e2b、e4b
- 必要な RAM: 2.95 GB以上
- e2b、e4b
- 必要な RAM: 4.24 GB以上
●gemma-3n
https://lmstudio.ai/models/gemma-3n
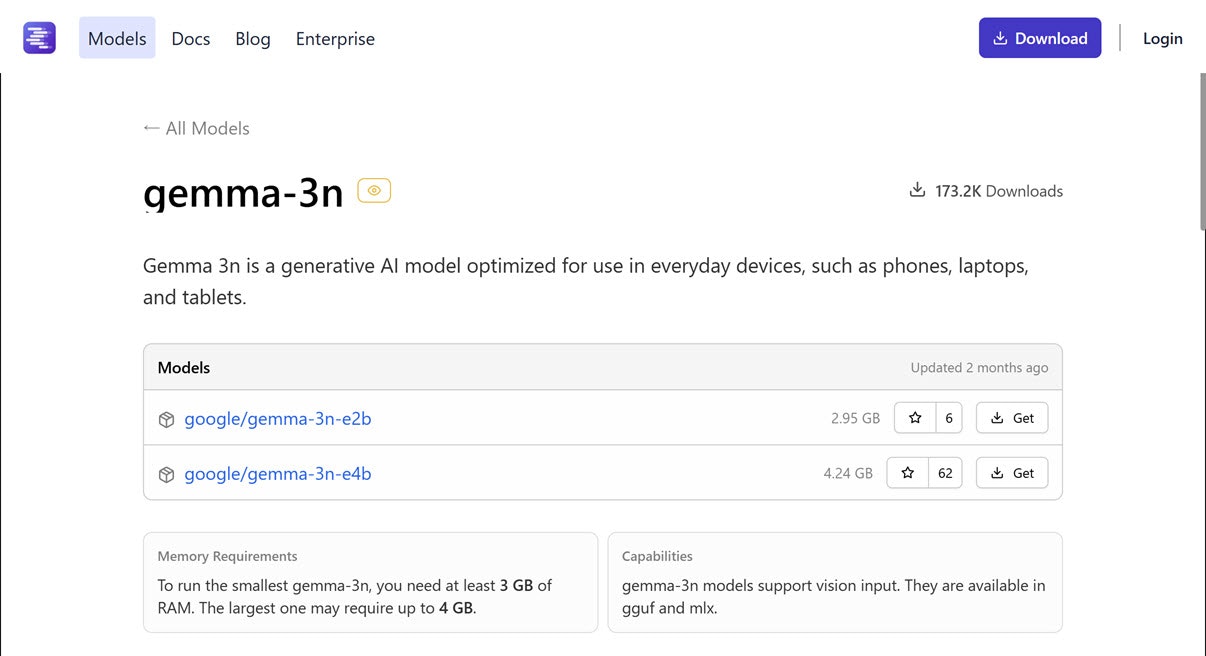
gemma-3(270M ~ 27B): 550 MB以上~ 15.60 GB以上の RAM、tool use・画像入力対応
次も Googleさんの Gemma系のモデル「gemma-3」です。画像入力・tool use に対応しています。
- 対応機能
- tool use
- 画像入力
パラメータ数違いのものがあり、全て VRAM 24GB で動かせそうです。
- パラメータ数: 270M
- 必要な RAM: 550 MB以上
- パラメータ数: 1B
- 必要な RAM: 754.97 MB以上
- パラメータ数: 4B
- 必要な RAM: 2.4 GB以上
- パラメータ数: 12B
- 必要な RAM: 10.74 GB以上
- パラメータ数: 27B
- 必要な RAM: 15.6 GB以上
●gemma-3
https://lmstudio.ai/models/gemma-3
おわりに
今回、LM Studio公式のモデルカタログで、VRAM 24GB あれば動くモデルで自分が気になるものをいくつか、ざっくりと見ていきました。
既に所有していた PC で試して記事を書いたものが大半でしたが、今回の VRAM 24GB で動くサイズのもので、試していないパラメータ数のものもあるので、それらを試せればと思っています。
また、今回は LM Studio公式のモデルカタログを見ましたが、別途 Hugging Face の LM Studio Community のモデルも見ていければと思っています。
モデルのお試しについて
とりあえず VRAM 24GB の PC に、以下のモデルをダウンロードしようと思いました。
- Qwen3-VL の 30B(qwen3-vl-30b)
- Qwen3 の 30(qwen3-30b-a3b-2507、qwen/qwen3-30b-a3b-thinking-2507)
- gpt-oss の 20b
- gemma-3n の e4b
- gemma-3 の 27B
各モデルのページへのリンク
●Qwen3-VL • LM Studio
https://lmstudio.ai/models/qwen/qwen3-vl-30b
●qwen/qwen3-30b-a3b-2507 • LM Studio
https://lmstudio.ai/models/qwen/qwen3-30b-a3b-2507
●qwen/qwen3-30b-a3b-thinking-2507 • LM Studio
https://lmstudio.ai/models/qwen/qwen3-30b-a3b-thinking-2507
●gpt-oss • LM Studio
https://lmstudio.ai/models/openai/gpt-oss-20b
●gemma 3n • LM Studio
https://lmstudio.ai/models/google/gemma-3n-e4b
●google/gemma-3-27b • LM Studio
https://lmstudio.ai/models/google/gemma-3-27b
【追記】 エラーの対処について
この記事を書いた時点では、MLX版のモデルを M5チップ搭載モデルの Mac で扱うとエラーが出る状況でした。そのエラーへの対処法について、以下の記事を書きました。
●M5チップ搭載モデルの Mac で LM Studio の MLX版モデルを使った時のエラーを解決(M5用のランタイム利用)【2026/1/12時点】 - Qiita
https://qiita.com/youtoy/items/f4f11c849008c4d4b651