【追記】 「後編の記事」も書きました。
はじめに(+余談)
以前、スマホアプリをビジュアルプログラミングで開発できないか調べた時や、ビジュアルプログラミングで BLE を扱う方法を調べた際に出てきて、軽く試したことはあったものの本格的には使っておらず、そのまま数年レベル以上の時間が経過していた状態だった「MIT App Inventor(以下、App Inventor と記載)」。
ブロックベースのビジュアルプログラミングを使って様々な機能を使った Androidアプリを開発できたり、作ったものは apkファイルとして出力できたりと、魅力的な仕組みをもつものです。過去に Java+Eclipse/Android Studio を使った Androidアプリ開発は少しだけやったことがあったのですが、その時に割と実装が面倒だった機能も App Inventor だと手軽に実装できそうな感じでした。
冒頭に書いたBLE関連の話に関しては、過去に以下の Qiitaの記事にたどり着いたりしたことがあったのですが、こちらの記事では BLE通信が可能なマイコンボードと Androidスマホとの無線通信を実現できていたりします。
●Nefry BTとMIT App InventorをつかったandroidアプリとのBLE通信をやってみた話 - Qiita
https://qiita.com/minwinmin/items/4123a05ee7a15c1d426c
また、App Inventor に関して元のものは英語で提供されていますが、日本語化のプロジェクトもあったりするようです(この記事では、元の英語版のほうを使っていきます)。
●MIT App Inventor 2 日本語化プロジェクト | 簡単に本格的スマホアプリを作れます
https://appinventor.tmsoftwareinc.com/
(余談ですが、同じようなビジュアルプログラミングによるスマホアプリ開発を行うことが可能なもので、iOSアプリ開発ができるものに「Thunkable」というものもあったります)
この記事では、App Inventor を使って音の機械学習を利用する Androidアプリを作るための準備を行います。
具体的にはWebサイト上で音の機械学習を行って学習モデルを作り、その学習モデルのダウンロードを行うところまで進めます。その学習モデルを使う Androidアプリの開発の話は続きの別記事を書く予定です。
音の機械学習を使った事例(JavaScript を利用)
以前、Googleさんが提供する Teachable Machine を使って音の機械学習を行い、その学習モデルを活用した音によるロボットトイ(toio)の制御を作ったことがあり、Maker Faire での作品展示を行ったりしたことがありました。
さらにもう1作品、機械学習 Teachable Machine と開発者向けマット(仮)の組み合わせです。
— you (@youtoy) May 17, 2020
音や声で 2台の #toio を操作します。
卓上ベル、「追跡開始」の人声、ハンドベルの音、そして、踏切の音で
toio が動き出したり、追跡が始まったり、止まったりします。#おうちでロボット開発 #toiotomo pic.twitter.com/rTWwueY9ZN
この作品を作った過程の話は、Qiita で複数の記事に書いていたりします(以下はその一例です)。
- toio を音で制御してみた(Audio用の Teachable Machine でベルやタンバリンの音を機械学習) - Qiita
- Teachable Machine を使った音声からの任意のキーワードの検出(ブラウザ上で機械学習) - Qiita
この時は、学習モデルを使う機械学習の推論の処理・toio の制御のプログラムは JavaScript(Web Bluetooth API等を利用)を使って書いていました。
App Inventor で音の機械学習
機械学習に関するガイド・チュートリアル
App Inventor のメニューを見ていると、以下のように「AI with App Inventor」という項目があります。
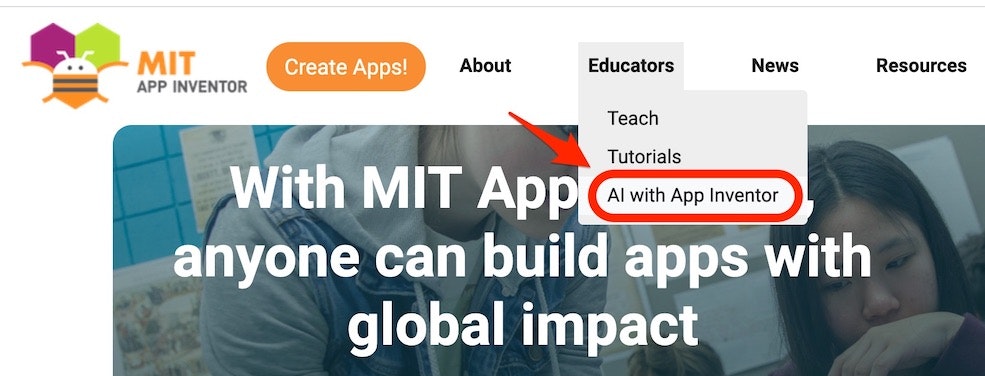
このページを見ると「画像を対象とした学習モデルの作成から推論までを行う Image Classification(画像分類)」、「画像ではなく音を対象としたもの」といった、学習済みモデルを使った機械学習ではなく、自分で学習モデルを作って推論を行う機械学習を行うガイド・チュートリアルもあります。
今回は、その中の音を対象にした機械学習に関するものを試していきます。
●Personal Audio Classifier
https://appinventor.mit.edu/explore/resources/ai/personal-audio-classifier
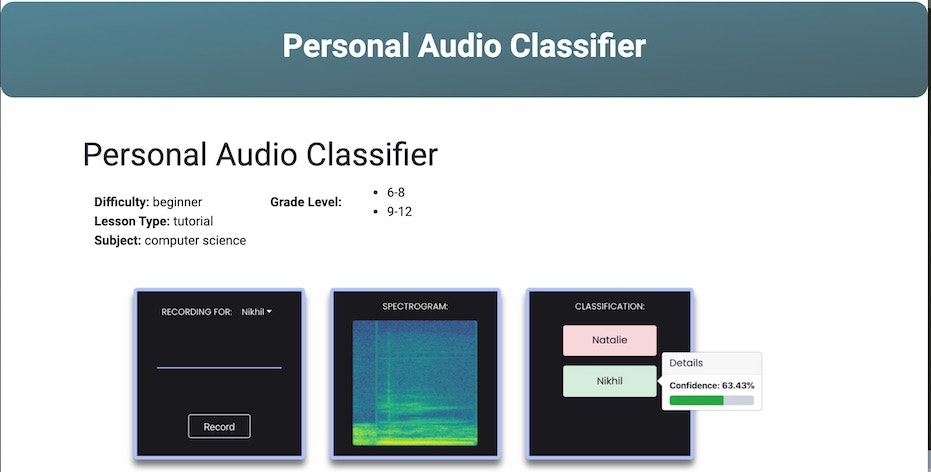
おおまかな手順
こちらのチュートアリルの進め方を見てみると、以下の手順で進めていくようでした。
- オンラインでの学習モデルの作成
- 学習モデルのダウンロード
- ダウンロードした学習モデルを組み込んだ Androidアプリの開発
こちらを進める前に、自分が持っている Androidデバイスで動作確認を行うためのアプリのファイル(apkファイル)が用意されているようだったので、その話に触れておきます。「Voice Authentication Diary Tutorial」というリンクの先の PDFファイルに、以下のような説明・リンクが記載されたページがありました。

この中の「link」から apkファイルをダウンロードし、Androidデバイスにインストールして動作確認が行えるようです。アプリを起動して「Waiting...」と表示がされた後、この表示内容が「Ready and working!」という表示になれば、チュートリアルで作る音の機械学習を使ったアプリが動くということのようです。
音の機械学習を行う
学習データの準備(録音)
チュートリアルの内容を見てみると、音の機械学習は以下の URL のページで行えるようです。
https://c1.appinventor.mit.edu/
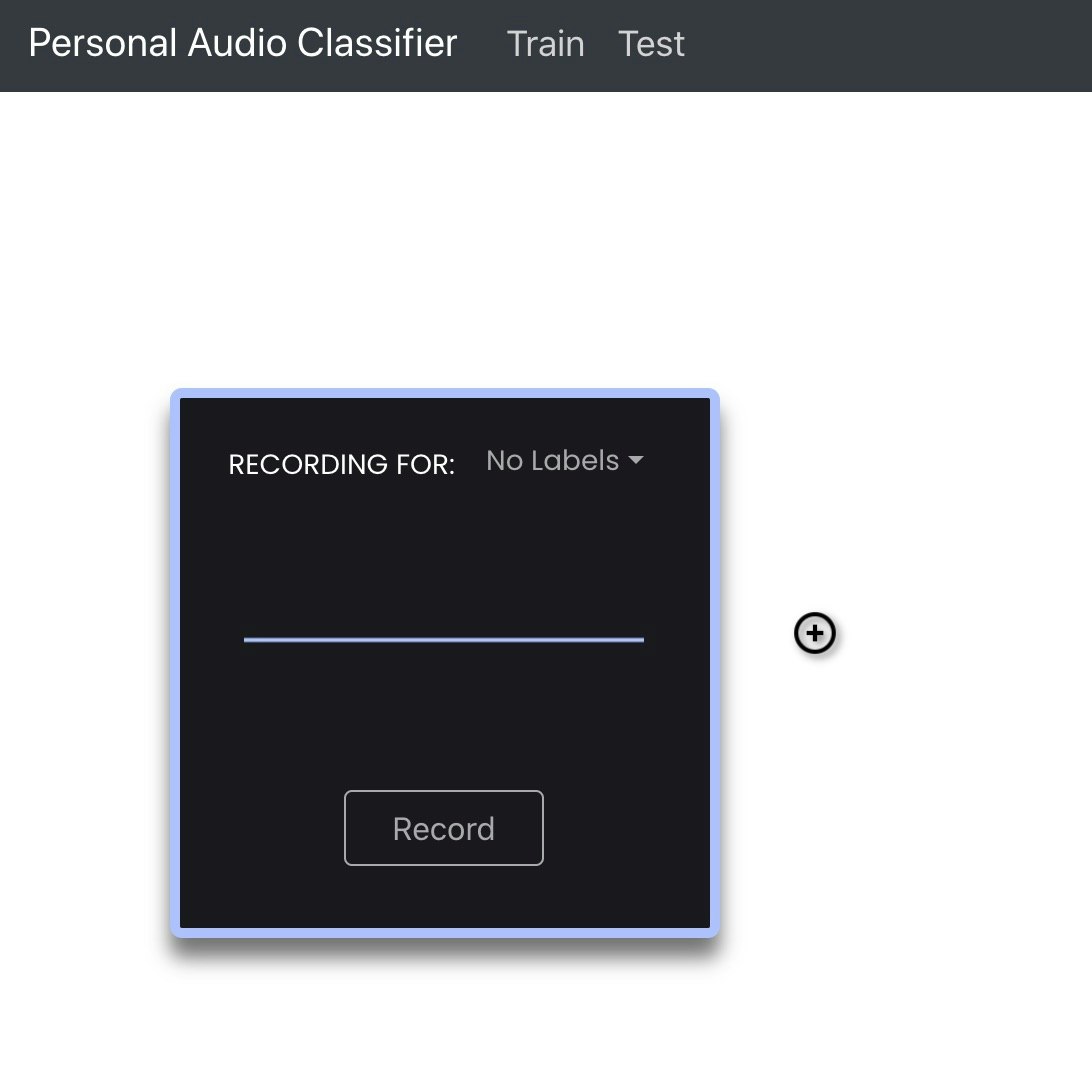
チュートリアルでは、複数の人物の声を学習させる内容になっていましたが、自分はしゃべる内容を変えたものを覚えさせてみることにします。覚えさせる内容は「おはよう、こんにちは、こんばんは」の 3つにしてみようと思います。
学習させる際は、覚えさせる内容に対応する名前(ラベル)を入力し、その後にそれらのラベルに対応する音の録音を行えば良いようです。ラベルの入力は、以下の赤い矢印で示したアイコンを押し、緑の枠・矢印で示したテキストボックスにテキストを入れれば良いようです(テキストを入力したら、Enterキーで内容確定)。
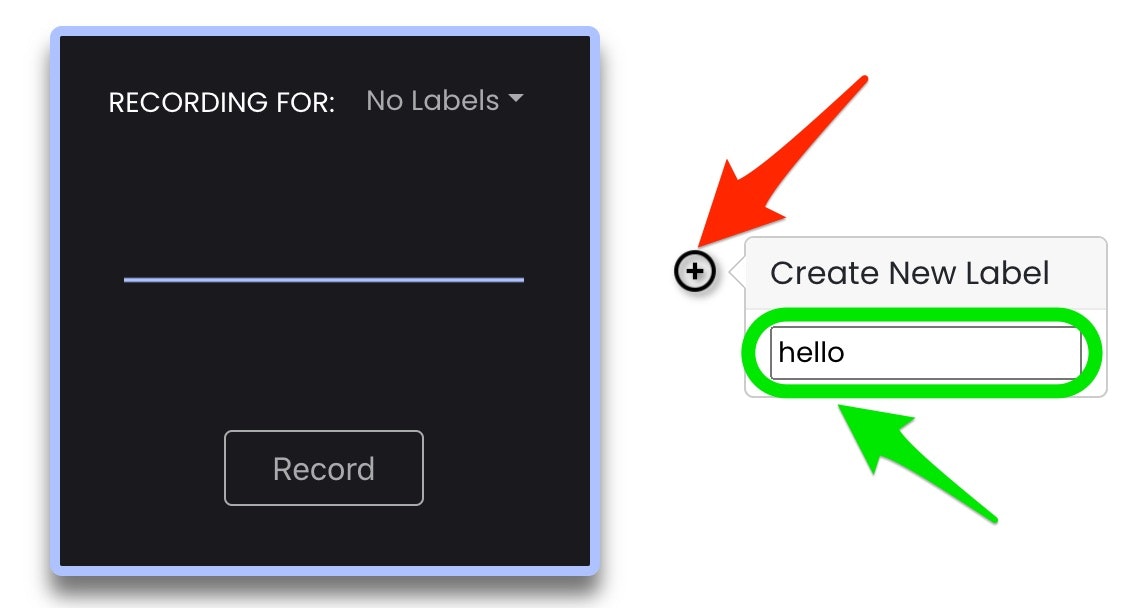
とりあえず「hello、good morning、good evening」の 3つのラベルを設定しました。
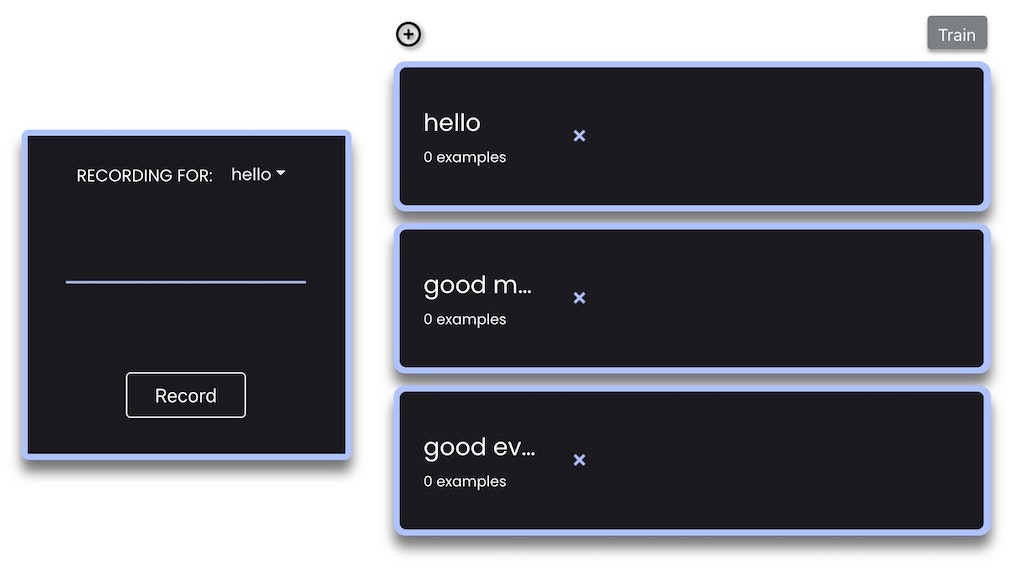
音を学習させるために録音をする際は、以下の赤い枠・矢印で示した部分でラベルを選択し、その後に緑の枠・矢印で示した「Record」ボタンを押して、覚えさせたい音をマイクに入力すれば良さそうです。
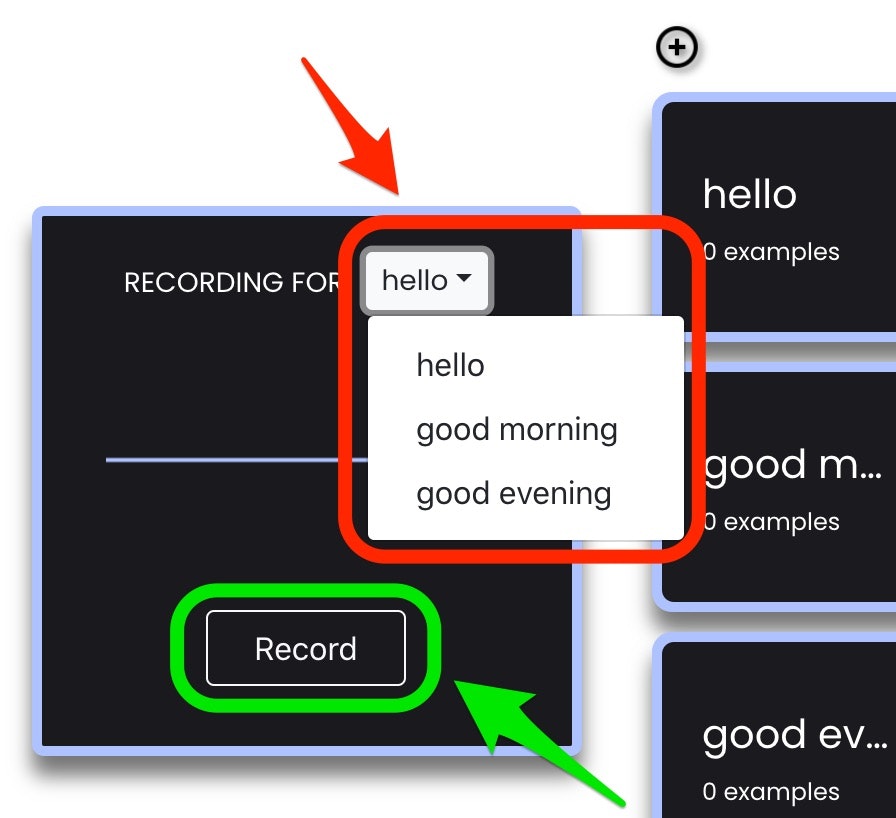
「Record」ボタンを押した際に、ブラウザ上でマイク利用の許可を確認するダイアログが出てきた際には、許可するようにしてください。その後、「Record」ボタンを押すと一定時間の録音が行われる状態になるようです。
録音されている状態の時には、以下の赤い矢印で示した部分のボタンが赤くなり、ボタンの下で赤いバーが横に伸びていきます。
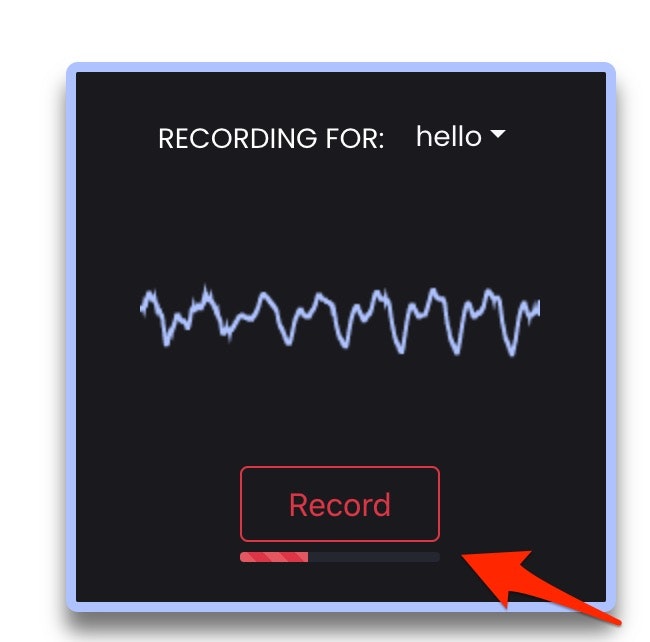
3つ設定したラベルの中の「hello」が選ばれている状態で、試しに「こんにちは」と録音中にしゃべってみるのを、8回行ってみました。その時の様子は以下のとおりで、赤い枠・矢印で示した部分が録音されたデータを示しています。
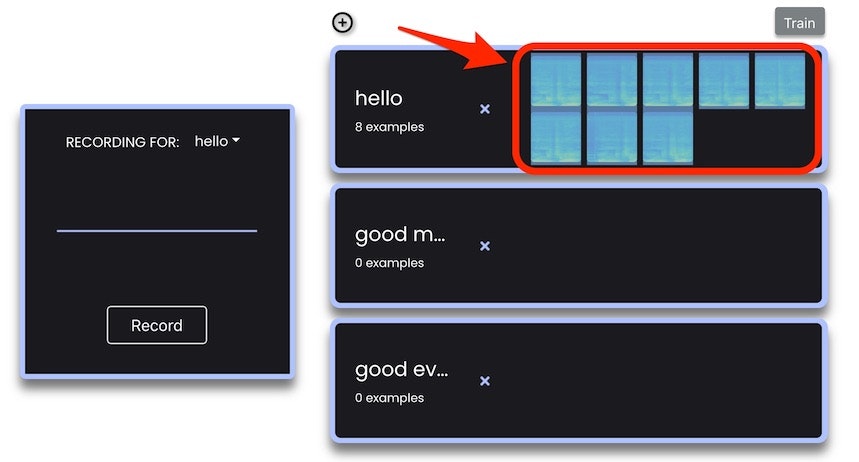
この録音された音は手動で削除もできるようです。この録音された音を示す部分の上にマウスカーソルを合わせると、以下の画像の赤い矢印で示したように薄くバツ印が表示されます。このバツ印をクリックすることで、特定の録音データが削除できます。

この録音を行う際に何回録音させれば良いかという話について、チュートリアルに以下の記載がありました。

1つのラベルに対して、5〜10個の録音データがあれば良いようです。
他の 2種類のラベルに関しても「good morning: おはよう、good evening: こんばんは」という対応関係になるよう、ラベルを選択して録音を行ってみました。
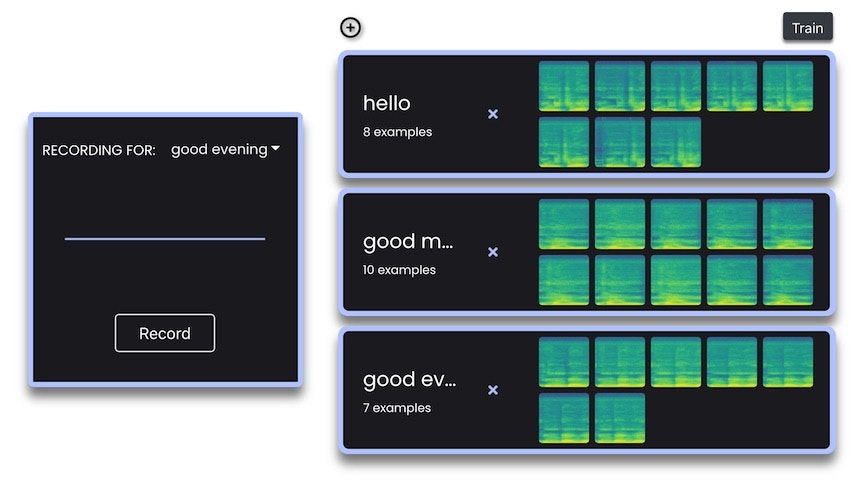
「おはよう」は 10個分、「こんばんは」は 7個分と、録音した個数は 5〜10個の範囲に含まれる回数で適当にやってみました。
学習モデルの作成(トレーニング)・簡単なお試し・データのダウンロード
学習用のデータがそろったら、画面右上の「Train」ボタンを押してトレーニング(学習)を開始させます。
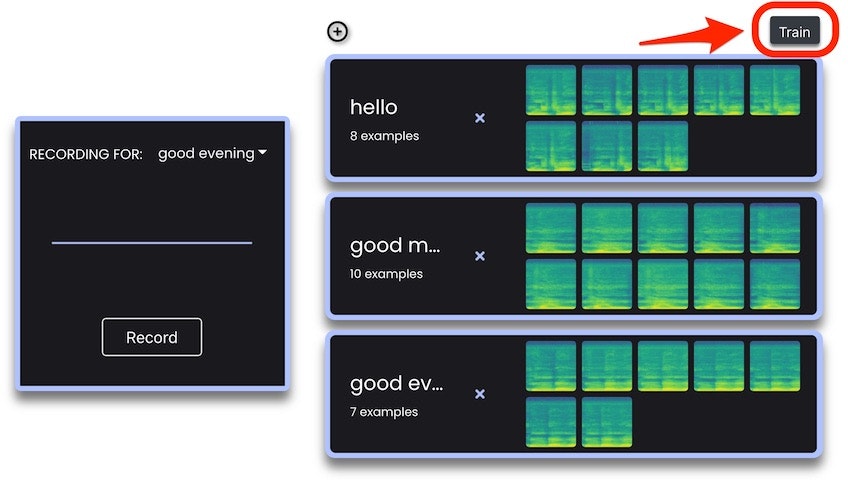
ボタンを押すと以下のような画面が出てきますが、設定内容は変更せずデフォルトのままで実行してみます。画面の中の「Train Model」と書かれたボタンを押します。
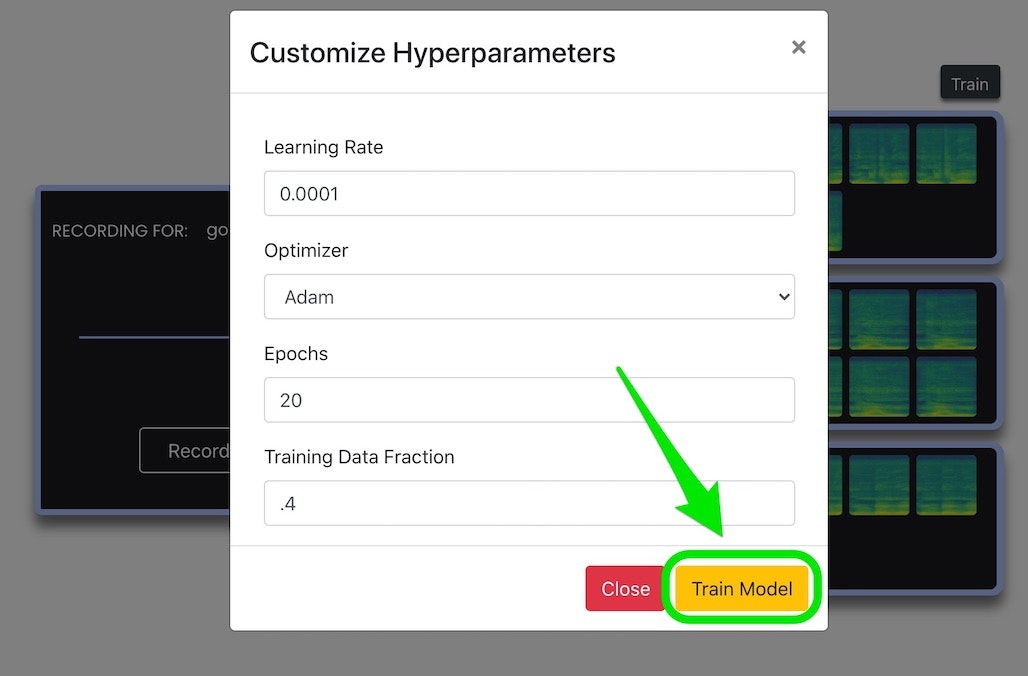
その後、しばらく待つと以下のような画面になりました。この画面の左のほうにある「Record」ボタンを押して、先ほどまでと同じように録音をすると、その音が 3つの種類のうちどの音かを判別してくれるようです。

以下は、「Record」ボタンを押した後に「こんにちは」としゃべった結果の画面です。
画面の右のほうで「hello」の部分が緑色になっていますが、「helloのラベルの内容 = こんにちは」と認識されたようです。この赤や緑になっているラベルの上にマウスカーソルを持っていくと、確信度が表示されます(以下の事例では、82.2% の確信度となっているようです)。
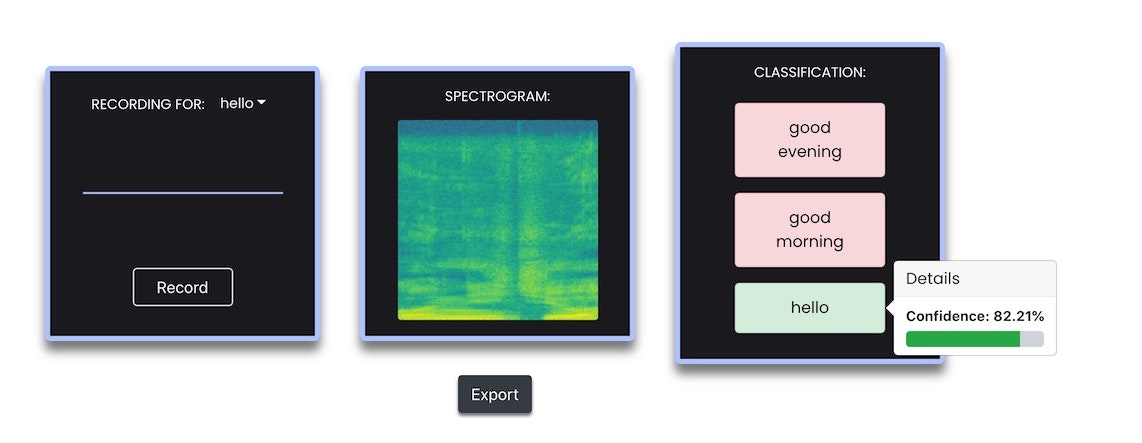
あとは、以下の赤い矢印で示した「Exportボタン」を押すことで、先ほど行った音の学習によって作成された学習モデルをダウンロードできます。適当な名前をつけて、保存をしてください。
終わりに
今回、Webサイト上での音の機械学習を行いました。
具体的には、自分の声で「おはよう、こんにちは、こんばんは」としゃべったものを学習させ、音の学習を行ったサイト上でしゃべった内容の識別(推論)も試しました。
この後は、今回ダウンロードした機械学習の学習モデルを使った Androidアプリを作っていくのですが、それは別の記事に分けて書いていこうと思います。
追記
その後、Androidアプリを作ることができ、この記事で作成した学習モデルを使った音声の識別を行うことができました。
ビジュアルプログラミングでAndroidアプリ開発ができる MIT App Inventorで音声の機械学習!
— you (@youtoy) February 21, 2021
「おはよう・こんにちは・こんばんは」の3つを事前に学習させ、その学習モデルを組み込んだAndroidアプリをスマホ上で動かしました。
3つの挨拶を機械学習で認識し、音声合成で同じ挨拶を返す仕組みです。 pic.twitter.com/IO8X1EqAnJ
さらに追記
後編の記事を書いて公開しました。
●ビジュアルプログラミングの MIT App Inventor を用いた音の機械学習を利用する Androidアプリ開発【後編:アプリ実装】 - Qiita
https://qiita.com/youtoy/items/b241809c93e8fcef0e26