はじめに
この記事は、以下の記事の続きの内容になります。
●ビジュアルプログラミングの MIT App Inventor を用いた音の機械学習を利用する Androidアプリ開発【前編:学習モデルの準備】 - Qiita
https://qiita.com/youtoy/items/322fc193700bcc4df566
ブロックベースのビジュアルプログラミングを用いて様々な機能を使った Androidアプリを開発できる「MIT App Inventor(以下、App Inventor と記載)」を使い、音の機械学習を組み込んだ Androidアプリを作る話です。
上記の記事では、Webサイト上で音を録音し、学習モデルを作成&ダウンロードするところまでの話を書きました。今回の内容は、それを使った Androidアプリの開発の話です。
完成したアプリが動作している様子
このアプリが完成して動作している様子を以下に掲載します。
ツイートの文章で書いているように、「おはよう・こんにちは・こんばんは」の 3つを認識する学習モデル(※ 前回の記事の中で作ったもの)を使って 音声の識別(3クラスの分類)を行い、その 3つの挨拶のどれが識別されたかによって音声合成での返答内容が変わる(※ 同じ挨拶を返すようになっている)というものです。
ビジュアルプログラミングでAndroidアプリ開発ができる MIT App Inventorで音声の機械学習!
— you (@youtoy) February 21, 2021
「おはよう・こんにちは・こんばんは」の3つを事前に学習させ、その学習モデルを組み込んだAndroidアプリをスマホ上で動かしました。
3つの挨拶を機械学習で認識し、音声合成で同じ挨拶を返す仕組みです。 pic.twitter.com/IO8X1EqAnJ
App Inventor のサンプルプロジェクトと組み合わせる
サンプルプロジェクトの取り込み(インポート)
前回の記事でも登場していた公式チュートリアルの PDF に、前回の記事で作った学習モデルを使う仕組みが組み込まれたサンプルプロジェクトのリンクが書かれています。
以下の赤い枠・矢印で示した「Voice_authentication_diary.aia」と書かれたリンクから、App Inventor のプロジェクト用ファイルをダウンロードします。
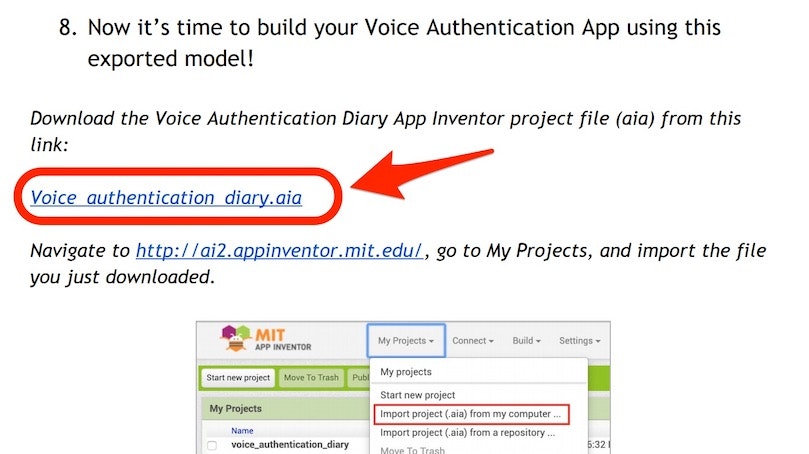
そして、「 http://ai2.appinventor.mit.edu/ 」へアクセスし、Googleアカウントを連携させて開発用の画面へ進みます。
開発が行える画面へ進むと、画面上部のメニューに「Projects」という項目があるので、それを選択します。

選択後に以下のメニューが表示されるので、その中の「Import project (.aia) from my computer ...」という項目を選択します。
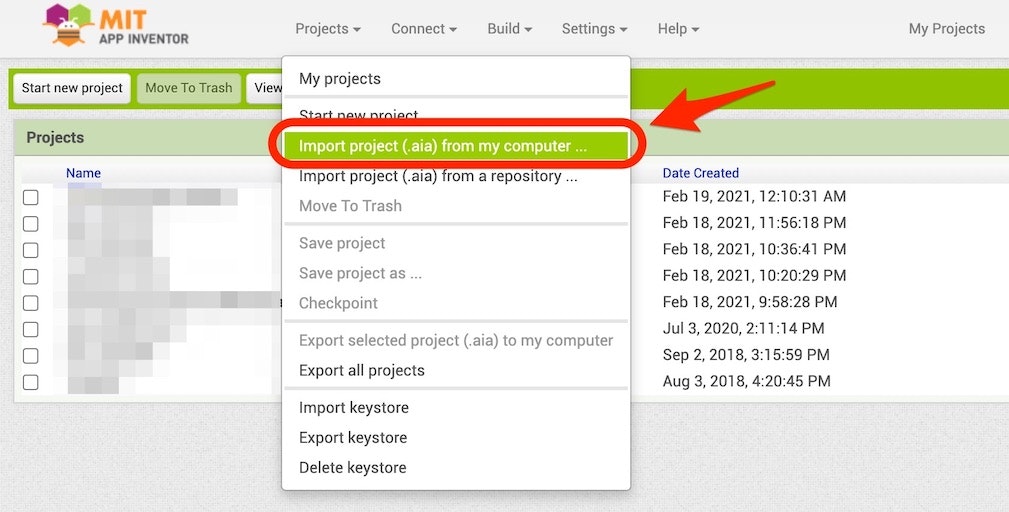
そうすると画面の中央あたりに以下の表示が出てくるため、赤い矢印で示した「ファイルを選択」ボタンを押し、その後に自分の PC の中の aiaファイル(※ デフォルトのファイル名だと voice_authentication_diary.aia という名前になっています)を選択します。その後、以下の緑色の矢印で示した「OK」ボタンを押します。
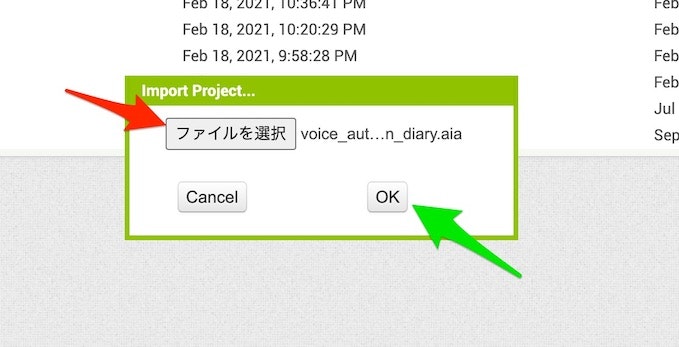
しばらくするとファイルの取り込みが完了し、以下のような画面が表示されれば OK です。
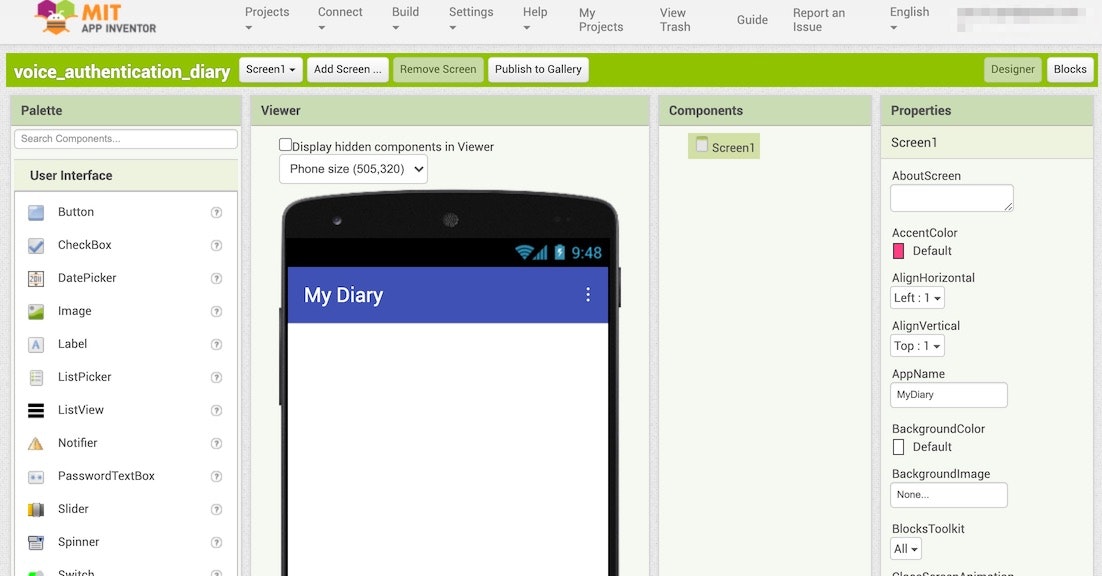
アプリの見た目などを作っていく
まずはチュートリアルと同じ見た目に合わせる
見た目を作る部分は、チュートリアルの資料によると、以下のものを配置・設定する必要があるようです。
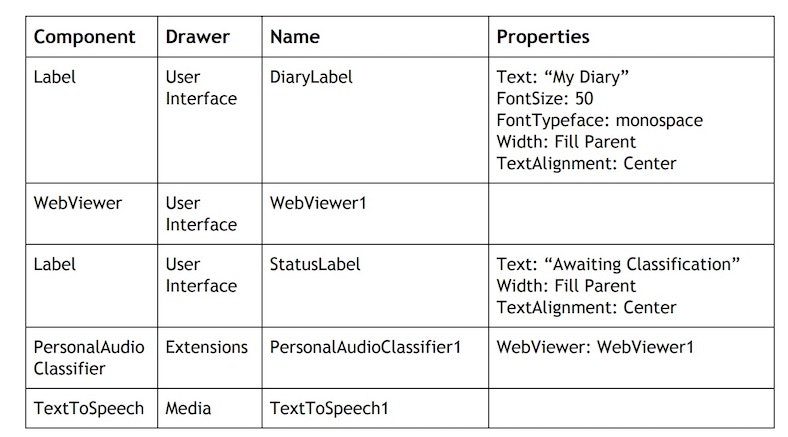
以下の赤の枠・矢印に示した部分で「Label」・「TextToSpeech」といった名前(上記の一番左の列に書かれている名前)を入力して、検索されたものを表示させてからドラッグアンドドロップで画面上に配置するか、以下の緑の枠・矢印で示した部分のメニュー内で該当する名前のものを探すかしてドラッグアンドドロップで画面上に配置してください。
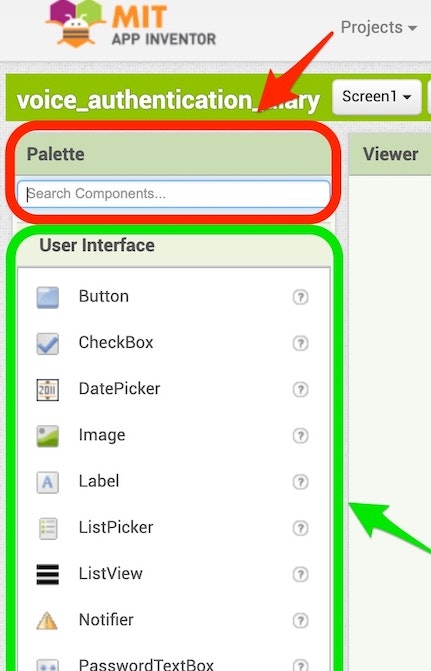
2つのやり方のうち名前の検索を使うやり方を行う場合に関して、名前の入力をしている途中段階でも絞りこまれた検索結果が表示される仕組みのため、それをうまく活用すると名称全ての文字を打ち込まずにすんで効率的です。
以下のアニメーションGIF は、「TextToSpeech」を探して画面上にドラッグ&ドロップしている時の様子です。名前の入力をして検索する方法のほうを使っていて、「textto」まで検索文字列を入力した際に絞りこまれた結果として出てきた「TextToSpeech」を、真ん中あたりの画面の上にドラッグアンドドロップしている様子です。
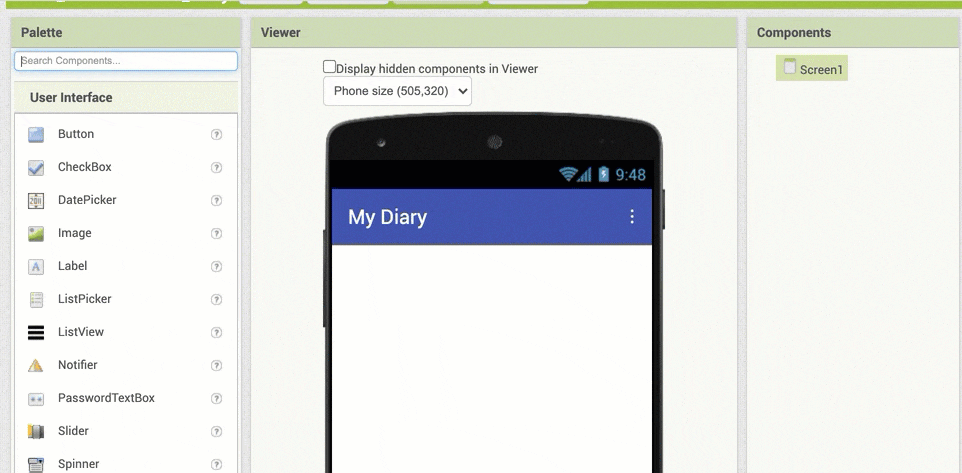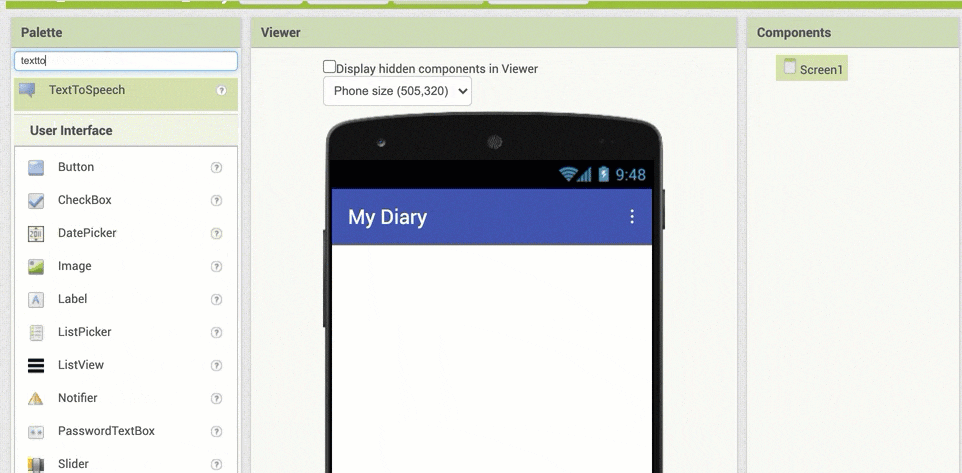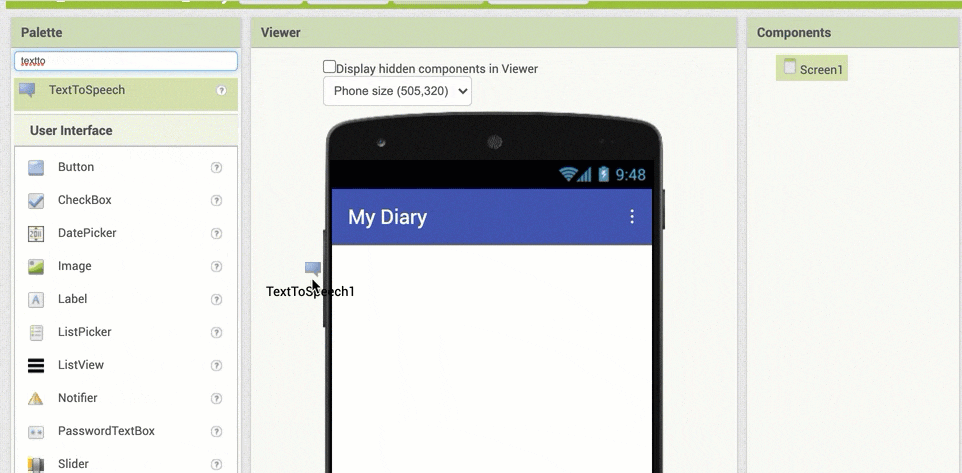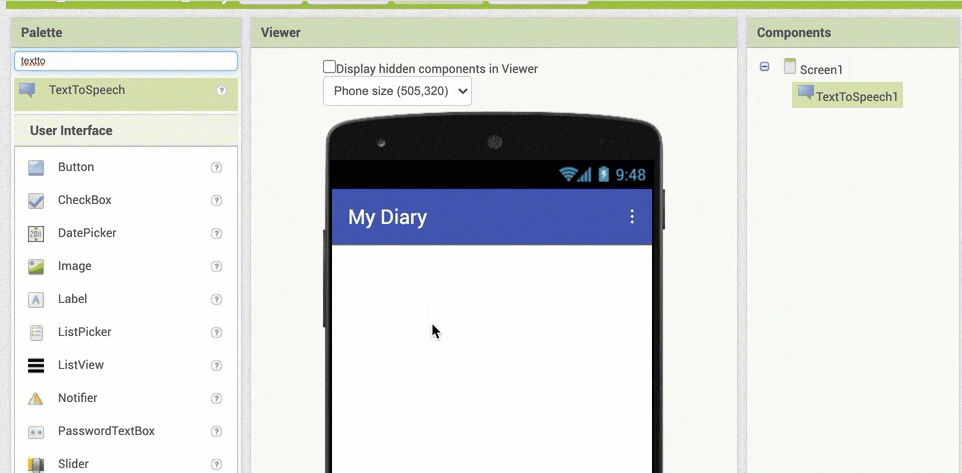
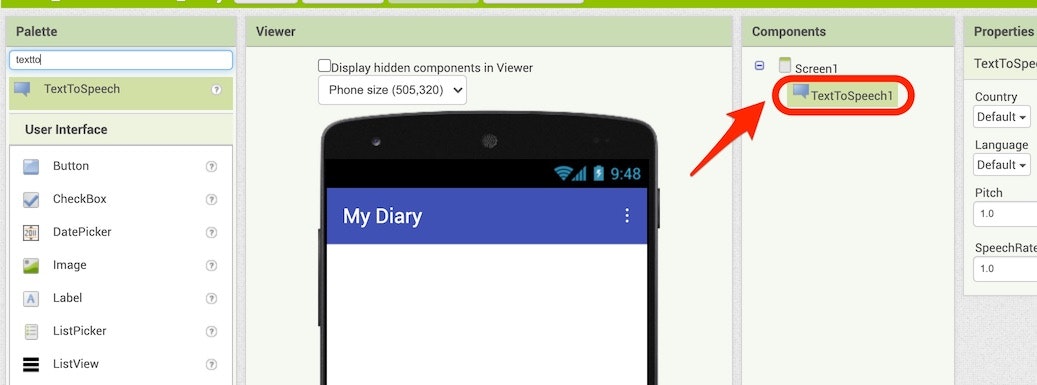
この操作を行った後の画面では、以下のように「TextToSpeech1」という項目が、Screen1という名前の項目の下に表示された状態になれば OK です。
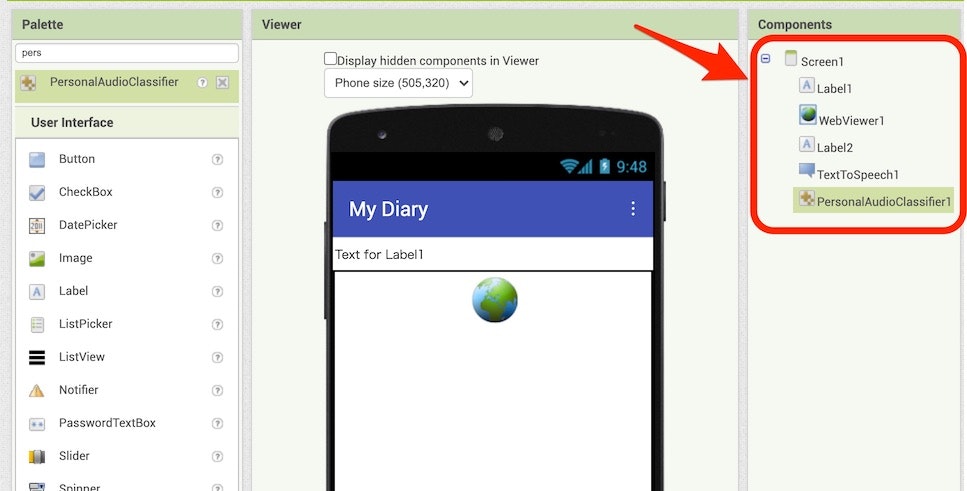
続けて「Label」⇒「WebViewer」⇒「Label」⇒「PersonalAudioClassifier」もドラッグアンドドロップで追加していきます。それが終わった後の画面は以下のとおりで、赤い枠・矢印で示した部分にこの 5つの項目が並んでいれば OK です(並び順に関しては、上の 3つが「Label1 ⇒ WebViewer1 ⇒ Label2」となっていれば良さそうです)。
さらに、「Label1・Label2・PersonalAudioClassifier1」の 3つについては、名前・プロパティの設定を以下のように変更・設定します。
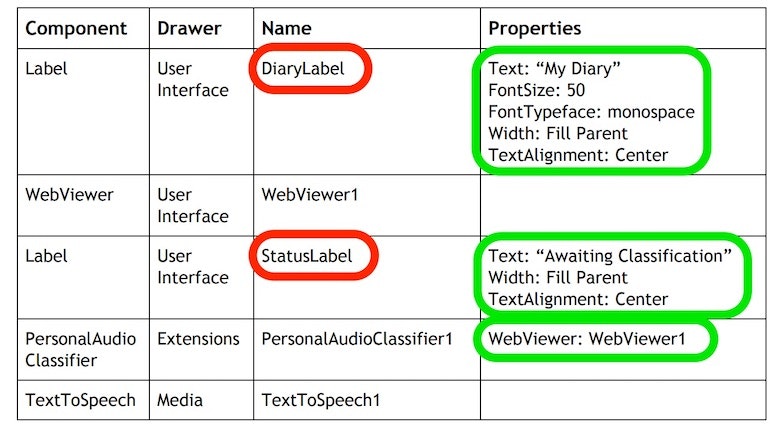
名前の変更は、例えば以下の赤い枠・矢印で示した「Label1」を選び、その後に以下の緑の矢印で示した「Rename」ボタンを押します。そうすると、この「Label1」の名前を変えるための表示が出てくるので、そこで「New name:」と書かれた部分に変更したい名前を入力して、「OK」ボタンを押します。
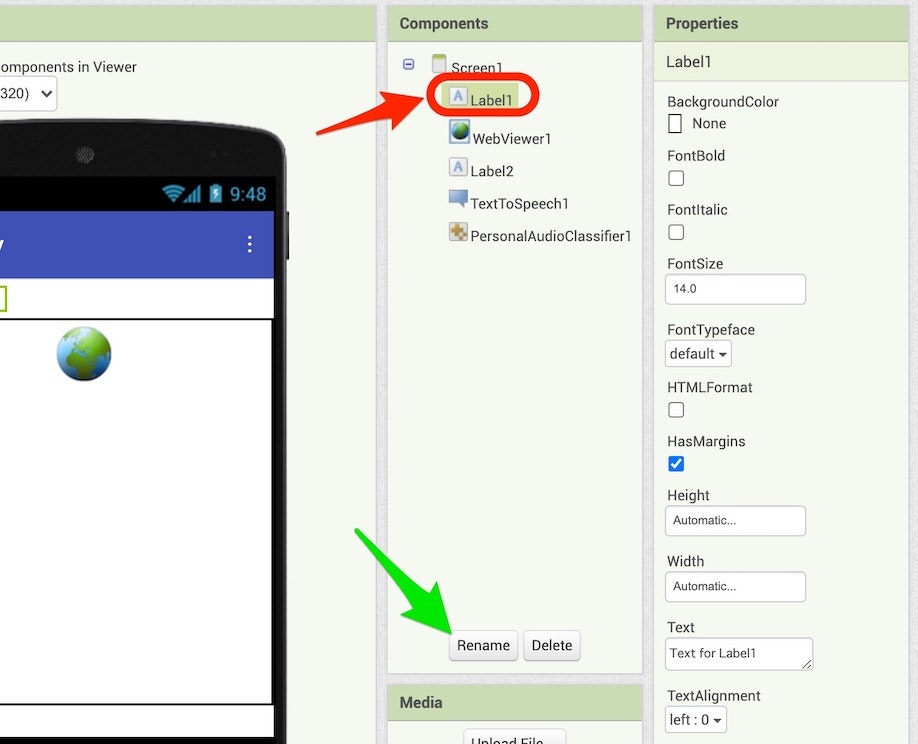
プロパティの変更については、名前の変更を行った時のようにプロパティを変更したい項目を選択し、その後に画面右端の「Properties」(以下の赤い枠・矢印で示した部分)の中で、変更対象の項目を探して所定の内容を設定します。
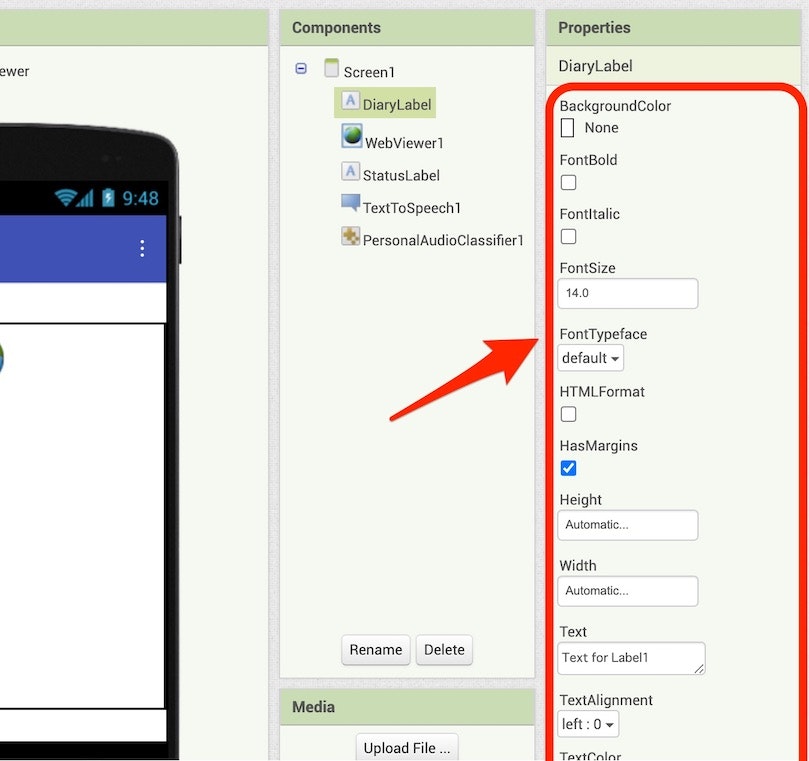
各設定を行った後の画面の状態は、以下の通りです。
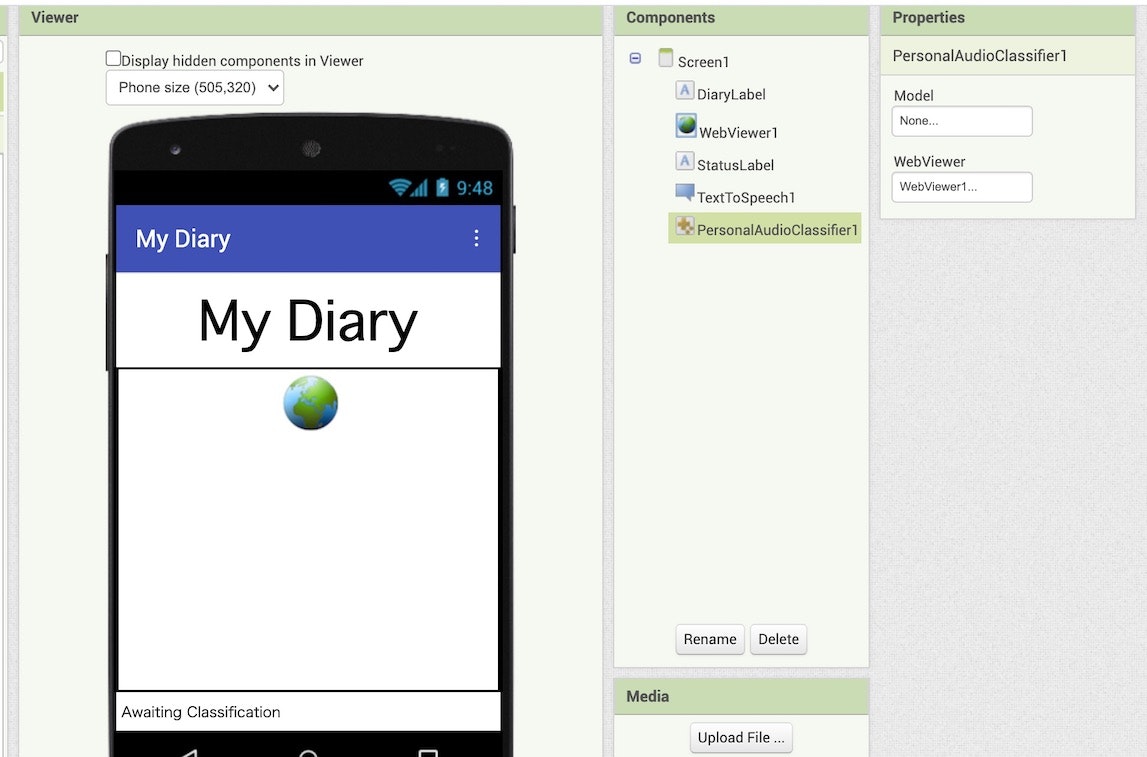
学習モデルを読み込ませる
ここで、前回の記事で作成した学習モデルを読み込ませます。
以下の赤い枠・矢印で示した「PersonalAudioClassifier1」が選択された状態で、以下の緑の矢印で示した「None...」と書かれた部分をクリックします。
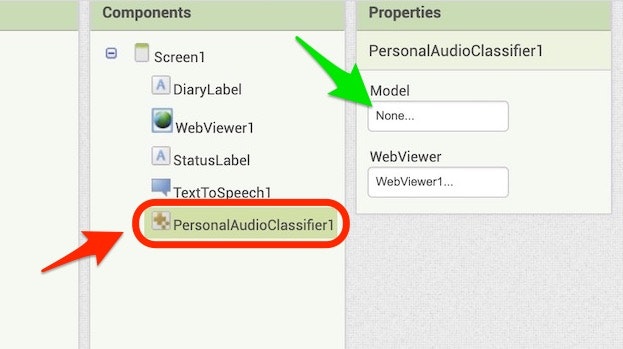
その後に表示される以下の画面で「Upload File ...」ボタンを押し、その後にファイルを選択する画面(「Import project (.aia) from my computer ...」を選択して、プロジェクトの取り込みを行った時と似た画面)が表示されるので、その画面で前回の記事で作成した学習モデルを選ぶようにします。
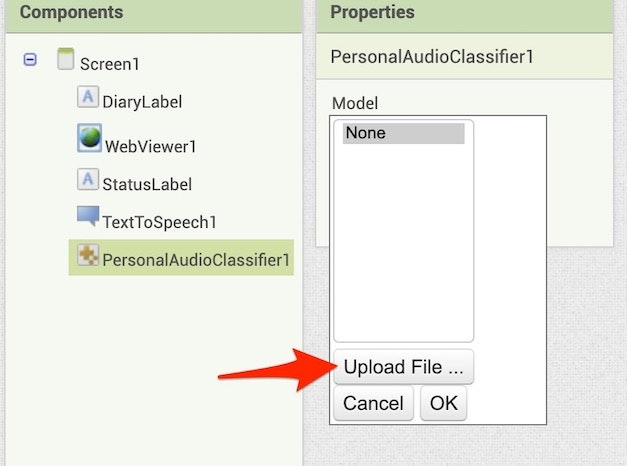
以下のように、先ほど「None...」と書かれていた部分が学習モデルのファイル名になっていれば OK です。
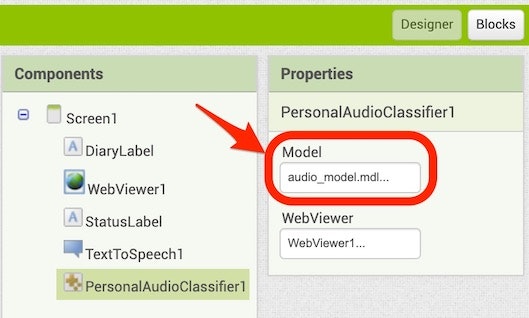
アプリの見た目の部分を変える
独自の変更を加える
これまでの手順では、見た目等の設定をチュートリアル通りに行ってきましたが、そもそも前回の学習モデルを作った時点でチュートリアルの内容と進め方が違っている部分があり、画面構成を変えたほうが良さそうなところがあります。
具体的には、チュートリアルでは「異なる 2人の人物の声が学習対象となっている(そして、しゃべった人物がどちらかによって、日記を扱うアプリの中で特定の画面から先に進めるかどうかを決める)」という想定になっていて、一方で自分が作ったものは「同じ人物が異なる内容をしゃべったものを学習させている」という点です。
チュートリアルのような人の識別という要素はないため、ここで自分が作るアプリの挙動は「事前に学習させた 3つの挨拶の内容によって、アプリが声で返す内容が変わる(同じ挨拶を返すようにする)」というものにしようと思います。そのため、少し画面に配置したものの並び順や、ラベルのプロパティに設定した内容を以下のように変更します。
並び順の変更は、以下のアニメーション GIF の内容のように、開発画面の真ん中あたりの部分(スマホを模した画面表示が出ている部分)で、配置したラベルなどを直接ドラッグアンドドロップで移動させる形です。
ここでは、「StatusLabel」と名称変更したラベルの配置を、全体の一番上に移動させています。
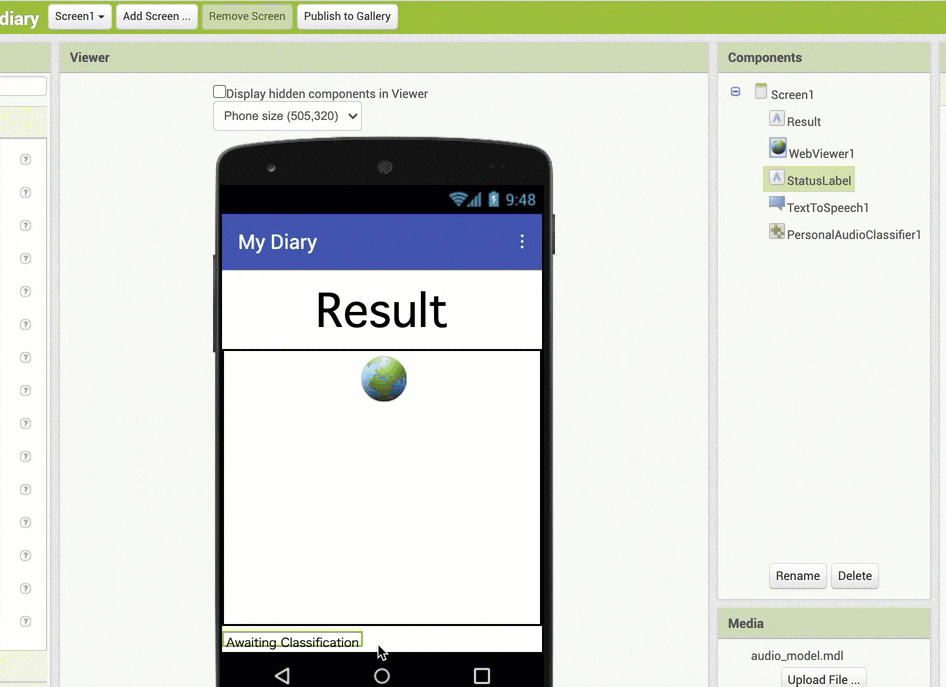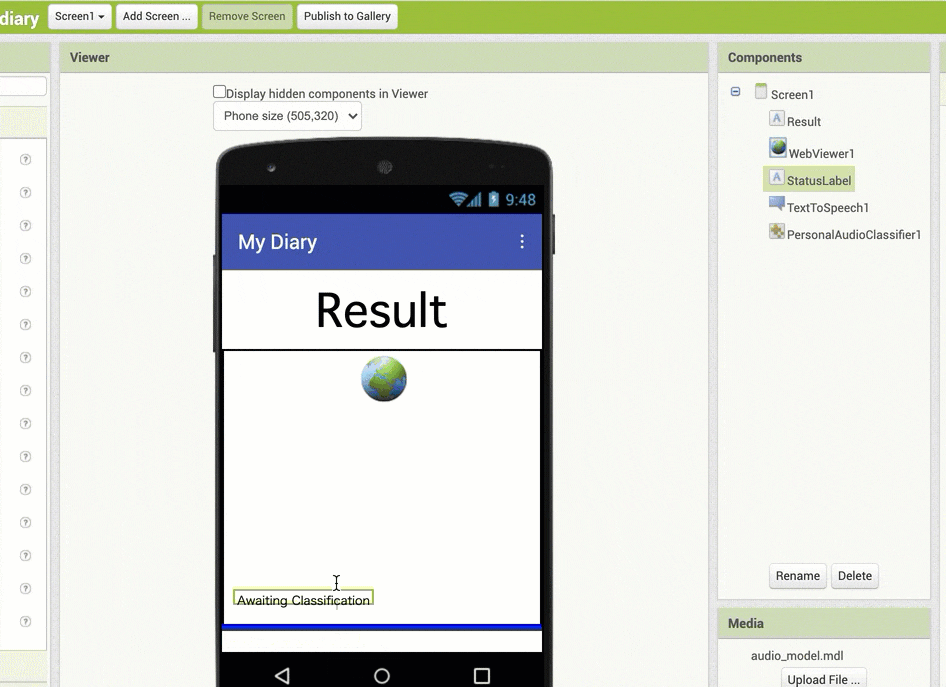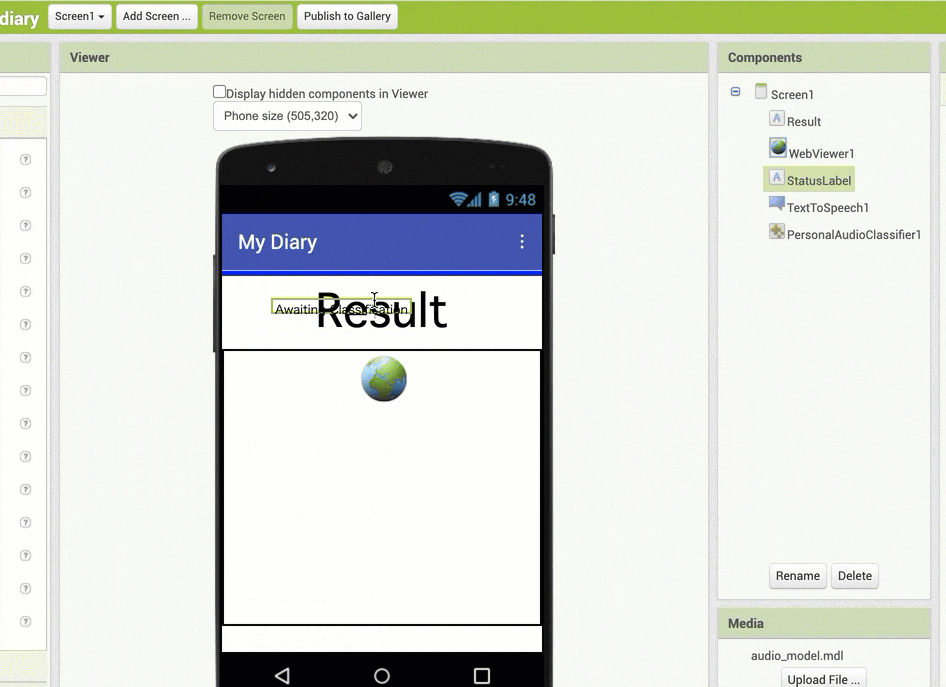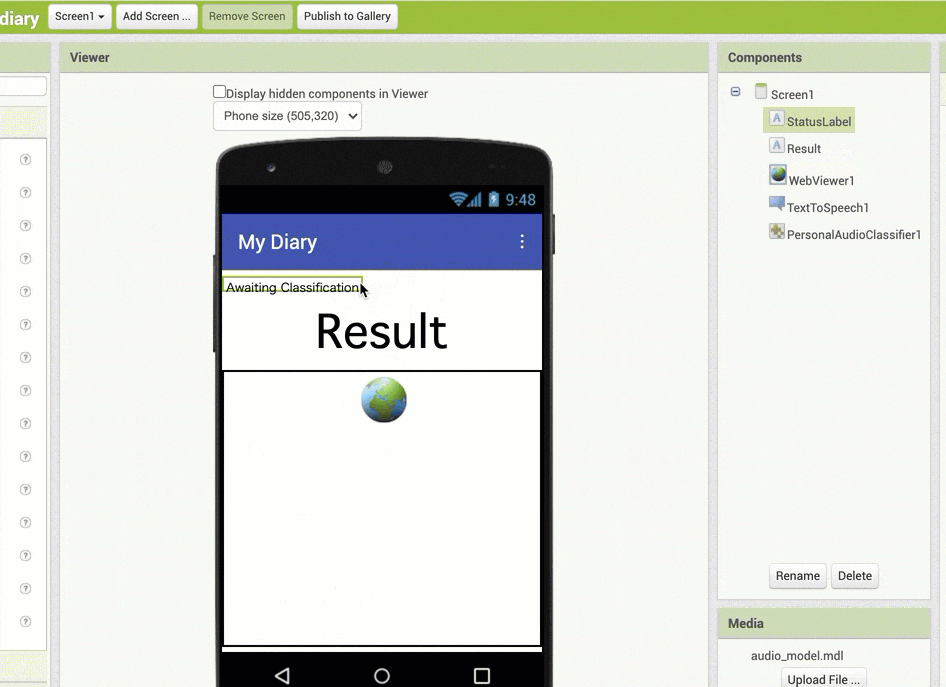
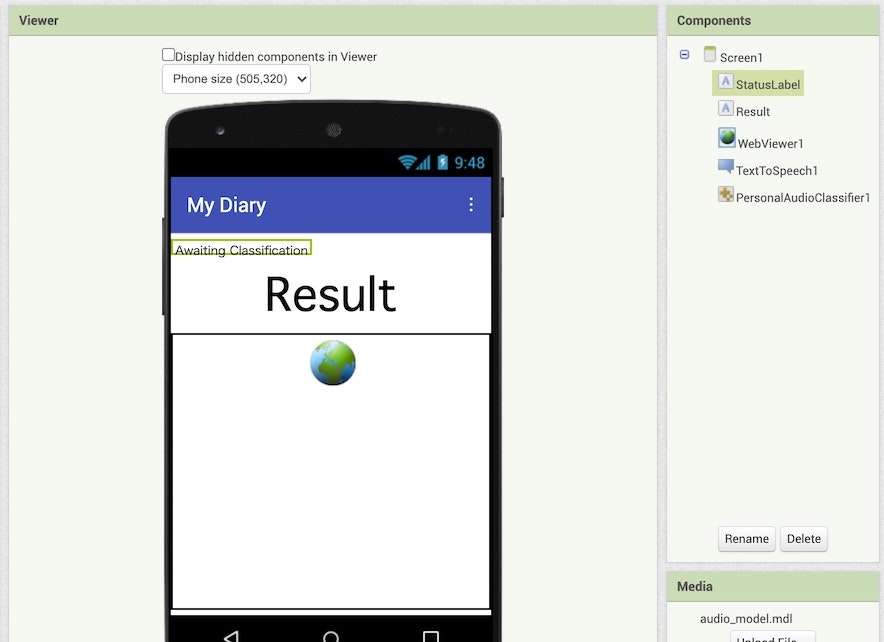
さらに、名前の変更については、「DiaryLabel」という名称になっていた部分を「Result」に変更しています。さらに、名前を Result に変更したラベルのプロパティで、Text として設定していた「My Diary」をラベル名称と同じ「Result」にしました。
変更後の画面は以下のとおりです。
プログラムを作る
この後はブロックベースでのプログラム作成を行っていきます。そのために、画面右上にある「Blocks」と書かれたボタンを押します。
そうすると、以下の画面に切り替わったかと思います。
ブロックを配置していく(その1)
ここで、チュートリアルの資料で示されたブロックを順番に配置していきます(見た目の部分と同じで、一部は独自の処理に変更していきます)。
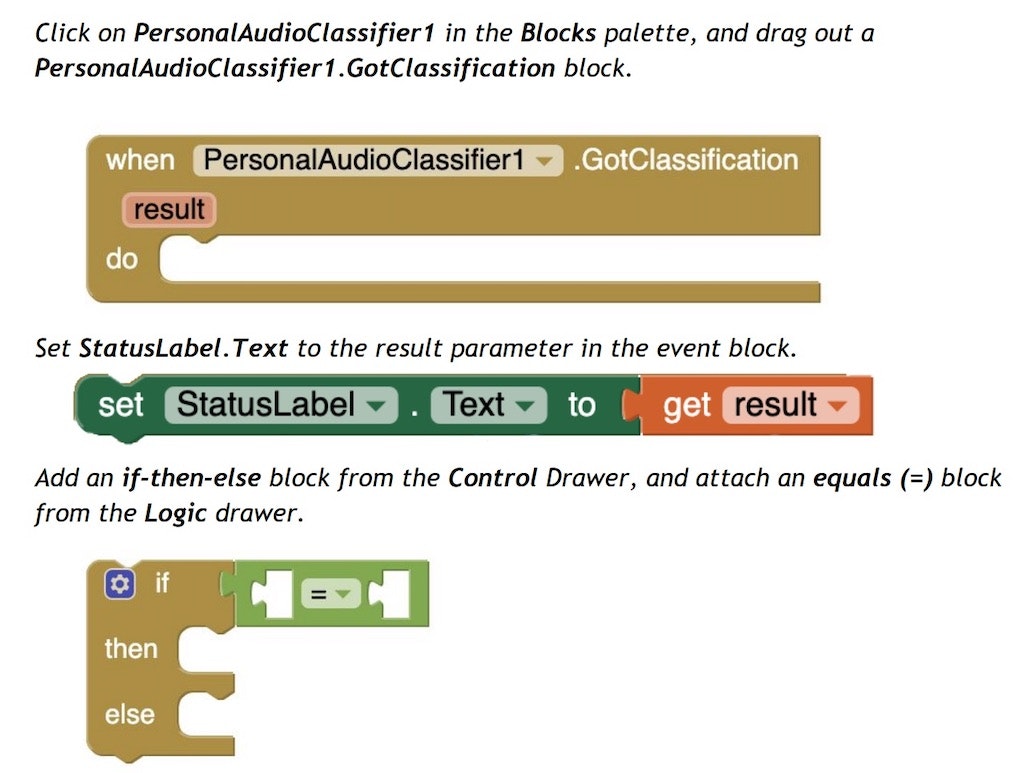
以下に、ブロックを配置していく様子をアニメーションGIF で掲載していきます。
↓機械学習により音声の識別を行うためのブロックの配置
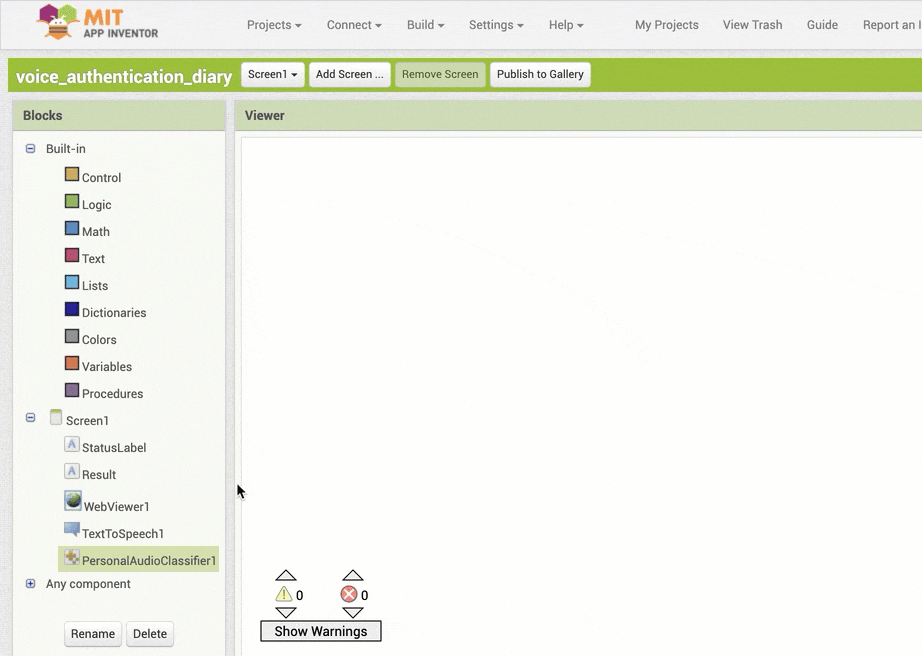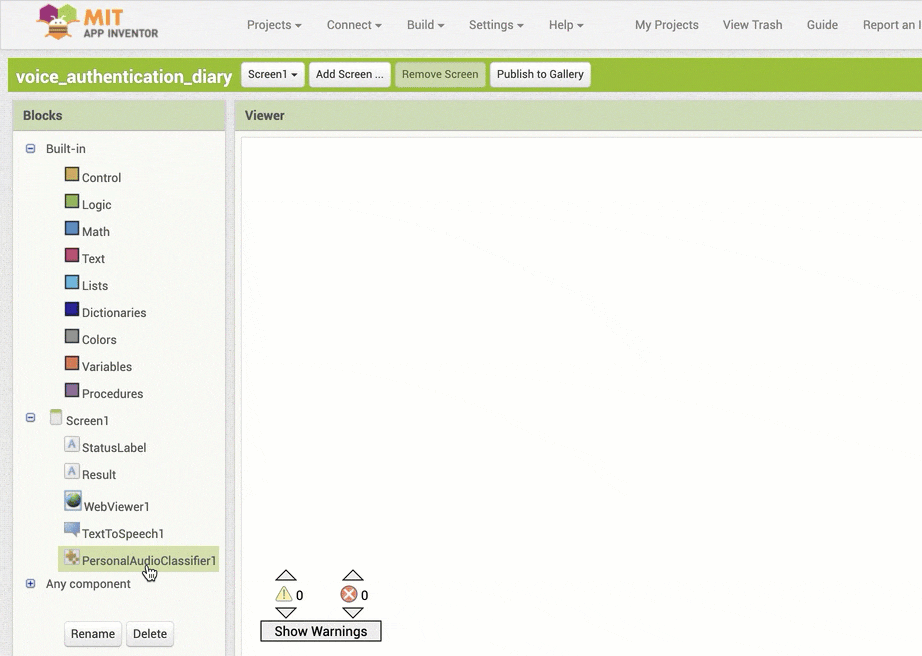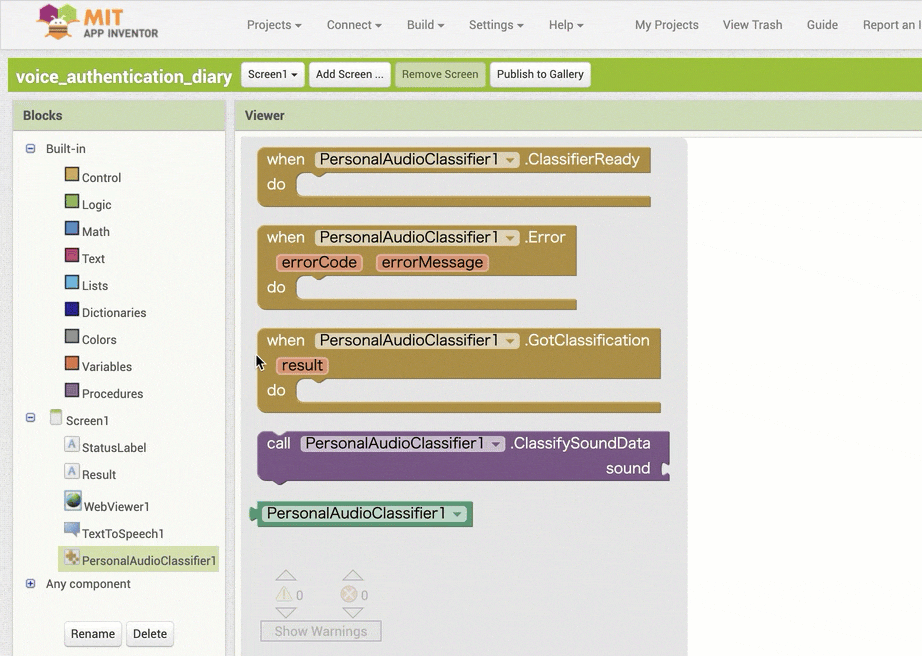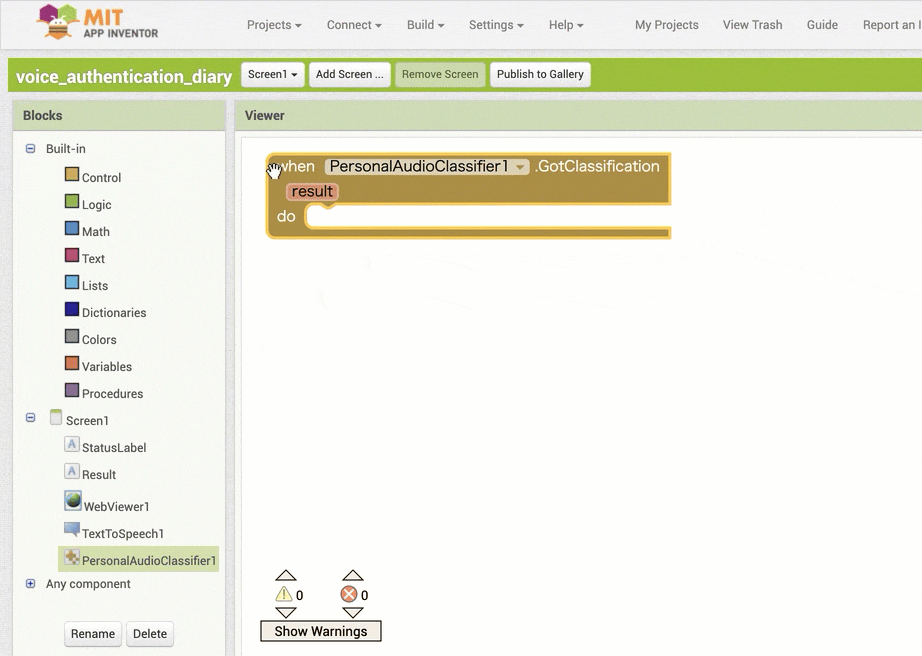
↓「StatusLabel」のテキストを書きかえるためのブロックの追加と設定
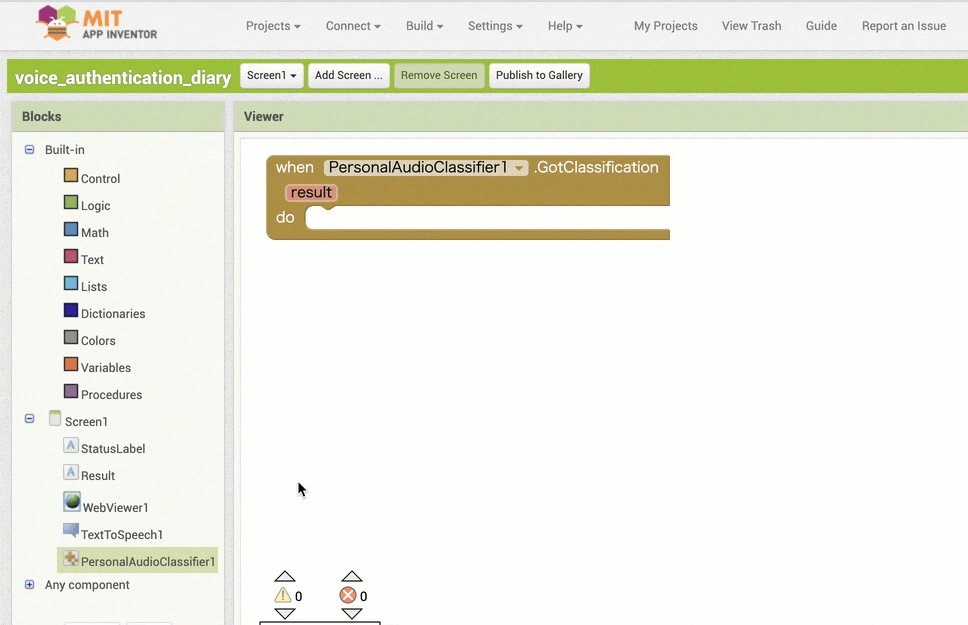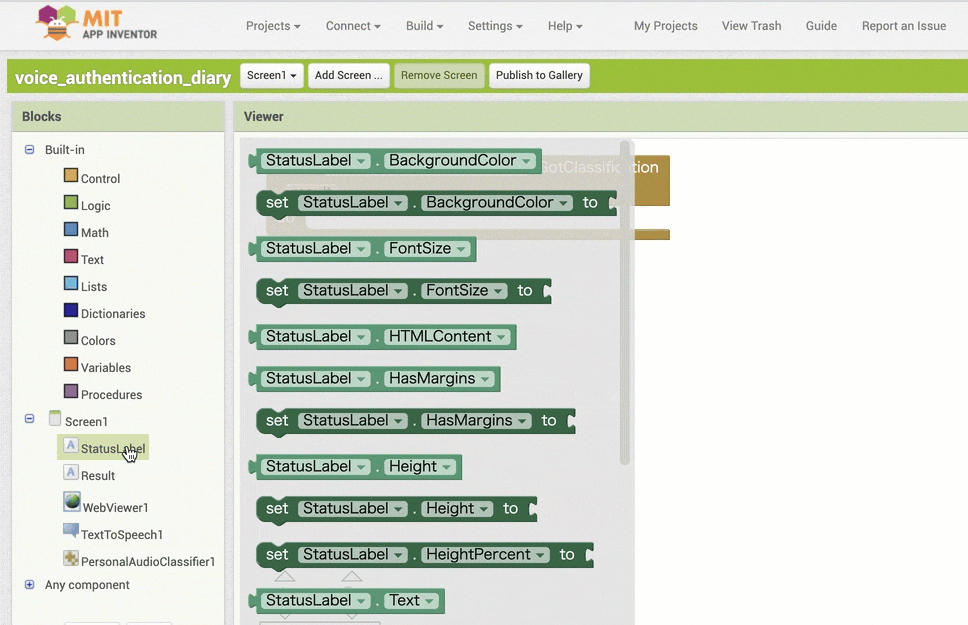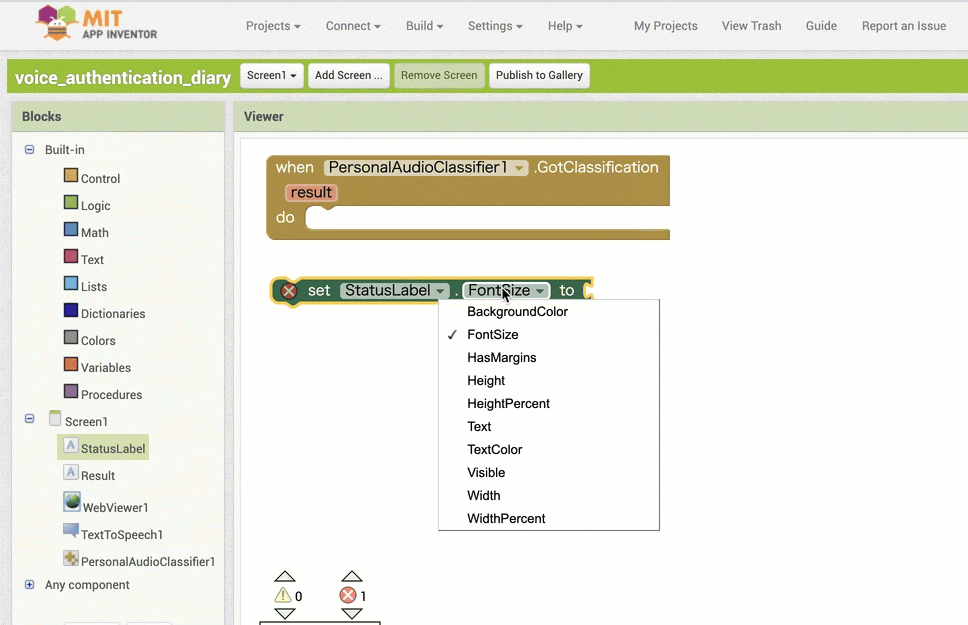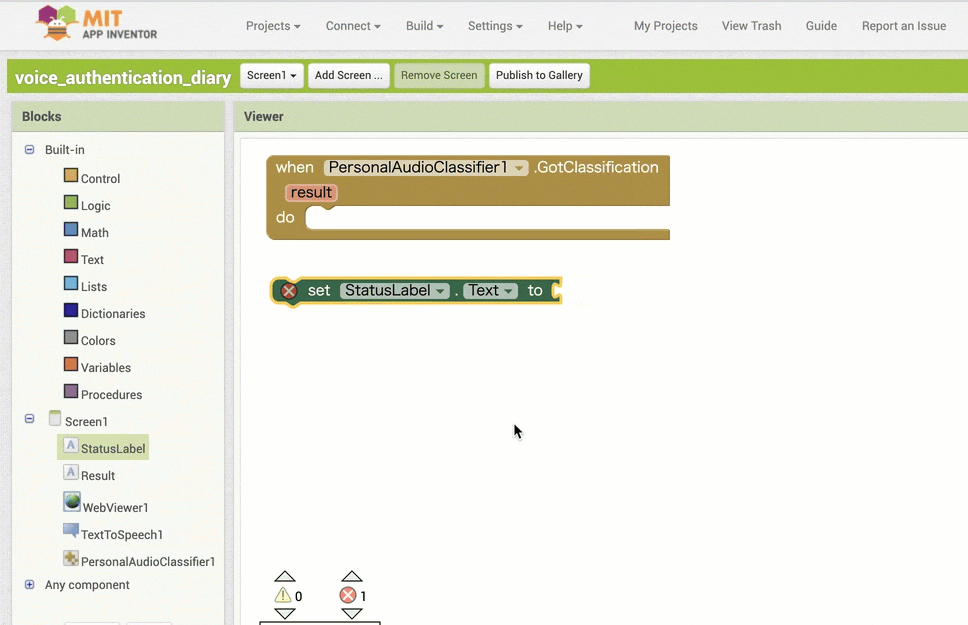
↓条件分岐をさせるためのブロックの追加と設定
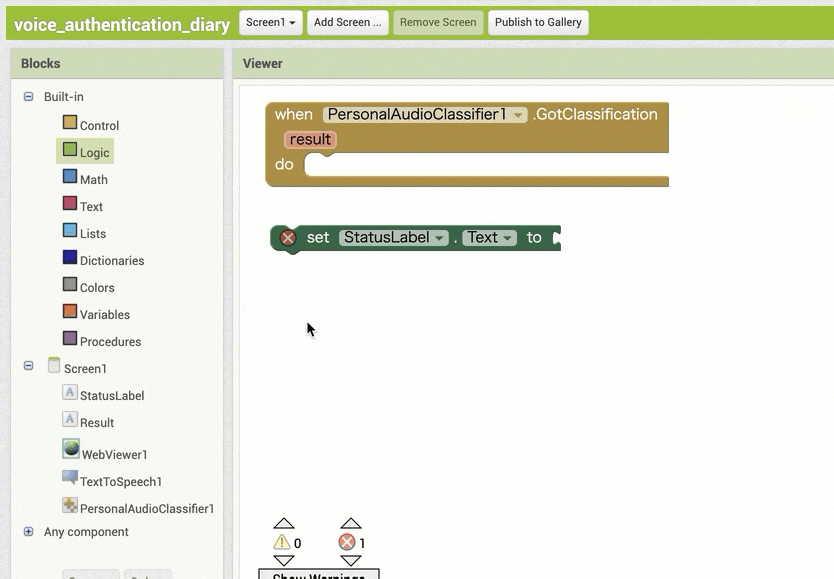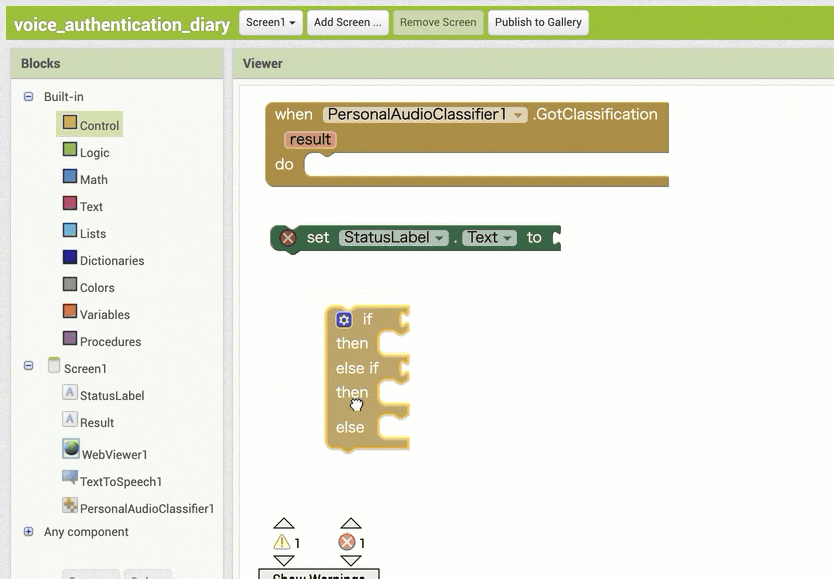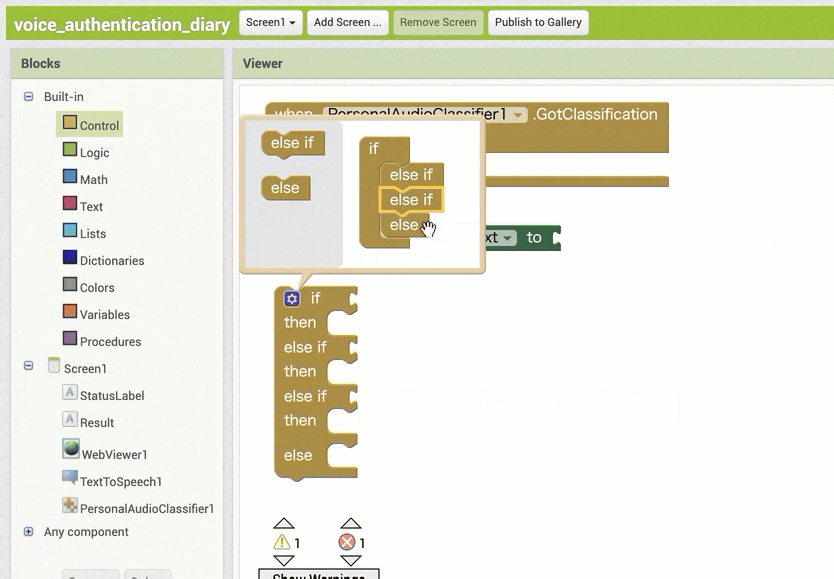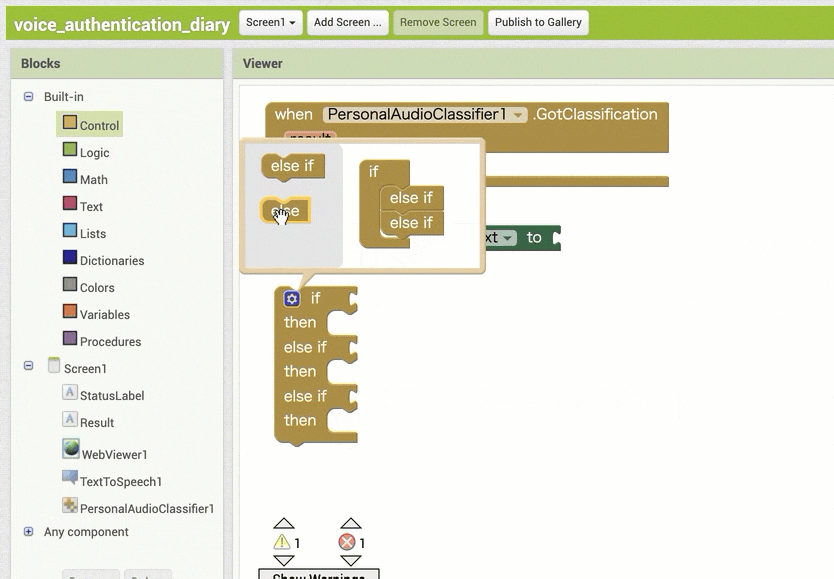
↓結果保存用の変数を利用するためのブロック追加・設定1
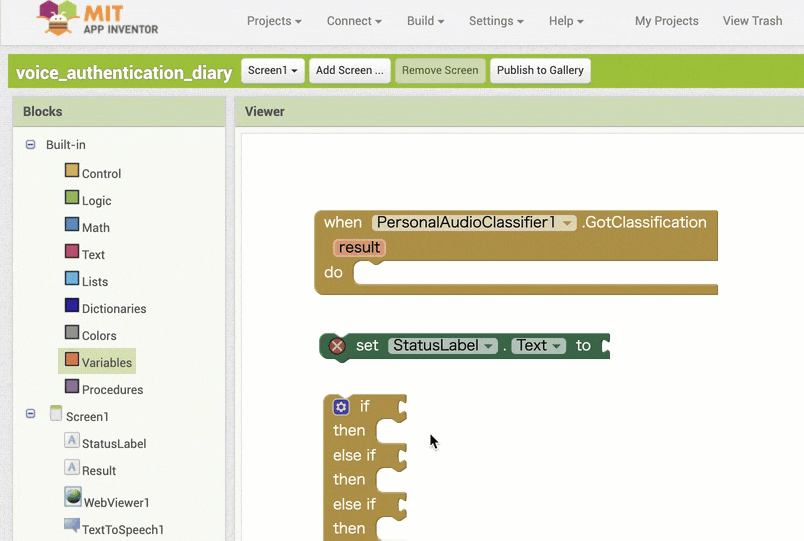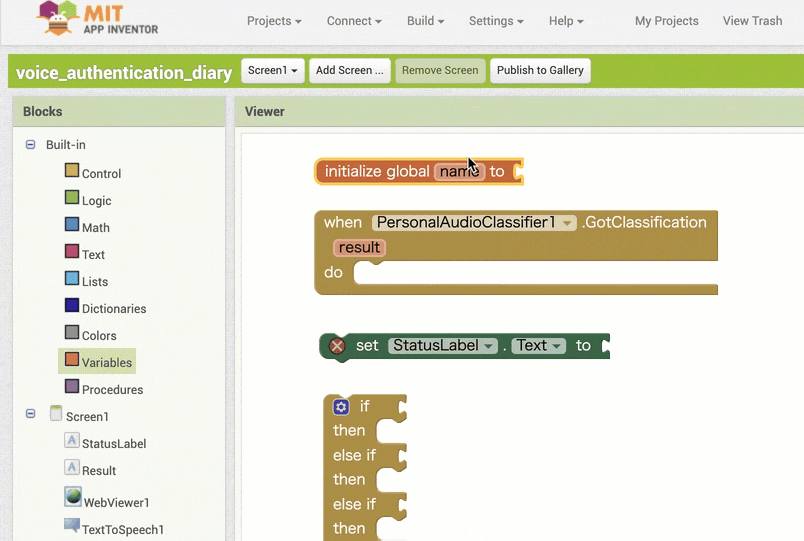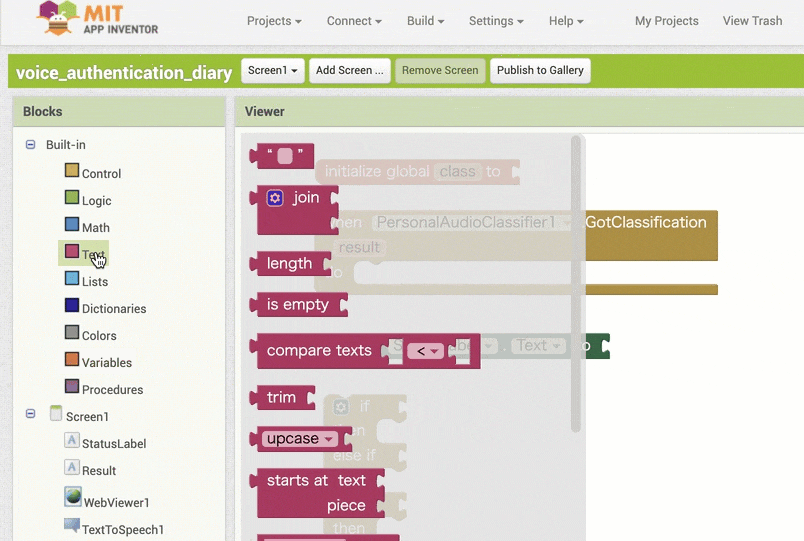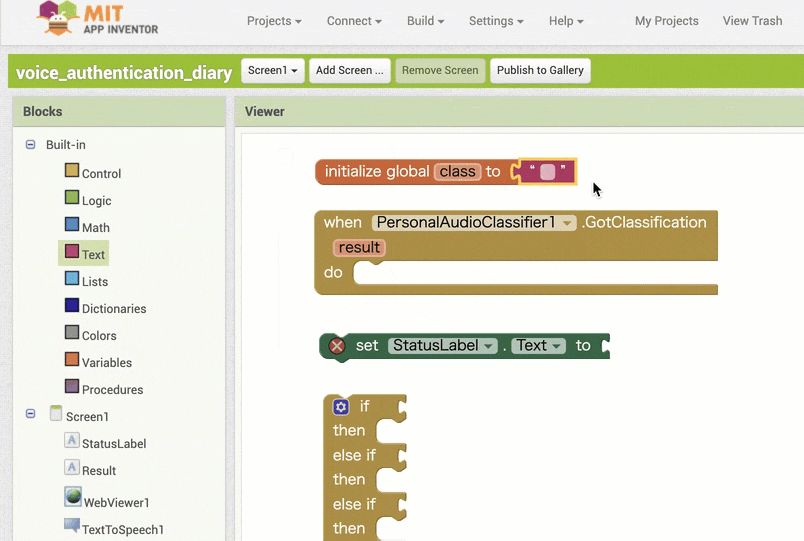
↓結果の取得のためのブロック追加(作るブロックの構成

↓結果の取得のためのブロック追加(ブロックの追加・設定手順)
【その1】
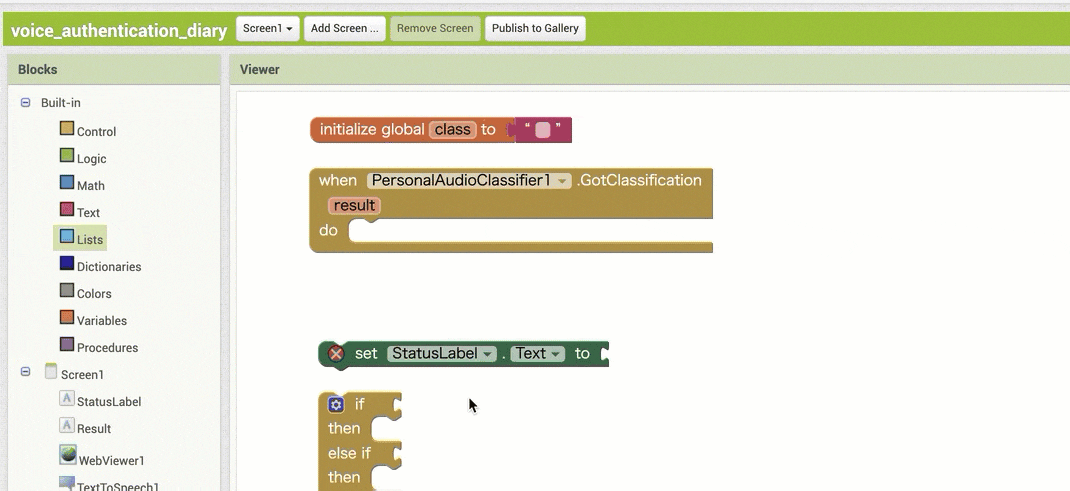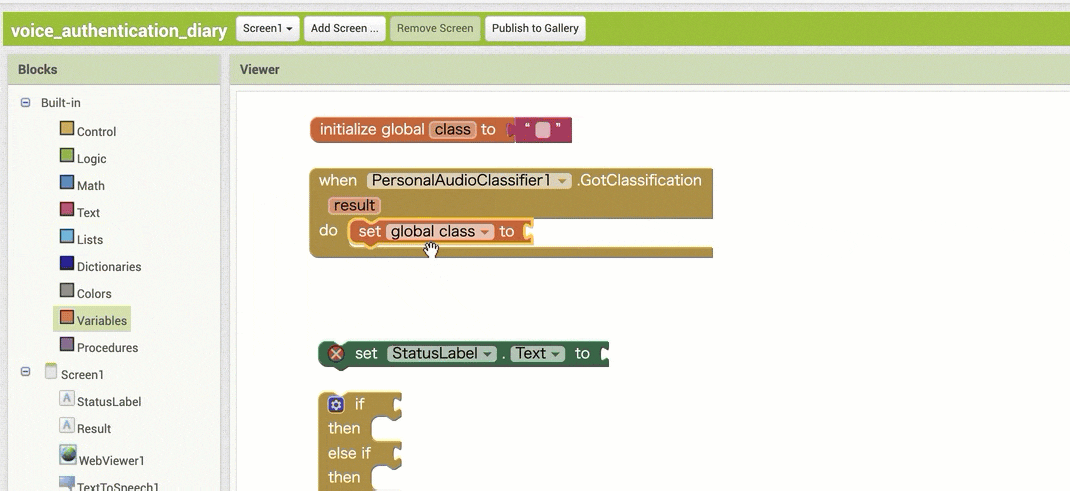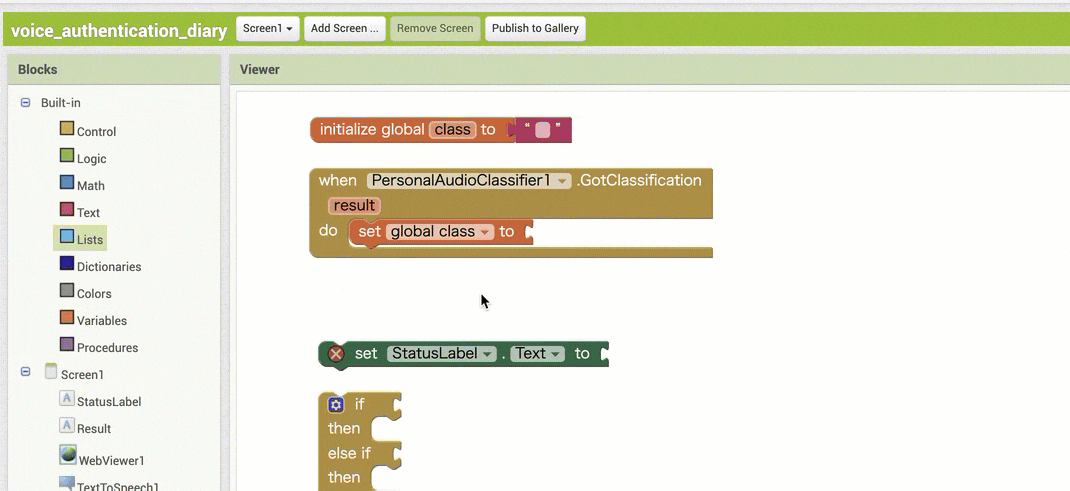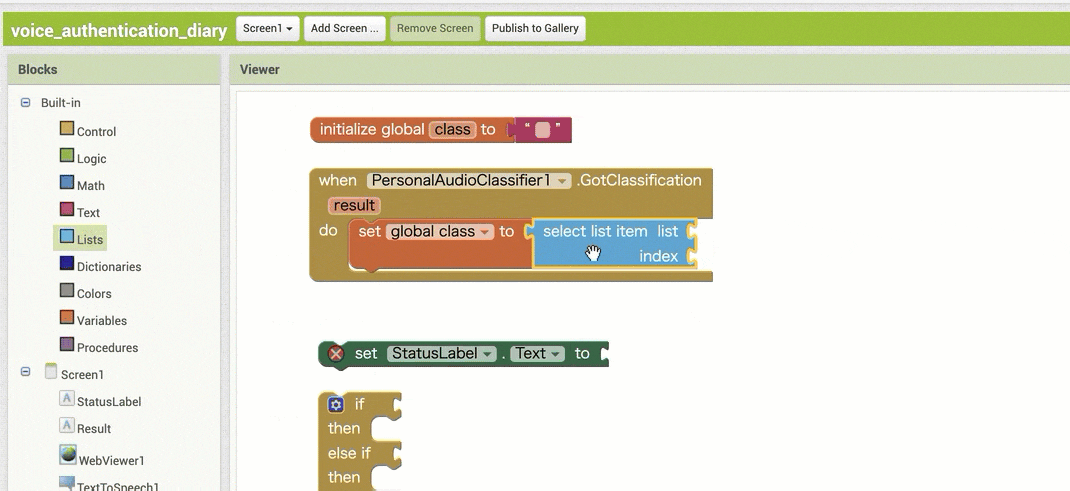
【その2】
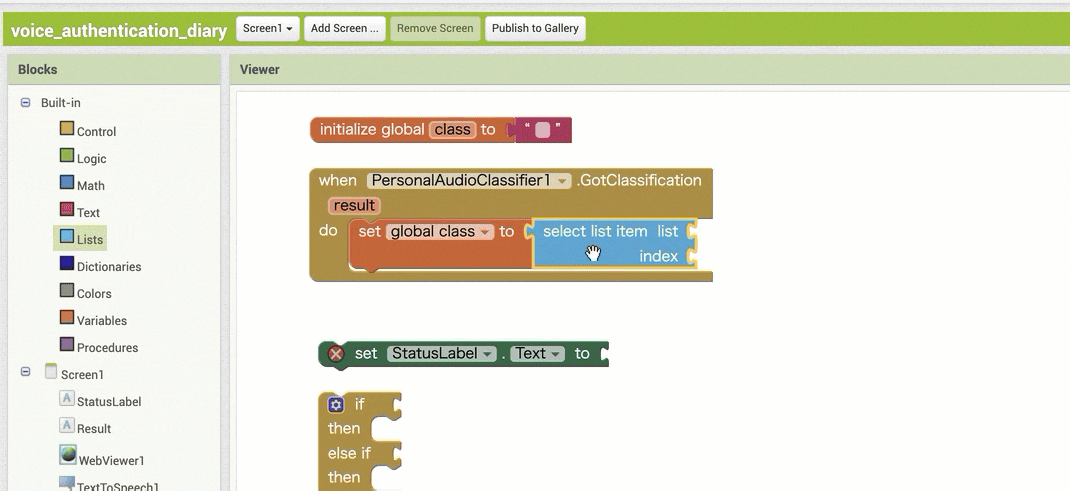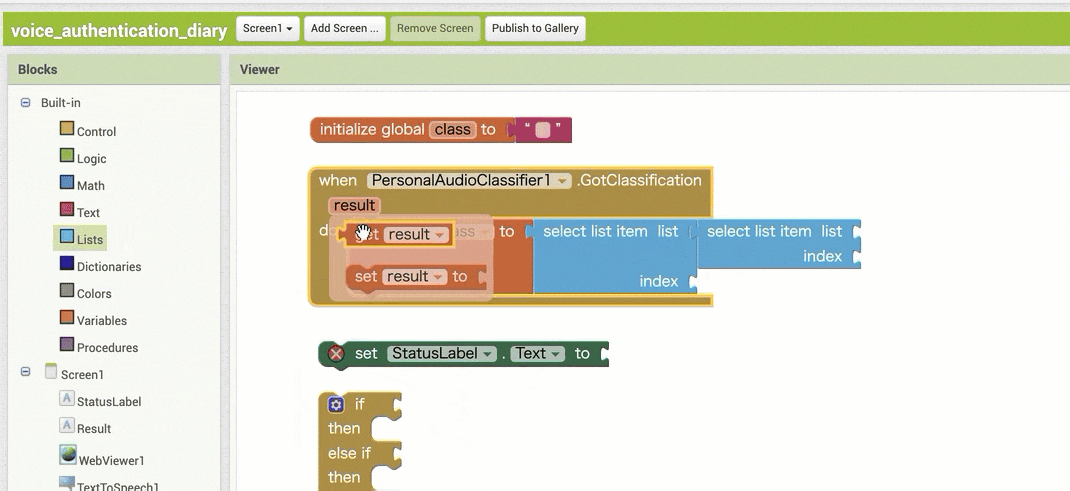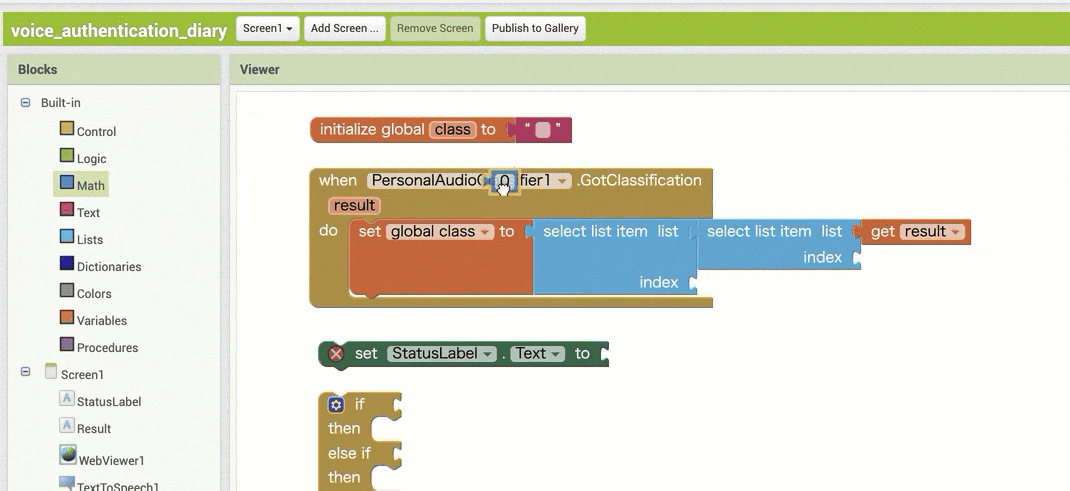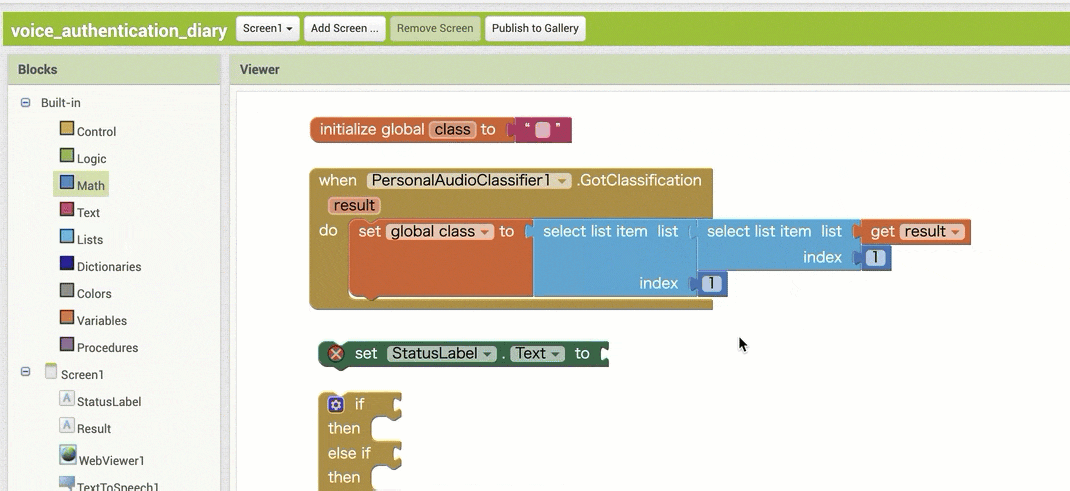
※ ここで、同じブロックを 2つ追加する部分が2箇所ありますが、コピー&ペーストを使う方法もあります。
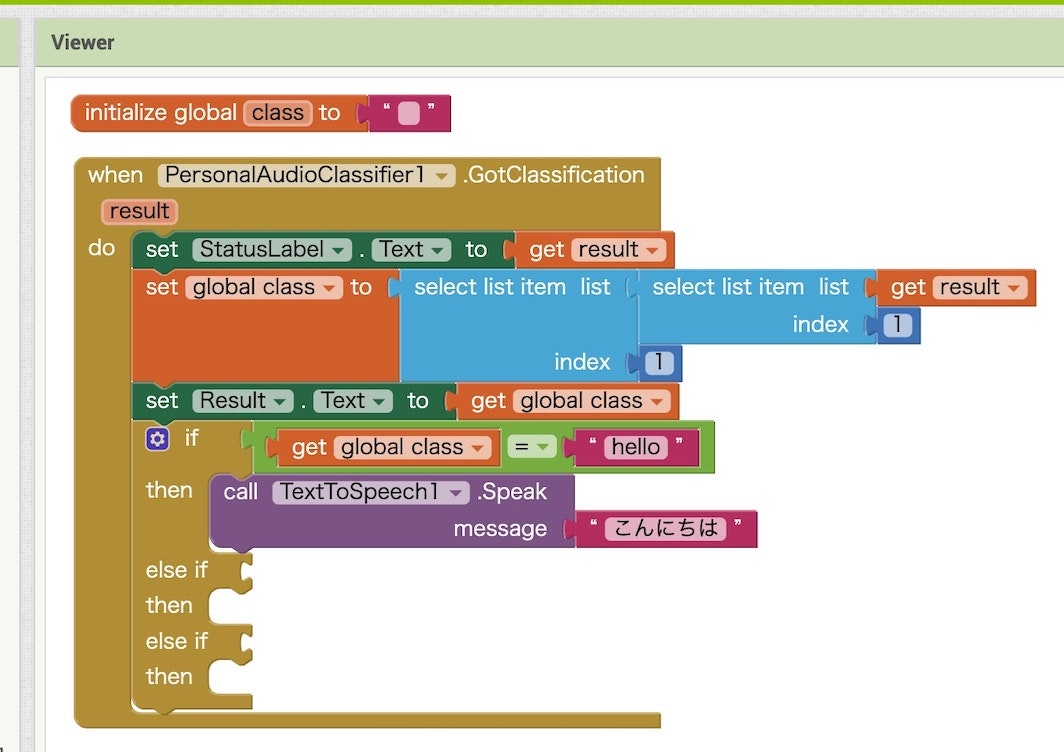
↓認識結果を表示させる処理のためのブロック追加
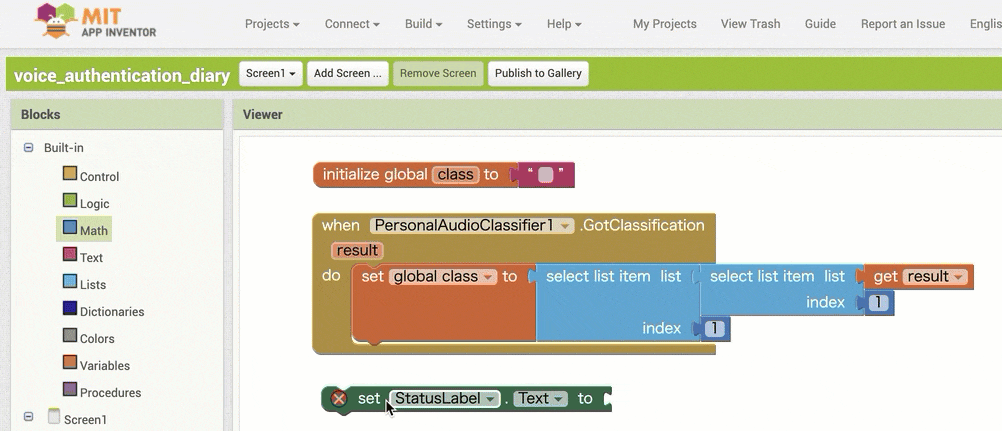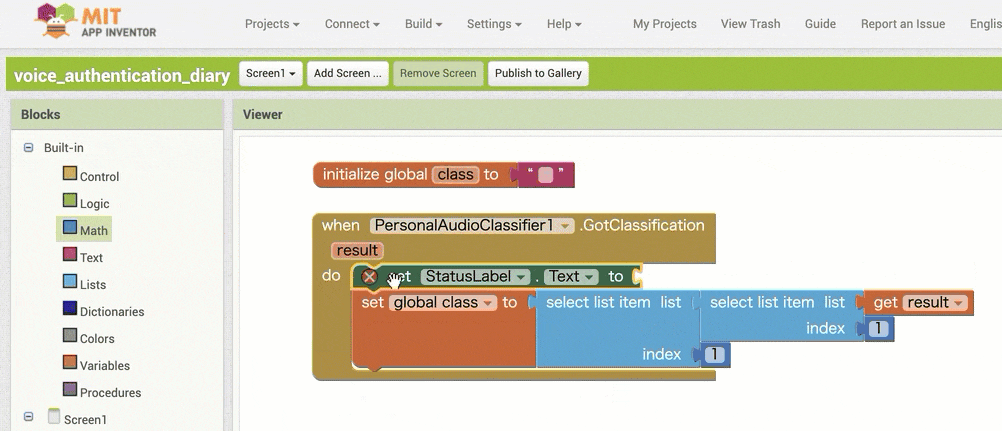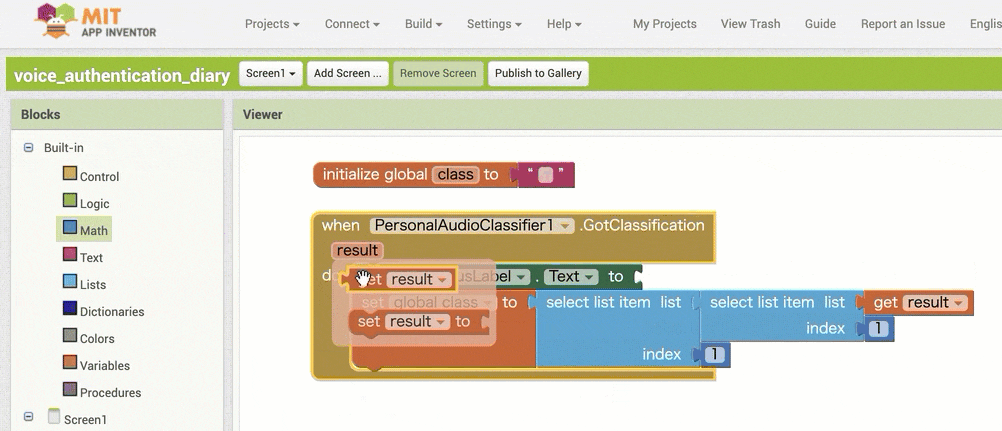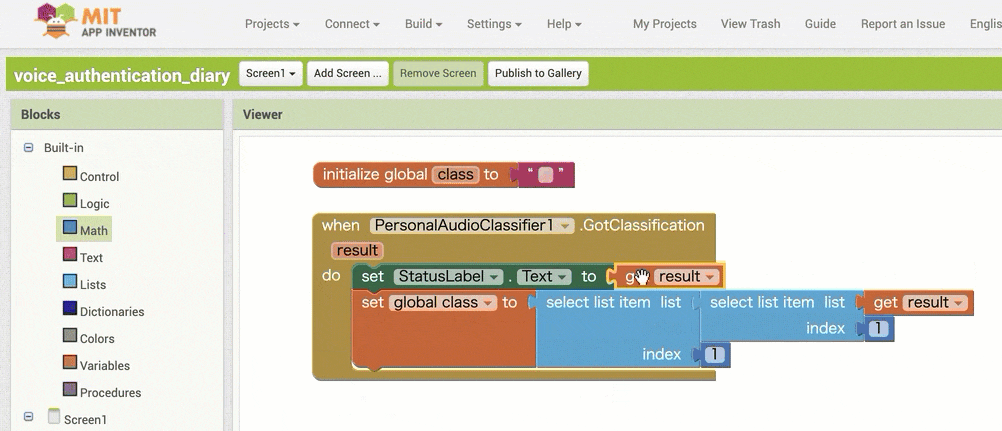
↓認識結果を用いた条件分岐の作成
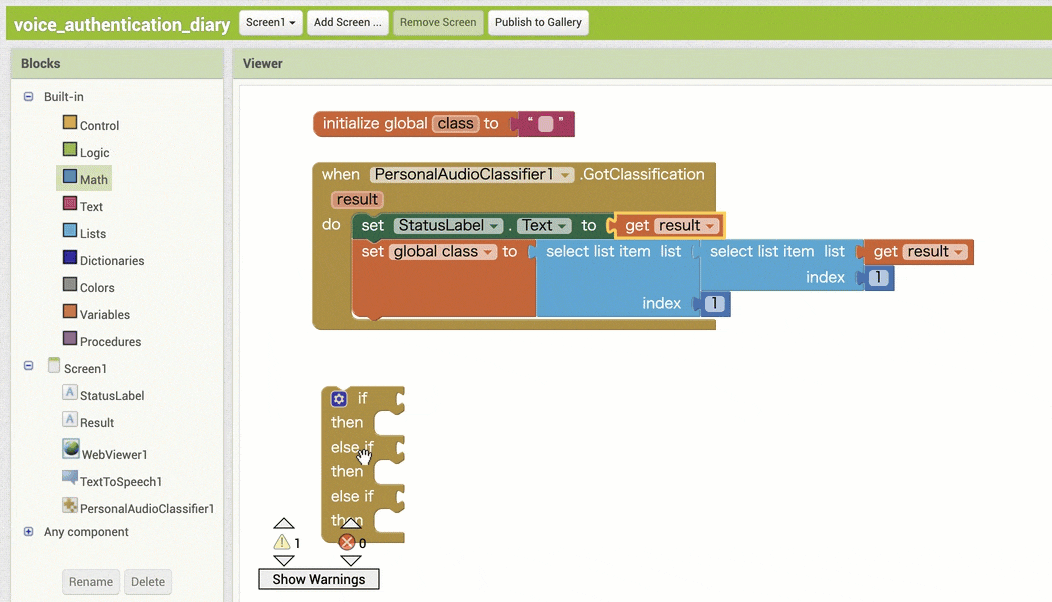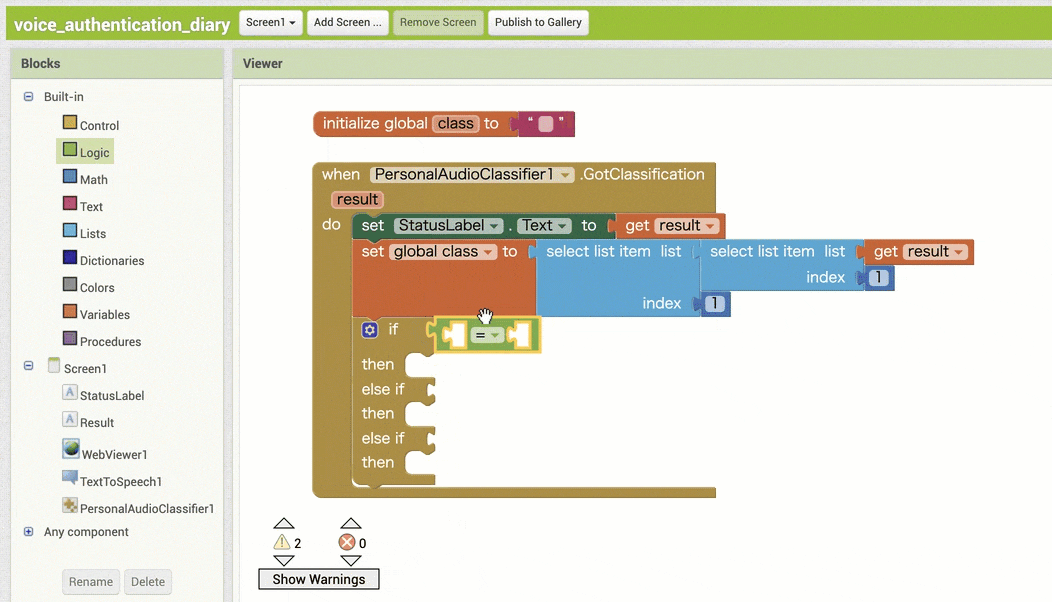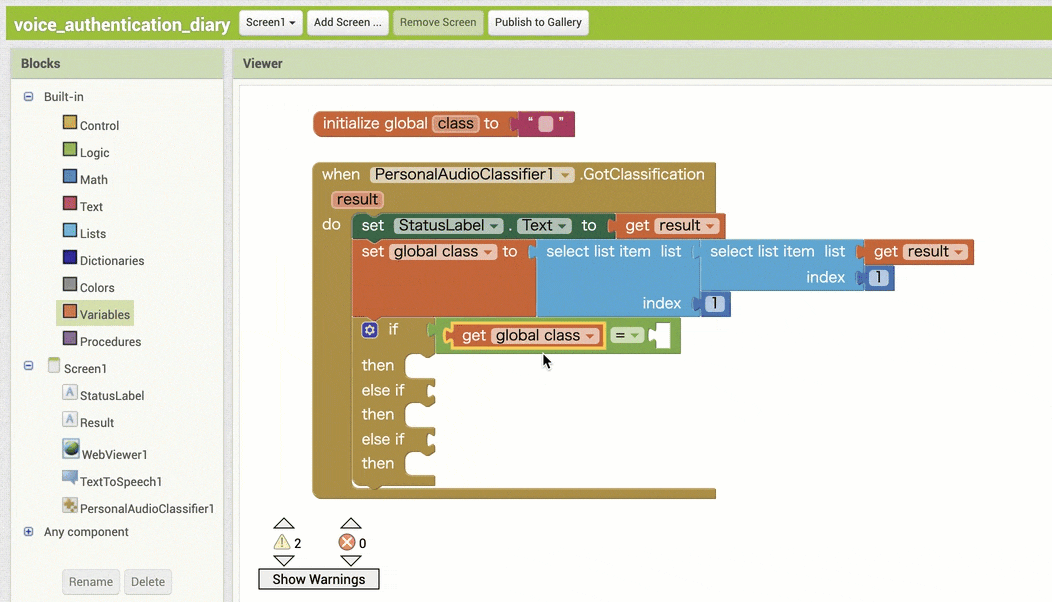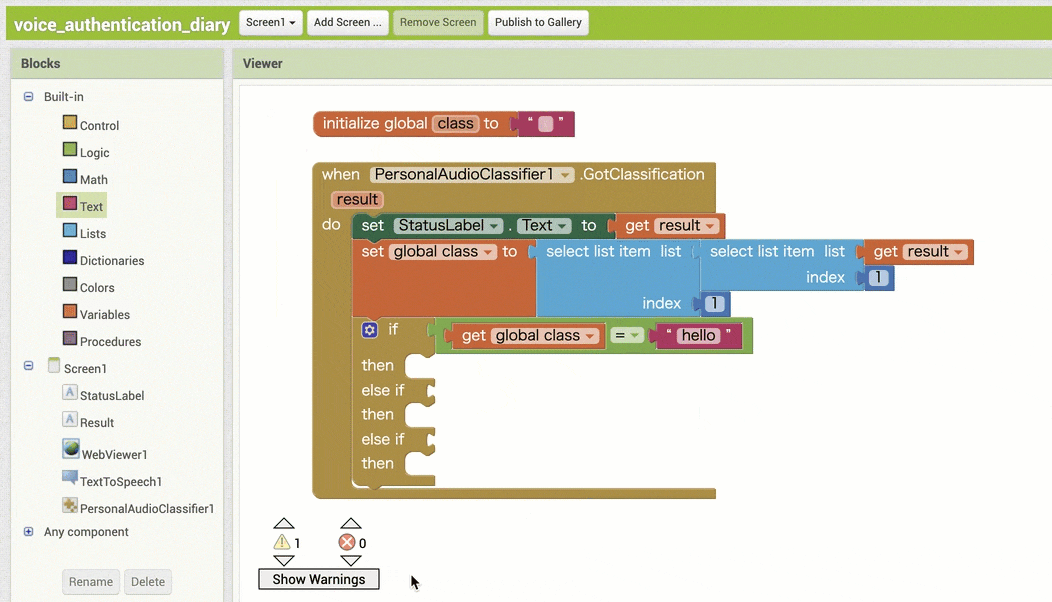
↓条件分岐後の処理の作成
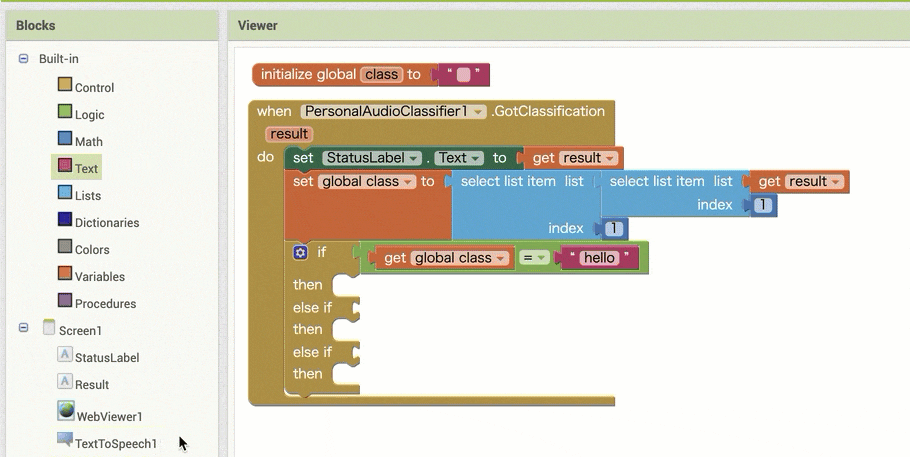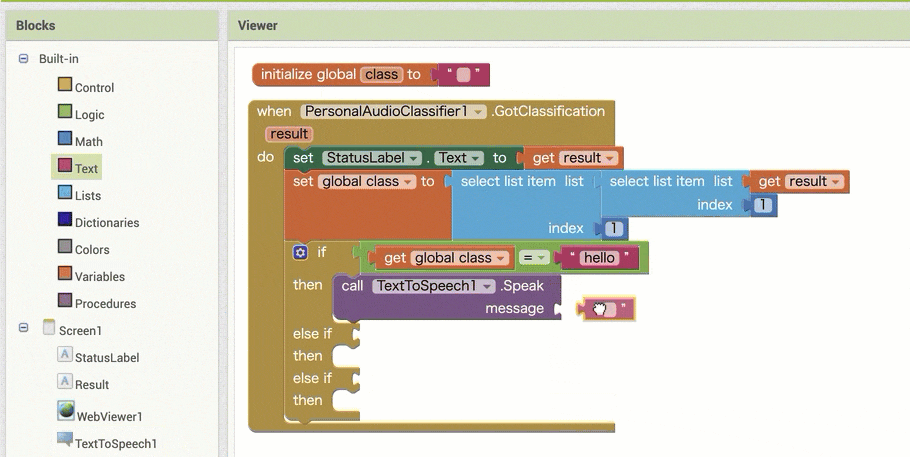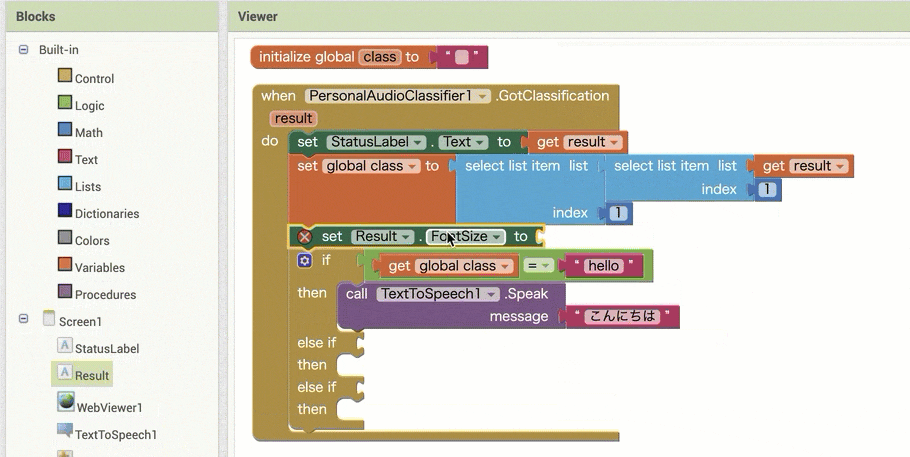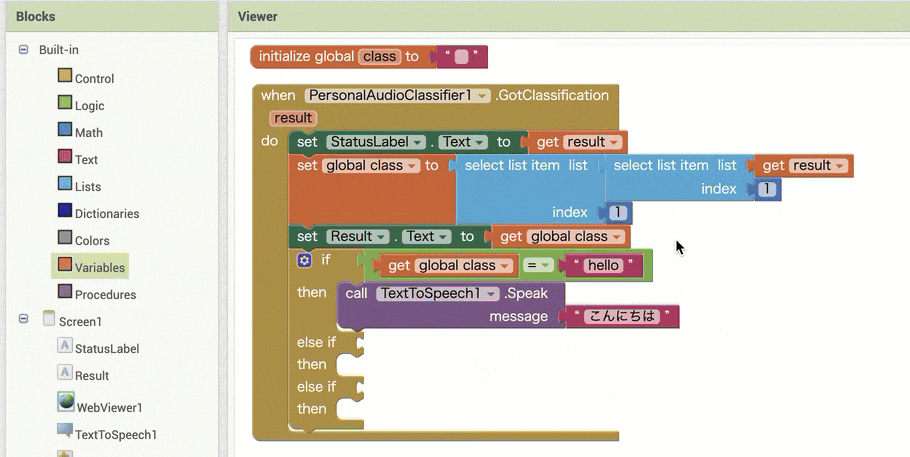
ここまでの手順で以下の状態になっていれば OK です。
ブロックを配置していく(その2)
さらに、認識結果によって分岐する他の 2つの処理も追加します。
基本的に、1つ目の分岐の内容と同じで、ごく一部のみが違うだけなので、最終結果だけを画像で示します。
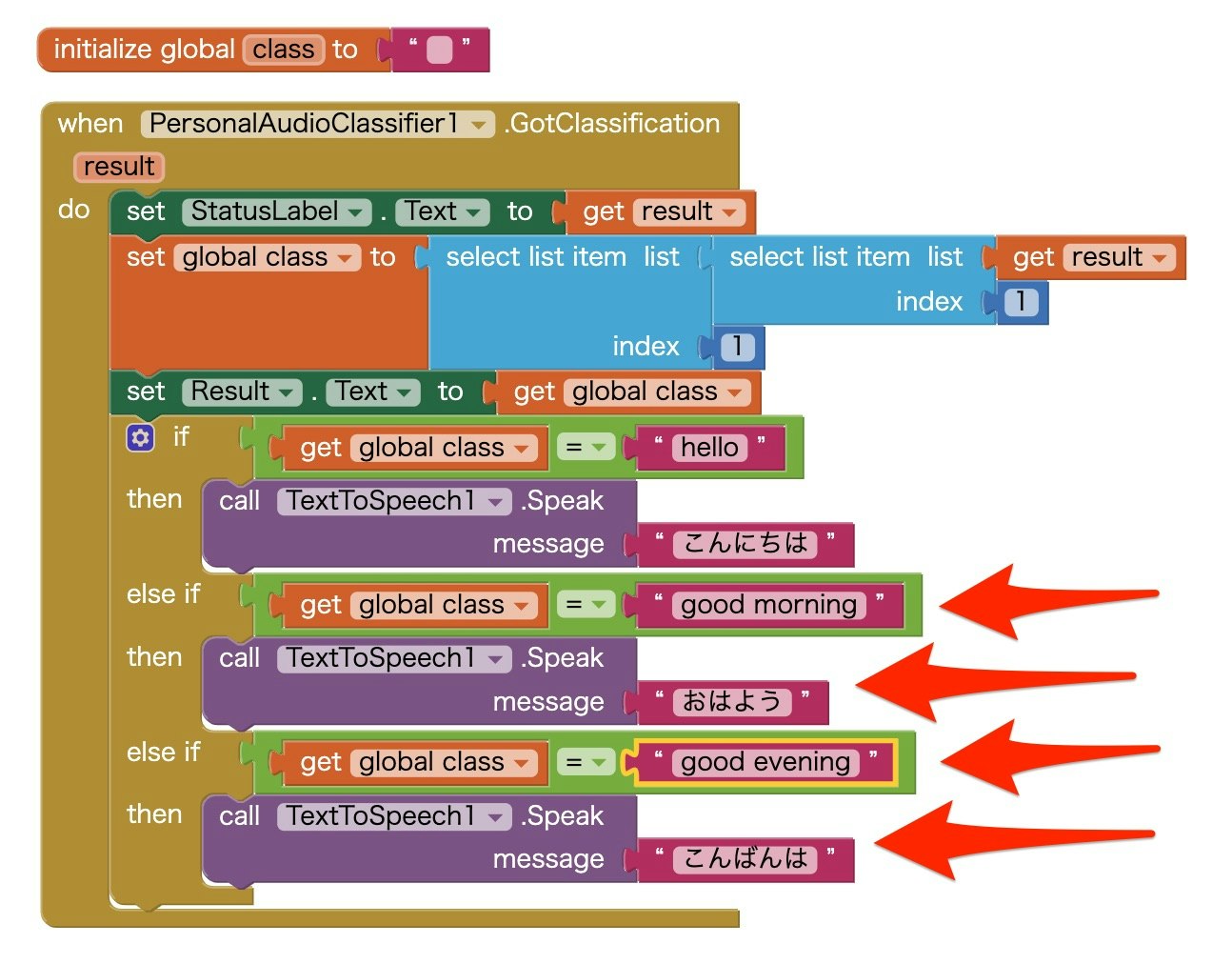
図の中で赤い矢印で示した、条件分岐+音声合成の処理を 2つずつ追加しています。
スマートフォンで動かしてみる
今回のアプリを動かす際の制約
ここまで作ったプログラムをスマートフォンで動かしてみます。
通常、公式ページの「Setting Up App Inventor」というページに書かれた 4つの方法で作ったアプリを試せます。
しかし、今回の場合はチュートリアルに以下の説明がありました。
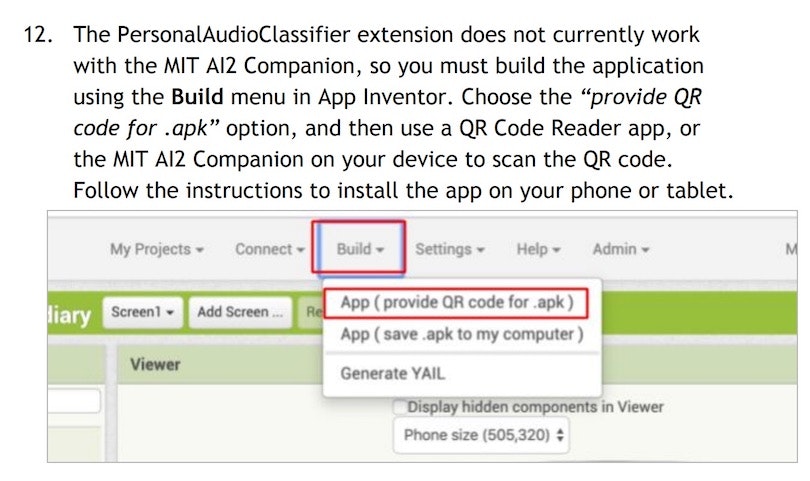
書いてある内容は「apkファイルをビルドしてインストールする方法を使う必要がある」というものです。
今回は使えない手軽にアプリを動かす方法
今回のような制約がなければ、Androidデバイスに以下のアプリを入れておいてから PC と Androidデバイスを同じ Wi-Fi につないでおき、作ったアプリを毎回インストールすることなく Androidデバイス(Androidスマホ等)で動かせる手軽な方法があったりします。
●MIT AI2 Companion - Google Play のアプリ
https://play.google.com/store/apps/details?id=edu.mit.appinventor.aicompanion3&hl=ja&gl=US
「Setting Up App Inventor」というページに書かれた4つの方法の中で、「Option One - RECOMMENDED」と書かれているものです。
それでは、apkファイルをビルドしてインストールする方法で進めていきます。
apkファイルをインストールして試す方法
【!!注意1!!】
ここで行うストア以外からのアプリインストールは、自分が作ったアプリをインストールするためには必要となる方法ですが、この方法は普段のアプリインストールを行う際は基本的に行わないでストアからのインストールを使うのを基本としてください。
【!!注意2!!】
ここで行うストア以外からアプリインストールをする際に、「提供元不明のアプリのインストール」というセキュリティの設定を一時的に許可する必要があります。自分が作ったアプリ・自分が理解して GitHub などからソースコードを入手してビルドした apkファイルをインストールする場合以外は、基本的にこの方法を使わないのがオススメです。
チュートリアルに書かれた、画面情報のメニューにある「Build」を選択し、その中の「App(provide AR code for .apk)」を選択します。
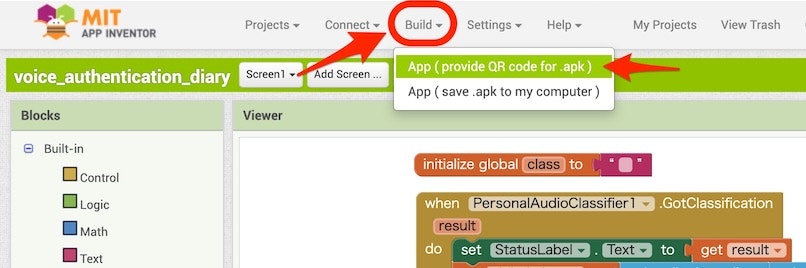
そうすると、作ったアプリの内容をインストールするためのファイルが生成されます。以下のような表示が出ている間は、待っていてください。
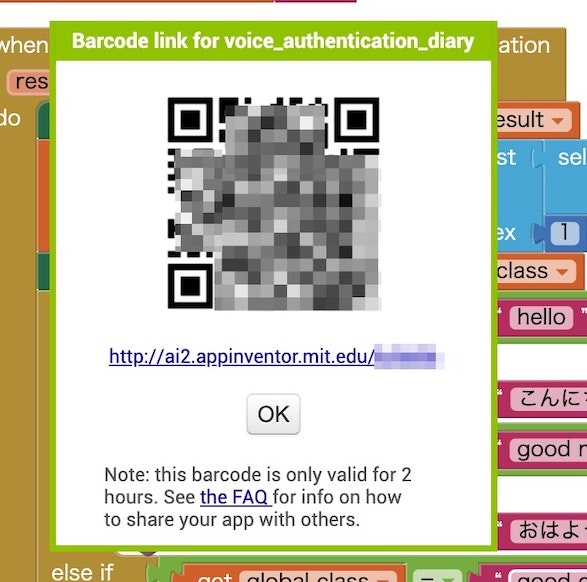
インストール用のファイル(apkファイル)の生成が終わると、以下のように QRコードと URL が表示されるので(※ 以下では QRコードの部分などの一部をマスクしています)、Androidデバイスで QRコードを読み込むか、表示された URL にブラウザでアクセスしてください。
その後は、apkファイルのダウンロードが行われ、apkファイルを使ったアプリのインストールのために、アプリインストールの許可・提供元不明のアプリのインストールなどといった設定を許可をするような操作を行い手順を進めていきます。詳細については、OS のバージョン・端末によって変わるかもしれない部分であるため、ここでは割愛します。
また「提供元不明のアプリのインストール」に関して、公式の開発者向けドキュメントの「提供元不明のアプリとソースに対するユーザーのオプトイン」という部分に、設定変更方法や説明が書かれた部分があります。
個人的には、この公式情報を 1度見ておくことをオススメします。
それと「提供元不明のアプリのインストール」の設定画面について、OS のバージョンごとに異なる画面表示・設定画面をのせている記事があったので、以下に URL などを記載しておきます。
●[Android]Google Playにない「野良アプリ」をインストールするために「提供元不明のアプリ」を許可する - Qiita
https://qiita.com/gumby/items/9e1431b73bdb6b0684d8
インストールがうまくいけば、冒頭に掲載したツイートの動画のように学習モデルを使った音声の識別・音声合成による返答を試すことができます。
ビジュアルプログラミングでAndroidアプリ開発ができる MIT App Inventorで音声の機械学習!
— you (@youtoy) February 21, 2021
「おはよう・こんにちは・こんばんは」の3つを事前に学習させ、その学習モデルを組み込んだAndroidアプリをスマホ上で動かしました。
3つの挨拶を機械学習で認識し、音声合成で同じ挨拶を返す仕組みです。 pic.twitter.com/IO8X1EqAnJ
おわりに
今回の記事では、前回の記事に書いた「音を対象に機械学習を行って作成した学習モデル」を使う Androidアプリの開発などを行いました。
そして、実際に Androidスマホを使った動作確認も行うことができました。
今回のプロジェクトは、アプリを試しに動かす際に apkファイルのインストールが必須という部分があり、最後の最後で手軽さに欠ける部分があるのが個人的には少し残念な点でしたが、その部分は App Inventor で実装する機能に依存した部分のようなので、今後も App Inventor を活用して Androidアプリ開発を身近なものにできればと思います。
(また、久しぶりに Android Studio を使って、Kotlin によるテキストプログラミングでの開発も、ちょっと手を出してみたいと思ったり)
今回の記事に出てくる「提供元不明のアプリのインストール・apkファイル」についての補足
今回の記事に出てくる、セキュリティの設定を変更する必要がある「提供元不明のアプリのインストール」について、またインストールに使う apkファイルについて最後に補足をしておきます。
提供元不明のアプリのインストールに関する話
Google の開発者向け公式ページの「ウェブサイトを通じてリリースする」という項目に、以下の記載があります。

記事の途中で書いたセキュリティリスクの話以外に、ストア以外でのアプリ提供では特定の仕組みを利用できないといった制約もあったりします。
apkファイルについて
以下のウィキペディアのページから説明を引用します。大まかに言うと、アプリに必要なデータがあれこれ詰め込まれたもの、といった感じです。
●APK (ファイル形式) - Wikipedia
https://ja.wikipedia.org/wiki/APK_(%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB%E5%BD%A2%E5%BC%8F)
APK(英: Android Application Package、アンドロイドアプリケーションパッケージ、エーピーケー)とは、Googleによって開発されたAndroid専用ソフトウェアパッケージのファイルフォーマットである。Android Packageとも[1][2]。
JARファイルをベースとしたZIP形式で、アーカイブファイルの一種である。