はじめに
前回はVGG16をFineTuningして、4人の顔画像の分類をしました。
VGG16は、ImageNetの一般物体認識データセットで学習済みのモデルで、1000種類の画像を分類できるモデルです。
つまり、人の顔画像ではなく、一般物体(犬や教会など)の画像を学習したモデルです。
そこで今回は、FaceNetという、2015年にGoogleが発表した顔認識に特化して設計されたニューラルネットワークモデルを利用して、顔画像の特徴を抽出し、クラスタリングします。
こんなことやりたい
顔画像の特徴別に画像をグループ分けするのが目標です。
全体の流れ
まずは全体の流れをざっくり説明します。
下の画像を見てください。
①顔部分を切り取った画像を、FaceNetの学習済みモデルにインプットすると、顔の特徴を多次元ベクトルの形で出力されます。
②多次元データの情報量を出来るだけ損なわせずに縮約する主成分分析を利用して、2次元まで次元削減を行います。
③K-means法を使って、顔の特徴量が近いもの同士でグループ分けをします。

下記のステップで、実際にコーディングしていきます。
【ステップ1】顔画像を準備する
【ステップ2】FaceNetの学習済みモデルを準備する
【ステップ3】顔画像から多次元特徴ベクトルを抽出する
【ステップ4】主成分分析で、多次元特徴ベクトルを二次元にする
【ステップ5】K-means法を用いてクラスタリングする
【ステップ6】結果を視覚化する
【ステップ1】顔画像を準備する
今回利用するモデルは、VGGFace2というデータセットを利用して学習したモデルです。
VGGFace2は、約9,000人分の330万枚の画像からなる大規模なデータです。
顔部分を切り取った写真を、4人×10枚=40枚準備しました。
スクレイピングでGoogle画像検索から画像を取得する方法と、画像から顔部分を抽出し切り抜く方法は、下記の記事でまとめているので、割愛します。
KerasのCNNで、顔認識AIを作って見た〜スクレイピングからモデルまで〜

また、論文によると、ピクセル単位の画像サイズがvalidation rateに与える影響がまとまっています。
160×160=25,600が良さそうだと思い、画像のサイズは160×160pxに統一しました。
| pixels | val-rate |
|---|---|
| 1,600 | 37.8% |
| 6,400 | 79.5% |
| 14,400 | 84.5% |
| 25,600 | 85.7% |
| 65,536 | 86.4% |
【ステップ2】FaceNetの学習済みモデルを準備する
任意のディレクトリで、FaceNetリポジトリをclone して下さい。
最後のlsコマンドで、facenetが格納されていれば、OKです。
$ mkdir facenet-example
$ cd facenet-example
$ git clone https://github.com/davidsandberg/facenet.git
$ ls
こちらから学習済みモデルをダウンロードし、解凍して下さい。
私の場合、下記のようなディレクトリ構造です。
facenet-example
├ facenet
└ README.md
└ src
└ その他色々
├ 20180402-114759
└ 20180402-114759.pb
└ model-20180402-114759.ckpt-275.data-00000-of-00001
└ model-20180402-114759.ckpt-275.index
└ model-20180402-114759.meta
├ FaceNet.ipynb ←(後述するコード)
├ images
└ 〇〇.jpg (40枚の画像)
【ステップ3】顔画像から多次元特徴ベクトルを抽出する
facenet-exampleの配下に、FaceNet.ipynbを作成し、プログラムを実行します。
こちらのブログを参考にさせていただきました。
from facenet.src import facenet
import tensorflow as tf
import numpy as np
from PIL import Image
class FaceEmbedding(object):
def __init__(self, model_path):
# モデルを読み込んでグラフに展開
facenet.load_model(model_path)
self.input_image_size = 160
self.sess = tf.Session()
self.images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
self.embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
self.phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0")
self.embedding_size = self.embeddings.get_shape()[1]
def __del__(self):
self.sess.close()
def load_image(self, image_path, width, height, mode):
image = Image.open(image_path)
image = image.resize([width, height], Image.BILINEAR)
return np.array(image.convert(mode))
def face_embeddings(self, image_path):
image = self.load_image(image_path, self.input_image_size, self.input_image_size, 'RGB')
prewhitened = facenet.prewhiten(image)
prewhitened = prewhitened.reshape(-1, prewhitened.shape[0], prewhitened.shape[1], prewhitened.shape[2])
feed_dict = { self.images_placeholder: prewhitened, self.phase_train_placeholder: False }
embeddings = self.sess.run(self.embeddings, feed_dict=feed_dict)
return embeddings
次に、学習済みモデルを読み込みます。
FACE_MEDEL_PATH = './facenet/src/models/20180402-114759/20180402-114759.pb'
face_embedding = FaceEmbedding(FACE_MEDEL_PATH)
特徴ベクトルを抽出したい画像を準備します。
import glob
faces_image_paths = glob.glob('./images/*.jpg')
顔画像から特徴ベクトルを抽出し、featuresに代入します。
# 顔画像から特徴ベクトルを抽出
features = np.array([face_embedding.face_embeddings(f)[0] for f in faces_image_paths])
print(features.shape)
私の場合、(40,512)と出力されました。
顔画像40枚が、512次元の特徴ベクトルとして抽出されました。
【ステップ4】主成分分析で、多次元特徴ベクトルを二次元にする
512次元の特徴ベクトルを2次元座標にプロットするために、512次元から2次元に主成分分析(PCA)を使って次元削減します。 scikit-learn を用いれば容易にPCAを利用できます。
主成分分析に関する補足
主成分分析(Principal Component Analysis : PCA)とは、多次元データの情報量を出来るだけ損なわせずに縮約する(より少ない次元数で表現する)方法です。
アルゴリズムをざっくり説明すると下記の手順です。
① 全データを特徴空間上にプロットする
② プロットされたデータから重心を求める
③ 求まった重心から、データの分散(ばらつき)が最大となる方向を見つけ、その方向に直線を得る(第一主成分)
※分散が最大になっているということは、元のデータを最も損失なく表現できているという事です。
④ 第一主成分と直交する直線の中で、その直線に各データを射影した際の分散が最大となるような直線を得る(第二主成分)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(features)
reduced = pca.fit_transform(features)
print(reduced.shape)
私の場合、(40, 2)と出力されました。
顔画像40枚、512次元の特徴ベクトル→2次元の特徴ベクトルにされました。
【ステップ5】K-means法を用いてクラスタリングする
それぞれの画像の特徴ベクトルを2次元まで次元削減できました。
次は、K-meansh法を用いて、4つにクラスタリングします。
1人10枚の画像があるわけですが、どれくらい同一人物が同じクラスターになるのか、確認したいと思います。
K-means法に関する補足
K-means法はあらかじめクラスタの数(分けたいグループの数)を決めてクラスタリングする手法です。
① データをいくつのクラスタに分けるか決める(今回は4人なのでK=4)
② 全データに対してランダムにクラスタラベルを割り振る(初期化)
③ 割り振られたラベル毎のデータについて平均を取ることで、K個重心を求める。(重心の更新)
④ 全データに対してK個の重心との距離を求め、それぞれ最も距離が短い重心のクラスタラベルにそのデータを割り当て直す(クラスタラベルの更新)
⑤ ③と④の処理を繰り返し、全データについてクラスタの割当てが変化しなくなった場合、収束したとみなしそこで、学習を終了するこちらを参考にすると、直感的に理解しやすいです。
from sklearn.cluster import KMeans
K = 4
kmeans = KMeans(n_clusters=K).fit(reduced)
pred_label = kmeans.predict(reduced)
【ステップ6】結果を視覚化する
クラスタリングした結果をプロットします。
import matplotlib.pyplot as plt
%matplotlib inline
# クラスタリングした結果をプロット
x = reduced[:, 0]
y = reduced[:, 1]
plt.scatter(x, y, c=pred_label)
plt.colorbar()
plt.show()
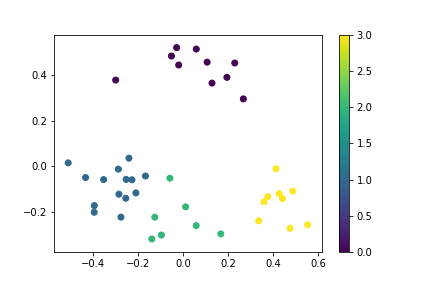
同じ人の顔写真でクラスタリングできているのか、わかりにくいですね。
マーカーを点ではなく、顔画像に変えてみます。
from matplotlib.offsetbox import OffsetImage, AnnotationBbox
def imscatter(x, y, image_path, ax=None, zoom=1):
if ax is None:
ax = plt.gca()
artists = []
for x0, y0,image in zip(x, y,image_path):
image = plt.imread(image)
im = OffsetImage(image, zoom=zoom)
ab = AnnotationBbox(im, (x0, y0), xycoords='data', frameon=False)
artists.append(ax.add_artist(ab))
return artists
x = reduced[:, 0]
y = reduced[:, 1]
fig, ax = plt.subplots()
imscatter(x, y, faces_image_paths, ax=ax, zoom=.2)
ax.plot(x, y, 'ko',alpha=0)
ax.autoscale()
plt.show()
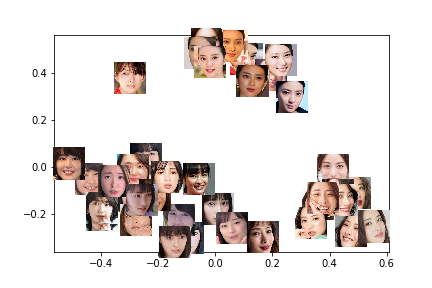
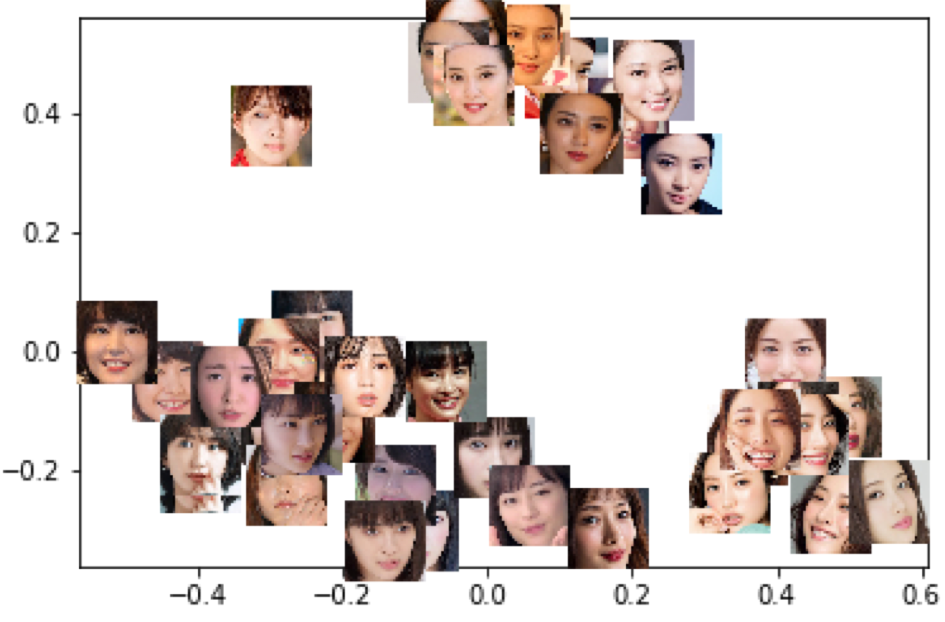
武井咲さんと、石原さとみさんは、上手にクラスタリングできてそうです!
点と画像のプロット結果を並べてみました。
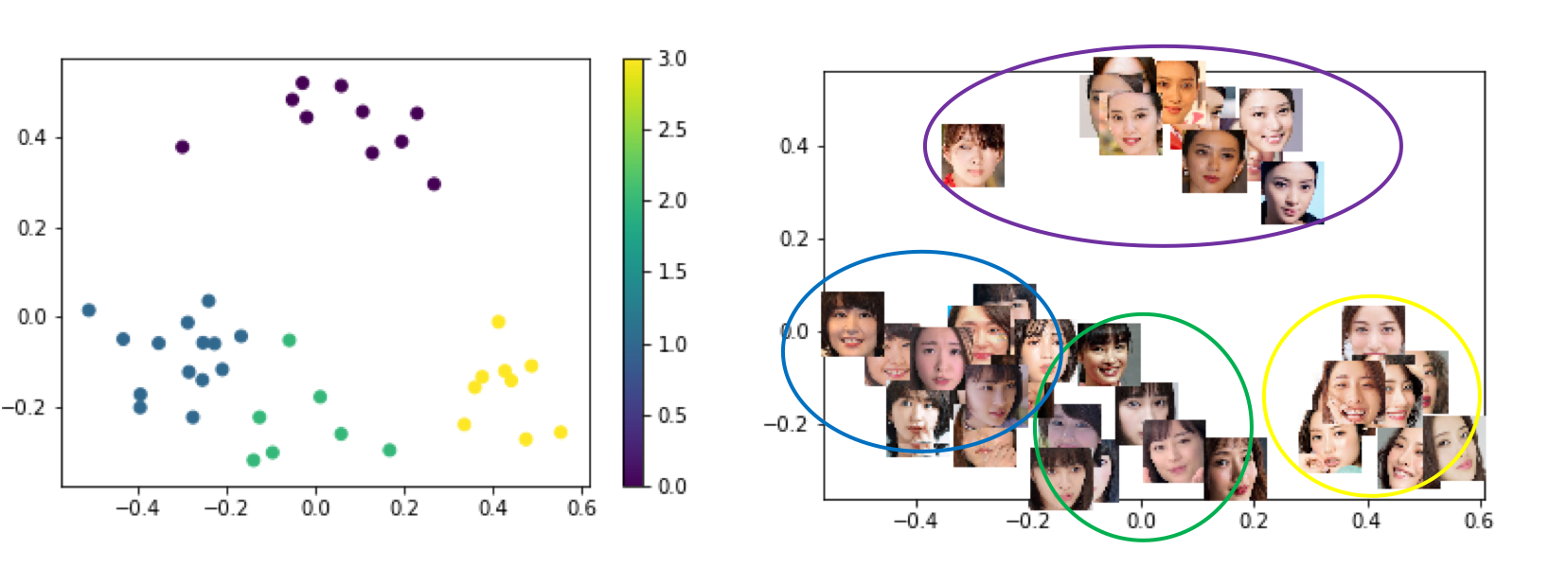
定量的にも評価してみました。
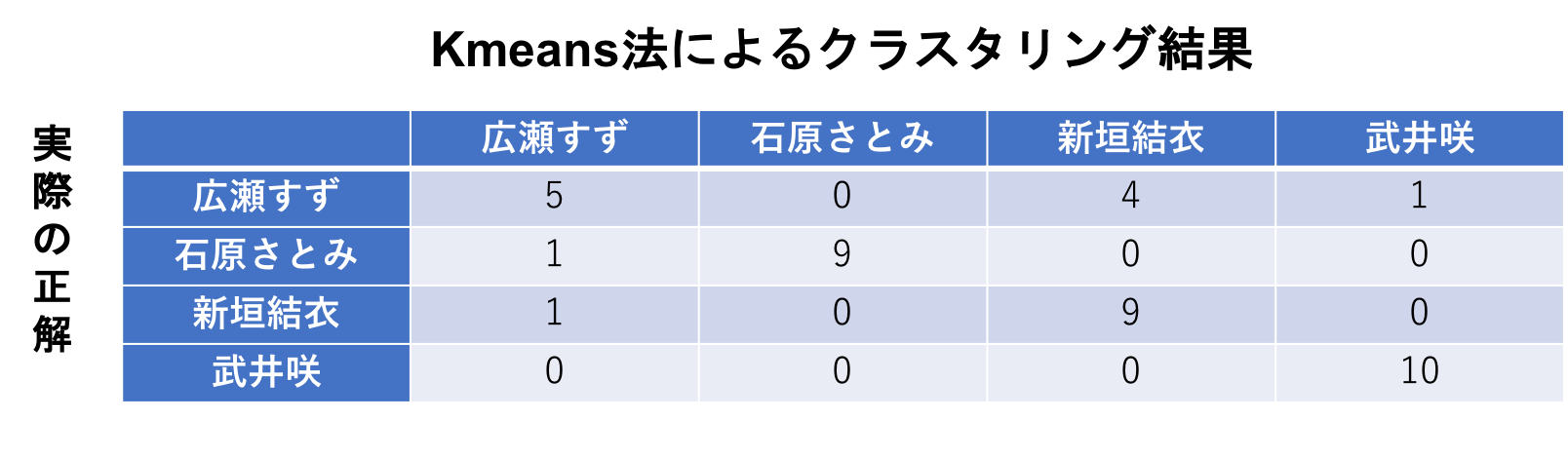
40枚中、同じ方でグループできているのが33枚あるので、82.5%の割合で、同一人物でのクラスタリングができています。
想像以上に精度が高くできていて驚きです。。。
CNNを1から学習させた、あの苦労はなんだったんだ。。。(笑)
表を見ると、広瀬すずさんの画像が新垣結衣さんに分けられてしまうケースが4件(10%)あります。
感想
たったの40枚でしか検証はしていませんが、FaceNetの学習済みモデルが想像以上に凄かったです。
今まで、CNNを学習させたり、VGG16をFineTuningしたりと、分類したい人の画像を数百、数千と必要でした。しかし今回の場合は、もはや学習すらしていないのに、約8割が正しくクラスタリングできた事に驚きでした。
参考文献
FaceNet: A Unified Embedding for Face Recognition and Clustering
Face Recognition using Tensorflow
FaceNetの論文を読んだメモ
FaceNet の学習済みモデルを使って顔画像のクラスタリングを行う