TL;DR
- 誤差関数の値が小さくなるニューラルネットワークの重み$w$を求めるには$w$の勾配$ \nabla E(w) $を計算する必要がある
- $ \nabla E(w) $を効率よく求める方法が「誤差逆伝播」
5.2.1 パラメータ最適化
さて、ここまでの節 (part18) で誤差関数を導出したので、誤差関数を小さくするような重み$w$を求めたい。
しかし、3章4章で扱った線形モデルと異なり、ニューラルネットワークでは出力$y$が式(5.7)のように複雑な非線形性で計算される。
$$
y_k(x, w) = \sigma \left(
\sum_{j=1}^M w_{kj}^{(2)} h
\left(
\sum_{i=0}^D w_{ji}^{(1)} x_i + w_{j0}^{(1)}
\right)
- w_{k0}^{(2)}
\right)
\tag{5.7}
$$
そのため、誤差関数を$w$についての偏微分=0、の方程式は解くことが難しい。
また、$w$を変化させたときの誤差$E(w)$の変化の様子は下図のように複雑になり、$w$の勾配が0になる点(数でいう赤い線の傾きが0)は多く存在する。
- 大域的最小点:誤差関数が最小となる点
- 局所的極小点:誤差関数が最小となる点ではないが、この点の周辺では最小となるような点
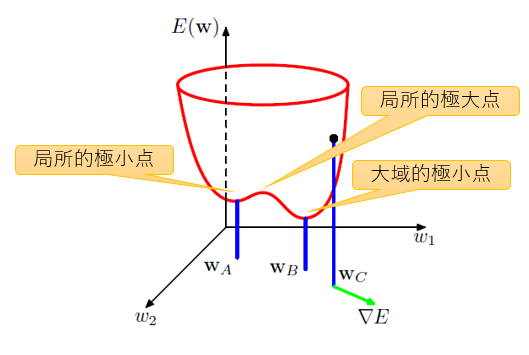
そのため、誤差関数を小さくするような$w$を求めるには数値的な反復手法を使うことになる。
5.2.2 局所二次近似:省略
最適化問題とそれを解くためのテクニックへの理解を得るには、誤差関数の局所二次近似を考えるとよい、とテキストに記載があるが、本節の小難しい話を知らなくても以下の節の理解に困らないので飛ばす。
5.2.3 勾配情報の利用
誤差関数の勾配$ \nabla E(w) $を使うと、誤差関数の極小点を求めるために必要な計算量が減り、効率よく求めることができる1。
5.2.4 勾配降下最適化
ここでは誤差関数の勾配$ \nabla E(w) $が求まったとしよう($ \nabla E(w) $を効率よく求める方法は5.3章「誤差逆伝播」で)。
この勾配情報から数値的な反復手法で$w$を求める単純なアプローチは、重み更新量を負の勾配方向に動かすものである。
$$
w^{ (\tau + 1) } = w^{ (\tau) } - \eta \nabla E( w^{ (\tau) } ) \tag{5.41}
$$
ここで$ \eta $は学習率 (learning parameter) と呼ばれるハイパーパラメータで、1回の反復で$w$をどの程度大きく更新するかを決定するパラメータである。
このアプローチの気持ちは3.1.3節「逐次学習」で導出した確率的勾配降下法と同じである ⇒ part8。
直感的には合理的に見えるが、実際には性能が悪いことが知られている。
そこで、訓練データセットのすべてのデータ点を使って誤差$ \nabla E( w^{ (\tau) } ) $を求めて式(5.41)で$w$を更新する代わりに、1つのデータ点、あるいは(すべてでなく)一部のデータ点集合(ミニバッチ)から誤差$ \nabla E_n( w^{ (\tau) } ) $を求め、データ点/データ集合ごとに$w$を更新するアプローチが用いられる。
5.3 誤差逆伝播
それでは誤差関数の勾配$ \nabla E(w) $を効率よく求める方法である誤差逆伝播 (backprop or backpropagation) を見ていこう。
5.3.1 誤差関数微分の評価
テキストでは何層目かという情報を変数に記載せず一般化しているが、分かりやすさを重視し、以下では記載する
隠れ層が多層あるようなニューラルネットワークを考えよう。
$L-1$層め、$L$層め、$L+1$層めのネットワークを抜き出したものが下図である。
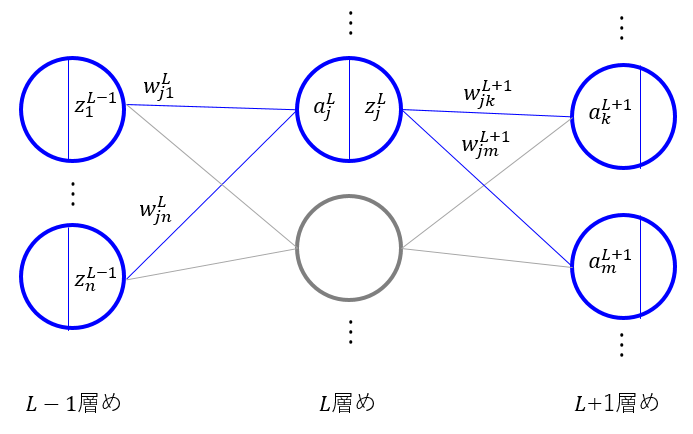
まずは入力層側にデータを入力し、出力層まで計算を行う順伝播について再確認しよう。
5.1節「フィードフォワードネットワーク関数」で見た(⇒part18)ように$L$層めのあるユニット$a_j^L$の値は$L-1$層めのユニットの出力値$ z_*^{L-1} $の線形和で与えられる。
$$
a_j^L = \sum_i w_{ji}^L z_i^{L-1} \tag{5.48}
$$
$ w_{*}^L $は$L-1$層めから$L$層めへの計算に使う重みであることを表し、$ w_{ji}^L $は($L-1$層めの)$i$番目のユニットから($L$層めの)$j$番目のユニットへの重みを表す。
自身の層より1つ浅い層(入力層側)のユニットの出力値の線形和で$a_j^L$を計算した後、シグモイド関数などの非線形関数$ h(\cdot) $によって、自身のユニットの出力値が計算される。
$$
z_j^L = h( a_j^L) \tag{5.49}
$$
この値が$L+1$層めのユニットの値$ a_k^{L+1} $を計算する際に用いられる。この手順が出力層まで繰り返される。
さて、本節の目的は誤差関数の勾配を効率よく求めることなので、あるデータ点に関する誤差 $E_n $の重み$ w_{ji}^L $に関する微分$ \partial E_n / \partial w_{ji}^L $の評価を考えよう。
$ \partial E_n / \partial w_{ji}^L $は$ w_{ji}^L $を(微小に)変化させたときに$ E_n $がどれぐらい変化するかを表す値だが、$ w_{ji}^L $の変化により$ a_j^L $が変化して$ E_n $に影響するということを踏まえて、微積分の連鎖律 (chain rule) という公式を使うとあたかも分数のように式変形ができる:
$$
\frac{ \partial E_n }{ \partial w_{ji}^L } =
\frac{ \partial E_n }{ \partial a_j^L } \frac{ \partial a_j^L }{ \partial w_{ji}^L }
\tag{5.50}
$$
となる。
式(5.48)より、式(5.50)の$ \partial a_j^L / \partial w_{ji}^L $は
$$
\frac{ \partial a_j^L }{ \partial w_{ji}^L } = z_i^{L-1} \tag{5.52}
$$
である。また、式(5.50)の$ \partial E_n / \partial a_j^L $を
$$
\frac{ \partial E_n }{ \partial a_j^L } = \delta_j^L \tag{5.51}
$$
と書くこととする。これらを使って式(5.50)を書き直すと
$$
\frac{ \partial E_n }{ \partial w_{ji}^L } = \delta_j^L z_i^{L-1} \tag{5.53}
$$
となり、$L$層めの$ \delta_j^L $の値と$L-1$層めの$ z_i^{L-1} $の値をかけることで必要な微分の値が得られることが分かる。
また、$ z_i^{L-1} $の値は順伝播方向に計算をする際にすでに求まっている値なので、実質$ \delta_j^L $を計算することで微分の計算が求まることが分かる。
もし$L$層めが出力層で、出力ユニットの活性化関数に恒等写像やシグモイド関数、ソフトマックス関数などと正準連結関数(⇒part16)と呼ばれる種類の関数を用いていれば
$$
\delta_k^L = y_k - t_k \tag{5.54}
$$
で与えられる2。
$L$層めが隠れ層であれば、連鎖律により式変形をしよう。$ \delta_j^L = \partial E_n / \partial a_j^L $は$ E_n $を(微小に)変化させたときに$ a_j^L$がどれだけ変化するかを表す値だが、$ a_j^L$の変化により$ a_k^{L+1} $が変化して $ E_n $に影響する(上図も参照)ことを踏まえて:
$$
\delta_j^L = \frac{ \partial E_n }{ \partial a_j^L }
= \sum_k \frac{ \partial E_n }{ \partial a_k^{L+1} } \frac{ \partial a_k^{L+1} }{ \partial a_j^L }
\tag{5.51}
$$
と変形できる。$L$層めの$j$番目のユニットと結合がある$ L+1 $層めのすべてのユニット$ k $について和をとっていることに注意。
誤差逆伝播の公式
式(5.51)の$ \delta_j^L $を式変形して、誤差逆伝播の公式を導出しよう。
右辺の$ \partial E_n / \partial a_k^{L+1} $は定義より$ \delta_k^{L+1} $と書き直せる。
続いて右辺の$ \partial a_k^{L+1} / \partial a_j^L $を変形しよう。
- $L+1$層めのユニットの入力$ a_k^{L+1} $は$L$層めのユニットの出力$ z_i^L $と重み$ w_{ik}^{L+1} $の線形和$ \sum_i w_{ik}^{L+1} z_i^L $で計算される
- $ z_i^L $は$ a_i^L $に非線形関数$ h(\cdot) $をかけて得られる値
であることを思い出すと:
\begin{align}
\frac{ \partial a_k^{L+1} }{ \partial a_j^L }
= \frac{ \partial ( \sum_i w_{ki}^{L+1} z_i^L) }{ \partial a_j^L }
= \frac{ \partial ( \sum_i w_{ki}^{L+1} h(a_i^L) ) }{ \partial a_j^L }
= h'(a_j^L) w_{kj}^{L+1}
\end{align}
と変形できる。$ w_{ki}^{L+1} h(a_i^L) $は$i \neq j$のときは$a_j^L $と無関係になるので微分すると消えることを利用して、$i$に関してのシグマが消えていることに留意。
以上により式(5.55)を変形すると:
$$
\delta_j^L = h'(a_j^L) \sum_k w_{kj}^{L+1} \delta_k^{L+1} \tag{5.56}
$$
と書ける。これを図示したものが下図。
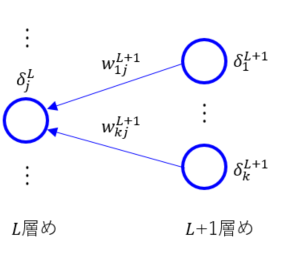
$L$層めの$ \delta $の値が$ L+1 $層めの$ \delta $の値を順伝播と逆向きに伝播させて得られている。
また、$L$層めのユニットと結合している$L+1$層めのユニットについて和(シグマ)をとっていることに注意。
出力層ユニットの$ \delta $の値は式(5.54)で計算できるので、この値を使って左側(入力層側)の$ \delta $の値を再帰的に計算していけばよい。
誤差逆伝播アルゴリズムまとめ
- 入力データ$x_n$をニューラルネットに入れ、下式ですべての隠れユニット/出力層の出力を求める
\begin{align}
a_j^L &= \sum_i w_{ji}^L z_i^{L-1} \tag{5.48} \\
z_j^L &= h( a_j^L) \tag{5.49}
\end{align}
- 出力ユニットの$ \delta $(誤差)を下式で評価
$$
\delta_k^L = y_k - t_k \tag{5.54}
$$
- 下式で誤差を入力層ユニット方向に逆伝播させ、ネットワークすべての隠れユニットの$ \delta $を計算
$$
\delta_j^L = h'(a_j^L) \sum_k w_{kj}^{L+1} \delta_k^{L+1} \tag{5.56}
$$
- 下式で必要な微分を評価
$$
\frac{ \partial E_n }{ \partial w_{ji}^L } = \delta_j^L z_i^{L-1} \tag{5.53}
$$
5.3.2 単純な例:省略
5.3.3 逆伝播の効率
逆伝播に代わる微分を求めるアプローチとして、差分による近似の利用がある。
$$
\frac{ \partial E_n }{ \partial w_{ji} } \simeq \frac{ E_n(w_{ji} + \epsilon ) - E_n(w_{ji}) }{ \epsilon } \tag{5.68}
$$
ここで、$ \epsilon << 1 $である。$ \epsilon \rightarrow 0 $の極限でこの式は微分の定義そのものであることに留意。
この方法の計算量はネットワークの重み(とバイアス)の総数を$W$とすると、$O(W^2)$となる(そういうものと思おう)。
一方、誤差逆伝播の計算量は$O(W)$なので、誤差逆伝播の方が効率が良い。
誤差逆伝播で求めた微分値が正しいかを検算する際に差分による近似値を活用するとよいだろう。
5.3.4 ヤコビ行列
簡単にだけ。
誤差逆伝播の応用としてヘッセ行列を求める例が書いてある。ヤコビ行列とは出力の入力に関する微分であり、
$$
J_{ki} = \frac{ \partial y_k }{ \partial x_i } \tag{5.70}
$$
である。この行列はガウス・ニュートン法と呼ばれる、関数の最小値(極小値)を求める手法などに出てくるようだ。
誤差逆伝播を使うことで、差分による近似値によって微分を求める方法より効率よくヤコビ行列の計算ができる。
一般に訓練済みのニューラルネットワークは非線形になるので、ヤコビ行列の各成分は定数でなく、用いる特定の入力データに依存する。
したがって、入力データが新しくなるたびにヤコビ行列を再評価する必要がある。