はじめに
このページではKubernetes v1.28 における SIG-Apps に関連する変更内容をまとめています。
SIG-AppsはKubernetesのワークロードの扱いなどの変更を主に扱っているため、他のSIGと関係する変更が多くなっております。
- 直近での過去の変更内容は以下になります。
SIG / SIG-Apps とは?
-
SIGとは?
- Special Interest Groups の略称
- 各 SIG には Subproject が与えられていて、 Subproject に対して独立して開発できるようになっています。
- Kubernetes は巨大なプロジェクトなので、各SIG 毎に担当(Subproject)が割り当てられていて、各SIG は独立して開発をしています。
- SIG 間を跨って話し合いをする必要が生じた場合は Working Groups が一時的に作られ、その枠組みの中で話し合うことになります。
-
SIG-Appsとは?
- Apps Special Interest Group の略称
- Kubernetes に対して、application を deploy したりすることに関することが対象。具体的には Pod, ReplicaSet, Deployments, DaemonSet, StatefulSet, Jobs, CronJob が対象。
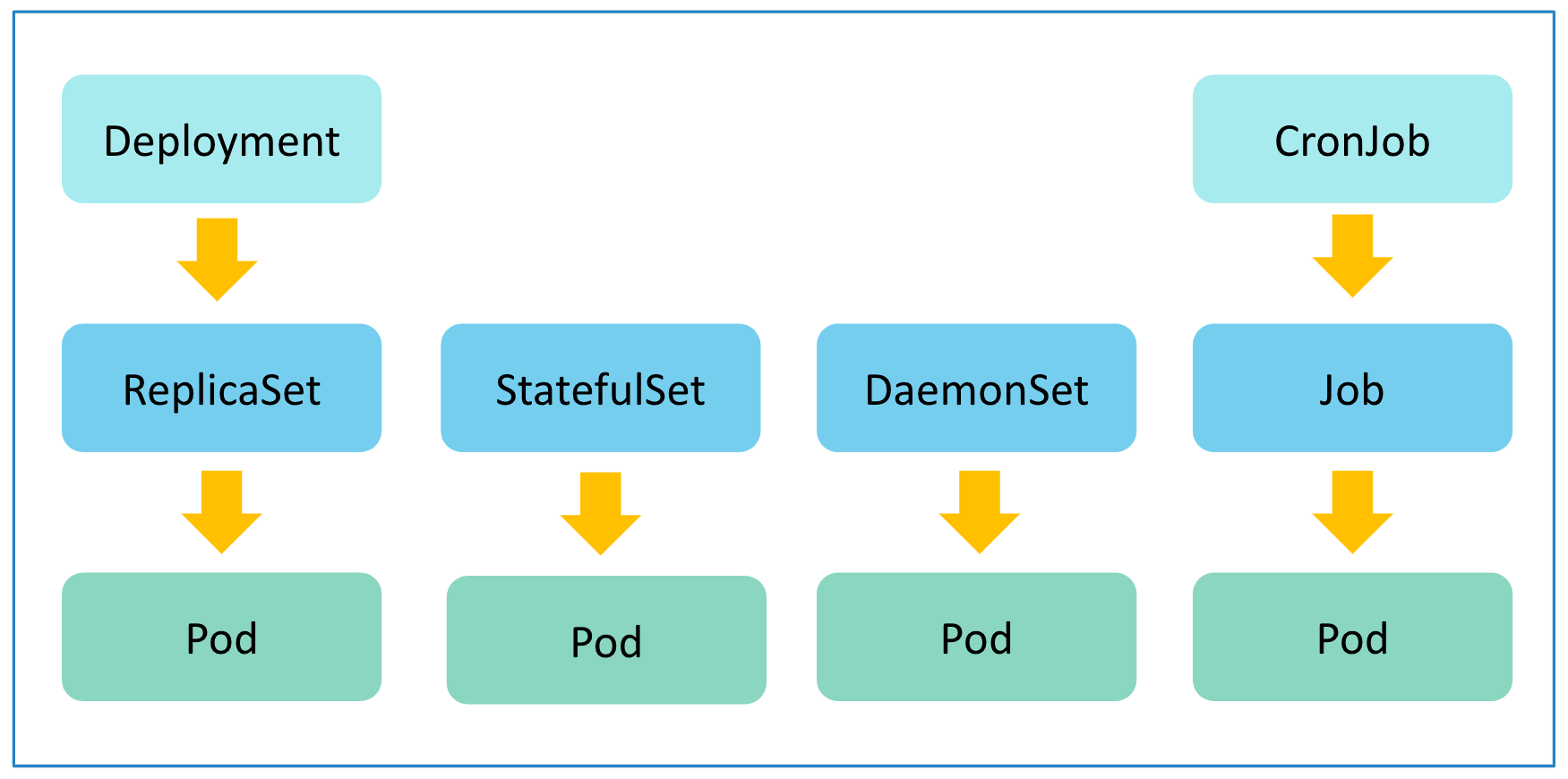
- 詳細について知りたい方はこちらをご参照ください。
SIG-Apps 以外の SIG に関する変更は以下にまとめてありますので、合わせてご参照下さい。
注目の変更
Feature Gatesの中で今回Stageに変更のあったSig-Appsに関連する機能は以下になります。
-
Pod
-
PodIndexLabel:Betahttps://github.com/kubernetes/enhancements/issues/4017
-
-
Job
-
JobBackoffLimitPerIndex:Alphahttps://github.com/kubernetes/enhancements/issues/3850 -
JobPodReplacementPolicy:Alphahttps://github.com/kubernetes/enhancements/issues/3939
-
-
CronJob
-
CronJobsScheduledAnnotation:Betahttps://github.com/kubernetes/enhancements/issues/4026
-
補足:今回の4件は全て1.28で追加された新機能ですが、以下のようにデフォルトの状態が異なるので注意してください。
# 1.28 で初めて追加されましたが Beta で追加されています
PodIndexLabel: {Default: true, PreRelease: featuregate.Beta},
JobBackoffLimitPerIndex: {Default: false, PreRelease: featuregate.Alpha},
JobPodReplacementPolicy: {Default: false, PreRelease: featuregate.Alpha},
# 1.28 で初めて追加されましたが Beta で追加されています
CronJobsScheduledAnnotation: {Default: true, PreRelease: featuregate.Beta},
ref https://github.com/kubernetes/kubernetes/blob/v1.28.0/pkg/features/kube_features.go
Pod
PodIndexLabel
Job と StatefulSet で作成した Pod のラベルに index 番号が付与されるようになります。
1.28 からの新機能ですが Beta として追加されているためデフォルトで有効になります。
- 関連情報
| KEP | KEP-4017 |
|---|---|
| Feature stage | Beta |
| Feature Gate | PodIndexLabel |
| issue | #4017 |
| 参考 | 公式ドキュメントJob,StatefulSet,Well-Known Labels |
詳しい内容の説明 (クリックすると開きます)
- Job の場合
Indexed で Job を作成します。
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
completionMode: Indexed
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
Pod を作成して該当のラベルを確認します。
$ kubectl apply -f job.yaml
$ kubectl get po -l job-name=pi -o yaml
apiVersion: v1
items:
- apiVersion: v1
kind: Pod
metadata:
annotations:
+ batch.kubernetes.io/job-completion-index: "0"
creationTimestamp: "2023-08-24T08:18:11Z"
generateName: pi-0-
labels:
batch.kubernetes.io/controller-uid: 96180273-f2f0-4bf0-ba99-0bfd527b3320
+ batch.kubernetes.io/job-completion-index: "0"
batch.kubernetes.io/job-name: pi
controller-uid: 96180273-f2f0-4bf0-ba99-0bfd527b3320
job-name: pi
以前はアノテーションにしか index の番号がありませんでしたが、ラベルにも同じものが付与されるようになりました。
- StatefulSet
StatefulSet を作成します。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
Pod を作成して該当のラベルを確認します。
$ kubectl apply -f sts.yaml
statefulset.apps/web created
kubectl get po -l app=nginx -o yaml
apiVersion: v1
items:
- apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2023-08-24T08:23:26Z"
generateName: web-
labels:
app: nginx
+ apps.kubernetes.io/pod-index: "0"
controller-revision-hash: web-5d85c59ddf
statefulset.kubernetes.io/pod-name: web-0
name: web-0
:
index の番号がラベルに付与されていることを確認できます。
こちらの方は Job と違いアノテーションの方には index の番号が付与されません。
Job
JobBackoffLimitPerIndex
Index 付きの Job を作成した時に backoffLimit の設定が Job 全体で一つしか設定できませんでしたが、Index 単位で制御できるようになりました。
- 関連情報
| KEP | KEP-33850 |
|---|---|
| Feature stage | Alpha |
| Feature Gate | JobBackoffLimitPerIndex |
| issue | #3850 |
| 参考 | 公式ドキュメント |
Index 付きの Job を作成する際(completionMode=Indexed)に以下の 2 つのパラメータを使って Index 単位で Job が作成した Pod が失敗できる回数を設定できるようになります。
-
backoffLimitPerIndex: Index 単位での Pod が失敗した際の backoffLimit の数。Index 毎の Pod の失敗を許容する数を制御します。 -
maxFailedIndexes: Job に対して許容する Index の失敗数。失敗した Index 数がこの値に達した時点で Job が新規に Pod を作成しなくなります。この値を completions の値より大きくした場合は全ての Index 付きの Pod が作成されます。
詳しい内容の説明 (クリックすると開きます)
- Job を作成します。
apiVersion: batch/v1
kind: Job
metadata:
name: job-backoff-limit-per-index-example
spec:
completions: 4
parallelism: 1 # 状態の変化がわかりやすいように並列数を 1 に設定しておきます。
+ completionMode: Indexed # required for the feature
+ backoffLimitPerIndex: 1 # maximal number of failures per index
+ maxFailedIndexes: 2 # maximal number of failed indexes before terminating the Job execution
template:
spec:
+ restartPolicy: Never # required for the feature
containers:
- name: example
image: python
command:
- python3
- -c
- |
import os, sys
print("Hello world")
+ if int(os.environ.get("JOB_COMPLETION_INDEX")) % 2 == 0: # index番号に応じて失敗するようにします。
sys.exit(1)
$ kubectl apply -f job.yaml
job.batch/job-backoff-limit-per-index-example created
$ kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/job-backoff-limit-per-index-example 2/4 4m11s 4m11s
NAME READY STATUS RESTARTS AGE
pod/job-backoff-limit-per-index-example-0-8qvgm 0/1 Error 0 3m58s
pod/job-backoff-limit-per-index-example-0-rpjlk 0/1 Error 0 4m11s
pod/job-backoff-limit-per-index-example-1-cbqdl 0/1 Completed 0 3m53s
pod/job-backoff-limit-per-index-example-2-jv56w 0/1 Error 0 3m48s
pod/job-backoff-limit-per-index-example-2-ndjqx 0/1 Error 0 3m35s
pod/job-backoff-limit-per-index-example-3-tgkq8 0/1 Completed 0 3m30s
backoffLimitPerIndex=1 がなので、Index 付きの Pod が失敗した場合に、同一の Index が付与された Pod がもう一回だけ作成されていることがわかります。
maxFailedIndexes=2 なので backoffLimitPerIndex の制限に達した Index の数が 2 に達した時点で新規に Pod を作成しなくなったことが確認できます。今回は parallelism=1 なので、失敗した Index の数がちょうど 2 つになっていますが、並列数をもっと増やした場合は、失敗した Index の数が 2 以上になることもあります。あくまで条件に達した段階で Job が停止する機能になります。
- Job の状態を確認します。
$ kubectl get job -l job-name=job-backoff-limit-per-index-example -o yaml
apiVersion: v1
items:
- apiVersion: batch/v1
kind: Job
:
status:
+ completedIndexes: 1,3
conditions:
- lastProbeTime: "2023-08-24T09:40:58Z"
lastTransitionTime: "2023-08-24T09:40:58Z"
+ message: Job has failed indexes
+ reason: FailedIndexes
status: "True"
type: Failed
+ failed: 4
+ failedIndexes: 0,2
ready: 0
startTime: "2023-08-24T09:40:11Z"
+ succeeded: 2
terminating: 0
uncountedTerminatedPods: {}
status には failedIndexes が増えていて、上記の status あたりを見ることによって Job がどういう状態になっているかわかるようになります。
今回の例だと failed=4 なので、未指定時のデフォルト値である backoffLimit=6 を超過していないので BackoffLimitExceeded で失敗していませんが、backoffLimit の制限は以前のままなので、backoffLimitPerIndex を利用するときは注意が必要です。
今回、2件のパラメータが増えたのでそれぞれのエラーメッセージが追加されて、Job 失敗時のエラーメッセージは以下のようになりました。
| reason | message | memo |
|---|---|---|
| FailedIndexes | Job has failed indexes | new! |
| MaxFailedIndexesExceeded | Job has exceeded the specified maximal number of failed indexes | new! |
| BackoffLimitExceeded | Job has reached the specified backoff limit | |
| DeadlineExceeded | Job was active longer than specified deadline |
JobPodReplacementPolicy
Job は既に作成している Pod が Terminating (deletion timestamp が Pod に記録されている)か Faild (status.phase=Failed) 時にすぐに代わりの Pod を作成していましたが、.spec.podReplacementPolicy=Failed を設定することにより、Faild の時のみに代わりの Pod を作成することができるようになりました。
- 関連情報
| KEP | KEP-3939 |
|---|---|
| Feature stage | Alpha |
| Feature Gate | JobPodReplacementPolicy |
| issue | #3939 |
| 参考 | 公式ドキュメント |
Terminating の Pod というのは完全にプロセスが動作を停止しているわけではなく、以下の図から分かるように preStop や SIGTERM に対応する処理を実施しています。この状態で新規の Pod が作成されると .spec.parallelism で指定した数よりも多くの Pod が動作している状態になります。これが GPU などの限られたリソースを使用する Pod の場合に期待した動作にならないということで追加されました。

StatefulSet の podManagementPolicy=OrderedReady や DaemonSet の maxSurge=0 のような状態を Job で実現するための機能になります。 ただ、 Deployment には該当する機能がないため KEP-3973 の中で現在検討中になります。
既存の以下の機能を使用すれば、成功するまで実行するということはできます。
-
backoffLimit
失敗の許容回数を決めれるので、成功するまで繰り返すようにできますが、 Job の faild のカウント数は上昇します。 -
Pod failure policy
特定の Exit Code を指定して faild にカウントされないようにすることが可能です。ただし、アプリケーション側で失敗時の Exit Code を管理する必要があるのと、Pod の失敗自体を抑制はできません。
JobPodReplacementPolicyを用いると、そもそも該当の Pod が起動するときに失敗すること自体を抑制できることが特徴になります。
詳しい内容の説明 (クリックすると開きます)
-
podReplacementPolicy=TerminatingOrFailed(デフォルトの動作)
Job を作成します。
apiVersion: batch/v1
kind: Job
metadata:
name: busybox
spec:
completions: 3
+ parallelism: 1 # 状態の変化がわかりやすいように並列数を 1 に設定しておきます。
+ podReplacementPolicy: TerminatingOrFailed # 未指定の場合のデフォルト値で、既存の動作と同じになります。
template:
metadata:
deletionGracePeriodSeconds: 70
spec:
containers:
- name: busybox
image: busybox
command: ["sleep", "60"]
+ lifecycle:
+ preStop:
+ exec:
+ command: ["sleep", "60"] # 検証しやすいように設定しています
restartPolicy: Never
実行中の Pod を削除することで Terminating 状態を意図的に発生して確認します。
# Job を作成します
$ kubectl apply -f job.yaml
job.batch/busybox created
# Pod が実行中なことを確認します、
$ kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/busybox 0/3 14s 14s
NAME READY STATUS RESTARTS AGE
pod/busybox-lkqgn 1/1 Running 0 14s
# Pod を delete することで意図的に Terminating にします。
kubectl delete po -l job-name=busybox
pod "busybox-lkqgn" deleted
# 既存の Pod は Terminating ですが、新規の Pod が作成されることが確認できます。
$ kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/busybox 0/3 36s 36s
NAME READY STATUS RESTARTS AGE
+ pod/busybox-fgh6g 0/1 ContainerCreating 0 1s
- pod/busybox-lkqgn 1/1 Terminating 0 36s
busybox-lkqgn は Terminating ですが、preStop の処理を実行中なので、parallelism=1 より多くの Pod が動作している状態が発生しています。
podReplacementPolicy=Failed
Job を作成します。
apiVersion: batch/v1
kind: Job
metadata:
name: busybox
spec:
completions: 3
+ parallelism: 1 # 状態の変化がわかりやすいように並列数を 1 に設定しておきます。
+ podReplacementPolicy: Failed # 今回、新しく追加された機能になります
template:
metadata:
deletionGracePeriodSeconds: 70
spec:
containers:
- name: busybox
image: busybox
command: ["sleep", "60"]
+ lifecycle:
+ preStop:
+ exec:
+ command: ["sleep", "60"] # 検証しやすいように設定しています
restartPolicy: Never
実行中の Pod を削除することで Terminating 状態を意図的に発生して確認します。
# Job を作成します
$ kubectl apply -f job.yaml
job.batch/busybox created
# Pod が実行中なことを確認します、
$ kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/busybox 0/3 9s 9s
NAME READY STATUS RESTARTS AGE
pod/busybox-cvztl 1/1 Running 0 9s
# Pod を delete することで意図的に Terminating にします。
kubectl delete po -l job-name=busybox
pod "busybox-cvztl" deleted
# 既存の Pod は Terminating ですが、新規の Pod が作成されません
$ kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/busybox 0/3 42s 42s
NAME READY STATUS RESTARTS AGE
+ pod/busybox-cvztl 1/1 Terminating 0 42s
# 既存の Pod が削除された後で、新規の Pod が作成されることを確認できます
$ kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/busybox 0/3 66s 66s
NAME READY STATUS RESTARTS AGE
+ pod/busybox-b9pk5 1/1 Running 0 6s
CronJob
CronJobsScheduledAnnotation
CronJob で作成された Job のアノテーションに CronJob がスケジュールした時刻が付与されるようになります。
1.28 からの新機能ですが Beta として追加されているためデフォルトで有効になります。
- 関連情報
| KEP | KEP-4026 |
|---|---|
| Feature stage | Alpha |
| Feature Gate | CronJobsScheduledAnnotation |
| issue | #4026 |
| 参考 | 公式ドキュメント |
詳しい内容の説明 (クリックすると開きます)
- CronJob を作成します。
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/5 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
作成された Job の該当のアノテーションを確認します。
$ kubectl apply -f cronjob.yaml
cronjob.batch/hello created
$ kubectl get cronjob,job
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob.batch/hello */5 * * * * False 0 4m13s 4m33s
NAME COMPLETIONS DURATION AGE
job.batch/hello-28214435 1/1 9s 4m13s
$ kg job -o yaml
apiVersion: v1
items:
- apiVersion: batch/v1
kind: Job
metadata:
annotations:
+ batch.kubernetes.io/cronjob-scheduled-timestamp: "2023-08-24T08:35:00Z"
creationTimestamp: "2023-08-24T08:35:00Z"
generation: 1
labels:
batch.kubernetes.io/controller-uid: 48372461-9fe8-4a5d-ace3-5713aeebccb9
batch.kubernetes.io/job-name: hello-28214435
controller-uid: 48372461-9fe8-4a5d-ace3-5713aeebccb9
job-name: hello-28214435
Job が Cronjob によってスケジュールされたタイムスタンプがアノテーションに付与されていること確認できます。
通常のケースだと既存の Job の creationTimestamp を確認すれば十分だと思いますが、
v1.28 Release Notes
v1.28 Release Notes の中で SIG-Apps に関するものについて以下に和訳したものを記載します。
がついた文章は、CHANGELOGの公式内容ではなく筆者の補足です。
 Deprecation(非推奨)
Deprecation(非推奨)
-
Kube-controller-manager の
--volume-host-cidr-denylistと--volume-host-allow-local-loopbackのフラグが非推奨になりました。 (#118128, @carlory) [SIG API Machinery, Apps, Network, Node, Storage and Testing] [sig/network,sig/storage,sig/node,sig/api-machinery,sig/apps,sig/testing] -
tracking annotation が validation と defaulting が削除されました。 (#117633, @kannon92) [sig/apps]
-
JobTrackingWithFinalizers の機能が GA になるまでの間は Job のアノテーションに
batch.kubernetes.io/job-trackingが付与されていましたがそれが付かなくなるという話になります。 - https://qiita.com/yosshi_/items/95b8a38ad1c44a0266bd#job-tracking-with-finalizers
-
-
NetworkPolicyStatusに関する feature 削除されました。 (#115843, @rikatz) [sig/network,sig/api-machinery,sig/apps,sig/testing,sig/architecture] -
Indexed Job の completions 数が 10^5 以上で parallelism 数が 10^4 となる巨大な Indexed Job が失敗した場合に Kubernetes が Job の終了を正しくトラッキングできない可能性があります。それらの制限を超過する Job の manifest を作成する際に警告を出すようにしました。 (#118420, @alculquicondor) [SIG Apps] [sig/apps]
-
completions=100000かつparallelism=10000の Indexed Job というのは中々ないと思います。変更の理由自体もそういうユースケースがあったというのではなく、理論上発生しうるので警告しましたという形で追加されいます。
-
 API Changes(変更)
API Changes(変更)
-
Indexed Job の completions 数が 10^5 以上で parallelism 数が 10^4 となる巨大な Indexed Job が失敗した場合に Kubernetes が Job の終了を正しくトラッキングできない可能性があります。それらの制限を超過する Job の manifest を作成する際に警告を出すようにしました。 (#118420, @alculquicondor) [SIG Apps] [sig/apps]
-
loadbalancer status ingress に
IP modeフィールドが追加されました。 (#118895, @RyanAoh) [sig/network,sig/api-machinery,sig/apps,sig/testing,sig/cloud-provider]-
service.status.loadBalancer.ingressにIP modeが増えてVIPとかProxyのような値がはいるようになります。 - 詳細についてはKEP-1860を参照ください。
-
-
CronJobs でスケジュールされた Job のオブジェクトに
batch.kubernetes.io/cronjob-scheduled-timestampのアノテーションが追加されるようになりました。 (#118137, @helayoty) [sig/apps] -
Job API に
BackoffLimitPerIndexalpha として追加されました。 (#119294, @mimowo) [sig/api-machinery,sig/apps] -
cgroups v2 利用する際に、
memory.oom.group経由で container cgroups の cgroup aware OOM killer が有効化されます。これにより cgroup ないのプロセスは1つの unit として扱われ、OOM kill が発生した際に、cgroup 内のプロセスが同時に kill されるようになります。 (#117793, @tzneal) [SIG Apps, Node and Testing] [sig/node,sig/apps,sig/testing] -
Indexed Job pods に completion index の label が追加されます。 (#118883, @danielvegamyhre) [SIG Apps] [sig/apps]
-
PersistentVolumes に新しく
LastPhaseTransitionTimeフィールドが追加されました。このフィールドはボリュームが最後に phase を移行した時刻が記録されます。 (#116469, @RomanBednar) [sig/storage,sig/node,sig/api-machinery,sig/auth,sig/apps,sig/testing,sig/release] -
Pods に
hostNetwork: trueが設定され ports が宣言されている場合にhostPortフィールドが自動で設定されます。以前の挙動は Deployment, DaemonSet その他の workload API の PodTemplate にhostPortが設定されている場合に実際の Pod が作成されていました。もしこの状態で問題が発生した場合はDefaultHostNetworkHostPortsInPodTemplatesfeature gate を true にすると元の挙動に戻ります。その際には kubernetes の bug として報告してください。(#117696, @thockin) [SIG Apps] [sig/apps] -
ValidatingAdmissionPolicyとValidatingAdmissionPolicyBindingの API がv1beta1に昇格しました。(#118644, @alexzielenski) [SIG API Machinery, Apps and Testing] [sig/api-machinery,sig/apps,sig/testing] -
ValidtaingAdmissionPolicyfeature gate が beta になりました。これにデフォルトで有効化されるようになります。 (#119409, @alexzielenski) [sig/storage,sig/node,sig/api-machinery,sig/auth,sig/apps,sig/instrumentation,sig/testing,sig/release] -
pvc.StatusからresizeStatusenum が削除されAllocatedResourceStatusにリプレイスされます。 (#116335, @gnufied) [SIG API Machinery, Apps, Auth, Node, Storage and Testing] [sig/storage,sig/node,sig/api-machinery,sig/auth,sig/apps,sig/testing] -
WindowsHostProcessContainersfeature-gate が削除されました。(#117570, @marosset) [SIG API Machinery, Apps, Auth, Node and Windows] [sig/node,sig/api-machinery,sig/auth,sig/apps,sig/windows] -
PodFailurePolicyfeature-gate level のコメントが alpha から beta に変わるので修正されました。 (#117802, @kerthcet) [SIG API Machinery and Apps] [sig/api-machinery,sig/apps] -
StatefulSet pods に pod index が label に
statefulset.kubernetes.io/pod-indexとして付与されるようになりました。 (#119232, @danielvegamyhre) [SIG Apps] [sig/apps] -
local apiserver が version skew や local apiserver で無効化されている api のリクエストの問題で serve できない時、peer kube-apiserver へのリクエストを proxy でサポートします。(#117740, @Richabanker) [SIG API Machinery, Apps, Auth, Cloud Provider, Network, Node and Testing] [sig/network,sig/node,sig/api-machinery,sig/auth,sig/apps,sig/testing,sig/cloud-provider]
-
Job で
BackoffLimitPerIndexがサポートされました。 (#118009, @mimowo) [sig/api-machinery,sig/apps,sig/testing] -
ResourceClaims の名前は ResourceClaimTemplate から作られます。 ベースの名前はまだ
<pod>-<claim name>ですが衝突を避けるためにランダムで suffix がつくようになります。 (#117351, @pohly) [SIG API Machinery, Apps, Auth, Node, Scheduling and Testing] [sig/scheduling,sig/node,sig/api-machinery,sig/auth,sig/apps,sig/testing] -
新しく "SidecarContainers" の feature gate が利用できるようになります。 この機能により sidecar containers が導入されます。 新しいタイプの init container は他の containers の前に開始されますが、Pod の lifecycle の全期間で動き続け、pod の termination をブロックしません。(#116429, @gjkim42) [SIG API Machinery, Apps, Node, Scheduling and Testing] [sig/scheduling,sig/node,sig/api-machinery,sig/apps,sig/testing]
-
PodFailurePolicyの feature-gate のコメントが修正されました。 (#118278, @mimowo) [sig/apps] -
kube-controller-manager:LegacyServiceAccountTokenCleanUpfeature gate が alpha で利用できるようにあります。(デフォルトではオフ) 有効化した場合はlegacy-service-account-token-cleanerが--legacy-service-account-token-clean-up-period(デフォルト1年) で指定した期間を過ぎた service account token secrets をループして削除します。ServiceAccount オブジェクトのリストの.secretsから参照され、pods からは参照されません。(#115554, @yt2985) [sig/api-machinery,sig/auth,sig/apps,sig/testing,sig/release]
 Feature(機能追加)
Feature(機能追加)
-
kube-controller-managerに--concurrent-cron-job-syncsフラグを追加して、cron job controller の workers 数を指定できるようになります。 (#117550, @borgerli) [sig/apps]-
デフォルトの cron job controller の workers 数は5に設定されていますが、クラスタ内で5000を超える CronJob を実行するケースで処理が出てきたので変更できるようになりました。
-
#117138で job controller に
--concurrent-job-syncsも増えたので以下の 2 つのフラグが Job の Controller 用にkube-controller-managerに追加されました。--concurrent-cron-job-sync (default 5)--concurrent-job-syncs (default 5)
-
-
Pods の podgc を
PodReplacementPolicyかPodDisruptionでハンドリングできるようになります。 (#118772, @kannon92) [sig/apps,sig/testing] -
attach detach controller の
attachdetach_controller_forced_detachesのメトリクスに reason が追加されました。(#119185, @xing-yang) [sig/storage,sig/apps] -
pod
hostNetworkfield selector のサポートが追加されました。 (#110477, @halfcrazy) [SIG Apps and Node] [sig/node,sig/apps] -
PodRecreationPolicyが実装されてことにより、既に存在している Pod が完全に終了するまで、新しい Pod の作成を待つことができるようになります。 (#117015, @kannon92) [sig/api-machinery,sig/apps,sig/testing] -
Dynamic resource allocation: claim が
wait for first consumerallocation (デフォルトの動作) を使用している場合、 pod が使用した後に割り当てが解除されるようになります。次のポッドが以前のスケジュール決定の影響を受けず、本当に必要でない限りリソースが割り当てられたままにならないことが保証されます。 claim への割り当てを継続したい場合は "immediate allocation." を使用します。 (#118936, @pohly) [sig/node,sig/apps,sig/testing] -
Kube-controller-manager: dynamic resource controller は pod が作成されると scheduler が無視するように処理し(spec.nodeName がセットされる) し、delayed resource claim allocation を実施し pod の要求を予約します。 (#118209, @pohly) [SIG API Machinery, Apps, Auth, Node and Testing] [sig/node,sig/api-machinery,sig/auth,sig/apps,sig/testing]
-
pod-security-admissionは contextual logging を使うように移行しました。(#114471, @Namanl2001) [SIG Apps and Auth] [sig/auth,sig/apps] -
Job controller (
kube-controller-managerに含まれる)は contextual logging を使うように移行しました。(#116910, @fatsheep9146) [SIG API Machinery, Apps and Testing] [sig/api-machinery,sig/apps,sig/testing] -
EndpointSliceとEndpointSliceMirroringcontrollers (kube-controller-managerに含まれる)は contextual logging を使うように移行しました。(#115295, @Namanl2001) [SIG API Machinery, Apps, Network and Testing] [sig/network,sig/api-machinery,sig/apps,sig/testing] -
non-graceful nodeshutdown は GA になりました。 (#118228, @carlory) [sig/storage,sig/apps,sig/testing] -
EndpointSlicereconciler の新しい staging repo が作成されました。 (#118953, @mskrocki) [sig/network,sig/apps,sig/release] -
Scheduler は scheduling cycle が始まるまで、handlers の同期完了を待つようになりました。 (#116729, @AxeZhan) [sig/scheduling,sig/apps,sig/testing]
-
webhook authorizers に送られる SubjectAccessReview のリクエストの
spec.resourceAttributes.versionが未設定の場合はデフォルトで*設定されるようになりました。 (#116937, @AxeZhan) [SIG Apps and Auth] [sig/auth,sig/apps] -
ExpandedDNSConfigfeature が GA になりました。 'ExpandedDNSConfig' feature がデフォルトでロックされ v1.30 で
削除予定になります。これを明示的に有効化していた場合はその設定を削除してください。(#116741, @gjkim42) [SIG Apps, Network and Node] [sig/network,sig/node,sig/apps] -
scheduler interface と cache methods が contextual logging を利用するように更新されました。 (#116849, @mengjiao-liu) [sig/scheduling,sig/apps,sig/instrumentation,sig/testing]
-
pod が完了もしくは実行されなくなった場合に
ResourceClaimsは他の Pod が再利用するか削除されます。 (#118817, @pohly) [sig/node,sig/api-machinery,sig/auth,sig/apps,sig/testing] -
RetroactiveDefaultStorageClassfeature が stable にデフォルトで有効化されます。 (#118102, @RomanBednar) [sig/storage,sig/apps,sig/testing] -
全ての Pod の delete の挙動をカウントする
force_delete_pods_totalとforce_delete_pod_errors_totalのメトリクスが追加されました。 (#118480, @carlory) [sig/apps]
 Documentation(ドキュメント改善)
Documentation(ドキュメント改善)
 Bug or Regression(バグ修正)
Bug or Regression(バグ修正)
-
削除された pod の backoff delay をより正確に計算するようになりました。 (#118413, @mimowo) [SIG Apps] [sig/apps]
-
孤立した Pod が発生することを避けるために、全ての Pod の finalizers が削除されたときに Job が完了するようになりました。 (#119159, @alculquicondor) [sig/apps,sig/testing]
-
Job status 更新が 1s でバッチで更新されることを保証します。この修正により即時に完了したPodがトリガーとなり、 non-batched Jobのステータスが更新される不運なシナリオが修正されました。 (#118470, @mimowo) [SIG Apps] [sig/apps]
-
Parallelモードが有効化されている時のStatefulSetの作成が早くなります。 (#117865, @aleksandra-malinowska) [sig/apps] -
AddHintsとSetNodesが同時に呼び出されたときの TopologyCache の競合が修正されました。(#117249, @tnqn) [SIG Apps and Network] [sig/network,sig/apps] -
ノード作成後に
topology.kubernetes.io/zoneのラベルが追加された場合に Topology Aware Hints がうまく機能しない件を修正しました。 (#117245, @tnqn) [sig/network,sig/apps]-
node 作成後に cloud provider とかが topology.kubernetes.io/zone のラベルを後で追加した時に kube-controller-manager のリスタートか、Node events が更新されるまで TopologyAwareHint に反映されていなかった問題になります。これは他のマイナーバージョンにもバックポートされています。
-
-
Job pod failure policy を利用した際の backoff delay の計算を修正しました。これにより、 backoffLimit counter から無視されるようになった失敗した Pod が backoff delay の計算に含まれるようになりました。(#119434, @mimowo) [sig/apps]
-
30 6-16/4 * * 1-5のように複雑なスケジュールを設定した際に cronjob controller ハンドリングできるように修正しました。(#118724, @soltysh) [sig/apps] -
Daemonset controller は terminal Pod (Failed/Succeeded のフェイズ) のついて、VM preemptions と明らかな場合か Pod finalizers に代わりの Pod を作成できるようになりました。 (#118716, @alculquicondor) [sig/node,sig/apps,sig/testing]
 Other (その他の修正)
Other (その他の修正)
-
Job controller のバッチの同期呼び出しを無条件で有効化しました。(以前は JobReadyPods feature が有効の時だけでした) また、Job controller のデフォルトの backoff と最大の backoff の定数がそれぞれ 10s から 1s と 6min から 1min に引き下げされました。これらの数値は Job controller がリクエストが失敗した場合に次の backoff delay を決定するために使用します。(#118615, @mimowo) [SIG Apps and Testing] [sig/apps,sig/testing]
-
backoff のところの変更内容が分かりにくいので補足を追加します。Job で管理してる Pod が失敗した時に新しい Pod を再作成するときの backoff と Queue を取りにいく時に失敗したときの backoff を同じ定数で管理していたのでそれぞれが別で管理されるようになりますという話になります。Queue を取りにいく時のリトライが最低で 10s になっているのはちょっと長かったので改善しましたという内容です。
## 元々、JobBackOff の定数が一種類だった // DefaultJobBackOff is the default backoff period. Exported for tests. - DefaultJobBackOff = 10 * time.Second // MaxJobBackOff is the max backoff period. Exported for tests. - MaxJobBackOff = 360 * time.Second ## ApiBackOff と FailureBackOff でそれぞれ別に定義されるようになりました。 // DefaultJobApiBackOff is the default backoff period. Exported for tests. + DefaultJobApiBackOff = 1 * time.Second // MaxJobApiBackOff is the max backoff period. Exported for tests. + MaxJobApiBackOff = 60 * time.Second // DefaultJobPodFailureBackOff is the default backoff period. Exported for tests. + DefaultJobPodFailureBackOff = 10 * time.Second // MaxJobPodFailureBackOff is the max backoff period. Exported for tests. + MaxJobPodFailureBackOff = 360 * time.Second -
-
disruption controller (
kube-controller-managerに含まれる) は contextual logging を使うようになりました。 (#119147, @mengjiao-liu) [SIG API Machinery, Apps, Instrumentation and Testing] [sig/api-machinery,sig/apps,sig/instrumentation,sig/testing] -
podgc controller と他の残りのログコール (
kube-controller-managerに含まれる)を contextual logging に移行しました。kube-controller-managerの移行は完了しました。 (#119250, @pohly) [SIG API Machinery, Apps, Cloud Provider, Instrumentation, Network, Storage and Testing] [sig/network,sig/storage,sig/api-machinery,sig/apps,sig/instrumentation,sig/testing,sig/cloud-provider] -
一時的な API エラーの後の Job のプロセスの遅延を軽減しました。 (#118759, @mimowo) [sig/apps]
所感
今回は主に Job に対する大きめの変更がいくつか入りました。該当の KEP が作成された理由を調べてみると Tensorflow などのユースケースで問題となったことに起因するようでした。おそらく背景として、GPU を必要とする Job を Kubernetes 上で動かすユースケースが増えてきたので、それに関連する課題を増えてきたのかなと思います。今後もこの傾向は続くと思うので Job についてはまだ新規機能が追加されていくのかなと思いました。