はじめに
このページではKubernetes v1.22 における SIG-Apps に関連する変更内容をまとめています。
SIG-AppsはKubernetesのワークロードの扱いなどの変更を主に扱っているため、他のSIGと関係する変更が多くなっております。
- 直近での過去の変更内容は以下になります。
SIG / SIG-Apps とは?
-
SIGとは?
- Special Interest Groups の略称
- 各 SIG には Subproject が与えられていて、 Subproject に対して独立して開発できるようになっています。
- Kubernetes は巨大なプロジェクトなので、各SIG 毎に担当(Subproject)が割り当てられていて、各SIG は独立して開発をしています。
- SIG 間を跨って話し合いをする必要が生じた場合は Working Groups が一時的に作られ、その枠組みの中で話し合うことになります。
-
SIG-Appsとは?
- Apps Special Interest Group の略称
- Kubernetes に対して、application を deploy したりすることに関することが対象。具体的には Pod, ReplicaSet, Deployments, DaemonSet, StatefulSet, Jobs, CronJob あたりが開発対象。
- 詳細について知りたい方はこちらをご参照ください。
SIG-Apps 以外の SIG に関する変更は以下にまとめてありますので、合わせてご参照下さい。
注目の変更
今回は、SIG-Apps に関して新規にアルファになったものと、ベータに移行したものについて取り上げます。
StatefulSet
minReadySeconds for StatefulSets
Deployment と Daemonset で設定することができた minReadySeconds が StatefulSet で使用できるようになりました。
詳しくはこちらの公式ブログをご確認ください。
- 関連情報
| KEP | KEP-2599 |
|---|---|
| Feature stage | Alpha |
| Feature Gate | StatefulSetMinReadySeconds |
| issue | #65098 |
| PR | #101316, #100842 |
| 参考 | 公式ドキュメント |
実際の使用イメージ (クリックすると開きます)
- explain で確認すると StatefulSet に
spec.minReadySecondsが追加されていることが確認できます。
$ kubectl explain statefulset.spec.minReadySeconds
KIND: StatefulSet
VERSION: apps/v1
FIELD: minReadySeconds <integer>
DESCRIPTION:
Minimum number of seconds for which a newly created pod should be ready
without any of its container crashing for it to be considered available.
Defaults to 0 (pod will be considered available as soon as it is ready)
This is an alpha field and requires enabling StatefulSetMinReadySeconds
feature gate.
- 以下のように
minReadySecondsを設定した StatefulSet を用意します。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 3
minReadySeconds: 60 # デフォルトでは 0 が設定されています
template:
metadata:
labels:
app: nginx
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: nginx
- StatefulSet でも Deployment と同じように
minReadySecondsが設定できるようになってることを確認できます。
$ kubectl apply -f sts.yaml
statefulset.apps/web created
$ kubectl get sts,po
NAME READY AGE
statefulset.apps/web 1/3 7s
NAME READY STATUS RESTARTS AGE
pod/web-0 1/1 Running 0 7s
$ kubectl get sts -o json | jq -r '.items[] | {"spec.minReadySeconds":.spec.minReadySeconds, "status.availableReplicas":.status.availableReplicas}'
{
"spec.minReadySeconds": 60,
"status.availableReplicas": null
}
### minReadySeconds を経過した Pod がないのでこの時点では availableReplicas が null
$ kubectl get sts,po
NAME READY AGE
statefulset.apps/web 2/3 2m39s
NAME READY STATUS RESTARTS AGE
pod/web-0 1/1 Running 0 2m39s
pod/web-1 1/1 Running 0 39s
$ kubectl get sts -ojson | jq -r '.items[] | {"spec.minReadySeconds":.spec.minReadySeconds, "status.availableReplicas":.status.availableReplicas}'
{
"spec.minReadySeconds": 60,
"status.availableReplicas": 1
}
### minReadySeconds を経過した Pod が増えたので availableReplicas がカウントアップしている
他でも使用している minReadySeconds が Statefulset で使えるようになっただけなので、この変更については現在アルファ機能で今後の大きな変更はあまりないのかなと個人的には思っています。
Job
Job tracking with finalizers
今までは Job Controller がクラスタ内の Pod を数えて Job の実行状況を管理していました。
そのため、以下のような理由で実行中の Pod が削除される場合に Job の実行状況の把握に課題がありました。
- Node がダウンした時に garbage collector で削除される Pod が出てくる
- 完了した Pod が閾値を超えると garbage collector によって削除される。詳細はこちら
- 人為的な削除や、他のコントローラー等による外部からの Pod の削除
今回の機能では Job controller が Pod に対して finalizer batch.kubernetes.io/job-tracking を用いることでジョブの実行状況を追跡できるようになります。
- 関連情報
| KEP | KEP-2307 |
|---|---|
| Feature stage | Alpha |
| Feature Gate | JobTrackingWithFinalizers |
| issue | #2307 |
| PR | #98817, #98238 |
| 参考 | 公式ドキュメント |
実際の使用イメージ (クリックすると開きます)
- 以下のように Job を用意します。
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-timeout
spec:
completions: 3
backoffLimit: 5
activeDeadlineSeconds: 100
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
- 実行すると以下のようになります。
$ kubectl apply -f job.yaml
job.batch/pi-with-timeout created
$ kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/pi-with-timeout 2/3 28s 28s
NAME READY STATUS RESTARTS AGE
pod/pi-with-timeout--1-95swl 0/1 Completed 0 28s
pod/pi-with-timeout--1-mtswv 0/1 Completed 0 16s
pod/pi-with-timeout--1-nvw9p 0/1 ContainerCreating 0 2s
$ kubectl get po -o json | jq -r '.items[].metadata| {name:.name,finalizers:.finalizers}'
{
"name": "pi-with-timeout--1-95swl",
+ "finalizers": null
}
{
"name": "pi-with-timeout--1-mtswv",
+ "finalizers": null
}
{
"name": "pi-with-timeout--1-nvw9p",
"finalizers": [
+ "batch.kubernetes.io/job-tracking" # 実行中のpodには付与される
]
上記のように、Job によって作成された Pod には finalizer が付与されるようになっており、コントローラー側が succeeded か failed を検知すると finalizer の batch.kubernetes.io/job-tracking が削除されます。
Finalizerの仕組みについては詳しく知りたい方はこちらのブログを参照ください.
- Job 側の確認
$ kubectl get job -o json | jq -r '.items[].metadata.annotations,.items[].status'
{
"batch.kubernetes.io/job-tracking": "",
"kubectl.kubernetes.io/last-applied-configuration": "{\"apiVersion\":\"batch/v1\",\"kind\":\"Job\",\"metadata\":{\"annotations\":{},\"name\":\"pi-with-timeout\",\"namespace\":\"default\"},\"spec\":{\"activeDeadlineSeconds\":100,\"backoffLimit\":5,\"completions\":3,\"template\":{\"spec\":{\"containers\":[{\"command\":[\"perl\",\"-Mbignum=bpi\",\"-wle\",\"print bpi(2000)\"],\"image\":\"perl\",\"name\":\"pi\"}],\"restartPolicy\":\"Never\"}}}}\n"
}
{
"completionTime": "2021-08-12T23:54:04Z",
"conditions": [
{
"lastProbeTime": "2021-08-12T23:54:04Z",
"lastTransitionTime": "2021-08-12T23:54:04Z",
"status": "True",
"type": "Complete"
}
],
"startTime": "2021-08-12T23:53:33Z",
"succeeded": 3,
"uncountedTerminatedPods": {} #
本機能を有効化すると Job のアノテーションに batch.kubernetes.io/job-tracking がつくようになり、このアノテーションのある Job が Pod を作成する時に finalizer が付与されるようになります。
このアノテーションは GA 以降に削除される予定で、それ以降は該当のアノテーションがなくても本機能が有効になる予定です。
今回登場した機能と k8s v1.21 でベータ機能になった TTL Controller との組み合わせにより、job で大量の Pod を作成した時に、完了済みの pod が自動で削除されるような状態を作れるようになったかなと思います。
- jobに
.spec.ttlSecondsAfterFinished設定した際に以下の条件をみたすjobを削除
- Job の実行結果が
CompleteorFailed -
.spec.ttlSecondsAfterFinished+.status.conditions.lastTransitionTime> now
- TTL Controller による完了した Pod の自動削除の例
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-ttl
spec:
ttlSecondsAfterFinished: 100 # Pod 完了後100秒以降に TTL Controller によって検知された場合に削除される
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
ただ、Job tracking with finalizers はまだアルファ機能のため、今後大きな変更が入る可能性があるので注意してください。
Indexed Job
Job を実行時に completionMode に Indexed を設定することで、Job を実行する Pod は、 Job 内でユニークな Completed Indexes を持つことが出来るようになります。
これにより、 Pod が実行時に自身に割り当てられた Completed Indexes を確認して処理を分岐することで、一つの Job の中でそれぞれの Pod が別の処理を容易に実現できるようになります。(今までは、これを実行するために、他の仕組みと併用する必要がありました。)
- 関連情報
| KEP | KEP-2214 |
|---|---|
| Feature stage | Beta |
| Feature Gate | IndexedJob |
| issue | #2214, #14188 |
| PR | #101292, #98441, #98812 |
| 参考 | 公式ドキュメント |
実際の使用イメージ (クリックすると開きます)
- 以下のように
completionModeを設定した Job のマニフェストを用意します。
apiVersion: batch/v1
kind: Job
metadata:
name: 'indexed-job'
spec:
completions: 5
parallelism: 3
completionMode: Indexed # デフォルトでは NonIndexed が設定されています
template:
metadata:
labels:
job: indexed-job
spec:
restartPolicy: Never
initContainers:
- name: 'input'
image: 'docker.io/library/bash'
command:
- "bash"
- "-c"
- |
items=(foo bar baz qux xyz)
echo ${items[$JOB_COMPLETION_INDEX]} > /input/data.txt # $JOB_COMPLETION_INDEX で取得
volumeMounts:
- mountPath: /input
name: input
containers:
- name: 'worker'
image: 'docker.io/library/busybox'
command:
- "rev"
- "/input/data.txt"
volumeMounts:
- mountPath: /input
name: input
volumes:
- name: input
emptyDir: {}
- 実際に実行すると以下のようになります。
$ kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/indexed-job 0/5 20s 20s
NAME READY STATUS RESTARTS AGE
pod/indexed-job-0-8k4ng 0/1 PodInitializing 0 20s
pod/indexed-job-1-qcbnn 0/1 PodInitializing 0 20s
pod/indexed-job-2-ktr4s 0/1 PodInitializing 0 20s
アルファ時点からの変更点として、Pod 名に Indexes 付与されるようになり、分かりやすくなりました。
pod の名:$(job-name)-$(index)-$(random-string)
- Job を確認すると以下のようになります。
$ kubectl describe job
e: indexed-job
Namespace: default
Selector: controller-uid=1be7fe59-7529-419e-9d15-c7f81395027f
Labels: controller-uid=1be7fe59-7529-419e-9d15-c7f81395027f
job-name=indexed-job
Annotations: batch.kubernetes.io/job-tracking:
Parallelism: 3
Completions: 5
Completion Mode: Indexed
Start Time: Fri, 13 Aug 2021 15:51:18 +0900
Completed At: Fri, 13 Aug 2021 15:51:56 +0900
Duration: 38s
Pods Statuses: 0 Running / 5 Succeeded / 0 Failed
+ Completed Indexes: 0-4 # 0 〜 {Completions - 1} になっています
Pod Template:
- Pod 毎の処理結果を確認すると、結果がそれぞれに異なることが分かります。
$ kubectl logs indexed-job-2-ktr4s
zyx # Completed Indexes が 4 だったため
$ kubectl logs indexed-job-4-l5fvz
bar # Completed Indexes が 2 だったため
Suspend Jobs
Job を実行時に suspend に true を設定することで、 Job を一時停止することが出来るようになりました。
今までだと、途中で優先度の高い Job が実行されたとしても既存の実行中の Job は実行し続けていましたが、この機能を使うことにより、限られたクラスタのリソースをより複雑な Job のワークロードの中でうまく使えるようになります。
- 関連情報
| KEP | KEP-2322 |
|---|---|
| Feature stage | Beta |
| Feature Gate | SuspendJob |
| issue | #2232 |
| PR | #102022, #98727 |
| 参考 | 公式ドキュメント |
実際の使用イメージ (クリックすると開きます)
- 以下のように
suspendを設定した Job のマニフェストを用意します。
apiVersion: batch/v1
kind: Job
metadata:
name: my-job
spec:
suspend: true # デフォルトでは false が設定されています
parallelism: 2
completions: 10
template:
spec:
containers:
- name: my-container
image: busybox
command: ["sleep", "5"]
restartPolicy: Never
- 実行すると以下のようになり、
Job suspendedとなっていることが分かります。
$ kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/my-job 0/10 9s
$ kubectl describe job
ame: my-job
Namespace: default
Selector: controller-uid=f3d22fdf-5d62-4f09-86e5-a0d19f4e6509
Labels: controller-uid=f3d22fdf-5d62-4f09-86e5-a0d19f4e6509
job-name=my-job
Annotations: batch.kubernetes.io/job-tracking:
Parallelism: 2
Completions: 10
Completion Mode: NonIndexed
Pods Statuses: 0 Running / 0 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=f3d22fdf-5d62-4f09-86e5-a0d19f4e6509
job-name=my-job
Containers:
my-container:
Image: busybox
Port: <none>
Host Port: <none>
Command:
sleep
5
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
+ Normal Suspended 19s job-controller Job suspended
-
suspendをfalseに変更します。
$ kubectl edit job my-job
spec:
- suspend: true
+ suspend: false
- Job が実行されることが確認できます。
$ kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/my-job 1/10 13s 2m8s
NAME READY STATUS RESTARTS AGE
pod/my-job--1-4q77z 0/1 Completed 0 14s
pod/my-job--1-mtf5d 0/1 ContainerCreating 0 3s
pod/my-job--1-zcf62 1/1 Running 0 13s
手動で suspend の値を切り替えることはあまりないと思いますが、 Operator 等で上手く制御することで、複雑な Job のワークロードを Kubernetes 上で実行するための下地の一つが出来たかなという印象があります。
DaemonSet
Allow DaemonSets to surge during update like Deployments
DaemonSet に MaxSurge が導入されました。
従来の通りだと、DaemonSet がローリングアップグレードする際には、既存の Pod が削除された後に新しい Pod が立ち上がり始めるのでダウンタイムが長かったのですが、 MaxSurge を利用すると新しい Pod が Ready になってから古い Pod が削除され始めるのでダウンタイムの低減が期待できます。
- 関連情報
| KEP | KEP-1591 |
|---|---|
| Feature stage | Beta |
| Feature Gate | DaemonSetUpdateSurge |
| issue | #1591 |
| PR | #101742, #96441 |
| 参考 | 公式ドキュメント |
実際の使用イメージ (クリックすると開きます)
- 以下のように
maxSurgeを設定した DaemonSet を用意します。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds-maxsurge
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 0
maxSurge: 1 # デフォルトでは 0 が設定されています
selector:
matchLabels:
app: ds-maxsurge
template:
metadata:
labels:
app: ds-maxsurge
spec:
containers:
- name: nginx
image: nginx:1.18
- ついに、DaemonSet に
maxSurgeが設定できるようになっています。
$ kubectl apply -f ds.yaml
daemonset.apps/ds-maxsurge created
$ kubectl get ds -ojson | jq -r '.items[].spec.updateStrategy'
{
"rollingUpdate": {
"maxSurge": 1,
"maxUnavailable": 0
},
"type": "RollingUpdate"
}
- ローリングアップデートすると
maxSurgeが機能してることが確認できます。
$ kubectl set image DaemonSet/ds-maxsurge nginx=nginx:1.19
daemonset.apps/ds-maxsurge image updated
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ds-maxsurge-42nwf 0/1 ContainerCreating 0 5s <none> minikube <none> <none>
ds-maxsurge-kfdxp 1/1 Running 0 49s 172.17.0.3 minikube <none> <none>
まだ、同一ノード上で Running の Pod があるにも関わらず、新しい Pod の ContainerCreating になっているところが今回の大きな変更になります。
注意点:hostPort の利用
KEP-1591 にも記載がありますが、 maxSurge と hostPort は併用できません。
- hostPort を利用するマニフェストを作成してデプロイしてみます。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds-maxsurge
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 0
+ maxSurge: 1
selector:
matchLabels:
app: ds-maxsurge
template:
metadata:
labels:
app: ds-maxsurge
spec:
+ hostNetwork: true
containers:
- name: nginx
image: nginx:1.18
ports:
- containerPort: 80
+ hostPort: 80
- Pod の生成には成功します。
$ kubectl get ds -o yaml
ports:
- containerPort: 80
+ hostPort: 80
+ hostNetwork: true
updateStrategy:
rollingUpdate:
+ maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
- ローリングアップデートをすると新しい Pod がずっと Pending になります。
$ kubectl set image DaemonSet/ds-maxsurge nginx=nginx:1.19
daemonset.apps/ds-maxsurge image updated
$ kubectl get po
NAME READY STATUS RESTARTS AGE
ds-maxsurge-jmq2v 1/1 Running 0 28s
ds-maxsurge-nkrfw 0/1 Pending 0 6s
- 中を確認すると、port がなくてスケジューラーが割り当てられないことが分かります。
$ kubectl describe po ds-maxsurge-khm9w
:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 25s default-scheduler 0/1 nodes are available: 1 node(s) didn't have free ports for the requested pod ports.
ReplicaSet
Random Pod Selection on ReplicaSet Downscale
ReplicaSet をスケールダウンするときに優先的に削除される Pod が、従来では起動時間が短い Pod が優先的に削除されてましたが、この優先度の付け方に少し変更が入りました。これは、起動時間の短い Pod の方がより影響範囲が小さいだろうという仮定の元に実装されていました。
今回の変更では以下のように変更になっています。
- Pod の起動時間を対数目盛(logarithmic scale) で丸め込んでから起動時間の短い方を比較
- 同じものがあれが、Pod の UUID で比較する。
これにより、従来の起動時間が短いものを優先するというのをある程度守りながら、 UUID を用いることでランダムに選択されるようになりました。
Pod の起動時間を対数目盛を丸め込むイメージ (クリックすると開きます)
基数 10 で対数目盛を使用した際のイメージになります。
| Duration | Scale |
|---|---|
| 5ns | 0 |
| 23ns | 1 |
| 71ns | 1 |
| 1ms | 6 |
| 8ms | 6 |
| 50ms | 7 |
| 2m | 11 |
| 11m | 11 |
ある程度起動時間の近しいものだけが、比較対象となり、 UUID を用いて擬似的にランダムで削除される Pod が選択されるイメージが持てるかと思います。
- 関連情報
| KEP | KEP-2185 |
|---|---|
| Feature stage | Beta |
| Feature Gate | LogarithmicScaleDown |
| issue | #2185, #96748 |
| PR | #101767,#99212 |
| 参考 | 公式ドキュメント |
ReplicaSet Pod Deletion Cost
Pod に controller.kubernetes.io/pod-deletion-cost のアノテーションを付与することで、スケールダウン時に優先的に削除するように制御できるようになりました。
従来だと、起動時間が短いものがより優先的に削除されましたが、例えば preemptible/spot VM などで起動している Pod を優先的に削除したいなど、起動時間と削除の優先度に関係がない場合により柔軟な制御が可能になりました。
- 関連情報
| KEP | KEP-2255 |
|---|---|
| Feature stage | Beta |
| Feature Gate | PodDeletionCost |
| issue | #2255 |
| PR | #101080, #99163 |
| 参考 | 公式ドキュメント |
実際の使用イメージ (クリックすると開きます)
- 以下のように
controller.kubernetes.io/pod-deletion-costのアノテーションを設定した Deployment のマニフェストを用意します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-deployment
spec:
replicas: 3
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
annotations:
# 何も設定していない場合は、"0" が設定されているものとしてコスト計算されます
controller.kubernetes.io/pod-deletion-cost: "0"
spec:
containers:
- name: nginx
image: nginx
- Deployment によって、 Pod が3つ生成されます。
$ kubectl get po
NAME READY STATUS RESTARTS AGE
sample-deployment-d9489fcc6-2vt9n 1/1 Running 0 5m14s
sample-deployment-d9489fcc6-q69bk 1/1 Running 0 5m14s
sample-deployment-d9489fcc6-twhrr 1/1 Running 0 5m14s
- 1つだけ Pod を削除し、 Pod の起動時間が他より短くなるようにします。
$ kubectl delete po sample-deployment-d9489fcc6-2vt9n
pod "sample-deployment-d9489fcc6-2vt9n" deleted
$ kubectl get po
NAME READY STATUS RESTARTS AGE
sample-deployment-d9489fcc6-7wvvc 1/1 Running 0 15s
sample-deployment-d9489fcc6-q69bk 1/1 Running 0 5m37s
sample-deployment-d9489fcc6-twhrr 1/1 Running 0 5m37s
- 起動時間が長い Pod の内の一つを選択して
pod-deletion-costの値を変更します。
$ kubectl edit po sample-deployment-d9489fcc6-q69bk
apiVersion: v1
kind: Pod
metadata:
annotations:
- controller.kubernetes.io/pod-deletion-cost: "0"
+ controller.kubernetes.io/pod-deletion-cost: "-10"
pod-deletion-cost の値は -2147483647 〜 2147483647 の範囲で指定が可能です。
-
pod-deletion-costの値を確認すると、1つだけ異なることが分かります。
$ kubectl get po -ojson | jq -r '.items[].metadata.annotations'
{
"controller.kubernetes.io/pod-deletion-cost": "0"
}
{
"controller.kubernetes.io/pod-deletion-cost": "-10"
}
{
"controller.kubernetes.io/pod-deletion-cost": "0"
}
- この状態で、スケールダウンをして Pod 数を削減します。
$ kubectl scale deployment.v1.apps/sample-deployment --replicas=2
deployment.apps/sample-deployment scaled
$ kubectl get po
NAME READY STATUS RESTARTS AGE
sample-deployment-d9489fcc6-7wvvc 1/1 Running 0 79s
sample-deployment-d9489fcc6-twhrr 1/1 Running 0 6m41s
従来なら、起動時間の最も短い sample-deployment-d9489fcc6-7wvvc が削除されているはずですが残っていることが分かります。
-
pod-deletion-costの値を確認します。
$ kubectl get po -ojson | jq -r '.items[].metadata.annotations'
{
"controller.kubernetes.io/pod-deletion-cost": "0"
}
{
"controller.kubernetes.io/pod-deletion-cost": "0"
}
pod-deletion-cost が -10 を設定した Pod が削除されていることが確認できます。
手動で pod-deletion-cost を操作することはあまりやらないと思いますが、 preemptible/spot VM で動作してる Pod に対して自動で pod-deletion-cost を付与する仕組みを作ったり、 Pod の起動時間とサービスの影響度の関連性が低い場合において、より柔軟に ReplicaSet をスケールダウンする際の Pod の制御ができるようになったかなと思います。
v1.22 Release Notes
v1.22 Release Notes の中で SIG-Apps に関するものについて以下に和訳したものを記載します。
がついた文章は、CHANGELOGの公式内容ではなく筆者の補足です。
 Deprecation(非推奨)
Deprecation(非推奨)
-
kube-proxyからアルファ機能だったtopologyKeysのフィールドが削除されました. このフィールドは数サイクル前から非推奨となっていました。エンドポイント毎に対する Topology Aware Hints(alpha) 機能を auto で使用することとinternalTrafficPolicyフィールド (alpha) を組み合わせて使用することで置き換えます。 (#102412, @andrewsykim) -
PodUnknownフェイズが非推奨になります。 (#95286, @SergeyKanzhelev)
 Changes(変更)
Changes(変更)
-
NodeResourcesFit plugin の新しい score extension は
NodeResourcesLeastAllocated,NodeResourcesMostAllocated,RequestedToCapacityRatioの機能を統合します。v1beta2 では非推奨になりますが、v1beta1 では引き続き統合された3つのプラグインを使用できますが、NodeResourcesFitと同時に使用することはできません。 the three plugins can still be used in v1beta1 but not at the same time with the score extension ofNodeResourcesFit. (#101822, @yuzhiquan) -
service.kubernetes.io/topology-aware-hintsのアノテーションでAutoが有効になりました。 (#100728, @robscott)-
中身を確認すると今まで
auto(小文字)しか設定できなかったのでAuto(大文字)も設定できるようにしただけのようです。- // corev1.AnnotationTopologyAwareHints key with a value set to "auto". + // corev1.AnnotationTopologyAwareHints key with a value set to "Auto" or "auto".
-
-
PVC の sepc に
DataSourceRefフィールド(アルファ機能) が追加されました。 これによりPVCsとVolumeSnapshots以外のデータソースが指定できるようになります。 (#103276, @bswartz)-
Volume populators and data sources について詳細を知りたい方は公式サイトのこちらをご参照ください。
-
-
StatefulSet API に
PersistentVolumeClaimDeletePoilcyが追加されました。 (#99378, @mattcary)-
この PR については revert されているため k8s v1.22 で導入されませんでした。
-
詳細についてはこちらの KEP をご確認ください。
-
-
Windows で HostProcess containers のアルファサポートを開始します。 (#99576, @marosset) [SIG API Machinery, Apps, Node, Testing and Windows]
-
job controller に job の状態の監視ように3つのメトリクスが追加されました。
IndexedJobがベータになりました。 (#101292, @AliceZhang2016)-
以下の3つのメトリクスが追加されました。
-
job_sync_duration_seconds: The time it took to sync a job -
job_sync_total: The number of job syncs -
job_finished_total: The number of finished job
-
-
-
job に
.status.uncountedTerminatedPodsのフィールドが追加されました。 このフィールドは job controller が 完了した pod を job status カウンターに追加する前に追跡するために使用します。job controller で作成された Pod は finalizer にbatch.kubernetes.io/job-trackingを持ちます。この方法で追跡される Job はbatch.kubernetes.io/job-trackingのアノテーションを持ちます。この方法は一時的なものです。2リリース後にベータになった以降、このアノテーションは Job に追加されなくなります。 (#98817, @alculquicondor)-
Job tracking with finalizers について詳細を知りたい方は公式サイトのこちらをご参照ください。
-
-
PersistentVolumesとPersistentVolumeClaimsにアクセスモードReadWriteOncePodが追加されました。ボリュームへのアクセスが単一ノードの単一 Pod に制限されます。 (#102028, @chrishenzie)-
ReadWriteOnce(RWO)は単一ノードからのボリュームへの制限でしたが、ReadWriteOncePod(RWOP)ができたことで単一ノードの単一 Pod からの制限となり、より細かく制御できるようになりました。 -
ReadWriteOncePodを含むアクセスモードについて詳細を知りたい方は公式サイトのこちらをご参照ください。
-
-
Because of the implementation logic of
time.Formatin golang, the displayed time zone is not consistent. (#102366, @cndoit18) -
Go言語の
time.Formatの実装のため、表示される time zone に一貫性がありません。(#102366, @cndoit18)-
Changelogの直訳だと意味が分かりにくいので中身をみていきたいと思います。以下のように
UTCを明示したことにより、異なるノードでも表示される time zone に一貫性が得られるという変更になります。- endpointSlice.Annotations[corev1.EndpointsLastChangeTriggerTime] = triggerTime.Format(time.RFC3339Nano) + endpointSlice.Annotations[corev1.EndpointsLastChangeTriggerTime] = triggerTime.UTC().Format(time.RFC3339Nano)
-
-
コンテナの env, command , args で
$をエスケープする際の記述が修正されました。 (#101916, @MartinKanters) [SIG Apps] -
DaemonSetのMaxSurgeがデフォルトで有効になりました。(#101742, @ravisantoshgudimetla) -
スケジューリング中に PVC access mode の
ReadWriteOncePodが適用されます。 (#103082, @chrishenzie)-
ReadWriteOncePodに関する追加の変更になります。 PVC でReadWriteOncePodをもつ Pod をスケジュール際に他に同一の PVC を既に使用している Pod がないか確認するように修正されました。 -
詳細についてはこちらの KEP をご確認ください。
-
-
Ephemeral containers は Pod とは別の
securityContextを指定できるようになりました。 この機能を使用するためにはクラスタ管理者は事前に security policy controllers でEphemeralContainersがサポートされていることを確認する必要があります。(#99023, @verb)-
詳細についてはこちらの KEP をご確認ください。
-
-
StatefulSetsにminReadySecondsの API が追加されました。 (#100842, @ravisantoshgudimetla)-
既に [Deployment]https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#progress-deadline-seconds) と Daemonset で設定できた
minReadySecondsがStatefulSetで使用できるようになりました。 -
詳細を知りたい方は公式サイトのこちらをご参照ください。
-
-
horizontal pod autoscaler のために Heapster をサポートする
--horizontal-pod-autoscaler-use-rest-clientsフラグが Kube-controller-manager から削除されました。このフラグについては 1.12 から非推奨となっています。 (#90368, @serathius) -
Kubelet から probe-level termination grace period の feature flag が削除されました。既に作成されている Pod に対してこの変更を適用させたい場合は Pod を再作成してください。 (#103168, @raisaat) [SIG Apps and Node]
-
詳細についてはこちらの KEP をご確認ください。
-
-
StatefulSetに追加されたPersistentVolumeClaimDeletePoilcyの API が Revert されました。 (#103747, @mattcary) -
k8s v1.22 での導入は見送りになりました。
-
Suspend Job が beta になりました。 Job controller の
job_sync_totalとjob_sync_duration_secondsのメトリクスにactionラベルが追加されました。 (#102022, @adtac) -
DaemonSet の
spec.updateStrategy.rollingUpdate.maxUnavailableフィールドに関する API のドキュメントが修正され、値が切り上げられることが記載されました。(#101296, @Miciah) -
CertificateSigningRequest.certificates.k8s.ioAPI はオプションで expirationSeconds フィールドをサポートするようになりクライアントは特定の期間を指定した issued certificate 要求できるようになりました。 Kubernetes controller manager が提供するデフォルトの署名の実装は --cluster-signing-duration のフラグを超えない限り、このフィールドの設定を尊重します。(#99494, @enj) -
EndpointSlicen Mirroring controllerはkubectlでアップデートされたEndpointSlicesのlast-applied-configurationアノテーションをミラーしなくなりました。(#102731, @sharmarajdaksh) -
PodDeletionCostがベータとなり、デフォルトで使用できるようになりました。 (#101080, @ahg-g) -
Pod の spec と container probe の
TerminationGracePeriodSecondsは負の値を取れません。TerminationGracePeriodSecondsに負の値が設定された場合は削除され1sが設定されます。負の値を更新するために Immutable field のバリデーションが緩和されます。将来のリリースで負の値の設定は許可されなくなります。 (#98866, @wzshiming) -
pod/evictionのサブリソースはpolicy/v1beta1に加えてpolicy/v1を受け入れるようになりました。 (#100724, @liggitt) -
podAffinity,NamespaceSelector,CrossNamespaceAffinityの機能はベータとなりデフォルトで使用できるようになりました。 (#101496, @ahg-g) -
The
pods/ephemeralcontainersAPI now returns and expects aPodobject instead ofEphemeralContainers. This is incompatible with the previous alpha-level API. (#101034, @verb) [SIG Apps, Auth, CLI and Testing] -
pods/ephemeralcontainersAPI はEphemeralContainersではなくPodオブジェクトを返し、期待するようになります。この変更はアルファの時から互換性がありません。 (#101034, @verb) [SIG Apps, Auth, CLI and Testing] -
v1.Nodeと.status.images[].namesはオプションとなりました。 (#102159, @roycaihw) -
status と Pod finalizers を用いて Job の完了を追跡し、Pod からの依存を削除します。 (#98238, @alculquicondor) [SIG API Machinery, Apps, Auth and Testing]
 FEATURE(機能追加)
FEATURE(機能追加)
-
1000 を超える endpoints は truncate されるようになり Endpoint リソースの
endpoints.kubernetes.io/over-capacityのアノテーションにtruncatedが設定されます。 (#103520, @swetharepakula) [SIG Apps and Network] -
StatefulSetsにminReadySecondsが実装されました。 (#101316, @ravisantoshgudimetla) -
新しく
ExpandedDNSConfigfeature gate 使用できるようになります。この機能により Kubernetes で DNS configuration の拡張ができるようになります。 (#100651, @gjkim42)-
詳細についてはこちらの KEP をご確認ください。
-
-
Cronjobs storage version が
batch/v1になりました。 (#102363, @mengjiao-liu) -
CronJobControllerV2フラグが GA となりました。このフラグは 1.23 で削除予定になります。 (#102529, @soltysh) -
HugePageStorageMediumSize機能が GA となり無条件で有効化されるようになります。 コンテナレベルで複数サイズの huge page resources を利用できるようになります。 (#99144, @bart0sh) -
LogarithmicScaleDown機能がベータとなりデフォルトで有効になります。 (#101767, @damemi) -
このリリースで
NamespaceDefaultLabelNameが GA となりました。 全ての Namespace API objects はmetadata.nameフィールドと一致するkubernetes.io/metadata.nameを持つようになり、label selector を使用してnamespaceを指定できるようになります。 (#101342, @rosenhouse)-
詳細についてはこちらの KEP をご確認ください。
-
-
ServiceInternalTrafficPolicy機能がベータとなりデフォルトで有効化されるようになります。これにより、Service のinternalTrafficPolicyフィールドがデフォルトで有効になります。 (#103462, @andrewsykim)-
詳細についてはこちらの KEP をご確認ください。
-
-
ServiceLBNodePortControl機能がベータになりデフォルトで有効になります。 (#100412, @hanlins)-
詳細についてはこちらの KEP をご確認ください。
-
-
job controller removes 完了回数を達成した起動中の Pod を削除するようになります。 (#99963, @alculquicondor)
-
kubeconfig で
the kube-schedulerframework handle が公開されるようになりました。Out-of-tree plugins はこれを使用して CRD informers を簡単にビルドできるようになります。 (#100644, @Huang-Wei)
 BUGFIX(バグ修正)
BUGFIX(バグ修正)
-
Disruption controller は unmanaged pod と同期中にエラーを出さなくなります。 (#103414, @ravisantoshgudimetla) [SIG Apps and Testing]
-
endpointslicemirroringcontroller が endpointNotReadyAddressesが Ready で一致するEndpointSliceをミラーされる際のバグが修正されました。twere mirrored as Ready to the correspondingEndpointSlice. (#102683, @aojea) -
Pod が起動もしくは停止中に停止に時間がかかり、Kubelet でいくつかの競合状態になるバグが修正されました。 (#102344, @smarterclayton) [SIG Apps, Node, Storage and Testing]
-
json patches の array と object で null が処理される方法が修正されました。 (#102467, @pacoxu)
-
CSI migration translation での Azure file inline volume namespace の問題が修正されました。 (#101235, @andyzhangx)
-
kubectl describeで Job completion mode の表示が修正されました。(#101160, @alculquicondor) -
kube-controller-managerの起動時に、CSI に移行されたPersistentVolumesにぶら下がっているVolumeAttachmentsの garbage collection が修正されました。(#102176, @timebertt) -
batch/v1でcronjob.statusに追加されたlastSuccessfulTimeフィールドにコントローラーが追加していなかったバグが修正されました。 (#102642, @alaypatel07) -
CSI migrated volumes 予期しないデタッチに繋がるfalse-positive uncertain volume attachments が修正されました。 (#101737, @Jiawei0227) [SIG Apps and Storage]
-
EndpointSliceIP のバリデーションがEndpointsIP のバリデーションと一致するようになりました。 (#101084, @robscott)
その他:CronJobでの任意のタイムゾーンの指定
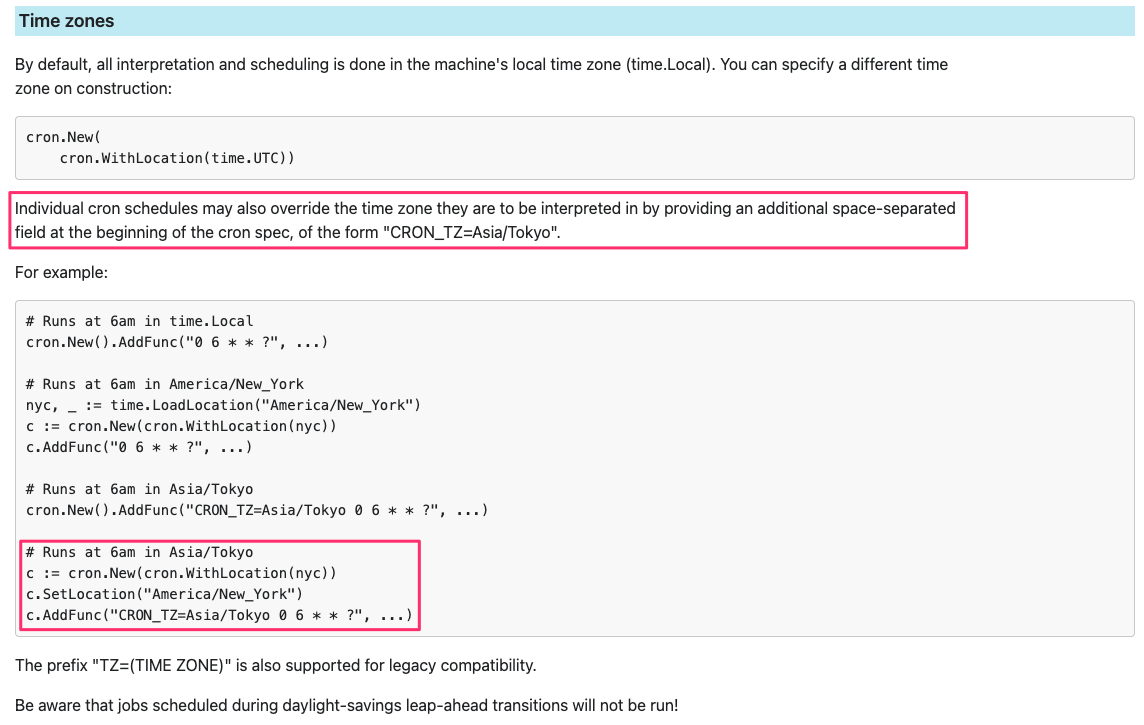
k8s v1.22からCronJobの実行時に任意のタイムゾーンを指定できるようになりました。
CronJobはkube-controller-managerプロセスから見たタイムゾーンで実行されますが、このタイムゾーンを確認することができない利用者にとってはCronJobが実行する時刻が保証されないという課題がありました。
また、国内ではk8sのクラスタがUTCで作られているが、Jobの実行についてはAsia/Tokyoで指定したいというケースも多くあったのではないかと思います。
今回のそれらの課題に対応する機能が追加されました。
実施方法
CronJobのspec.scheduleに対してCRON_TZにタイムゾーンを設定することで使用することができます。
- 以下のようの
CRON_TZを設定したCronJobを作成
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
+ schedule: "CRON_TZ=Asia/Tokyo 15 18 * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
- Manifestをapplyして指定時刻まで待つとjobが実行されます。
$ kubectl apply -f cronjob.yaml
cronjob.batch/hello created
$ kubectl get cronjobs,job,po
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob.batch/hello CRON_TZ=Asia/Tokyo 15 18 * * * False 0 5m55s 9m38s
NAME COMPLETIONS DURATION AGE
job.batch/hello-27166155 1/1 1s 5m55s
NAME READY STATUS RESTARTS AGE
pod/hello-27166155--1-4tgf2 0/1 Completed 0 5m55s
- describeでPodの
Start Timeでも確認できます。
$ kubectl describe po hello-27166155--1-4tgf2
Name: hello-27166155--1-4tgf2
Namespace: default
Priority: 0
Node: minikube/192.168.49.2
+ Start Time: Thu, 26 Aug 2021 18:15:00 +0900 <--- Asia/Tokyo の 18:15 に実施されたことを確認
Labels: controller-uid=e82c7f37-ce7b-4356-89de-3d43f13a1bb1
job-name=hello-27166155
Annotations: <none>
Status: Succeeded
:
:
導入の経緯
今回の機能追加にはChangelogのDependenciesの以下が大きく関係しています。
- Added
- github.com/robfig/cron/v3: v3.0.1
具体的にはこのPR以下の部分になります。
- github.com/robfig/cron v1.1.0
+ github.com/robfig/cron/v3 v3.0.1
v1.22での上記の変更によりGo言語のCron v3で追加された以下の機能がk8sにも取り込まれたため、実現できるようになりました。
そのため、k8s v1.21やそれ以前のバージョンでは使用できません。
Go言語側の詳細はこちらを確認ください。
 |
|---|
コミュニティの反応
元々はCronJobでのタイムゾーンのサポートについてはこちらのKEPで、CronJobに.spec.timezoneを追加してそこにAsia/Tokyo等を指定できるようにすることが検討されていたので、コミュニティ側でも予想外の機能追加になりました。
元々この議題について話していたissueでの反応は以下。
今後
CRON_TZでタイムゾーンを指定できる機能については、以下のPRで公式ドキュメントへの説明とテストが追加されつつあります。
ただ、本来は想定していた形の解決方法ではないため、.spec.timezoneの方が採用され今後のアップデートで使用できなくなる可能性もあります。そのため、利用を検討される際はこちらのissueで状況を確認してから採用することをお勧めします。
2021年11月18日追記
k8s v1.23からCronJobでCRON_TZをk8sプロジェクトとして、サポートしない旨の警告が出るようになります。k8sのdocsにも同じ内容が反映されました。

ref https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/
上記の関連するissueは以下になります。
- https://github.com/kubernetes/website/pull/30509
- https://github.com/kubernetes/kubernetes/pull/106455
k8s v1.23でもCRON_TZは動作するがk8sプロジェクト推奨しない方向になったようです。
CronJobでタイムゾーンをサポートする件については継続して以下のissueで議論されていくようです。
所感
Cronjobのタイムゾーンについては2017年頃から議論がありましたが、まずはCronJobControllerをV2にすることを優先して新規機能の追加は凍結。V2がリリースされたのでやっと新機能の追加が動き出した矢先にこういう形で実装されたのは驚きました![]()
CronJobControllerV2 が GA となり、それとともに Job に関する機能が追加されたことによって今までずっと課題とされていた Job 周りの挙動がだいぶ整理されてきたので、その流れの中でタイムゾーンの機能も実装されると思っていたので意外でした。
Job周りの機能は今回でだいぶ増えて落ち着いてきた印象があるので、次回は今回 revert されて延期となった PersistentVolumeClaimDeletePoilcy など Stateful 周りの変更が増えてくるのかなと楽しみにしてます。