はじめに
Pods は Kubernetes の中でもっとも重要なリソースです。複数のコンテナとボリュームの組み合わせで Kubernetes におけるスケールの最小単位であり、アプリケーションコンテナは必ず Pods としてデプロイされます。
ここでは Pods の終了の流れについて詳しく扱います。Deployments の更新などで新しいバージョンのアプリケーションをデプロイするとき、既存の Pods は終了されます。このとき正しく Pods の終了処理を準備できていないと、ユーザのリクエストが正しく処理されずエラーが出力されているかもしれません。ワンオフなジョブと異なり、サーバとしてデプロイされる Pods はそれと比べて比較的寿命は長く、更新の頻度は少ないかもしれません。しかしサービスの価値をいち早くユーザに届けるに頻繁なデプロイは欠かせません。よりデプロイの頻度が高くなるほど Pods が終了される頻度が高くなり、その都度エラーが出力されているとユーザの信頼を少しずつ失っていきます。これは一般的な仮想マシンにおけるサーバプロセスの終了でも同じことですが、Kubernetes は分散システムであるため、その処理の流れが分かりにくくなっています。Kubernetes のプロダクションでの利用を前に Pods の終了の流れを理解しておきましょう。
このエントリは公式ドキュメント Termination of Pods と大部分が同じ内容です。それに加えて Kubernetes のシステムコンポーネントそれぞれが各フェイズでどのように機能しているかを説明します。また Kubernetes 1.8 での内容です。それ以外のバージョンでは異なっている可能性があることに注意してください。
Pods の終了
全体の流れです。次から各フェイズについてそれぞれみていきます。
- ユーザが Pod を削除するコマンド (kubectl delete) を送信する。デフォルトの猶予期間(GracePeriod) は30秒。
- Grace Period から Pod が死ぬと考えられる日時が API Server の Pod に設定される
- Pod はクライアントからリストされた際に Terminating と表示される
- (3 と同時に) kubelet が 2 において Pod が Terminating と設定されたことが分かると、Pod のシャットダウンプロセスを開始する
- Pod に preStop フックが定義されている場合、Pod 内でそれが呼び出される。もし preStop フックが猶予期間を過ぎてもまだ実行されている場合、直ちに次の処理に移行し猶予期間を2秒に設定する。
- Pod 内のプロセスに SIGTERM が送信される。もし猶予期間が過ぎてもまだプロセスが終了していない場合、SIGKILL が送信される
- (3 と同時に) Service のエンドポイントのリストから Pod が削除される
- (3 と同時に) ReplicaSets, ReplicationControllers で Pod が管理対象から削除される
1. ユーザが Pod を削除するコマンド (kubectl delete) を送信する
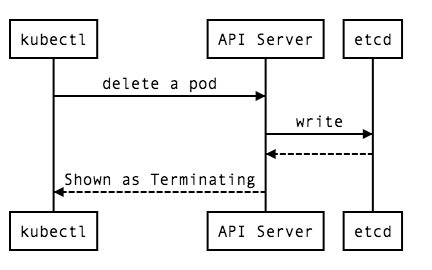
[](
https://bramp.github.io/js-sequence-diagrams/
kubectl->API Server: delete a pod
API Server->etcd: write
etcd-->API Server:
API Server-->kubectl: Shown as Terminating
)
Pod の削除をリクエストする最初のフェイズです。クライアントから API Server に対してリクエストされます。ユーザからの kubectl delete pod によるものも controller-manager からによるものでも同様です。Pod の削除には、その Pod が Graceful に終了するために必要な猶予時間(秒)を指定する gracePeriodSeconds パラメータ1 を指定することができ、デフォルトは30秒です。0 が指定されている場合、ただちに削除を実行することを意味します。このパラメータによる猶予時間の指定は PodSpec terminationGracePeriodSeconds を上書きします。2
terminationGracePeriodSeconds (integer): Optional duration in seconds the pod needs to terminate gracefully. May be decreased in delete request. Value must be non-negative integer. The value zero indicates delete immediately. If this value is nil, the default grace period will be used instead. The grace period is the duration in seconds after the processes running in the pod are sent a termination signal and the time when the processes are forcibly halted with a kill signal. Set this value longer than the expected cleanup time for your process. Defaults to 30 seconds.
2. Grace Period から Pod が死ぬと考えられる日時が API Server の Pod に設定される
API Server はクライアントから Pod 削除のリクエストを受け取ると、削除対象の Pod リソースの metadata deletionTimestamp (削除されるであろう日時) と deletionGracePeriodSeconds (削除猶予時間(秒)) を設定し、etcd に書き込みます。3
ここから先は分散システムの世界です。並列(Parallel)、非同期で実行されることに注意してください。他のシステムコンポーネントは、Pod のステートの変更を API Server を通じて監視しており、このフェイズで deletionTimestamp が設定されたことが、Pod の終了プロセスの開始の合図になっています。システムコンポーネントそれぞれがその合図を元に自律的に動作します。
3. Pod はクライアントからリストされた際に Terminating と表示される
Pod リソースの metadata deletionTimestamp に値が設定されたことにより、kubectl get pods コマンドの結果で得られるの Pod のステータスに Terminating と表示されるようになります。4
4. (3 と同時に) kubelet が Pod のシャットダウンプロセスを開始する
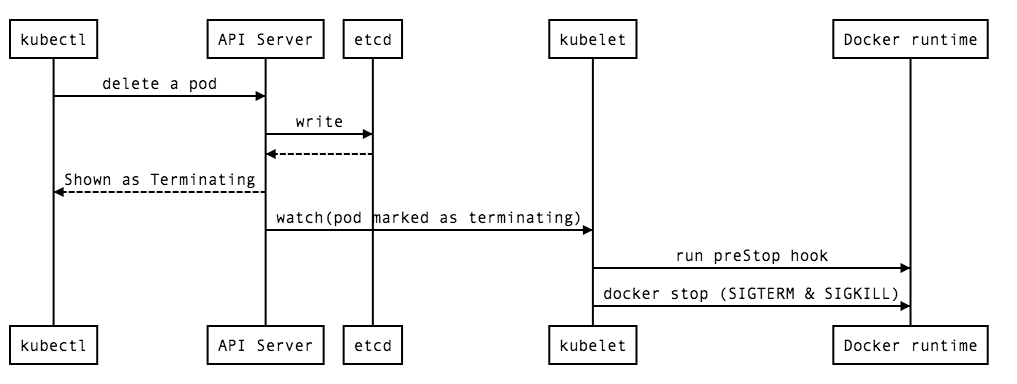
[](
kubectl->API Server: delete a pod
API Server->etcd: write
etcd-->API Server:
API Server-->kubectl: Shown as Terminating
API Server->kubelet: watch(pod marked as terminating)
kubelet->Docker runtime: run preStop hook
kubelet->Docker runtime: docker stop (SIGTERM & SIGKILL)
)
kubelet は API Server を通じて Pod リソースの変更を監視しており、metadata deletionTimestamp が設定されたことを合図に Pod のシャットダウンプロセスを開始します。
まず最初にその Pod に preStop フックが定義されている場合、それが kubelet から実行されます。5 preStop フックは Pod のシャットダウンプロセスの最初に実行され、コンテナを正常終了させるために任意のコマンド (exec)や HTTP GET (httpGet)、TCP Socket (tcpSocket)のアクションを選択できます。
ここで重要なのが preStop フックは同期でなければならないということです。exec の場合、このコマンドが非同期で終了処理を行ってしまうと、kubelet は preStop フックのフェイズが終了したと判断し、ただちに次のフェイズに遷移してしまいます。そのため、もし非同期であるなら終了処理にかかる時間を目安に sleep させる必要があります。
preStop: PreStop is called immediately before a container is terminated. The container is terminated after the handler completes. The reason for termination is passed to the handler. Regardless of the outcome of the handler, the container is eventually terminated. Other management of the container blocks until the hook completes.
preStop フックの実行が終了したら、実行にかかった時間を GracePeriodSeconds (猶予時間) から引いた時間(秒)で GracePeriodSeconds を更新します。もし GracePeriodSeconds を過ぎてもまだ preStop フックが終了していなかったら、kubelet はただちに次の処理に移行し6、GracePeriodSeconds を2秒に設定します。
次に kubelet からコンテナランタイムを通じてコンテナ内のプロセスに SIGTERM が送信されます。もし GracePeriodSeconds を過ぎてもまだコンテナ内のプロセスが実行中であれば SIGKILL が送信されます。
このシグナルの送信は Docker ランタイムのコンテナ停止命令 (docker stop) に GracePeriodSeconds をタイムアウト値として引数に渡され実行されています。7 8 9 Docker のコンテナ停止命令は、t パラメータとしてタイムアウト値を取り、まずコンテナ内のプロセスに対して SIGTERM を送信します。タイムアウト値を過ぎてもプロセスが終了しない場合、SIGKILL が送信されます。10
t (integer): Number of seconds to wait before killing the container
5. (3 と同時に) Service のエンドポイントのリストから Pod が削除される

[](
kubectl->API Server: delete a pod
API Server->etcd: Write
etcd-->API Server:
API Server-->kubectl: Shown as Terminating
API Server->endpoints controller: watch(pod marked as terminating)
endpoints controller->API Server: Remove a pod from endpoint of all services
API Server->etcd: Write
etcd-->API Server:
API Server->kube−proxy: watch(update endpoints)
Note right of kube−proxy: Update iptables rules
)
endpoints controller (controller-manager) は、kubelet と同様に API Server を通じて Pod リソースの変更を監視しており、metadata deletionTimestamp が設定されたことを合図に Service のエンドポイントのリストから Pod の IP アドレスを削除します。11 また kube-proxy は、Service のエンドポイントの更新を API Server を通じて監視しており、Pod の IP アドレスがエンドポイントのリストから削除されたことから、iptables のルールを変更します。これはこれ以降 Service の
ClusterIP 経由で Pod で新規コネクションが確立しなくなることを意味しています。もちろん処理中のものや Keep-Alive などにより接続済のコネクションは残っています。
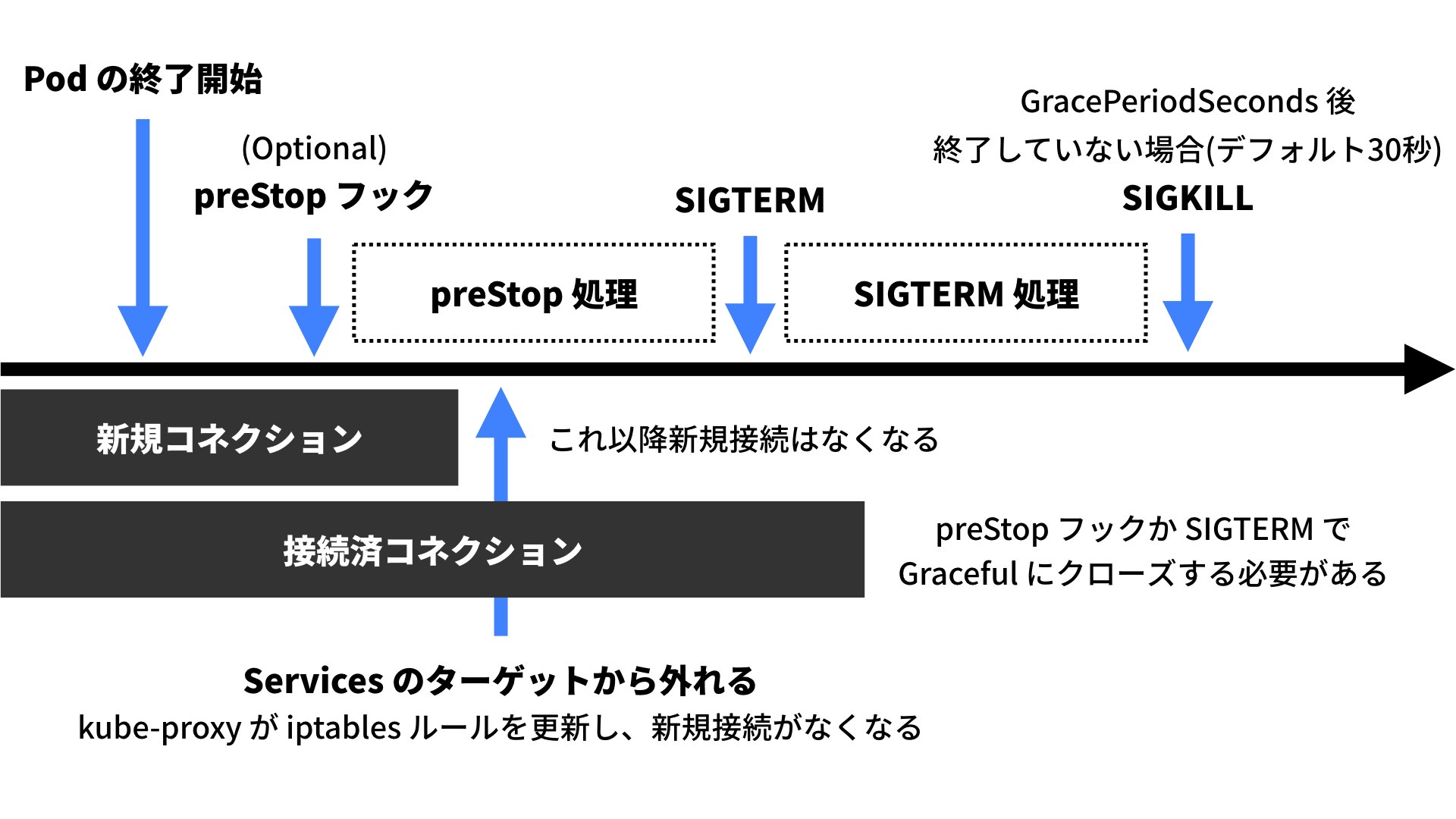
ここで注意しなければいけないことは、Pod preStop フックの実行と Service エンドポイントから Pod IP アドレスの削除は並列して実行されているということです。これはどちらが先に実行されるか分からないことを意味します。通常アプリケーションサーバを終了する場合、新規コネクションが確立されないようにしてから、Keep-Alive などで残っている接続済のコネクションをクローズし、コネクション数が0になる、またはタイムアウトによりサーバをクローズします。しかし、Kubernetes は分散システムであることから各システムコンポーネントは並列で処理を実行するため、ClusterIP 経由での新規コネクションが作成されないようにする前に、preStop フックによる Graceful Shutdown の処理が実行される可能性があります。これは仕様です。12 そのため、正常に終了させるには次のどちらかの方法をとる必要があります。
- preStop フックまたは SIGTERM の受信で Graceful Shutdown 中も新規コネクションを受け入れるようにする
- preStop フックまたは SIGTERM の受信で Graceful Shutdown 実行前に数秒 sleep し、ClusterIP 経由で新規コネクションが確立されないように待つ
このどちらかにしなければ正常に Graceful Shutdown を行うことができません。例えば nginx コンテナの場合、Graceful Shutdown を行うには nginx -s quit を実行しますが、実際にはこの実行前に数秒 sleep しないとシャットダウン中に新規コネクションを作成しようとされる可能性があり、もしそうなるとクライアントにコネクションエラーが返ります。
apiVersion: apps/v1beta2
kind: Deployment
metadata:
labels:
app: graceful-nginx
name: graceful-nginx
spec:
selector:
matchLabels:
app: graceful-nginx
template:
metadata:
labels:
app: graceful-nginx
spec:
containers:
- image: nginx:1.13
name: graceful-nginx
livenessProbe:
httpGet:
path: /
port: 80
timeoutSeconds: 20
readinessProbe:
httpGet:
path: /
port: 80
timeoutSeconds: 20
lifecycle:
preStop:
exec:
command: ["sh", "-c", "sleep 1; nginx -s quit; sleep 5"]
6. (3 と同時に) ReplicaSets, ReplicationControllers から Pod が管理対象から削除される

[](
kubectl->API Server: delete a pod
API Server->etcd: write
etcd-->API Server:
API Server-->kubectl: Shown as Terminating
API Server->replicasets controller: watch(pod marked as terminating)
Note right of replicasets controller: no longer consider as part of the set of running pods
)
replicasets controller, replicationcontrollers controller (controller-manager) は、kubelet と同様に API Server を通じて Pod リソースの変更を監視しており、metadata deletionTimestamp が設定されたことを合図に ReplicaSets および ReplicationControllers で Pod が管理対象から削除されます。これは、ReplicaSets のレプリカ数として終了する Pod がカウントされなくなることを意味しています。これにより Pod の終了を待たずに新たに新しい Pod の作成が開始され、完全に終了するまでに時間のかかる Pod に Deployments のローリングアップデートがブロックされないようになっています。また処理に時間のかかるサーバを時間をかけて終了させることができます。
おわりに
Pods の終了についてみてきました。またその中でシステムコンポーネントそれぞれがどのように機能するのか説明しました。今回のように内部の仕組みを少し理解しておくことでアプリケーションをよりよく構成することにもつながります。ぜひ Pods の他、Services, ReplicaSets, Ingress などどのように機能しているのかのぞいてみてください。
-
https://github.com/kubernetes/kubernetes/blob/v1.8.3/pkg/registry/core/pod/strategy.go#L137-L163 ↩
-
https://github.com/kubernetes/kubernetes/blob/v1.8.3/staging/src/k8s.io/apiserver/pkg/registry/rest/delete.go#L127-L128 ↩
-
https://github.com/kubernetes/kubernetes/blob/v1.8.3/pkg/printers/internalversion/printers.go#L613-L615 ↩
-
https://github.com/kubernetes/kubernetes/blob/v1.8.3/pkg/kubelet/kuberuntime/kuberuntime_container.go#L577-L580 ↩
-
https://github.com/kubernetes/kubernetes/blob/v1.8.3/pkg/kubelet/kuberuntime/kuberuntime_container.go#L473-L496 ↩
-
https://github.com/kubernetes/kubernetes/blob/v1.8.3/pkg/kubelet/dockershim/docker_container.go#L259-L262 ↩
-
https://github.com/kubernetes/kubernetes/blob/v1.8.3/pkg/kubelet/dockershim/libdocker/kube_docker_client.go#L154-L163 ↩
-
https://github.com/kubernetes/kubernetes/blob/v1.8.3/vendor/github.com/docker/docker/client/container_stop.go#L11-L21 ↩
-
https://docs.docker.com/engine/api/v1.32/#operation/ContainerStop ↩
-
https://github.com/kubernetes/kubernetes/blob/v1.8.3/pkg/controller/endpoint/endpoints_controller.go#L442-L445 ↩