はじめに
先日、2025/01/20 にAmazon S3 Tablesが東京リージョンで利用可能になりました。
そこで今回は、Amazon S3 Tablesについて以下を中心に解説していきます。
- Amazon S3 Tablesとは何か
- 既存構成との違い
- 実際の使い方
実際に検証した内容も含めて紹介するので、導入を検討されている方の参考になれば幸いです。
Amazon S3 Tablesについて
概要
Amazon S3 Tablesは、Apache Icebergサポートが組み込まれた初のクラウドオブジェクトストアです。
以下のサービスとシームレスに連携可能です。
- Amazon Athena
- Amazon Redshift
- Amazon EMR
- Apache Spark
また、継続的なテーブルメンテナンス機能を備えており、クエリ性能の最適化やストレージコストの削減を自動的に実施してくれます。
主なメリット
では、既存のS3 + Glue + クエリエンジン(Athena, Redshift, EMR, Spark)の組み合わせとどう違うのでしょうか?
大きく異なるポイントは2つあると考えております。
1つ目は クエリパフォーマンスの最適化
Icebergテーブルをセルフマネージドで運用する場合と比較して、
クエリ性能が最大3倍高速化、1秒あたりのトランザクション数が10倍増加します。
2つ目は 管理コストの低減
自動的な以下のメンテナンス機能により、管理の手間を大幅に削減:
- コンパクション(ファイル統合)
- スナップショット管理
- 未使用ファイルの削除
参照:https://aws.amazon.com/jp/s3/features/tables/
おおまかにですが、以上の2点が既存の手法と比べて優れている点なのではないかと思います。
個人的に嬉しいポイント
①コンパクションの部分と②データの削除メンテナンス機能がとても画期的だと感じております。
コンパクションは、一定サイズ(デフォルト512MB)のファイルになるように、複数の小さなファイルを1つのファイルにまとめてくれる機能です。
Amazon Athena のパフォーマンスチューニング Tips トップ10 にもあるようにAthenaでクエリするS3上のファイルはほどよく大きい方がクエリのパフォーマンスが高いです。

私も現場で度々、大量のサイズの小さいログデータファイルが配置されたS3に対してクエリを実行するという機会があったのですが、わかりやすくパフォーマンスが低下します。これを自動でメンテナンスしてくれるというのは大変ありがたいです。
②データの削除
既存の構成(S3, Glue, Athena)では特定のデータを削除することができません。
それだと何が不都合だったかというと、GDPR対応などで特定のユーザーのデータだけを削除するということができませんでした。そのため、AthenaではなくDelta Lakeなどを導入してどうにかして特定のユーザーのデータを削除するということをしておりました。Apache IcebergテーブルデータだとAthena上でDELETE文を実行するだけでそれが可能になるため運用がかなり楽になります。
参考:https://docs.aws.amazon.com/ja_jp/athena/latest/ug/delete-statement.html
使ってみた
百聞は一見にしかず ということで実際に使って検証してみましょう。
テーブルバケットの作成
まずはテーブルバケットを作成していきます。
AWSコンソールからS3のサービスを選択し、ナビゲーションペインの部分からテーブルバケットを選択
そして "テーブルバケットを作成"

今回は inu-is-dog-s3-table-test というバケットを作成します。


無事、作成できました。(アカウントIDは伏せさせていただいております。)
データの投入
AWSが公開しているチュートリアルに従って、
Amazon EMRを使ってデータを投入していきます。
まずEMRのIAMロールを作成します。
CloudShellを開いて以下のコマンドを実行

~ $ aws emr create-default-roles
これでIAMロール EMR_EC2_DefaultRole が作成されました。
次にこのロールに AmazonS3TablesFullAccess ポリシーをアタッチしたいので以下のコマンドを実行します。
aws iam attach-role-policy --role-name EMR_EC2_DefaultRole --policy-arn arn:aws:iam::aws:policy/AmazonS3TablesFullAccess
これでアタッチが完了しました。
一応、IAMの画面でも確認しておきましょう。

きちんと追加されていますね。大丈夫そうです。
では、EMRクラスターを起動してみましょう。
下ごしらえとして、CloudShell上で configurations.jsonファイルを生成します。
echo "[{\"Classification\":\"iceberg-defaults\",\"Properties\":{\"iceberg.enabled\":\"true\"}}]" > configurations.json
そしてキーペアをCloudShellにアップロードした後、以下のコマンドをCloudShell上で実行します。
aws emr create-cluster --release-label emr-7.5.0 \
--applications Name=Spark \
--configurations file://configurations.json \
--region ap-northeast-1 \
--name My_Spark_Iceberg_Cluster \
--log-uri s3://inu-is-dog-log/emr/ \
--instance-type m5.xlarge \
--instance-count 2 \
--service-role EMR_DefaultRole \
--ec2-attributes \
InstanceProfile=EMR_EC2_DefaultRole,SubnetId=subnet-1234567890abcdef0,KeyName=junjun-key
サブネットのsubnet-1234567890abcdef0 と EMRインスタンスへのキーペア junjun-keyはご自身の環境にあわせてカスタマイズしてください。
私の設定ですと、s3://inu-is-dog-log/emr/ 配下にログファイルを生成するので EMR_DefaultRole にこのS3へのアクセス許可をしております。これを忘れるとログファイルを保存できなくなってしまうのでお忘れなきよう。
このコマンドを実行してエラーが出なければ、EMRクラスターが生成されているはずです。

AWSコンソールでも確認してみましょう。
EMRクラスターが無事生成されていますね。

EMR Clusterの準備ができたら、CloudShellからSSH接続してみましょう
SSHコマンドはこちらから参照できます。

このご機嫌な画面がでてきたらSSH接続成功です。

それではSpark Shellを立ち上げましょう
※ は置換してください。
spark-shell \
--packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \
--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \
--conf spark.sql.catalog.s3tablesbucket.warehouse=<S3 Tables BucketのARN> \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
お馴染み(?)のSparkの画面が出てきましたね。

Spark SQLコマンドでnamespaceを作成します。今回はinuspaceというnamespaceを作ってみます。
scala> spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.inuspace")
res0: org.apache.spark.sql.DataFrame = []
namespaceができたようです。確認しましょう。
scala> spark.sql("SHOW NAMESPACES IN s3tablesbucket").show()
~中略~
+---------+
|namespace|
+---------+
| inuspace|
+---------+
無事、作成されたようです。
次に、Icebergテーブルを作成します。テーブル名はdog_tableです。
scala> spark.sql(
""" CREATE TABLE IF NOT EXISTS s3tablesbucket.inuspace.dog_table (
id INT,
name STRING,
value INT
)
USING iceberg """
)
作成したdog_tableにデータを投入します。
scala> spark.sql(
"""
INSERT INTO s3tablesbucket.inuspace.dog_table
VALUES
(1, 'ABC', 100),
(2, 'XYZ', 200)
""")
show()関数でデータを確認しましょう。
scala> spark.sql(""" SELECT * FROM s3tablesbucket.inuspace.dog_table """).show()
+---+----+-----+
| id|name|value|
+---+----+-----+
| 1| ABC| 100|
| 2| XYZ| 200|
+---+----+-----+
これでS3 Tables Bucketへのデータの投入は以上となります。
EMRクラスターは用済みなので終了しておきましょう。(残っていると費用がかかってしまいますので)
aws emr terminate-clusters --cluster-ids <cluster-id>
S3 Tables Bucketの確認
では、namespace、tableを作成したテーブルバケットをAWSコンソール上で確認してみましょう。

AWS Lake Formation 権限付与
データができたということでこのデータにアクセスしてクエリできるように権限設定していきたいと思います。
AWS Lake Formation をAWSコンソールで開き、s3tablescatalog にGrantしていきます。
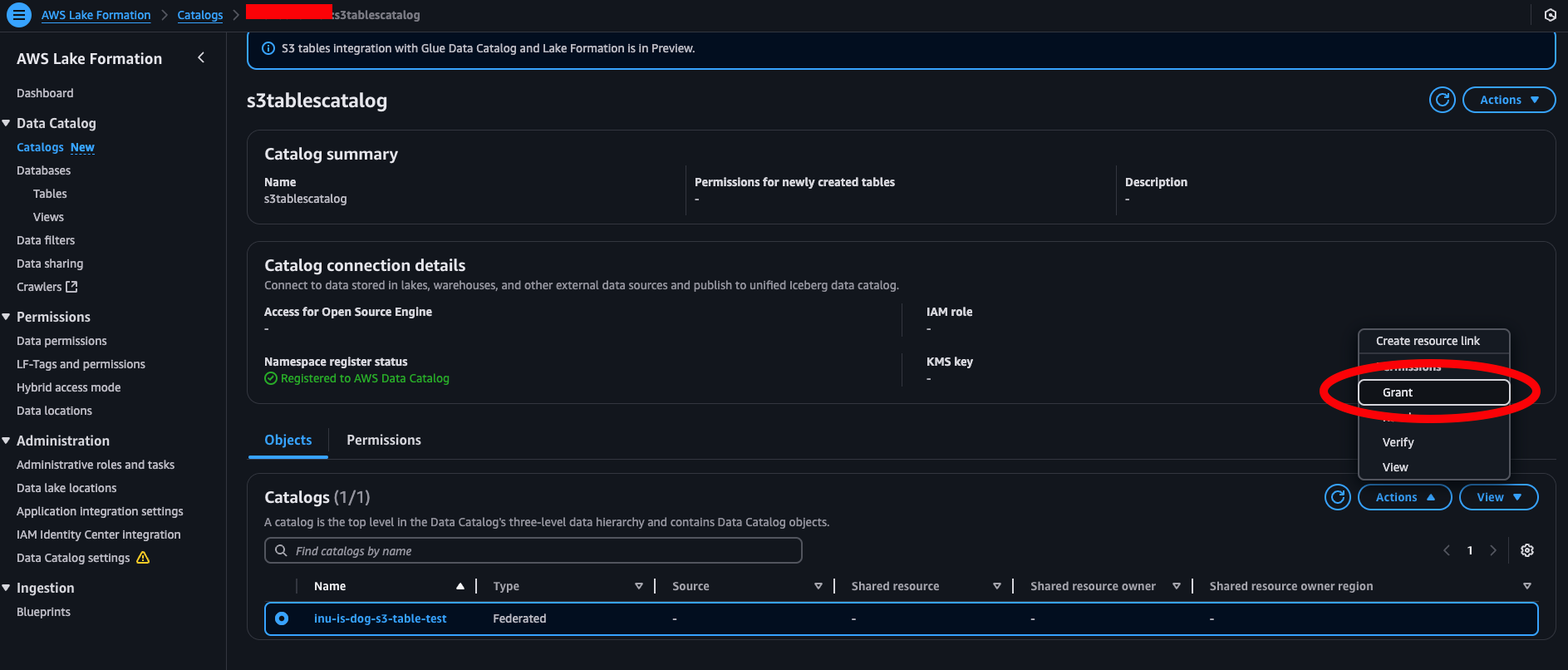
今回はIAMユーザー junjun に以下のように権限付与していきます。


これで権限付与は完了です。
Athena連携
AWSのコンソールでAthenaを開きます。
データソースをAwsDataCatalog、
カタログをs3tablescatalog/inu-is-dog-s3-tables-test、
データベースをinuspaceに設定し、以下のクエリを実行
SELECT * FROM "inuspace"."dog_table" LIMIT 10;

無事、データを取得することができました。
データの削除も試してみましょう。
DELETE文を実行した後、
DELETE FROM "inuspace"."dog_table" WHERE id = 1;
再度、データを取得。データがちゃんと消えていますね。素晴らしい。

これで検証は以上になります。
最後に
この記事がこれからAmazon S3 Tablesを使ってみたいという方のご助力になれば幸いです。
所感としては、データ(テーブル)のメンテナンスコストがかなり低減された一方で、テーブルの作成はEMRやData Firehose経由でなければならない点のハードルの高さが気になりました。このあたりが既存の構成(S3, Glue, Athena)と同じようにサクッと導入できるようになればより嬉しいですね。
AWS Athenaについて詳しく知りたい方はこちらをどうぞ