初めに
具体的なコードや方法も記述しますが、それよりも JUnit などの自動テストのFW、ユニットテストの概念や目的など本質的なことを把握し理解する事を主題にしてます。
また、参考資料欄にあるように、様々なものを参考に網羅的にまとめています。非常にボリュームがるので興味あるところだけ読んでもらう方が良いかもしれません。
こちらでは、ある程度開発経験(1〜2年程度)があり、自動テストについて少しでも触れた事があるくらいの方が対象になる記事です。自分がそうだからです。ただし、コンパイルエラーにならないだけの書き方では意味がないのでそういった構文やお作法に関する話はあまりしません。なぜそのようなお作法になったのか?そうである理由は何なのか?トレードオフは?といった、本質的な部分にフォーカスを当てていきたいと思います。
1. 概要
JUnit は Java 言語向けのユニットテストフレームワークです。
1997年に、Smalltalk のためのユニットテストのフレームワークであるSUnitをもとにして、エーリヒ・ガンマと、SUnitの開発者のケント・ベックが中心となって開発されました。飛行機の中でペアプロして作っちゃったというエピソードがあります。
JUnitは最も有名なオープンソースのユニットテストフレームワークで、Javaアプリケーション開発者にとって非常に有用なツール。JUnitは、シンプルなアサーションを使用して、開発者がコードが期待どおりに動作するかどうかをテストすることを可能にしています。JUnitを使用することで、開発者は、コードの品質を外部に定量的に示すことができ(※ これには注意が必要。カバレッジの項にて合わせて解説します)、エラーを早期に検出して修正することができるようになります。
JUnitは、多くのIDEがデフォルトでサポートしていて、Eclipse、NetBeans、IntelliJなどのIDEでは標準装備です。
具体的には、Javaのプログラムをテストするためのテストケースを定義し、テストケースを実行して、テスト結果を把握することができます。JUnitを使用することで、開発者は、変更を加えたコードが思わしくない動作をしないことを保証できるようになります。
2. ソフトウェアテストの目的
ソフトウェアテストとは、あるソフトウェアを実行し、そのソフトウェアが特定の方法で動作することを保証するものです。
ソフトウェアテストによって、ソフトウェアのある部分が期待通りに動作することを保証します。これらのテストは通常、ビルドシステムを通じて自動的に実行されるため、開発者が開発活動中に既存のコードを壊さないようにするために役立ちます。
テストを自動的に実行することで、ソースコードの変更によって生じたソフトウェアのデグレード(修正したバグや不具合が復活したり、ソフトウェアのバージョンアップで機能が低下したりすること)を特定することができます。コードのテストカバレッジが高ければ(後述しますが注意が必要)、多くの手動テストを実行することなく、機能開発を継続することができます。
そもそも、なぜテストが必要かというと、プログラムは人間が書きます。そして人間は間違いを犯します。つまり、プログラムは間違っていることが前提となるわけでけです。そして、プログラムの間違いは人や企業に損害を与えることがあります。例えば、業務の中断・人手による代替・損害賠償・企業イメージ低下・人の財産や生命の損害、などなどが考えられます。なので、それらの損害を未然に防ぐために、リリース前に間違いを検知修正する必要がります。それがテストです。
もし、手動でのテストのみの場合は以下の様な問題が常に降り掛かります。
- 低い信頼性
- コスト・時間的制約から一度行ったテストは再度行われることは殆どない(回帰テストされない)
- デバッグが終了しているかどうかを開発者が確認しない(少ない)
- 機能追加時、影響範囲の特定が不明瞭
などが存在します。これらは企業そのものにも悪影響を与えます。テストを自動化すれば、上記の問題点の多くは解決します。詳細に関しては 「3-6. JUnit の特徴と問題点」 で解説します。
※回帰テスト
ソフトウェアプログラムに変更を加えた際、それによって新たな不具合が起きていないかを検証するテスト。今までのテストをやり直す。影響範囲の調査から始まりる。全て手動で行わなければならない場合は、プロダクトの規模に指数関数的に比例して時間と人的リソースを無駄に消費します。一ヶ月単位のリリースでは、毎月回帰テストが必要となり非常に大変。
テストには大まかに、以下の種類があります。本記事ではユニットテストについての記事なので他に関しては解説はありないですが、後述します。
- ① 単体テスト
- 各クラスやメソッドがちゃんと動作するか確認する
- ② 結合テスト
- いくつかのクラスをつなげてテストする(機能単位など)
- ③ システムテスト
- システム全体のテスト
- パフォーマンスやセキュリティのテストも行う
テストレベル・テストタイプなどの詳細に関しては、以下記事にてめっちゃ網羅的にまとめました。
2-1. 単体(ユニット)テスト
単体テストとは、開発者が書いたコードの一部で、テスト対象のコードの特定の機能を実行し、特定の動作や状態を保証するものです。ユニットテストによってテストされるコードの割合は、一般的にテストカバレッジと呼ばれます。依存関係をテストの実装やテストフレームワークで作成されたモックオブジェクト(テストダブルが正式名称)に置き換えることで、外部依存性をユニットテストから取り除くことができます。
ユニットテストは、コードの小さな単位、例えば、メソッドやクラスを対象とするため、複雑なユーザインターフェイスやコンポーネントの相互的なやりとりをテストするのには適していません。なので、外部システムに依存する動作をテストで再現するのは手間がかかります。再現する際にはテストダブルが必要です。再現できない部分については、統合テストで実施する必要があります。
テストダブルについての詳細は後述する 「8. モックなどのテストダブルとユニットテストについて」 にて。
ユニットテストの特徴を簡単に紹介します(詳細は 「3-6. JUnit の特徴と問題点」 で紹介)
-
プログラムとして実行できる仕様書となる(仕様を保証する)
- そのようなテストコードが正しく記述できていれば、という前提ですが
-
プログラムの修正のたびに繰り返し実施する
- 自動化が必須であり、JUnit のようなフレームワークで実現する
Junitなどのフレームワークを使用すれば
- テストの実行
- 検証
- テスト結果のレポートetc・・・
といった、テストケースとは直接関連しない面倒な部分を実装する必要がなくなります。フレームワークを使用することで、テストケースの設計と実装に専念できるようになるわけです。
2-2. ユニットテストを作成するべきタイミングと、その理由
- 何らかの機能のコーディングが完了し、期待どおりに振る舞うかどうか確認したい場合
- コードへの変更内容を記録し、自分や他の開発者が変更の意図を理解できるようにしたい場合
- コードを変更する必要があり、その際に既存の機能を損ねないようにしたい場合
- 現在のシステムのふるまいについて理解したい場合
- 他者によるコードが期待どおりに機能しなくなった際に、それがいつからなのか知りたい場合
何よりも重要なのは、よいユニットテストを行えば自信を持って実運用向けのシステムをリリースできるという点です。
2-3. バグが発生しやすい場所
バグが発生しやすい場所(状況)として以下のようなものがあります。
これらは重点的にテストすべき箇所となります。
-
境界値近傍の引数
- 境界値分析や同値クラス分析で対応。
-
ifやforループなどがネストしている箇所
- そもそもそういったネストは発生させない書き方をするのが先ですが。
-
if文の条件が複雑になっている箇所
- 余りにも複雑化するのであれば strategy パターンの採用なども見据えた再設計を行う事を検討した方がいいもしれません。
-
メソッド内で早期returnができる状況で早期returnをしていない場合
- 早期リターンするようにリファクタしましょう。
-
nullを取り扱っている箇所
- 極力 null を取り扱うのは避ける方がいいと思います。null 安全の考え方を取り入れる方がいい。
- どうしても発生してしまうところ以外では制御しましょう。null を取り扱う可能性を考慮するのは無駄でしかなく、バグの温床になります。
-
ローカル変数を使い回している箇所
- スコープや再代入などは制限し、必要な場合以外ローカル変数の寿命は短い方が良いです。
-
他プロダクト(他システムと)とのインターフェース境界部分
- ここは防御的に考えるべきでしょうか。どんな値がくるかのか信頼できませんから。
- あまり有名でないライブラリやサードパーティライブラリなどは、予期せぬ値が渡される可能性や、破壊的な変更が突然行われる可能性もあります。
- 標準ライブラリが使いづらい場合にサードパーティ製のライブラリを選択したくなるかもしれませんが、その際は長期的運用目線での検討が必要です。
-
不変ではない(可変の)変数やオブジェクトをマルチスレッドで扱っている場合
- より正確に言えば可変オブジェクトを複数のスレッド共有している状態です。ひとつのスレッドでの変更が、他のスレッド全てに意図せぬ変更を与える可能性があります。あり得る事を続けていればいつか必ず起きるので、そもそも可変オブジェクトを「共有する事」をやめるべきです。
- 共有したいのであれば「不変オブジェクト」を扱うか「ディフェンシブコピーで別のインスタンスの参照を扱う」などの手段を講じるべきです。
参考︰可変に対するセキュアなプログラミングについて
3. JUnit は単体テスト用のフレームワーク
単体テストは最も低いレベルでのソフトウェアテストです(静的テストがもっとも低いという考え方もあります)。Javaの世界の単体テストでは、通常、特定のメソッドが正しい結果を返すかどうかをチェックします。
すべての優れたソフトウェアには単体テストが必要であり、すべてのソフトウェア開発者は単体テストを書くべきとの意見がよく見られます。単体テストは、開発中の信頼性を高め、よりクリーンで再利用可能なコードを書くことに繋がるからです。
クラスの単体テストを書こうとしてそれができない場合は、クラス設計が間違っている可能性があります。よく言われるのは、DIP(依存性逆転原則)が適切に適用されていない場合などです。JUnitで行うテストはユニットの独立性が前提となります。ここに関しては 「9. 良いユニットテストであるための原則『FIRST』」 にて解説します。
正しい単体テストはミスのコストを低減します。バグを修正するのは、アプリケーションがバグを検出するときよりも、開発の早い段階で検出した方がはるかに簡単です。単体テストは通常、ソフトウェアではなく、新しい機能を作成する際にソフトウェア開発者によって作成されます。以下の画像は、いわゆるテストピラミッドを示しています。
ピラミッドの下位から上位に向かうにしたがってコストがかさむことを表しています。幅がテストケースの実行量を表現し、より下位のテストにテストケースを移動した方がコストの改善に繋がることを意味します。 テストを充実させるためには、テストをこのピラミッドの下位へ寄せていくように工夫する必要があります。
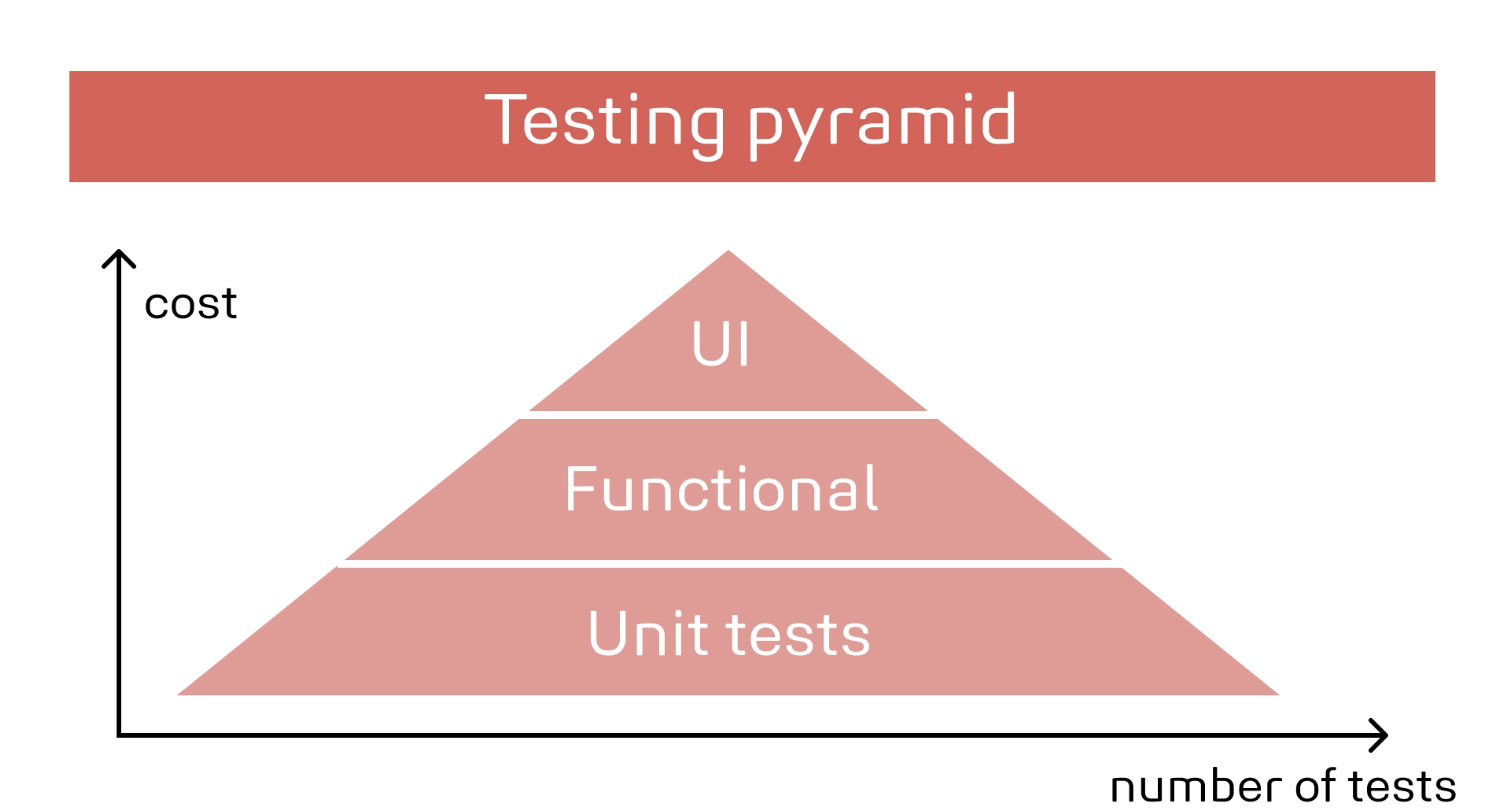
本質的に、統合テストは単体テストに比べて作成も保守も難しいものです。成功しなくなることも多く、その場合のデバッグには長い時間がかかります。 しかし、統合テストは依然としてテストの中で重要な役割を果たしています。統合テストは必須のものですが、設計と保守は容易ではありません。ユニットテストを使って検証できるロジックを最大限に増やし、統合テストの数や複雑さを減らようにするべきでしょう。
ただし近年では、統合テストに最も重きを置いたテスト戦略が有用な場合もあると言われています。テスティングトロフィーという考え方です。以下の記事にて触れております。
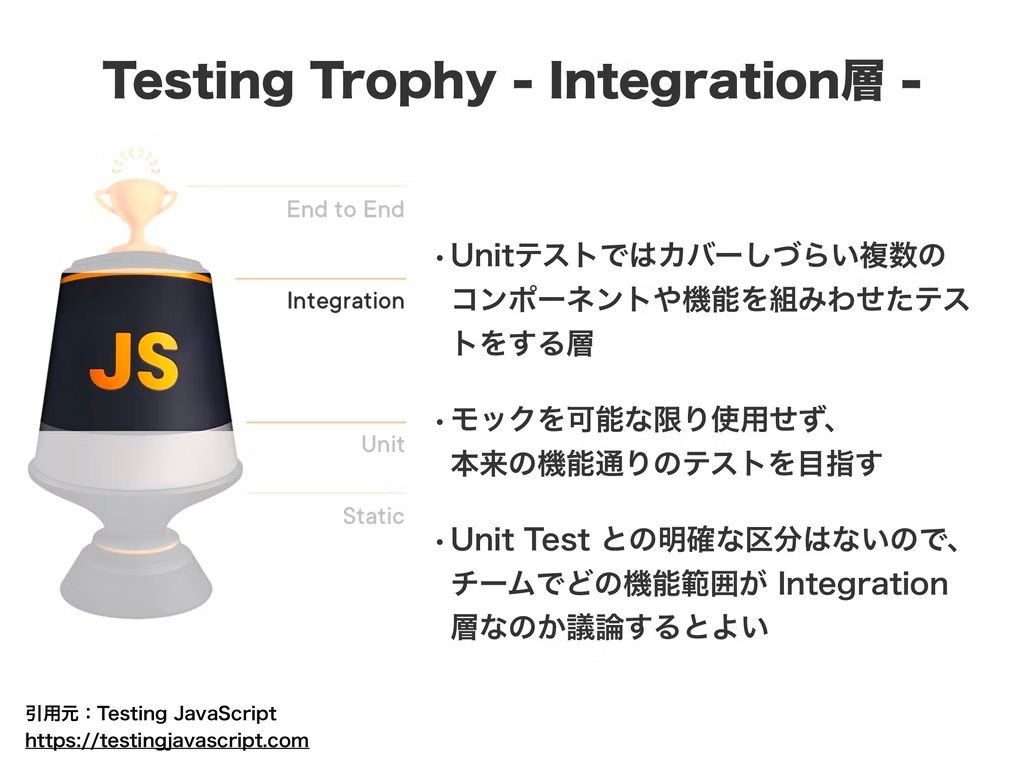
しかし、ピラミッドの上に行くほど、それぞれのテストの信頼指数が高くなることは、この図では示されていません。(中略)統合テストは、信頼性と速度 費用のトレードオフのバランスをうまくとっています。 このため、ほとんどの労力をそこに費やすことが推奨されます (すべてではありませんが)。
https://kentododds.com/blog/write-tests より引用
3-1. JUnit4 と JUnit5
JUnit4 と JUnit5 に互換性はありません。使い方・アーキテクチャも全て異なります。また、5 からは「ラムダ」が導入され、関数型言語のパラダイムが使用できる様になっています。assertAll()やassertThrows()などで使用できます。その他、以下の様な違いがあります。
- アノテーションが一部異なっている
- テストクラス・テストメソッドの可視性が違う
- 4 は public でないとダメ、5 はパッケージプライベートでもOK
- Hamcrest(assertThat)マッチャーは 5 ではデフォルトでは同梱されていない
- 後から追加することはできる
- 5 で モック を使用したい場合は、@ExtendWith(MockitoExtension.class) を付与
ついでに、3 と 5 の違いも
- アノテーションがない
- テストクラスは TestCase を継承する必要がある
- テストメソッドは test で始める
- テストクラス・テストメソッドは public
ただ、4 上で5のテストを動かしたり、5上で4のテストを動かしたりすることは可能ではあります。現在、新規に JUnit を導入する場合は 5 を一択と言われています。4 のサポートがいつ切れるかわかりません。
3-2. JUnit はホワイトボックステスト
仕様を元に準備値と期待結果のみをテストする
ブラックボックステストは、テスト対象の仕様を元に動作を確認します。テスト対象のロジックそのものの内容を知る必要がありません。渡した引数に対しての戻り値がなんであるかが解れば、実装の詳細について知る必要がありません。
仕様を元に準備値から期待結果までのロジックもテストする
対してホワイトボックステストは、テスト対象のロジックそのものに対してテストを行うため、実装の詳細について知る必要があります。実装の詳細・ロジックが正しいかどうかをテストするためです。
3-2-1. 単体テストはブラックボックステストであるべき??
t_wada さん曰く、「ユニットテストもブラックボックステストであるべきなんですよね。振る舞いをテストするべきだと思います」というようなことをポッドキャストでおっしゃっています。
実装の観点からテストを行うのではなくて、どうあるべきか?といった振る舞いの観点から実施するべきだと思っています。詳しくは後述する
- 「5-3. メソッドではなくふるまいをテストすることによって、テストの保守を容易にする」
- 「10-1. 単体テストの定義と性質」
にて解説しています。
3-3. ホワイトボックステストの実行手順
- 実装されているプログラムを分析する
- プログラム中のパス (実行経路)を把握する
- if などの条件分岐でプログラムの実行経路が何パターンあるか?
- 試験を行うパスを決定する
- 指定したパスを通るような条件を求める
- 試験を実施する
- 実行経路のパターン数分実施する
- 試験結果と期待値を比較する
- テスト対象が意図通りの動作を行っているか判定する
3−4. カバレッジとコードの品質
カバレッジとはテスト網羅率のことです。ソフトウェアテスト進捗を表す尺度。テスト対象ソースコードのうち、どの程度の割合のコードがテストされたかを表します。適当なテスト内容でもテストを実施していればカバレッジを上げることはできます。必ずしも数字が高ければコードの品質が高い、ということに直結しない場合もあるので盲信には注意が必要です。
カバレッジには以下の特徴があります。
-
「適切な境界値分析ができていなくても検出できない」
- 境界値に関しては後述します
- テスト時に実装されている処理・条件で通っていれば(正しいかどうかは考慮されず)100%になる
-
「仕様に対して実装が適切かどうかは判断できない」
- 上記のように、テスト時に実装されている全処理・全条件を通っていれば、正しい処理なのかは関係なく100%になる
結局は仕様をコードで実現できてるかどうかが重要であり、カバレッジはそういった前提でなければ意味のない指標になります。また、本当の意味で100%を目指すのならば、到達可能なパスの全パターン、その時にアクセス可能なデータの全パターン、それら全部の組み合わせを検証しなければならないのですが、現実的ではありません。カバレッジのみに重きを置くことはナンセンスです。 「3-8. ユニットテストと再設計・リファクタリング」 で後述しますが、品質保証としてのテストとして以外に、既存のプロダクトコードをより洗練(ビジネス的に)させる機会を提供するものという側面も重要です。
カバレッジが高すぎる場合は、逆に疑う方が良いかもしれません。テストコード(あるべき振る舞い)に実装を合わせたのではなく、実装にテストコードを合わせたのかもしれません。なんなら、検証も何もしないままでいる事もあるかもしれません。もちろん、全く無駄なテストになりますね。かといって、「カバレッジが低い=品質が低い」はある程度は因果関係あるのではと思います。
最初に、
JUnit はコードの品質を外部に定量的に示すことができ(※これには 注意が必要。カバレッジの項にて合わせて解説します)
と記述しました。ここで疑問があると表現したのはこの様な理由があったからです。
また、カバレッジを上げることにこだわりすぎる必要もありません。自動生成される getter / setter にはテスト不要ですし、すでに信頼性の高いライブラリなどに対しても不要です。自身のプロダクトに対して意識を向けましょう。
網羅率を上げるための基本的な考え方が以下の方法です。上記で言った、「到達可能なパスの全パターン、その時にアクセス可能なデータの全パターン、それら全部の組み合わせ」のうち「到達可能なパスの全パターン」を知る方法です。
| 網羅方法 | 内容 | 網羅率 (下にいくほど高い) |
|---|---|---|
| 命令網羅 | すべての命令を最低1回は実行 | C0 |
| 判定条件網羅 | 判定文によるすべての分岐を最低一回は実行。条件は特に考慮しない | C1 |
| 分岐条件網羅 | 判定文中のすべての条件を最低1回は実行 | C2 |
| 判定条件&分岐条件網羅 | 分岐条件を決める際に判定結果を考慮する | 中 (※イメージ) |
| 複数条件網羅 | 判定文中のすべての条件のすべての組み合わせを最低1回は実行 | 大 (※イメージ) |
| 経路組み合わせ網羅 | すべての経路(パス)を最低1回は実行 | 特大 (※イメージ) |
カバレッジの有効活用方法には、チームのヘルスチェックという観点があります。カバレッジの時間的な変化を観察することによってチームの品質管理に裂けているリソースを判断できます。カバレッジ率が低下している場合、テストコードの実装を妨げる障害が存在することを示唆します。
3-5. テストの網羅方法・同値分析と境界値分析
以下の過去記事にて紹介しております。
3-6. JUnit の特徴と問題点
特徴
- 一度作成すればすばやくテスト可能である。
- その後はテストコードを標本とすることでバグ訂正が容易となる。
- テストコードを見れば仕様が一目瞭然となる。
- 誰でも同じテストを行えるようになる。
- 独自のテストコードによるテスト作成の手間を省ける。
- 視覚的にデバッグの完了が確認できる。
以下は JUnit そのものというよりは自動テストのより重要な点となります。本記事全体で関連する話が出てきますので個別で解説というよりは、多角的に見ていくことになります。
- 再設計・リファクタリングの機会を提供できる。
- リファクタリングを円滑に実行するための環境を担保する。
既存のコードに変更を加えてもバグの検知が用意であるため、機能追加・リファクタリングを行い易くなります。それを大きな目的の一つとして、テストの自動化があるといってもいいかもしれません。
プログラムの変更コストやリスクが小さくなれば、市場の変化に追随し易くなることはもちろん、ユーザーのニーズに対しても素早く対応できる様になるでしょう。企業の競争力の増加に直結するといっても過言では無いでしょう。
人力のテストなんて非効率かつ非網羅的でただの自己満なんじゃ?エクセルにスクショペタペタ作業は苦痛でしかなかった.....。やろう思えばいくらでも改竄できるものがエビデンス扱いされていることに強い違和感でしかないですが、納品物として契約上存在するのだからやらざるを得ないのでね、社会人としてやるしかありません。。クソがっ!!
手動テストでは、テストの実行に多くの時間と人件費が発生する上、それでもバグは全て検知しきれません。プロダクトの規模が大きくなっていくのに対し、人間の認知能力は変わらないからです。人間の認知能力を超えた規模には人間では立ち向かえません。また、機能追加や修正などのプログラム変更に莫大なコストと時間が発生(影響調査。下手すれば追加やバグ修正無理です、なんていう解答すらあり得ます。というか、あった。。。。)し、競争力が低下することになります。
しかし.....。自動テストは「書いたことしかテストしない」のです。人間による手動テストはなくすことは出来ません....。手動テストは、驚くほどの量の暗黙的なテストが実施されております。それらを全て自動テストとして実装することはメンテナンスコストも考えると難しいのだろうなと思います。
問題点
-
仕様変更ごとにテストコードを作り直さなければならない。
- プロダクトコードの coupling(結合度)と cohesion(凝集度)を改善するためのテストコード自体が、プロダクトコードに強く依存している
- プロダクトコードに大きな修正が入った場合の、テストコードに及ぼす影響は甚大で、粒度が小さく数の多いユニットテストのメンテナンスコストは想像以上に大きい
-
テストコードがあるだけで、品質が高いと捉えられる
- 次の章で更に解説しますが、テストコードがある・カバレッジが高い = 品質が高いではない
- 「テストがコードのクオリティを上げる訳ではない、上げるのは開発者自身である」
-
書いたことしかテストできない
- 自動テストの意義としては、一度動いたはずの機能の不具合を発見することにあるため、未知のバグの発見ができるわけではない
- その様なバグはテストの実装時に発見されるはず
3-7. 実装とテストの両コードは資産ではなく負債
メンテナンスコストを思えば負債であることは自明です。費用対効果の観点で、要・不要を見極める必要があります。品質の担保、リファクタ時(機能追加・機能修正・障害対応時・設計修正も含む)のリグレッションテスト及び回帰テストの高速化・自動化によるリファクタ実行のハードル低下といったような2軸の観点が必要に思えます。
単体テストは品質保証・リファクタリングの下支えでありますが、全てのコードに対して実施する必要はないと考えてます。
- ビジネスロジック部分こそが最も単体テストが重要ですが、自明のロジックはやる必要もないのでは?
- プレゼンテーションロジック・UIに関しては、人間の目で見ないと意味がないのが多いので優先度は低めでよいのでは?
- 画面への表示順などはモデルとビューを適切に切り離して、なるべくビジネスロジックへのテスト実施で検証できるように設計する方がいよいと思われる。
- メンテナンスコストも考えると盲目的にカバレッジ100%を目指すのは悪手に思える。
- こちらに関しては後述する 「3−4. カバレッジとコードの品質」 で解説します。
3-8. ユニットテストと再設計・リファクタリング
ユニットテストを行えばコードの品質が上がる・高い、とは必ずしも言えません。品質を上げるには、適切な設計と継続的なリファクタリングが重要です。要件定義から最初のリリースまでの間ですら数多くの変更が発生します。当初の予定通りに進むことなど殆どないのがソフトウェア開発ではないでしょうか。
TDD再考 (2) – 何故、ほとんどのユニットテストは無駄なのか?
バグを取り除く最大の機会はテスト以外のところにある
これはウォーターフォール時代から言われていた事だが、プログラムの品質にもっとも重大な影響を及ぼすのは、要求・ドメインの分析結果を設計に落とし込むタイミングである。
ただ、プロダクト初期の設計で全ての品質を長期にわたって保証できる訳ではありません。設計によって変更に強くなるソフトウエアが作れるという考え方は、現在では否定的に捉えられる様になっています。なぜなら、現場では想像を超える多くの変化がはいってくるが、その変化の一つ一つは生きた変化であり、実際のユーザからの生きたニーズによる変化で取り入れざるを得ないからです。
設計によって備えるというのが、実際の生きた変化にどのくらいフィットできるのかというのは大きな疑問です。最初の設計で備えても大体においてその通りにはならないし、準備した備えは使う事がないことが多いというのは最早エンジニアにとっては共通認識ではないでしょうか。大事なのは、将来に必ずやってくる変更にいつでも対応できる様にするということです。今必要ないなら、やらない(YAGNI)。
リファクタリングと自動テストによって、設計を後から安全に変更できる様になりました。後から、現実にシステムを合わせる事ができる様になったわけです。これにより、設計に重きを置きすぎて硬直する事を回避できる様になり、変更に強い設計と後に変更することも見据えた設計も合わせた設計を行うことが重要視される様になりました。
新たな生きたニーズが入ってきたら、それに合わせた設計にする。既存との設計の差異・似ている部分をリファクタリングしながら見本としてのデザインパターンや、現状の中での理想に近づけていく。
変化に対して構造で備えるのではなく、備えない事・身軽でいる事が備えになるという考え方です。将来は何が起きるかわからないし、想像を超えた仕様変更がやってくる。現状の仕様を実現するコードを最もシンプルに設計・実装し、新たな仕様にもシンプルに対応する方がいいわけです。
こういった中でユニットテストは、品質保証としてのテストだけではなく、再設計とリファクタリングを「支える」ツールという側面の方が重要に思えてなりません。テストを書いて、カバレッジが高い、というだけで現状の問題点に気づこうとせず再設計の必要性を度外視するのであれば、それはただ回帰テストしているだけの現状追認にしかないのではないでしょうか。
それはそれで手動だけでいい加減にやろうとする所よりはいいではないんか!?
後述する 「6-4-1. プライベートメソッドのテストについて」 では、その辺りの話もしております。
4. 基本的なルール
4-1. テストクラスのルール
- テスト対象となるクラスに対し、対になるテストクラスを作成する
- 作成するテストクラスのクラス名は「テスト対象クラス名 + Test」とする
- テスト対象クラスとテストクラスのパッケージは同一構造にする
- これには方法が三つある(「5. テストクラスと対象クラスの分離」にて解説)
4-2. テストメソッドのルール
- @Test アノテーションを付与する
- 戻り値はvoid(戻り値なし)とする
- 引数は持たせない
- 各assertメソッドで期待値と実際値を検証する
4-3. @Testの注意点
- JUnit 5と4でパッケージ名が異なる
- JUnit 5:
org.junit.jupiter.api.Test - JUnit 4:
org.junit.Test - 期待する動作と異なる場合、 import文を確認する
5. テストクラスを構造化する
あるユニットテストではテスト対象となるクラスごとに対応するテストクラスを作成しますが、テストケースが増加してくるとテストコード自体の多さに認知的負荷が増大していきます。 また、テストコードは似たようなコードの繰り返しが多くなりがちです。なのでテストクラスを構造化することで可読性を高く保つ必要が出てきます。その際、構造化する上でグループ化を行います。その基準としてAAAを紹介します。まずは以下のコードを見てみましょう。
引用元:JUnit 5 チュートリアル - 単体テストの書き方を学ぶ
package com.vogella.junit5;
public class Calculator {
public int multiply(int a, int b) {
return a * b;
}
}
package com.vogella.junit5;
import static org.junit.jupiter.api.Assertions.assertEquals;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.RepeatedTest;
import org.junit.jupiter.api.Test;
class CalculatorTest {
Calculator calculator;
@BeforeEach // ❶
void setUp() {
calculator = new Calculator();
}
@Test // ❷
@DisplayName("掛け算の結果が、20になる") // ❸
void testMultiply() {
assertEquals(20, calculator.multiply(4, 5), // ❹
"Regular multiplication should work"); // ❺
}
@RepeatedTest(5) // ❻
@DisplayName("0の掛け算の結果は、必ず0になる")
void testMultiplyWithZero() {
assertEquals(0, calculator.multiply(0, 5), "Multiple with zero should be zero");
assertEquals(0, calculator.multiply(5, 0), "Multiple with zero should be zero");
}
}
- ❶. @BeforeEach でアノテーションが付けられたメソッドは、各テストの前に毎回実行されます。
- ❷. @Test アノテーションが付けられたメソッドは、テストメソッドとして定義されます。
- ❸. @DisplayName を使用して、ユーザーに表示されるテストの名前を定義できます。
- ❹. これは、期待値と実際の値が同じであることを検証する assert メソッドです。
- ❺. そうでない場合、メソッドの最後にメッセージが表示されます。なくても問題ありません。
- ❻. @RepeatedTest は、このテストメソッドが複数回 (この例では 5 回) 実行されることを定義します。
5-1. @Before と @After について
@BeforeAll/@BeforeEach
テストごとに行われる初期化や事前条件準備などの処理は @Before メソッドを使用します。@Beforeメソッドはセットアップメソッドとも呼ばれます。関連性のある一連のメソッドについてテストを追加してゆくと、複数のテストで同じ初期化の処理が行われているということがよくあります。このような場合に @Before メソッドを使うと、冗長なコードを集約し一元的に管理できます。
また、テストメソッドが正常に動作するための事前条件として、必要なデータをDBに準備しておくことが多いのではないでしょうか?
またDBの初期化(データの削除)などもこちらで実行するのが一般的な使い方の様です。
@AfterAll/@AfterEach
テストメソッドで出来上がったものの削除が主な用途の様です。
5-1-1. @DatabaseSetup と @ExpectedDatabase について
DBUnitというライブラリを利用すると、DBのデータ検索・追加・更新・削除のテストを実施できるようになります。このライブラリには、
- テスト前にテストデータを設定する@DatabaseSetup
- テスト後のデータを検証する@ExpectedDatabase
があります。DBへのCRUDに関しては、これを使用すると上記で紹介した @Before と @After への前処理・後処理の記述が必要なくなります。。また、テスト実施後の実際値が期待値になっているかも検証してくれるので assert の記述量を減らしてくれます。
このアノテーションを使うとCRUD関係のユニットテストの正確性と効率性が大きく上昇するので一つの選択肢として覚えておくべきでしょう。この方法では CSV/xml/xlsx などのファイルを事前に準備し、それを元に事前条件のデータをDBに投入します。投入前に対象DBの対象テーブルの初期化も行ってくれるので一意制約系のエラーも起こりません。また、検証作業も用意したファイルの値を期待値とし、テストメソッド実行後の実際値とを検証してくれます。
※ ただ、検証内容が外部ファイルなので確認に余計なコストがかるのでその点はトレードオフがあります。
5-2. AAAの構造に沿った記述を通じて、テストに視覚的な一貫性を与える
- Arrange(前提条件、事前準備)
- Act(テスト対象の実行)
- Assert(想定結果と実行結果の比較検証)
このような構成は、頭文字を取ってAAAあるいはトリプルAと呼ばれます。
Arrange(前提条件、事前準備)
テストが実行される際に、システムが適切な状態にあることを保証します。オブジェクトを生成してテスト対象とテストクラスでやりとりできる様にしたり、他のAPIを呼び出したりといった処理がここで行われます。システムがすでに適切な状態であるために準備が不要だということもあります。
Act(テスト対象の実行)
テストのコードを実行します。
テスト用のメソッドを呼び出すことによって、テストが開始されます。
Assert(想定結果と実行結果の比較検証)
テスト対象のコードが正しくふるまったかどうか確認します。 コードからの戻り値や、テストにかかわったオブジェクトの状態などがチェックされます。テスト対象のコードと他のオブジェクトとの間で、やりとりが発生したかどうかを調べるということもあります。
それぞれの部分の間には、必ず空行をはさむようにしましょう。 これによって、テストの構造を視覚的にも理解しやすくできます。
4つ目の構成要素として After が追加されることもあります。
After(事後処理)
何らかのリソースを割り当ててテストを実行した場合、その終了後にリソースを解放します。
上記の参考コードは、AAAの構造になっていません。必ずしも当てはめなくてはいけないわけではないのです。AAAの構造にしてみると以下の様になります。
class CalculatorTest {
// Arrange(前提条件、事前準備)
Calculator calculator;
@BeforeEach
void setUp() {
calculator = new Calculator();
}
// Act(テスト対象の実行)
Integer multiplyResult = calculator.multiply(4, 5);
Integer zeroMultiplyResultPatternFirst = calculator.multiply(5, 0);
Integer zeroMultiplyResultPatternSecound = calculator.multiply(0, 5);
// Assert(想定結果と実行結果の比較検証)
@Test
@DisplayName("掛け算の結果が、20になる")
void testMultiply() {
assertEquals(20, multiplyResult, "Regular multiplication should work");
}
// Assert(想定結果と実行結果の比較検証)
@RepeatedTest(5)
@DisplayName("0の掛け算の結果は、必ず0になる")
void testMultiplyWithZero() {
assertEquals(0, zeroMultiplyResultPatternFirst, "Multiple with zero should be zero");
assertEquals(0, zeroMultiplyResultPatternSecound, "Multiple with zero should be zero");
}
// After(事後処理)
/*
* インスタンスの破棄やファイルのcloseなど
* 必要があれば処理を書く
*/
}
5-2-1. 構想化のアノテーション
JUnit 5では、ネスト構造を利用したテスト・クラスの階層化が可能です。このオプションを使用すると、論理的にテストをグループ化して同じ親を持たせることができます。これによって、それぞれのテストに同じ初期化メソッドを適用することが簡単になります
インナークラスを作成して @Nested を付与
public class PointCalculatorTest {
@Nested
@DisplayName("掛け算の計算結果")
public class Multiply {
@Test
@DisplayName("掛け算の結果が、20になる")
void testMultiply() { ...... }
@Test
@DisplayName("0の掛け算の結果は、必ず0になる")
void testMultiplyWithZero() { ...... }
}
5-3. メソッドではなくふるまいをテストすることによって、テストの保守を容易にする
テストを作成する際には、個々のメソッドをテストするのではなく、対象のクラスのふるまいに着目すべきです。この意味を理解するために、ATMクラスについて考えてみましょう。このクラスには
- deposit()
- withdraw()
- getBalance()
というメソッ ドがあり、それぞれ入金と出金そして残高照会を行えます。 まず、次のようなテストを作成することにします。
- makeSingleDeposit (1回の入金を行う)
- makeMultipleDeposits (複数回の入金を行う)
これらのテストの結果を確認するには、 getBalance() を呼び出す必要があります。しかし、このメソッドのふるまいだけを検証するようなテストを作ろうとは思わないはずです。getBalance() は単にフィールドの値を返すだけで前提として入金・出金などが事前に行われている必要があります。ふるまいはすべて、 他の操作つまり入金と出金に伴って発生します。 withdraw()メソッドについても見てみましょう。
- makeSinglewithdrawal (1回の出金を行う)
- makeMultiplewithdrawals (複数回の出金を行う)
- attempt ToWithdraw Too Much (残高以上の出金を行う)
出金のテストを行うためには、まず入金が必要です(残高の初期値を指定してATM オブジェクトを初期化するということも可能ですが、ここでも実質的に入金が行われています)。入金なしにテストを行えるような、簡単あるいは意味のある方法はありません。何故なら、入金などの操作が行われた事実が先になければ意味がないからです。ユニットテストを作成する際には、まず全体的な観点を持つべきです。つまり、個々のメソッドをテストするのではなく、それぞれの組み合わせからなるクラスとしての本来求められている機能、ふるまいをテストすることが必要となります。
ここに関しては後述する 「10-1. 単体テストの定義と性質」 でも更に言及しています。
5-4. テストクラスとテスト対象コードの関係
JUnit テストクラスは、テスト対象クラスと同じプロジェクトに配置されます。
ただし、両者のコードはプロジェクト内の別の位置に分けて置くべきです。 テスト対象クラスは納品されても問題はありませんが、テストのコードはプロジェクト内にとどまるのが一般的です。ユニットテストを作成するのはプログラマーです。 顧客やエンドユーザーそして非プログラマーは、ユニットテストを実行することも目にすることもないでしょう。 ユニットテストには一方通行の関係があり、テストはその対象コードに依存していますが、この依存関係は単方向です。 テスト対象コードはテストクラスを知り得る必要はありません。
6. テストクラスと対象クラスの分離
ソフトウェアをデプロイする際に、テストのコードを含めるということはほとんどありません。読み込まれる JAR ファイルのサイズが増加して低速化を招くほか、コードへの攻撃対象領域が増大するという問題も発生します。テストを含めるかという判断とは別に、プロジェクト内のどこにテストのコードを置くべきかという点についても検討する必要があります。主な選択肢は以下の3つです。
- テスト対象のコードとパッケージ名を一致させ、同じディレクトリに配置
- テスト対象のコードとパッケージ名を一致させ、別のディレクトリに配置
- 実運用向けのコードと似ているが異なるパッケージ構造を定義し、別のディレクトリに配置
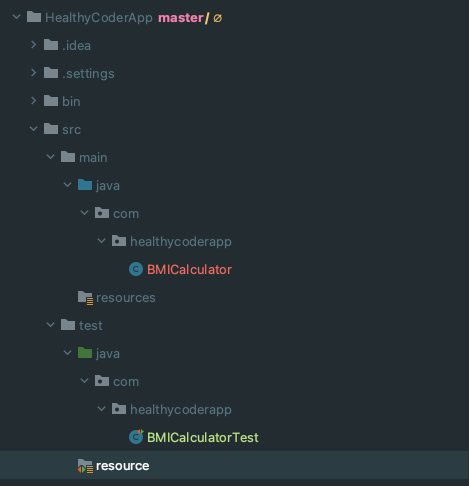
2 の 「テスト対象のコードとパッケージ名を一致させ、別のディレクトリに配置」は以下の画像の様な形です。
6-1. テスト対象のコードとパッケージ名を一致させ、同じディレクトリに配置
実装は簡単ですが、実際のシステムで使用されるべきではありません。テストのコー ドを除いて出荷したいという場合に、スクリプトなどを使った分別の処理が必要になるためです。例えばファイル名 (Test* class など) に基づいて抽出を行ったり、リフレクションのAPIを使ってテストのコードを検出するといった手順が必要です。1つのディレクトリに含まれるファイルが多すぎるというのも問題です。
6-2. テスト対象のコードとパッケージ名を一致させ、別のディレクトリに配置
テスト対象のコードとパッケージ名を一致させ、別のディレクトリに配置します。ほとんどのケースで、この方法がとられています。 Eclipse や Maven などのツールも、このモデルに基づいています。
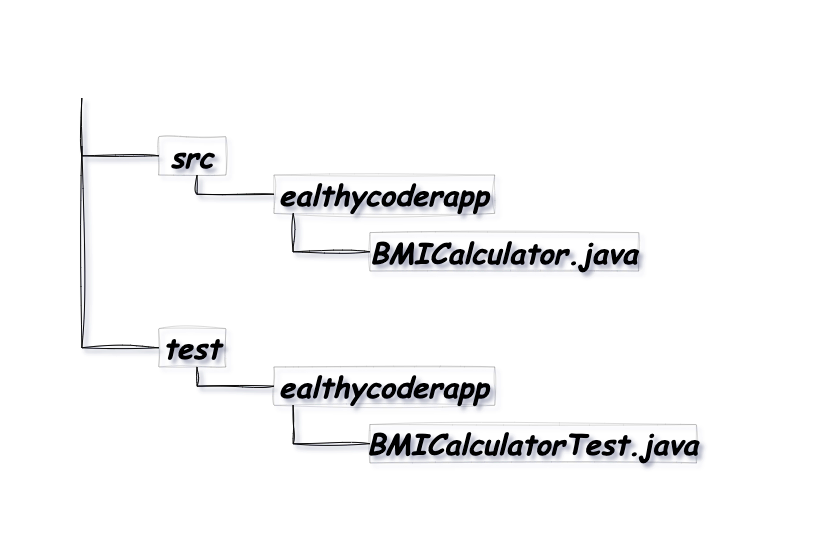
ここでは、 src・test の両ディレクトリに ealthycoderapp パッケージが用意されています。 テスト用のealthycoderapp.BMICalculatorTest クラスは、 test ディレクトリ配下の BMICalculatorTest.java に記述されます。 一方、テスト対象のealthycoderapp.BMICalculator クラスは src ディレクトリに含まれます。
test ディレクトリの構造は src ディレクトリと一致しているため、それぞれのテストは対象のクラスと同じバッケージに含まれることになります。 つまり、テストクラスはテスト対象クラス内のアクセス修飾子なしのメンバーにアクセスできます。
6-3. 実運用向けのコードと似ているが異なるパッケージ構造を定義し、別のディレクトリに配置
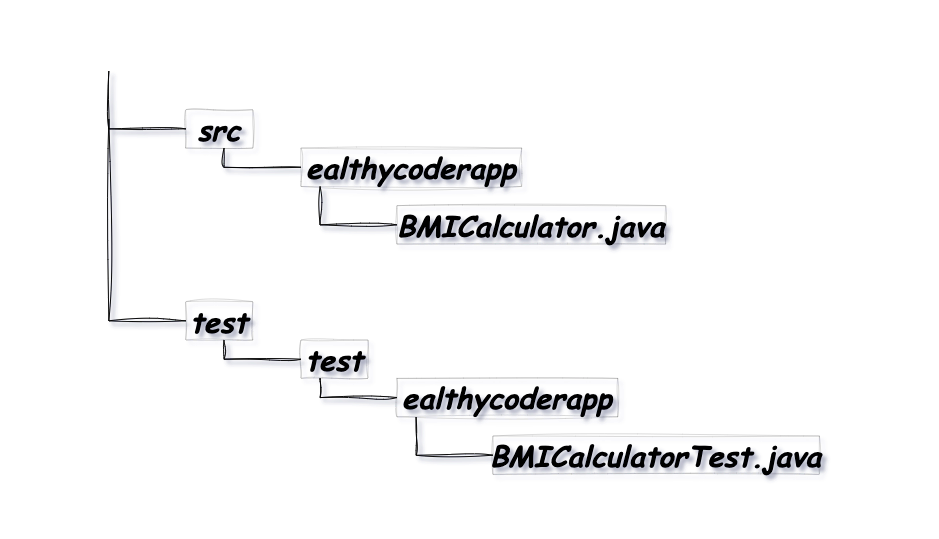
ここで test ディレクトリに置かれているコードは、実運用向けのコードとは異なる test.ealthycoderapp パッケージに含まれます。テスト用のパッケージ名に接頭辞 (ここではtest)を加えるということがよく行われますが、まったく別の組織名などを指定することもあります。テストを実運用向けのコードとは別のパッケージに置いた場合、テストは public な API だけを介したものになります。多くの開発者は、このやり方を健全な設計上の判断だと考えています。
6-4. プライベートフィールドの公開、 プライベートメソッドの公開
テストの際には実運用向けのコードが持つ public な API だけを使うべきだ、と主張する方々もいます。 そこでは、テストの中から public 以外のメソッドにアクセスすることはカプセル化の概念に反すると考えられています。つまり、 非public のコードを使ったテストは、テスト対象の実装詳細に依存されてしまうことになります。 この実装が変更されると(たとえ public なふるまいに変更がなかったとしても)テストが失敗してしまう可能性が生じます。
private な実装の詳細をテストすることによって、コードの質が下がってしまう可性が生まれます。これには理由があります。クラス内の private メソッドは直接呼び出せないため、単純にはテストができません。内部処理を強引にリフレクションでテストすることで、テストコードが内部実装に依存することになり、リファクタリングや機能追加の際に障壁となります。テストが実装の詳細を知り依存が多くなる(密結合)と、コードへの小さな変更が多数のテストの失敗を招くことになります。リファクタリングへの弊害につながります。リファクタリングの頻度が低下すれば、その分だけコードの質の低下も加速します。
private なフィールドについてアサーションを行いたい場合はゲッターメソッドを用意しなければなりません。なんらかの操作(メソッドの実行)を行った時に、プライベートフィールドの値が期待した通りに変化していることを検証したい場合に、プライベートフィールドを参照するためです。実運用向けのコードと同じパッケージにテストが置かれているなら、ゲッターはアクセス修飾子なしのメソッドとして定義できます。
public class Counter {
private int count;
public void countUp() {
count++;
}
public int getCount() {
return count;
}
}
public class CounterTest {
// オブジェクト生成時にcountが0であること
@Test
public void objectGenerationAtCountZeroIs() {
Counter counter = new Counter();
assertEquals(0, counter.getCount());
}
// countUpを実行するとcountが1であること
@Test
public void countUpInvokeAfterCount1Is() {
Counter counter = new Counter();
count.countUp();
assertEquals(1, counter.getCount());
}
}
private なフィールドを公開するというのは private なメソッドを公開するのとはまったく異なります。テスト用に外部からのアクセスを可能にしたとしても、テストと実運用向けのコードとの間に過剰な密結合が生じることはありません。テストと対象のコードのパッケージ名を一致させている場合、アクセス修飾子のない(パッケージプライベート)メソッドはテストのコードからアクセスできます。なるべくフィールドの可視性は狭く、メソッドも増やしたくない、というならば、フィールドの可視性をパッケージプライベートとすることがオススメです。パッケージプライベートは、privateの次に可視性の狭く、同一パッケージからのアクセスを許可しますが、他のパッケージからのアクセスは許可しません。パッケージプライベートを使えば、プロダクションコードもテストコードも可読性を保ちつつ、カプセル化も大きく崩しません。
一致していない場合には、リフレクションのAPIを使ってアクセス制御を回避することができますが、リフレクションには頼らないというのが最善の策です。
6-4-1. プライベートメソッドのテストについて
private メソッドは原則としてユニットテストすべきではありません。適切に設計された private メソッドであれば、呼び出し元のメソッド経由で網羅性はテスト可能です。仮に private メソッドをテストする必要が出たら、設計を見直す必要があります。private メソッドは、呼び出し元のメソッド経由でテストするのが原則です。
private メソッドをテストしたくなるような設計は、何らかの問題があると言えます。テストしたくなる private メソッドが多く存在している状態は、SRP (Single Responsibility Principle、 単一責任の原則) に反している可能性が高いです。クラスの中で、public なメソッドに依存してるハスの private なメソッドに対して独立したテストを行いたいのであれば、それは独立した責務がある可能性が高いと考えることができるからです。なので、private メソッドをテストしたくなる場合というのはリファクタリングの切っ掛けだという考えかたの方が良いでしょう。
privateメソッドのテストへの対応には例えば以下のようなものが挙げられます。すでにいくつかは紹介しているものも含まれています。
- public メソッド経由でテストする
- 別クラスに切り出して public メソッドとする
- テスト対象の可視性を一段上げる
- リフレクション(無い言語では不可)でアクセスしてテストを書く
一つずつ見ていきましょう。
-
①パブリックメソッド経由でテストする
多くの場合、そのクラスのパブリックメソッド経由でプライベートメソッドのテストも同時に行えます。Private メソッドはテスト対象内に隠されていて、それは Public メソッドによってのみ実行されるはずです。そのため、Private メソッドにバグがあったとしても Public メソッドのテストによって検知されるはずです。『技術的には出来ます(by t_wadaさん)』 -
②別クラスのパブリックメソッドとする
プライベートなメソッドのテストを書きたいということは、実はテスト対象の責務が多すぎること(SRP違反)を示唆している場合があります。テストがどうしても書きたい場合は、その責務はテスト対象のプライベートな振る舞いではなく、他の誰かのパブリックな振る舞いの可能性があります。テスト対象のプライベートメソッドを「クラスの抽出」や「メソッド/関数の移動」を使って、テスト対象のコラボレータのパブリックメソッドとして抽出し、普通にパブリックメソッドとしてテストすることができます。 -
③テスト対象の可視性を一段上げる
Java ではパッケージプライベートがあり、これは同一のパッケージからのみアクセスできる可視性のことです。テストを同一パッケージに配置することでテストからアクセスできるような設計を行うことがあります(4-4-2. テスト対象のコードとパッケージ名を一致させ、別のディレクトリに配置)。ただし、JavaScript はこの手段をとれません。-
@VisibleForTesting
可視性をユニットテストのために変更した(見える様にした)ことを、後続の開発者に伝えるためのアノテーションです。このアノテーションはテスト実施側にではなく、テスト対象メソッドに付与します。
-
@VisibleForTesting
-
④プライベートのまま、リフレクションでアクセスしてテストを書く
リフレクションは最後の手段であり、強力な手段でもあります。プロダクトコードに手を入れることができない状況や、レガシーコード(テストコードの無いコード)に対する「仕様化テスト(Characterization Test)」を書いているような状況では、リフレクションは唯一の、かつ強力な手段になります。プライベートメソッドにテストを書くことのデメリットを理解しつつ、行うしかありません。
内部処理を強引にリフレクションでテストすると、テストコードが内部実装に依存することになり、リファクタリングや機能追加の際に障壁となります。JavaScript やリフレクションが存在しない言語ではこの選択はできません。
ただし、これらの方法でなにがベストかを議論する上で暗黙の前提があります。
public class Counter {
private int count;
public void countUp() {
count++;
}
}
public class CounterTest {
@Test
public void objectGenerationAtCountZeroIs() throws Exception {
Counter counter = new Counter();
int actualCount = getCountByReflection(counter);
assertEquals(0, counter.getCount());
}
@Test
public void countUpInvokeAfterCount1Is() throws Exception {
Counter counter = new Counter();
counter.countUp();
int actualCount = getCountByReflection(counter);
assertEquals(1, counter.getCount());
}
int getCountByReflection(Counter obj) throws Exception {
// クラスのメタ情報にアクセスして、フィールドのメタ情報も取得する
Field field = Counter.class.getDeclaredField("count");
// メタ情報にアクセスしてアクセス可能性を不可から可能に書き換え、ゲットする
field.setAccessible(true);
return field.getInt(obj);
}
}
引用元:プライベートメソッドのテストは書かないもの? - t-wadaのブログ
まとめ
繰り返すと、プライベートなメソッドや関数をテストする必要は無いと考えています。プライベートなメソッドは、実装の詳細であるからです。ホワイトボックステストを書きたくなるのは、テストの問題ではなく、設計の問題だ。コードがきちんと動いているかどうかを変数を使って確かめたくなるときは、設計を改善する機会であると私は考えている。不安に負けて変数をチェックしてしまえば、改善の機会は失われる。
『テスト駆動開発』 第29章 xUnitのパターン p.226自動テストを書くモチベーションの一つとして「リファクタリングの支えになる」ことが挙げられますが、リファクタリングとは簡単に言うと「外部から見た振る舞いを変えずに内部の実装をきれいにすること」です。外部から見た振る舞いは、多くの場合自動テストで検証されます。
しかし、プライベートメソッドに対するテストは内部の実装に対するテストになってしまうことが多く、そして内部の実装に対するテストはリファクタリングの妨げになりがちです。自動テストの助けを借りて積極的にリファクタリングを行いたいのに、その自動テストがリファクタリングの妨げになる。これはとても皮肉な状況であり、避けられれば避けたいものです。このような状況は「構造的結合が強い」と表現されます。
プログラマーのテストは、振る舞いの変化に敏感であり、構造の変化に鈍感でなければいけない。つまり、プログラムの振る舞いが安定しているように見えるなら、テストを変えるべきではない。
プログラマーテストの原則 by Kent Beck - Waicrew - Mediumテスト「できる」ことと「すべきである」ことは異なります。リフレクションを使えばプライベートなメソッドのテストは「できる」のですが、そのテストはやがて実装改善の邪魔になりかねません。
「できる」ことと「すべきである」を区別し、目的に添わない場合「しない」という選択をできる様にしなくていはいけませんね。
また、設計の問題として、処理の一部を別クラスに抽出したり、package private に変更するなどの対応が考えられるようです。
そもそもテストする時は関係なく全部できる様にしたらあかんのか?と素人の僕は素朴に感じてしまいます。言語の標準サポートでできる様でけんのか?と。出来たのにやらずにいたのであればそれには理由があって、設計の見直しを示唆させるためなんかと思ったり。
表出した事象を叩き潰してはいけない。ここでは「privateメソッドをテストしたい」と感じたことが表出した事象。
「privateメソッドをテストしてはいけない」って言葉は「privateメソッド だから テストしてはいけない」という呪いに容易に変わってしまう。そうじゃないって言いたい。「privateメソッドをテストしたい」と思った感覚は、その瞬間その場その人にとって、絶対に正しい。「そのprivateメソッドをそのままテストしなきゃいけない」かどうかは別の話。
開発の初期段階はともかく最終的にはpublicな属性を相手にしたテストで賄ってしまって削除しちゃったほうがいいと思います。
結局のところprivateメソッドをprivateなままテストするのは(少なくとJavaにおいては)リファクタリングの妨げになるので、よほどの理由があるときにそのマイナスをプロダクトとして許容して行うものだと思う。
6-5. テストを分離するメリット
テストケースごとに1つずつテストのメソッドを用意し、検証対象のふるるまいを的確に表す名前をつけるほうが管理しやすくなります。
テストを分離することによって、以下のようなメリットを得られます。
- アサーションが失敗すると、そのテストの名前が報告されます。
これを通じて、どのふるまいに問題があったのかすぐに知ることができます。 - 失敗したテストの分析にかかる手間を最小限にできます。
JUnit ではテストごとに 個別のインスタンスが使われるため、あるテストが失敗したとしても別のテストに影響が及ぶことはありません。 - すべてのテストケースが実行されることを保証できます。
java.lang. AssertionErrorが throw されるため、実行中のテストメソッドは終了します (JUnit 本体がこれをcatchし、 テストを失敗であると報告します)。失敗したアサーションよりも後に記述されているコードは実行されません。そして、次のテストメソッドの実行に移り、再びテストが実行されます。
7. ドキュメントとしてのテストとして一貫性のある名付けを
1つのテストにさまざまなシナリオを含めると、その分だけテストの名前は一般的で無意味なものにせざるを得ません。そうなれば、そのテストで何が行われるのかまったくわかりません。個々のふるまいに着目した詳細なテストを作成するようになると、テスト名にもきちんとした名前を与えられます。
テスト対象の文脈を示すのではなく、文脈の中でふるまいを呼び出すと何が起こるのか示しましょう。つまり「振る舞い + 結果」を示すことです。
| 悪い名前 | テスト内容に即した良い名前 |
|---|---|
| makeSingleWithdrawal (1回出金する) |
withdrawalReducesBalanceByWithdrawnAmount (出金を行うとその分だけ残高が減る) |
| attemptToWithdrawTooMuch (多額の出金を試みる) |
withdrawalOfMoreThanAvailableFundsGeneratesError (残高以上の出金を行うとエラーが発生する) |
| multipleDeposits (複数回の入金) |
multipleDepositsIncreaseBalanceBySumOfDeposits (複数回入金を行うとその合計額の分だけ残高が増加する) |
正確な名前をつけることによって 他のプログラマーはテストの内容をよりよく理解できるようになります。長い文からなる名前は、理解が難しくなります。 多くのテストで名前が長すぎるという場合には、そもそも設計が誤っている可能性もあります。
理解しやすい名前は、次のような構造です。「振る舞い + 結果」
-
doingSomeOperationGeneratesSomeResult
- 何らかの処理を行うと何らかの結果が発生する
-
someResultOccursUnderSomeCondition
- 何らかの条件下では何らかの結果が発生する
-
givenSomeContextWhenDoingSomeBehaviorThenSomeResultOccurs
- 何らかの条件下で、何らかのふるまいを行うと何らかの結果が発生する
-
whenDoingSomeBehaviorThenSomeResultOccurs
- 何らかのふるまいを行うと何らかの結果が発生する
形式は複数ありますが、何を選択するかはあまり重要ではなく(個人的には短い方が好き)、選択に一貫性を持たせることのほうが大切です。他人にとって意味のあるテストにしましょう。
7-1. 意味のあるテスト
作成したテストを誰か(または自分自身)がわかりにくいと感じた場合に、単にコメントを追加するというのは望ましくありません。まずは、テストの名前を改善することから始めるべきです。
- テストクラス、テストケース、変数などに意味のある名前をつける
- 1行ずつテストするのではなく、 意味のある振る舞いになる最小の粒度でテストする
- テストケースを見てコードの目的・ふるまい・仕様がわかるようにする
説明のコメントを追加するのではなく、テストの名前やコード自体を通じてストーリーを伝えるようにします。
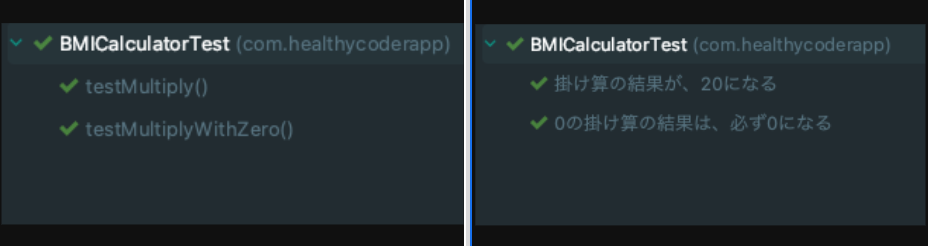
7-2. テストに名前をつける @DisplayName
とはいえ、メソッド名だけだと解り辛いですね。長いとそれだけで認知負荷が上昇します。このアノテーションを使用して、引数に名前を渡して別名をつけましょう。IDEのテスト実行欄に、その名前でテスト名一覧が表示されます。こちらでも、上記の様に「振る舞い + 結果」を書く様にします。説明には空白および特殊文字を含めることができます。また、絵文字も含めることができます。
名前をメソッド名では表現せず、このアノテーションで表現することで統一する方針も見たことがあります。
@Test
@DisplayName("掛け算の結果が、20になる")
void testMultiply() {
assertEquals(20, multiplyResult, "Regular multiplication should work");
}
@RepeatedTest(5)
@DisplayName("0の掛け算の結果は、必ず0になる")
void testMultiplyWithZero() {
assertEquals(0, zeroMultiplyResultPatternFirst, "Multiple with zero should be zero");
assertEquals(0, zeroMultiplyResultPatternSecound, "Multiple with zero should be zero");
}
8. モックなどのテストダブルとユニットテストについて
以下の記事にて解説しています。
- はじめに
- 1. モックなどのテストダブルとユニットテストについて
- 2. 「関節的な出力」と「関節的な入力」とは
- 3. 各テストダブルの違い・使い所
- 4. モックの使用例
- 5. テストダブルオブジェクト使用の注意点
- 6. テスト駆動開発における「ロンドン学派」と「デトロイト学派」
9. 良いユニットテストであるための原則『FIRST』
FIRST原則は次の単語の頭文字をとって名付けられており、良いテストは FIRST であると言われます。
- Fast(迅速):テストは素早く終わるべき。DBやファイルなどメモリ外の処理にアクセスするテスト実行には時間がかかるのでスタブやモックなどで置き換える
- Isolate(隔離):他のテストや同一メソッド内の処理に依存しない(2つの振る舞いをするアサーションがあるならば別にすべき)
- Repeatable(繰り返し可能):何回実行しても常に同じ結果になること(時刻などタイミングで変わるものはモック化するなど必要)
- Self-Validate(自律的検証):CIなどにより自動でテストがセットアップされて実行される
- Timely(適切なタイミング):今書いているコードに対してテストを書く。バグが無く変更の可能性が無いコードに対して後から追加するのは効果が少ない
以下に該当するテストは上記の FIRST を基準にすると良いでしょう。
- 読んだ人が理解できないテスト
- 成功することも失敗することもあるテスト
- 意味のある検証を行っていないテスト
- テスト対象のコードを十分に網羅していないテスト
- 実行に長い時間がかかるテスト
- テスト対象のコードが少し変更されただけでも、多数の失敗が発生してしまうような依存性の強いテスト
- セットアップに多くの時間を必要とする複雑なテスト
9-1. Fast(迅速)
二つの意味があります。
- コードよりも先にユニットテストを作成する(テスト駆動開発:TDD)
- 従来の手法(plain old unit testing またはPOUT)との違いはテストが先だという点
- テストの実行そのものが迅速に完了すること
- テスト対象メソッドのみを操作し、実行は数ミリ秒で完了
※TDDについては触れません、というか触れれません。まずは、POUT から順に学んでいくつもりです。
迅速にテストを実行できない場合とはどの様な場合でしょうか
DBへのCRUD・ファイル出力・ネットワークといった外部リソースに依存するメソッドのテストを実行する場合です。セットアップに時間がかかります。例えば、セットアップごとに対象テーブルの初期化として全削除を実行し必要データを挿入する、などです。
テスト対象メソッドの独立性が保たれていない場合、つまり副作用(戻り値を返す以外に外部に影響を及ぼす、もしくは戻り値が外部の状態変化に依存して変化してしまう)があるメソッドは確認のための手段そのものにも手間がかかりますし、実行そのものにも時間がかかります。テスト対象メソッドが外部の他の何かに依存している状態はいずれテストの実行が困難なることが装いされます。もし、この様なテストが3000個あり、一回のテストに500msec(0.5秒)かかる場合、全体のテストを一度実行するのに25分かかってしまいます。
対応策として
- 外部システムにアクセスする箇所を抑える
- そういったコードに依存する箇所を減らすのが最も重要。N+1問題に似ている。
- モックも検討材料。
- DBに保存されている値を使用するテストでは、引数に固定値を代入する
- DBの値は変更されうるし、テスト条件によっては昨日まではOKだったのに今はNGなどの結果になりうる。副作用を無駄に起こさない様にする。
- テストの並列実行
- マルチスレッド環境などで並列にテストを実行する。
- 共有テスト
- セットアップ後の状態や事前準備したオブジェクトを共有し、コストを下げる
- デメリットとして問題の切り分けなどし辛くなる。単一責任原則に抵触しやすい
- カテゴリ化テスト
速度と信頼性はトレードオフ
テストダブルで項で紹介しておりますが、テストダブルに置き換えた場合は分離性が高まり速度は上がりますが、テストダブルの動きはあくまで想像でしかないので信頼性に欠けます。
9-2. Isolate(テストを隔離する)
良いユニットテストは、コードの中の小さな一部分に着目して検証を行います。対象とするコードが(直接的にも間接的にも)増えれば増えるほど、テストの質は下がりやすくなります。
テスト対象のコードが、 データベースにアクセスしている状態は、そいデータに依存していること表します。 データベースに依存したテストを行うということは、副作用をもつ振る舞いであるということになります。DBの値によって結果が変動する可能性がるため様々なケースを想定し、テストコードを書く必要があります。
- 適切なデータが格納されているかどうかのチェック処理
- データベースが共有されている場合
- 外部で発生した自分とは関係のない変更によってテストが壊れる。
- 排他制御などの影響を受けた場合
- 単純にデータベースにアクセスするだけのコードはうまく機能しなくなる可能性。
よいユニットテストは、他のユニットテストや同一メソッド内の他のシナリオにも依存しません。テストの順序を工夫すれば、作成が面倒なデータを使い回せると思われるかもしれません。しかし、そうすると依存関係が連鎖し、硬直したコードになってしまいます。そういったコードはいずれ必ず問題を引き起こし、修正の必要に迫られます。安定したテストを幾度も実現するためには、コントロールできないような外部システムや環境からテストを完全に切り離す必要があります。
どんなテストも、時期や順序に依存せず実行でき、繰り返し成功しなければなりません。それぞれのテストがふるまいのうち小さな部分だけに注目するように心がければ(テストケースを可能な限り小さな単位で多く作成する)、独立性の高いテストの作成は容易なはずです。
SOLIDの中の SRP (Single Responsibility Principle, 単一責任の原則)では、クラスは目的を1つだけ持った小さなものであるべきとされ、1つのクラスに対して変更が必要になる理由は1つだけであるべきともされています。この原則は多くの設計に当てはまる原則ですが、テストメソッドの設計にも当然ながら当てはまります。問題の局所化ができる事で、テスト失敗時の原因特定へのノイズを減らすことができます。
もしテスト失敗の原因が複数存在するのであれば、SRP に違反していること示唆しています。
9-3. Repeatable(繰り返し)
繰り返し可能なテストとは、何度実行しても同じ結果が得られるということを意味します。これを実現するためには、制御できないような外部環境からテストを切り離す必要があります。
自動化されたユニットテストであれば、 何度でも繰り返してテストを実行することが容易となるはずです。であれば、不具合などを早い段階でフィードバックでき、安心してリファクタリングや機能拡張を行うことができるようになるわけです。繰り返し可能なテストとは実行するたびに同じ結果を得られるという事を意味します。実現するためには、自分がコントロールできないような外部の環境からテストを完全に切り離す必要があります。
しかし、管理下にない外部システムなどとの相互的なやりとりが不可欠だという場合があることも考えられます。上記で軽く紹介しましたが、現在時刻を元に処理を行うコードでは、時刻にも関わらず繰り返し可能なテストを作成するのは容易ではありません。また、システムが他のコンポーネントに依存しており、そのコンポーネントをテスト環境で利用できないこともあります。
その際は、上記で紹介したやり方や、テストダブルオブジェクトの仕組みを使うことでテスト対象のコードを、外部にある制御できない不確定要素から隔離することができます。。発生したりしなかったりする問題の修正には大きな手間がかかります。すべてのテストは、何回実行しても同じ結果を返す様にしましょう。ここでも副作用の存在がクリーンで有用な自動テストの障害になることが解りました。
9-4. Self-Validating(自律的検証)
クラスの振る舞いが期待通りなのかをアサーションとして検証しなければ、テストと呼べません。よくテストを書く暇がないから書かないというのを聞きますが、それが適用できるのは以下の様な場合のみです。
- 使い捨てのソフトウェア
- 年単位でしかリリースされないソフトウェア(回帰テストが年一回)
- 手動で自動テストと同じ品質が担保できるソフトウェア
3番目は論外ですね。出来るわけがありません。回帰テストが年一回でも何故この様な無駄なことしているのだろうか?という虚無な気持ちを覚えるこ間違いないです。人がすることには必ずミスがあります。その時起きなかったとしても、起き得ることを続けていればいつか必ず起きます。
自動テストで振る舞いの検証を行うことを、出来る限り徹底すべきです。ひいてはそれが企業の競争力に繋がるからです。ただし、自動テスト自身が独立しているためには、自動テスト自身のみで成り立つ設計にしなくてはなりません。セットアップ処理は自動化し、その実行を外部に依存してはいけません。単一責任原則を守りましょう。
この考え方を拡張していけば、以下の様なツールによってより規模・抽象度の高い場所で自動テストを適用できることに気づくことが出来ます。
- IDEA の Infinitest
システムに対して変更が行われると、Infinitest がその内容を検知し、影響が予想されるテストをすべてバックグラウンドで実行してくれます。 Infinitest を使うと、コンパイルと同様に、成功するまで次のステップには進めなくなります。
- 継続的インテグレーション(CI:continuous integration)
さらに大きな視点から見ると、Jenkins や Circle CI などのCI/CD(継続的インテグレーション/継続的デリバリー)ツールを利用することで、コードのリポジトリを監視し、変更を検出するとビルドやテストのプロセスの起動を自動化できます。CI とはコード変更をリポジトリに頻繁にマージし、かつ「定期的・自動的」に「ビルド・テスト」を行うという手法です。リポジトリに頻繁にマージすることで複数人での作業の衝突や競合を早期に発見し、自動化しておくことでリリースまでの時間を短縮できるといった効果があります。
また、CIはテストを自動化していること、という前提条件があります。継続的インテグレーションはプログラムをコミットすることで自動的にテストを行う仕組みになっているため、テストの自動化も必要になります。
9-5. Timely(適切なタイミングでテストする)
ユニットテストは、いつでも追加実施できますが、できる限り今現在実装しているコードと共に実施すべきです。テストを意識したコードの書き方になります。何度も紹介しましたが、副作用を引き起こす様なメソッドを、ユニットテストで検証するのは非常に面倒な場合もあります。また、副作用を引き起こすメソッドは変化を起こすため、本来は本質的な処理を担います。常に状態の変更を扱い保存しているのですから、実行のたびに変化が起きるというのはなくてはならない現象です。
ただし、そのようなメソッドを無秩序に作成してしまうと人間の認知限界を簡単に超えてしまいます。できる限り副作用のないメソッド(純粋関数といいます)を作成し、必要な場合にのみ副作用を起こすメソッドを記述する様に意識すべきです。ユニットテストは副作用のない純粋関数であれば非常に簡単にテストを行うことが出来ます。副作用がある場合は、分かりづらく繰り返し実行しづらいテストになってしまうかもしれません。また、一つのメソッドが複数の責務を担う様なコードも、ユニットテストを行う上で問題があることに気づくことになるはずです。これも単一責任原則に則っていないことが示唆されます。
10. 単体テストの定義と流派
書籍 「単体テストの考え方/使い方」 では単体テストと統合テストを以下のように定義しています。本章は上記の書籍での情報を中心に記述しております。
10-1. 単体テストの定義と性質
- 単体(Unit)と呼ばれる少量のコードを検証する
- (1単位の振る舞いを検証するこ)
- 実行時間が短い
- 隔離された状態で実行される
- (他のテストケースから隔離された状態で実行されること)
※ 対象はドメインモデル・ビジネスロジック・アルゴリズムである
の3つの性質を持つ。
3つの性質のうち1つでも損なっているものを統合テストに分類しています。
ただし、 上記定義でも全てが明確になるものではなく、 例えば 以下のように古典学派とロンドン学派によって「Unit」の定義・範囲が異なる。最も重要な焦点は「隔離された状態」の考え方です。
隔離に対する考え方の違いは、単体とは何か、そして、テスト対象システム (SystemUnder Test: SUT) が必要とする依存をどのように扱うのか、ということに関する見解に影響を与えています。
本来の単体テストの意義としては古典学派であると考えます。上記で紹介した 「5-3. メソッドではなくふるまいをテストすることによって、テストの保守を容易にする」 でも言及しています。ビジネス的に意味のあるテストで言えば、古典学派の考え方だからです。
ただしその場合、統合テストとの責務の分け方がやや曖昧になります。詳細は後述する「ロンドン学派にとっての統合テスト」を参照して下さい
|
隔離対象 |
Unitの意味 |
テストダブル(モック)の置換対象 |
置換対象例 |
|---|---|---|---|---|
ロンドン学派 |
単体 |
1つのクラス |
不変である依存対象(本来のValueObjectがこれ。Setterなし。そ他、enumもこれにあたる)以外の全ての依存 |
不変オブジェクト以外は全て対象 |
古典学派 |
テスト・ケース 1単位の振る舞い (a unit of behavior) を検証 |
1つのクラス、もしくは、同じ目的を達成するためのクラスの1グループ |
共有依存 |
|
10-2. ロンドン学派(モック主義者)
テスト対象となる単体を他の単体から隔離すべきである、という考えを持っています。そして、ロンドン学派の考える 「単体」とは、 1単位のコード(a unit of code)、 つまり、クラスのことと考えているのです。そのため、ロンドン学派の単体テストでは、不変依存を除くすべての依存がテスト・ダブル(モック)に置き換えられます。ただし、モックは所詮モック。作成者の思い描く挙動でしかなく、本物の挙動であることは保証されません。
10-3. 古典学派(デトロイト学派)
古典学派では、クラスを隔離するのではなく、単体テストのテスト・ケースをそれぞれ隔離しなくてはならない、という考えを持っています。そして、古典学派の考える 「単体」とは、 1単位のコードではなく、 1単位の振る舞い (a unit of behavior)のことを指します。古典学派の単体テストでは、他のテストケースの実行に影響を与えるであろう共有依存だけをテストダブルに置き換えるようになっています。単一のテストで共有依存先のデータを変更したことにより、次のテストの成否が左右される様なものは共有依存となります。
10-4. 両学派の比較
- ロンドン学派の長所はより細かな粒度で検証できることに加え、複雑に絡み合った依存関係を持つクラスのテストが簡単に行えるようになること、さらには、テストが失敗したときにその原因となるバグが潜んでいる箇所を見つけやすくなることがあります。
- ロンドン学派の長所は魅力的なように思えますが、課題もいくつか抱えています。 まず、単体テストにおいて、テスト対象の焦点をクラスに当てることは間違いであることです。焦点を当てなくてはならないのは1単位のコードではなく、 1単位の振る舞いです。さらに、もし、一部のコードを簡単にテストできないのであれば、それはコードの設計に問題があることを強く示唆しています。 しかも、この問題はテストダブルを使っても解決できるものではなく、仮に、テストダブルを使ってテストを行えるようにしたとしても、問題そのものはテストの際に隠れるようになっただけに過ぎません。
- また、ロンドン学派が単体テストの導入において利点として考えている、テストが失敗した際、どこにバグが潜んでいるのかを簡単に見つけられるようになる、ということは確かに有用な事実ではありますが、古典学派の単体テストと比べて、その有用性にあまり大きな違いはないようです。なぜなら、古典学派の単体テストであっても、プロダクション コードを変更するたびに単体テストを実施するようにしていれば、どこに間違いがあったのかをすぐに見つけられるからです(つまり、最後に修正をした部分がバグを持ちこんだ部分ということになります)。
- ロンドン学派の最大の課題は検証内容が詳細になり過ぎてしまうことです。つまり、単体テストがテスト対象の内部的なコードと密接に結び付いてしまうことです。
10-5. ロンドン学派にとっての統合テスト
古典学派にとっての単体テストは、共有依存やプライベート依存を用いたテストは全て統合テストとなります。
プライベート依存とは共有されない依存であり、可変依存と不変依存に別れます。不変依存とは、上記で言うところの ValueObject です。可変依存とはテスト対象とはならないが、テスト実施に必要なオブジェクトで協力者オブジェクトなどと呼ばれます。ロンドン学派は協力者オブジェクトもモックに置き換え、呼び出された際にどの様な振る舞いをするかを、以下の様に事前に定義してから検証を行います。
Mockito.doReturn(toBeReturn)when(mock).getSomeThing(any(), anyString(), anyInt());
古典学派では、when()の引数にある mock オブジェクトをコンストラクタで初期化しインスタンス化して使用するため、古典学派にとっての単体テストはロンドン学派からすると統合テストに分類されるわけです。
テスト対象をSUT(System Under Test)と呼ぶため変数名をSUTとすることもあります。
※ Java においての ValueObject は setter をつけられるせいで可変にできてしまうため、不完全な ValueObject が散見されたり、不変であることが ValueObject であると定義されますが、そもそも不変でしか扱えない言語発祥の概念のため定義となり得ません。前提でしかないのです。本来の定義は「一意の識別子ではなく、自身の持つ値の組み合わせのみによって識別性を有するオブジェクト」です。例えば、位置情報を表現するオブジェクトがあったとします。緯度と経度という二つのフィールドによってオブジェクトが識別されます。
詳しくはこちらを参照
10-6. 古典学派の定義の延長線上にある統合テストとE2Eテストの考え方
統合 (integration) テストとは、単体テストが持つべき1〜3の性質を1つでも欠いたテストのことであり、対象はドメインモデル・ビジネスロジックではなく、コントローラとなる。統合テストはドメインモデルとプロセス外依存を結びつけるコントローラを検証する。
下記の定義は古典学派の定義に則っって再定義された単体テストの定義である
- 1単位の振る舞い (a unit of behavior) を検証すること
- 実行時間が短いこと
- 他のテスト・ケースから隔離された状態で実行されること
E2E (End-to-End) テストは統合テストの一種であり、エンド・ユーザの視点からシステムを検証するため、テスト対象のアプリケーションが使用するすべての(もしくは、ほぼすべての)プロセス外依存をそのまま使ってテストすることになります(統合テストもプロセスが依存を1•2個は使用されることもある)。
プロセス外依存とは「更新機能を有する外部API」「DB」などがあたります。DBは共有依存でもあり、プロセス外依存でもあります。統合テストとE2Eテストの違いは「プロセス外依存」を多く含むか含まないかです。多く含めば含むほど、ユーザ視点の操作に近くなります。また、統合テストで扱われるプロセス外依存は開発者の制御下(DBなど)にあるものが、E2Eテストでは制御外のプロセス外依存を含めます(外部APIなど)。ただし、E2Eでも全てのプロセス外依存を扱えるわけではありません。ST環境でのある外部APIのレスポンスはその外部APIが用意したモックである、などは珍しくないかと思います。自前で用意する場合もあるかと思いますが、その場合は統合テストとの境界線が曖昧になります。
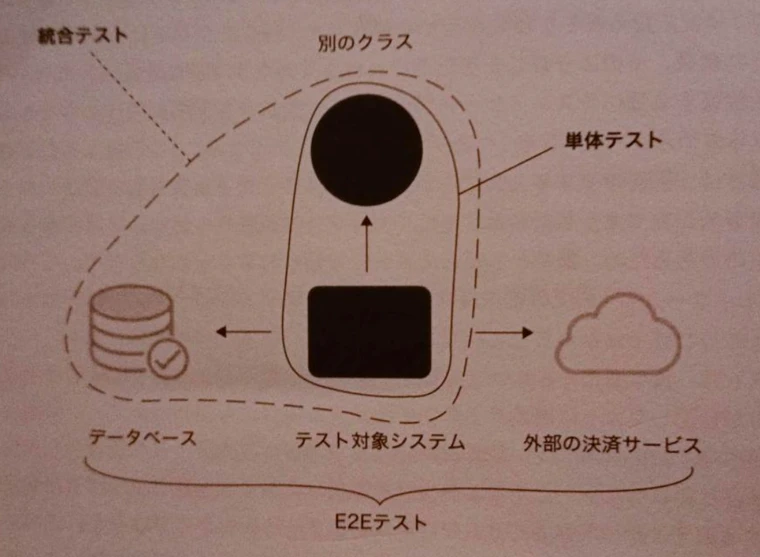
※ 「1単位の振る舞い (a unit of behavior) を検証すること」と振舞駆動開発(BDD)には関連性があります。
終わりに
長かったです。疲れました。奥が深すぎます。またどこかでE2Eテストについてもまとめれたらと思います。
おまけ~アサーションの種類~
こちらの過去記事にまとめてます。
参考資料
- Eclipse環境でGradleビルドするJavaアプリケーションの自動テスト(JUnit5)の書き方(テスト自動化のためのフレームワーク② JUnit)
- JUnit 5 User Guide
- 初めてのJUnit5単体テスト、最低限知っておきたいあれこれ
- Spring Bootでテストコードを書いてみる
- JUnit5 テストの記述
- JUnit5を使おう
- JUnit 5 ユーザーガイド
- org.mockito Class Mockito
- 事例で学ぶテストピラミッドを使ったテスト戦略
- 【超初心者向け】DBUnit超入門
- doma-spring-bootのSQL例外変換
- JUnit4でDBUnitの@DatabaseSetupや@ExpectedDatabaseというアノテーションを利用してみた
- コンストラクタインジェクションされたクラスのprivate メソッドでもテストファーストしたい
- 13. ペアプロやテストの疑問とか、ソフトウェアエンジニアの育成とか
- プライベートメソッドのテストは書かないもの?
- JUnit5 使い方メモ
- 入門: テスト技法とJUnit
- A 1230 多田真敏 入門:テスト技法とJUnit
- Interface Executable
- Mockito使い方メモ
- Kent Beck氏インタビュー
- リフレクションでprivateをテストしてみる
- xUnit Test PatternsのTest Doubleパターン(Mock、Stub、Fake、Dummy等の定義)
- テスト
- phpunit-documentation
- [図解]スタブとモックの違い
- Javaでユニットテストを書く時に気を付けたいこと
- JUnit 5 tutorial - Learn how to write unit tests
- Using the Gradle build system in the Eclipse IDE - Tutorial
- What is software testing with unit and integration tests
- JUnitでprivateメソッドのテストをする場合に注意すること
- プライベートフィールドに対するテスト
- 担当したPJの単体テストが地獄絵図だったので独自に作成したガイド(?)を公開する
- JUnitのMockitoで例外処理のテストをしてみた
- Spring Bootでmockitoを使ってテストする方法
- JUnit未経験者がテストコードを書ききるためにまずやったことと、初心者的悩みポイントを逆引き解説
- Annotation Type InjectMocks
- B6:テストを自動化するのをやめ、自動テストを作ろう - JTF2020
- -Qiita記事Part.5-「5種類のテストダブルを知ろう!」
- テスト駆動開発の過去・現在・未来(和田卓人さん)
- テスト駆動開発(TDD)はもう終わっているのか? Part1を読んでリポジトリ層に関するMockについて思いをはせる
- JavaScriptでスパイ、スタブ、モックなどのテストダブルを行う
- モックは必要悪で、しないにこしたことはない
- スタブ・モックは本当に悪者なのか?〜テスト駆動開発をやめて、なお残すべき習慣とは (2)
- テストダブル
- Mocks Aren't Stubs
- xUnit Patterns.com
- 和田拓人さんのツイッター発言複数