1. はじめに
先日、Azure OpenAI Embedding モデルを利用し最も関連性の高いドキュメントを見つける方法 について説明しました。これを利用する事で、最も関連性の高いドキュメントを見つける事ができます。
この記事では、この機能を利用し PDF ファイルを Azure Blob Storage にアップロードすると、自動的に PDF ファイルをテキストに変換し、Azure OpenAI Embedding モデルを利用して、ベクトル検索を行う方法について説明します。
このサービスを利用すると、社内ドキュメントも、各種論文も PDF ファイルであれば何でも、Azure の Storage にアップロードするだけで、自動的にそのドキュメントを検索できるようにして、実際に検索をすると該当箇所を ChatGPT が該当部分をまとめて表示してくれるようになります。
1.1 サービスの概要
本記事で紹介するサービスは、具体的に下記の手順で処理を行います。
アプリケーションの「ソースコードはこちら」からご入手ください。
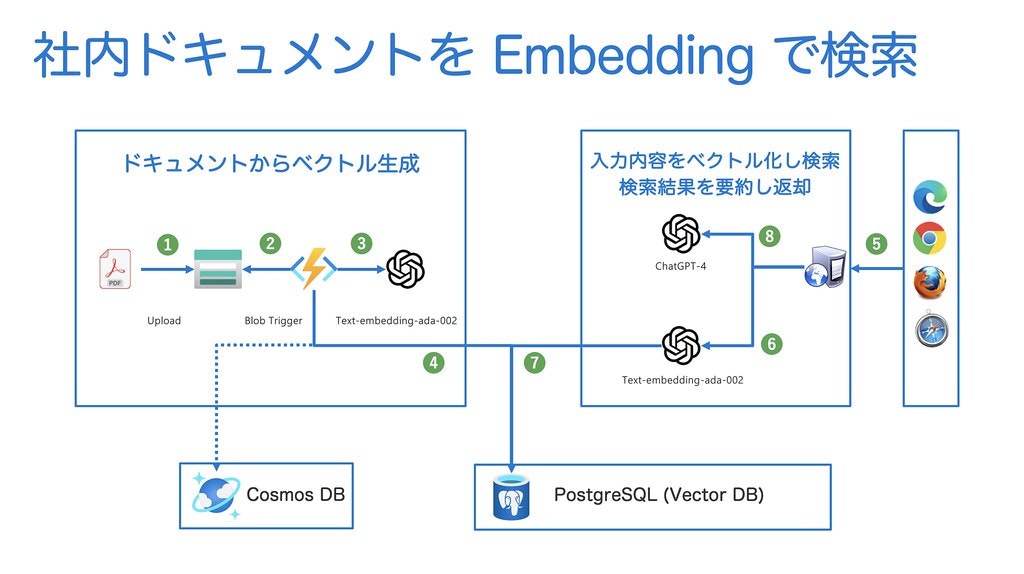
- Azure Blob Storage に PDF ファイルをアップロードする
- Azure Functions の Blob Trigger がアップロードされたファイルを検知し、PDF をページ毎にテキストに変換する
- 変換したテキストを、Azure OpenAI Embedding を呼び出してベクトル化する
- ベクトル化したデータを Azure PostgreSQL Felxible Server に保存する
- 利用者が検索したい文字列を入力する
- 入力した文字列を Azure OpenAI Embedding を呼び出してベクトル化する
- ベクトル化したデータを元に Azure PostgreSQL Felxible Server から類似度の高いデータを取得する
- 類似度の高い結果のドキュメント Azure OpenAI ChatGPT で解析し、該当箇所を Streaming 形式で返す
1.2. 利用するテクノロジー
この記事で紹介するサービスは下記の Azure のサービスを利用しています。
- Azure Blob Storage
- Azure Cosmos DB
- Azure OpenAI
- Azure Functions
- Azure PostgreSQL Flexible Server
- Apache Apache PDFBox
2. 環境構築
Azure OpenAI のインスタンスは、現時点で Azure CLI コマンドが用意されていないため、Azure Portal から作成する必要があります。
下記を実施する前に、Azure OpenAI のインスタンスを Azure Portal の GUI から作成してください。(2023/6/13 時点)
それ以外の Azure のリソースにつきましては、下記のコマンドを利用してかんたんに作成する事ができます。
> create-env.sh
注意:
複数回に一度、Azure PostgreSQL Flexible Server でベクトル検索 (pgvector) の機能を ON にしても、有効にならず Vector によるクエリーの実行に失敗する場合があります。その場合は、再度あらためて上記のスクリプトを実行して別の PostgreSQL Flexible Server インスタンスを作成してください。
上記のコマンドを実行する前に、環境に合わせてスクリプト内の変数を修正してください。
####################### Azure のリソースを作成するための環境変数の設定 #######################
# 作成するリソースグループとロケーション設定
export RESOURCE_GROUP_NAME=Document-Search-Vector1
export DEPLOY_LOCATION=japaneast
# Azure PostgreSQL Flexible Server に関する設定(私の環境では構築制限があるため eastus に設定)
export POSTGRES_INSTALL_LOCATION=eastus
export POSTGRES_SERVER_NAME=documentsearch1
export POSTGRES_USER_NAME=azureuser
export POSTGRES_USER_PASS='!'$(head -c 12 /dev/urandom | base64 | tr -dc '[:alpha:]'| fold -w 8 | head -n 1)$RANDOM
export POSTGRES_DB_NAME=VECTOR_DB
export POSTGRES_TABLE_NAME=DOCUMENT_SEARCH_VECTOR
export PUBLIC_IP=$(curl ifconfig.io -4)
# Azure Blob ストレージに関する設定
export BLOB_STORAGE_ACCOUNT_NAME=documentsearch1
# 注意: 下記の値を変更する場合は、Functions.java の BlobTrigger の実装部分も変更する必要があります。
export BLOB_CONTAINER_NAME_FOR_PDF=pdfs
# Azure Cosmos DB に関する設定
export COSMOS_DB_ACCOUNT_NAME=odocumentsearchstatus1
export COSMOS_DB_DB_NAME=documentregistrystatus
export COSMOS_DB_CONTAINER_NAME_FOR_STATUS=status
# Azure のサブスクリプション ID の取得(デフォルトのサブスクリプションを使用する場合は下記の変更は不要)
export SUBSCRIPTION_ID="$(az account list --query "[?isDefault].id" -o tsv)"
####################### Azure のリソースを作成するための環境変数の設定 #######################
2.1 環境変数の設定
上記のスクリプトを実行すると、スクリプトが成功すると下記のようなメッセージが表示されます。
下記の出力された内容に従って、Azure Functions (BlobUploadDetector) の local.settings.json ファイルと、Spring Boot の application.properties ファイルを、それぞれ更新してください。
####################### Azure のリソースを作成するための環境変数の設定 #######################
########## 下記の内容を local.settings.json file に書いてください ##########
-----------------------------------------------------------------------------
# Azure 関連の環境設定設定
"AzureWebJobsStorage": "****************************",
"AzurePostgresqlJdbcurl": "jdbc:postgresql://documentsearch1.postgres.database.azure.com:5432/VECTOR_DB?sslmode=require",
"AzurePostgresqlUser": "azureuser",
"AzurePostgresqlPassword": "********",
"AzurePostgresqlDbTableName": "DOCUMENT_SEARCH_VECTOR",
"AzureBlobstorageName": "documentsearch1",
"AzureBlobstorageContainerName": "pdfs",
"AzureCosmosDbEndpoint": "https://documentsearchstatus1.documents.azure.com:443/",
"AzureCosmosDbKey": "********************",
"AzureCosmosDbDatabaseName": "documentregistrystatus",
"AzureCosmosDbContainerName": "status",
"AzureOpenaiUrl": "https://YOUR_OPENAI.openai.azure.com",
"AzureOpenaiModelName": "gpt-4",
"AzureOpenaiApiKey": "YOUR_OPENAI_ACCESS_KEY",
-----------------------------------------------------------------------------
### 下記の内容を別実装の Spring Boot の application.properties に書いてください ###
-----------------------------------------------------------------------------
# Azure PostgreSQL 関連の接続情報の設定
azure.postgresql.jdbcurl=jdbc:postgresql://documentsearch1.postgres.database.azure.com:5432/VECTOR_DB?sslmode=require
azure.postgresql.user=azureuser
azure.postgresql.password=**********
azure.postgresql.db.table.name=DOCUMENT_SEARCH_VECTOR
# 下記の Blob 関連の設定
azure.blobstorage.name=documentsearch1
azure.blobstorage.container.name=pdfs
# Azure Cosmos DB 関連の設定
azure.cosmos.db.endpoint=https://documentsearchstatus1.documents.azure.com:443
azure.cosmos.db.key=********************************************
azure.cosmos.db.database.name=documentregistrystatus
azure.cosmos.db.container.name=status
# Azure OpenAI 関連の設定
azure.openai.url=https://YOUR_OPENAI.openai.azure.com
azure.openai.model.name=gpt-4
azure.openai.api.key=********************************************
-----------------------------------------------------------------------------
# PostgreSQL を作成したのち、下記のコマンドで接続してください
-----------------------------------------------------------------------------
> psql -U azureuser -d VECTOR_DB \
-h documentsearch1.postgres.database.azure.com
自動生成した PostgreSQL のパスワード: **********
# PostgreSQL に接続したのち、下記のコマンドを実行してください
-------------------------------------------------------------
VECTOR_DB=> CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
VECTOR_DB=> CREATE EXTENSION IF NOT EXISTS "vector";
# 最後に、下記のコマンドを実行して TABLE を作成してください
VECTOR_DB=> CREATE TABLE IF NOT EXISTS DOCUMENT_SEARCH_VECTOR
(id uuid, embedding VECTOR(1536),
origntext varchar(8192), fileName varchar(2048),
pageNumber integer, PRIMARY KEY (id));
-----------------------------------------------------------------------------
注意:
上記の OpenAI 関連の設定は、Azure Portal で作成した時の接続 URL, モデル名、API キーをそれぞれ設定してください。
2.1.1 PostgreSQL の拡張機能の設定
PostgreSQL のインスタンスを生成した後、ローカルの環境からアクセスができるようになっているか、下記のコマンドを実行して確認してください。
psql -U azureuser -d VECTOR_DB \
-h documentsearch1.postgres.database.azure.com
※ パスワードはターミナルに出力されています
PostgreSQL に接続したのち、下記のコマンドを実行し拡張機能を追加してください。
下記では、UUID と pgvector の拡張機能を有効にしています。
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE EXTENSION IF NOT EXISTS "vector";
最後に、下記のコマンドを実行して Vector を利用できるテーブルを作成してください。
CREATE TABLE IF NOT EXISTS DOCUMENT_SEARCH_VECTOR
(id uuid, embedding VECTOR(1536),
origntext varchar(8192), fileName varchar(2048),
pageNumber integer, PRIMARY KEY (id));
3. アプリケーションの実行
環境構築が完了しのち、下記の手順でアプリケーションを実行してください。
3.1 Azure Functions (BlobUploadDetector) の実行
環境変数を変更しているため、一度、Azure Functions をビルドして、その後で実行してください。
> cd BlobUploadDetector
> mvn clean package
> mvn azure-functions:run
3.2 Spring Boot の実行
環境変数を変更しているため、一度、Spring Boot をビルドして、その後で実行してください。
> cd SpringBoot
> mvn clean package
> mvn spring-boot:run
3.3 Blob Sroage へのファイルのアップロード
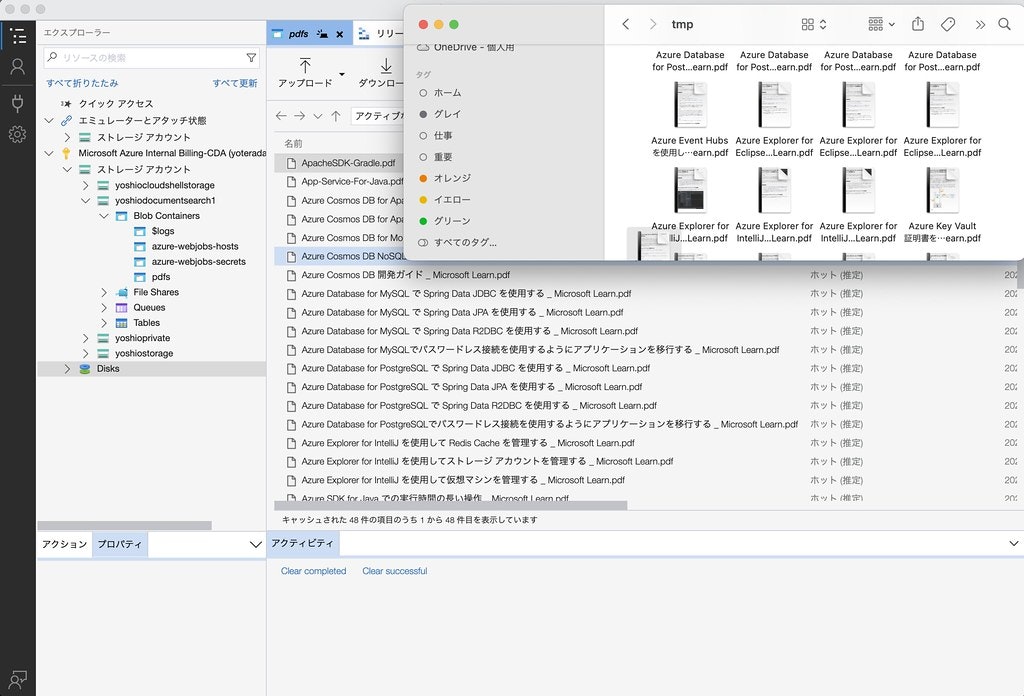
Azure Portal に接続して、個別にファイルをアップロードする事もできますが、簡単にファイルをアップロードできるように、Azure Storage Explorer を利用します。
Azure Storage Explorer のダウンロードから、Azure Storage Explorer をダウンロードしてインストールしてください。
Azure Storage Explorer を起動すると、Azure アカウントで接続が求められますので、接続してください。接続をすると、下記のような画面が表示され、ドラッグ&ドロップで複数のファイルをまとめてアップロードできるようになります。
3.4 Spring Boot のアプリケーションの動作確認
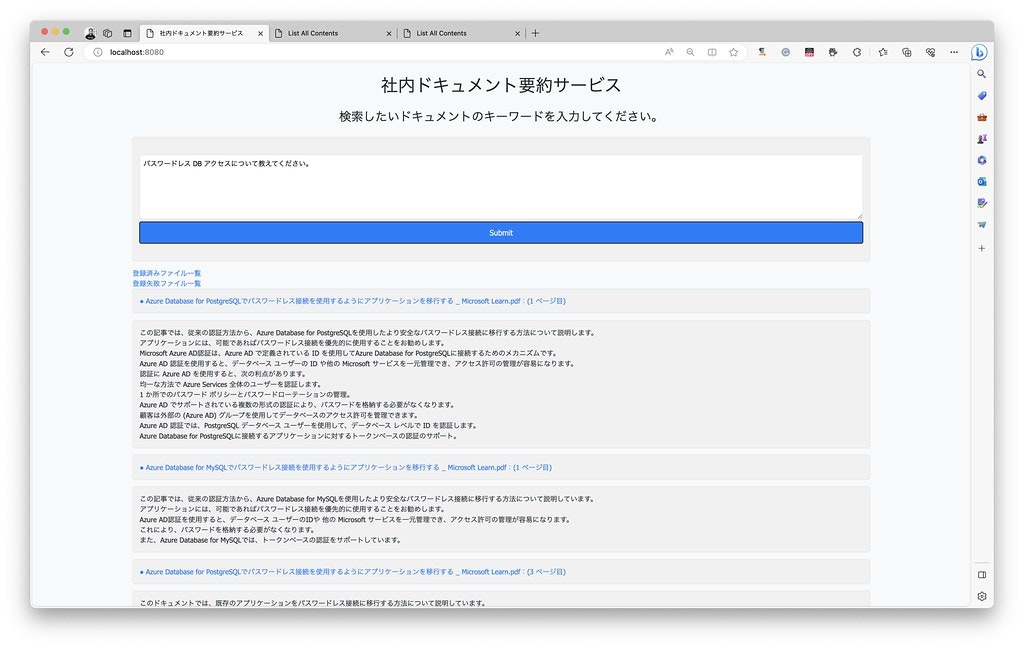
http://localhost:8080/ にアクセスすると、下記のような画面が表示されます。
テキスト・エリアの箇所に、検索したいキーワードを入力して、Submit ボタンをクリックしてください。
すると、検索結果がストリーミング形式で表示されるようになります。
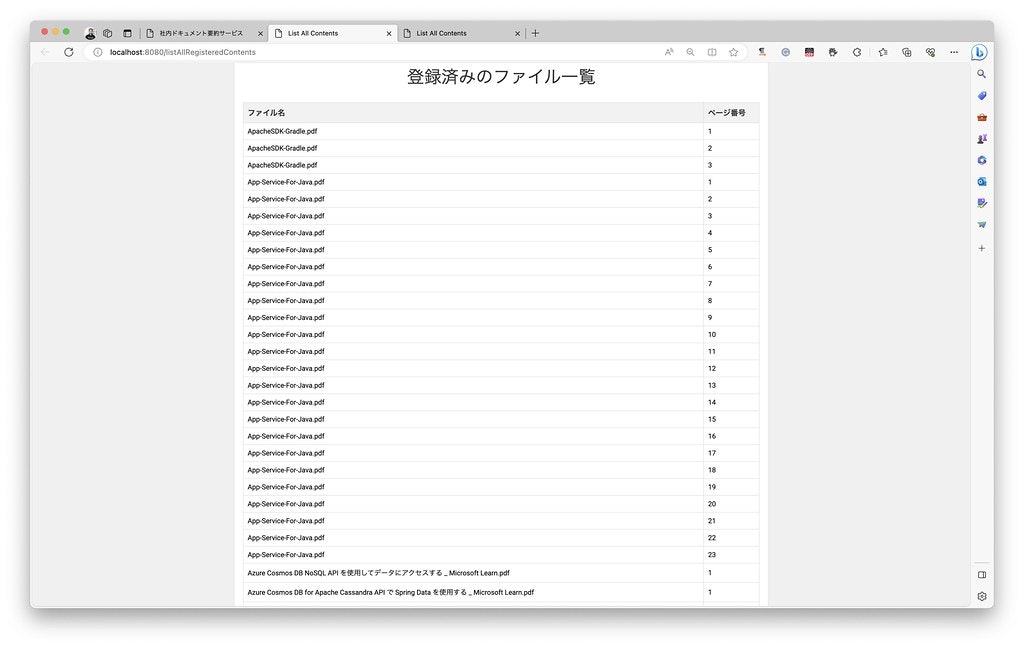
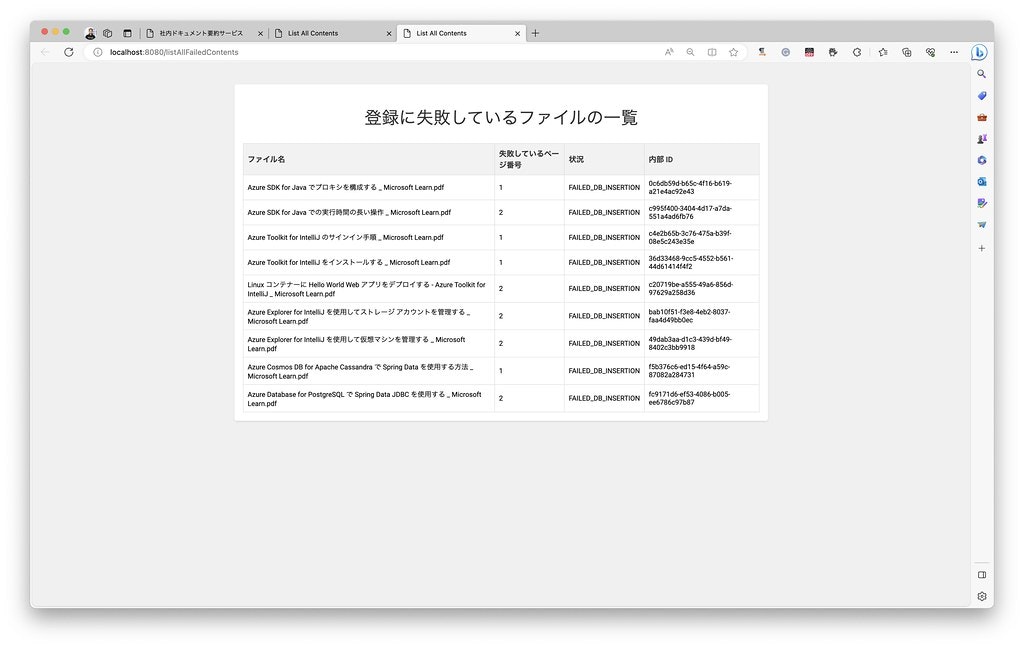
また、登録済みファイル一覧 のリンクをクリックすると、DB に登録されているファイルの一覧が表示されます。
登録失敗ファイル一覧 のリンクをクリックすると、DB の登録に失敗したファイルの一覧が表示されます。
4. アプリケーションの実装の注意点
4.1 Azure Functions (BlobUploadDetector) の実装の注意点
まず、Azure Functions で実装した BlobUploadDetector について、実装上の注意点を下記に説明します。
4.1.1 Azure Functions の実行時間の延長
Azure Functions は、デフォルトでは 5〜30 分間の実行時間の制限があります。この制限を超えると、Azure Functions はタイムアウトしてしまいます。しかし、大量のページを持つ PDF ファイルを解析・処理する場合、この制限時間では処理が終わらない可能性があります。そのため、Azure Functions の実行時間の延長を行なっています。
本サンプルでは、host.json に下記のような設定を追加することで、Azure Functions の実行時間を無期限に延長しています。ただし、無期限に設定できるのは Premium プラン と 専用プラン だけです。従量課金プラン では、無制限に設定することはできないのでご注意ください。
{
"version": "2.0",
"functionTimeout": "-1",
}
4.1.2 Azure OpenAI Embedding API の利用間隔の調整
Azure OpenAI text-embedding-ada-002 の1分間辺りの呼び出し回数の上限数は、インスタンス毎に異なります。制限を超えると、Azure OpenAI Embedding API は 400 のエラーを返します。そのため、Azure OpenAI Embedding API の呼び出し間隔を環境に合わせて調整してください。
// Azure OpenAI の呼び出し間隔(ミリ秒)
private final static int OPENAI_INVOCATION_INTERVAL = 20;
参考:
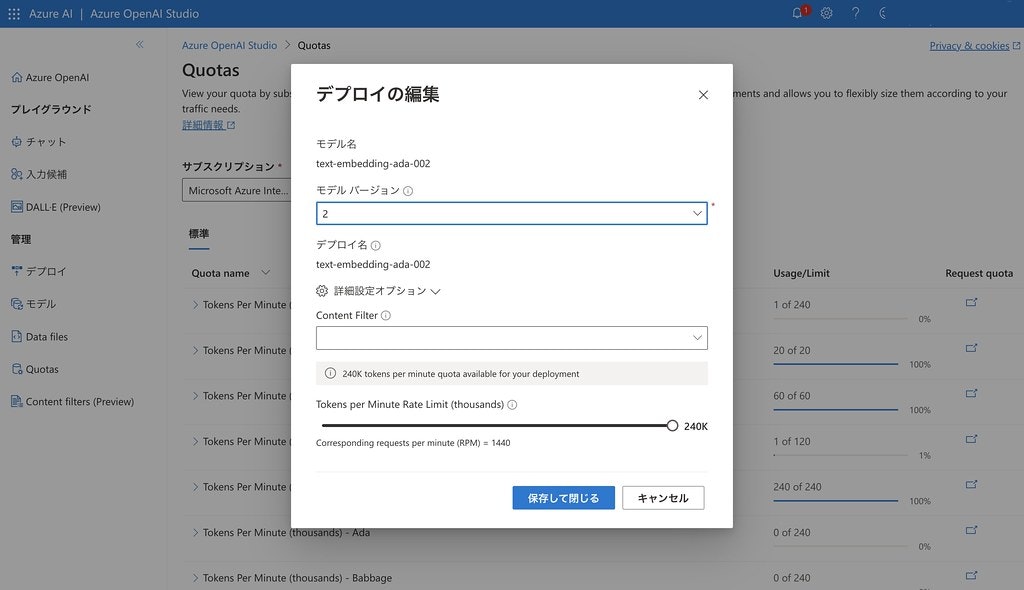
上記の設定は、text-embedding-ada-002のモデルの1分間辺りの呼び出し回数を、私の環境で設定可能な上限の 240k Tokn/min (約 1440 req/min) の値に設定して実行した場合の設定です。1 分間辺りの呼び出し回数が異なる場合は、この設定値を調整してください。場合によってはミリ秒単位ではなく、5〜10秒の単位で設定変更が必要になります。
1分間辺りの呼び出し回数は、Azure OpenAI Studio の Quotas からご確認・変更して頂くことができます。
4.1.3 Azure Functions における環境変数の設定
Azure Functions では、ローカルの環境では環境変数は local.settings.json ファイルに設定します。そして Azure Functions にデプロイする場合は、Azure Functions の Configuration に設定します。
ご注意:
Java で一般的に利用されるsrc/main/resources/以下のプロパティ・ファイルには環境変数の設定はできないためご注意ください。
local.settings.json に設定した環境変数の値は、プログラム上で System.getenv() メソッドを呼び出して取得できます。
4.1.4 Azure Blob Storage で作成するコンテナ名を変更する場合の注意点
環境変数で "AzureBlobstorageContainerName": "pdfs", の値を変更する場合は、Function.java のソースコードの下記の部分も修正してください。path で指定できる値は、constants での定義が必要なため、環境変数から取得し path に設定することはできません。
@FunctionName("ProcessUploadedFile")
@StorageAccount("AzureWebJobsStorage")
public void run(
@BlobTrigger(
name = "content", path = "pdfs/{name}", dataType = "binary") byte[] content,
@BindingName("name") String fileName,
@BlobInput(name = "inputBlob", path = "pdfs/{name}",
dataType = "binary") byte[] inputBlob,
final ExecutionContext context) throws UnsupportedEncodingException {
4.1.5 PDF 解析処理における注意点(特に ChatGPT-4 以外を利用する場合)
PDF ファイルからテキストに変換する際に下記の手順で処理を行なっています。
- PDF ファイルの 1 ページ数毎に分割
- 分割したページ毎にテキストに変換
- 変換したテキストに「改行」、「複数の空白」が含まれる場合は、それらを「1つの空白文字に」削除
- 変換後のテキストのサイズを計測
- テキストのサイズが (7200-7500) 文字の範囲で、”。”、”?”、”!”などの文字を見つけた場合は、そこで分割
- MAX_SEPARATE_TOKEN_LENGTH (7500) までに上記の区切り文字が見つからない場合は強制的に分割
- 分割したテキストを Azure OpenAI Embedding API に投げて、ベクトルを取得
- ベクトルを PostgreSQL データベースのテーブルに登録
- 上記の各処理状況は Cosmos DB に登録し適宜更新
注意:
text-embedding-ada-002, gpt-4 は 1 リクエストあたりのトークン数の上限が 8192 までとなっています。経験上、MAX に近い値を指定すると、リクエスト条件によってエラーが発生する場合があります。そのため、1 ページの文字数の上限を 7500 文字にしています。ただし、文の途中で強制的に区切るのを極力避けるため、7200 文字から 7500 文字の範囲に区切り文字があれば、そこで分割できるように実装しています。仮に gpt-35 turbo を利用する場合は、MAX が 4000 トークンになるため、現在設定しているMAX_SEPARATE_TOKEN_LENGTH の値ではデカ過ぎます。この値を変更してください。
4.1.6 挿入するデータについて
経験上、PostgreSQL の DB に挿入するデータは、ある程度の文字数があるページを挿入した方が、より効果が高いと考えています。
例えば、1ページに 「Azure Functions の情報はこちらをご参照ください。」というたった一行しか記載されていないページを DB に挿入した場合、text-embedding-ada-002 で取得したベクトルの値は、他のデータとの差異が小さく、結果として類似度が高くなってしまいます。
そのため、ある程度文字数の多いページを挿入することで、ベクトルの値の差異を大きくすることができます。
つまり、簡単に申し上げるならば、Azure Functions という文字を検索した場合、後続にどのような文章が書かれていたとしても、上記のページに引っ掛かりやすくなります。そこで、ある程度の文字数が含まれるページを DB にご登録ください。
4.2 Spring Boot の実装の注意点
次に、Spring Boot アプリケーションの実装における注意点を記載します。
4.2.1 Server Sent Event として実装
OpenAI に対してリクエストを送信する際、Java の SDK では同期処理用と、非同期処理用のインスタンスを用意しています。今回は、非同期処理用の OpenAIAsyncClient クラスを利用して実装します。
これを利用すると、リアルタイムに Stream 処理として結果を返すことができます。
Server 側からリアルタイムに Stream 処理として結果が返ってきますので、もちろん、その結果をクライアントに対しても同様に Server Sent Event でリアルタイムに返すことができます。
今回 Spring Boot のアプリケーションを Server Sent Event として実装するために、Spring Boot の WebFlux を利用して実装します。
また、WebFlux で SSE を実装する際に、1 対 1 で通信ができるように下記のような実装を加えています。
クライアントのブラウザ (JavaScript) 側で UUID を生成し、その UUID で /openai-gpt4-sse-streamに接続します。
下記は、JavaScript のコードの抜粋です。
let userId;
let eventSource;
window.onload = function () {
userId = generateUUID();
setupEventSource();
};
function setupEventSource() {
eventSource = new EventSource("/openai-gpt4-sse-stream?userId=" + userId);
注意:
JavaScript での UUID の生成方法は今回の実装ではとても簡単に実装しています。
本番環境で利用する場合は、より安全な UUID の生成方法をご検討ください。
サーバ側に接続をすると、サーバでは Map で クライアントの UUID と Sinks.Many<String> を1対1で紐付けて登録します。
下記は、Java のコードの抜粋です。
private static Map<UUID, Sinks.Many<String>> userSinks;
@GetMapping(path = "/openai-gpt4-sse-stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
@ResponseBody
public Flux<String> sseStream(@RequestParam UUID userId) {
Sinks.Many<String> userSink = getUserSink(userId);
if (userSink == null) {
userSink = createUserSink(userId);
}
LOGGER.trace("USER ID IS ADDED: {}}", userId);
return userSink.asFlux().delayElements(Duration.ofMillis(10));
}
private Sinks.Many<String> createUserSink(UUID userId) {
Sinks.Many<String> userSink = Sinks.many().multicast().directBestEffort();
userSinks.put(userId, userSink);
LOGGER.debug("User ID: {} User Sink: {} is Added.", userId, userSink);
return userSink;
}
// Get User Sinks
private Sinks.Many<String> getUserSink(UUID userId) {
return userSinks.get(userId);
}
そして、この UUID に紐付いている Sinks.Many<String> に対して、tryEmitNext を呼び出す事で、クライアントのブラウザに対して文字列を返すことができます。
userSink.tryEmitNext(jsonMessage);
上記の処理は、window.onload で Web サイトにアクセスした際に自動的に行っています。
4.2.2 文字列が入力されて Submit ボタンが押された時の処理
ブラウザで検索文字を入力し Submit ボタンを押した時の処理は、下記のようになっています。
Submit 時にも /openai-gpt4-sse-submit に対して UUID を渡し POST でアクセスします。
下記は JavaScript のコードの抜粋です。
function submitText() {
let elements = document.querySelectorAll('#target *');
elements.forEach(function (element) {
element.remove();
});
const textFieldValue = document.getElementById("inputText").value;
fetch("/openai-gpt4-sse-submit?userId=" + userId, {
method: "POST",
body: textFieldValue,
headers: {
"Content-Type": "text/plain"
}
});
}
サーバ側では、@RequestBody で受け取った、ユーザから入力された文字列を text-embedding-ada-002 でベクトル化し、その後 PostgreSQL でベクトルで検索を行います。
PostgreSQL の検索結果を、OpenAI の ChatGPT を呼び出して要約処理を行っています。
最後に、その結果をクライアントのブラウザに対して Server Sent Event で返しています。
@PostMapping("/openai-gpt4-sse-submit")
@ResponseBody
public void openaiGpt4Sse(@RequestBody String inputText, @RequestParam UUID userId) {
var userSink = getUserSink(userId);
LOGGER.debug("InputText --------------: {}", inputText);
// ユーザからの入力を受け取り、PostgreSQL の Vector DB からドキュメントを検索
findMostSimilarString(inputText).subscribe(findMostSimilarString -> {
// ドキュメントの検索結果を元に、OpenAI による要約を実施し結果をクライアントに送信
findMostSimilarString.forEach(docSummary -> {
requestOpenAIToGetSummaryAndSendMessageToClient(docSummary, inputText, userSink);
});
});
}
4.2.3 非同期処理の実装における注意点
Spring WebFlux の非同期処理として実装する際、内部処理は全て非同期処理として実装しなければなりません。途中の処理で block() すると、実行時にエラーが発生します。
例えば、PostgreSQL に対してクエリーを送信して結果を返す際も、結果を List<DocumentSummarizer> として返すのではなく Mono<List<DocumentSummarizer>> として返します。
また、OpenAI を呼び出す際にも、下記のように実装を行っており、処理を一切ブロックせずに実行しています。
// OpenAI にリクエストを送信し、結果をクライアントに送信する
client.getChatCompletionsStream(OPENAI_MODEL_NAME, new ChatCompletionsOptions(chatMessages))
.doOnSubscribe(subscription -> {
// HTML の中で、リンクと結果の文字列を表示するための DIV エリアを作成する為のリクエスト・イベントを送信
sendCreateAreaEvent(userSink, docSummary);
// HTML の中で、リンクを表示する為のリクエスト・イベントを送信
sendCreateLinkEvent(userSink, docSummary);
})
.subscribe(chatCompletions -> {
// OpenAI からの結果をクライアントに Streaming で送信
sendChatCompletionMessages(userSink, docSummary, chatCompletions, inputText);
}, error -> {
LOGGER.error("Error Occurred: {}", error.getMessage());
userSink.tryEmitError(error);
}, () -> {
LOGGER.debug("Completed");
});
非同期のノンブロッキングで処理を行う場合、結果が複数返ってくる場合に、複数の回答結果が混ざる可能性があります。そこで、どの検索結果に対するサマリーの結果なのかを正しく識別するために、ドキュメントに紐付く UUID(docSummaryに含まれる) もクライアントに対して送信しています。
例えば、各ドキュメント毎に表示エリアを分ける為に、documentID に紐付く表示エリアを作成する為のリクエストを JSON で送信しています。
// HTML の中で、リンクと結果の文字列を表示するための DIV エリアを作成する為のリクエスト・イベントを送信する
private void sendCreateAreaEvent(Sinks.Many<String> userSink, DocumentSummarizer docSummary) {
var documentID = docSummary.id().toString();
var createArea = new CreateAreaInHTML("create", documentID);
var gson = new Gson();
var jsonCreateArea = gson.toJson(createArea);
LOGGER.debug("jsonCreateArea: {}", jsonCreateArea);
userSink.tryEmitNext(jsonCreateArea);
// wait few mill seconds
intervalToSendClient();
}
上記の JSON を受信した JavaScript 側の実装は下記のようになります。
下記では、JSON の "type" が "create" という文字列を受信した場合に、documentID に対応するエリアを作成するようにしています。
const json = JSON.parse(data);
if (json.type === "create") {
var documentId = json.id;
// ターゲットの下に child 要素を追加
addArea(documentId);
return;
} else if (json.type === "createLink") {
var documentId = json.id;
var link = json.link;
var fileName = json.fileName;
var pageNumber = json.pageNumber;
// child の下のリンク記載部分にリンクを追加
createLink(documentId, link, fileName, pageNumber);
return;
} else if (json.type === "addMessage") {
var documentId = json.id;
var content = json.content;
// child の下のテキスト記載部分にテキストを追加
addMessage(documentId, content);
return;
}
上記のように実装する事で、複数の検索結果を取得した場合でも、それぞれの検索結果に対して、分けて表示することができるようになります。
4.2.4 Cosmos DB の実装における注意点
この下記の内容は、create-env.sh スクリプト内で対応している内容ですので特に重要ではありませんが、情報お共有の為に記載しておきます。
Cosmos DB でクエリを実行しソートを行うために、下記のような SQL を実行しています。
"SELECT * FROM c WHERE c.status = 'COMPLETED' ORDER BY c.fileName ASC, c.pageNumber ASC
Cosmos DB では、ORDER BY でソートする場合、対象のプロパティにインデックスを作成する必要があります。作成しない場合クエリーの結果が正しく表示されません。
今回は create-env.sh の中 Cosmos DB のコンテナを作成する際に、cosmos-index-policy.json ファイルを読み込み、fileName と pageNumber のプロパティに対しインデックスを作成しています。
下記のコマンドを実行しています。
az cosmosdb sql container create --account-name $COSMOS_DB_ACCOUNT_NAME -g $RESOURCE_GROUP_NAME --database-name $COSMOS_DB_DB_NAME --name $COSMOS_DB_CONTAINER_NAME_FOR_STATUS --partition-key-path "/id" --throughput 400 --idx @cosmos-index-policy.json
4.2.5 Spring Data JPA の実装における注意点
当初、PostgreSQL に対するクエリーの実装で、Spring Data JPA で実装しようと考えていましたが、Spring Data JPA で PostgreSQL の pgvector 型を扱うことができませんでした。そこで今回の実装では、Spring Data JPA での実装は断念しました。
色々と試しましたが、Native Query を用いて実装しても、エラーを出力したため、今回は標準の JDBC で実装しています。
補足
現時点では、まだ実装していない機能がいくつかあります。
例えば、現時点で削除関連 (登録に失敗したファイルの UUID にマッチする Blob ファイルの削除, CosmosDB のエントリの削除)の機能は実装していません。
最後に
繰り返しますが、このサービスを利用すると、社内ドキュメントも、各種論文も PDF ファイルであれば何でも、Azure の Storage にアップロードするだけで、自動的にそのドキュメントを検索できるようにして、実際に検索をすると該当箇所を ChatGPT が該当部分をまとめて表示してくれるようになります。
また、PDF だけでなく、ライブラリを利用すれば Word も Excel も、それ以外の文章を扱うことができるようになるかと思います。
もし、コチラの内容にご興味のある方がいらっしゃいましたら、どうぞお試しください。