Raspberry Pi 4B (4GB)に 64bit OSを載せ、Tensorflow 2.4.1とkeras2.4.3を使って、カメラで撮った7セグ画像から、数字認識をする実験(その1)を試してみた。まだ、問題は多いが、インストールで色々手間取ったところもあったので手順を載せておく事にする。

- 1. Raspberry Pi OS 64bitのインストール
- 2. Tensorflow 2.4.1のインストール
- 3. keras 2.4.3のインストール
- 4. jupyterのインストール
- 5. opencvのインストール
- 6. sambaのインストール
- 7. matplotlib のインストール
- 8. imutilのインストール
- 9. 「7セグ」画像から輪郭抽出
- 10. 切り取った画像から、数字を推定(判定)する
- 11. 主なパッケージのバージョン整理
- 12. その2につづく・・・
- 13. おまけ
1. Raspberry Pi OS 64bitのインストール
Raspberry Pi4で64bit版のRaspberry Pi OSを使うを参考にさせて頂き、64bit OSの SDカードを作成する。
1.1. OSイメージをダウンロード
ここからイメージをダウンロードする。
この中から、最新を選ぶ。

ここから、2021-03-04-raspios-buster-arm64.zip (1.0Gbyte)のファイルをダウンロードする。
1.2. Raspberry Pi ImagerでSDに書き込む
Raspberry Pi Imagerを起動し、書き込むイメージには、"Use Custom"を選んでから、ダウンロードしたZIPファイルを選択する。Zipのままで書き込める。SDカードを差し込んでから、書き込み対象として選択した後、書き込みを実施する。書き込み~ベリファイまで数分を要する。
Raspberry Pi Imagerの使い方は、ネット上から多く得られるのでここでは割愛する。
書き込み終わったSDカードをPCから取外し、ラズパイ(電源が入っていない事)に挿入し、キーボード、マウス、有線LAN、HDMIモニターを接続してからラズパイに電源を供給する。(カメラも接続して問題ないが、後述するように現時点 (2021/4/18)では、カメラ用の定番アプリのraspistillやraspividが 64bit OSでは動作しない。別のqv4l2というアプリが動作する事は確認したが、不具合もある)
無線LAN接続でも良いが、この記事ではWiFiは接続せず有線LANのみを使う形にしている(安定性を期待するため)
1.3. 初期設定
GUIで行える設定は、極力GUIでの設定を使う事にする。ここでは、ユーザー設定、ネットワーク設定、ロケール設定、キーボード設定、解像度設定などを行う。ネット上に設定記事は多く見つかるので、詳しくはここでは書かない。
なお、個人的に、shellの画面で日本語のメッセージが出てくるのは、見づらいし好まないので、基本的に使用言語は英語のままにしておく。
- Country設定➡ Japan, Japanese, Tokyo, Use English language
- password for pi user設定➡ 適当にパスワードを設定
- 画面の黒枠確認:➡ 特に問題無いのでそのまま
- WiFi ➡ Skip
- Update software ➡ 実行。updateとupgradeが実行されるため、結構時間がかかる。
- reboot 実行
- raspberry pi configuraionを起動
- hostname 設定 ➡ 好きな名前に。(ここでは rpi4b002)
- camera, ssh, vnc設定 ➡ enableして reboot実行
- 画面右上のBluetoothアイコンから Bluetooth off
- 画面右上のネットワークアイコンから WiFi Off
- おなじく、Network設定からeth0設定を開き、
- automatic:無、
- disable IPv6 チェック
- IPv4 : 192.168.55.211等 (←環境に合わせた固定IP)
- DNS Search:空白のまま
- Applyして closeし、reboot実行
- reboot後に、ip a でIPアドレスの確認。
- VNCのアイコンがある事を確認 (PCからVNC Viewerで接続して、画面のキャプチャーや、コピペを自在に行いたいためVNCを有効にしている。それが不要なら VNCを disableのままでも問題なし) VNCの設定を色々いじると、時として VNCサーバーが動作しなくなり、アイコンが無くなってしまう事があるから注意。
ここまでで、基本的な設定は終わり。GUIのデスクトップに用意されている各種のアプリやコマンドを色々触ってみて、特に問題が無い事を確認すれば良い。少し前述したが、64bit OSでは、まだカメラ関係のコマンドは用意できておらず、入っていない。raspistillや、raspividを起動しても、"command not found"となる。
以降の各種インストールは、GUI上のシェル(ターミナル)から行っても良いが、PCから SSHのターミナル接続をして、設定する方が個人的には便利。ちなみに私は、Teratermの SSH接続を多用している。
1.3.1. 追加の設定
画像処理、jupyter notebook処理などを行うために、更に多くのパッケージのインストールが必要であるが、経験的には、インストールが複雑なアプリを先に、なるべく綺麗な環境状態の時にインストールする方が、トラブルが少ない気がするので、tensorflowとか、kerasのような多くの依存性のあるアプリを先にインストールし、正常に終わってから、それ以外の様々なアプリ(シンプルな)のパッケージをインストールすることにする。
2. Tensorflow 2.4.1のインストール
tensorflowの新しいバージョン(2.3以降)は、下記サイトの情報によると、32bit OSでのリリースがなされないとの事。(2.2.0が 32bit OSでの最終更新)
Install TensorFlow 2.4 on Raspberry 64 OSのサイト情報を参考に、64bit用の tensorflow 2.4.1をインストールする。
2.1. OSとpythonのバージョン確認
念のために、uname -a コマンドと gcc -vコマンドでOSのバージョンを確認しておく。
どちらも、aarch64になっている必要がある。
ダウンロードするファイルとpython3のバージョンが一致している必要がある。 pythonのバージョンは、python3 --version で確認できる。私の環境では、3.7.3 なので、ダウンロードする tensorflowのアーカイブは、"cp37"の wheelファイルが必要。
pi@rpi4b002:~ $ uname -a
Linux rpi4b002 5.10.17-v8+ #1403 SMP PREEMPT Mon Feb 22 11:37:54 GMT 2021 aarch64 GNU/Linux
pi@rpi4b002:~ $ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/aarch64-linux-gnu/8/lto-wrapper
Target: aarch64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Debian 8.3.0-6' --with-bugurl=file:///usr/share/doc/gcc-8/README.Bugs --enable-languages=c,ada,c++,go,d,fortran,objc,obj-c++ --prefix=/usr --with-gcc-major-version-only --program-suffix=-8 --program-prefix=aarch64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-bootstrap --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-libquadmath --disable-libquadmath-support --enable-plugin --enable-default-pie --with-system-zlib --disable-libphobos --enable-multiarch --enable-fix-cortex-a53-843419 --disable-werror --enable-checking=release --build=aarch64-linux-gnu --host=aarch64-linux-gnu --target=aarch64-linux-gnu
Thread model: posix
gcc version 8.3.0 (Debian 8.3.0-6)
pi@rpi4b002:~ $
2.2. インストールの手順
前述のサイト情報をそのまま利用させて頂く。基本的にpythonから使う予定であることと、scratchからコンパイルしてビルドするのは、私には敷居が高すぎるので、このサイトが参照しているwheelファイルをそのまま利用させて頂く事にする。
以下のコマンド群を順に実行する。各コマンドの目的は英語での下記説明を参考にされたし。まずは、updateと upgradeで最新のOS状態にしてから、pipをインストールし、tensorflowがもし過去にインストールされていれば削除し、コンパイルに必要な環境を入れ、google driveに格納されたwheelを gdownというアプリでダウンロードした上で、インストールするという手順になっている。
sudo apt-getで行うインストールと、sudo pip3で行うインストールを併用している。 sudo apt-getの代わりに sudo aptでインストールすることも出来るようだ。今後の推奨は、apt-getでは無くて、aptであるという記事を読んだこともあるが、どのような違いがあるのか不勉強で良く分らない。
# get a fresh start (remember, the 64-bit OS is still under development)
$ sudo apt-get update
$ sudo apt-get upgrade
# install pip and pip3
$ sudo apt-get install python-pip python3-pip
# remove old versions, if not placed in a virtual environment (let pip search for them)
$ sudo pip uninstall tensorflow
$ sudo pip3 uninstall tensorflow
# install the dependencies (if not already onboard)
$ sudo apt-get install gfortran
$ sudo apt-get install libhdf5-dev libc-ares-dev libeigen3-dev
$ sudo apt-get install libatlas-base-dev libopenblas-dev libblas-dev
$ sudo apt-get install liblapack-dev
# upgrade setuptools 47.1.1 -> 50.3.2
$ sudo -H pip3 install --upgrade setuptools
$ sudo -H pip3 install pybind11
$ sudo -H pip3 install Cython==0.29.21
# install h5py with Cython version 0.29.21 (± 6 min @1950 MHz)
$ sudo -H pip3 install h5py==2.10.0
# install gdown to download from Google drive
$ pip3 install gdown
# copy binairy
$ sudo cp ~/.local/bin/gdown /usr/local/bin/gdown
# download the wheel
$ gdown https://drive.google.com/uc?id=1WDG8Rbi0ph0sQ6TtD3ZGJdIN_WAnugLO
# install TensorFlow 2.4.1 (± 68 min @1950 MHz)
$ sudo -H pip3 install tensorflow-2.4.1-cp37-cp37m-linux_aarch64.whl
英語のメモにあるように、数十分を要する処理もあるので、気長に実行する。全部をスクリプト化して実行する事も考えたが、エラー処理をちゃんとしないといけないので、今回は全部手作業で行った。
時間は掛かるが、正常に終了すればオーケー。
python3からtensorflowがimport出来るか、バージョンが正しいかを確認しておく。下記のように、importでエラーが生じず、バージョン番号が表示されればオーケー。
pi@rpi4b002:~ $ python3
Python 3.7.3 (default, Jan 22 2021, 20:04:44)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow
>>> tensorflow.__version__
'2.4.1'
>>>
念のために、h5pyのバージョンを確認しておく。2.10.0ならオーケー。
$ pip3 show h5py
Name: h5py
Version: 2.10.0
Summary: Read and write HDF5 files from Python
Home-page: http://www.h5py.org
Author: Andrew Collette
Author-email: andrew.collette@gmail.com
License: BSD
Location: /usr/local/lib/python3.7/dist-packages
Requires: numpy, six
Required-by: tensorflow, Keras
このあと、sudo rebootする。(必須とは思わないが念のため)
3. keras 2.4.3のインストール
次にkerasをインストールする。
3.1. pipを最新にする
正常にインストールするために、pip3のバージョンが最新である事が重要だと思われる。pipが古いと、コンパイルが途中でエラーになったり異常に時間が掛かったりするので、以下のコマンドで最新にする。既に、最新になっていればオーケー。2021/4/18時点では、21.0.1が最新。
$ sudo python3 -m pip install --upgrade pip
・
・
・
$ pip3 show pip
Name: pip
Version: 21.0.1
Summary: The PyPA recommended tool for installing Python packages.
Home-page: https://pip.pypa.io/
Author: The pip developers
Author-email: distutils-sig@python.org
License: MIT
Location: /usr/local/lib/python3.7/dist-packages
Requires:
Required-by:
$
3.2. keras 2.4.3 をインストールする。
下記コマンドでインストールする。
相当時間が掛かるが、下記のように正常終了すれば良い。
$ sudo pip3 install keras==2.4.3
・
・
Successfully installed cached-property-1.5.2 h5py-3.2.1 keras-2.4.3 pyyaml-5.4.1 scipy-1.6.2
$
3.3. 確認する。
このインストールをした際、途中で h5pyのバージョンが変わってしまった事があった。h5pyのバージョンは、学習のモデルファイルの互換性に大きく影響するので、指定したバージョンである必要がある。
もし、今回使いたいバージョン (2.10.0)以外であれば、一度、h5pyをアンインストールして、再度 h5py==2.10.0でインストールする必要がある。
python3から、kerasをインポート出来、バージョンが正しいかを確認する。
$ python3
Python 3.7.3 (default, Jan 22 2021, 20:04:44)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import keras
>>> keras.__version__
'2.4.3'
>>>
4. jupyterのインストール
4.1. dillo ブラウザーの削除
ラズパイの32bit OSの時には、jupyter notebookを実行すると、自動的にブラウザが立ち上がり、notebookの編集、実行ができたが、今回インストールした Raspberry Pi OS 64bitのパッケージでは、'Dillo'という軽量ブラウザーが含まれており、jupyter notebookを起動すると、Chromiumブラウザではなく、Dilloブラウザが立ち上がってしまうため、うまく操作できなかった。
Dilloブラウザの価値は、現時点自分にはわからないので、jupyterをインストールする前に、Dilloを削除しておく。そうすれば、jupyter notebookで、Chromiumが defaultブラウザとして起動してくれるだろう・・・と思ったためである。
$ sudo apt purge dillo
注:が、実際には、Dilloを削除してから、jupyterをインストールすると、jupyter notebook起動時に、なんと、テキストエディタで、htmlファイルが開かれるだけになった(default browserが、chromiumになっているのにも関わらず)。仕方が無いので、jupyter notebookを起動するときに、browserオプションで Chromiumを指定する事で対応した。 このあたりのjupyter notebookの起動メカニズムが良く分らない・・・・。以前、32bit OSで使っていた時は、何の問題も無く、Chromiumが立ち上がっていたのに・・・・
$ jupyter notebook --browser=chromium
4.2. jupyterのインストール
下記コマンドでインストールする。
$ sudo apt install jupyter
各種の依存関係にあるパッケージもインストールされる。
Setting up jupyter (4.4.0-2) ...
Setting up jupyter-notebook (5.7.8-1) ...
Setting up python3-widgetsnbextension (6.0.0-4) ...
Setting up python3-ipywidgets (6.0.0-4) ...
4.3. jupyter notebook 確認
前述のように、64bit OSでは、dilloを削除したとしても、jupyter notebookコマンドで自動的にChromiumブラウザが開いてくれないため、以下のように、--browser=chromiumというオプションを付けて起動する必要がある。
$ jupyter notebook --browser=chromium
もちろん、jupyter notebookを起動した後、表示されるURLをクリックすれば、Chromiumブラウザが立ち上がり正常に動作する。
jupyter notebookを起動したときに、テキストエディタが開いてしまうので、これは単純に閉じる。
そのうち、何らかの対処方法を探したい・・・
5. opencvのインストール
5.1. pipが最新である事を確認
opencvのインストールに於いても、pipのバージョンが最新であることが大変重要であり、少しでも古いpipだと、何故かものすごく時間が掛かったり、インストールに失敗したりする。
$ sudo python3 -m pip install --upgrade pip
現時点での最新は、21.0.1
5.2. opencv のインストール
下記コマンドで python用の opencvをインストールする。
$ sudo pip3 install opencv-python
・
・
Successfully installed numpy-1.20.2 opencv-python-4.5.1.48
$
numpy等、必要な他のライブラリもインストールされる。
5.3. 確認
pythonから opencv (cv2)を import出来るか確認する。下記のように、4.5.1が正常にインストールされていることを確認できる。
$ python3
Python 3.7.3 (default, Jan 22 2021, 20:04:44)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> cv2.__version__
'4.5.1'
>>>
$
6. sambaのインストール
PC側で色々なファイル処理をしたい場合も多く、ラズパイとのファイルコピーを容易に行うため、ラズパイにsambaをインストールして、ラズパイ側の /home/pi 以下を、PC側のエクスプローラーでアクセスできるように設定する。
6.1. インストールする
パッケージのインストールは単純に aptで実行できる。
$ sudo apt install samba
6.2. 設定する
PC側から、どのようにアクセスするかを設定ファイルで設定する。設定ファイルは、/etc/samba/smb.conf 。 このファイルの最後に、エディタ (vimとか、nanoとか)で、以下の行を追加する。
この設定では、ラズパイの/home/piを、PCから「rpi」という共有名でアクセスできるようににして、読み書き可能、guest可能(PCユーザーがゲスト)で、ラズパイに入った際の、ラズパイ側でのユーザーは、常に「pi」とする設定にしている。
[rpi]
comment = Raspberry Pi
path = /home/pi/
guest ok = yes
read only = no
browsable = no
force user = pi
6.3. デーモンを再起動する
設定ファイルを変えただけでは、有効では無いため、sambaデーモン(smbd)を再起動する。
$ sudo service smbd restart
6.4. PCからのファイル読み書きを確認する。
PC(当然だが同じネットワーク上の)の、「ファイル名を指定して実行」から、"\\ラズパイのIPアドレス\rpi\" を指定して実行すると、ラズパイの "/home/pi/"フォルダがエクスプローラーで開く。
適当にファイルを作ったり、PCとの間でファイルの相互コピーが出来る事を確認する。
7. matplotlib のインストール
7.1. インストール
$ sudo apt install python3-matplotlib
関連する各種のパッケージがインストールされる。
Setting up ttf-bitstream-vera (1.10-8) ...
Setting up fonts-lyx (2.3.2-1) ...
Setting up python3-pyparsing (2.2.0+dfsg1-2) ...
Setting up python3-cycler (0.10.0-1) ...
Setting up python3-kiwisolver (1.0.1-2+b1) ...
Setting up python-matplotlib-data (3.0.2-2) ...
Setting up python3-matplotlib (3.0.2-2) ...
Processing triggers for fontconfig (2.13.1-2) ...
7.2. 確認
ここまでに、インストールされた jupyter、opencvを使って、matplotlibが正常に動作するかを確認する。
7.2.1. jupyter notebookを起動
ラズパイのデスクトップ画面のターミナル(terminal)アイコンをクリックし、shell画面を出した状態で、下記を実行すると、Chromiumブラウザが開き、jupyter notebookの初期画面が表示される。初期画面は、/home/piのフォルダ上のファイル一覧になる。
$ jupyter notebook --browser=chromium
7.2.2. 新しいnotebookを作成
「New」➡「Python 3」を選んで新しいnotebookを作成して開く(Untitledという名称)。
7.2.3. 画像ファイルを用意する
PCから、sambaによる共有機能を使って、ラズパイの /home/pi/Picturesの下に適当に画像ファイル(写真, jpegファイル等)を、一つコピーしておく。ここでは、'test.jpg'というファイルを、/home/pi/Pictures/に格納したとする。
7.2.4. スクリプトを入力し実行する。
In[]という枠にカーソルがある状態(緑色の枠:編集モード)で、その枠の中に下記スクリプトを入力してから、「Run」ボタンをクリックする。
%matplotlib inline
import cv2
import matplotlib.pyplot as plt
img = cv2.imread("/home/pi/Pictures/test.jpg")
img_r = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img_r)
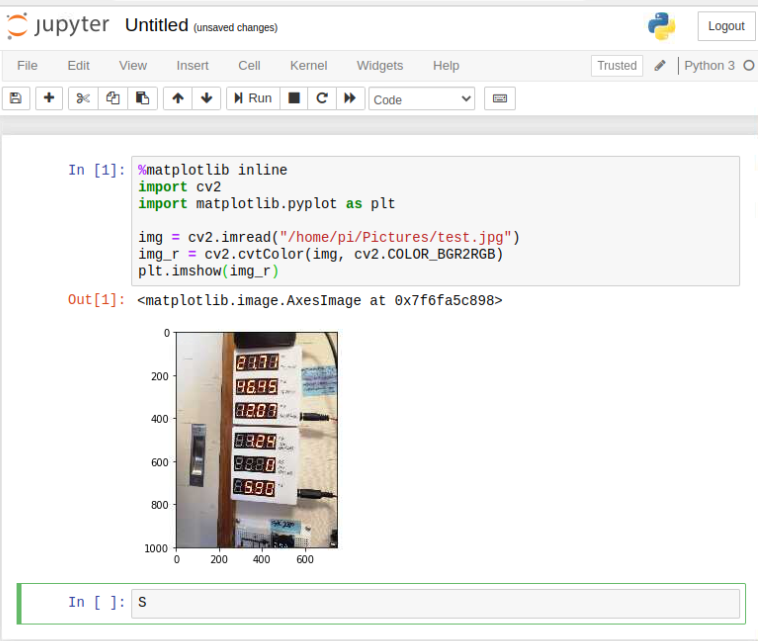
7.2.5. 結果を確認する。
正常にスクリプトが実行され、/home/pi/Pictures/test.jpgが以下のように表示されれば、ここまでの matplotlib、jupyter、opencv、sambaのインストールは正常である事の確認になる。
「Run」ボタンをクリックする代わりに、「Shift」+「Enter」でも同じく、入力したスクリプトを実行できる。 jupyter notebookの使い方については、ネット上に様々な情報があふれているのでここでは割愛する。
8. imutilのインストール
この後、画像を認識するために輪郭を抽出する等の処理が必要であるが、そのために必要なパッケージを追加でインストールする。
8.1. インストール
pip3を使って、簡単にインストールできる。
$ sudo pip3 install imutils
8.2. 確認
python3で、import出来る事を確認する。
$ python3
Python 3.7.3 (default, Jan 22 2021, 20:04:44)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import imutils
>>> imutils.__version__
'0.5.4'
>>>
9. 「7セグ」画像から輪郭抽出
【7セグメント編 – 自動文字検出・抽出OCR】連続文字判定(デジタル数字:1〜4桁以上の連続数字)+再学習を大いに参考にさせて頂いた(というより、基本的には、この記事の通りにひとつずつ確認しただけです・・・。ありがとうございます。)
9.1. 事前準備
最終的には、カメラで撮影した「7セグLEDを含む写真」から、7セグLEDの範囲を特定し、その部分の画像を抜き出した上で、台形処理をして直角形の画像にし、自動的に数字の位置を特定した上で、数字を推定するという処理を行いたい。が、まずは、7セグLEDの範囲を特定して切り出すところまでは、手動で行うことにした。
カメラで撮った写真はこれ(汚い部屋でお恥ずかしい)点灯していないセグメントも光ってしまっている(表面のフィルムを付けていない)問題がありますが、実験としては、これもよかろうという事でこのまま進める。
 7seg1.jpg
7seg1.jpg
このファイルから、7セグの部分の座標を読取、その部分を切り取った画像を手作業で作成する。座標の読取は、PCの画像ソフトを使えば出来る(例えば、PhotoScapeのようなソフト)。
写真には、最大4桁表示の7セグが6行あるので、それぞれの行の座標を調べ、合計6セットの座標を取得する。下記はそれぞれ、左上、右上、左下、右下の座標情報。
- (282,109),(477,99),(279,182),(473,175)
- (279,218),(473,214),(277,292),(470,290)
- (277,329),(469,328),(275,400),(467,401)
- (274,468),(465,473),(271,537),(462,546)
- (251,575),(461,582),(269,645),(460,658)
- (269,681),(459,692),(267,751),(457,765)
9.2. 画像の読込み、切り取り、台形歪補正
7seg1.jpgを読込み、上記の範囲で切り取った後、台形歪を補正した結果を6つのpngファイルとして保存する。
%matplotlib inline
import cv2
import matplotlib.pyplot as plt
import numpy as np
import math
from imutils import contours
def cut_img(img,p1,p2,p3,p4):
o_width = np.linalg.norm(p2 - p1)
o_width = math.floor(o_width * w_ratio)
o_height = np.linalg.norm(p3 - p1)
o_height = math.floor(o_height)
src = np.float32([p1, p2, p3, p4])
dst = np.float32([[0, 0],[o_width, 0],[0, o_height],[o_width, o_height]])
M = cv2.getPerspectiveTransform(src, dst)
img_sq = cv2.warpPerspective(img, M,(o_width, o_height))
return img_sq
w_ratio = 1.1
input_file_path = "7seg1.jpg"
img = cv2.imread(input_file_path)
pnts= [[(282,109),(477,99),(279,182),(473,175)],
[(279,218),(473,214),(277,292),(470,290)],
[(277,329),(469,328),(275,400),(467,401)],
[(274,468),(465,473),(271,537),(462,546)],
[(271,575),(461,582),(269,645),(460,658)],
[(269,681),(459,692),(267,751),(457,765)]]
plt.figure(figsize=(12,4))
for i, pnt in enumerate(pnts):
p1 = np.array([pnt[0][0],pnt[0][1]])
p2 = np.array([pnt[1][0],pnt[1][1]])
p3 = np.array([pnt[2][0],pnt[2][1]])
p4 = np.array([pnt[3][0],pnt[3][1]])
ret = cut_img(img,p1,p2,p3,p4)
filename = 'sq_img{}.png'.format(i)
cv2.imwrite(filename, ret)
plt.subplot(2,3,i+1)
ret = cv2.cvtColor(ret, cv2.COLOR_BGR2RGB)
plt.imshow(ret)
結果

このファイル一つ一つに対して、輪郭抽出、数字位置の外枠取得、数値毎の画像切り出し、数値推測というステップを踏んで、画像から数値への変換を行っていく。それぞれ、ファイル名は sq_img0.png~sq_img5.pngとしてある。
9.3. 輪郭抽出
上記のファイルそれぞれに対し、二値化、膨張処理、輪郭抽出を行う。まず、前項で生成されたそれぞれのファイルを読込み、脱色(decolor)して白黒の映像にした後、指定したしきい値で二値化処理を行う。
二値化の方法には、色々あるが、ここではテストのために、指定した数値で二値化する方法で試してみた。画素毎に 0~255の値をとるので、180という値でしきい値を取る事により、LEDが光って明るい所で二値化するようにした。
この値を数値で指定せず、自動的に画像から取得する方法もあるので、別途試してみるが、とりあえず今は、手動で設定した値を使うことにする。
二値化した後、切れた輪郭を補うため(例えば、7セグだと、縦の線はどうしても真ん中で途切れているので、それを一つの輪郭として得るため)、二値化した境界線を「膨張」させて、隣接する画素と一体化させる処理をしている。 どの程度膨張させるが良いかは、画像によるところがあるが、7セグだと、縦の膨張は必要だが、横の膨張は不要と考えて、膨張用のマトリクスは、縦 5ピクセル、横 1ピクセルとした。 繰り返しは一回のみとしている。
三つ目の画像に於いて、一番左側にノイズを拾ってしまった形跡が見られる。試しに、二値化のしきい値を変更してみたが、他の部分へ悪影響が見られるためしきい値による除外で不可能である。
参考にさせて頂いたサイトでは、この後の処理(外枠の取得)に於いて、一定範囲に入らない輪郭はノイズとして除外する方法を取っているので、次の項の処理で試してみる事にする。
膨張させた二値化画像から輪郭を抽出するが、その際のオプションとして、最も外側の輪郭だけを抽出する。何故なら、「0」とか「6」のように、間に閉じられた空間がある場合、内側の輪郭は文字認識には不要なため。また、輪郭データをシンプルにするため、全ての点を保持せず、直線的に置き換えられる所は直線の端点データのみを保持する方法(CHAIN_APPROX_SIMPLE)で抽出している。
抽出した輪郭データを、左から右へと並べ替え、輪郭線を可視化するために、真っ黒な画像(img_black)を同じサイズで作ってから、その画像に輪郭を緑色で、幅2ピクセルで描いている。
結果は、それぞれファイルに出力している(cnt_img0.png~)
最終的なプログラムでは、ファイルに書き出す必要は無いが、途中の検討に便利と思われるため書き出して置く。
%matplotlib inline
import cv2
import matplotlib.pyplot as plt
import numpy as np
import math
from imutils import contours
def contour_img(img, threshold):
img_gray, _ = cv2.decolor(img)
ret, img_binary = cv2.threshold(img_gray, threshold, 255, cv2.THRESH_BINARY)
kernel = np.ones((5,1),np.uint8)
img_dilation = cv2.dilate(img_binary,kernel,iterations = 1)
cnts, hierarchy = cv2.findContours(img_dilation, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts, hierarchy = contours.sort_contours(cnts, method='left-to-right')
#img_black = (img * 0).astype(np.uint8) #
img_out = cv2.cvtColor(img_dilation, cv2.COLOR_GRAY2BGR)
img_out_tmp = img_out.copy() # make clone
img_cnts = cv2.drawContours(img_out_tmp, cnts, -1, (0,0,255), 2) #img changes
return img_cnts, img_out, cnts
plt.figure(figsize=(12,4))
for i in range(6):
filename = 'sq_img{}.png'.format(i)
img = cv2.imread(filename)
img_cnt, img_out, cnts = contour_img(img, 180) # 180 as temporal value
filename = 'cont_img{}.png'.format(i)
cv2.imwrite(filename, img_out) # save dilated gray image (no contour)
img_r = cv2.cvtColor(img_cnt, cv2.COLOR_BGR2RGB) # show contoured image
plt.subplot(2,3,i+1)
plt.imshow(img_out)
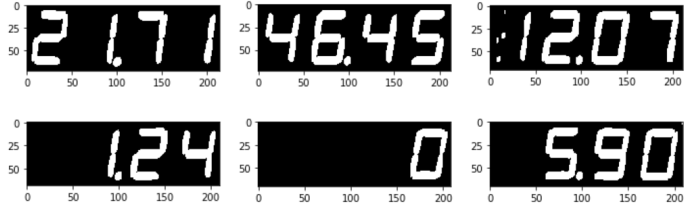
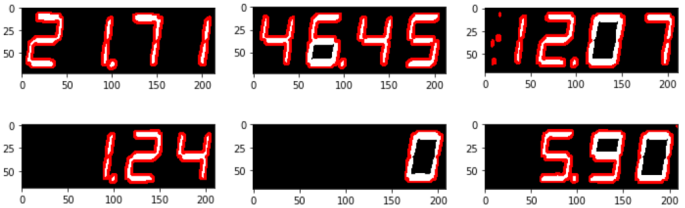
結果
輪郭無し (膨張後の画像) ここから推定に使うために切り出す。
輪郭付き(膨張後の画像に輪郭)
9.4. 検出枠の切り出し
これまでに得られた輪郭から、切り出すための四角い枠を取得し、一文字ずつ切り出すための境界線を明確にする処理。
前項でも気になった、ノイズについて、一定の範囲内の大きさの枠のみ有効として、幅が狭すぎる枠や高さが低すぎる枠は除外する事を取り入れてみる。 ただ、小数点のドットを取得する事が出来なくなるのが副作用である。小数点のドットを認識しつつ、ノイズを削除する方法が何かしら必要であると思われる。
%matplotlib inline
import cv2
import matplotlib.pyplot as plt
import numpy as np
import math
from imutils import contours
def contour_img(img, threshold):
img_gray, _ = cv2.decolor(img)
ret, img_binary = cv2.threshold(img_gray, threshold, 255, cv2.THRESH_BINARY)
kernel = np.ones((4,1),np.uint8)
img_dilation = cv2.dilate(img_binary,kernel,iterations = 1)
cnts, hierarchy = cv2.findContours(img_dilation, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts, hierarchy = contours.sort_contours(cnts, method='left-to-right')
#img_black = (img * 0).astype(np.uint8) #
img_out = cv2.cvtColor(img_dilation, cv2.COLOR_GRAY2BGR)
img_out_tmp = img_out.copy() # make clone
img_cnts = cv2.drawContours(img_out_tmp, cnts, -1, (0,0,255), 2) #img changes
return img_cnts, img_out, cnts
def roi_img(img, cnts, i):
img_h, img_w = img.shape[:2]
ROI_index = 0
result = []
for contour in cnts:
x, y, w, h = cv2.boundingRect(contour)
#if h < img_h/2:
# continue
ROI = img[y:y+h, x:x+w]
ROI = cv2.bitwise_not(ROI)
cv2.imwrite('ROI_img{}{}.png'.format(i, ROI_index), ROI)
ROI_index += 1
result.append([x, y, w, h])
for x, y, w, h in result:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
return result, img, ROI_index
plt.figure(figsize=(12,4))
for i in range(6):
filename = 'sq_img{}.png'.format(i)
img_org = cv2.imread(filename)
img_cont, img_out, cnts = contour_img(img_org, 180) # 180 as temporal value
result, img, ROI_index = roi_img(img_out, cnts, i)
# filename = 'roi_img{}.png'.format(i)
# cv2.imwrite(filename, img)
img_r = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.subplot(2,3,i+1)
plt.imshow(img_r)
結果
大きさの制限を付けない場合の結果は以下の通り。
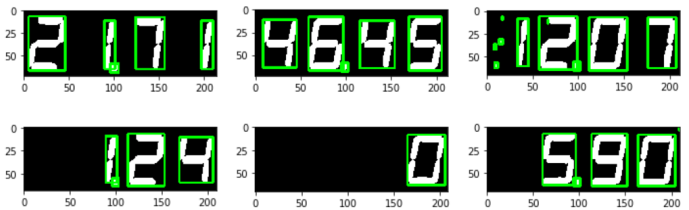
例えば、「高さが半分に満たない枠は無視する」というルールを適用するれば、下図のように、三つ目の画像の左側にあるノイズは検出されなくなる。ただ、逆に小数点のドットは全て無視される事になる。 小数点の件は一旦許容する事として、このルールを適用して進める事にする。
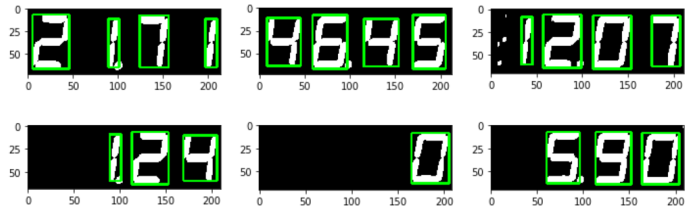
こうして枠で切り出した数字の画像(ROI_img00.png~)は以下の通り。小数点のドットは全て、無視されてしまった。
%matplotlib inline
import cv2
import matplotlib.pyplot as plt
import glob
import os
plt.figure(figsize=(12,8))
file_list = sorted(glob.glob("ROI_img*png"))
for i, file in enumerate(file_list):
img = cv2.imread(file)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.subplot(8,12,i+1)
plt.imshow(img)

注記:各文字に軸と枠が表示されているが、実際のファイルには枠も軸も無い。
10. 切り取った画像から、数字を推定(判定)する
いよいよ、tensorflowと kerasの出番。
ここまでで、切り取る事が出来た各数字の画像ファイルを、一つずつ処理して、数値を推定し、表示する。
10.1. 学習済モデル
モデルとしては、カラーのモデルとグレーのモデルがあるが、ここではグレー(白黒)のモデルを使って推定する。
モデルのファイルは、参照にしたページからダウンロードして物を、そのまま使っている。
なお、これらのモデルの作成に使われたtensorflowやkerasのバージョンは以下の通り。
- tensoflow 2.4.1
- keras 2.4.3
このバージョンが違うと、モデルのSerializationの違いなどで、モデルファイルの互換性が無い。ちなみに、ラズパイの32bit OS用として、最終バージョンである tensorflow 2.2.0 とは、互換性が無い事が分かっている。 「この学習済みモデルを使いたかった」というのが、今回 64bit OSをインストールして、tensorflow 2.4.1を導入した一番の理由である。
10.2. プログラム
参照したページと、流れは全く同じ。
%matplotlib inline
import cv2
import matplotlib.pyplot as plt
from keras.models import load_model
import glob
import os
model = load_model('model_gray.h5')
folder = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ''] # 空白の表示に対応させるため、blankのところを「' '」で空白に設定
image_width = 28 # 使用する学習済みモデルと同じwidth(横幅)を指定
image_height = 28 # 使用する学習済みモデルと同じheight(縦の高さ)を指定
color_setting = 1 # ここを変更。学習済みモデルと同じ画像のカラー設定にする。モノクロ・グレースケールの場合は「1」。カラーの場合は「3」
def predict_img(img):
if color_setting == 1:
gazou = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
elif color_setting == 3:
gazou = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
gazou = cv2.resize(gazou, (image_width, image_height))
suuti = gazou.reshape(image_width, image_height, color_setting).astype('float32')/255
n = model.predict(np.array([suuti]))
return n
plt.figure(figsize=(12,5))
file_list = sorted(glob.glob("ROI_img*png"))
for i, file in enumerate(file_list):
img = cv2.imread(file)
n = predict_img(img)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.subplot(3,12,i+1)
plt.axis('off')
plt.imshow(img)
plt.title(folder[n.argmax()] )
print(folder[n.argmax()] , end=' ')
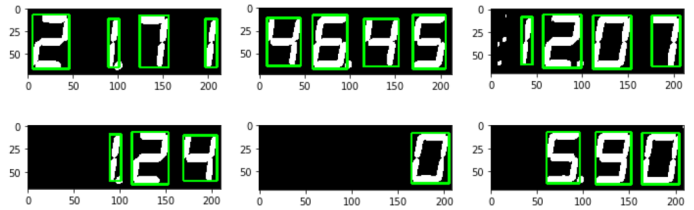
10.3. 推定結果
下図が、今回の処理による、7セグLEDの数字を推定した結果である。
10.3.1. 結果
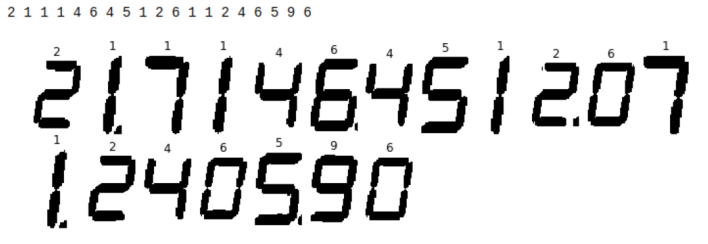
10.3.2. 問題点1
残念ながら、「7」が全く認識できておらず、常に「1」と推定してしまっている。7という絵柄の、上にある横線が全然認識できておらず、「1」になってしまっている。安定して「1」と推定しているところを見ると、何らかの解決があるはず。
10.3.3. 問題点2
「0」が常に、「6」と推定されてしまっている。理由は不明。もう少し分析する必要あり。
10.3.4. 今後にむけて。
今回のモデル作成時に使われた7セグ画像と、今回、自分で撮影した7セグ画像との類似性は、調べていないので、今後の検証をする。
また、自分でモデルを作成して、実験してみたいと思う。
また、今回は、膨張させた二値化画像を使って最終的な判定(推定)を行ったが、オリジナルの画像を使った実験もしてみたい。
いずれにせよ、第一段階は出来ることが分かったのと、環境がラズパイ上に整ったことは大きく、今後正しく判定できるようにしていきたい。
11. 主なパッケージのバージョン整理
sudo pip3 list から、インストール中に見かけたパッケージ名を適当に残したリストは以下。
Package Version
---------------------- -----------
Cython 0.29.21
decorator 4.3.0
grpcio 1.32.0
h5py 2.10.0
imutils 0.5.4
ipython 5.8.0
jupyter-client 5.2.3
jupyter-console 5.2.0
jupyter-core 4.4.0
Keras 2.4.3
Keras-Preprocessing 1.1.2
matplotlib 3.0.2
notebook 5.7.8
numpy 1.19.5
opencv-python 4.5.1.48
opt-einsum 3.3.0
Pillow 5.4.1
pip 21.0.1
pybind11 2.6.2
PyYAML 5.4.1
scipy 1.6.2
SecretStorage 2.3.1
setuptools 56.0.0
six 1.15.0
tensorboard 2.4.1
tensorboard-plugin-wit 1.8.0
tensorflow 2.4.1
tensorflow-estimator 2.4.0
wheel 0.36.2
wrapt 1.12.1
~
12. その2につづく・・・
13. おまけ
13.1. 64bit OSでカメラ確認
raspistillコマンドは、まだ 64bit OS上ではリリースされていないため、別のアプリが無いか探して見たところ、qv4l2 (QV4L2)というアプリがあるとの事。早速インストールして試してみた。
13.1.1. インストール
aptでインストールできる。
$ sudo apt install qv4l2
QV4L2の小文字なので間違えないように。
カメラが認識されているかどうかを確認すると、認識できている。
$ vcgencmd get_camera
supported=1 detected=1
13.1.2. 確認
アプリを立ち上げてキャプチャーしてみる。
$ qv4l2
qt5ct: using qt5ct plugin
qt5ct: D-Bus global menu: no
GUIのメニューが立ち上がるので、snap shotを撮ってみる。

キャプチャーできたが、色がおかしい。色がおかしいのは、32bitの時にもあった(突然色がおかしくなった)。raspistillの時には、autowhitebalanceの設定を0にしたら、とりあえずそれなりの色になったが、qv4l2のメニューで whitebalanceを変更してみても上手く変わらなかった。(というか、一回変更すると、元に戻しても正常なキャプチャが出来なくなるから、ソフトがちゃんと動いていないと思われる)