はじめに
※この記事はおおよそ実用的でない内容です。(作ってるときはもう少し実用的かと思いましたが、そうでないため供養のために書いています。)
Claude Code を毎日使っていると、ふと「最近ちょっと賢くなった?」や逆に「なんか最近頭悪くなった?」と感じる瞬間があります。SNS でも「劣化した」「いや前より良くなった」という声が定期的に上がります。
しかし体感でしかありません。本当に性能が変わったのか、それとも気のせい(自分のタスクが難しかっただけ)なのか、誰も客観的な数字を持っていない。
そこで「Claude Code の性能の向上・劣化を、時系列で可視化できないか?」と思い立ったのが今回の取り組みです。
最初のアプローチ:自分で課題を解かせて測定する
はじめに考えたのは、ごく素直な発想でした。
「Claude Code に毎日同じコーディング課題を出して、出来栄えを採点すれば、性能の変化が数値として見えるはず。」
具体的には次のようなことを試しました。
- アルゴリズム問題やリファクタリング課題などの固定タスクセットを用意する
- 毎日(あるいはバージョンが変わるたびに)同じタスクを解かせる
- それを時系列でプロットして「性能トレンド」とする
しかし、実際にやってみるとほとんど差が出ませんでした。。。
原因としては問題が簡単すぎたことかなと思われます。
なら難しい問題にすれば良いかなと思いましたが、実際に開発する程度の難易度の試験設計やその難易度の物を様々な観点で設計するのはかなり難しいと感じました。
方針転換:みんなの「体感」を集めて可視化する
ベンチでダメなら、視点を変えることにしました。
性能変化は、まずユーザーの体感として SNS に現れると考えました。「速くなった」「バカになった」「直った」といった声は、個々はノイズでも統計的に集めれば傾向が見えます。
作ったもの:性能センチメント・ダッシュボード
そこで、X の投稿から Claude Code の「性能の向上 ↔ 劣化」を感情+キーワードで数値化し、時系列で可視化するダッシュボードを作りました。
評価構成
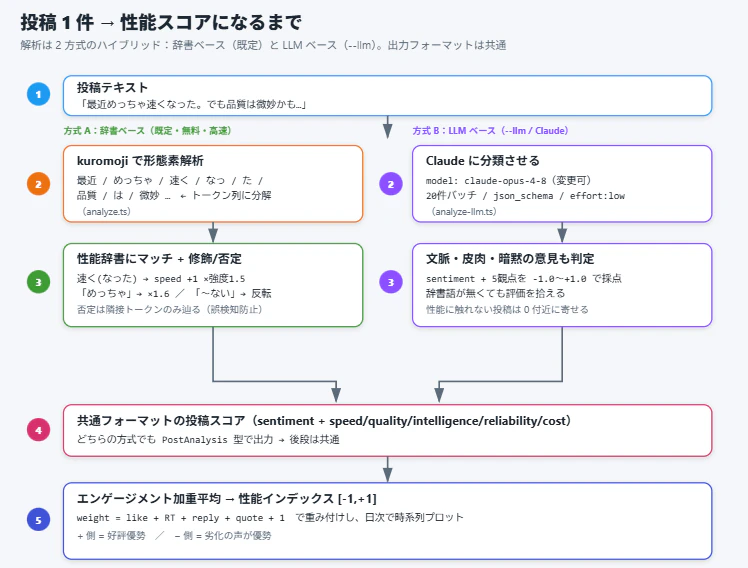
投稿1件を性能スコアに変換する部分が、このシステムの肝です。辞書ベースと LLM ベースの2方式を用意し、どちらも同じ出力フォーマット(全体の sentiment + 5観点スコア)に揃えてあるので、後段の集計・可視化は方式を問わず共通で動きます。
方式A:辞書ベース
単純なポジネガ判定では「Claude Code の性能」という文脈を拾えません。そこで、性能に関する語をカテゴリ・極性・強度つきで辞書化しました。
例
E('爆速', 'speed', 1, 'ja', 2),
E('遅くなった', 'speed', -1, 'ja', 1.5),
E('劣化', 'quality', -1, 'ja', 1.5),
E('賢くなった', 'intelligence', 1, 'ja', 1.5),
E('指示を無視', 'intelligence', -1, 'ja', 1.5),
E('クラッシュ', 'reliability', -1, 'ja', 1.5),
カテゴリは speed / quality / intelligence / reliability / cost の5つにし、「速度は良いけど賢さは落ちた」のように、観点ごとに分解して見られるようにしています。
処理の流れは、形態素解析 → 辞書マッチ → 修飾語・否定の調整です。
体感に近づけるための工夫として強度修飾語「とても」「めっちゃ」「super」などで隣接する語のスコアを増減させています。
また、否定の反転「速く”ない”」「劣化して”ない”」のような否定を、隣接トークンだけを辿って反転しており離れた句の否定を誤って拾わないようにしています。
辞書ベースは無料・高速で毎日回せるのが強みですが、辞書に載っていない言い回しや、皮肉・遠回しな評価は取りこぼします。そのため方式Bを追加しました。
方式B:LLM ベース(Claude に分類させる)
辞書の穴を埋めるため、Claude 自身に分類させる方式も用意しました。
const MODEL = process.env.LLM_MODEL || 'claude-opus-4-8';
// 20件ずつバッチ、json_schema で構造化出力、effort:low でコスト最適化
各投稿を「全体の sentiment + 5観点」で -1.0〜+1.0 に採点させます。辞書語が無くても文脈・皮肉・暗黙の意見を拾えるのが利点で、「性能に触れていない投稿は 0 付近に寄せる」ようシステムプロンプトで指示しています。
合流:性能インデックスへ
どちらの方式も同じPostAnalysis型を返すので、最後は共通処理。投稿ごとのスコアを**エンゲージメント加重平均して [-1, +1] の「性能インデックス」に落とし込み、日次で時系列プロットします。+ 側に振れていれば「最近は好評」、− 側なら「劣化の声が優勢」と一目で分かる、という仕組みです。
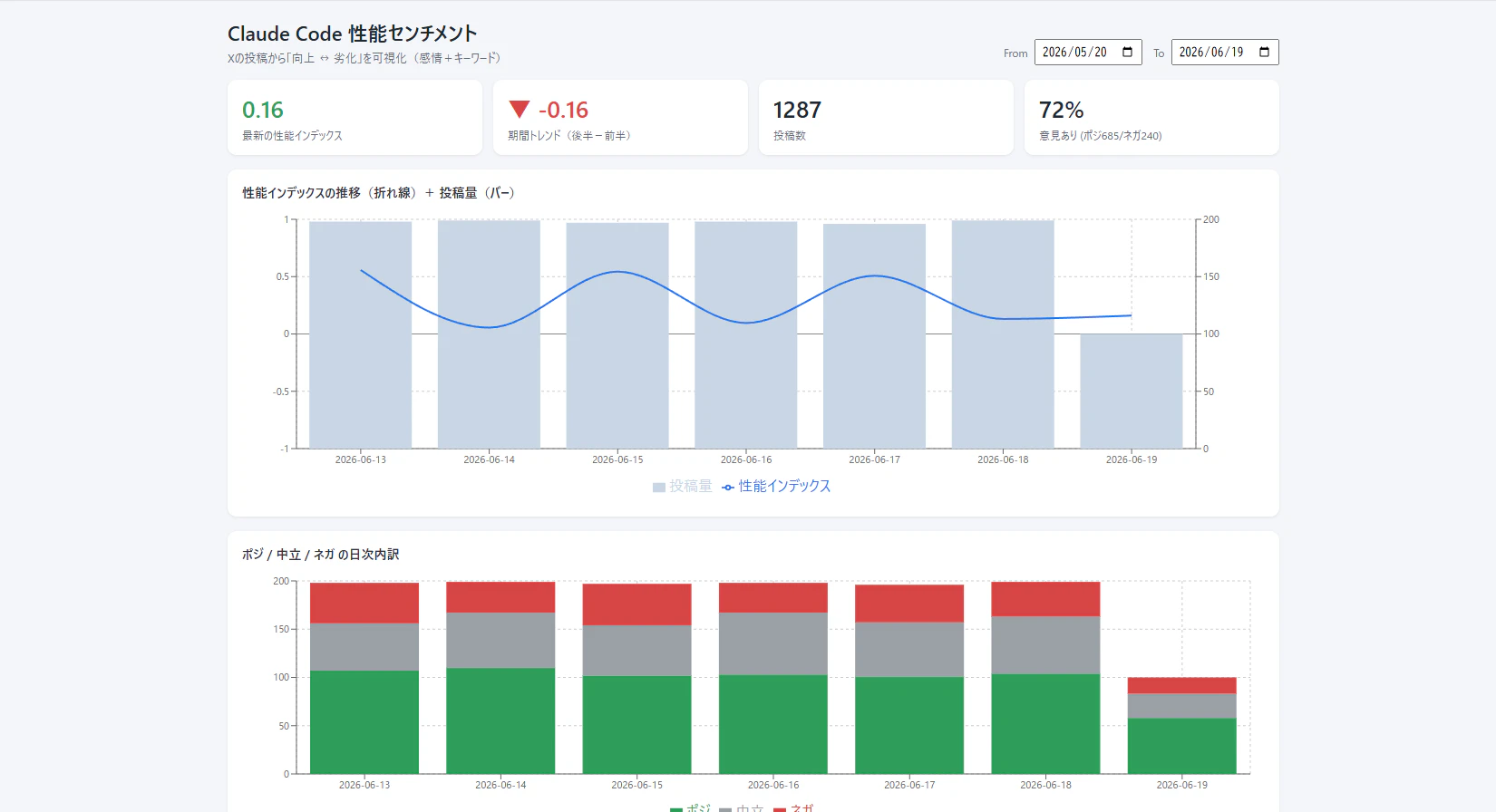
表示されるダッシュボード
このアプローチの良かった点・限界
今回のアプローチで試験を行うよりも簡単に人々の声からサンプリングしClaude Codeの性能について可視化することができるようになりました。しかし今回の方法でも定量的な評価ではない点や性能以外の投稿もあるためデータ自体に疑問が残るアプローチとなっています。24時間均等ではなく 3時間ごとの8クラスタ(計200件/日 25件/3時間 最大1400/週)に分けて投稿を取って来ていますがサンプル数としては現状かなり少ないです。
また、特にひどいのがコスト面です。このサンプル数で1週間分2500円程度かかっています。その大部分がX APIの料金です。しっかり計測するとなると個人的に1000件/日は取りたいところです。そうすると5倍なので1週間で12500円、1か月で60000円。。。考えたくないですね。
最後に
少ないサンプル数とはいえ仕組みとしてClaude Codeの性能向上・劣化を可視化する仕組みを作れたことは良かったかなと感じました。ただ正直性能劣化を検知しても何かできるかと言われると特にない気もするのでそれに1か月で60000円はコスパだ悪いどころの話ではないと思いますw
今後はよりコスパの良い方法を模索して第2弾が出せるといいなと思っています!