はじめに
この記事は、GitHub 上で公開されている Azure Synapse Link for Azure Cosmos DB のサンプルの解説記事です。
本家の記載は英語となっています。こちら のリポジトリにて日本語訳を行っていますので、どちらか好きな方にアクセスを行ってください。
- 本家 (English): Azure-Samples/Synapse
- 日本語訳 (非公式): ymasaoka/Synapse
なお、Azure Synapse Link for Azure Cosmos DB のサンプルは、/Notebooks/PySpark/Synapse Link for Cosmos DB samples/ に用意されています。詳細を確認したい方は、こちらも合わせてご確認ください。
環境構築
このサンプルの実行には、以下の環境が必要です。
- Azure Cosmos DB アカウント (SQL API)
- Spark プールがある Azure Synapse ワークスペース
環境の作成方法については、以下の記事を参考にしてください。
シナリオ 1 - Internet of Things (IoT)
今回は、Azure Synapse Spark を使用して Azure Cosmos DB にストリーミングおよびバッチの IoT データを取り込み、Azure Synapse Link を使用して結合と集計を実行し、Azure Cognitive Services on Spark (MMLSpark) を使用して Anomaly Detector を実行するまでを行います。
Anomaly Detector は、Azure のサービス(2020/08/18現在、プレビュー)で、異常検出機能をアプリに簡単に組み込むことができるサービスです。
今回の流れ
IoTのストリーミングデータ、およびバッチデータを Azure Synapse Analytics の Spark プールを使用して Cosmos DB のトランザクションストアに書き込みます。その後、トランザクションストアから分析ストアに自動同期されたデータを Azure Synapse Link for Azure Cosmos DB で参照し、Azure Synapse Analytics 上でデータの結合や集計を実行していくイメージです。

事前準備
/Notebooks/PySpark/Synapse Link for Cosmos DB samples/IoT/README.md の内容に従って、データの準備、設定を行います。
ここで行うことは、以下の5点です。
- IoTDeviceInfo.csv ファイルのアップロード
- Synapse ワークスペースに関連付けられているストレージアカウントのアクセス制御 (IAM) 設定
- データエクスプローラーにて Azure Synapse Link を有効化
- Azure Cosmos DB アカウントでデータベースとコンテナーの作成
- CosmosDBIoTDemo
- IoTSignals (分析ストアは有効)
- IoTDeviceInfo (分析ストアは有効)
- CosmosDBIoTDemo
- Azure Synapse ワークスペースにて、Azure Cosmos DB のリンクサービスを作成
IoTDeviceInfo.csv ファイルのアップロード
IoTDeviceInfo.csvファイルは、/Notebooks/PySpark/Synapse Link for Cosmos DB samples/IoT/IoTData 以下にあります。
ファイルを取得して、Azure Synapse ワークスペースの画面から、Azure Data Lake Storage にアップロードしましょう。
まずは、IoTData フォルダを作成します。Data / Linked タブを選択し、Azure Synapse Analytics 環境にアタッチされている Azure Data Lake Storage Gen 2 環境を選択し、+New Folder を選択してフォルダを新規作成していきます。
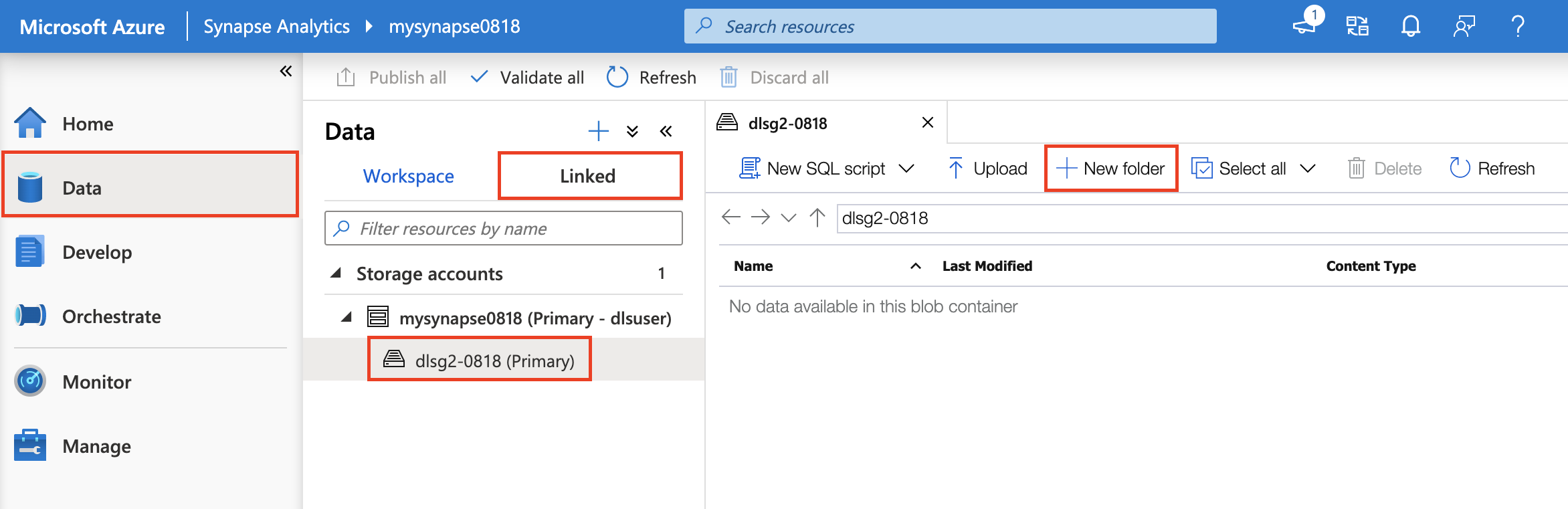
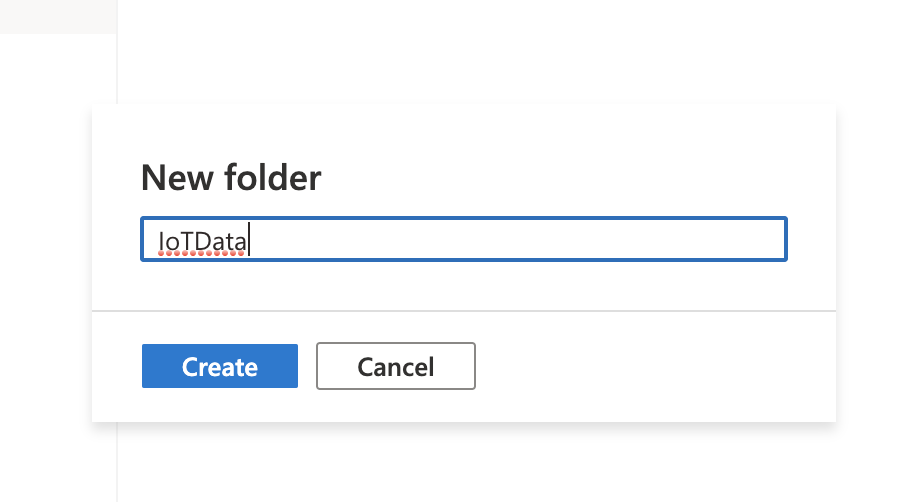
IotData フォルダを作成したら、IoTData フォルダ内にIoTDeviceInfo.csvファイルを配置しましょう。
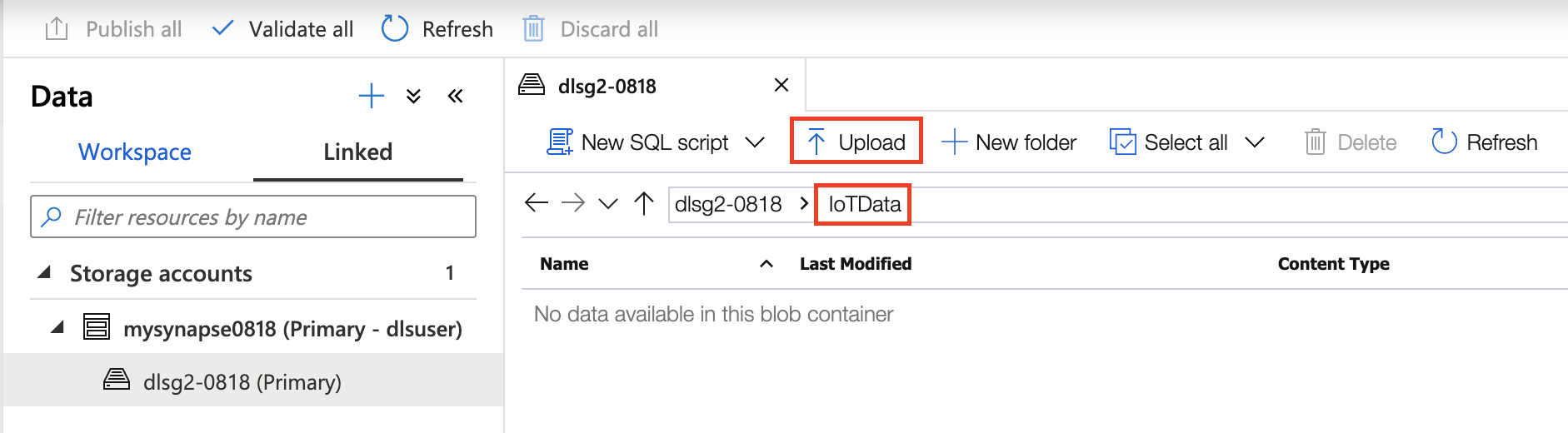
ストレージアカウントのアクセス制御 (IAM) 設定
アクセス制御(IAM) タブにて、ロールの追加を行いましょう。
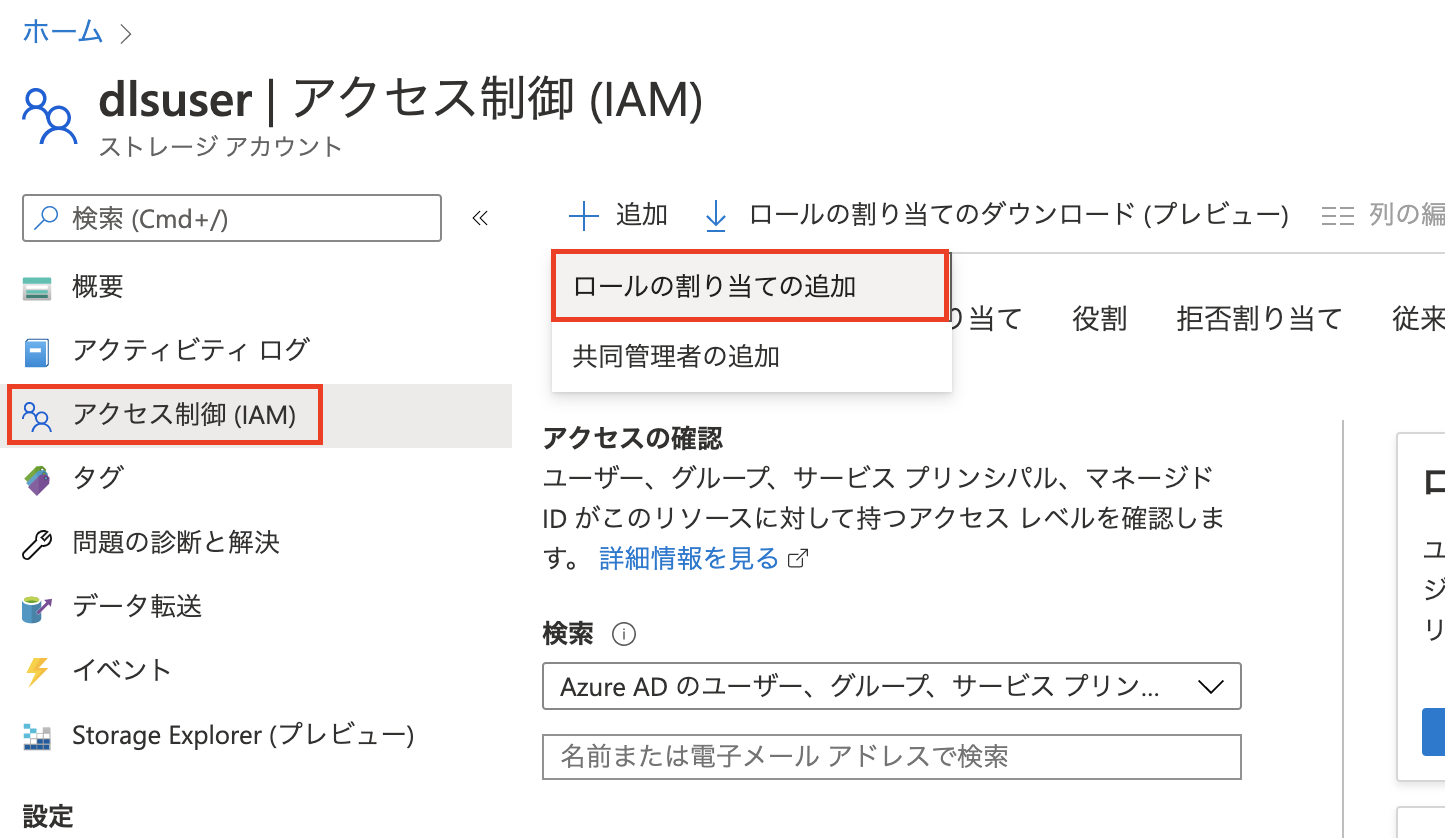
割り当てるロール(役割)は、ストレージ BLOB データ共同作成者にします。自分のユーザーを追加して、ロールを追加します。

Azure Synapse Link を有効化
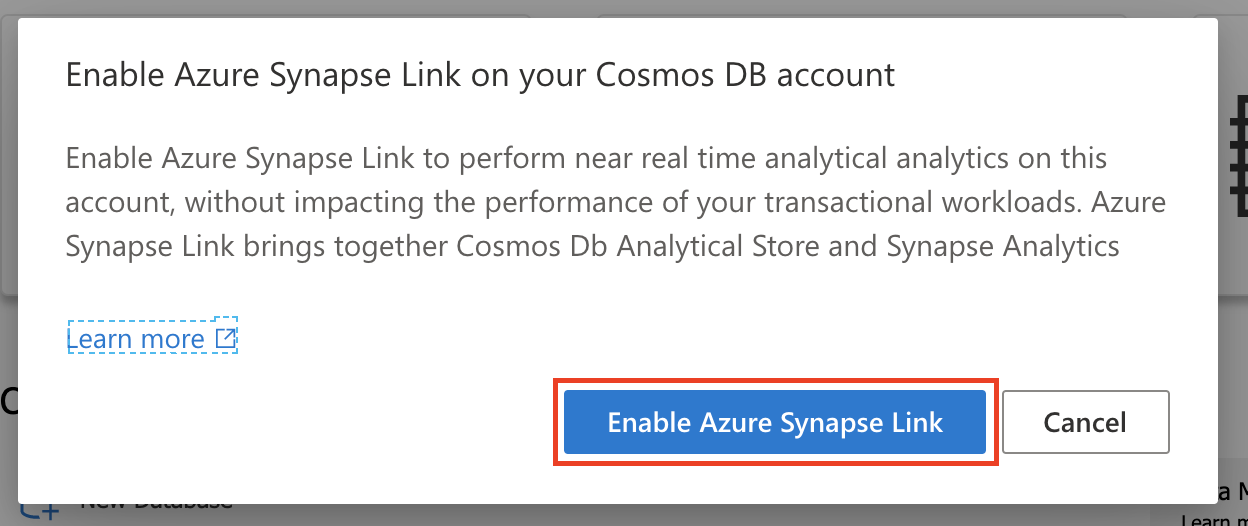
Azure Synapse Link を有効化しないと、Azure Cosmos DB の分析ストアが作成できないため、有効化します。
データエクスプローラー上にある Enable Azure Synapse Link ボタンを選択し、Azure Synapse Link を有効化します。

データベースとコンテナーの作成
先述の情報に従って、データベースとコンテナーを作成してください。GitHub では CosmosDBIoTDemo データベース作成時、オートスケール(Autoscale)設定を有効化し、4000 RU/s で作成 とありますが、実際の処理開始までは、オートスケール無し(Manual)の 400 RU/s での作成で問題ありません。こちらは後で変更可能です。
コンテナーのパーティションキーは、両方/idです。各コンテナー作成時、Analytical store が On になっていることを必ず確認してください。
Azure Cosmos DB のリンクサービスを作成
これは冒頭に紹介した記事を参考にしてください。リンクサービス名はCosmosDBIoTDemoです。
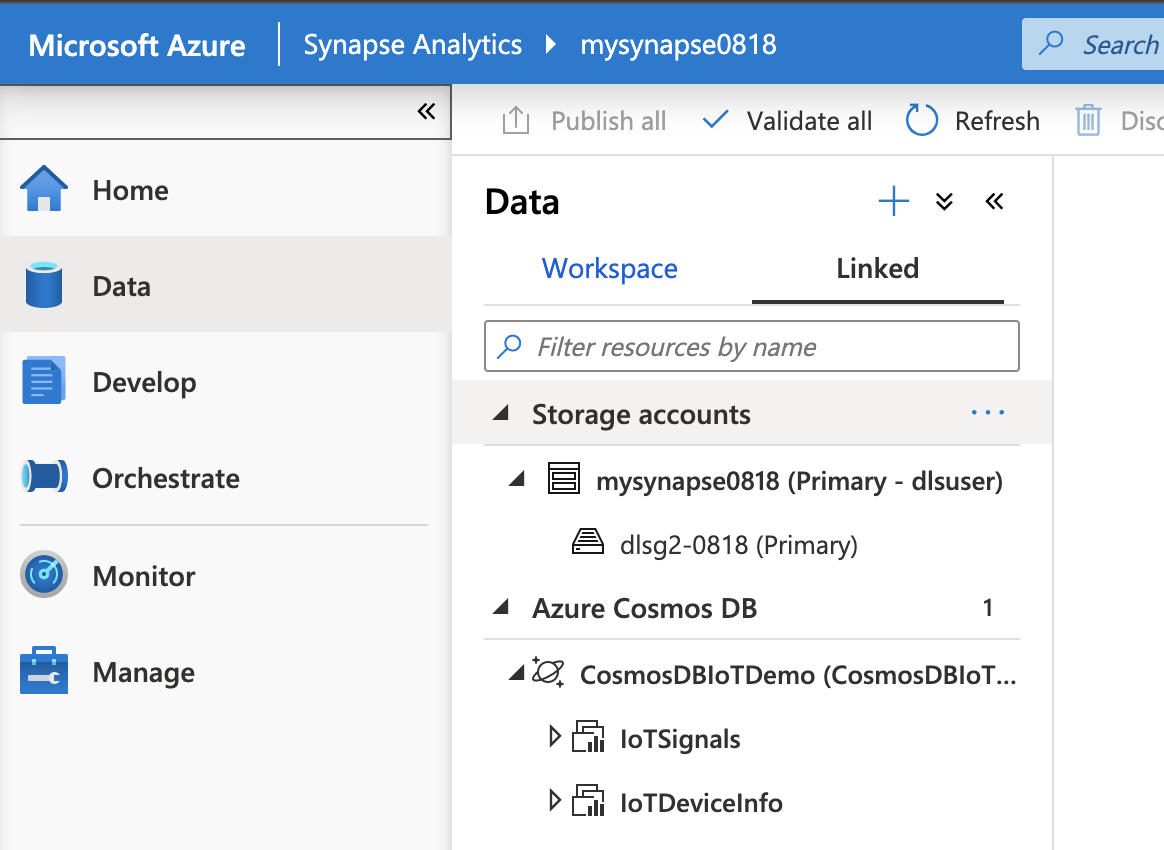
リンクサービスを作成できたら、以下のように、Azure Synapse ワークスペースから Cosmos DB の情報が確認できるはずです。
01-CosmosDBSynapseStreamIngestion
最初のノートブックです。ここでは、構造化ストリーミングを使用して Azure Cosmos DB コレクションにストリーミングデータを取り込むことを行います。
.ipynb ファイルは IoTDeviceInfo.csv ファイル同様、GitHub 上にあるので取得し、Azure Synapse ワークスペースの Develop よりインポートを行ってください。
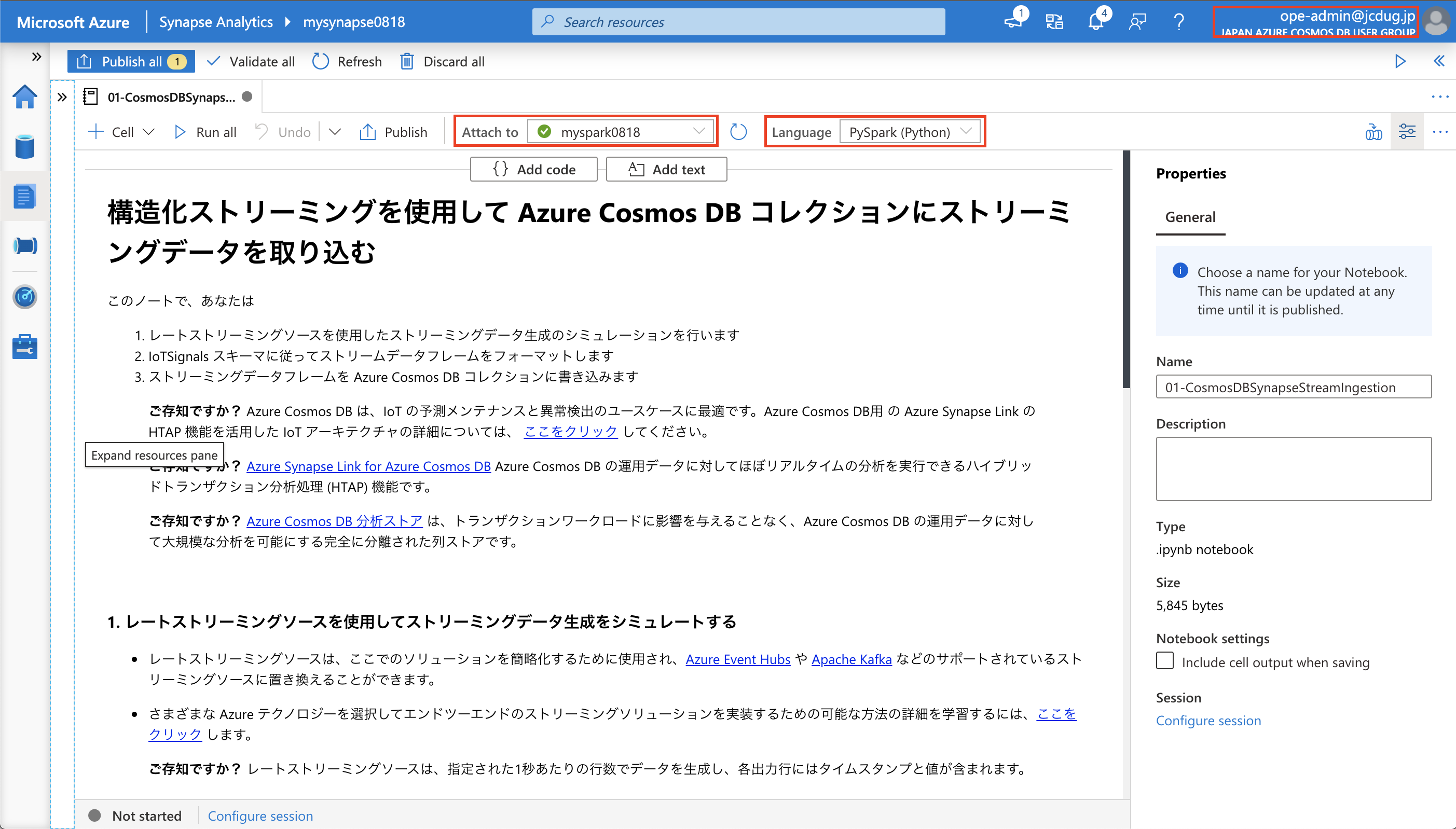
インポートが完了したら、以下のようにノートブックが表示されるはずです。ここで、Attach to に事前に作成済みの Spark プール、Language に PySpark が設定されていることを確認してください。
ここまで完了したら、あとはノートブックを実行するだけです。実行する前に、Azure Cosmos DB のオートスケールの設定を変更している場合は、オートスケールを有効にしましょう。オートスケールの設定を行わず、400 RU/s のまま実行すると、ステータスコード Http 429 が返され、データの投入がうまくいかなくなります。
実行するコードについては、ノートブック内に合わせて解説があるので、そちらを参照してください。
なお、Readme.md に記載してある通り、このノートブックは、後半のサンプル実行のためのデータ作成がメインです。実行開始後、2〜5分の時間は放置しましょう。ただし、この2〜5分という時間に Spark プールの初回起動は含みません。 Spark プールは、アイドル状態に移行した後の初回の PySpark 実行時にプールの起動を行うため、実行に時間がかかります。
下記の図の通り、Cell 3 と Cell 5 の処理が終了し、Cell 7 の処理が動き続けていることを確認してから放置しましょう。いわゆる、この放置の作業が IoT のストリーミングデータの受信と保存 の再現サンプルということになります。
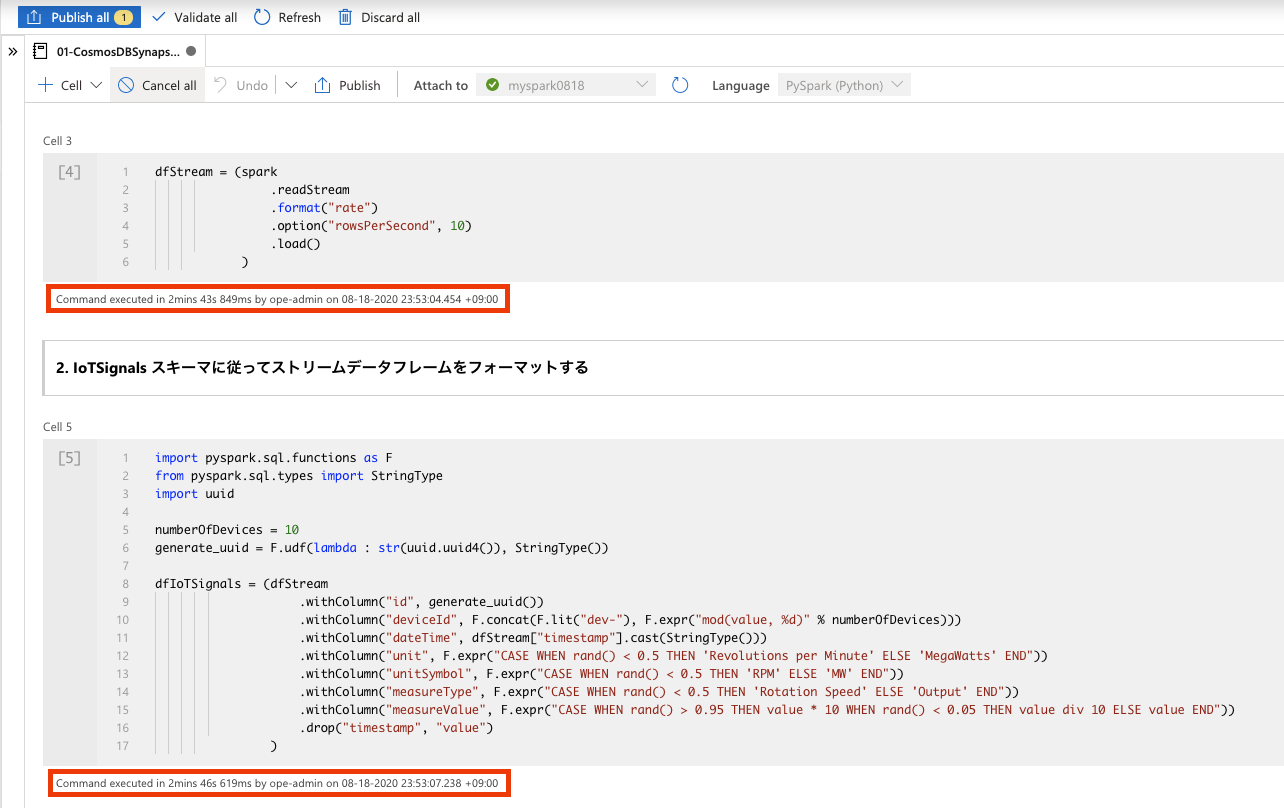
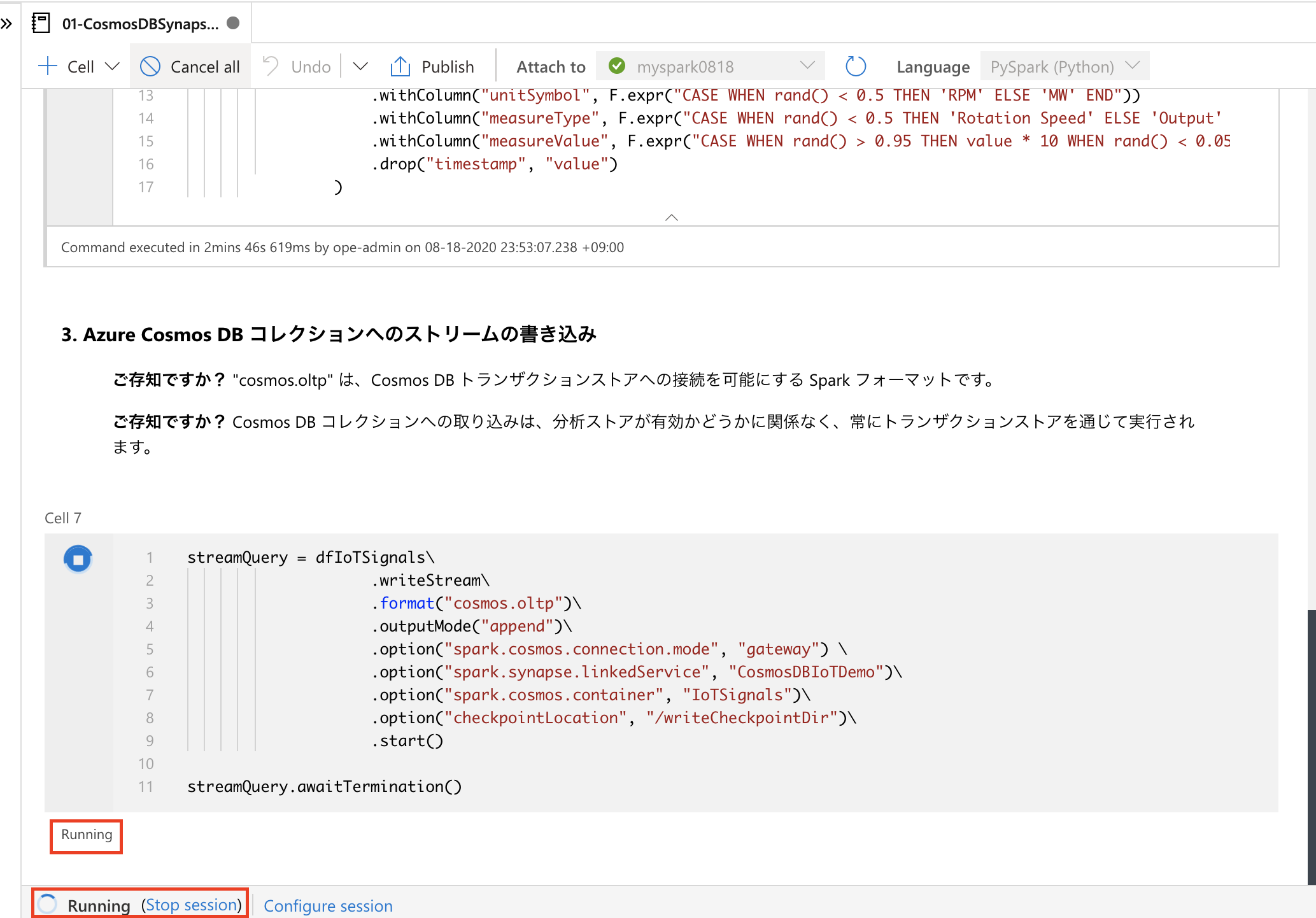
時間が経過したら、Azure Cosmos DB のIoTSignalsコンテナーにデータが投入されたことを確認しましょう。オートスケールの設定も、元に戻して OK です。
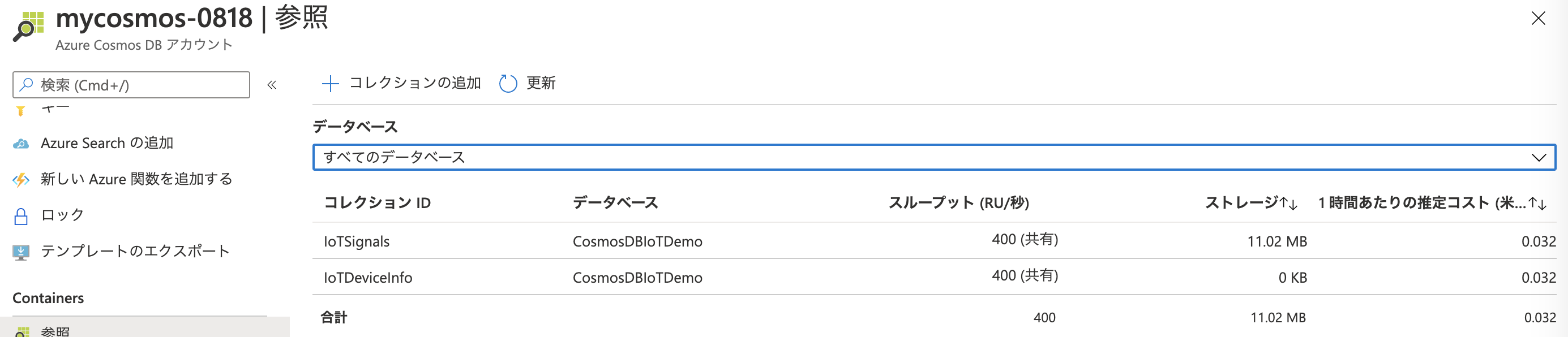
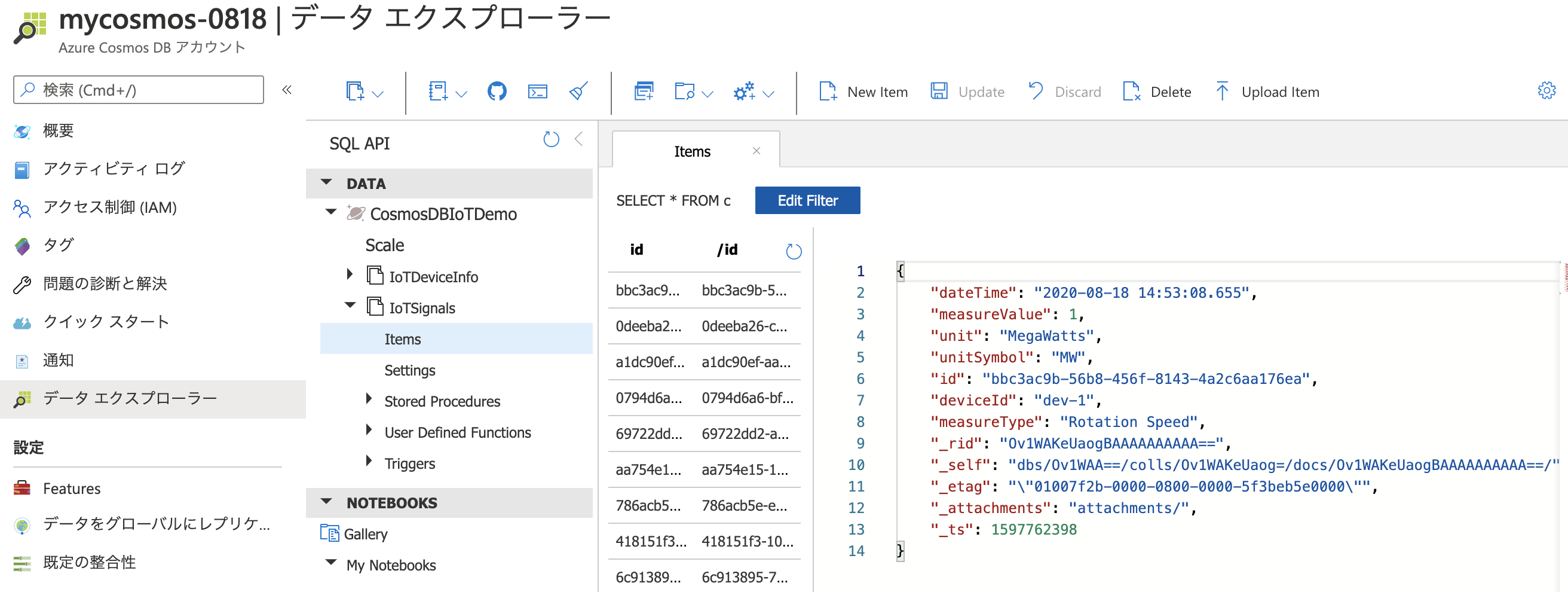
02-CosmosDBSynapseBatchIngestion
次のノートブックです。ここでは、Azure Synapse Spark を使用してバッチデータを Azure Cosmos DB コレクションに取り込むことを行います。
01の時と同様、GitHub 上にあるノートブックを取得して、Azure Synapse ワークスペースにインポートし、実行しましょう。
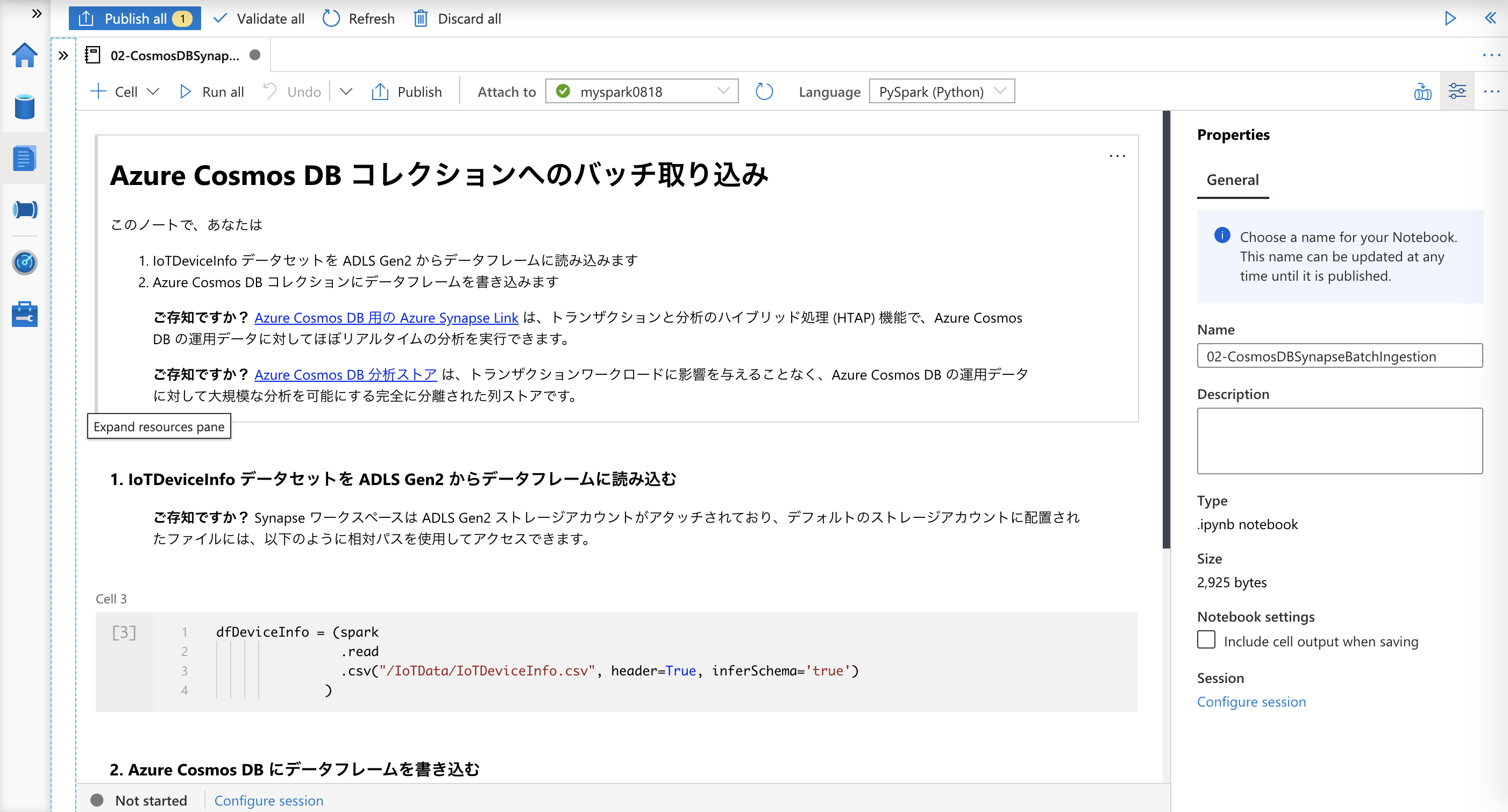
IoTDeviceInfo.csvの中身をみていただければわかると思いますが、データはヘッダー部分を除いて10行分しかありません。そのため、Azure Cosmos DB のオートスケール設定をここでまた元に戻す必要はありません。
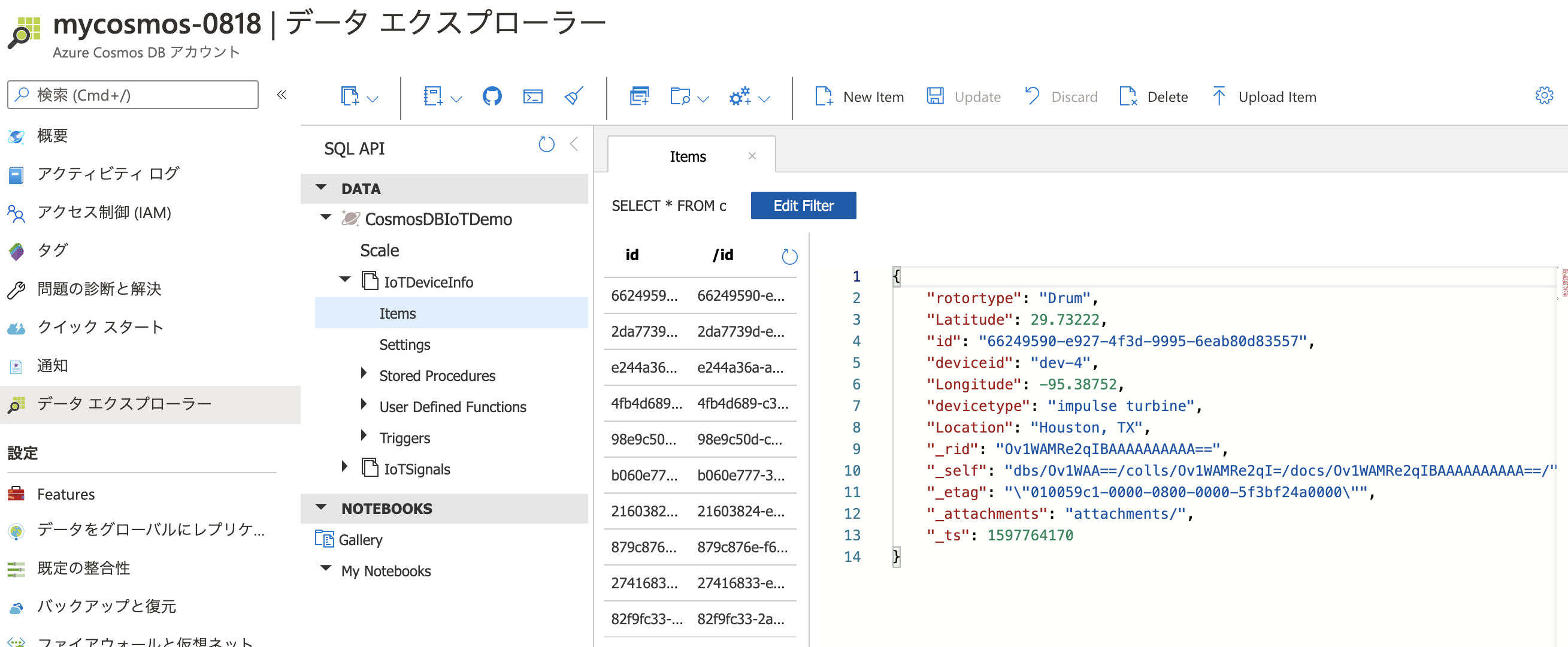
ノートブックの実行が完了したら、Azure Cosmos DB のIoTDeviceInfoコンテナーにデータが投入されたことを確認しましょう。きちんと10行データがあるはずです。
03-CosmosDBSynapseJoins
次のノートブックです。ここでは、Azure Synapse Link を使用して Azure Cosmos DB コレクション全体で結合と集計を実行することを行います。
まずはこれまで同様、GitHub 上にあるノートブックを取得して、Azure Synapse ワークスペースにインポートし、実行していきましょう。
少しここでは解説をします。
これまでは、Azure Synapse ワークスペースにインポートしたノートブックにて、以下のような PySpark を実行し、Azure Cosmos DB のトランザクションストアに書き込むことを行っていました。
streamQuery = dfIoTSignals\
.writeStream\
.format("cosmos.oltp")\
.outputMode("append")\
.option("spark.cosmos.connection.mode", "gateway") \
.option("spark.synapse.linkedService", "CosmosDBIoTDemo")\
.option("spark.cosmos.container", "IoTSignals")\
.option("checkpointLocation", "/writeCheckpointDir")\
.start()
ここで注目したいのは、.format("cosmos.oltp")の部分です。cosmos.oltp は、Azure Cosmos DB トランザクションストアへの接続を可能にします。(ノートブック内の「ご存知ですか?」の部分にも記載していました)
ここからは、Azure Cosmos DB 分析ストアへアクセスしていきます。そのため、cosmos.oltp は使用できません。その代わり、cosmos.olapを使用していきます。
また、このノートブックでは、Azure Cosmos DB 分析ストアのコレクションに紐づく、Spark テーブルを作成します。この Spark テーブルはいわゆるメタデータテーブルであり、Spark SQL のクエリが実行された時に、対応する Azure Cosmos DB 分析ストアのコレクションに対してクエリを渡す役割を持っています。
%%sql
create database CosmosDBIoTDemo
%%sql
create table if not exists CosmosDBIoTDemo.IoTSignals
using cosmos.olap
options(spark.synapse.linkedService 'CosmosDBIoTDemo',
spark.cosmos.container 'IoTSignals')
%%sql
create table if not exists CosmosDBIoTDemo.IoTDeviceInfo
using cosmos.olap
options(spark.synapse.linkedService 'CosmosDBIoTDemo',
spark.cosmos.container 'IoTDeviceInfo')
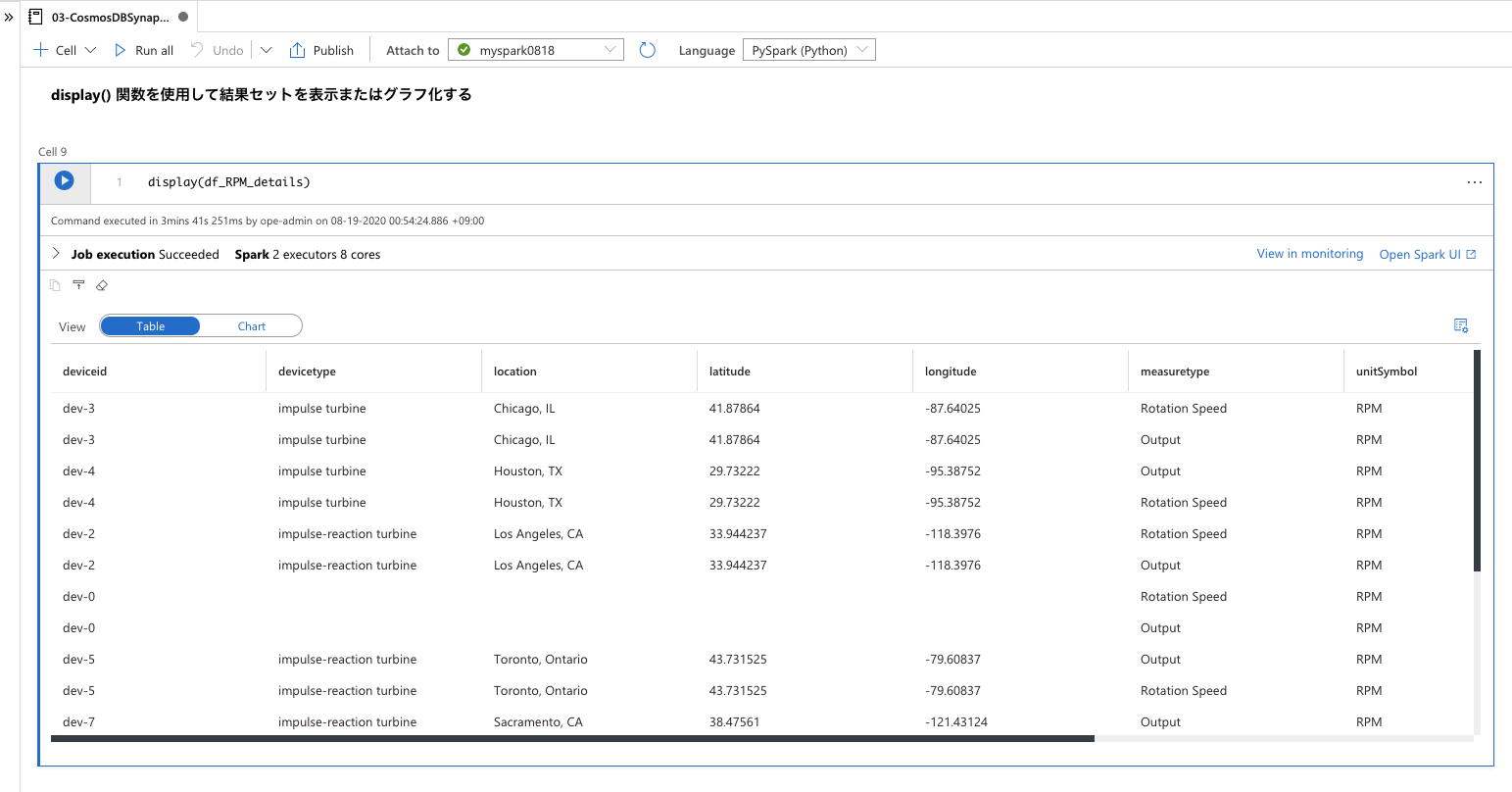
df_RPM_details = spark.sql("select a.deviceid \
, b.devicetype \
, cast(b.location as string) as location\
, cast(b.latitude as float) as latitude\
, cast(b.longitude as float) as longitude\
, a.measuretype \
, a.unitSymbol \
, cast(sum(measureValue) as float) as measureValueSum \
, count(*) as count \
from CosmosDBIoTDemo.IoTSignals a \
left join CosmosDBIoTDemo.IoTDeviceInfo b \
on a.deviceid = b.deviceid \
where a.unitSymbol = 'RPM' \
group by a.deviceid, b.devicetype, b.location, b.latitude, b.longitude, a.measuretype, a.unitSymbol")
なお、Azure Cosmos DB 分析ストアに対するアクセスについては、Azure Cosmos DB のオートスケール設定は関係ありません。オートスケールはトランザクションストアに関するものであり、トランザクションストアと分析ストアのアクセスは区別されています。そのため、ここでも Azure Cosmos DB のオートスケール設定を変更する必要はありません。
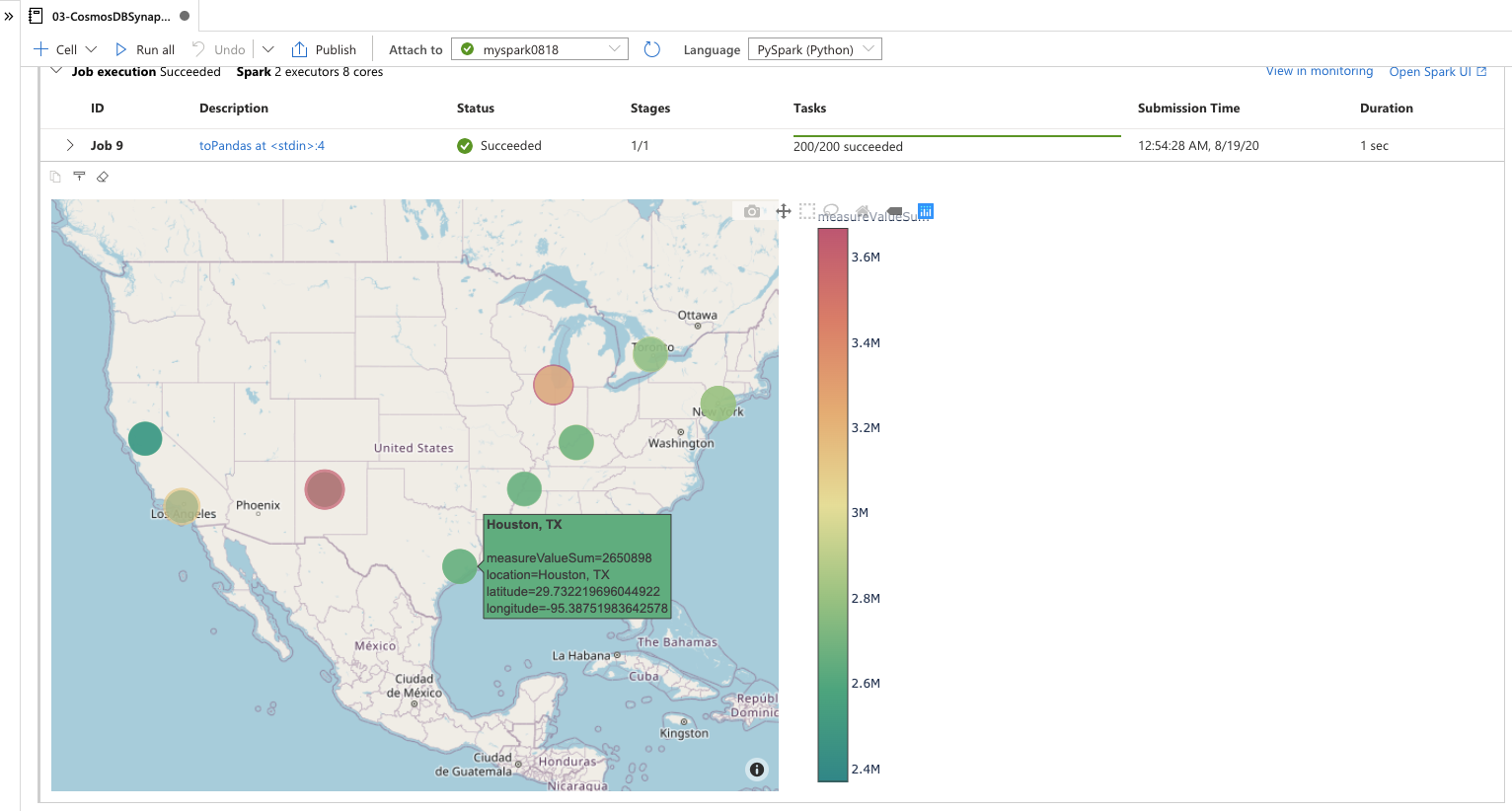
実行が完了すると、Azure Cosmos DB 分析ストアのコレクションから参照したデータ、およびそのデータを用いて plotly で地図にプロットした内容を確認できるはずです。
04-CosmosDBSynapseML
さあ、最後のノートブックです。03では、受信済みの発電所の蒸気タービンからの信号データを取得して、地図にプロットしただけでした。これだけでも大きな成果かもしれませんが、ビックデータの活用としては、もう一歩いきたいところです。
というわけで、最後はSynapse Spark (MMLSpark) で Azure Synapse Link と Azure Cognitive Services を使用して異常検出を実行することを行っていきます。
ノートブックは、これまでと同じく、GitHub 上にあります。インポートしておいてください。
機械学習については触れると記事ボリュームが増大するので、ここでは記載しませんが、ここでは、MMLSpark (Azure Cognitive Services on Spark) を使用しています。
このノートブックの実行には、Cognitive Services の一部である Anomaly Detector API を使用するため、Cognitive Services API アカウントを作成しておく必要があります。(最初の環境構築の時に言おうよ...)
Azure ポータルから、新規作成を行いましょう。Anomaly Detector もポータル上で検索でき、作成することができるようになっていますが、2020/08/18時点では Cognitive Services で作成してください。

Cell 8 にて、自身の Cognitive Services API アカウントのキーを入力する部分があります。.setSubscriptionKey("paste-your-key-here")の paste-your-key-here の部分を、自身のキーに置き換えてください。
from pyspark.sql.functions import col
from pyspark.sql.types import *
from mmlspark.cognitive import SimpleDetectAnomalies
from mmlspark.core.spark import FluentAPI
anomaly_detector = (SimpleDetectAnomalies()
.setSubscriptionKey("paste-your-key-here")
.setUrl("https://westus2.api.cognitive.microsoft.com/anomalydetector/v1.0/timeseries/entire/detect")
.setOutputCol("anomalies")
.setGroupbyCol("grouping")
.setSensitivity(95)
.setGranularity("secondly"))
キーは Azure ポータル上で確認できます。
キーを置き換えたら、ノートブックを実行して、実行結果を確認しましょう。
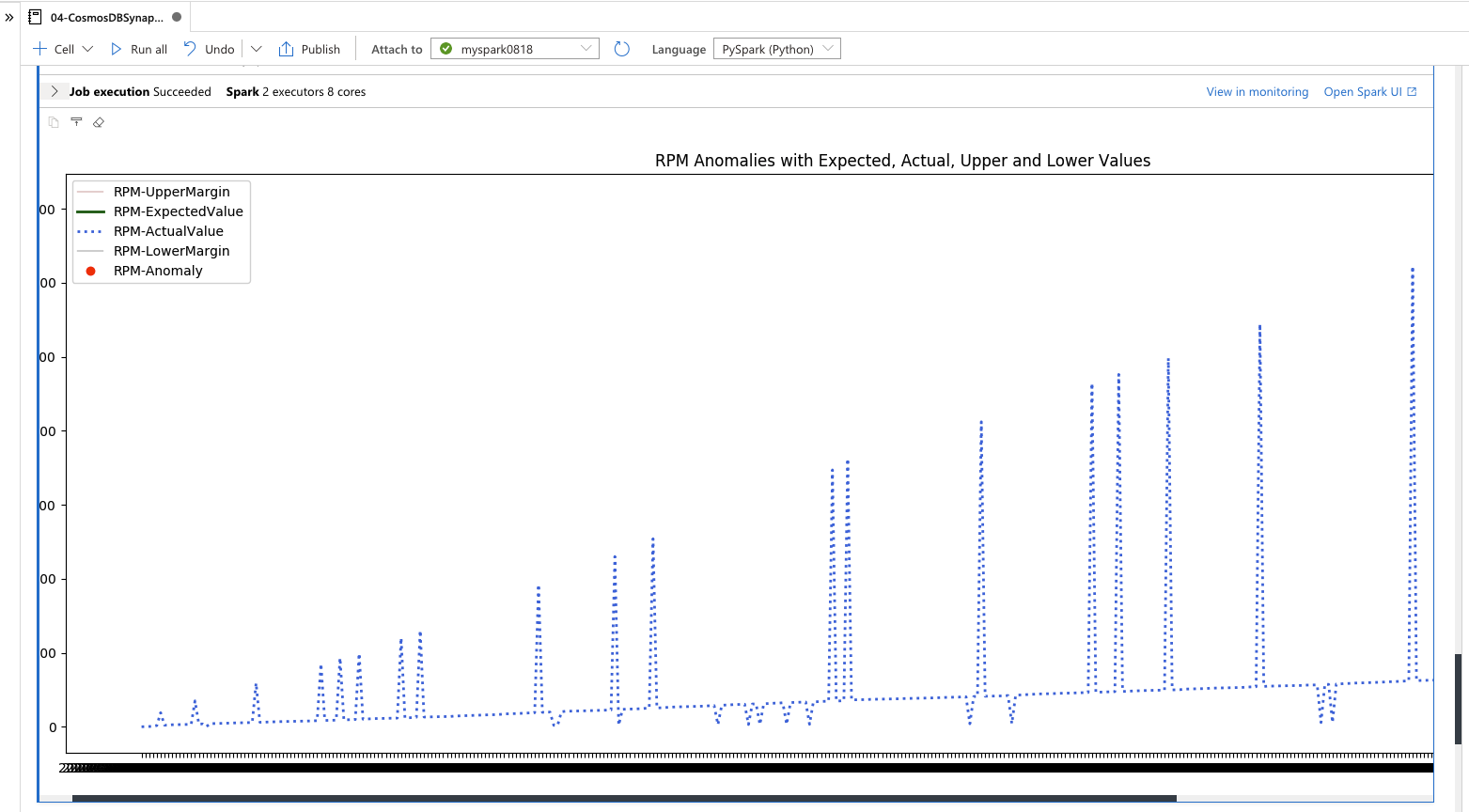
残念ながら、私の環境はデータ不足だったのか、ノートブック内にあるサンプル画像にあるような図にはなりませんでした。データが不足しているのか、内容に偏りがあったみたいです。
是非、あなたの環境でこのデモを実行して、サンプル画像にあるような図を再現できたら、コメントで私に教えてください! (Azure Cosmos DB コンテナーのデータ量などについてお聞きしたいと思っています)
環境のクリーンアップ
デモの実行が終わったら、不要な環境は削除し、課金が行われないようにしましょう。
とは言っても、Azure Cosmos DB はデモ環境のみであれば Free Tier が有効化されており、Azure Synapse workspace も Spark プールはアイドル状態に移行すればコンピューティング課金が止まります。
Azure Synapse ワークスペース自体も使用しなければ、月額で数百円程度の課金です。
他に Azure Cosmos DB アカウントやデータベースを作成することがなければ、後学のために残すのも良いかもしれません。どうするかはお任せです。
ただし、課金体系がいつ変わるかは私にもわからないため、急に高額な請求がくるのがいやであれば、きちんと環境削除しましょう。
クリーンアップ作業の参考情報は、この記事で3回目の登場になる、以下の記事に記載しています。
さいごに
今回、ご紹介および解説を行った GitHub のリポジトリには、もう一つ、Azure Synapse Link for Azure Cosmos DB のデモが収録されています。
興味ある人は、こちらも実践してみてください。
※そのうち、こちらも解説記事を公開すると思います。
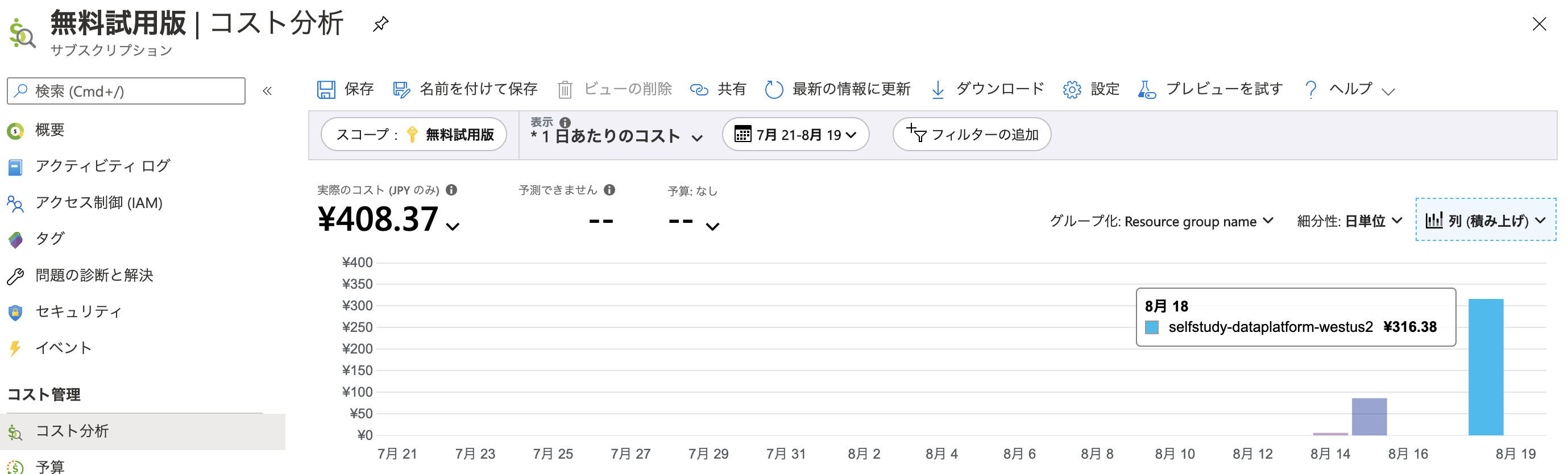
今回のデモ実行にかかった金額
316.38円 でした。
身銭を切れ、ではないですが、300円強で Azure Synapse Link for Azure Cosmos DB について学習できるのであれば、格安ではないでしょうか。
(これは個人的な意見ですが、)お金や時間といった身銭を切らない限り、自分のスキルや知識の向上は難しいです。書籍を1冊購入するよりも安い金額だと思いますので、是非この機会に試してみるといいと思います。