はじめに
MS Build 2020 にて、Azure Cosmos DB のアップデートの1つに Azure Synapse Link for Azure Cosmos DB が発表されました。
今回は、Azure Synapse Link for Azure Cosmos DB の環境を作成して、実際に Azure Synapse ワークスペース上から Azure Cosmos DB のデータを参照できることを確認します。
Azure Synapse Link for Azure Cosmos DB
Azure Synapse Link とは、クラウドネイティブのハイブリッドトランザクションと分析処理 (HTAP) の機能で、Azure Cosmos DB の分析ストア を活用しています。Azure Synapse Analytics の環境から、Azure Cosmos DB の分析ストアに対してリンクサービス(Linked Services)として接続することで、Azure Cosmos DB 上にある運用データに対してほぼリアルタイムの分析を実行できるというものです。
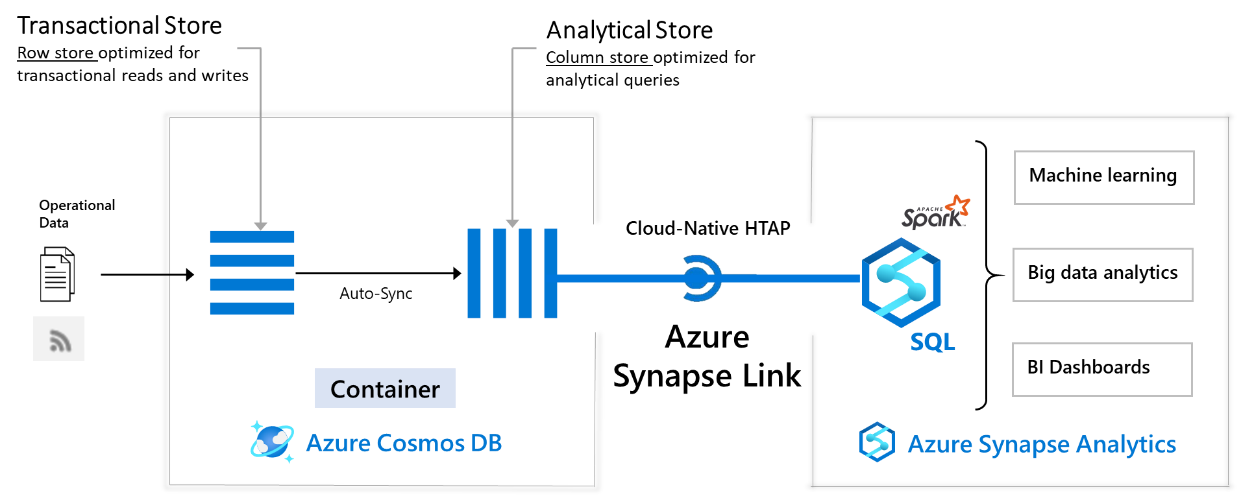
Azure Cosmos DB におけるドキュメントの読み取り/書き込みは、通常トランザクションストア(Transaction Store)とよばれる読み取りおよび書き込みに特化された行ストアの領域で行われます。分析ストア(Analytical Store)は分析クエリに特化された列ストアの領域であり、Azure Cosmos DB 単体でも利用することが可能です。
- 詳細はこちら
分析ストアを有効化すると、5分毎に、トランザクションストアから分析ストアへデータの同期が行われるようになります。分析ストアにかかる料金は、以下のサイトを参照してください。
料金について
Azure Synapse Link for Azure Cosmos DB の場合、2020/8/31 までは無料で試すことができます。 ※2020/08/17現在
無料期間が終了した後は、Azure Synapse Link for Azure Cosmos DB を構成する、以下2つの内容の課金が発生します。
- Azure Cosmos DB: Azure Cosmos DB 分析ストアの利用料
- Azure Synapse Link: SQL プール または Spark プールの利用料
2020/08/17現在で確認できている Azure Cosmos DB 分析ストアの料金体系は以下の通りです。 ※東日本リージョンの場合

分析ストアは、トランザクションストアから同期され分析ストアに保存されているデータの容量(ストレージ)と分析ストアに対するデータの読み取り/書き込みの2つについて課金が発生します。これは、Azure Cosmos DB 自体の課金とは別で行われます。
Azure Synapse Analytics における SQL プール、および Spark プールの料金については、以下を参照してください。
なお、2020/08/17現在、SQL プールを使用した Azure Synapse Link はプライベートプレビューです。Spark プールの利用を検討しましょう。
環境構築
Azure Cosmos DB
以下の記事を参考に、SQL API で Azure Cosmos DB アカウントを作成します。
1点注意点として、Azure Cosmos DB アカウントを作成する際のリージョンは以下のものから選択するようにしてください。
理由は、Azure Synapse ワークスペースが下記のリージョンでのみしか作成できないからです。リージョンを跨いだデータ転送はレイテンシの問題など、通常想定しないので、同じリージョンに作成するようにします。
- オーストラリア東部
- 英国南部
- 西ヨーロッパ
- 東南アジア
- 米国西部2
- 米国中西部
- 米国中南部
- 米国東部
- 米国東部2
Azure Cosmos DB アカウントを作成したら、データベースとコンテナーを作成します。本記事においては、データベースやコンテナー(コレクション)、コンテナー内のデータについては指定しません。好きな値を入れてください。
本記事のサンプルとして、私の好きな Perfume の楽曲データサンプルを投入することにします。
- Database id: Perfume
- Provision throughput: On
- Throughput: 400
- コンテナー名: Songs
- Provision database throughput: On
- Throughput: 400
- Container id: Songs
- Indexing: Automatic
- Partition key: /album/name
- My partition key is larger than 100 bytes: Off
- Analytical store: On
[
{
"no": 1,
"title": "スウィートドーナッツ",
"album": {
"name": "Fan Service ~Prima Box~"
},
"release": 2003
},
{
"no": 2,
"title": "シークレットメッセージ",
"album": {
"name": "Fan Service ~Prima Box~"
},
"release": 2003
},
{
"no": 3,
"title": "ジェニーはご機嫌ななめ",
"album": {
"name": "Fan Service ~Prima Box~"
},
"release": 2003
},
{
"no": 4,
"title": "モノクロームエフェクト",
"album": {
"name": "Fan Service ~Prima Box~"
},
"release": 2004
},
{
"no": 5,
"title": "エレベーター",
"album": {
"name": "Fan Service ~Prima Box~"
},
"release": 2004
}
]
Azure Synapse ワークスペース
以下の記事を参考に環境を作成してください。
Spark プールの作成
Azure ポータル、もしくは Azure Synapse ワークスペースから Spark プールを作成します。
※今回は、Azure Synapse ワークスペースを使用します。
Azure ポータルから作成した Azure Synapse ワークスペースの概要タブに移動し、ワークスペースの Web URL' を選択して Azure Synapse ワークスペースにアクセスします。
Manage / Analytics pools / Apache Spark pools に移動し、+New ボタンを選択し、Spark プールを新規作成します。
- Apache Spark pool name: <任意の名前>
- Autoscale: Enabled
- Node size family: MemoryOptimized
- Node size: Small
- Number of nodes: 3
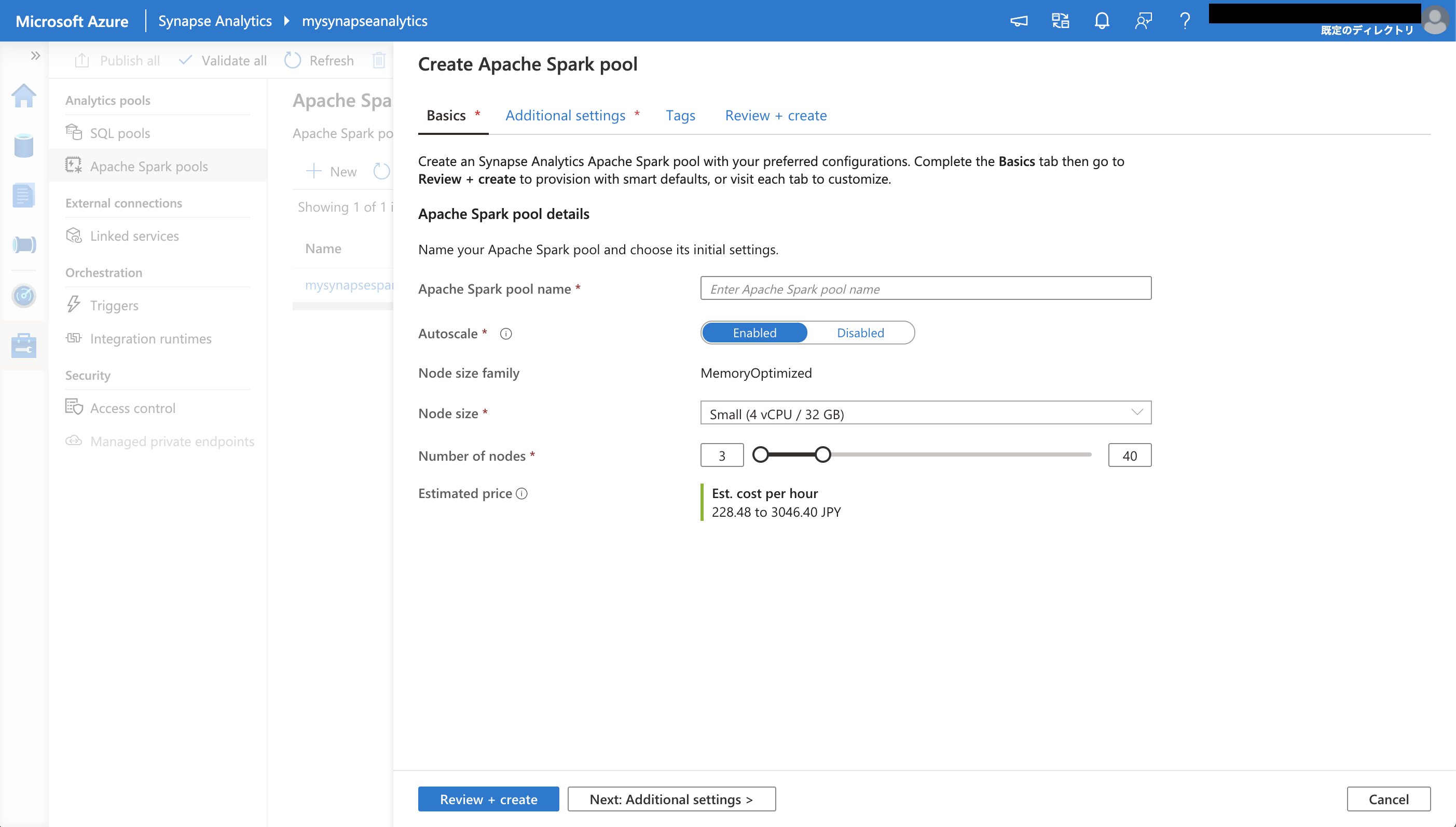
Review + create を選択すると、Spark プールの作成が開始されます。
Azure Synapse Link の設定
2つの環境ができたので、Azure Synapse Link を設定していきます。
まずは、先ほど作成した Azure Cosmos DB アカウントのデータエクスプローラーを表示します。

データエクスプローラーの画面上部に、Enable Azure Synapse Link (preview)のボタンがあります。これを選択します。
Azure Cosmos DB 側の操作はこれだけです! (簡単)
次に、Azure Synapse ワークスペースにて、リンクサービス (Linked Service) の設定を行います。
Azure Synapse ワークスペースにアクセスし、Manage / External connections / Linked services に移動します。
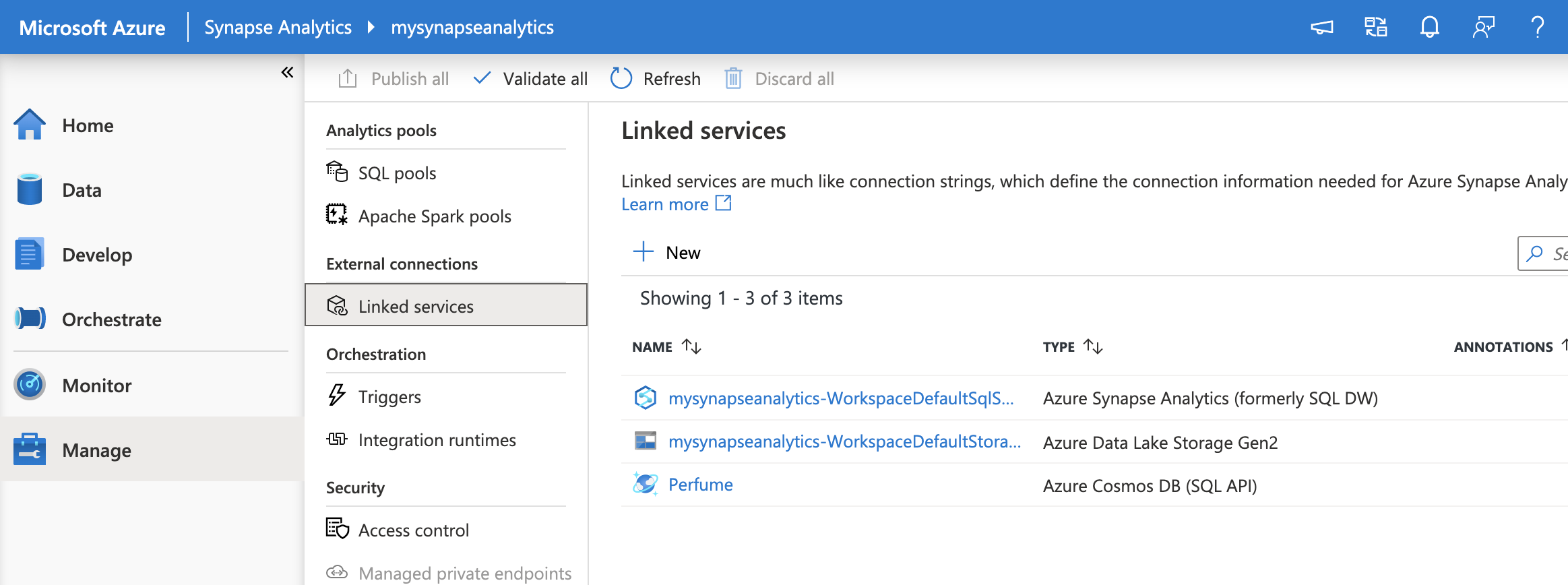
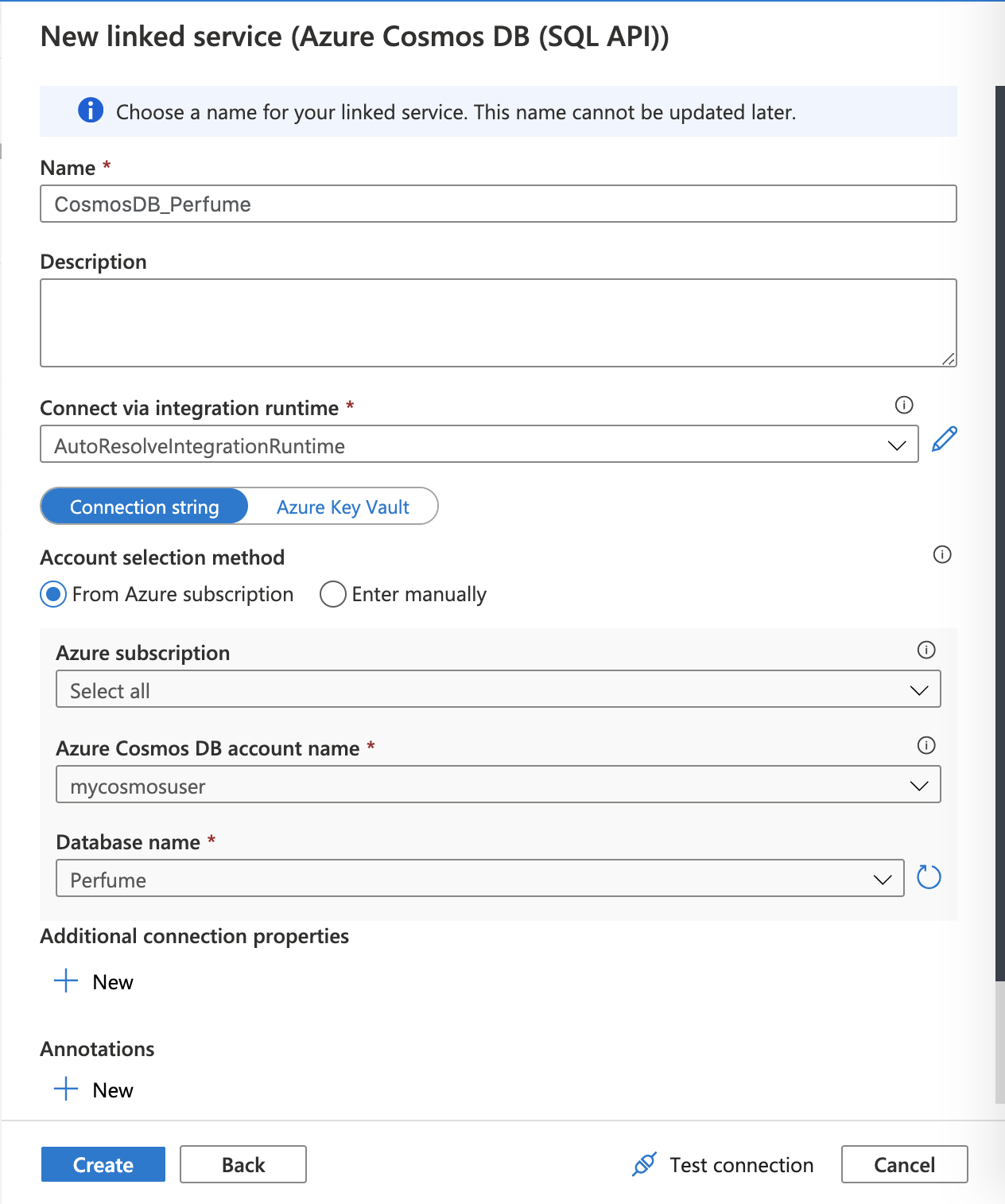
+New ボタンを選択し、New linked service の画面の検索窓にCosmos DBを入力します。
Azure Cosmos DB (SQL API) を選択して、Continue を選択します。
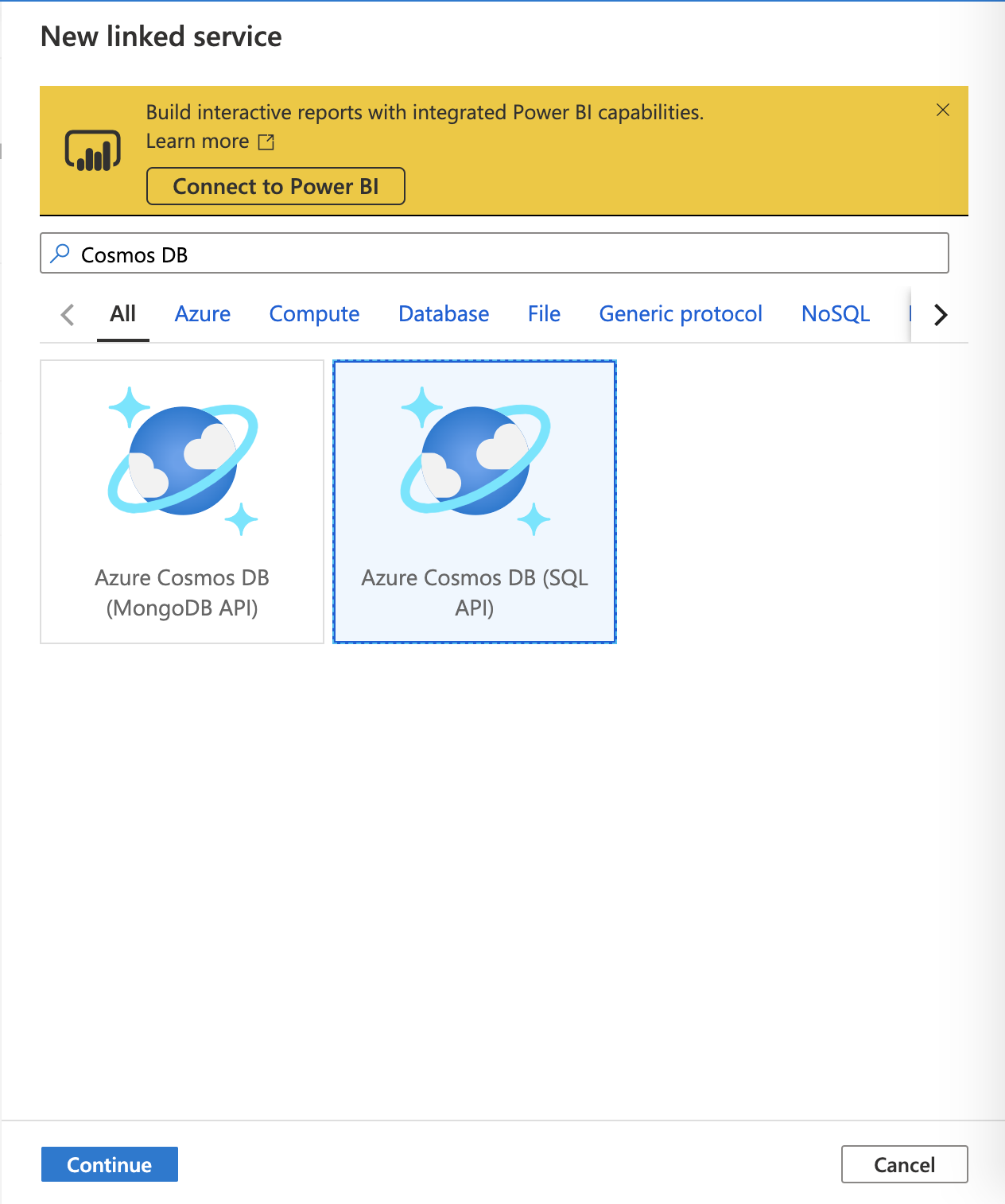
リンクサービスに関する設定値の入力を求められます。名前 (Name) は好きなものを入力してください。
Account sekection method の欄にて、作成した Azure Cosmos DB の値を設定してください。
設定が終わったら、Create ボタンを選択してリンクサービスを作成します。
Azure Cosmos DB 分析ストアに接続
これで、Azure Synapse Link for Azure Cosmos DB として、Azure Cosmos DB 分析ストアにあるデータにアクセスできるようになりました。
実際に PySpark でデータを取得し、データフレームにデータを入れてみましょう。
Azure Synapse ワークスペースにアクセスし、Data / Linked / Azure Cosmos DB タブを確認します。
データベースに存在するコンテナー(コレクション)が表示されるので、右クリック、もしくは Action ボタンを選択し、New notebook / Load to DataFrame を選択します。
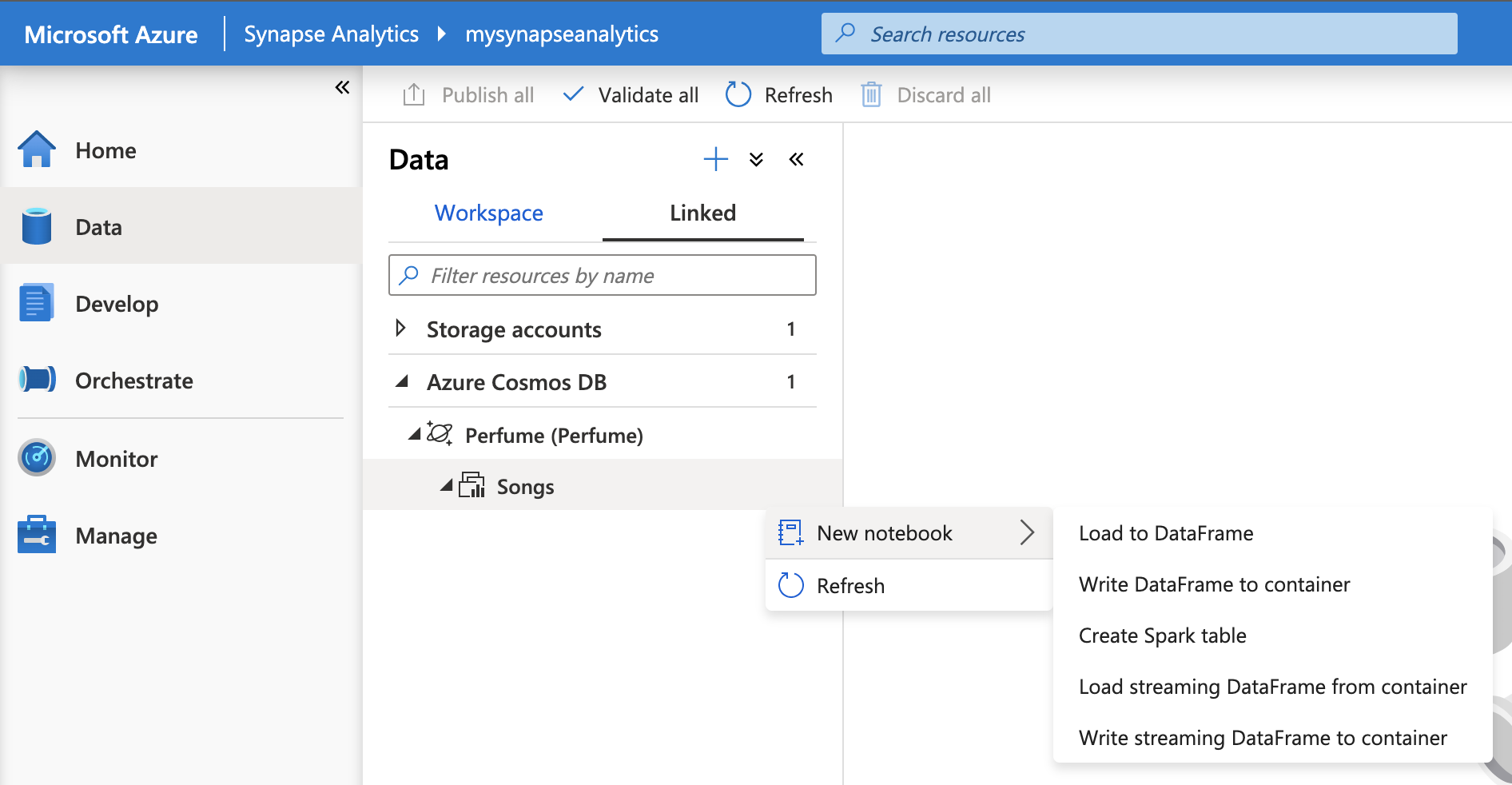
ノートブックが作成されますので、以下の部分を確認しましょう。
- Attach to: 先ほど作成した Spark プール
- Language: PySpark(Python)
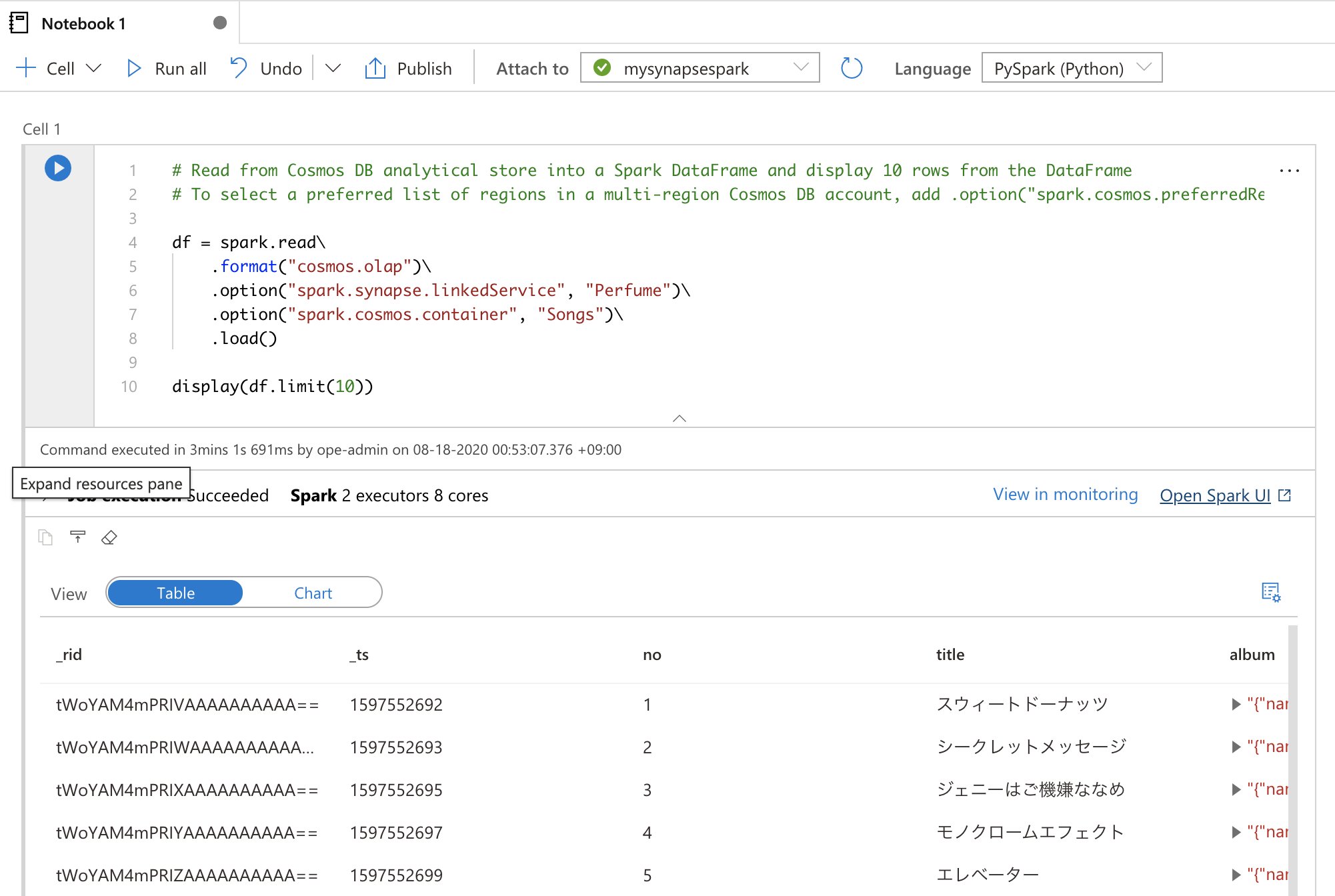
確認できたら、コードは自動で作成されているので、そのままShift+Enterでセル実行しましょう。
Spark プールは、デフォルトで15分未使用の場合、自動でアイドル状態に移行します。そのため、アイドル状態からコードを初回実行をする場合、Spark プールの起動のため、完了までに少し時間がかかります。
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService", "Perfume")\
.option("spark.cosmos.container", "Songs")\
.load()
display(df.limit(10))
処理が正常に完了したら、以下のような出力を確認できるはずです。
さいごに
今回は、Azure Synapse Link for Azure Cosmos DB を実行できる環境を作成し、PySpark にて Azure Cosmos DB のデータを参照できることを確認しました。
この後は、実際に PySpark を使ってデータを加工・分析していくことになります。その話はまた次回にします。