結果から要因を推論する逆推論に拡散モデルを使いたくて、まずは Irisデータセットのデータ生成を試してみました。本記事では、拡散モデルで Irisデータセットの分布を学習しその分布からサンプリングすることでデータを生成します。なお、理論の解説はありません。
実行環境
Google Colab で動作確認しました。軽量なので CPU でも動作します。
使用する Python パッケージ
import os
import math
import time
import random
from typing import List
import torch
import torch.nn.functional as F
from torch import nn
from torch.utils.data import Dataset, TensorDataset, DataLoader
import numpy as np
import pandas as pd
import sklearn.datasets
import sklearn.preprocessing
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import seaborn as sns
Iris データセット
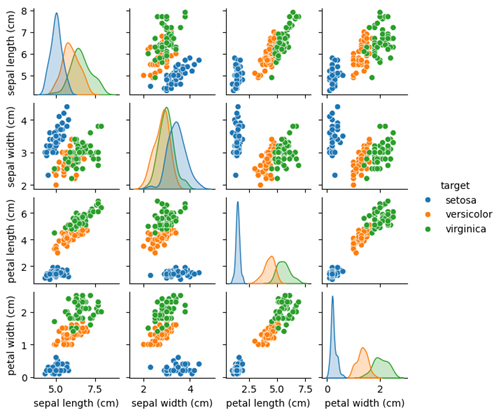
Iris(アヤメの花)データセットは有名なマルチクラス分類データセットです。scikit-learn の load_iris でロードできます。
Irisデータセットを相関行列チャートで確認。
iris = sklearn.datasets.load_iris(as_frame=True)
target = pd.Series(iris.target_names[iris.target], name='target')
df = iris.data.assign(target=target)
g = sns.pairplot(df, hue='target', height=1.5)
plt.show()
ノイズスケジューラ
拡散モデルはノイズを加えて元のデータを破壊します。ノイズスケジューラはその際の信号成分(つまりデータ)の大きさと加えるノイズの大きさを時刻によって制御するためのものです。スケジュールにはシグモイド関数を用います。
class ContinuousNoiseScheduler():
def __init__(self, stop=0.99996, gain=6, shift=0.5, device=None):
"""分散保存型 連続時間シグモイドノイズスケジューラ"""
if device is None:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.device = device
self.stop = stop
self.gain = gain
self.shift = shift
range_t = torch.tensor([0, 1])
y_min, y_max = self.sigmoid(range_t)
self.y_ratio = torch.as_tensor(stop / (y_max - y_min), device=device)
self.y_bias = torch.as_tensor(- self.y_ratio * y_min, device=device)
def gamma(self, t):
return self.gain * ((2 * t - 1) + self.shift)
def sigmoid(self, t):
t = torch.as_tensor(t, device=self.device)
assert torch.all(t >= 0) and torch.all(t <= 1)
y = 1 / (1 + torch.exp(-self.gamma(t)))
return y
def get_alpha_bar(self, t):
"""ノイズ時刻 t の信号成分
Args
t : 時刻 0 <= t <= 1
"""
y = self.sigmoid(t)
beta_bar = self.y_ratio * y + self.y_bias
alpha_bar = 1 - beta_bar
return alpha_bar
ノイズスケジュールを可視化
t = torch.linspace(0, 1, 1000)
alpha_bar = ContinuousNoiseScheduler().get_alpha_bar(t).detach().cpu()
plt.figure(figsize=(3,2))
plt.plot(t, alpha_bar, label='Signal')
plt.plot(t, 1 - alpha_bar, label='Noise')
plt.xlabel('Time')
plt.ylabel('Ratio')
plt.legend()
plt.grid()
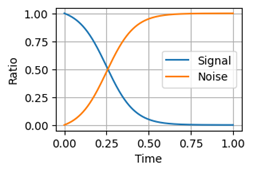
ここで青色の線は信号成分の比率、オレンジ色の線はノイズ成分の比率です。横軸は時間の経過を表し、任意の時刻において信号成分とノイズ成分の比率の合計は1となります。最終的に信号成分はほぼゼロとなりノイズによりデータはほぼ完全に破壊されます。
拡散過程と逆拡散過程
信号成分を減衰させノイズを加えてデータを破壊していくのが拡散過程、ノイズから始めて信号成分を復元していきデータを生成するのが逆拡散過程です。
拡散過程 q_sample() は、元のデータ $x_0$ を減衰させノイズを加えて時刻 t の値 $x_t$ を求めます。
def q_sample(x0, ts, noise_scheduler):
"""Sample q(x_t | x_0)."""
alpha_bar = noise_scheduler.get_alpha_bar(ts)
noise = torch.randn_like(x0) # ノイズ. Normal(0,1)
xt = torch.sqrt(alpha_bar) * x0 + torch.sqrt(1 - alpha_bar) * noise
return xt, noise
逆拡散過程 p_sample() は、拡散過程とは逆にノイズから信号成分を増幅します。時刻 $t$ の値 $x_t$ とモデルで推定したノイズから、少し前の時刻 $s$ の値 $x_s$ を求めます。ここで $s<t$ です。ここでもノイズを加えていますがそれにより多様なサンプルを生成できます。
def p_sample(xt, noise_pred, t, s, noise_scheduler):
"""Sample p(x_{t-1} | x_t)."""
alpha_bar = noise_scheduler.get_alpha_bar(t)
alpha_bar_prev = noise_scheduler.get_alpha_bar(s)
alpha = alpha_bar / alpha_bar_prev
beta = 1 - alpha
beta_bar = 1 - alpha_bar
beta_bar_prev = 1 - alpha_bar_prev
# 期待値
mu = (xt - (beta / torch.sqrt(beta_bar)) * noise_pred) / torch.sqrt(alpha)
# ノイズ
if s > 0:
noise_scale = torch.sqrt(beta * beta_bar_prev / beta_bar)
noise = noise_scale * torch.randn_like(xt, device=xt.device)
else:
noise = 0
# 時刻 s の値
xs = mu + noise
return xs
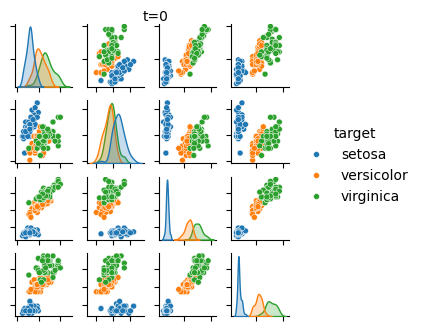
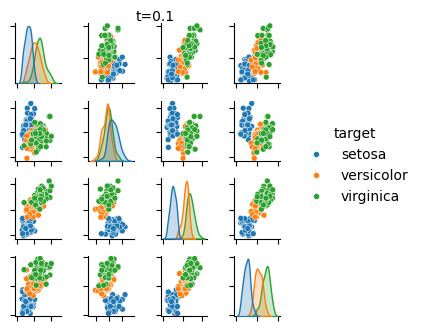
次は、拡散過程で Iris データセットの信号成分が破壊されていく様子です。コードは省略。
初期状態
時刻 t=0.1
時刻 t=0.9
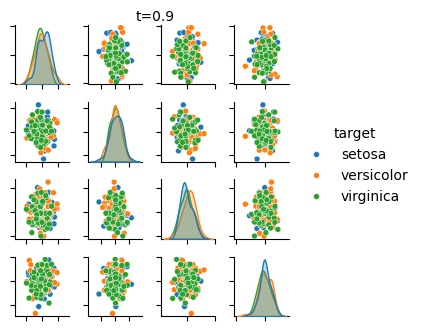
ネットワーク
位置埋め込み
位置埋め込みは、"位置" ではなくノイズスケジュールの "時刻" を埋め込むために使用します。位置埋め込みの詳細は Transformer の位置埋め込み等を参照ください。
class PositionEmbeddings(nn.Module):
def __init__(self, dim: int=10, max_period=10000):
"""位置埋め込み"""
super().__init__()
assert dim % 2 == 0
self.dim = dim
half_dim = dim // 2
progressions = torch.arange(half_dim)
freqs = math.log(10000) / (half_dim - 1)
self.freqs = torch.exp(progressions * -freqs)
def forward(self, t):
device = t.device
if t.ndim >= 2:
t = t.squeeze(dim=-1)
freqs = self.freqs.to(device)
embed = t[:, None] * freqs[None, :]
embed = torch.cat([embed.sin(), embed.cos()], dim=-1)
return embed
残差ブロック
出力値そのものではなく入力値との差分を推定します。
class ResBlock(nn.Module):
def __init__(self, dim, dim_out, bias=True):
"""残差ブロック"""
super().__init__()
self.block1 = nn.Sequential(
nn.Linear(dim, dim_out, bias=bias),
nn.LayerNorm(dim_out),
nn.SiLU(),
)
self.block2 = nn.Linear(dim_out, dim_out, bias=bias)
self.residual = nn.Linear(dim, dim_out, bias=bias) if dim != dim_out else nn.Identity()
def forward(self, x):
h = self.block1(x)
h = self.block2(h)
return h + self.residual(x)
本体
位置埋め込みと入力値の変数の次元を合わせてから加算しその後、デコーダで元の次元へ戻します。
class Network(nn.Module):
def __init__(
self,
in_dim:int,
hidden_dim:int=64,
tm_dim:int=64,
):
super().__init__()
# 時間ステップエンコーダ
self.timestep_encoder = nn.Sequential(
PositionEmbeddings(dim=tm_dim),
nn.Linear(tm_dim, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, hidden_dim)
)
# エンコーダ
self.encoder = nn.Sequential(
nn.Linear(in_dim, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.SiLU(),
nn.Linear(hidden_dim, hidden_dim),
)
# デコーダ
self.decoder = nn.Sequential(
ResBlock(hidden_dim, hidden_dim),
ResBlock(hidden_dim, hidden_dim),
ResBlock(hidden_dim, hidden_dim),
nn.Linear(hidden_dim, in_dim),
)
def forward(self, x, timestep):
# エンコーダ
h = self.encoder(x)
# 時間ステップエンコーダ
tm_emb = self.timestep_encoder(timestep)
h += tm_emb
# デコーダ
h = self.decoder(h)
return h
損失関数
時刻 $t$ をランダムに決定し、q_sample() で時刻 $t$ の値 $x_t$ と加えたノイズを求めます。$x_t$ をネットワークへ入力し、加えたノイズを推定するように学習します。
# 損失関数
def criterion(x0, net, noise_scheduler, device='cpu'):
x0 = x0.to(device)
# ノイズスケジュールの時刻 t. 一様分布 [0,1) to (0,1]
t = 1 - torch.rand(len(x0), 1, device=device)
# ノイズ時刻 t における x の値 xt と加えたノイズ
xt, noise_true = q_sample(x0, t, noise_scheduler)
net.train()
noise_pred = net(xt, t)
loss = F.mse_loss(noise_pred, noise_true, reduction='mean')
return loss
訓練
特筆すべき点はありません。
def train(
dataset,
net,
noise_scheduler,
eval_func=None,
max_epoch=100,
lr=0.001,
batch_size=None,
device=None,
):
# デバイス
if device is None:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if batch_size is None:
batch_size = len(dataset)
# データローダー
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# ネットワーク
net.to(device)
# オプティマイザ
optimizer = torch.optim.AdamW(net.parameters(), lr=lr)
for epoch in range(1, max_epoch+1):
total_loss = 0.
for batch in loader:
optimizer.zero_grad()
loss = criterion(batch, net, noise_scheduler, device=device)
loss.backward()
optimizer.step()
total_loss += loss.item()
total_loss /= len(loader)
if callable(eval_func):
eval_func(epoch=epoch, loss=total_loss)
サンプル生成
初期状態のノイズから時刻をさかのぼり徐々に信号成分を復元していきます。
@torch.no_grad()
def generate_sample(shape, net, noise_scheduler, n_step=1000, device=None):
# デバイス
if device is None:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ネットワーク
net.to(device)
net.eval()
# 初期値
x = torch.randn(shape, device=device)
for step in range(n_step, 0, -1): # step from start_step to 1
# 現在の時刻 t
t = torch.tensor(step / n_step, device=device)
# 1つ前のの時刻 s < t
s = torch.tensor((step - 1) / n_step, device=device)
# ノイズ予測
noise_pred = net(x, t.view(-1, 1))
# 時刻 s の値
x = p_sample(x, noise_pred, t, s, noise_scheduler)
return x.detach()
実行
Irisデータセットを学習し、新たなサンプルを生成します。
target = pd.Series(iris.target_names[iris.target], name='target')
df_org = iris.data.assign(target=target)
# target をダミー変数化
target = pd.get_dummies(target, dtype=np.float32)
x = pd.concat([iris.data, target], axis=1)
# 標準化
scaler = sklearn.preprocessing.StandardScaler()
x = scaler.fit_transform(x)
x = torch.as_tensor(x, dtype=torch.float32)
# ネットワーク
net = Network(in_dim=x.shape[1])
# ノイズスケジューラ
noise_scheduler = ContinuousNoiseScheduler()
# 評価関数
def eval_func(epoch, loss):
if epoch % 100 == 0:
print(f'[{epoch}] Train loss: {loss:.5f}')
# 訓練
train(x, net, noise_scheduler, eval_func=eval_func, max_epoch=5000, lr=0.0003)
# サンプル生成
samples = generate_sample(x.shape, net, noise_scheduler, n_step=1000)
# 標準化の逆変換
samples = scaler.inverse_transform(samples)
df_gen = pd.DataFrame(samples[:, :-3], columns=iris.feature_names)
target = samples[:, -3:]
target = np.argmax(target, 1)
target = pd.Series(iris.target_names[target], name='target')
df_gen = df_gen.assign(target=target)
print('# 元データ')
g = sns.pairplot(df_org, hue='target', hue_order=iris.target_names, height=1.5)
plt.show()
print('# 生成データ')
g = sns.pairplot(df_gen, hue='target', hue_order=iris.target_names, height=1.5)
plt.show()
次図は実行結果です。左側が元のデータ、右側が生成したデータです。
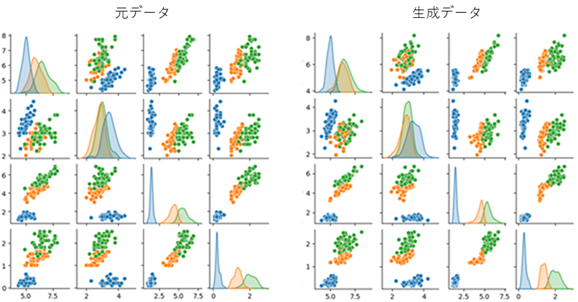
以上です。最後までお読みいただきありがとうございます。
参考文献