はじめに - あなたに最適なWebデータ収集法を見つけよう
「Webページに表示されている、あの情報や画像をまとめて手に入れたい…」
そう感じたことはありませんか?
Webからデータを集める方法は、単純なコピペから高度なプログラムまで様々です。その中でも特に強力なのが「スクレイピング」。これは、プログラムを使ってWebページから情報を自動で抽出する技術のことで、人間がブラウザでページを見る代わりに、プログラムがHTML(Webページの設計図)を読み解き、必要な部分だけを高速に抜き出してくれます。
非常に強力ですが、実施する際はサイトの利用規約やサーバへの負荷に十分配慮する必要があります。
(補足)利用規約に違反すると、サイトへのアクセスがブロックされたり、法的な問題に発展する可能性もあります。必ず事前に確認し、ルールを守って利用しましょう。
この記事では、簡単な手作業から本格的なスクレイピングまで含めた5つの具体的な手法に分類し、あなたの目的やスキルに合った最適なアプローチがわかる「Yes/Noチャート」を用意しました。それぞれのメリット・デメリットを理解し、賢い「武器」を選びましょう。
あなたに最適な方法は?Yes/Noチャートで診断!
それでは、あなたのやりたいことに最適なデータ収集方法をチャートで探してみましょう。

5つの解決策を徹底解説
チャートの結果はいかがでしたか?
ここからは、それぞれの解決策について詳しく見ていきましょう。
【重要】スクレイピングを行う前に
Webサイトから情報を取得する際は、必ずそのサイトの利用規約を確認し、サーバに過度な負荷をかけないよう十分注意してください。ルールを守って、安全に情報を収集しましょう。
🔰 解決策①:手作業(コピペ)
最もシンプルで、誰もが使ったことのある方法です。
- 方法: ブラウザでページを開き、マウスとキーボードでコピー&ペーストします
- 長所: 特別な知識は不要。すぐに実行できます
- 短所: 時間がかかり、量が多いとミスも発生しやすくなります
- 最適な場面: 取得したいデータが数件〜数十件程度で、一度きりの作業
💾 解決策②:Webページ保存
手動と自動の「いいとこ取り」とも言える手法で、手動でログイン認証を回避した状態で、Webページの完全なローカルコピーを作成できます。
この方法では、まずブラウザの機能を使ってWebページを丸ごと保存します。操作は簡単ですが、保存形式の選択が重要です。
【手順】
-
ブラウザで目的のページを開き、右クリックメニューから「名前を付けて保存」を選択します
-
「ファイルの種類」で「Webページ、完全 (*.htm; *.html)」を選んで保存します
- こうすることで、表示されているテキストだけでなく、ページ内の画像ファイルなども
(保存名)_filesというフォルダにまとめてダウンロードされます
- こうすることで、表示されているテキストだけでなく、ページ内の画像ファイルなども
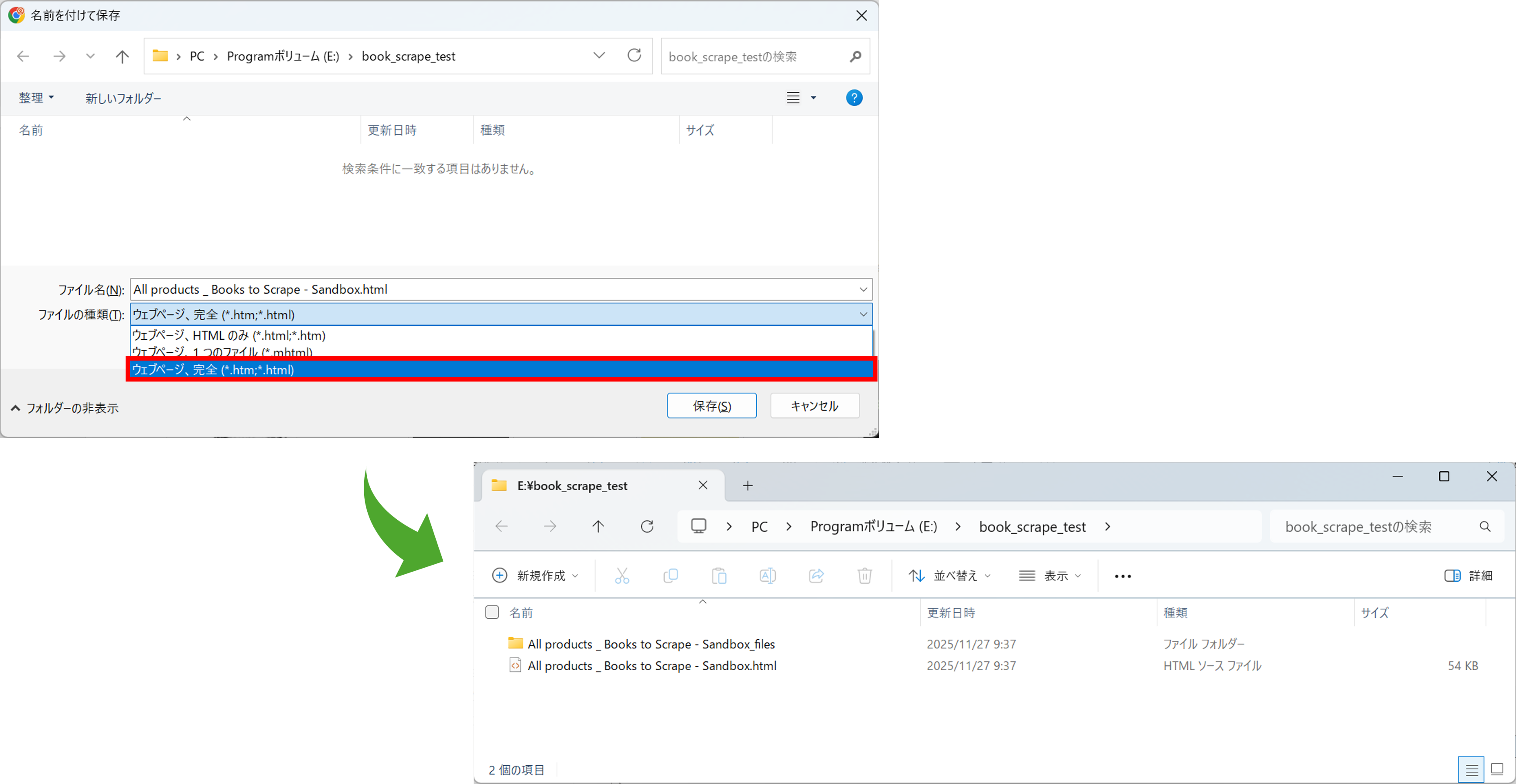
これで、Webページ本体(HTMLファイル)と、そこに含まれる画像などのファイル(filesフォルダ)を丸ごと手元に保存できました。
-
長所:
- 複雑なログイン認証(SSOなど)が必要なサイトでも、手動ログインで回避できます
- サーバに負荷をかけずに、安全にデータを収集できます
- ページ内の画像やCSSファイルなどを一括でダウンロードできます(「ウェブページ、完全」の場合)
- 短所: 毎回手動で保存する手間が残ります
- 最適な場面: 社員名簿の顔写真一覧など、ログイン保護されたページから大量の画像や情報を収集したい場合
🧩 解決策③:ブラウザ拡張機能
プログラミング不要で、定型的なデータ収集を自動化できる便利なツールです。
- 方法: Chromeウェブストアなどから、目的に合った拡張機能(例: Scraper, Instant Data Scraper, Image Downloaderなど)をインストールして利用します
-
長所:
- プログラミング知識が不要で、インストールすればすぐに使えます
- 定型的な作業であれば、手作業より大幅に効率化できます
-
短所:
- 機能が拡張機能に依存するため、細かいカスタマイズはできません
- 特定のサイトやHTML構造でしか動作しない場合があります
- 最適な場面: プログラミングはしたくないが、ECサイトの商品リストや検索結果一覧など、単純なコピペ作業は効率化したい場合
🔥 解決策④:HTML解析によるスクレイピング(Beautiful Soupなど)
Webサーバから直接HTMLを取得し、その中身を解析するスクレイピング手法です。主に「静的サイト」向けで、古典的かつ高速に動作します。
-
方法: プログラムでWebページのHTMLを取得し、そのHTMLを解析するライブラリを使って情報を抽出します。(例: Pythonでは
requestsで取得し、Beautiful Soupで解析するなど、各言語に同様のライブラリがあります) -
長所:
- 非常に高速に動作する
- プログラムの構造が比較的シンプル
-
短所:
- Webサーバから最初に送られてくるHTMLに含まれていないコンテンツは取得できない。
- 最適な場面: ニュースサイト、ブログ、天気予報など、ページを開いた時点で全ての情報が表示されているサイトの定期的な情報収集
【補足】チャートの「ページを開いたときに、すべての情報が見えているか?」の判断基準
この質問は、Webページが「静的」か「動的」かを見分けるための、簡単な目安です。
- Yes(静的): ページを開いた最初のHTMLに、全ての情報が含まれている場合です。
Beautiful Soupが得意なのはこちらです- No(動的): 「もっと見る」ボタンのクリック、下へのスクロール(無限スクロール)、メニューの選択といったユーザーの操作によってはじめて表示される情報がある場合です。
Beautiful Soupではこれらの情報は取得できないため、次の「解決策⑤」の出番となります
【注意】サーバ負荷への配慮
この方法は非常に高速なため、短時間に連続してアクセスするとサーバーに負荷をかける可能性があります。もし複数ページを巡回するような処理を行う場合は、time.sleep(1)のように意図的な待ち時間を設けるなど、サーバーへの配慮を怠らないようにしましょう。
🚀 解決策⑤:ブラウザ操作によるスクレイピング(Selenium/Playwrightなど)
人間と同じようにブラウザを操作することで情報を取得するスクレイピング手法です。ログインが必要なサイトの自動化における、現代のスタンダードと言える最も強力な手法です。
-
方法:
SeleniumやPlaywrightといったツールを使い、プログラムでブラウザ(Chromeなど)を実際に動かす。ID/PWの入力、ボタンのクリック、スクロールといった操作を自動化できる -
長所:
- ログインが必要なサイトに確実に対応できる
- ユーザーの操作(クリック、スクロール等)によって動的に生成されるコンテンツも取得可能
- 人間が見ている画面とほぼ同じ状態から情報を取得できるため、最も確実性が高い
-
短所:
- 実際のブラウザを動かすため、処理速度は④に比べて遅くなる
- 環境構築やコードがやや複雑になる
-
最適な場面:
- ID/PWでのログインが必要なWebサービス
- 無限スクロールやボタンクリックで情報が追加される、現代的なWebアプリケーション(SPAなど)
【注意】サーバ負荷への配慮
この方法はブラウザを操作するため、本質的に解決策④より低速です。しかし、それでも自動で高速にページ遷移を繰り返せば、サーバの負荷となります。ページ遷移やクリックの合間には、time.sleep(1)のように、操作の間に1秒以上の待ち時間を設けることを心がけましょう。これは、サイトへの配慮だけでなく、ページの表示を待つことでプログラムが安定する、というメリットもあります。
【実践】Pythonサンプルコード
ここでは、具体的なPythonコードを見ていきましょう。
解決策②と解決策④の簡単なサンプルをご紹介します。
解決策②:Webページ保存(ウェブページ、完全)の実装サンプル
Webページ保存機能を使えば、HTMLファイルと画像などの関連ファイルを一括で手元に置くことができますが、そのままだと目的の画像を探しにくかったり、ファイル名が分かりづらかったりすることがあります。
そこで、手動で保存したHTMLファイルと、それに付随する画像フォルダから、必要な画像ファイル名(本のタイトルなど)をHTMLから抽出し、整理してコピーするPythonコードを紹介します。
ここでは、先ほどの【手順】の画像でも例として使用した、スクレイピング練習用サイト「Books to Scrape」のトップページを保存した、という想定で進めます。
semi_auto.py
import os
import shutil
from bs4 import BeautifulSoup
import re
from urllib.parse import urljoin
# --- 設定 ---
# ここをあなたの環境に合わせて変更してください。
# HTMLファイルと、それに付随する画像フォルダ(例: "Books to Scrape_files")が
# 置かれている親ディレクトリのパスを指定します。
base_dir = r"E:\\book_scrape_test"
# 解析対象のHTMLファイル名。
# ブラウザで「Webページ、完全」形式で保存したファイル名に合わせてください。
html_filename = "All products _ Books to Scrape - Sandbox.html"
# 画像ファイルが格納されているディレクトリ名。
# HTMLファイル保存時に自動生成される「(HTMLファイル名)_files」形式のフォルダ名です。
img_dir_name = "All products _ Books to Scrape - Sandbox_files"
# 抽出した画像を保存する出力先ディレクトリ名。
output_dir_name = "output_book_covers"
# ----------------
# 各種パスを構築
# HTMLファイルの完全なパス
html_path = os.path.join(base_dir, html_filename)
# 画像フォルダの完全なパス
img_dir = os.path.join(base_dir, img_dir_name)
# 出力ディレクトリの完全なパス
out_dir = os.path.join(base_dir, output_dir_name)
# 出力先ディレクトリが存在しなければ作成
os.makedirs(out_dir, exist_ok=True) # exist_ok=True で既に存在してもエラーにならない
# HTMLファイルを読み込んでBeautiful Soupでパース(解析)
try:
# 'utf-8'エンコーディングでHTMLファイルを読み込む
with open(html_path, "r", encoding="utf-8") as f:
soup = BeautifulSoup(f, "lxml") # 'lxml'パーサーは高速でおすすめ
except FileNotFoundError:
print(f"エラー: HTMLファイルが見つかりません。パスを確認してください: {html_path}")
exit() # ファイルが見つからない場合はスクリプトを終了
# <article class="product_pod"> タグをすべて取得
# 各書籍の情報(画像、タイトル、価格など)はこのタグ内に含まれています
book_articles = soup.find_all("article", class_="product_pod")
# 書籍情報が見つからなかった場合のチェック
if not book_articles:
print("エラー: 書籍情報を含む<article class='product_pod'>タグが見つかりませんでした。HTMLの構造を確認してください。")
exit()
print(f"{len(book_articles)} 件の書籍を検出しました。")
count = 0
# 各書籍情報(<article>タグ)をループ処理
for article in book_articles:
# 書籍の表紙画像を示す <img> タグを探す
img_tag = article.find("img")
# 書籍タイトルを示す <h3> タグの中の <a> タグを探す
title_tag = article.find("h3").find("a")
# <img>タグまたはタイトル<a>タグが見つからない場合はスキップ
if not (img_tag and title_tag):
continue
# 画像の相対パス (src属性) と書籍タイトル (title属性) を取得
src_path = img_tag.get("src")
book_title = title_tag.get("title")
# src_pathまたはbook_titleが取得できない場合はスキップ
if not (src_path and book_title):
continue
# ファイル名としてWindowsで使えない文字(\ /* ? : " < > |)を削除・置換
# これにより、安全なファイル名を作成します
safe_filename = re.sub(r'[\\/*?:\"<>|]', "", book_title).strip()
# 元となる画像ファイルのフルパスを構築
# "src_path"は"./All products _ Books to Scrape - Sandbox_files/xxx.jpg"のような相対パス形式のため、
# os.path.normpathを使ってパスを正規化し、正確なファイルパスを生成します。
original_img_path = os.path.normpath(os.path.join(img_dir, src_path))
# コピー先のファイルパスを構築 (拡張子は元のファイルに合わせる)
_, ext = os.path.splitext(original_img_path) # 拡張子を取得(例: .jpg)
output_filename = f"{safe_filename}{ext}" # 拡張子付きのファイル名を生成
output_img_path = os.path.join(out_dir, output_filename) # 出力ディレクトリとファイル名を結合
# 画像ファイルをコピー
if os.path.exists(original_img_path):
shutil.copy2(original_img_path, output_img_path) # ファイルのメタデータもコピー
print(f"コピー完了: {output_filename}")
count += 1
else:
# original_img_pathでファイルが見つからない場合、
# src_pathが単なるファイル名(パス情報を含まない)である可能性も考慮し、
# 画像フォルダ直下のファイルとして再度試します(フォールバック処理)。
fallback_path = os.path.join(img_dir, os.path.basename(src_path))
if os.path.exists(fallback_path):
shutil.copy2(fallback_path, output_img_path)
print(f"コピー完了 (Fallback): {output_filename}")
count += 1
else:
print(f"警告: 画像ファイルが見つかりません: {original_img_path} または {fallback_path}")
print(f"\n処理が完了しました。{count} 件の画像をコピーしました。")
実行結果のイメージ
スクリプトの実行によって、何がどのように変わるのかを見てみましょう。
1. 実行前のファイル構成 (Before)
スクリプトを実行する前は、手動で保存したHTMLファイルと画像フォルダが存在します。
E:\book_scrape_test (base_dirで指定したパス)
├─ All products _ Books to Scrape - Sandbox.html
├─ All products _ Books to Scrape - Sandbox_files
│ ├─ 09a3aef48557576e1a85ba7efea8ecb7.jpg
│ ├─ 0bbcd0a6f4bcd81ccb1049a52736406e.jpg
│ └─ ... (たくさんの書籍画像ファイル)
└─ semi_auto.py
2. 実行ログ (Process)
この状態でスクリプトを実行すると、ターミナルには以下のようなログが出力されます。
$ python semi_auto.py
20 件の書籍を検出しました。
コピー完了 (Fallback): A Light in the Attic.jpg
コピー完了 (Fallback): Tipping the Velvet.jpg
コピー完了 (Fallback): Soumission.jpg
...
処理が完了しました。20 件の画像をコピーしました。
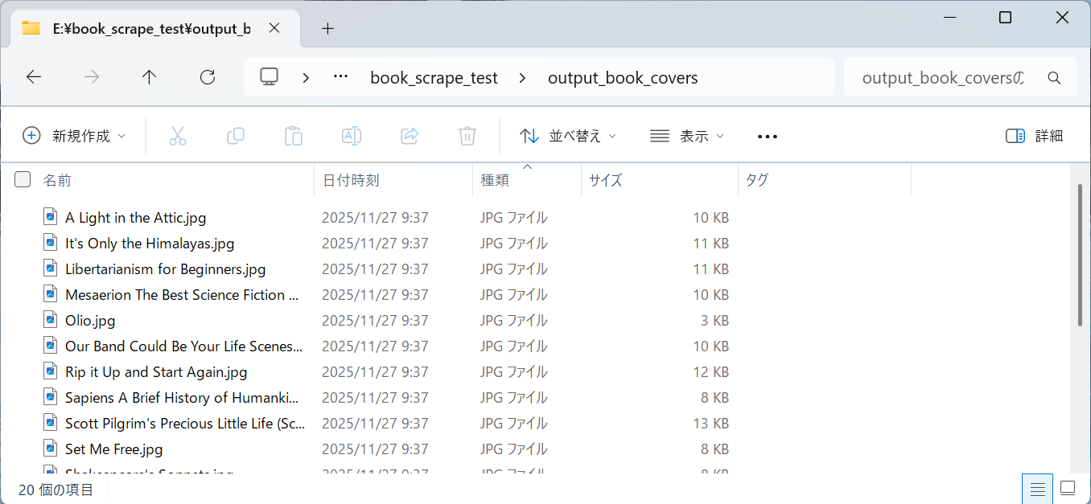
3. 実行後の生成フォルダ (After)
実行が完了すると、新しく output_book_covers フォルダが作成され、その中に h3 > a タグの title 属性(書名)を使ってリネームされた画像ファイルが格納されます。
解決策④:HTML解析によるスクレイピング(Beautiful Soup)の実装サンプル
full_auto_sample.py
# ライブラリのインポート
import requests # Webページにアクセスするため
from bs4 import BeautifulSoup # HTMLを解析するため
import csv # CSVファイルに書き出すため
import time # サーバに負荷をかけないよう待機するため
import re # テキスト整形(注釈削除など)のため
# --- 設定 ---
# スクレイピング対象のURL (Wikipedia: 都道府県の人口一覧)
TARGET_URL = "https://ja.wikipedia.org/wiki/都道府県の人口一覧"
# 出力するCSVファイル名
OUTPUT_CSV_FILE = "prefectures.csv"
# ----------------
def fetch_html(url):
"""
指定されたURLからHTMLコンテンツを取得する関数。
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
print(f"Webページを取得中: {url}")
try:
# WebページにGETリクエストを送信
response = requests.get(url, headers=headers)
# 200 OK以外のステータスコード(404, 403など)の場合にエラーを発生させる
response.raise_for_status()
# 文字化けを防ぐため、エンコーディングを正しく設定してテキストを返す
response.encoding = response.apparent_encoding
return response.text
except requests.exceptions.RequestException as e:
print(f"エラー: HTMLの取得に失敗しました。 {e}")
return None
def parse_and_extract_table(html):
"""
HTMLコンテンツを解析し、目的のテーブルからヘッダーとデータ行を抽出する関数。
"""
print("HTMLを解析し、テーブルデータを抽出中...")
# BeautifulSoupオブジェクトを作成し、HTMLを解析
soup = BeautifulSoup(html, "html.parser")
# <table class="wikitable"> を探し出す
table = soup.find("table", class_="wikitable")
if not table:
print("エラー: 対象のテーブルが見つかりませんでした。")
return None, None
# --- ヘッダー行の抽出 ---
# ユーザーの指定に基づき、tbodyの最初のtrからthをすべて取得する
headers = []
first_row = table.find("tbody").find("tr")
if first_row:
headers = [header.get_text(strip=True) for header in first_row.find_all("th")]
if not headers:
print("エラー: ヘッダーが見つかりませんでした。テーブル構造を確認してください。")
return None, None
# --- データ行の抽出 ---
rows_data = []
# <tbody>内のすべての<tr>タグをループ処理する
for row in table.find("tbody").find_all("tr"):
row_cells = []
# 1. 順位列の処理: 行のヘッダーである<th>タグからテキストを取得
rank_th = row.find("th")
if rank_th:
row_cells.append(rank_th.get_text(strip=True))
# <td>タグをすべて取得
td_elements = row.find_all("td")
if not td_elements:
continue # データセルがない行はスキップ(ヘッダー行など)
# 2. 都道府県列の処理: 最初の<td>内の<span class="sorttext">から取得
prefecture_td = td_elements[0]
prefecture_span = prefecture_td.find("span", class_="sorttext")
if prefecture_span:
row_cells.append(prefecture_span.get_text(strip=True))
else:
# spanがない場合 (例: 全国合計の行) は、tdのテキストをそのまま使用
row_cells.append(prefecture_td.get_text(strip=True))
# 3. それ以降のデータ列の処理: 2番目以降の<td>のテキストを順番に取得
for cell in td_elements[1:]:
# 注釈(例: [注 1])を正規表現で除去して、セルテキストを整形
cell_text = re.sub(r'\[.*?\]', '', cell.get_text(strip=True))
row_cells.append(cell_text)
# 抽出した行データをリストに追加
rows_data.append(row_cells)
return headers, rows_data
def save_to_csv(headers, rows, filename):
"""
抽出したヘッダーとデータ行を、指定されたファイル名のCSVファイルに保存する関数。
"""
print(f"データをCSVファイルに書き込み中: {filename}")
try:
# CSVファイルを書き込みモードで開く
# newline="" は、書き込み時に不要な空行が入るのを防ぐ
# encoding="utf-8-sig" は、Excelで開いた際の文字化けを防ぐ
with open(filename, "w", newline="", encoding="utf-8-sig") as f:
# csv.writerオブジェクトを作成
writer = csv.writer(f)
# 1行目: ヘッダーを書き込み
writer.writerow(headers)
# 2行目以降: データ行をすべて書き込み
writer.writerows(rows)
print(f"CSVファイルの保存が完了しました: {filename}")
except IOError as e:
print(f"エラー: ファイルの書き込みに失敗しました。 {e}")
def main():
"""
メインの処理を実行する関数。
HTMLの取得、解析、CSV保存の一連の流れを管理する。
"""
# 1. WebページからHTMLを取得
html = fetch_html(TARGET_URL)
if not html:
return
# 2. HTMLを解析してテーブルデータを抽出
headers, rows = parse_and_extract_table(html)
if not headers or not rows:
return
# 3. 抽出したデータをCSVファイルに保存
save_to_csv(headers, rows, OUTPUT_CSV_FILE)
# このスクリプトが直接実行された場合にのみ、main()関数を呼び出す
if __name__ == "__main__":
main()
実行結果
このスクリプトを実行すると、ターミナルに処理の進捗が表示され、最終的にCSVファイルが生成されます。
実行ログ
$ python full_auto_sample.py
Webページを取得中: https://ja.wikipedia.org/wiki/都道府県の人口一覧
HTMLを解析し、テーブルデータを抽出中...
データをCSVファイルに書き込み中: prefectures.csv
CSVファイルの保存が完了しました: prefectures.csv
生成された prefectures.csv の中身(一部抜粋)

※補足: 上記のコードは、対象WebページのHTML構造に強く依存します。もしサイトのデザインが変更されると、コードが動作しなくなる可能性があります。情報を正確に取得するためには、ブラウザの開発者ツールなどを使い、目的のデータが含まれるタグ(例:<div>や<span>、<table>など)を特定する必要があります。
【重要】 スクレイピングを行う際は、技術的な側面だけでなく、サイトの利用規約を必ず確認し、ルールを遵守することが重要です。
まとめ
今回は、Webデータ収集の5つの手法を、Yes/Noチャートを交えてご紹介しました。
| 手法 | 特徴 | 最適な場面 |
|---|---|---|
| ① 手作業 | シンプル、知識不要 | 少量の単発作業 |
| ② Webページ保存 | ログイン後もOK、安全 | 手動実行での、複雑な情報・画像収集 |
| ③ ブラウザ拡張機能 | プログラミング不要、手軽 | 手動実行での、単純な一覧・表の収集 |
| ④ HTML解析(Beautiful Soup) | 高速、軽量 | 完全自動での、静的サイトからの収集 |
| ⑤ ブラウザ操作(Selenium) | 強力、万能 | 完全自動での、動的・ログイン必須サイトからの収集 |
「自動化」と聞くと、つい④HTML解析や⑤ブラウザ操作のような「完全自動」のシステムを目指したくなりますが、常にそれが最善とは限りません。開発コスト、利用頻度、セキュリティなどを総合的に考え、時には②Webページ保存や③ブラウザ拡張機能のような「半自動」のアプローチこそが、業務効率化への最も賢い選択となることもあります。
この記事が、あなたのデータ収集作業を効率化する第一歩となれば幸いです。
参考資料
-
Pythonでスクレイピングを始めるならこれ!ライブラリの選び方と使い分け
- 本記事の④HTML解析と⑤ブラウザ操作について、さらに詳しく比較解説しています