はじめに
皆さん、Webページの情報を自動で取得したり、ブラウザ操作を自動化したい、と思ったことはないでしょうか。
Webページから必要な情報を自動的に取得する手法を『スクレイピング』と呼びます。
スクレイピングは、データ収集や業務の効率化に役立つ便利な技術です。
私自身Pythonをよく使用しており、Pythonでのスクレイピングをすることがあるのですが、Pythonライブラリ「Playwright」を使う機会があり、これまでは他のライブラリである「BeautifulSoup」や「Selenium」を使用していたので、何が違うのか、それぞれ何ができるのか、というのが気になりまとめてみました。
スクレイピングの例
① Webページ上のHTML情報の取得
HTMLに埋め込まれているテキストの情報や、表のデータを取得できます。
以下の画像は、体重と体脂肪率を記録したWebページの例です。このような表形式のデータをスクレイピングで取得し、分析や保存に活用できます。
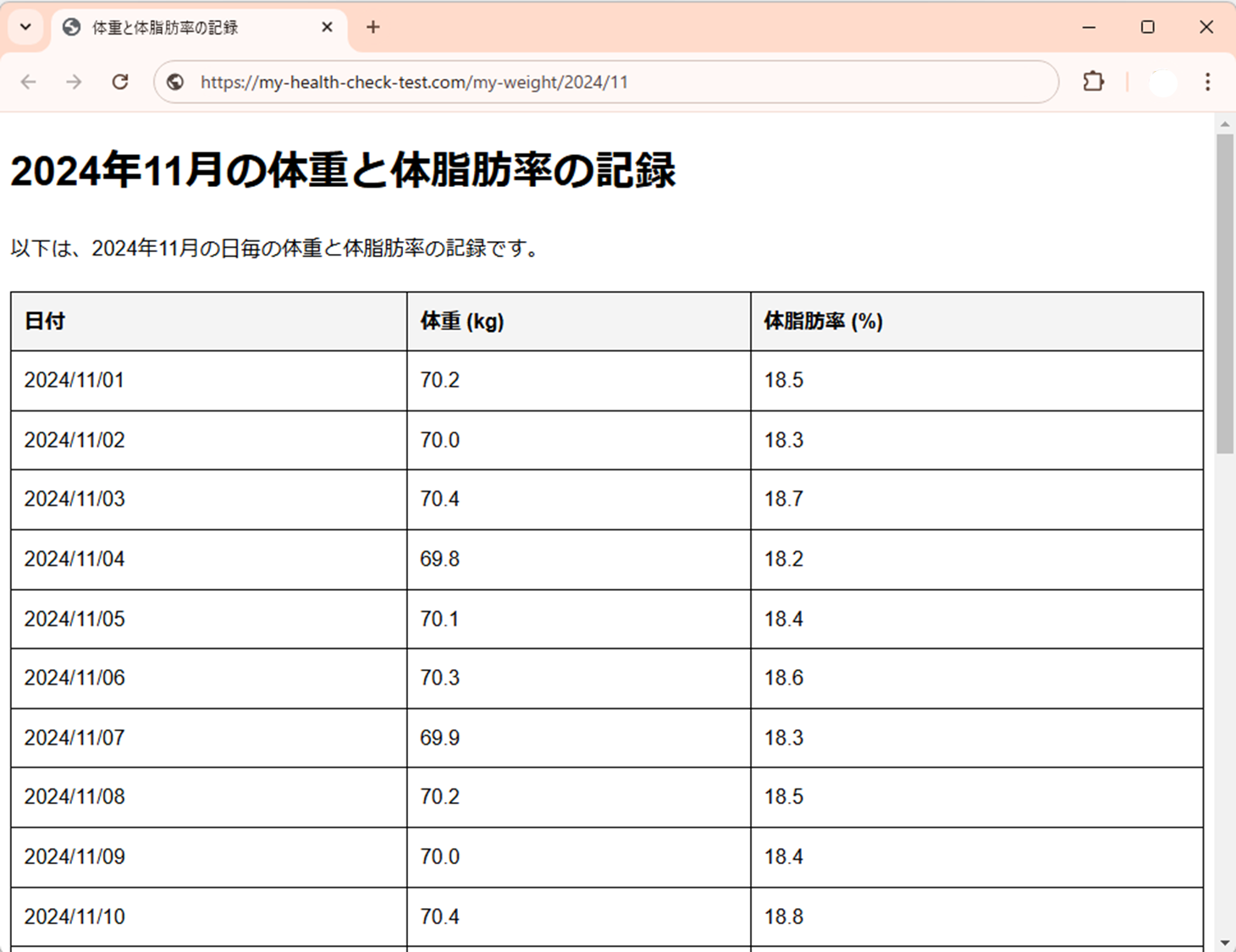
② ブラウザ操作
一部のWebページでは、目的のデータを表示するためにユーザー操作が必要な場合があります。
ログインが必要なページがその一例です。
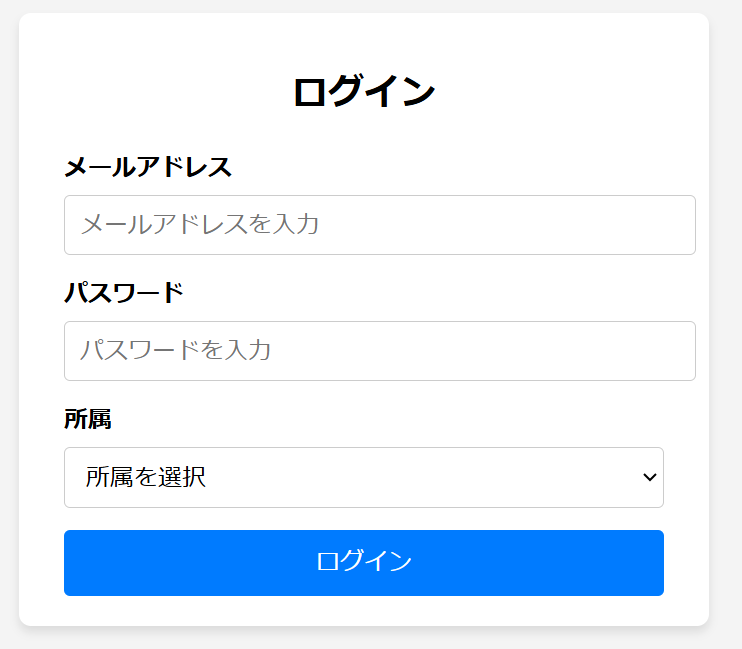
以下の画像は、ログイン画面の例です。このようなページでは、スクレイピングを行う前に自動的にログイン操作を行い、ログイン後のページからデータを取得することができます。
スクレイピング用ライブラリ比較
スクレイピングでは主に先述の2つのことができるのですが、やりたいことによって使うべきライブラリが異なります。
Pythonでのスクレイピングのライブラリを3つ取り上げますが、それぞれの特徴は下表の通りです。
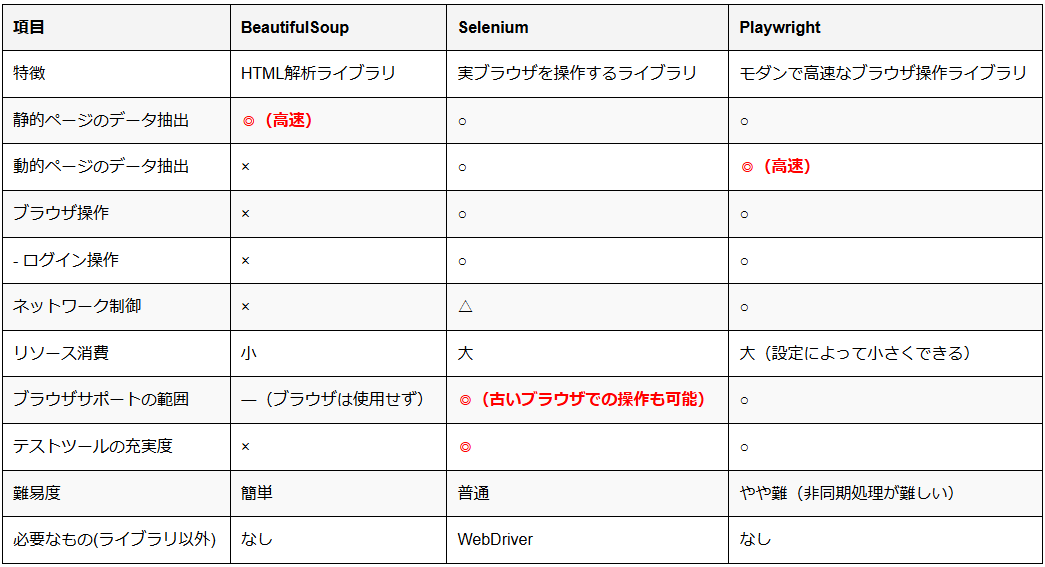
スクレイピング用ライブラリの使い分け
① Webページ上のHTML情報の取得
基本的には、静的WebページのHTMLを取得するだけであれば「BeautifulSoup」が最適です。
「BeautifulSoup」はURLからHTML情報を直接取得するため、動作が軽量で高速です。
例えば、ニュースサイトやブログのように、ページロード時にすべてのデータがHTMLに含まれている場合に適しています。
「Selenium」や「Playwright」は実際にブラウザを起動して画面を表示させてからHTMLを取得するため、HTMLのみを取得する場合には余分なリソースを消費し、動作が遅くなることがあります。
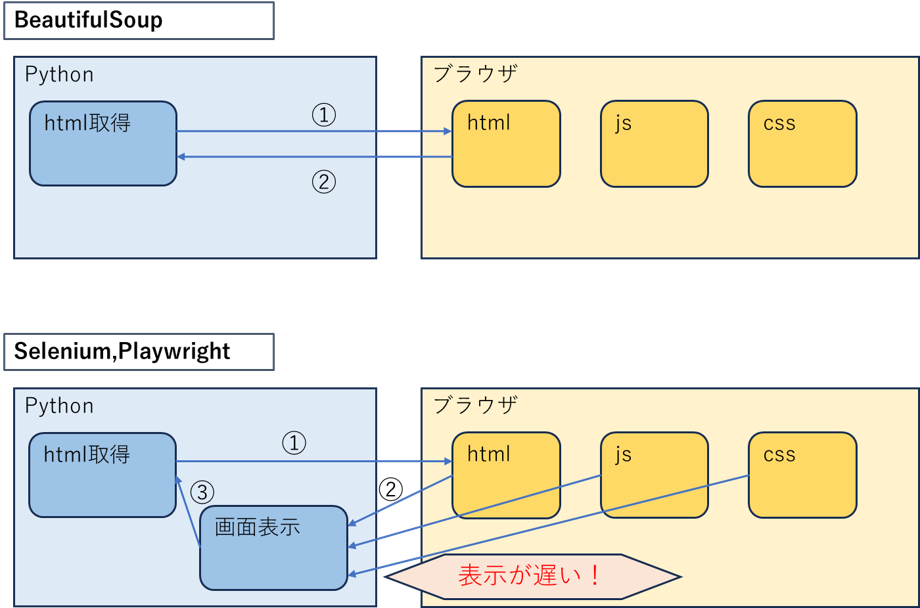
しかし、「BeautifulSoup」では外部ファイルの(HTMLに埋め込まれていないJavaScriptファイルや、ページ読込後に動的に生成される要素)を取得することができません。
そのため、ページによっては取得したい情報が欠落してしまう可能性があります。
このような場合は、「Selenium」や「Playwright」を使用することで、動的に生成されたデータも取得することができます。
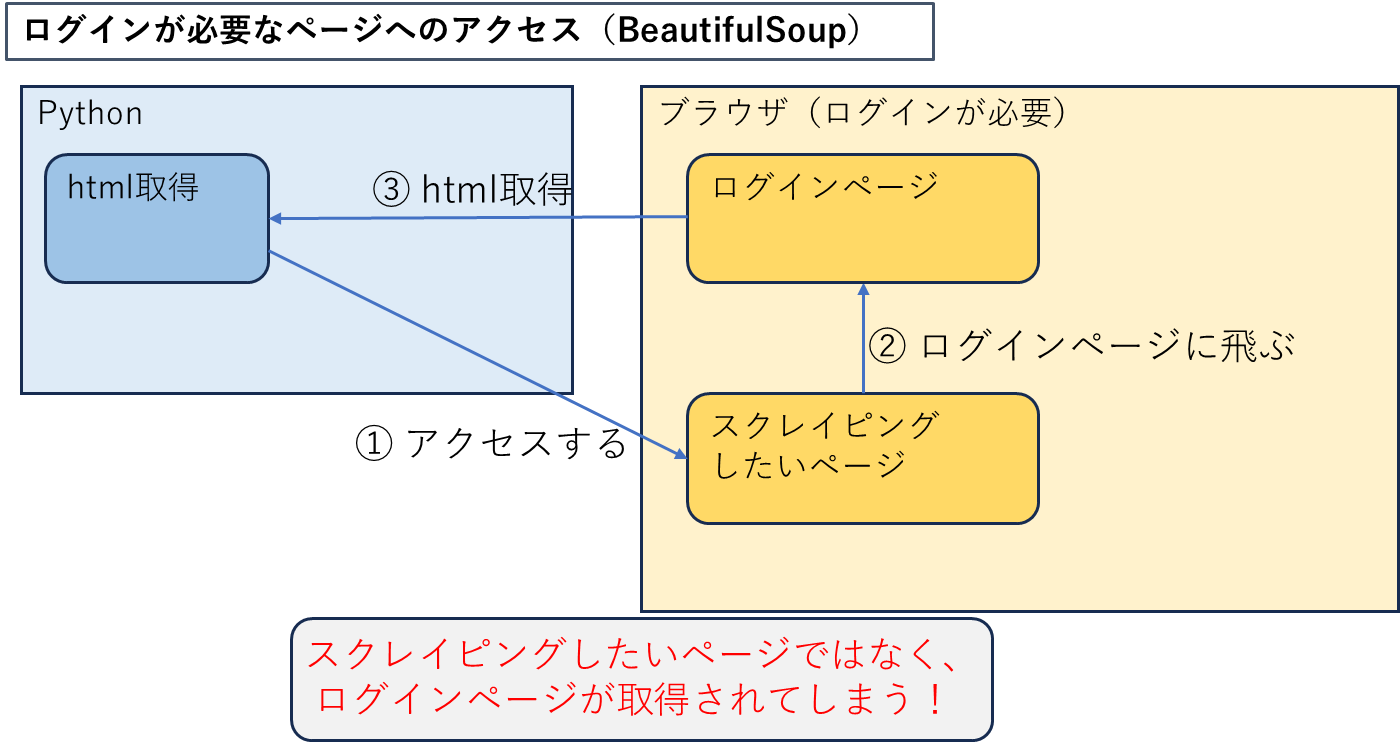
また、ログインが必要なページでは、「BeautifulSoup」だけではデータを取得できません。
なぜなら、URLにアクセスしてもログインページにリダイレクトされてしまうためです。ログインページのデータが取得されてしまいます。
このような場合も、「Selenium」や「Playwright」を使用することで、ログイン操作を自動化し、必要なデータを取得することが可能です。
② ブラウザ操作
ブラウザ操作が必要な場合、基本的にJavaScriptが関与していることが多いため、「BeautifulSoup」では操作を行うことができません。
例えば、ボタンのクリックやフォームへの入力、ページのスクロールなど、Webページ上でのユーザー操作をシミュレートする必要がある場合は、「Selenium」や「Playwright」を使用する必要があります。
「Selenium」や「Playwright」は、JavaScriptで生成される動的コンテンツを取得できるだけでなく、ユーザー操作を完全にシミュレートできるため、ログインや複雑な操作が必要なシナリオでも活躍します。
例えば、定期的に生成するデータをもとにメールを作成し、送信するといったようなことも実現できます。
まとめ
複数のライブラリを使い分けるのは難しそうだと思っていましたが、それぞれに得意分野や向き不向きがあることを知り、使い分ける理由が分かりました。
また、今回調べたことで、「ログインページがあるからスクレイピング諦めよう」とか、「スクレイピングにかなりの時間がかかるけどブラウザにアクセスしているから仕方ないよね」といったことがなくなり、私自身の実装できる幅が広がったと思います。
本記事では、Pythonでのスクレイピングに使用する主要なライブラリの特徴と使い分けについて解説しました。
それぞれのライブラリの得意分野を理解することで、効率的にスクレイピングを行うことができます。
ぜひ、この記事を参考にして、自分のプロジェクトに最適なライブラリを選び、スクレイピングを活用してみてください!