はじめに
WEB会議の多い昨今。
私も様々なツールでのWEB会議に参加しています。
多くのWEB会議では字幕の機能が標準で備わっており、この字幕を保存する機能や、保存内容を生成AIと連携して議事録を起こす機能までリリースされています。
議事録機能などは残念なことに、少し前までは日本語に対応されておらず、私には宝になりきれない機能でした。
Chromeブラウザで利用することを前提に、Chrome拡張を通じて字幕を保存できないかと考え、DOM上に現れるテキスト情報を集める方法を検討してみました。
本記事では
ブラウザ上に現れる文字情報を保存する方法はいくつかあろうかと思います。
本記事では私が試した2手法を紹介します。
サンプルページ
字幕情報の取得に先立って、ターゲットとするサンプルページがこちらです。
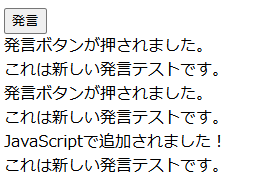
説明の簡略化のため、デザインも何もないシンプルなページとしています。
発言ボタンを押すことでメッセージが追加されていきます。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>字幕取得のためのサンプルページ</title>
<script src="sample.js"></script>
</head>
<body>
<input class="send-message" type="button" value="発言">
<div class="talk-area">
</div>
</body>
</html>
const randomMessages = [
"おはようございます。",
"これは新しい発言テストです。",
"ランダムなメッセージだよ。",
"JavaScriptで追加されました!",
"発言ボタンが押されました。"
];
document.addEventListener('DOMContentLoaded', () => {
const talkArea = document.querySelector('.talk-area');
const sendButton = document.querySelector('.send-message');
sendButton.addEventListener('click', () => {
// 1. ランダムメッセージの選択
const randomIndex = Math.floor(Math.random() * randomMessages.length);
const message = randomMessages[randomIndex];
// 2. 要素の作成
const newDiv = document.createElement('div');
const newSpan = document.createElement('span');
// 3. spanにテキストを設定
newSpan.textContent = message;
// 4. divとtalk-areaに要素を追加
newDiv.appendChild(newSpan);
talkArea.appendChild(newDiv);
});
});
ローカルファイルに対してChrome拡張を動作させる
本記事では、サンプルページをローカルに保有し、Chromeでローカルから開いた状態で、Chrome拡張を動作させます。
manifest.jsonは以下
{
"manifest_version": 3,
"name": "字幕取得サンプル",
"version": "1.0",
"description": "字幕取得サンプル",
"content_scripts": [
{
"matches": ["file://*/*"],
"js": ["content.js"]
}
]
}
ローカルファイルでのChrome拡張の動作を許可するため、拡張管理画面から「ファイルの URLへのアクセスを許可する」を有効にしておきます。

setTimeoutを用いたポーリング監視
今回はシンプルに記録済みのメッセージ数で取得を終えた数を管理します。
取得した内容はconsole.logに保存するシンプルな実装としました。
(function() {
const talkArea = document.querySelector('.talk-area');
// talk-areaが存在しない場合は処理を中断
if (!talkArea) {
console.log(".talk-area要素が見つかりませんでした。監視は開始しません。");
return;
}
// --- メッセージ監視処理 ---
// 初期の子要素数を記録
let lastChildCount = talkArea.children.length;
const POLLING_INTERVAL = 500; // 500msごとにチェック
// ポーリング関数
const checkMessages = () => {
const currentCount = talkArea.children.length;
if (currentCount > lastChildCount) {
// 新しい要素が追加された場合、新しく追加された分だけを処理
for (let i = lastChildCount; i < currentCount; i++) {
const childDiv = talkArea.children[i];
// div > span の構造を想定して span のテキストを取得
const spanElement = childDiv.querySelector('span');
if (spanElement) {
const capturedMessage = spanElement.textContent;
// コンソールに出力
const timestamp = new Date().toLocaleTimeString();
console.log(`[${timestamp}] ${capturedMessage}`);
}
}
// カウントを更新
lastChildCount = currentCount;
}
// 次のポーリングを設定
setTimeout(checkMessages, POLLING_INTERVAL);
};
// ポーリング開始
checkMessages();
})();
動かしてみます。
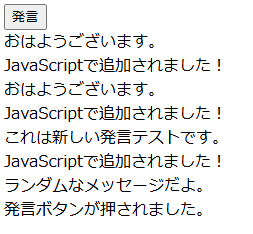
consoleを確認
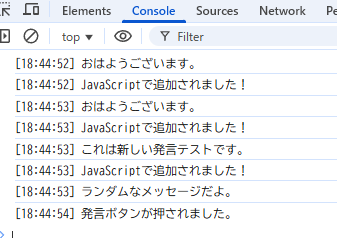
無事取ることが出来ました。
この方法はポーリングする負荷や、どこまで読み込んだかを自己管理する必要があるなど、様々なデメリットがあります。
一方で、ポーリングは一定間隔でDOMの状態を再評価するため、変更の過程が複雑でも最終的なテキストを捉えやすいという利点があります。
MutationObserverを用いたDOM監視
DOMをMutationObserverを用いて監視してみます。
(function() {
const talkArea = document.querySelector('.talk-area');
// talk-areaが存在しない場合は処理を中断
if (!talkArea) {
console.log(".talk-area要素が見つかりませんでした。監視は開始しません。");
return;
}
// --- メッセージ監視処理(MutationObserver) ---
// MutationObserverのコールバック関数を定義
const observerCallback = (mutationsList, observer) => {
for (const mutation of mutationsList) {
// 子要素の追加 (childListの変更) をチェック
if (mutation.type === 'childList') {
// 追加されたノードを反復処理
mutation.addedNodes.forEach(node => {
// 追加されたノードが要素 (Element Node) かつ div要素であることを確認
if (node.nodeType === 1 && node.tagName === 'DIV') {
// div > span の構造を想定して span のテキストを取得
const spanElement = node.querySelector('span');
if (spanElement) {
const capturedMessage = spanElement.textContent;
// コンソールに出力
const timestamp = new Date().toLocaleTimeString();
console.log(`[${timestamp}] ${capturedMessage}`);
}
}
});
}
}
};
// MutationObserverのインスタンスを作成
const observer = new MutationObserver(observerCallback);
// 監視オプションの設定
// childList: 子ノードの追加や削除を監視
const config = { childList: true };
// talkAreaに対して監視を開始
observer.observe(talkArea, config);
// 必要であれば、監視を停止する関数を公開することも可能ですが、ここでは省略します。
// observer.disconnect();
})();
同様に動かしてみました。
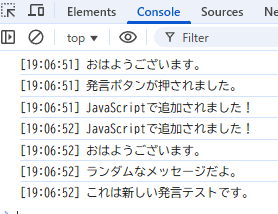
MutationObserverによるDOMの変更イベントにより、ポーリング負荷を軽減することができます。
今回のサンプルでは、ノード追加のみを検知していますが、字幕の場合、すでに存在しているノードのtext要素だけが書き換わるシーンや、既存ノードが削除され、別途新たに追加されるケースなども存在していました。
その場合、subtree や characterData をtrueとしたMutationObserverを使用したり、削除や再作成を考慮したつくりにする必要があり、MutationObserverでの処理は複雑になりがちでした。
さいごに
それぞれメリット/デメリットがあり、シーンにあわせて使い分ける必要があると感じました。
本稿にはJavaScriptでのテキスト収集を記載しましたが、実際の字幕では難しいポイントがいくつかあります。
・DOM構造が複雑
・idやclassが未指定で、対象のDOMが特定しきれない
・構造やclassがツール側のアップデートで変更される
・textの変更、divやspanタグ自体の置き換えなど更新方法も変更される
・字幕表示DOMが順次消されていく
この辺りがネックとなり、当初MutationObserverで取得していましたが、現在はパフォーマンスよりも維持・管理コストを優先してポーリングでの処理へ変更しています。