はじめに
TensorFlowは、「データフローグラフ」という形で計算を表現し、機械学習をプログラミングします。この形式は、大規模な並列計算を行うのに有用とされています(参考記事)が、スクリプトを上から下に読んで計算を行う普通のプログラミング言語とは考え方が異なるので、はじめは少しとっくきづらさがあります。
そこで、この記事では、TensorFlowのプログラミングで必要になる3つのキーコンセプト
- Opノード
- セッション
- 変数
について簡単に説明します。
データフローグラフとOpノード
「データフローグラフ」はノードといわれる計算ブロックのようなものをエッジといわれる線で繋げたもので、データはノードからノードへ、エッジのつながり方に従って受け渡され、計算が行われます。
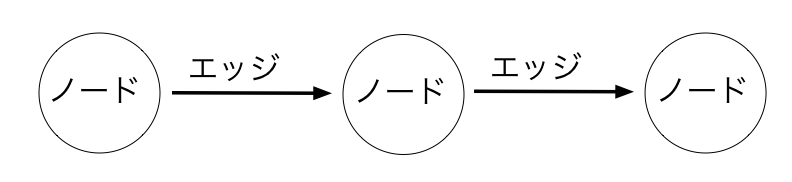
似たようなプログラミング手法は、SIMULINKやUnreal Engine4のBlueprintでも見られますね。
TensorFlowでは、ノードは「op」(operation:計算操作の略)と言われます。たとえば、
hello = tf.constant('Hello, TensorFlow!')
は、’Hello, TensorFlow!’ というstringを出力する, helloという名前の定数型のopを定義している、と考えます。
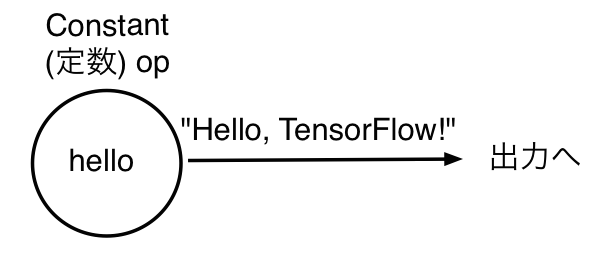
各々のopノードは「tensor」(テンソル)という形でデータを保持しています。テンソルは、ここでは多次元配列の一種だと理解してください。先ほどのhelloノードの型は、print文で確認できます:
Tensor("Const_4:0", shape=TensorShape([]), dtype=string)
helloノードが定数、0次元、データ型は文字列であることがわかります。しかし、helloに'Hello, TensorFlow'という文字列が割り当てられていることは、わかりません。Opノードの中身や計算結果を知るには、Session(セッション)オブジェクトを作って、グラフを実行する必要があります。
セッション
TensorFlowで、データフローグラフを用いた計算を実行する際は、以下のような形で、必ずSessionオブジェクトを作る必要があります。
sess = tf.Session()
セッションオブジェクトを作ったら、runコマンドに出力として使いたいopノードを指定して実行することで、グラフからの出力を計算できます。たとえば、先ほどのhelloノードを出力とするなら、
result = sess.run(hello)
で、helloからの出力(文字列)がresultに保存されます。
resultの中身は、print文でわかります:
Hello, TensorFlow!
ここで注意したいのは、runの引数で指定するのは最後のアウトプットのopノードで、そのアウトプットの計算に必要なノードの計算は自動的に行われる、ということです。たとえば、
import tensorflow as tf
num1 = tf.constant(1)
num2 = tf.constant(2)
num3 = tf.constant(3)
num1PlusNum2 = tf.add(num1,num2)
num1PlusNum2PlusNum3 = tf.add(num1PlusNum2,num3)
sess = tf.Session()
result = sess.run(num1PlusNum2PlusNum3)
print(result)
を考えましょう。グラフのイメージは、以下の通りです。
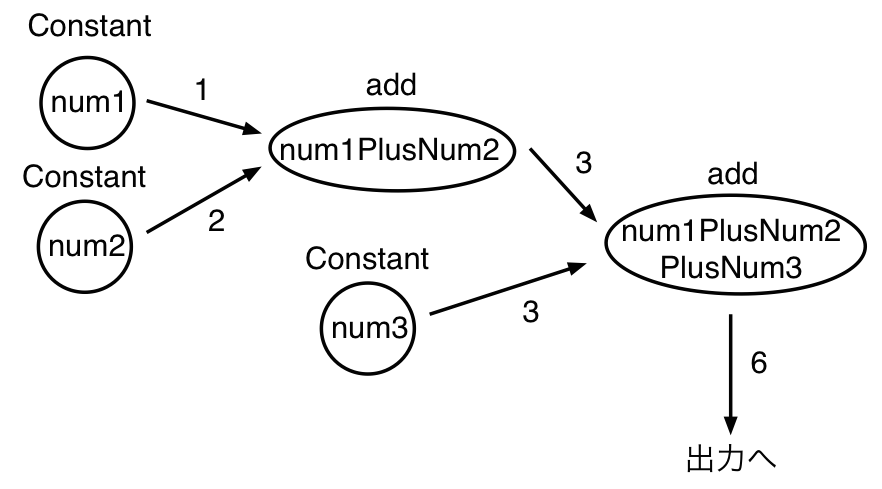
つまり、num1, num2, num3にそれぞれ1,2,3を割り当て、num1PlusNum2にnum1+num2の値を計算させ、num1PlusNum2PlusNum3で、num1PlusNum2+num3を計算する、というグラフを作ります。
そしてsess.runで、アウトプットとしてnum1PlusNum2PlusNum3を指定してます。このnum1PlusNum2PlusNum3の値を得るには、その前にnum1PlusNum2の計算が必要になりますが、TensorFlow側は自動的にそちらの計算を行い、num1PlusNum2PlusNum3の計算結果が得られるようにしてくれます。
変数
TensorFlowでは、
State = tf.Variable(0, name="counter")
の形で、初期値と名前を指定し、変数を定義します。変数を使うときは、tf.initialize_all_variables()などの関数を用い、後述する方法で変数の初期化が必要なので注意しましょう。
そして、変数に値を代入するときは、tf.assignを使います。たとえば、
import tensorflow as tf
State = tf.Variable(0, name="counter")
one = tf.constant(1)
new_value = tf.add(State, one)
update = tf.assign(State, new_value)
init_op = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init_op)
print(sess.run(State))
sess.run(update)
print(sess.run(State))
では、State(初期値 0)とone(初期値 1)を加算した結果であるnew_valueをStateに代入するupdateというopノードを作っています。
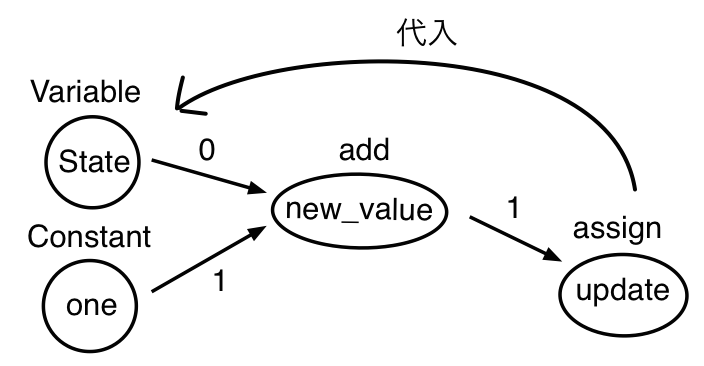
またここでは、変数を初期化するtf.initialize_all_variables() をもつノードとしてinit_opも定義しています。sess = tf.Session()でセッションを作ったら、まずセッションの最初にsess.run(init_op)で変数を初期化しています。
次に、print(sess.run(State))を実行していますが、この時点ではStateはまだ初期値のままなので「0」がアウトプットされます。しかし、sess.run(update)でnew_value(Stateとoneの値の合計)の値をStateに代入するので、次のprint(sess.run(State))の出力は「1」になります。
セッションと変数
tf.Session()で作るセッションは、変数などの状態を保持することができます。そのため、上のassign.pyではsess.run()を複数回行っていますが、それらの間で変数の値は保持されています。
また、セッションは複数作ることが可能で、変数の値は、それぞれ別に保存されます。たとえば、
import tensorflow as tf
State = tf.Variable(0, name="counter")
one = tf.constant(1)
new_value = tf.add(State, one)
update = tf.assign(State, new_value)
init_op = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init_op)
sess.run(update)
print(sess.run(State))
sess2 = tf.Session()
sess2.run(init_op)
sess2.run(update)
sess2.run(update)
print(sess2.run(State))
では、同じグラフを使って計算をする二つのセッションsess, sess2があります。
sess.run(update)は1回、sess2.run(update)は2回実行しているので、sess2では、new_valueノードでのStateとoneの加算操作(つまり、Stateに1を足す)が2回行われます。その結果、おなじ"State"であっても、print(sess.run(State))の出力は1、print(sess2.run(State))の出力は2になります。
終わりに
TensorFlowは、データーフロープログラミングに慣れてない人には少し難しく感じられますが、この記事で取りあげたノード、セッション、変数の概念を理解すれば、スムーズにプログラミングできると思います。何かの参考になれば、幸いです。