こんにちは、食べログ技術部のデータサイエンスチームの@yang_mingです。
本記事では食べログで1年を通じて取り組んだ、データ分析基盤の刷新について紹介します。
データサイエンスチームの紹介
データサイエンスチームは、食べログのデータの利活用を推進し、メディア/ビジネス/組織/飲食業界のデータによる意思決定を支援する組織です。食べログを取り巻くあらゆるデータを蓄積し、再利用可能な形で提供する仕組みをグランドデザインから構築・導入まで推進しております。「データ活用のハードルを下げ、データドリブンの取り組み全体を促進させる」というミッションのもと、各部門のデータ活用の課題をデータサイエンスの力で解消することを目指しています。
従来のデータ基盤の抱える課題
従来のデータ基盤はTreasure Dataを中心として運用を行ってきました。日次、マスター系のMySQLデータ、Adobe Analyticsユーザー行動ログをS3に一時保存し、Treasure Dataに自動的にロードする構成を取っています。
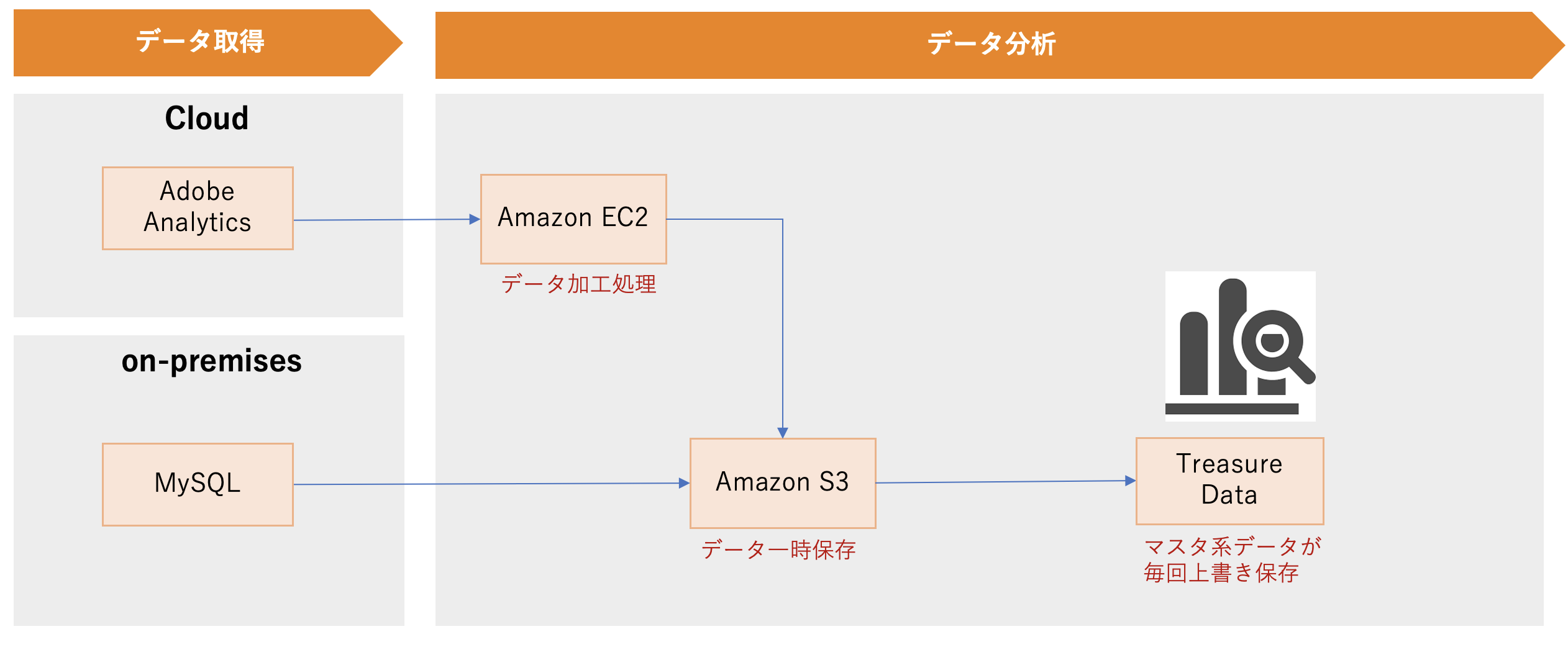
データ分析&活用の際、従来のデータ基盤では下記の課題があることが見えてきます。
- 大規模データ分析用のクエリを複数発行する場合、Treasure Dataの性能制限により、キュー詰まりが発生する。
- マスタ系データは最新のものしか蓄積しておらず、過去のスナップショットでの分析が不可能。
- Treasure Dataにアップロード上限があり、食べログの全てのデータを配備することができない。
- データ可視化は、BIツールを使用せずExcelを使用してグラフを作成しているため効率が悪い。
1〜3の課題はいずれも、Treasure Dataという利便性が高いもののデータ量に上限があるスケールしないインフラを採用したことによる課題です。また、4はBIツールが未採用であることによる課題です。そこで、データ基盤自体を別のインフラに移し替えて刷新し、BIを新たに採用することにしました。
データ分析基盤の刷新
新データ基盤の要件
食べログデータ基盤は膨大な量と種類のデータを高速に分析し、それらビッグデータをビジネスに活用できるようにするために必要となる「土台(プラットフォーム)」のことです。以下のような要求が求められます。
- データサイズが大きく、かつ、本数が多い。
- ログデータとスナップショットデータがあり、共に非常に巨大なデータを持っている。
- スナップショットデータは過去に遡って集計したいことが度々ある。
- クエリの実行は様々な部署が行うため時間帯がよく重なる。そのような状況でも、待機することなく集計作業を実施したい。
クラウドの選定
クラウドを選定するにあたり、下記の視点を重視してクラウドを選定しました。
- TreasureDataの課題を解決できる。
- 過去のスナップショットも含め、食べログの全てのデータが配備できる。
- クエリ実行が重なったり、データ量が増大してもクエリ実行が詰まらない。
- 煩雑な基盤管理が不要で少人数で運用できる。
- 初期費用が不要のシンプルな課金制。
- 今後機械学習の活用に耐えることができる。
- レコメンデーション/画像認識など
選定の候補として、Amazonが運営するAWS、Microsoftが運営するAzure、Googleが運営するGoogle Cloud Platform(以下GCP)の3つを検討しました。食べログではAWS, GCPすでに別のプロジェクトで採用しており、特にこの2つを詳細に検討しました。
今回比較した、データ基盤の構築に関するGCPとAWSのサービスリストは以下の通りです。
| 構成要素 | GCPサービス | AWSサービス |
|---|---|---|
| データレイク | Cloud Storage | S3 |
| データウェアハウス | BigQuery | RedShift |
| ETL処理 | Dataflow, Dataproc, Cloud Pub/Sub | DataPipeline, EMR, Simple Queue |
| ワークフローオーケストレーション | Cloud Composer | Amazon Managed Workflows for Apache Airflow |
| 機械学習 | Vertex AI, BigQueryML, Cloud AutoML, | Machine Learning |
| 運用監視 | CloudIAM, Stackdriver | IAM, CloudWatch |
これらを比較した上で、私達は最終的にGCPを選定しました。具体的には下記の点が決定打となりました。
-
BigQueryは、クエリが詰まることなく実行できる
BigQueryはクエリ実行数/スキャンするデータ量に応じて自動的にスケールします。キュー詰まりがほぼ発生しないため分析クエリの実行開始を待機することはありませんし、データ量が増大しても実行完了は早いケースが多いです。 -
BigQueryの管理が簡単
BigQueryはサーバーレスであるため、サーバー管理を行う必要がありません。スキャン量に比例した従量課金モデルであるため、課金増になりやすい要因を特定しやすく、運用改善が容易です。 -
機械学習関連の機能が充実している
GCPで機械学習ができるBigQuery MLなど、各種機械学習サービスが充実しています。Python, R 各種 ML ツールを統合したプラットフォームVertex AIも提供され、GPUも利用可能でありディープラーニングの各種手法も採用可能です。
AWS/GCP共にデータ基盤としての技術要素は揃っており、データ上限を意識せずに使うことが出来るようになっており、金額面も大きな差はありませんでした。TreasureDataでのシステム課題や、運用課題、今後の拡張性を考慮すると、BigQueryやBigQuery ML, VertexAIの優位性が大きく、結果GCPを採用することに決めました。
GCP上で新データ分析基盤の構築
アーキテクチャの設計
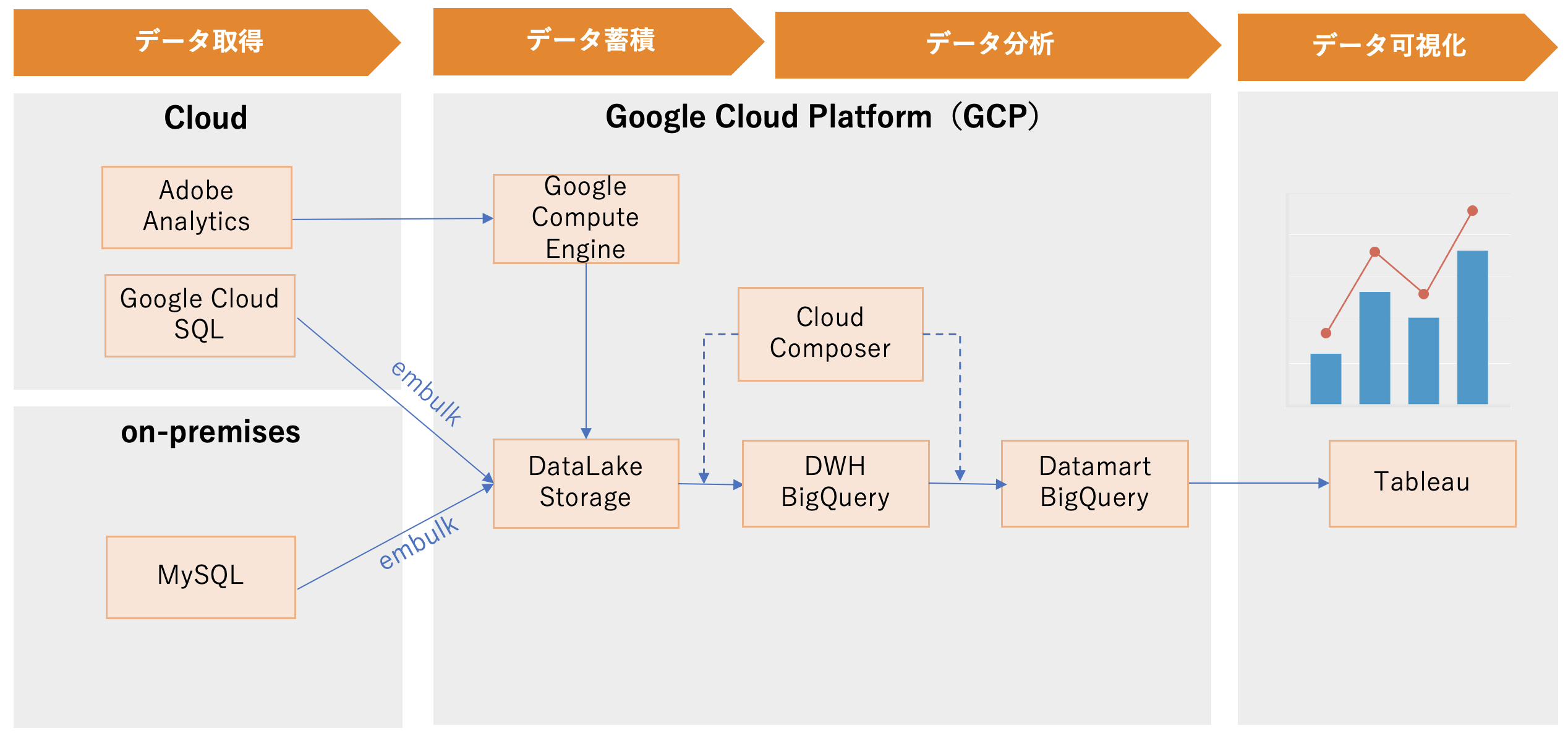
新データ分析基盤は主に以下の機能があります。
- データレイク(データを蓄積する)
- データウェアハウス(データを整形・加工・クレンジングする)
- データマート(データを分析する)
- データ可視化(BIツール)
以降でそれぞれ詳しく説明していきます。
データレイク
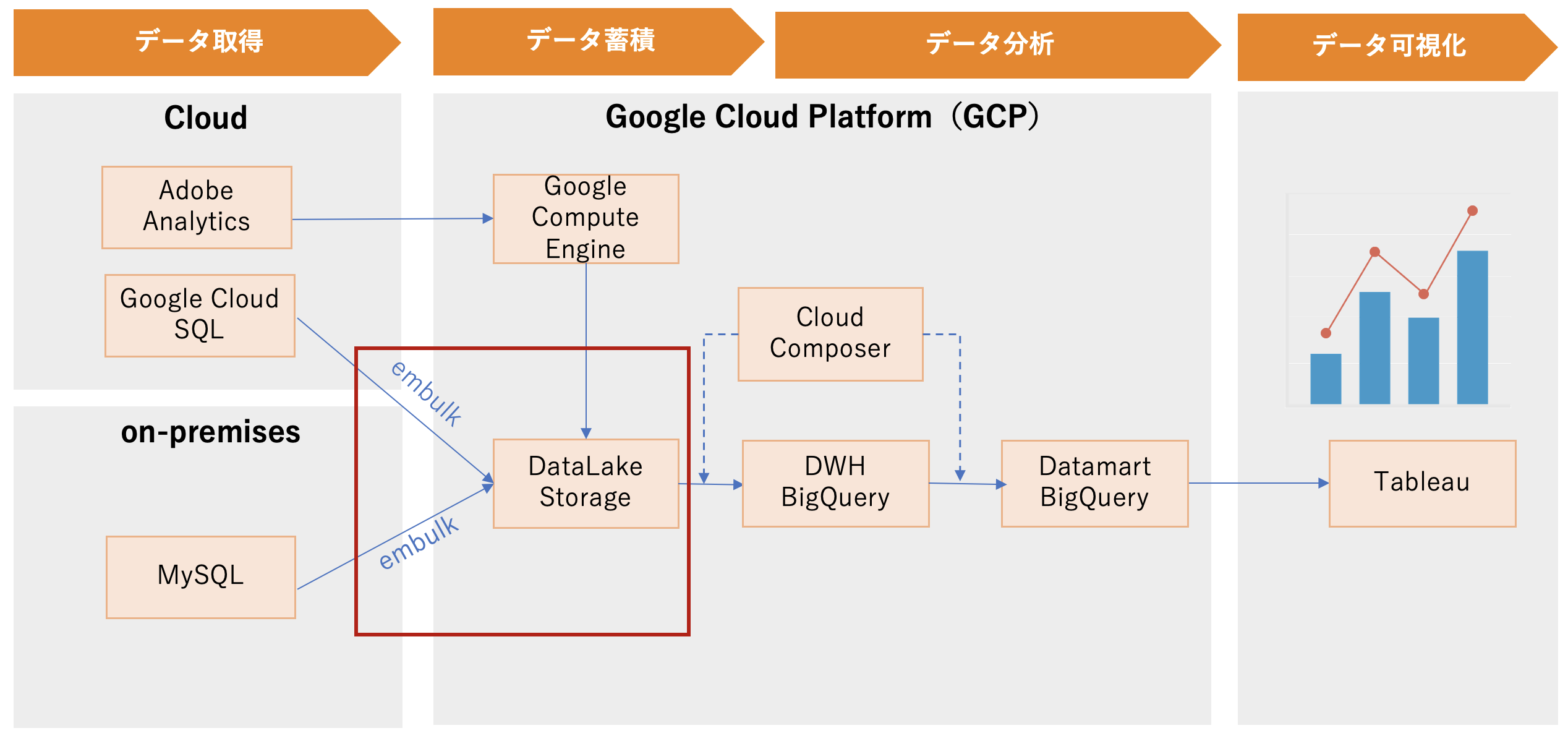
食べログを取り巻くあらゆるデータをデータレイクに集約します。セキュリティ強化のため、データソースごとにデータレイクを分割して構築し、権限を設定しています。

データレイクの1層のデータ連携
Google Compute Engine(以下GCE)上でデータを加工してから、データレイクGoogle Cloud Storage(以下GCS)の1層にデータをアップロードします。
Adobe Analyticsデータ連携を例とすると、Adobe Analyticsのデータフィードを設定して、1時間毎に指定したGCEへログファイルを自動的に転送します。GCE上ではバッチでデータを加工してから、データレイク(GCS)の1層にログファイルをアップロードします。
データレイクの2層のデータ連携
Embulkを活用して、MySQLのデータをデータレイク(GCS)の2層にロードします。
Embulkとは、プラガブルなマルチソースバルクデータローダーです。
下記の理由で、Embulkを使ってETLバッチを実装しています。
- 柔軟なプラグイン構造による機能拡張が可能。
- 1回の処理を複数のタスクに分割することで並列実行する仕組みを備えているため、大規模データの高速バルク処理が可能。
- YAMLファイルを使用して一括データ読み込み処理を定義し、実装しやすい。
以下は、あるテーブルの内容をオンプレミスMySQLからGCSへの配信を行うために、embulkに渡すYAMLファイルの一例を示しています。
in:はデータソースからの読み込みについての設定を記述します。 データソースはオンプレミスのMySQLですので、embulk-input-mysqlプラグインを使用して、接続設定、抽出クエリについて記述しています。
out:は転送先への配信設定を記述します。配信先は、データレイク(GCS)ですので、embulk-output-gcsプラグインを使用して、接続設定、配備先について記述しています。
exec: はembulk内部の設定を記述します。ここでは、並列数や出力のファイル数を指定することで、ETL処理の高速化を図っています。
exec:
max_threads: 8
min_output_tasks: 20
in:
type: mysql
host: {{ env.DB_HOST }}
user: {{ env.DB_USER }}
password: {{ env.DB_PASSWORD }}
database: {{ env.DB_NAME }}
options: {useLegacyDatetimeCode: false, serverTimezone: Asia/Tokyo}
default_timezone: "Asia/Tokyo"
query:
SELECT
, `id`
, `name`
, `created_at`
, `updated_at`
FROM users
column_options:
id: {type: long}
name: {type: long}
created_at: {type: string, timestamp_format: "%Y-%m-%d %H:%M:%S"}
updated_at: {type: string, timestamp_format: "%Y-%m-%d %H:%M:%S"}
out:
type: gcs
bucket: {{ env.GCS_BUCKET_NAME }}
path_prefix: {{ env.DB_NAME }}/users/v=001/d={{ env.TARGET_DATE }}/users
file_ext: .csv.gz
auth_method: json_key
json_keyfile:
content: |
{
"type": "{{ env.GCS_ACCOUNT_TYPE }}",
"private_key_id": "{{ env.GCS_PRIVATE_KEY_ID }}",
"private_key": "{{ env.GCS_PRIVATE_KEY }}",
"client_email": "{{ env.GCS_CLIENT_EMAIL }}",
"client_id": "{{ env.GCS_CLIENT_ID }}"
}
mode: replace
formatter:
type: csv
delimiter: ","
newline: LF
newline_in_field: LF
charset: UTF-8
quote: '"'
escape: ''
encoders:
- { type: gzip, level: 9 }
Embulk実行は簡単です。embulkをインストールした環境で embulk run users.yml.liquid を実行すると、input、ouput設定通り、データ転送を行います。
データレイクの3層のデータ連携
GCSの3層bucketに直接にファイルをアップロードします。
GCPアカウントを持つ方の場合、GCSの3層bucketに直接にファイルをアップロードできます。
BigQueryで作成したデータマートの場合、Cloud Composerで自動的にGCSの3層bucketにファイルをエクスポートします。
データウェアハウス
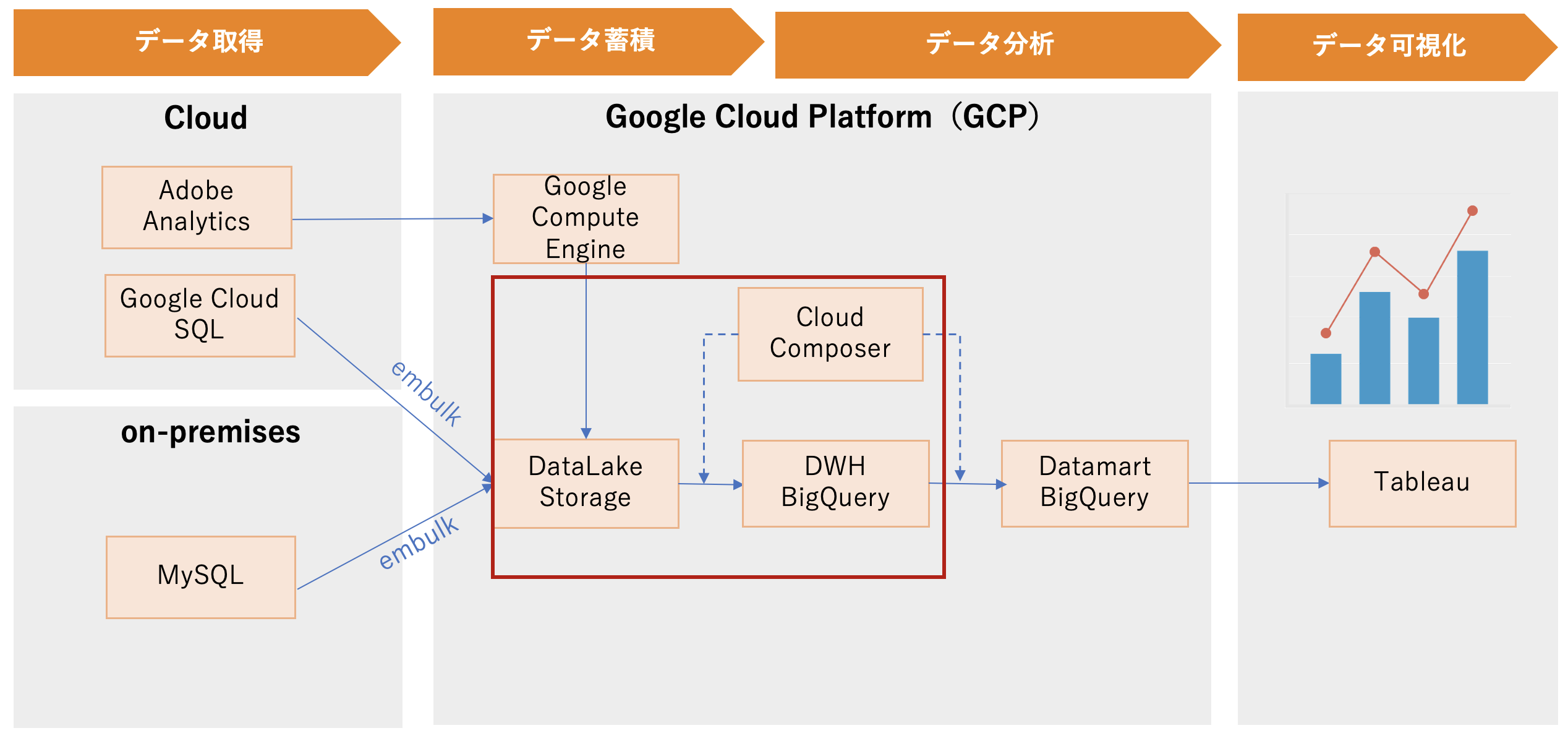
Cloud Composer + bq load でGCSからBigQueryにCSVファイルを自動で取り込むことを実現します。
詳しく実装内容を説明すると、まず、bq loadバッチを作成します。
# !/bin/bash
bq load \
--source_format=CSV \
--replace \
--skip_leading_rows=1 \
--field_delimiter=',' \
--allow_quoted_newlines \
--max_bad_records=0 \
${DATASET_NAME}.${TABLE_NAME}'$'${TARGET_DATE} \
${GCS_URI}/*.csv.gz \
${TABLE_SCHEMA_JSON}
次はCloud Composer上で、bq loadバッチを実行するDAGを作成します。
import datetime
import airflow
from airflow.operators import bash_operator
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
'owner': 'airflow',
'start_date': yesterday,
'depends_on_past': False,
'retries': 4,
'retry_delay': datetime.timedelta(minutes=15),
'project_id': airflow.models.Variable.get('gcp_project')
}
with airflow.DAG(
'load_gcs_to_bq',
default_args=default_dag_args,
schedule_interval=('00 00 * * *') -- スケジュール設定
) as dag:
load_gcs_to_bq = bash_operator.BashOperator(
task_id='load_gcs_to_bq',
bash_command='load_db_to_bq.sh' -- bq loadバッチ実行
)
load_gcs_to_bq -- タスク実行
ここまで、事前準備が終わり、DAGファイル、バッチファイルをCloud Composerサーバー上に反映すれば、設定したスケジュール通り、GCSからBigQueryにCSVファイルが自動で取り込まれます。
データマート
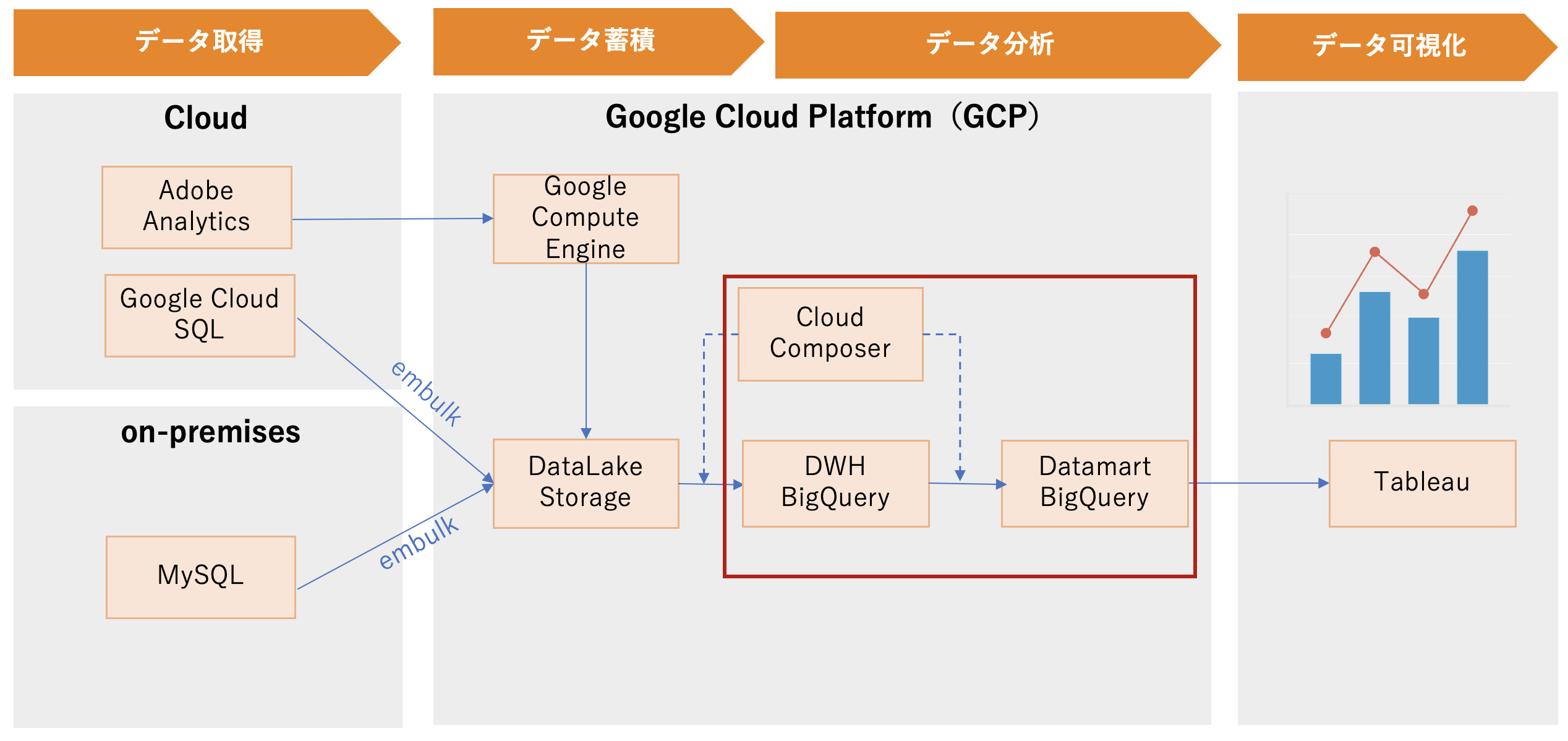
Cloud Composer + bigquery_operator でBigQuery SQLを実行して、データマートテーブルを自動的に更新することを実現します。
Cloud ComposerのDAGのサンプルコード
from airflow import DAG
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
with DAG(dag_id='my_dags.my_dag') as dag:
start = DummyOperator(task_id='start')
end = DummyOperator(task_id='end')
sql = """
SELECT *
FROM 'my_dataset.my_table'
"""
bq_query = BigQueryOperator(bql=sql,
destination_dataset_table='my_dataset.my_datamart'),
task_id='bq_query',
bigquery_conn_id='my_bq_connection',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
create_disposition='CREATE_IF_NEEDED',
query_params={})
start >> bq_query >> end
データ可視化
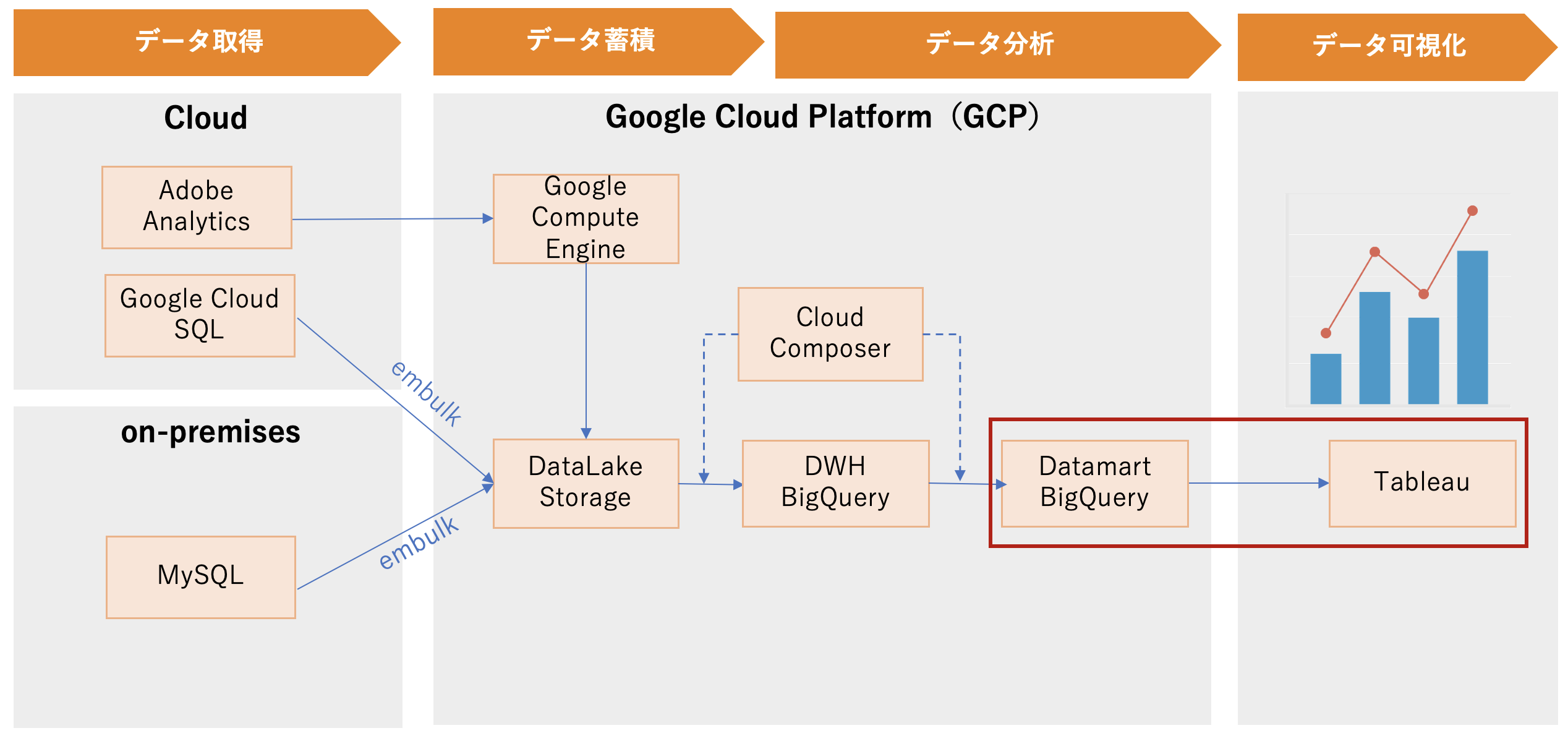
TableauからBigQueryに可視化データマート(view)を接続して、データビジュアライズを行います。
TableauからBigQueryを利用するには
- Tableau 内の DB に指定した時間にすべてのデータを取得してきてそれを使ってグラフを表示する方法(抽出)
- グラフ描画の際毎回 BigQuery にクエリを投げる方法(ライブ)
の二種類が選べます。
BigQueryでは1が好ましいです。2を採用した場合、BigQueryのクエリ実行が高速のためデータ量が大きい場合表示が早くなりますが、表示を変えるたびにクエリが実行されるため、スキャン量がかかり、料金がかさんでしまう恐れが高いです。
データ分析基盤の刷新における成果
今回のデータ基盤刷新における成果を下記にまとめます。
- データを集約することで、全てのデータを横断的に利用ができるようになった。
- BigQueryにより、大規模データを分析できるようになった。
- マスター系データの過去の全てのスナップショットを蓄積して、過去データ分析が可能となった。
- Tableauを導入し、クイックに課題定義からデータビジュアライズまで実現し、意思決定に活用しやすくなった。
今後について
下記は食べログデータ基盤のロードマップです。
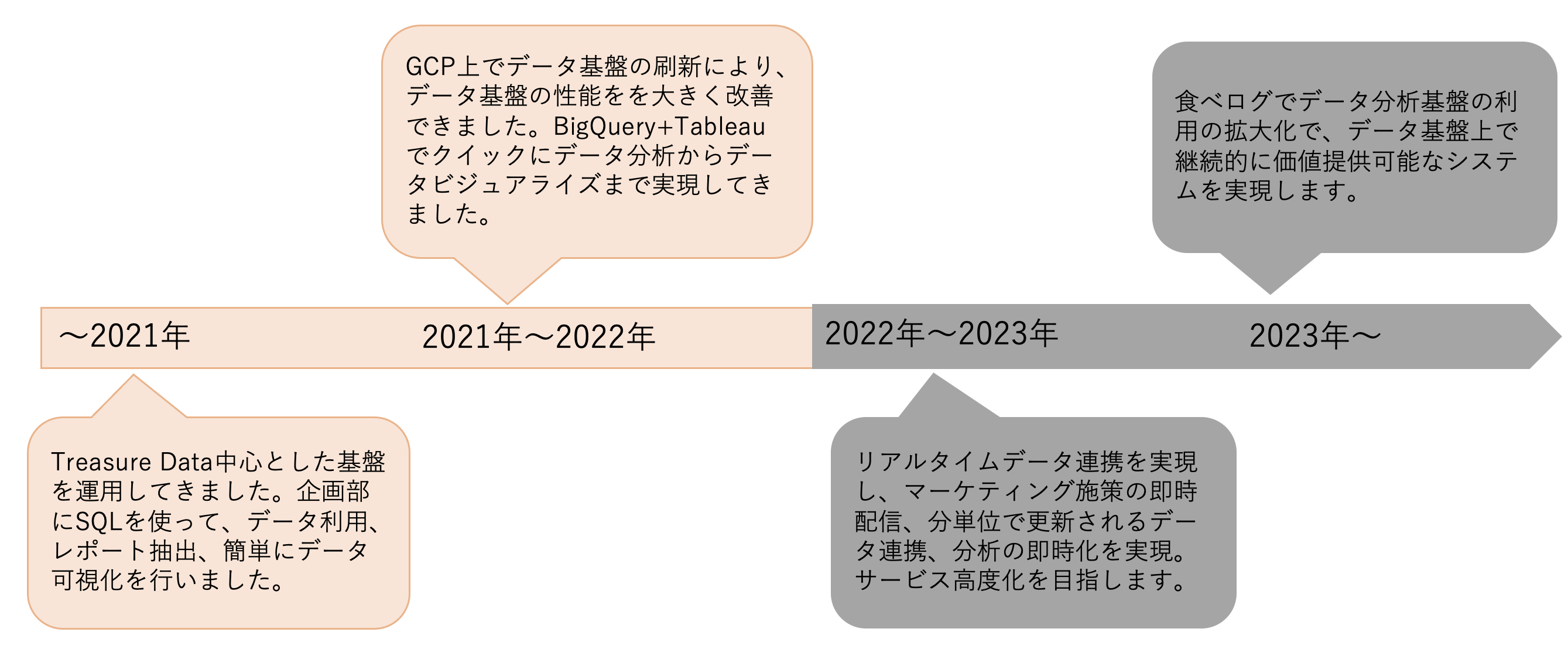
これまで食べログでは日次でBigQueryへデータを連携して、BigQuery+Tableauでクイックにデータ分析からデータビジュアライズまで実現してきました。今後はマーケティング施策や機械学習、異常検知などの案件が増えてきており、リアルタイムなデータを必要とするサービスも増えてきています。食べログデータ基盤の次のフェーズでは、リアルタイムデータ連携を実現することを目指します。
最後に
「データ活用のハードルを下げ、データドリブンの取り組み全体を促進させる」をミッションに、データ基盤の開発・運用を通してプロダクトの成長を共に推し進める仲間を募集しています。この記事を読んで、もしご興味をもたれた方は是非採用ページからお申し込みください。
正式なご応募以外にも、転職活動前の情報収集やランチを交えた情報交換なども大歓迎です。その場合はご応募いただくときに、フリーテキスト記入欄に「カジュアル面談希望」とご記載ください。
明日はエンジニア @_shar さんの「OpenAPIとMSWを組み合わせてAPIモックしている話」です。
お楽しみに!