課題
-
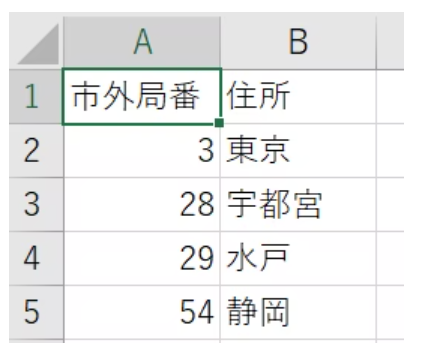
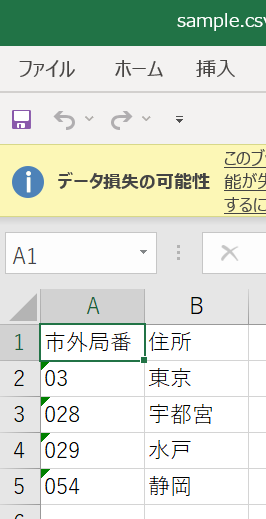
マスタのコードなどに使われる0始まりの番号が .csvをExcelで開くと先頭の0が消えてしまい、これではデータとして壊れてしまう。 手動の場合の対処はこちら
-
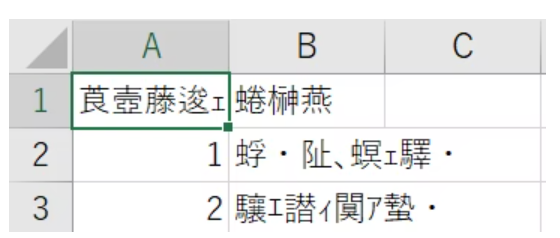
UTF-8で保存されることが要件のcsvファイルをExcelで開くと文字化けする。手動の場合の対処はこちら
-
ファイルの拡張子を.txtに変更して、テキストファイルウィザードで開けばいいのだが、これは割と面倒なので、自動化したい。
対処方法
VBSのスクリプトを作りました。
csvをtxtの拡張子にしたコピーを作り、そのファイルをExcelのテキストウィザードですべての列を文字列属性にして開くことを自動化するスクリプトです。
後述のスクリプトを OpenCSV.vbs というファイル名で(本当はなんでもいいけど、説明の都合、なにかファイル名を決めたいので、このファイル名にします。) デスクトップに保存してください。(これも本当はデスクトップじゃなくてもいいです。)
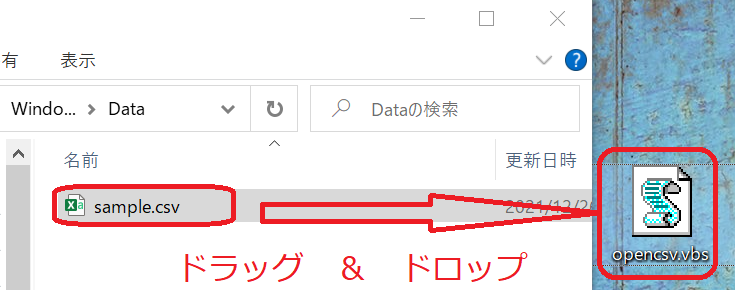
OpenCsvファイルに開きたい csvファイルあるいはtxtファイルをドラッグしてください。
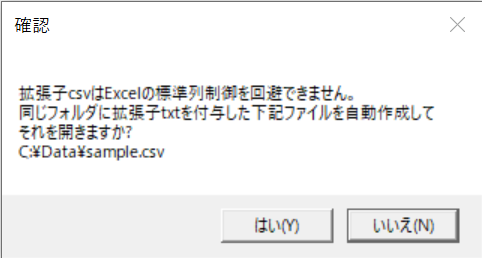
csvファイルの場合は、以下のメッセージがでるの、「はい」を選択します。
以下の通り、Excelが開きます。
文字化けもせず、0落ちもしません。
ドラッグ & ドロップすら 面倒くさい場合
そういう場合は、エクスプローラの「送る」に、OpenCSV.vbs を登録してしまいます。
手順
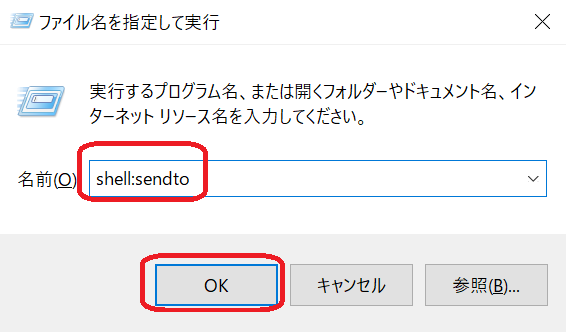
- Windowsキーを押したまま、Rキーを押します。
- 「ファイルを指定して実行」ダイアログが表示されますので、「Shell:Sendto」と入力します。
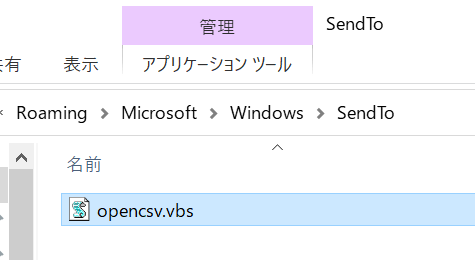
表示された 「SendTo」フォルダに、上記で保存したデスクトップ上の「OpenCSV.vbs」ファイルをコピーします。
これで「送る」に OpenCSV.vbsが登録されました。
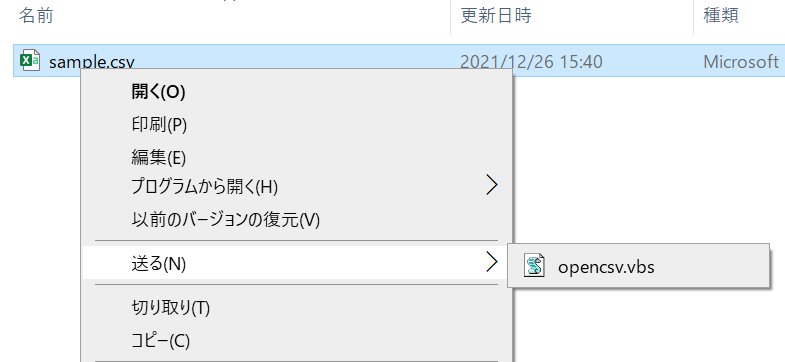
- 開きたいファイルを右クリックして、「送る」→「OpenCSV.vbs」を選択します。
コードの保存方法
後述のコードをコピーして、 OpenCSV.vbs として保存してください。
コードを囲っている黒い領域の右上にカーソルをあてると、コピー用のアイコンがでてくるので、それでコピーできます。

※ vbs保存時は 文字コードを ANSIにしてください。 メモ帳のデフォルトは 近年、UTF-8になっています。 保存時にANSIに変更してください。
コード
OpenTxtAsStringColumns
'指定されたファイルを標準列属性ではなく文字列属性で開くためのvbsです。
'CSVがUTF-8かどうかも判断します。
Sub OpenTxtAsStringColumns
If WScript.Arguments.Count = 0 Then
Exit Sub
End If
TargetFilePath = WScript.Arguments(0)
'ファイルの拡張子がcsvだとExcelが変な自動判定をしてしまうので
'うまくうごかない。よって、拡張子が .csvかを調べる
Set FSO = CreateObject("Scripting.FileSystemObject")
FileExt = FSO.GetExtensionName(TargetFilePath)
If UCase(FileExt) = "CSV" Then
NewTargetFilePath = TargetFilePath & ".txt"
Response = MsgBox( _
"拡張子csvはExcelの標準列制御を回避できません。" & vbCrLf & _
"同じフォルダに拡張子txtを付与した下記ファイルを自動作成して" & vbCrLf & _
"それを開きますか?" &vbCrLf & _
TargetFilePath, vbYesNo + vbDefaultButton2 , "確認" )
If Response = vbNo Then
MsgBox "処理が取り消されました"
Exit Sub
End If
On Error Resume Next
FSO.CopyFile TargetFilePath, NewTargetFilePath
If Err Then
MsgBox "コピー先のファイルが他のプログラムで開かれていますので" & _
"コピーができません。処理を中止します。" & _
vbCrLf & vbCrlf & NewTargetFilePath , vbExclamation
Exit Sub
End If
On Error Goto 0
TargetFilePath = NewTargetFilePath
End If
Const xlDoubleQuote = 1
Const xlWindows = 2
Const xlDelimited = 1
Dim Origin
Origin = xlWindows 'ANSI CodePage
If CanBeUTF8(TargetFilePath) Then
Origin = 65001 'UTF-8
End If
'ファイルの内容をみて列数分の列情報を作るのは手間なので
'最大列数分の列情報を作っておきます。
'すべての列を文字列属性で読み込ませます。
Const MaxColInExcel = 16384
ReDim FieldInfo(MaxColInExcel-1)
For i = 1 To MaxColInExcel
'Array(4,1) は 4列(A列)が標準属性(1)であることを示します。
'Array(5,2) は 5列(B列)が文字列属性(2)であることを示します。
'Array(6,3) は 6列(C列)が日付属性(3)であることを示します。
FieldInfo(i-1) = Array(i, 2)
Next
Set XL = CreateObject("Excel.Application")
XL.Application.Visible = True
XL.Application.WorkBooks.OpenText _
TargetFilePath, Origin, _
, xlDelimited, xlDoubleQuote, _
False, False, False, True, _
False, False,, FieldInfo
End Sub
Function CanBeUTF8(TestFilePath)
'UTF8の規定に従ったファイルでないときにこの既定値で処理を抜けます。
'VBSでは As Boolean宣言ができず、Variant型の扱いなので、既定値を明示します。
'VBAの場合は、Function ... As Boolean で宣言しておけば、この1行は不要です。
CanBeUTF8 = False
'ファイルをバイナリデータとして読み取るために ADODB.Streamを用います。
Const adTypeBinary = 1
Set Ado = CreateObject("ADODB.Stream")
Ado.Type = adTypeBinary
Ado.Open
'バイトデータの並びを文字列型変数に読み取ります。
'読み取ったデータは、配列としてはアクセスできません。
'代わりにMidB を使って取得、代入ができます。
Ado.LoadFromFile TestFilePath
ByteArrayAsString = Ado.Read
Ado.Close
'1バイト目 2バイト目以降
'00..7F なし
'C2..DF 80..BF
'E0..EF 80..BF 80..BF
'F0..F4 80..BF 80..BF 80..BF
'文字列型の形式をとっていますが、中に入っているのはUnicode文字列ではなくByteの並びなので
'その長さは、Lenではなく、LenBで判断します。
For i = 1 To LenB(ByteArrayAsString)
'MidBで各バイトにアクセス可能です。 さらにAscBに代入して、数値として扱うことができます。
FirstByte = AscB(MidB(ByteArrayAsString,i,1))
'1バイト目の値によって、2バイト目以降が何バイトあるかが決まります。
If &h00 <= FirstByte And FirstByte <= &h7F Then
FollowingBytesCount = 0
ElseIf &hC2 <= FirstByte And FirstByte <= &hDF Then
FollowingBytesCount = 1
ElseIf &hE0 <= FirstByte And FirstByte <= &hEF Then
FollowingBytesCount = 2
ElseIf &hF0 <= FirstByte And FirstByte <= &hF4 Then
FollowingBytesCount = 3
Else
'UTF-8として解釈可能ではありません。
Exit Function
End If
'2バイト目以降が決められたバイトの数だけ 80-BFの間の値で続いているかを確認します。
For j = 1 To FollowingBytesCount
i = i + 1
If i > LenB(ByteArrayAsString) Then
'UTF-8として解釈可能ではありません。読み取るデータがもうありませんでした。
Exit Function
End If
'後続1バイトを数値として読み取ります。
FollowingByte = AscB(MidB(ByteArrayAsString,i,1))
'後続バイトは 0x80 ~ 0xBF の範囲のバイトでなければなりません。
If &h80 <= FollowingByte And FollowingByte <= &hBF Then
Else
'UTF-8として解釈可能ではありません。
Exit Function
End If
Next
'ここに来た時、変数iは jのループの中で後続バイト数の分加算されているので
'次のバイトの組み合わせの直前のバイト位置を指し示しています。
Next
'すべてのバイトデータがUTF-8の規則に準じていました。
CanBeUTF8 = True
End Function
解説
あまり、このコードの解説には興味はもたらないかと思いますが
今月作ったqiitaの記事の集大成となっています。
UTF-8か判断する部分には、
UTF-8ファイルとして解釈可能かを判断するVBS / VBA 関数 の記事で作った関数を使っています。
肝になるのは、以下の箇所です。
この列情報の設定が Excelの「マクロの記録」では記録されないので、これを実現できてない人が多いんだろうと思います。
列番号を指定した配列をさらに上の配列につっこむのがミソです。
列番号を配列の第1列で指定しているので、本当は順不同でも大丈夫です。
また指定しない列は標準列として処理されるので、文字列にしたい列があらかじめ特定されているなら、全列分の情報を用意する必要もないです。
Const MaxColInExcel = 16384
ReDim FieldInfo(MaxColInExcel-1)
For i = 1 To MaxColInExcel
'Array(4,1) は 4列(A列)が標準属性(1)であることを示します。
'Array(5,2) は 5列(B列)が文字列属性(2)であることを示します。
'Array(6,3) は 6列(C列)が日付属性(3)であることを示します。
FieldInfo(i-1) = Array(i, 2)
Next
おことわり
このコードによる損害に対しては、一切、責任を負いません。
自由に改変して配布していただいてかまいません。