この記事は創薬 (dry) Advent Calendar 2019 (#souyaku2019) の12月2日の記事です。
普段はMediumで記事を書いていることが多いですが今回はコードが多いので可読性を考慮して久々にQiitaで書きます。
背景
日々ますます難しくなっていく新規医薬品候補化合物創出のために、従来のメドケムによるSARにAIや機械学習を組み合わせることが期待されています。
しかし、機械学習手法は
- データセットの外れ値削除
- 記述子発生&選択
- パラメータチューニング
- 予測性能評価
といったタスクから構成されているパイプライン(ワークフロー)を前から進めるというルーチンワークが必要となってきます。
そしてよりよい予測モデル構築のためには「もう一度データセットの外れ値削除から見直そう」というように、パイプラインの前の方に戻ってやり直すと行った作業もよく行います。
また、SARが進んでいくと化学構造に大きな変化が出てきて既存の予測モデルではいわゆるApplicability Domainの外のデータを予測する必要が出てきて、予測モデルの更新を行う必要が出てきます。
以上のことから、一度ボタンを押しただけで「はい、できあがり」とはいかずによりよい予測モデルを得るためにいわゆる泥臭い作業を何度も行う必要があります。
したがって、機械学習のパイプラインの各タスクのコストが高い場合、例えば社内の各SARの各予測したいプロパティごとに予測モデルを構築するといったことは非常に難しくなってきます。
MLOps
このようなタスクの計算コストを下げようという考えの一つにMLOpsというものがあります。
MLOpsは例えば以下のような図で表されます。
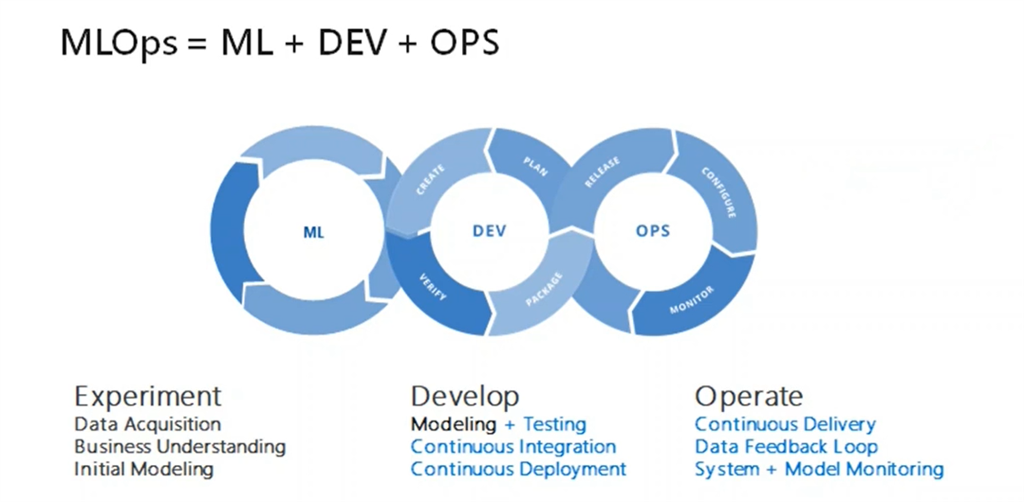
出典: [MLOps Explained]
(https://www.c-sharpcorner.com/blogs/mlops)
MLOps = ML + Dev + Ops とも考えられ、DevOpsという考えをML(Machine Learning)に適用したものと言えます。ML部分もサイクルになっているのは先ほど背景で指摘したパイプラインを何度も実行する必要があることを現していると言えます。
そこで今回は、MLOpsをサポートしてくれるエムスリーさんが開発・実装したgokart, redshellsと呼ばれるOSSを利用し、MLOpsの一例を紹介したいと思います。
gokart
gokartはSpotify社が開発したluigiと呼ばれるPipelineをより使いやすくするためのモジュールです。
gokartについては最近Qiitaにまとめてくださった方やいるのでそちらを読んだり公式ブログやドキュメントを読んでから読めばよりこの記事の理解が深まると思います。
- Luigiで行うパイプライン処理をより円滑に!gokartについて紹介
- 機械学習プロジェクト向けPipelineライブラリgokartを用いた開発と運用
- gokart repository
- gokart Documentation
pip install gokart
でインストールが可能です。
簡単に説明しますとluigi, gokartはパイプラインのフレームワークで背景で述べたような各タスクをclassで表現します。
以下にサンプルコードを示します。
class LoadIrisData(SampleTask):
def output(self):
return self.make_target('LoadIrisData.pkl')
def run(self):
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df['target_name'] = df.target.apply(lambda x: iris.target_names[x])
self.dump(df)
class MakeMoldelInputData(SampleTask):
def requires(self):
return LoadIrisData()
def output(self):
return self.make_target('MakeMoldelInputData.pkl')
def run(self):
data = self.load()
data = data.drop(['target_name'], axis=1)
self.dump(data)
各タスクをgokart.TaskOnKartを継承しているclassとし、各classのmethodで以下のことを書くというルールがあります。
| method | description |
|---|---|
| requires | ワークフローの一つ前のタスクを指定する |
| output | 各タスク終了時に保存されるファイルの名前を指定する |
| run | 各タスクの実際の作業を書く |
上記の例の場合
LoadIrisData
- requires: Pipeline最初の処理のため記載なし
- output:
runの最後にself.dumpされるデータをLoadIrisData.pklという名前で保存 - run: 親の顔より見た
irisのデータセットを呼び出しデータフレームへと変換
MakeMoldelInputData
- requires:
LoadIrisDataをオブジェクトとして指定することでPipelineの一つ前のタスクがLoadIrisDataであることを定義、runのself.load()でLoadIrisDataでself.dumpしたデータフレームを呼び出すことができるようになる。 - output:
runの最後にself.dumpされるデータをMakeMoldelInputData.pklという名前で保存 - run: この後に予測モデル構築を行う予定なので、データフレームから
target_nameという名前のカラムを削除
と言うことを表しています。この後、前処理、パラメータチューニング、予測モデル構築といった機械学習に必要なタスクへと進みます。
このようにフレームワークで実装することで複数人がコードを分担しても高い可読性&拡張性を維持した実装が可能になります。
さらにgokartがluigiと比較して特によくなった点として
- pikcleでのデータの保存に対応(機械学習のモデルを保存するのに必須)
- outputの接尾語としてハッシュキーを追加&拡張子から自動で形式を判断して保存
- Taskをパラメータとして受け取ることでより柔軟なコードが可能に
などなどがあげられます。
(詳細については需要や時間があればまた別のQiitaでまとめたいと思います)
- outputの接尾語としてハッシュキーを追加&拡張子から自動で形式を判断して保存
ちなみに、こちらに関しましては元々用意されている拡張子だけでは足りないなという時は自身でFileProcessorを継承したclassを実装すれば追加することができます。
私は例えば予測モデル構築をして予測性能評価の結果としてconfusion matrixやobserved-predicted plotが欲しいなと思って以下のようにpngという拡張子に対応するPNGFileProcessorを実装しています。
(ただし、以下の実装ではPipelineの最後にしかおけないのでPipelineのポリシーから見たらちょっとアウトレイジかもしれません)
from logging import getLogger
from gokart.file_processor import FileProcessor
import luigi
import matplotlib
import maplotlib.pyplot as plt
class PNGFileProcessor(FileProcessor):
def format(self):
return luigi.format.Nop
def dump(self, obj, file):
assert isinstance(obj, matplotlib.figure.Figure), \
f'requires matplotlib.figure.Figure, but {type(obj)} is passed.'
obj.savefig(file, format='png')
class DrawExample(SampleTask):
def output(self):
return self.make_target('DrawExample.png', processor=PNGFileProcessor())
def run(self):
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.scatter([1, 2, 3], [1, 2, 3])
self.dump(fig)
redshells
luigi, gokartは機械学習だけでなく、定期的なログ解析など様々な業務にも適用できます。さらに機械学習のパラメータチューニング、モデル構築にフィーチャーしてエムスリーさんが開発されているのがredshellsという別のモジュールです。gokartと組み合わせて使います。
(luigiがgokartの上で3つのredshells...あのゲームですね ![]() )
)
こちらもpipでインストールできます。
pip install redshells
redshellsでは実装がやや複雑になってしまいそうなパラメータチューニング、モデル構築部分をFactory型のデザインパターンを用いることで柔軟に実装できるようにしていただいています。
公式Repostiroyのexamplesにあるコードをお借りしつつ紹介したいと思います。
class MakeData(gokart.TaskOnKart):
task_namespace = 'examples'
def output(self):
return self.make_target('binary_classification/data.pkl')
def run(self):
x, y = sklearn.datasets.load_breast_cancer(return_X_y=True)
data = pd.DataFrame(dict(x=list(x), y=list(y)))
logger.info(f'columns={data.columns}')
logger.info(f'info=\n{data.info()}')
self.dump(data)
class OptimizeModelExample(gokart.TaskOnKart):
task_namespace = 'examples'
def requires(self):
data = MakeData()
redshells.factory.register_prediction_model('XGBClassifier',
xgboost.XGBClassifier)
return redshells.train.OptimizeBinaryClassificationModel(
rerun=True,
train_data_task=data,
target_column_name='y',
model_name='XGBClassifier',
model_kwargs=dict(n_estimators=50),
test_size=0.2,
optuna_param_name='XGBClassifier_default')
def output(self):
return self.make_target('binary_classification/results.pkl')
def run(self):
model = self.load()
logger.info(model)
出典: https://github.com/m3dev/redshells/blob/master/examples/binary_classification_example.py
MakeDataではsklearnモジュールのbreast_cancerのデータセットを呼び出し機械学習のためにデータフレームにしています。gokartの例で示したLoadIrisDataとほぼ同様のタスクですね。
OptimizeModelExampleではパラメータチューニングを行なっています。redshellsは内部で機械学習アルゴリズムとそのチューニング候補のパラメータをsingletonのFactory classで保持しており、呼び出すことができるようになっています。
これによりFactoryに登録しておくことでUserは利用時に機械学習の名前XGBClassifier, チューニングするパラメータ名XGBClassifier_defaultを呼び出すだけでOKです。
ちなみに公式ではxgboostしか登録されていません。例としてLGBMClassifierとそのパラメータLGBMClassifier_default, LGBMClassifier_accuracyを登録してみます(sklearnAPIのほうが好ましいと思います)
import lightgbm as lgb
import redshells
def register_prediction_model():
redshells.factory.register_prediction_model('LGBMClassifier', lgb.LGBMClassifier)
def register_optuna_param_name():
redshells.factory.register_optuna_param('LGBMClassifier_default', lgbmclassifier_default)
redshells.factory.register_optuna_param('LGBMClassifier_robust', lgbmclassifier_robust)
def lgbmclassifier_default(trial):
# パラメータのチューニング幅はかなり適当です
max_depth = trial.suggest_int('max_depth', 1, 8)
learning_rate = trial.suggest_int('learning_rate', 1e-4, 0.1)
n_estimators = 10000
return trial
def lgbmclassifier_robust(trial):
# パラメータのチューニング幅はかなり適当です
max_depth = trial.suggest_int('max_depth', 1, 4)
learning_rate = trial.suggest_int('learning_rate', 1e-4, 0.01)
n_estimators = 1000
return trial
class OptimizeModelExample(gokart.TaskOnKart):
task_namespace = 'examples'
# 使用するモデル、パラメータを気軽に変更できるように引数に追加します
model_name = self.luigiParameter()
param_name = self.luigiParameter()
def requires(self):
data = MakeData()
# 自身が設定したモデル、パラメータをすべて登録します
register_prediction_model()
register_optuna_param_name()
return redshells.train.OptimizeBinaryClassificationModel(
rerun=True,
train_data_task=data,
target_column_name='y',
# self.model_nameを受け取るように変更
model_name=self.model_name,
test_size=0.2,
# self.param_nameを受け取るように変更
optuna_param_name=self.param_name)
def output(self):
return self.make_target('binary_classification/results.pkl')
def run(self):
model = self.load()
logger.info(model)
上記のように私は自身が日頃よく使うモデルや色々学んでこういうパラメータチューニングをすれば良さそうだなというものをあらかじめregister_prediction_model, register_optuna_param_nameですべて登録し呼び出すようにしています。
ちなみにOptunaによるパラメータチューニングはredshells.train.OptimizeBinaryClassificationModelというタスクに委譲しています。他にもいくつか例となるタスクがexamplesの中で実装されているのでちょうどよいものを使うか、実装例を参考に自身のニーズに合うタスクを実装するといいと思います。
以上のように実装したPipelineを用いることで
「まずはこのデータならLGBMClassifierのlgbmclassifier_defaultでやってみるか」
「overfitしたからlgbmclassifier_robustに変えてまたやってみよう」
さらに前処理の部分も同じように作っておけば
「前処理の部分のパラメータhogeの値を0.0から0.1に変えてlgbmclassifier_defaultでもう一回しよう」
といったようなタスクが気軽にできるようになり機械学習の回転を早めることができます。
またgokartはすでに同じパラメータでタスクを行ないその出力ファイルが存在している場合は自動でパスしてくれるので
- Pipelineの後半の方のタスクをやり直す時は前半部分は自動でパスする
- 同じパラメータでもう一度予測モデル構築を行うというよくあるイージーミスも防ぐ
といった特徴もあります。
まとめ
gokart, redshells を用いたMLOpsの一例を紹介しました。gokartやredshellsって便利そうだな、使ってみようかなと思っていただけたら幸いです。
Cheminformaticianはどうしても化学構造に関する勉強も行う必要があるためエンジニアとしての知識や技術が不足することがあります。今回のような技術も学び社内で紹介・導入(ここが一番ハードル高い)していけばよりよい創薬が可能になるかなと思います。
最後に素晴らしいPipelineモジュールを作っていただいたSpotifyさん、エムスリーさんに改めて感謝します。ありがとうございました。
それではAdvent Calenderを書くというタスクは無事終了したので、luigiやgokartのPipelineが正常に終了した時のメッセージでお別れしたいと思います。
This progress looks :) because there were no failed tasks or missing dependencies