初めに
こんにちは。
20代最後の3日間をしまなみ海道自転車走破チャレンジに費やした朝日新聞社メディア研究開発センター(以下M研)の山野です。
早速ですが今回は、自然言語処理と音声認識を活用した字幕の自動作成機能の実装を試みたので、その方法と結果を報告させていただきます。
こんな感じで書いていきます、お付き合いくださいませ。
取り組む背景
私は普段、YOLOという社内サービスの開発をしています。YOLOというと物体検出の方を思い描く方もいらっしゃるかと思います。同姓(?)同名のサービス名でややこしいと思いますが、以後YOLOは我々のサービスのことを指すことにします。
YOLOは"You Only upLoad Own file"の略で、「ファイルだったらなんでも処理するのでなんでもアップロードしてね」みたいな理想を掲げ日々研究開発を進めており、2021年1月にリリースしました。もうすぐリリースして2年ぐらい経ちます。
詳しいことは以下のnoteの記事をご覧ください。
https://note.com/asahi_ictrad/n/nc2089a017491
https://note.com/asahi_ictrad/n/nccda294a9a28
さて、今回字幕を対象とした機能を検討することに至った理由は主に3.5つあります。
1. ユーザーからの要望
まず一つ目は、ユーザーからの要望です。字幕がついた動画の再生・編集機能がほしいという要望がありました。YOLOでは動画を見ながら音声認識の結果を編集することができますが、その動画に字幕をつけることでより一層、書き起こし作業が楽になることが考えられます。
2. セキュリティ
Youtubeにアップロードするだけで字幕を作成することもできますが、社内のセキュリティ規約上、社外サービスに社内データを上げることができません。
3. 動画コンテンツが多くなってきた
YOLOでもそうですが本社全体を考えた時、動画コンテンツを取り扱う機会や発信が今後さらに加速していくことが考えられます。自動で字幕をつけることができる仕組みがあれば、コンテンツ制作現場において重宝されるのではないかと考えられます。
4. 割と面白いテーマがたくさんありそう
三つ目は、字幕を付与するタスクを考えたとき、割と面白いテーマがたくさんありそうということです。
これらの理由から自動字幕について考え、実装にトライしてみました。
なお、非常に短い時間で構想から実装まで進めたため、考慮できていないことがたくさんあると思います。
その点はご了承ください。
実装方針
まず、字幕の特性について改めて考えてみました。以下に箇条書きで列挙します。
- 基本的には発した言葉をテキスト化し表示している。
- 話者によって表示方法やタイミングを切り替えている。
- 文脈に応じて適切に文が分割されている。
- 「えー」や、「あー」などのフィラーや、不要な言葉などを省いていることが多い。
- 声のボリュームや話した内容に応じて文字の大きさや色、フォントなどを変えている。
- 一文字ごとにテキストを表示することで次に発する言葉を意図的に視聴者に伝えないよう表現する場合もある。
もちろんこれだけではなく他にもさまざまな特徴があるかと思いますが、列挙した特徴を実装できるよう、以下のフロー図に落とし込んでみました。
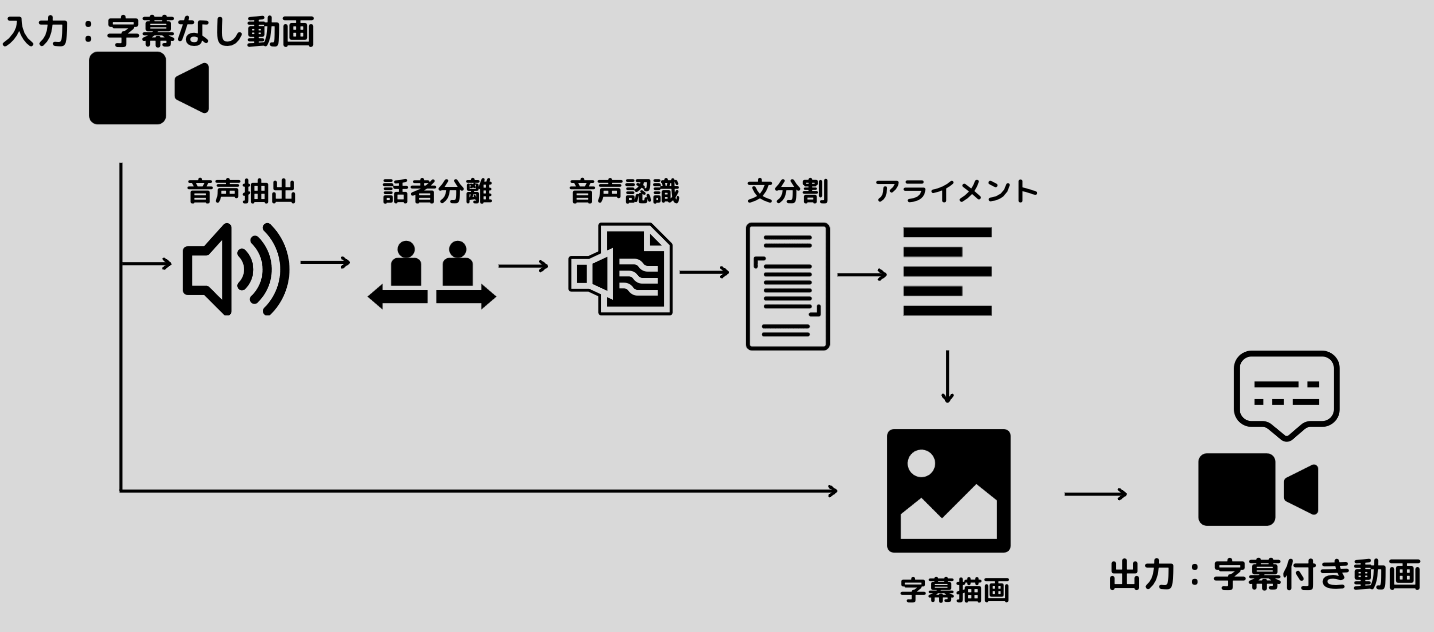
つまり、字幕なしの動画がYOLOにアップロードされると、
- 動画を音声と画像に分離
- 話者分離
- 音声認識
- 文分割
- アライメント
- 字幕にテキストを描画
- 画像と音声を結合し、字幕付き動画を作成
上記の流れで処理を行っていきます。
また、今回字幕を付与する動画はこちらになります(字幕付与前です)。
なお、右上の"Speaker 00"や"Speaker 01"は話者の変化がわかりやすいよう、事前に設定したものとなります。
実装
話者分離
まず話者分離です。話者分離は先日こちらの記事(https://qiita.com/sayo0127/items/e22fdc229d2dfd879f75 )でもあったように、pyannoteを使って話者のIDを付与していきます。
from pyannote.audio import Pipeline
from pyannote.audio.pipelines.speaker_verification import PretrainedSpeakerEmbedding
dialize_model = Pipeline.from_pretrained("pyannote/speaker-diarization")
dialize_embedding_model = PretrainedSpeakerEmbedding("speechbrain/spkrec-ecapa-voxceleb", device=torch.device("cuda"))
def run_dialize(audio_path):
# 話者分離
_dialize_result = [i.split(" ") for i in dialize_model(audio_path).to_rttm().split("\n")]
dialize_result = [[float(dr[3]), float(dr[3]) + float(dr[4]), dr[7]] for dr in _dialize_result if len(dr) ==10]
return dialize_result
run_dialize("path/to/audio_path")
# >>>
# [
# [0.498, 17.643, 'SPEAKER_00'],
# [18.487, 29.996, 'SPEAKER_00'],
# [31.21, 70.54599999999999, 'SPEAKER_00'],
# [71.272, 88.417, 'SPEAKER_00'],
# [88.417, 98.07000000000001, 'SPEAKER_01'],
# [98.93, 123.26400000000001, 'SPEAKER_01'],
# [123.871, 137.287, 'SPEAKER_01'],
# ]
このような感じで発話区間とその話者の一意のIDを取得することができます。
ただし、pyannoteも全能の神ではないので、人間が発している区間を検知できない可能性もあります。
そのため、空白時間を補完していきます。
# 以下サンプル
## before
start, end, speaker_id
12.55, 15.55, SPEAKER_00
16.55, 22.77, SPEAKER_00
32.22, 37.55, SPEAKER_01
# n秒以上空いたら、以下のようにUNKNOWNで補完する。
## after
start, end, speaker_id
12.55, 15.55, SPEAKER_00
16.55, 22.77, SPEAKER_00
22.77, 32.22, UNKNOWN
32.22, 37.55, SPEAKER_01
ここでは、空白時間を3秒としました。
さらに、後段の処理を考慮し、連続した話者を連結することとします。
イメージは以下の通りです。
# 以下サンプル
## before
start, end, speaker_id
12.55, 15.55, SPEAKER_00
16.55, 22.77, SPEAKER_00
22.77, 32.22, UNKNOWN
32.22, 37.55, SPEAKER_01
# 連続した話者を連結する
## after
start, end, speaker_id
12.55, 22.77, SPEAKER_00
22.77, 32.22, UNKNOWN
32.22, 37.55, SPEAKER_01
空白時間を補完し話者を連結すると、以下のような結果となりました。
| start | end | speaker_id | |
|---|---|---|---|
| 0 | 0.498 | 88.417 | SPEAKER_00 |
| 1 | 88.417 | 137.287 | SPEAKER_01 |
なんとなくそれっぽい結果を得ることができています。
動画の右上に表示した話者とも一致していることがわかります(偶然)。
脱線しますが、pyannoteに関してはfine-tuningなどもできるみたいなので、データがあれば今後やってみてもいいかもしれません。
https://github.com/pyannote/pyannote-audio/blob/develop/tutorials/training_a_model.ipynb
音声認識
次に、話者分離の発話区間の結果をもとに音声認識処理をしていきます。
結果は以下の通りとなりました。
| start | end | speaker_id | transcription | |
|---|---|---|---|---|
| 0 | 0.498 | 88.417 | SPEAKER_00 | それではヨロというサービスについてご紹介しますまずヨロというのはユーオンリーアップロードオンファイルの逆で音声ファイルでも動画ファイルでも画像ファイルでもどんなファイルでもアップロードしたらあとはうまく処理してくれるというような理想を掲げたサービスです具体的に何ができるのかと言いますと音声や動画ファイルの文字起こし動画への字幕自動生成画像内テキストの抽出いわゆるオーシーアール機能を備えております開発に至った背景としてはまず記者さんの取材音源の文字起こしを実現しようというところから始まりました取材音源の保管場所がなかったなり文字起こしをする作業コストがかかっていたことそしてオフレコ音源を既存のサービスで扱えないといった課題から音源を保存共有できて自動で文字起こしをしてくれて保存した音声ファイルやテキストファイルを簡単に検索することができるサービスの開発に至りましたそこからだんだんと記者の方の要望があったりもっとこういう機能があったらいいんじゃないかというように我々で考えてえー様々な機能を拡張していって今のようなサービスになりました基本的な流れとしてはまずユーザー認証をしたのち処理したいファイルをアップロードしますそしてアップロードを検知したらごじょうこしとの処理を実行し処理が完了したらエラスティックサーチに投入され文字起こし結果をメールで通知するというような流れになっております |
| 1 | 88.417 | 137.287 | SPEAKER_01 | 続きましてサムネイル抽出機能が挙げられますえっとこちらは動画がアップロードされた時にその動画に適したサムネイルを自動で抽出する機能となります先ほどデモ画面でお見せしたようにまあ画像が数枚表示されていたかと思いますがそちらがこの機能となります実際にその朝日まあ本社が持つ画像とその説明文であったりだとか朝日時に掲載されたその画像の順序だったりを学習してまあ独自のアルゴリズムを構築して提供する機能となっておりますまあこれによって検索時の一覧性が高くなるだけではなくて以外でも例えば動画編集者の方々のサムネイルを作る際のまあサポートになったりだとかそういったところにも期待が持てるような機能となっております |
上記の結果は、M研で構築した音声認識モデルによって得られた出力を表示しています。
ここで、各発話区間は内部的に15秒ごとで区切って音声認識をしています。これは、長時間の音声波形だと計算量が膨大になってしまうことや、我々が保持している音声認識のための学習データが平均約15秒で構成されているなどどいった理由からです。
また、学習データを作成する際に、人名やアルファベットをカタカナで表しているため、”ElasticSearch”が”エラスティックサーチ”、”OCR”が"オーシーアール"とカタカナになっていたりします。
この辺は、Inverse Text Normalization(https://machinelearning.apple.com/research/inverse-text-normal ) といった分野に該当すると考えられます。今後取り組んでいきたい課題の一つです。
さて、無事話者IDとともに音声認識結果を得ることができましたが、このままだと1つの発話区間が長すぎて字幕に収まりきりません。
字幕っぽい感じになるよう、適切に分割していく方法を考えていきます。
文分割
いろいろな分割方法があるかとおもいますが、今回は句読点を自動で付与するモデルを使って分割していくことにしました。
そもそも、音声認識モデルの出力は基本的には句読点はつかないことから、M研では音声認識の後処理として句読点を自動で付与するモデルを構築していました。今回はその句読点付与モデルを使って話の切れ目を推定し、その結果をもとに短い文に分割していきます。
# 以下サンプル
## 素の音声認識結果
えー自然言語処理と音声認識を活用してうーん自動で字幕を作成する仕組みを考えてみた
↓
## 句読点付与結果
えー自然言語処理と音声認識を活用して、うーん自動で字幕を作成する仕組みを考えてみた。
さらにこちらも構築済みの、「えー」や「あー」などのフィラーや不要な言葉を検知するモデルを活用することで、以下のような出力を得ます。
# 以下サンプル
## 句読点付与結果
えー自然言語処理と音声認識を活用して、うーん自動で字幕を作成する仕組みを考えてみた。
↓
## フィラー・不要検知モデル結果
(えー)自然言語処理と音声認識を活用して、(うーん)自動で字幕を作成する仕組みを考えてみた。
↓
## 句読点で分割
["(えー)自然言語処理と音声認識を活用して", "(うーん)自動で字幕を作成する仕組みを考えてみた"]
ここでは、フィラー・不要検知モデルによる結果は括弧で囲むこととします。
上記の処理を行い、以下の結果を得ました。
| transcription | punc_text | |
|---|---|---|
| 0 | それではヨロというサービスについてご紹介しますまずヨロというのはユーオンリーアップロードオンファイルの逆で音声ファイルでも動画ファイルでも画像ファイルでもどんなファイルでもアップロードしたらあとはうまく処理してくれるというような理想を掲げたサービスです ... | ['それではヨロというサービスについてご紹介します', '(まず)ヨロというのはユーオンリーアップロードオンファイルの逆で', '音声ファイルでも動画ファイルでも画像ファイルでも', '(どんな)ファイルでもアップロードしたら', 'あとはうまく処理してくれるというような理想を掲げたサービスです' ...] |
| 1 | 続きましてサムネイル抽出機能が挙げられますえっとこちらは動画がアップロードされた時にその動画に適したサムネイルを自動で抽出する機能となります先ほどデモ画面でお見せしたようにまあ画像が数枚表示されていたかと思いますがそちらがこの機能となります ... | ['続きましてサムネイル抽出機能が挙げられます', '(えっと)こちらは動画がアップロードされた時に', '(その)動画に適したサムネイルを自動で抽出する機能となります', '(先ほど)デモ画面でお見せしたように', '(まあ)画像が数枚表示されていたかと思いますが', 'そちらがこの機能となります' ...] |
ある程度自動で話の区切れ目を推定できており、検知モデルもそこそこ機能していそうです。
しかし、このままだとリストの各要素の発話区間がわからないため、字幕を表示することができません。
そのため、発話区間に該当する音声波形とテキストのリストをもとに発話区間を推定していきます。
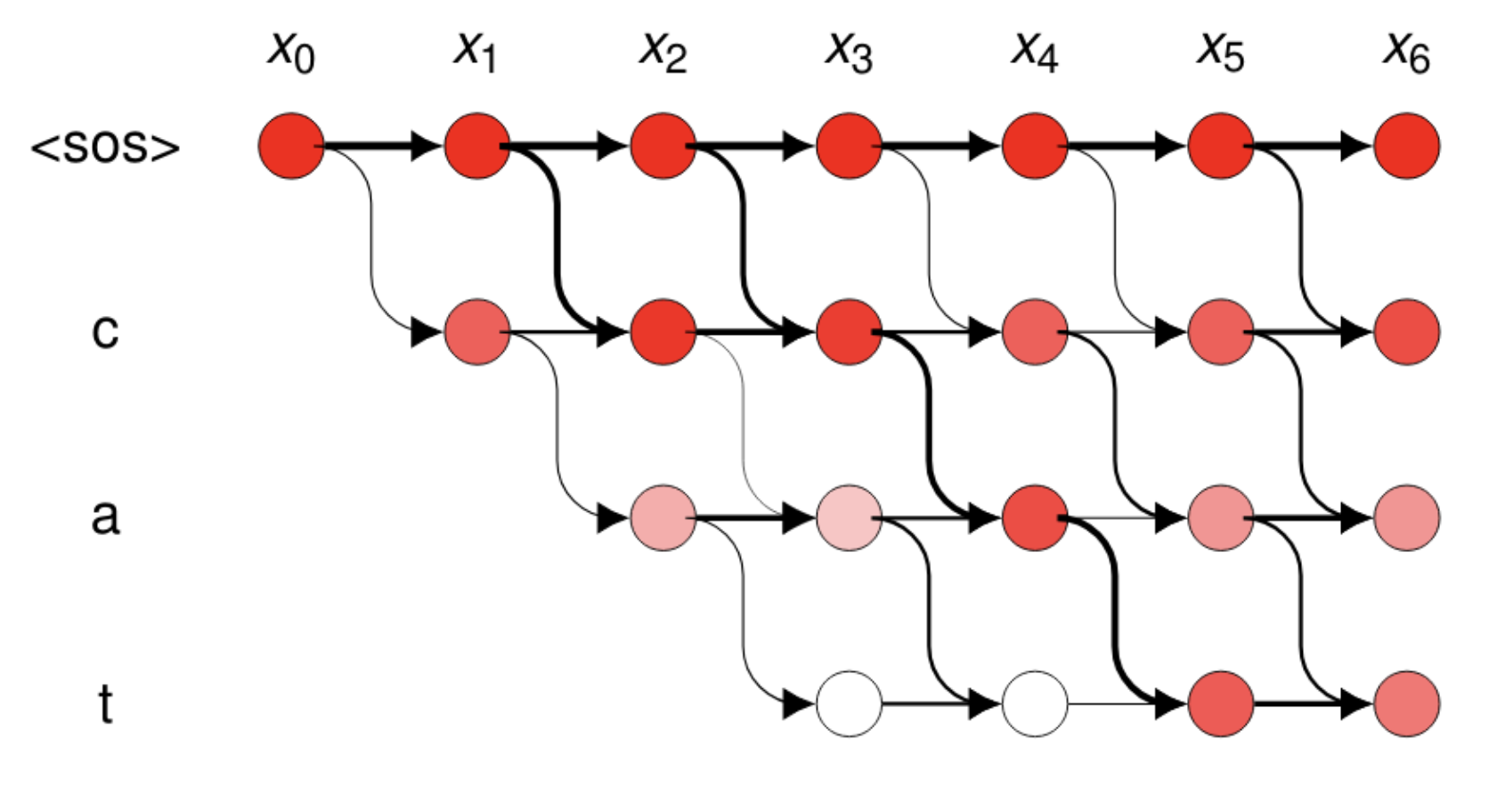
アライメント
ここでは、wav2vec2のモデルとctc-segmentationを使って各発話区間のタイムスタンプを推定していきます。
やっていることを簡単に説明します。
-
Forward Propagation
各時間ステップごとの確率をCTCから取得し、トレリス行列を生成。
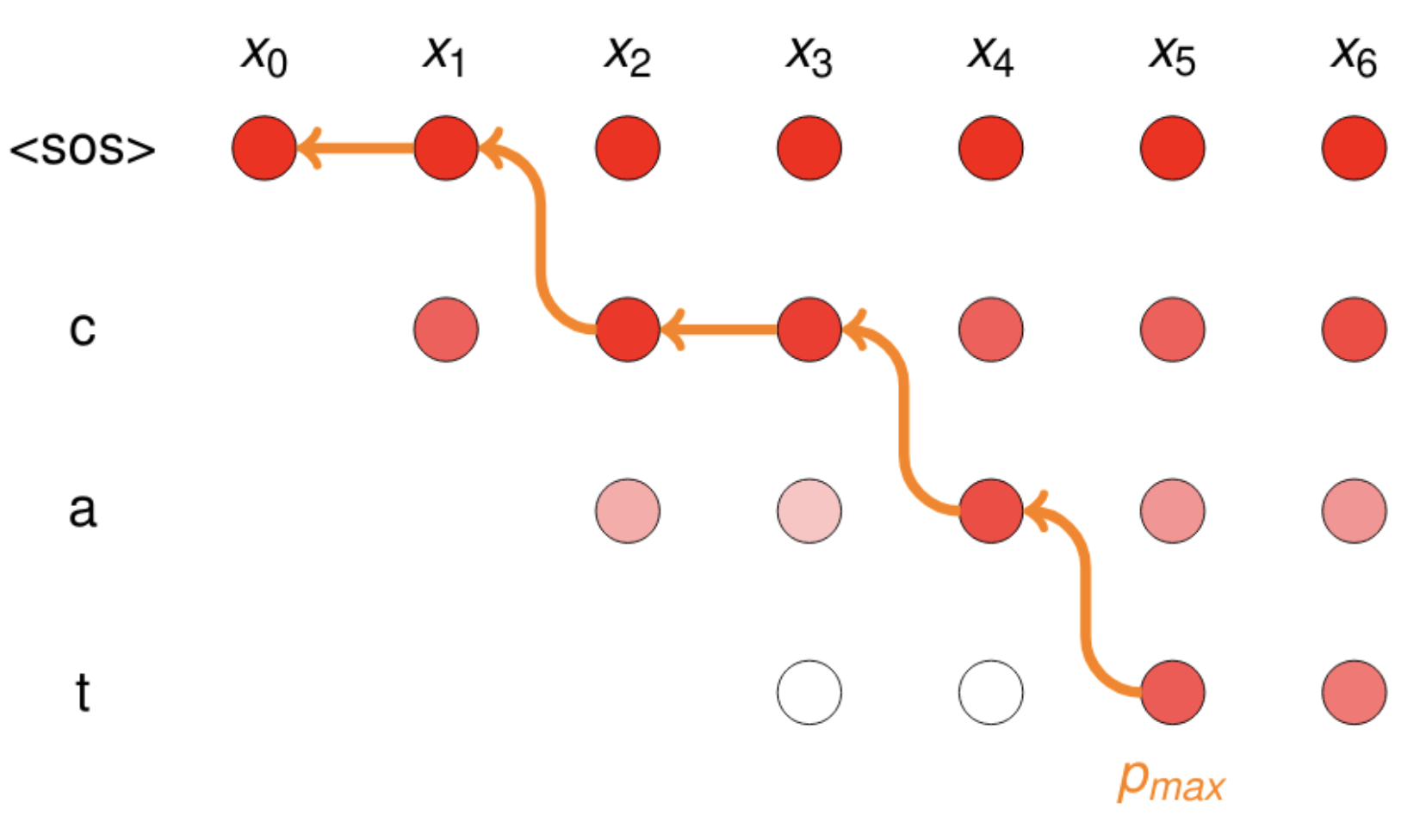
-
Backtracking
すべての時間ステップの中から最も確率の高い経路を決定する。
以上のことを踏まえ、wav2vec2のモデルを使ったctc-segmentationによるテキストのアライメント推定はこのようなスクリプトになります。
vocab = w2v2_tokenizer.get_vocab()
inv_vocab = {v:k for k,v in vocab.items()}
unk_id = vocab["[UNK]"]
char_list = [inv_vocab[i] for i in range(len(inv_vocab))]
config = ctc_segmentation.CtcSegmentationParameters(char_list=char_list)
def align_with_transcript(start, end, speaker_id, audio_array, sampling_rate, model, processor, tokenizer):
audio_array = audio_array[:, int(start*sampling_rate):int(end*sampling_rate)]
resampler = torchaudio.transforms.Resample(sampling_rate,16_000)
audio_array = resampler(audio_array).squeeze().numpy()
inputs = processor(audio_array, return_tensors="pt", padding="longest")
with torch.no_grad():
logits = model(inputs.input_values).logits.cpu()[0]
probs = torch.nn.functional.softmax(logits,dim=-1)
tokens = []
transcripts = df["punc_text"]
for transcript in transcripts:
assert len(transcript) > 0
tok_ids = tokenizer(transcript.replace("\n"," ").lower())['input_ids']
tok_ids = np.array(tok_ids,dtype=np.int)
tokens.append(tok_ids[tok_ids != unk_id])
config.index_duration = audio_array.shape[0] / probs.size()[0] / sampling_rate
ground_truth_mat, utt_begin_indices = ctc_segmentation.prepare_token_list(config, tokens)
timings, char_probs, state_list = ctc_segmentation.ctc_segmentation(config, probs.numpy(), ground_truth_mat)
segments = ctc_segmentation.determine_utterance_segments(config, utt_begin_indices, char_probs, timings, transcripts)
return [{"text": t, "start": p[0]+start, "end": p[1]+start, "speaker":speaker} for t,p in zip(transcripts, segments)]
ここで、wav2vec2のモデルは既にM研で構築したものを使用することにします。
アライメント結果は以下の通りです。
| start | end | speaker_id | alignment_punc_text | |
|---|---|---|---|---|
| 0 | 0.498 | 88.417 | SPEAKER_00 | [{'text': 'それではヨロというサービスについてご紹介します', 'start': 0.5080021615472128, 'end': 3.7787089874857793, 'speaker': 'SPEAKER_00'}, {'text': '(まず)ヨロというのはユーオンリーアップロードオンファイルの逆で', 'start': 3.7787089874857793, 'end': 8.299686006825938, 'speaker': 'SPEAKER_00'}, {'text': '音声ファイルでも動画ファイルでも画像ファイルでも', 'start': 8.299686006825938, 'end': 11.580394994311716, 'speaker': 'SPEAKER_00'}, {'text': '(どんな)ファイルでもアップロードしたら', 'start': 11.580394994311716, 'end': 13.49080784982935, 'speaker': 'SPEAKER_00'}, {'text': 'あとはうまく処理してくれるというような理想を掲げたサービスです', 'start': 13.49080784982935, 'end': 17.681605460750852, 'speaker': 'SPEAKER_00'} ...] |
| 1 | 88.417 | 137.287 | SPEAKER_01 | [{'text': '続きましてサムネイル抽出機能が挙げられます', 'start': 88.42700204666394, 'end': 91.18756692591077, 'speaker': 'SPEAKER_01'}, {'text': '(えっと)こちらは動画がアップロードされた時に', 'start': 91.18756692591077, 'end': 93.75809291854277, 'speaker': 'SPEAKER_01'}, {'text': '(その)動画に適したサムネイルを自動で抽出する機能となります', 'start': 93.75809291854277, 'end': 98.98916332378224, 'speaker': 'SPEAKER_01'}, {'text': '(先ほど)デモ画面でお見せしたように', 'start': 98.98916332378224, 'end': 101.36965042979944, 'speaker': 'SPEAKER_01'}, {'text': '(まあ)画像が数枚表示されていたかと思いますが', 'start': 101.36965042979944, 'end': 104.5102930822759, 'speaker': 'SPEAKER_01'}, {'text': 'そちらがこの機能となります', 'start': 104.5102930822759, 'end': 107.3708784281621, 'speaker': 'SPEAKER_01'} ... ] |
本来なら括弧や句読点を除外して入力した方がいいと思いますが、今回はそのような処理をしなくてもそれっぽい結果が出ました。
結果を見やすくしていきます。
| start | end | speaker | text | |
|---|---|---|---|---|
| 0 | 0.508002 | 3.77871 | SPEAKER_00 | それではヨロというサービスについてご紹介します |
| 1 | 3.77871 | 8.29969 | SPEAKER_00 | (まず)ヨロというのはユーオンリーアップロードオンファイルの逆で |
| 2 | 8.29969 | 11.5804 | SPEAKER_00 | 音声ファイルでも動画ファイルでも画像ファイルでも |
| 3 | 11.5804 | 13.4908 | SPEAKER_00 | (どんな)ファイルでもアップロードしたら |
| 4 | 13.4908 | 17.6816 | SPEAKER_00 | あとはうまく処理してくれるというような理想を掲げたサービスです |
| ... | ... | ... | ... | ... |
| 32 | 88.427 | 91.1876 | SPEAKER_01 | 続きましてサムネイル抽出機能が挙げられます |
| 33 | 91.1876 | 93.7581 | SPEAKER_01 | (えっと)こちらは動画がアップロードされた時に |
| 34 | 93.7581 | 98.9892 | SPEAKER_01 | (その)動画に適したサムネイルを自動で抽出する機能となります |
| 35 | 98.9892 | 101.37 | SPEAKER_01 | (先ほど)デモ画面でお見せしたように |
| 36 | 101.37 | 104.51 | SPEAKER_01 | (まあ)画像が数枚表示されていたかと思いますが |
| 37 | 104.51 | 107.371 | SPEAKER_01 | そちらがこの機能となります |
| ... | ... | ... | ... | ... |
| 45 | 134.366 | 137.257 | SPEAKER_01 | そういったところにも期待が持てるような機能となっております |
分割後のテキストに対してもうまく発話区間を特定できていそうです。
ここでwav2vec2は我々が既に構築したモデルを活用しておりますが、huggingfaceで公開されている日本語のwav2vec2のモデル( https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-japanese )でも推定できるかと思います。
字幕描画
さてここからは、実際に字幕を作成していきます。有名そうなmoviepy (https://zulko.github.io/moviepy/ )というライブラリを使って進めていきます。
ここで最低限やりたいことは以下の通りです。
- 発話区間に対応するテキストを適切に字幕として表示すること
- 話者によって字幕の色やフォントを変えること
早速、moviepyを使って字幕を描画してみましょう。
from moviepy.editor import VideoFileClip, TextClip, CompositeVideoClip
video = VideoFileClip("path/to/video")
def text_clip(text, start, end, color, font):
return (TextClip(text, fontsize=72, color=color, font=font)
.set_position((video.w/5, video.h - 100))
.set_duration(end-start)
.set_start(start))
clip_video = [video]
for row in subtitle_df.itertuples():
_, _, start, end, speaker, text,speaker_color, speaker_id, speaker_font = row
clip_video.append(text_clip(text, start, end, speaker_color, speaker_font))
result = CompositeVideoClip(clip_video)
result.write_videofile(
"/path/to/save_path",
codec='libx264',
audio_codec='aac',
temp_audiofile='temp-audio.m4a',
remove_temp=True
)
このように話者によってフォントや色などを変えつつ、字幕付き動画を吐き出してみます。
字幕は画面左下に書き出しており、話者ごとにフォントと色を変更しています。
結果
完全自動の割にはそこそこいい感じに字幕がついているようにも見えます。
ただ、文字が長い場合画面から見切れてしまったり、人手でつけるよりも無機質な字幕になってしまっています。
今後は文字の長さに応じて文字サイズを自動で変えたり、音声認識結果に応じて字幕のスタイルを変えたりなど行っていければなと思います。
まとめ
コンテンツ制作の一助となりうる自動字幕の作成に関して、自然言語処理、音声認識を活用して実装ができるかどうか試してみました。
字幕動画としてみた時にまだ課題が残るものの、音声認識のモデル性能を継続的に向上させ、字幕を書き出す際のスタイルやパターンを増やしていけば実運用に耐えるものになるかもしれません。
今後、検証をさらに進めてリリースできればなと思います。
最後まで読んでくださりありがとうございました。
来年も朝日新聞社とM研をYOLOしくお願いします。