音声認識の世界では、OpenAIが開発したwhisperというモデルが話題になりましたね。99言語に対応しており、日本語の音声認識の精度も抜群です。
非常に優秀なwhisperですが、いつ誰が話したのかを認識する、いわゆる「話者分離」はできません…。
ということで、アドベントカレンダー8日目の記事では、pyannote.audioというライブラリを使った話者分離方法について紹介します。
pyannote.audioの概要
pyannote.audioは、話者分離のためのPythonによるオープンソースフレームワークです。
下記のようなパイプラインで話者分離を実現しています。
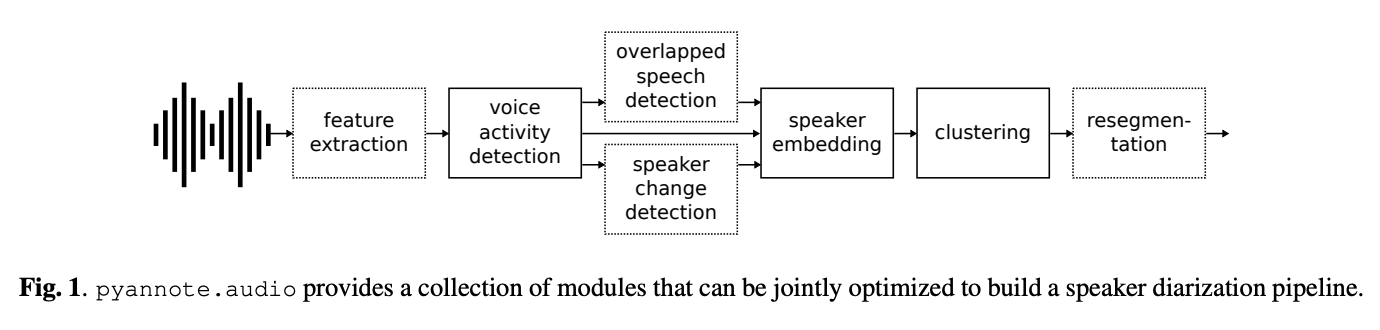
論文:pyannote.audio: neural building blocks for speaker diarization
Github:https://github.com/pyannote/pyannote-audio
論文の解説は下記の記事などをご参照ください。
https://ai-scholar.tech/articles/voice-recognition/%20pyannote
使い方
pipでインストールします。
※python3.8以上
pip install pyannote.audio
今回はこちらの日本語の音声を使用します。話者人数は2人です。
ファイルフォーマットは.wavの必要があるので、事前に変換しています。
なお、こちらの音声ファイルは下記リポジトリ内のデータセット(CC BY 4.0)から拝借しています。
https://github.com/koniwa/koniwa
※amagasaki/amagasaki__2015_01_27.mp3の一部区間を使用
音声ファイルを用意したら、下記のコードを実行するだけ。とても簡単です。
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization")
diarization = pipeline("audio.wav")
モデルのダウンロードにはHuggingFaceのaccess tokenが必要です。
notebookで実行する場合、結果はこのように図示できます。

詳細なタイムスタンプと話者情報は下記のコードで取得できます。
for turn, _, speaker in diarization.itertracks(yield_label=True):
print(f"start={turn.start:.1f}s stop={turn.end:.1f}s speaker_{speaker}")
start=0.8s stop=12.6s speaker_SPEAKER_00
start=12.6s stop=26.4s speaker_SPEAKER_01
start=27.1s stop=34.5s speaker_SPEAKER_01
start=35.3s stop=47.0s speaker_SPEAKER_01
start=47.0s stop=54.2s speaker_SPEAKER_00
start=54.8s stop=54.9s speaker_SPEAKER_00
start=54.9s stop=60.6s speaker_SPEAKER_01
start=61.4s stop=61.9s speaker_SPEAKER_01
start=62.6s stop=71.2s speaker_SPEAKER_01
start=71.9s stop=82.3s speaker_SPEAKER_01
start=82.9s stop=92.7s speaker_SPEAKER_01
start=93.5s stop=112.5s speaker_SPEAKER_00
音声ファイルを再生しながら結果のタイムスタンプを確認してみると、とてもいい感じです(雑)。
せっかくなので、音声認識結果と合わせて確認してみましょう。
ちなみに、話者人数の指定や表示エリアの設定も可能です。
-
話者人数の指定
予め話者人数がわかっている場合はnum_speakersオプションを指定すると精度向上が見込めます。
また、min_speakers・max_speakersオプションで範囲指定も可能です。diarization = pipeline("audio.wav", num_speakers=2) diarization = pipeline("audio.wav", min_speakers=2, max_speakers=5) -
表示エリアを絞る
notebookで結果を図示する際、事前に下記を実行しておくと指定した区間を拡大表示できます。
ex) 0〜30秒の区間を拡大表示from pyannote.core import Segment, notebook EXCERPT = Segment(0, 30) notebook.crop = EXCERPT
なお、デフォルトの表示に戻したい場合はnotebook.reset()を実行します。
音声認識と組み合わせてみる
それでは、pyannote.audio × whisperをやってみましょう。
組み合わせ方は様々考えられますが、今回は個人的に一番簡単だと思う方法を紹介します。
手順は下記の通りです。
- 音声ファイル全体の話者分離結果を取得する
- 1の結果の一区間毎に音声認識を行う
まず、whisperのインストールとモデルのloadを行います。今回はmediumモデルを使用します。
pip install git+https://github.com/openai/whisper.git
import whisper
model = whisper.load_model("medium")
また、pyannote.audioのインストール、モデルのloadなども前述の通りに実行します。
下記がメインの実装です(こちらを参考にしています)。
from pyannote.audio import Audio
audio_file = "audio.wav"
diarization = pipeline(audio_file)
audio = Audio(sample_rate=16000, mono=True)
for segment, _, speaker in diarization.itertracks(yield_label=True):
waveform, sample_rate = audio.crop(audio_file, segment)
text = model.transcribe(waveform.squeeze().numpy())["text"]
print(f"[{segment.start:03.1f}s - {segment.end:03.1f}s] {speaker}: {text}")
実行結果は…
[0.8s - 12.6s] SPEAKER_00: さて早くに創業再開された 真賀先の工場なんですけれどもその後の防災対策ということでは どのようなことを進められたんでしょうか
[12.6s - 26.4s] SPEAKER_01: 具体的な対策としてまず工場内 の地震対策を強化しました機械をアンカーボルトで固定したり 棚やキャビネットの点灯防止棚に置いてある事業工具の落下防止 を徹底させました
[27.1s - 34.5s] SPEAKER_01: 車内には水と食料、防災用品を備蓄し、 社員の安否確認のための連絡体制も整えました。
[35.3s - 47.0s] SPEAKER_01: また、阿摩川崎市消防局のob職員を 防災担当顧問におまねきし、社内の防災教育や防災マニュアルの 作成なども進めました。
[47.0s - 54.2s] SPEAKER_00: なるほど、まさにソフト面、ハード面両方でいろんな対策を進められたということですよね。
[54.8s - 54.9s] SPEAKER_00: you
[54.9s - 60.6s] SPEAKER_01: そして毎年春と秋には社内の防災訓練 を行っています
[61.4s - 61.9s] SPEAKER_01: 特に
[62.6s - 71.2s] SPEAKER_01: 秋の訓練は全社挙げての大規模 なもので警察や消防署の参加のもとはしご者による避難訓練なども 実施いたします
[71.9s - 82.3s] SPEAKER_01: 当社は普段から消防署とのコミュニケーション を密にとっており初活の北消防署から講習を招きしての救命講習 や訓練も実施しております
[82.9s - 92.7s] SPEAKER_01: 昨年7月には私自身も実際にできるかどうか少し不安がありましたのでAEDの使い方や心配蘇生マッサージの講習を受けました。
[93.5s - 112.5s] SPEAKER_00: そうですか素晴らしい取組みですね 私もledの使い方1回だけ講習を受けたんですけどやっぱり1回やったことあるのとないのでは全然違いますよねぜひまたね多くの 方に受講していただきたいなと思います市の方にねお問い合わせいただいたら消防署の方ですぐに受付いたしますのでよろしくお願いします
SPEAKER_00は女性の発話、SPEAKER_01は男性の発話としっかり分離できています。
音声認識も含め、いい感じではないでしょうか。
ぜひ皆さんもお試しください。