そこそこ実用的な翻訳アプリを開発しましたので、その構成や作り方を記録しておきます。コード は MITライセンスですので、参考になるところがあれば部分的にでも使ってみてください。
目次
- (1) 概要編 【このページ】
- (2) 開発環境の準備
- (3) 翻訳サービスの実装
- (4) ログサービスの実装
- (5) フロントエンド側の実装
- (6) 学習用データの作成
具体的にはこんなアプリです
NERM (Node.js + Express + React + Material-UI) ベースなWebアプリとして実装しました。
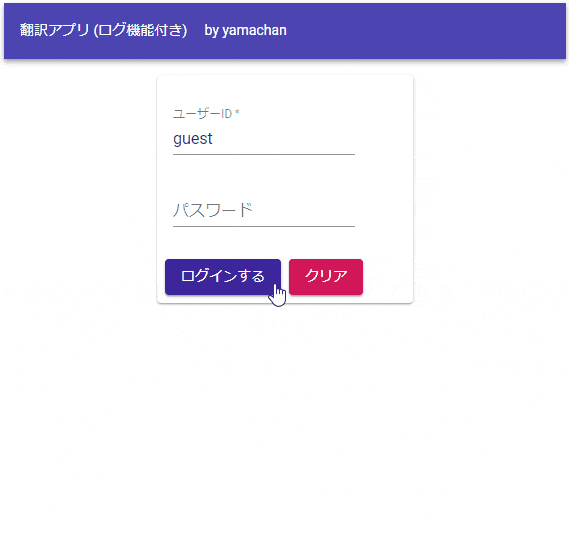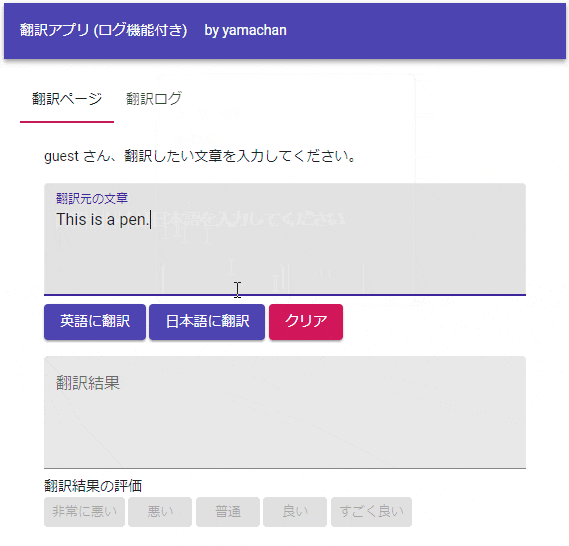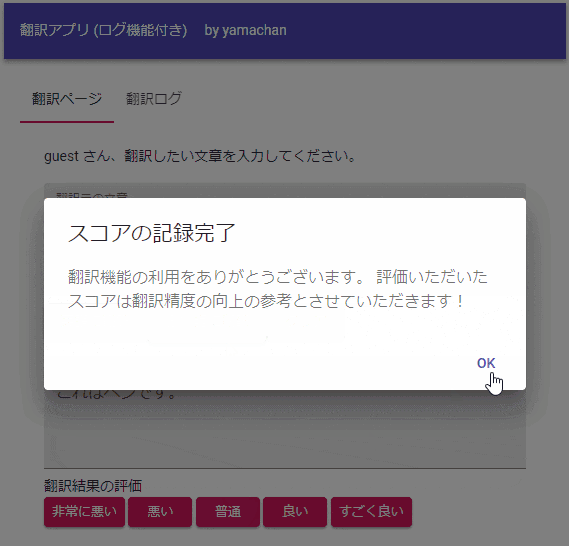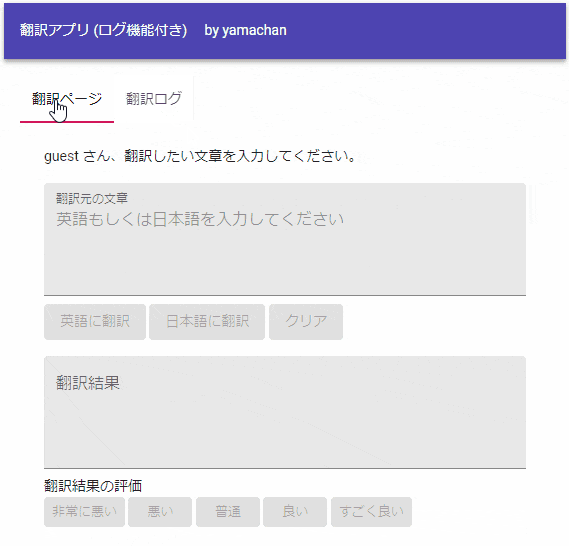
翻訳を実行した後に 5段階の評価ボタン が有効化されるのが特徴です。利用者が評価ボタンを押すことで、翻訳結果と評価がログに保存され、ポップアップ(これはデモ用)を表示した後、次の翻訳を続けることができます。
利用者は過去の翻訳ログを参照し、コピペして再利用することができます。この評価付きの翻訳ログこそ、今回作成した翻訳アプリの最大の特徴です。
実用的な翻訳ソフトとは?
最近は開発者が利用できる便利なAPIサービスが、数多く公開されています。例えば今回の翻訳アプリは IBM Cloud の Watson (AI) サービスである Language Translator (言語変換) を利用しています。
でもこれらの API を単に呼び出すだけのアプリは、実用的 ではない気がします。あくまで「サンプル」の範疇であって、API の基本機能をテストしているに過ぎない。
単に翻訳したいのであれば、翻訳アプリは幾つも販売されていますし、条件を満たすなら Google翻訳 を無料で利用できるわけで。アプリをわざわざ開発するのであれば、何らかの長所があり、既存のもしくは汎用のものを上回る実用性が欲しいところです。
AIを用いたアプリケーションの設計と運用
今回、利用する翻訳サービスは AI (Artificial intelligence, 人工知能) をベースとしたものです。であれば、当然ながら AI の長所を生かした翻訳アプリであれば、実用性があると言えるのではないでしょうか。
AIを用いたアプリケーション設計において、最も重要なのは 学習 です。状況に適応し、処理の効率を上げていくなど、いわゆる 進化 を最初から考慮にいれた設計をしておかないと、多様な可能性をもったせっかくの AI が、単なる高機能パーツ程度の効果しか発揮できないで終わってしまいます。
以下はAIを用いたアプリケーションの開発・運用のフロー図です。
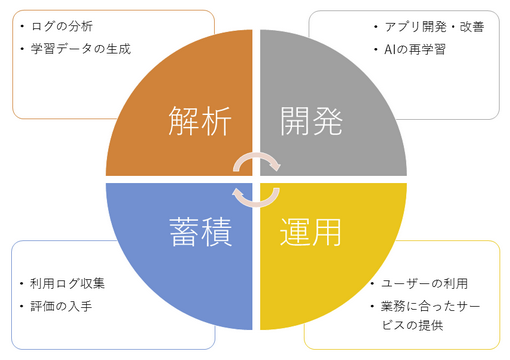
AI を用いたアプリケーションでは、開発・運用フェーズの他に、蓄積・解析 フェーズが必要だと思います。
蓄積 フェーズの目的は、アプリケーションの利用状況のログを保持しておくことです。あわせて、そのログに対する何らかの評価も同時に入手する必要があります。明示的に利用者に入力してもらうか、利用者の行動から評価を生成するか、このあたりをうまく、利用者への負担が少ないカタチでアプリに組み込むには、アプリの設計段階から上記のサイクルに関して考慮しておく必要がありそうです。
そうやって蓄積したログ、そして評価を解析して、AI の再学習(進化)のための学習データを生成するのが 解析 フェーズです。より効率的に、もしくはより対象の環境にあった AI に成長させるために、このフェーズは非常に重要です。
翻訳アプリにおける進化とは?
AI を説明する場合、翻訳アプリは理解のし易い題材のひとつだとおもいます。
日本語を英語に翻訳する、逆に英語を日本語を翻訳する、どちらもよく利用する機能です。そして現時点で 万能の翻訳エンジン がまだ存在しておらず、皆何かしらの不満をもち、改善点が多く存在するアプリケーションではないでしょうか。
さて、翻訳アプリにおける進化、そしてそれに必要とされる学習データとはどんなものでしょう?今回利用する Watson Language Translator (言語変換) では、以下のマニュアルが参考になりそうです。
専用辞書(強制用語集)の作成
ざっくりと読むと、まずは 専用辞書(強制用語集) の作成により翻訳モデルを改善できることがわかります。これは訳してはいけない用語、訳し方が特殊な用語をまとめた専用辞書です。どの業界でも、更に会社ごとに、そして同じ会社でも職種ごとに、他ではあまり使わない製品名、特殊用語、専門用語などがあるものです。
例えば 'International Business Machines' という英語を Google 翻訳すると '国際事務機' と翻訳されます。これで間違っているわけではないのですが、これ、IBM という米国の会社の正式名称なんです。つまり会社名・固有名詞であり、訳さないほうが良い場合もあるわけです。
※ この固有名詞への対応は (6) 学習用データの作成 で実施します
今回のアプリでは特に低評価のログが、この専用辞書を作成する際に参考になると思います。利用者の意に添わぬ変換をして評価が下がるわけで、そういったログに多く含まれる変換が、その利用環境における特殊な変換、つまり専用辞書の対象を見つける良いソースになると期待できます。
単一言語コーパスの作成
上記のマニュアルでもうひとつ出てくるのが、言語サンプルとして機能するターゲット言語による 大量のテキスト本文(単一言語コーパス) です。
これは翻訳対象の言語(今回だと英語と日本語)における、いわゆる 良い文章 を集めたデータを用意し、それをもとにモデルを学習させることで、より良い翻訳結果を得ようとするものです。
今回のアプリでは特に高評価のログが、このコーパスを作成する際に良い情報源になると思います。翻訳した結果、利用者が「すごく良い」と判断した翻訳結果ですから、それを集めれば良い言語サンプル(コーパス)になることが期待できます。
実際の実装について
今回の翻訳アプリは、いわゆる NERM (Node.js + Express + React + Material-UI) ベースなWebアプリとして実装しました。
翻訳サービスとしては IBM Cloud の Watson (AI) サービスである Language Translator (言語変換) を利用しています。
またログの保存には同じく IBM Cloud 上の NoSQL DB である Cloudant DB サービスを利用してユーザーごとの翻訳ログを保存(永続化)しています。
というわけで
さて、ざっと概要を説明したところで、実際の開発にはいりましょう。次回は (2) 開発環境の準備 を実施します。GitHub 上の ソースコード も参照してみてください。