Google Cloud Next Tokyo2023でBigQueryからVertexAIのLLMを使用する話を聞いてきたので試してみる。
質問に対して、グラウンディング用データを参照しつつLLMで回答するということをSQLで実装できた。
全体的にはこんなイメージ。

準備
BigQuery Connection API を有効にする
外部接続の作成
BigQueryの画面の左上のエクスプローラの追加をクリック

外部データソースへの接続をクリック
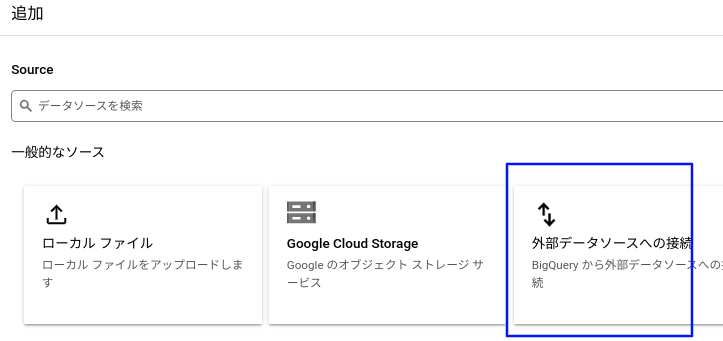
以下を設定して接続を作成
- 接続タイプ:BigLakeとリモート関数
- 接続ID:llm-conn
- ロケーション:マルチリージョンでUS(対象のデータセットと同じロケーション?)

外部接続が作成された

権限設定
外部接続で作成されたサービスアカウント(外部接続画像のサービスアカウントID)に[Vertex AI ユーザー] ロール権限を付与する
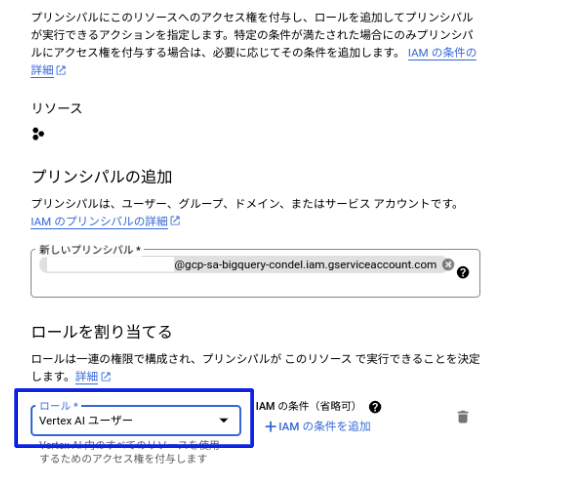
モデルを作成する
以下を使ってみる
LLM:リモートサービスのCLOUD_AI_LARGE_LANGUAGE_MODEL_V1
Embedding:エンドポイントのtextembedding-gecko-multilingual
CREATE OR REPLACE MODEL `project_id.dataset.model_name`
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
CREATE OR REPLACE MODEL `project_id.dataset.model_name_embedding`
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (ENDPOINT = 'textembedding-gecko-multilingual');
グラウンディングを用いた情報検索をする

要は自社のデータ等をLLMに渡して、LLMの学習していないデータを用いて回答してもらう方法
グラウンディング用のデータ(埋め込み、Embedding)を作成する

要は質問に似通ったデータを抽出しやすくするためのプロセスで、テキストデータを数値化(ベクトル化)する
まず以下のような色々な文章が記載されている項目(text列)をもつテーブルを作成する
(今回はChatGPTに小売店でのサンプルFAQを作ってもらった)

埋め込み列をもつテーブルを作成する
埋め込みを作成したい列はcontentというエイリアスにしておく必要がある
元々contentという列の名前をもつテーブルであればテーブルの指定だけでも良い
create table `project_id.dataset.table_name_embedding`
as
(
select *
from
ML.GENERATE_TEXT_EMBEDDING(
MODEL `project_id.dataset.model_name_embedding`,
(
select
text as content
from
`project_id.dataset.table_name_embedding`
),
STRUCT(TRUE AS flatten_json_output) --jsonデータを展開して列にするかのオプション
)
);
こんな感じのtext_embedding列を持つテーブルが作成された
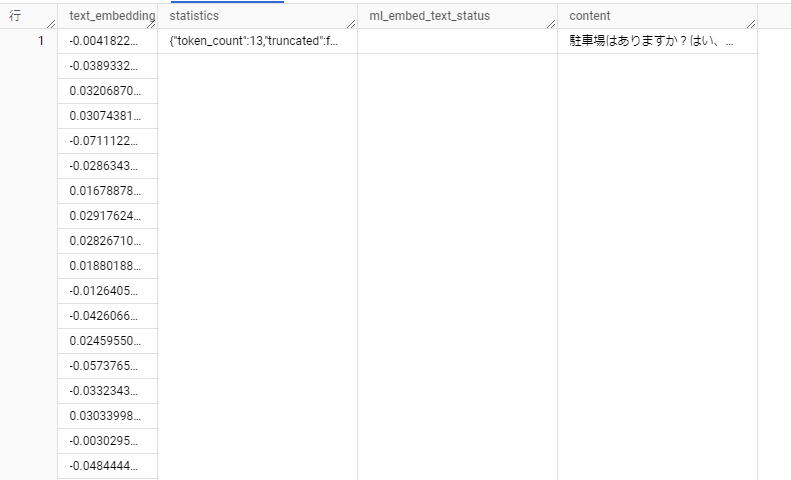
埋め込んだテキストのk-meansモデルを作成する
埋め込みを 10 個のクラスタに分類するk-meansモデルを作成する
いきなり埋め込み同士の距離計算するより、埋め込みの近いクラスタのデータのみで距離計算した方がパフォーマンスが良いらしい
CREATE OR REPLACE MODEL `project_id.dataset.model_name_cluster`
OPTIONS (
model_type = 'KMEANS',
KMEANS_INIT_METHOD = 'KMEANS++',
num_clusters = 10) AS (
SELECT
text_embedding
FROM
`project_id.dataset.table_name_embedding`
);
質問に近いデータを抽出する
質問内容を埋め込みし、質問内容が属するクラスタを予測する
WITH query_test as
(
SELECT
*
FROM
ML.GENERATE_TEXT_EMBEDDING(
MODEL `project_id.dataset.model_name_embedding`,
(SELECT
"現金以外の支払いはできますか" AS content),
STRUCT(TRUE AS flatten_json_output))
)
SELECT
centroid_id,
text_embedding
FROM
ML.PREDICT(
MODEL `project_id.dataset.model_name_cluster`,
(SELECT
text_embedding
FROM
query_test)
);
こんな感じにクラスタIDが7で埋め込まれた結果が返ってくる
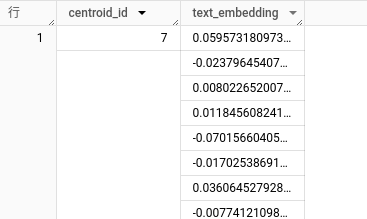
グラウンディング用のデータから同一クラスタのデータを抽出する
SELECT
*
FROM
ML.PREDICT(
MODEL `project_id.dataset.model_name_cluster`,
(SELECT
text_embedding,
content
FROM
`project_id.dataset.table_name_embedding`)
)
WHERE centroid_id = 7
;
クラスタ内で質問内容との距離を計算する
ここまでの内容を組み合わせて、同一クラスタ内で、質問と最初に作成したテーブルの文章で埋め込みのベクトルの距離(コサイン類似度)を計算する
WITH
--質問文の埋め込み
query_test as
(
SELECT
*
FROM
ML.GENERATE_TEXT_EMBEDDING(
MODEL `project_id.dataset.model_name_embedding`,
(SELECT
"現金以外の支払いはできますか" AS content),
STRUCT(TRUE AS flatten_json_output))
),
--質問文のクラスタ抽出
query_cluster as
(
SELECT
centroid_id,
content,
text_embedding
FROM
ML.PREDICT(
MODEL `project_id.dataset.model_name_cluster`,
(SELECT
text_embedding,
content
FROM
query_test)
)
),
--グラウンディング用データから質問文と同じクラスタを抽出
answer_cluster as
(
SELECT
*
FROM
ML.PREDICT(
MODEL `project_id.dataset.model_name_cluster`,
(SELECT
text_embedding,
content
FROM
`project_id.dataset.table_name_embedding`)
)
WHERE centroid_id in (select centroid_id from query_cluster)
)
--質問文と同一のクラスタのグラウンディングデータから質問文と距離が近い順に出力する
SELECT
s.content AS search_content,
c.content AS content,
ML.DISTANCE(s.text_embedding, c.text_embedding, 'COSINE') AS distance
FROM
query_cluster AS s,
answer_cluster AS c
ORDER BY
distance ASC
;
それっぽい結果が返ってきた

LLMに回答させる
質問内容とグラウンディング用の回答からLLMに回答させてみる
SELECT
prompt as query,
string(ml_generate_text_result.predictions[0].content) as answer
FROM
ML.GENERATE_TEXT(
MODEL `project_id.dataset.model_name`,
(
SELECT
CONCAT(
'質問内容に以下の情報を用いながら回答してください。',
'質問内容:','現金以外の支払いはできますか',
' 情報:', '店舗でのクレジットカード支払いは可能ですか?はい、主要なクレジットカードでの支払いを受け付けています。') AS prompt
),
STRUCT(
0.1 AS temperature,
1000 AS max_output_tokens,
0.1 AS top_p,
10 AS top_k));
それっぽく返ってきた

一連の流れをプロシージャにする
ここまでの流れをプロシージャにまとめて、質問内容を引数に渡してLLMからの回答をもらえるようにする
pythonから使用することも考慮し、OUT引数も設定しておく
CREATE OR REPLACE PROCEDURE `project_id.dataset.procedure_name`(
query_string STRING,
OUT llm_answer STRING
)
BEGIN
DECLARE grounding STRING;
DECLARE prompt_pre STRING DEFAULT '質問内容に以下の情報を用いて自然な文章で回答してください。' ;
DECLARE prompt_suf STRING DEFAULT 'なるべく詳細に回答してください。';
-- 質問からグラウンディングデータに一番近いものを取得する
SET grounding = (
WITH query_test as
(
SELECT
*
FROM
ML.GENERATE_TEXT_EMBEDDING(
MODEL `project_id.dataset.model_name_embedding`,
(SELECT
query_string AS content),
STRUCT(TRUE AS flatten_json_output))
),
query_cluster as
(
SELECT
centroid_id,
content,
text_embedding
FROM
ML.PREDICT(
MODEL `project_id.dataset.model_name_cluster`,
(SELECT
text_embedding,
content
FROM
query_test)
)
),
answer_cluster as
(
SELECT
*
FROM
ML.PREDICT(
MODEL `project_id.dataset.model_name_cluster`,
(SELECT
text_embedding,
content
FROM
`project_id.dataset.table_name_embedding`)
)
WHERE centroid_id in (select centroid_id from query_cluster)
)
--質問とグランディング用データで一番距離の近いデータを抽出する
SELECT
c.content AS content,
FROM
query_cluster AS s,
answer_cluster AS c
QUALIFY
ROW_NUMBER()OVER(order by ML.DISTANCE(s.text_embedding, c.text_embedding, 'COSINE') ASC) = 1) ;
--LLM回答用のデータを取得する
SET llm_answer = (
SELECT
string(ml_generate_text_result.predictions[0].content) as answer
FROM
ML.GENERATE_TEXT(
MODEL `project_id.dataset.model_name`,
(
SELECT
CONCAT(
prompt_pre,
'質問内容:',query_string,
' 情報:', grounding,
prompt_suf) AS prompt
),
STRUCT(
0.1 AS temperature,
1000 AS max_output_tokens,
0.1 AS top_p,
10 AS top_k))
);
SELECT llm_answer;
END;
プロシージャを実行する
DECLARE result STRING;
call `project_id.dataset.procedure_name`('返品はできますか。', result);
それっぽく返ってきた

pythonでストアドの返り値を取得する
google colabでストアドの返り値を取得するには以下の感じで、ストアド実行後にOUT引数をSELECTする
from google.colab import auth
auth.authenticate_user()
from google.cloud import bigquery
client = bigquery.Client(project='<project_id>')
# ストアドプロシージャを実行するクエリ
query = """
DECLARE result STRING;
call `project_id.dataset.procedure_name`('返品はできますか。', result);
SELECT result;
"""
# クエリの実行
query_job = client.query(query)
# 結果の取得
results = query_job.result()
for row in results:
print(row[0])
参考
BigQuery で Vertex AI モデルを使って、SQL のみで LLM のテキスト生成を実行する
The CREATE MODEL statement for remote models
ML.GENERATE_TEXT_EMBEDDING 関数を使用してテキストを埋め込む
テキスト エンベディングを使用して基本的なセマンティック検索を行う
The ML.DISTANCE function
SQL ストアド プロシージャを操作する