はじめに
Qiitaへの初投稿です。半年間、独学で機械学習やGCPについて学習したアウトプットとして記事を書きました。間違いなどございましたら、ご指摘いただけると幸いです。随時、加筆修正いたします。今回使用するコードはこちらのレポジトリにあります。
この記事では、Kubeflow Pipelinesを用いた機械学習パイプラインの自動化について記述します。Courseraの講座をベースにしました(当該GitHubレポジトリはこちら)。設計にはこちらのドキュメントが参考になります。
目的
パイプラインの実行を自動化することにより、機械学習モデルの運用コストを下げることを目的としています。具体的には、コードの変更後に、モデルの訓練・評価・デプロイなどのタスクを自動で実行されます。また、コンポーネントの追加が容易であるようなパイプラインを構築することで、段階的な機械学習モデルの導入を実現することができると考えられます。今回は、この目的を実現するために、Kubeflow PipelinesとGoogle Cloud Platformの各種サービスを利用します。
概要
Architecture
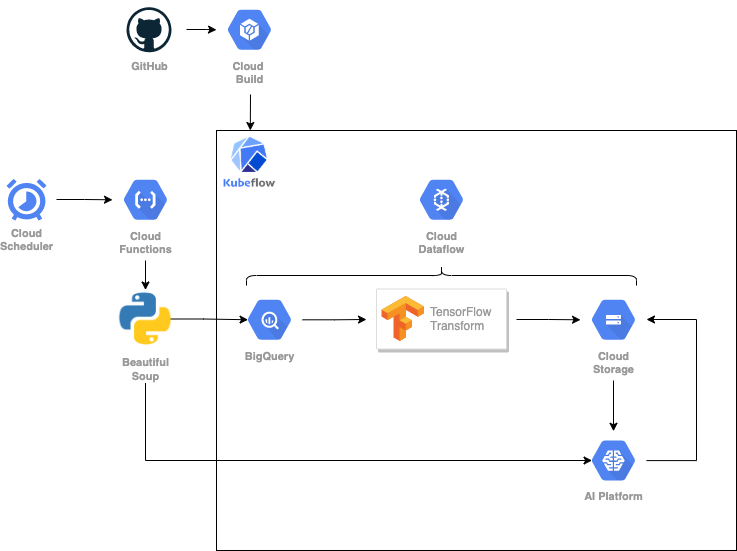
今回は、24時間分の気象データから、翌24時間分の気温の予測を作成するシステムを作ります。前準備として、気象庁から過去の気象データをスクレイピングし、BigQueryにアップロードします。パイプラインの構成には、Kubeflow pipelinesを用います。
ここから、パイプラインのコンポーネントを説明します。まず、Dataflowを用いて、データの分割・前処理・保存を行います。データの前処理に関しては、TensorFlow Transformを利用します。BigQueryのレコードを時系列に沿って分割抽出し、train, valid, testの3つのデータセットを作成します。train, validセットについては前処理を施し、それぞれのデータセットをCSVファイルに書き込んでCloud Storageへと保存します。
ここからは、AI Platform上でTensorFlowを使用します。まず、tf.dataでデータセットに時系列データ解析のためのwindow処理を行います。そして、tf.kerasとTensoFlow Addonsでseq2seqモデルを作成します。window処理したデータでこのモデルを訓練します。ハイパーパラメーターチューニングをした後に、再訓練を行い、モデルをTensorFlow Transformの前処理関数と併せて、Cloud Storageへと保存します。さらに、保存したモデルをロードし、テストセットを使って評価します。評価指標が事前設定した閾値より良ければデプロイします。デプロイ時には、カスタム予測ルーチンの設定をします。以上がパイプラインの概要です。
最後に、上記のパイプラインを実行するためのビルド構成ファイルを準備し、Cloud Buildを利用して、「GitHubのリモートレポジトリへの新しいtagのpush」などをトリガーとして、ビルド構成ファイルを自動実行するように設定します。1日1回のスクレイピングやオンライン予測の作成を実行プログラムをCloud FunctionsとCloud Schedulerを用いて実装し、システム全体の完成です。
Requirements
- Python 3.7
- TensorFlow 2.5.0
- TensorFlow Tansform 1.1.0
- TensorFlow Addons 0.13.0
- Kubeflow Pipelines
- GCP
- AI Platform
- Cloud Storage
- BigQuery
- Dataflow
- Cloud Build
- Cloud Functions
- Cloud Scheduler
ディレクトリ構造
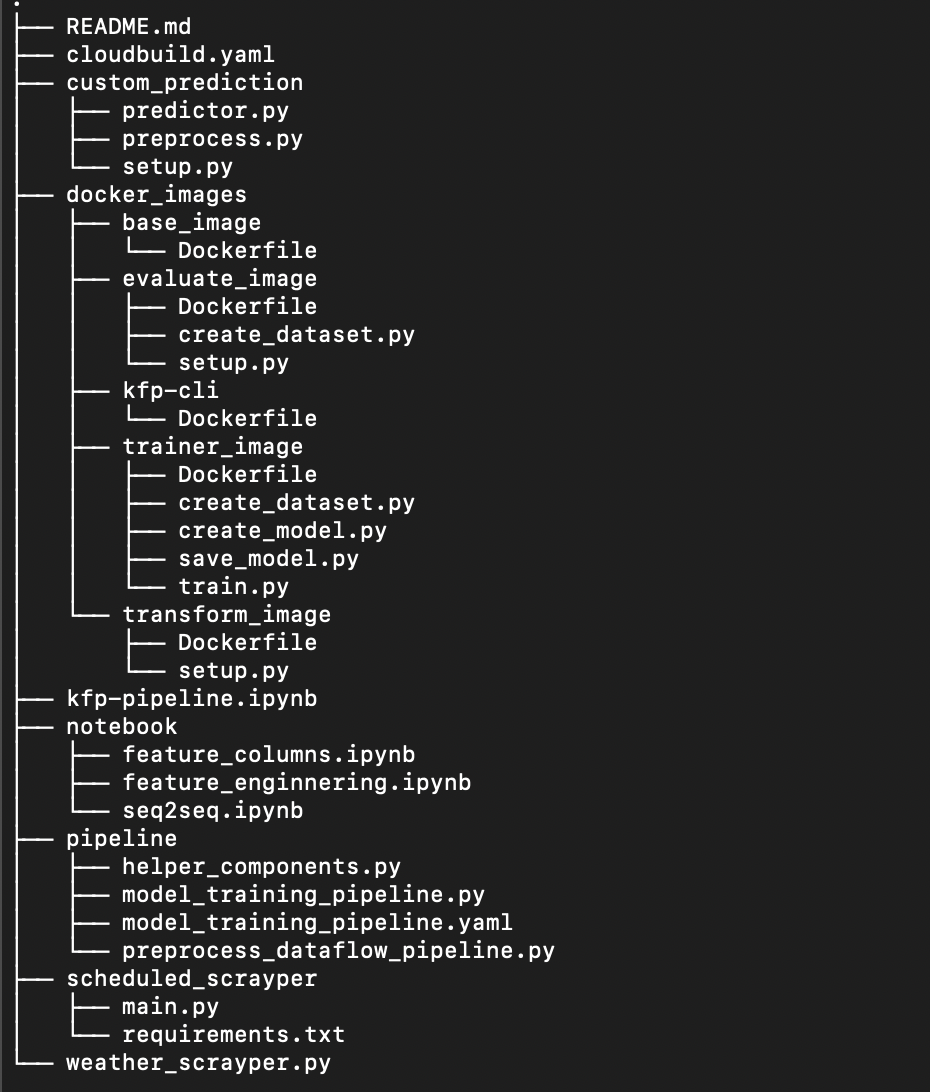
今回使用するディレクトリの構成は次のようになっています。
下準備
データセットの作成
使用ファイル
まず始めに、今回使用するデータセットの準備をします。気象庁の過去の気象データ検索からスクレイピングし、BigQueryのテーブルにアップロードします。取得するデータは、東京都の1時間ごとの値で、「時、気圧(現地、海面)、降水量、気温、湿度、風向、風速、日照時間、全天日射量」の列を使用します。本サイトでは、毎日午前2時頃に前日分のデータが更新されます。
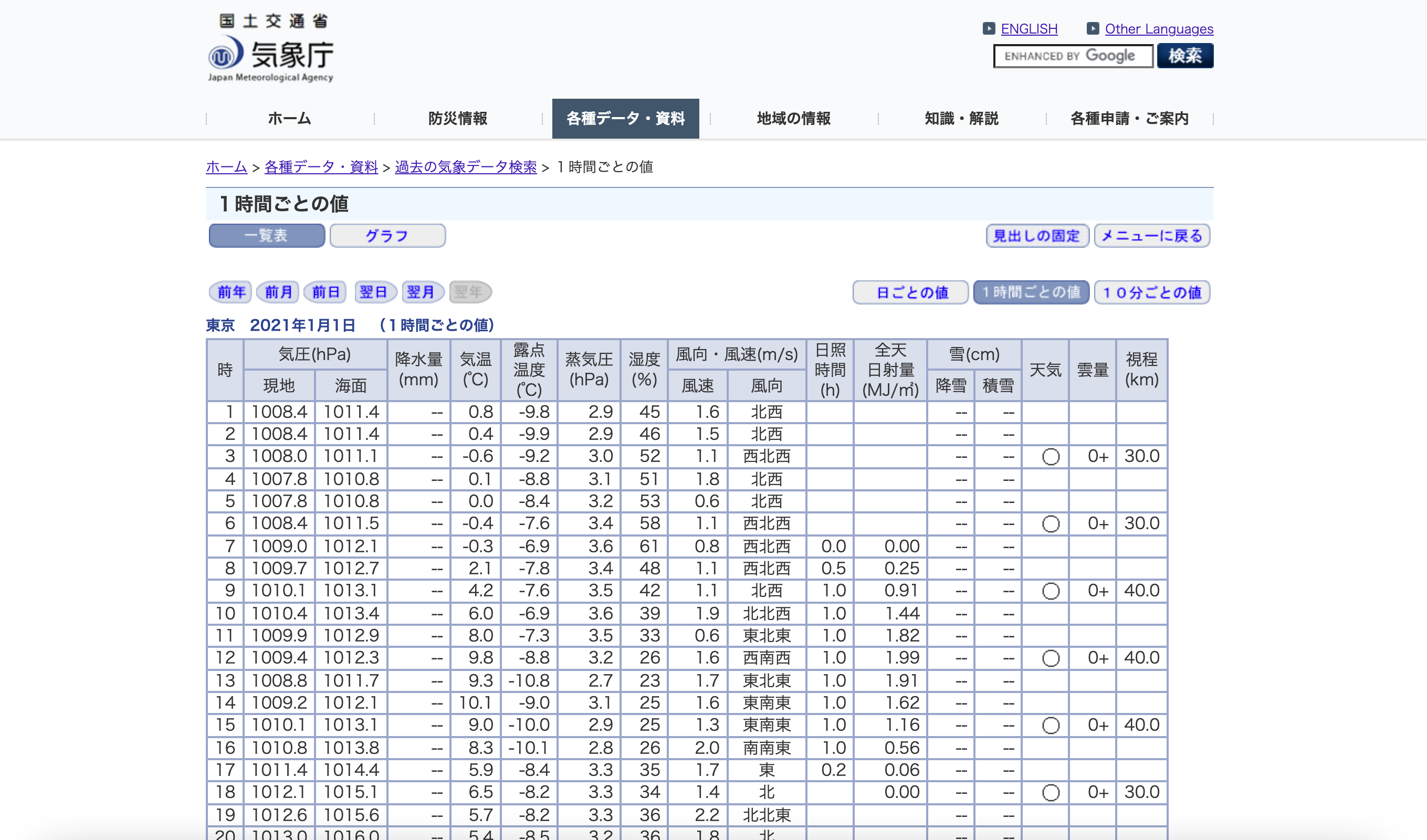
BeautifulSoupを用いてWebスクレイピングを行います。こちらの記事を参考にしました。ここで、BigQueryのテーブルへの書き込みを検討しましたが、大量の書き込みは不正なリクエストとして検知されてしまいます。そのため、今回はCSVファイルに書き込んでからBigQueryへとアップロードします。取得するデータの期間は、2011年1月1日の午前1時〜プログラム実行日の午前0時です。
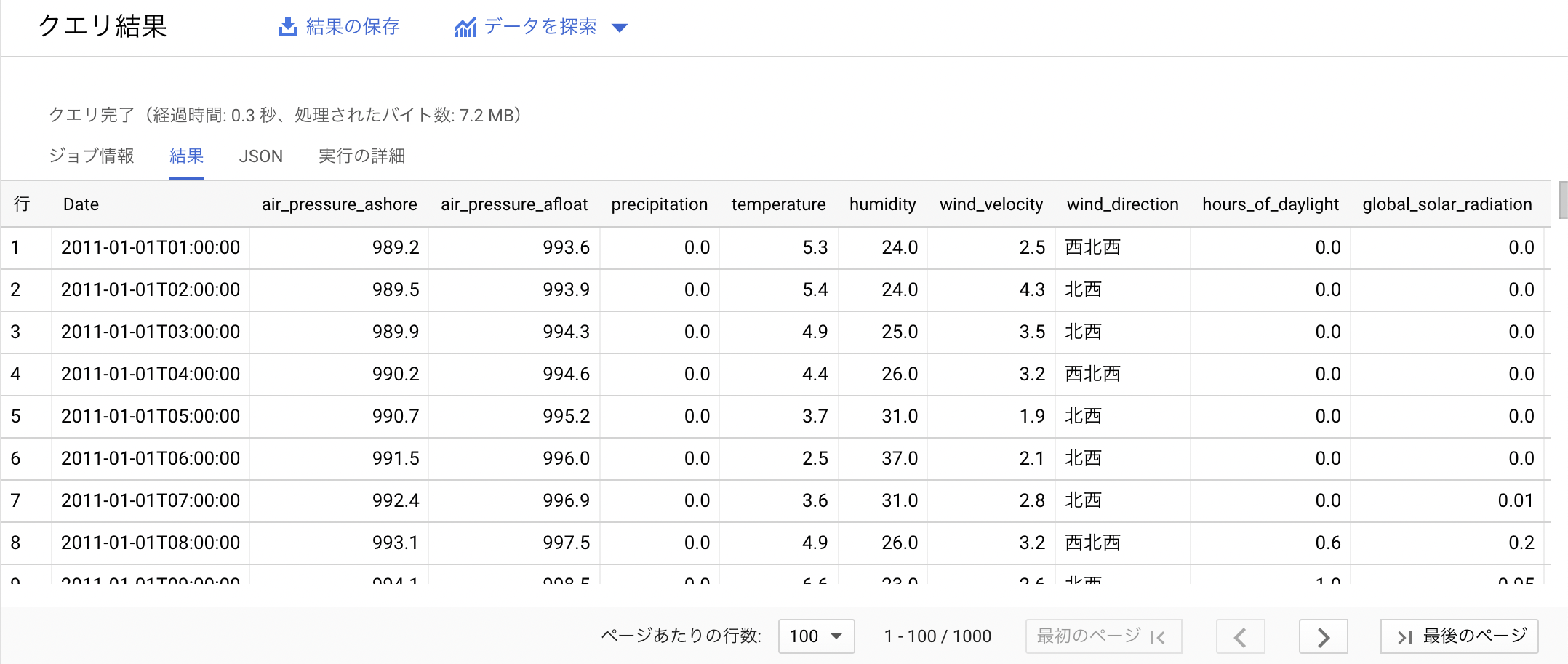
こちらのプログラムを実行後、CSVファイルが作成されたら、BigQueryへとアップロードします。この際、スキーマは自動取得ではなく、以下の様に設定します。詳細設定から、ヘッダーの1行分をスキップします。テーブル名はtokyoとしました。
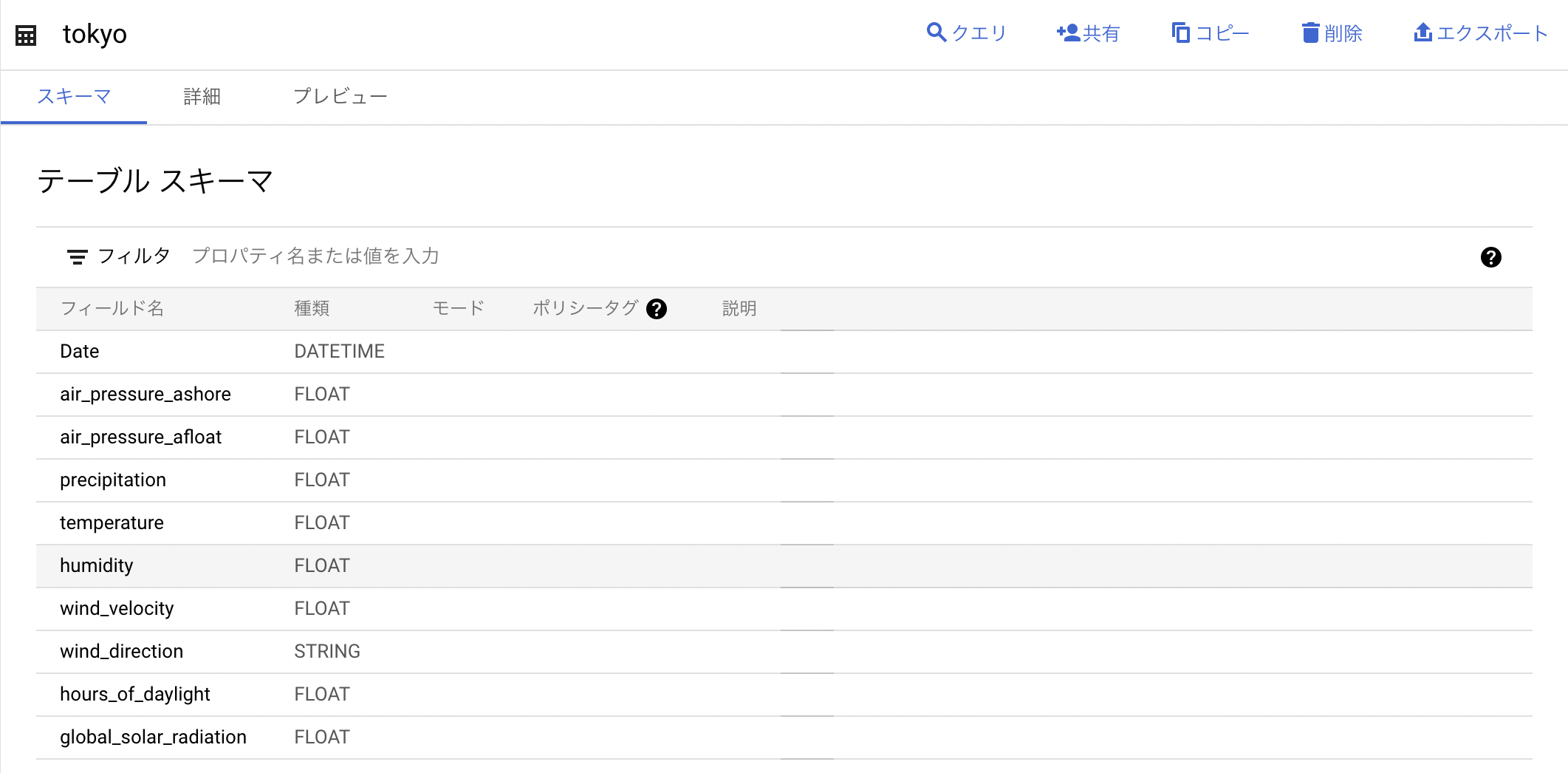
アップロードジョブが終了したら、レコードの確認をします。日照時間・全天日射量の欠損値は0.0で埋めています。この時点で、特徴量の数は10個となっています。
GKEクラスターの作成
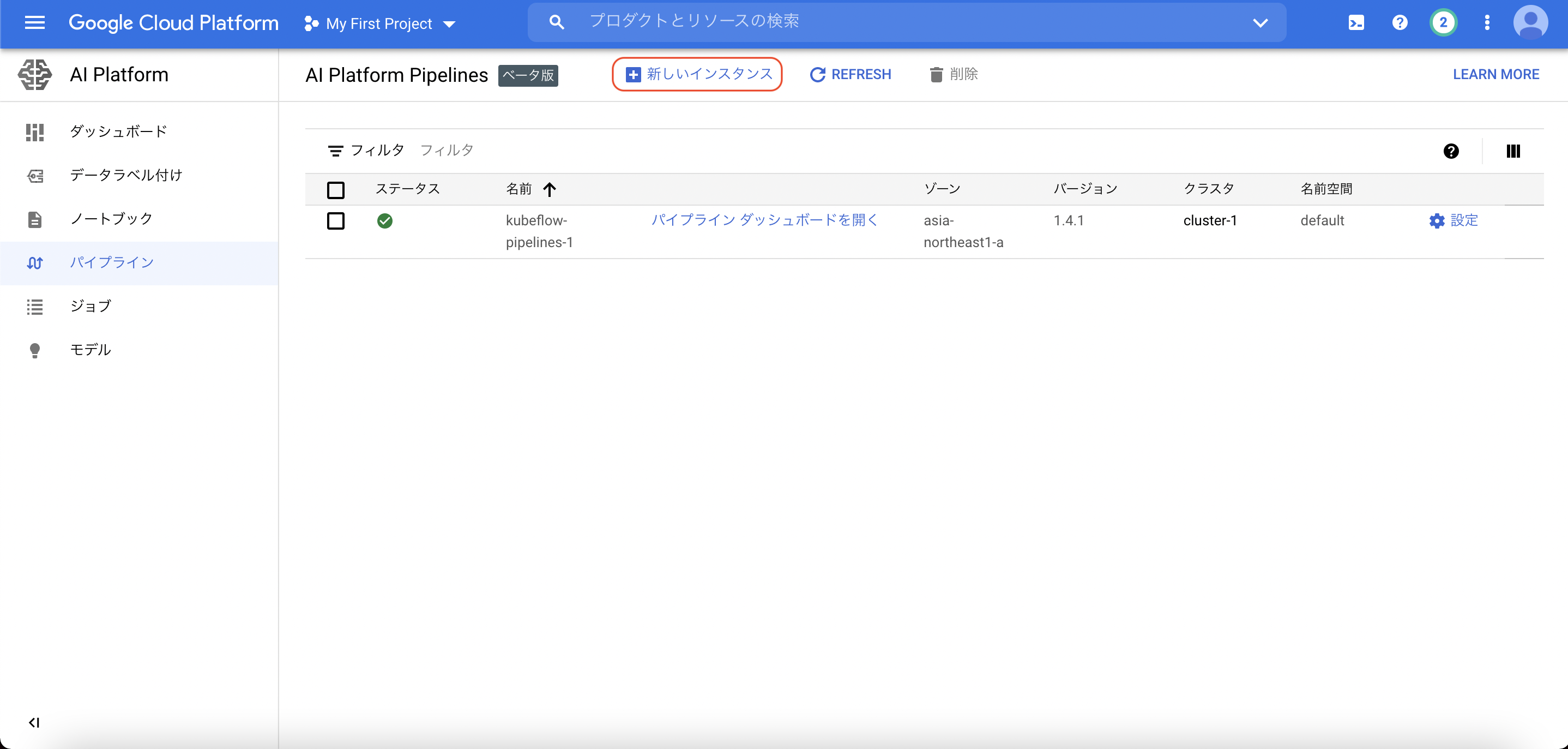
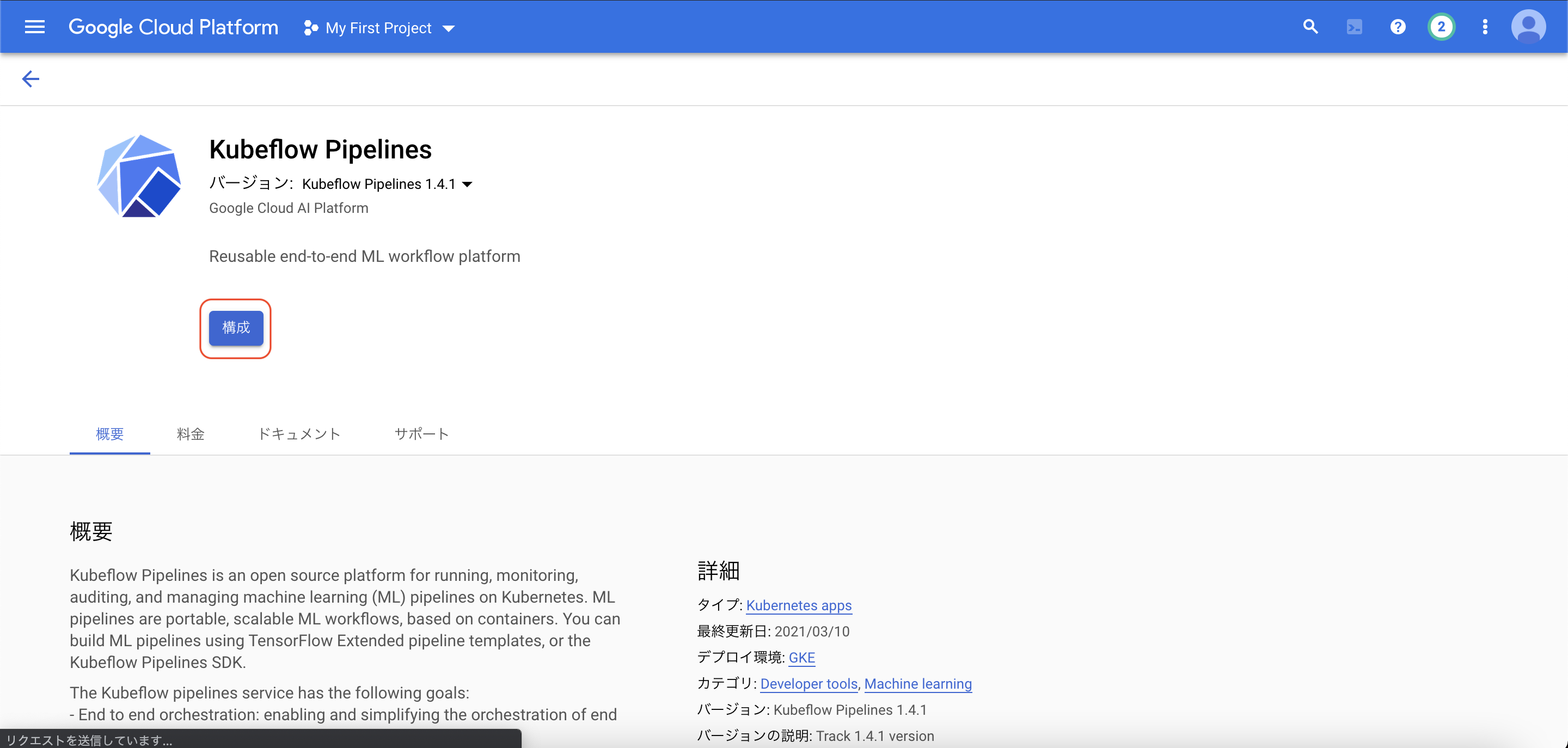
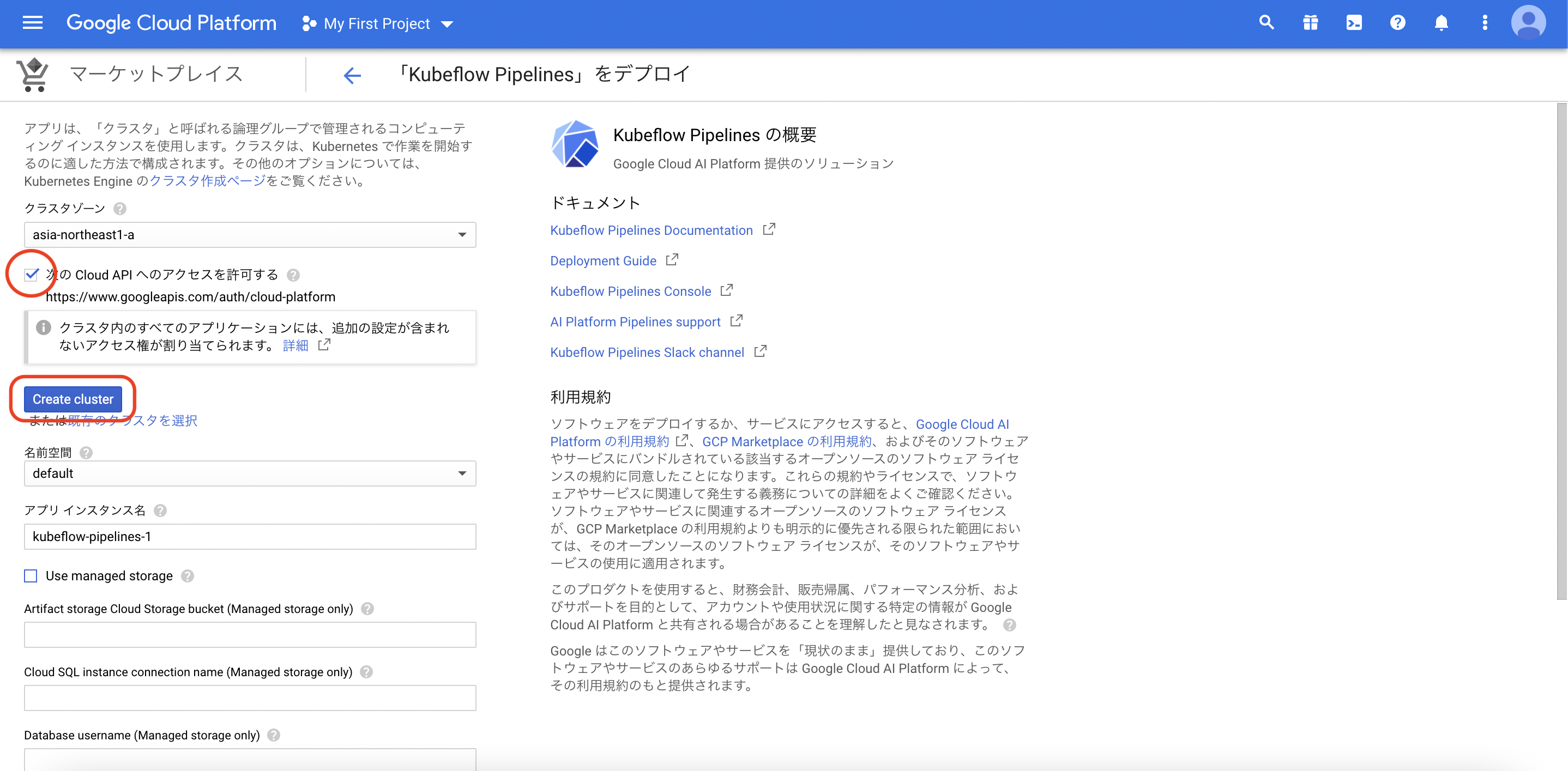
次の手順で、GKEクラスターの作成とデプロイをします。クラスターの作成後、画面最下部よりデプロイします。最後に、こちらを参考に、Kuberneteシークレットを使用して、クラスタにGoogle CloudリソースとAPIへのアクセスを許可します。比較的時間のかかるトレーニングジョブを実行した際に、BrokenPipeLineが出てしまうので、それを防ぐためにこの設定をします。エラーの詳細は、こちらのissueが参考になります。
Kubeflow Pipelines
使用ファイル:
今回パイプラインの作成に使用するKubeflow Pipelineについては、こちらのドキュメントが参考になります。
Kubeflow Pipelines は、以下で構成されます。
・一連のコンテナ化された ML タスク、またはコンポーネント。パイプライン コンポーネントは、Docker イメージとしてパッケージ化された自己完結型のコードです。コンポーネントは、入力引数を受け取り、出力ファイルを生成し、パイプラインで 1 つのステップを実行します。
・Python ドメイン固有の言語(DSL)で定義された ML タスクのシーケンスの仕様。ワークフローのトポロジは、上流ステップの出力を下流ステップの入力に接続することによって暗黙的に定義されます。パイプライン定義のステップは、パイプライン内のコンポーネントを呼び出します。複雑なパイプラインでのコンポーネントは、ループで複数回実行される場合や、条件付きで実行される場合があります。
・パイプライン入力パラメータのセット。値はパイプラインのコンポーネントに渡されます。データのフィルタリング条件や、パイプラインが生成するアーティファクトの保存場所が含まれます。
パイプライン全体はこちらのファイルをご覧ください。今回は、事前定義されたGoogle Cloudコンポーネントと軽量のpythonコンポーネントを使用します。事前定義されたGoogle Cloudコンポーネントについては、上記の記事で次のように説明されています。
事前定義された Google Cloud コンポーネントの使用: Kubeflow Pipelines は、必須パラメータを指定することで、Google Cloud でさまざまなマネージド サービスを実行する事前定義されたコンポーネントを提供します。これらのコンポーネントは、BigQuery、Dataflow、Dataproc、AI Platform などのサービスを使用したタスクの実行に役立ちます。これらの事前定義された Google Cloud コンポーネントは、AI Hub でも利用できます。再利用可能なコンポーネントを使用する場合と同様に、これらの component op は、ComponentStore.load_components を通じて事前定義されたコンポーネント仕様から自動的に作成されます。その他の事前定義されたコンポーネントは、Kubeflow などのプラットフォームでジョブを実行するために使用できます。
GCPから利用できる事前定義されたコンポーネントは、こちらから確認できます。今回使用するのは、AI platform上でのトレーニングジョブとトレーニング済みモデルのデプロイを行うコンポーネントです。load_conponents関数で指定するのは、次のような、conponents.yamlを含むディレクトリです。COMPONENT_URL_SEARCH_PREFIXに続くpathを指定しましょう。同時に、READEME.mdからコンポーネントの必須パラメーターや実行後の出力について確認できます。(参照:https://github.com/kubeflow/pipelines/tree/master/components/gcp/ml_engine/train)
import kfp
# COMPONENT_URL_SEARCH_PREFIX = 'https://raw.githubusercontent.com/kubeflow/pipelines/1.6.0/components/gcp/'
COMPONENT_URL_SEARCH_PREFIX = os.getenv('COMPONENT_URL_SEARCH_PREFIX')
# Create component factories
component_store = kfp.components.ComponentStore(
local_search_paths=None, url_search_prefixes=[COMPONENT_URL_SEARCH_PREFIX])
# Predefined components
# component.yamlがあるディレクトリを指定
mlengine_train_op = component_store.load_component('ml_engine/train')
mlengine_deploy_op = component_store.load_component('ml_engine/deploy')
次に、軽量のPythonコンポーネントについてです。
軽量の Python コンポーネントの実装: このコンポーネントでは、コードを変更するたびに新しいコンテナ イメージを作成する必要はなく、ノートブック環境での迅速なイテレーションを対象としています。kfp.components.func_to_container_op 関数を使用して、Python 関数から軽量コンポーネントを作成できます。
今回は以下のように、func_to_container_op関数によって3つのコンポーネントを作成しています。
from helper_components import retrieve_best_run
from helper_components import evaluate_model
from preprocess_dataflow_pipeline import run_transformation_pipeline
import kfp
from kfp.components import func_to_container_op
TRANSFORM_BASE_IMAGE = os.getenv('TRANSFORM_BASE_IMAGE') # docker_images/transform_image/Dockerfile
BASE_IMAGE = os.getenv('BASE_IMAGE') # docker_images/base_image/Dockerfile
EVALUATE_IMAGE = os.getenv('EVALUATE_IMAGE') # docker_images/evaluate_image/Dockerfile
# Lightweight components
run_transform_pipeline_op = func_to_container_op(
run_transformation_pipeline, base_image=TRANSFORM_IMAGE)
retrieve_best_run_op = func_to_container_op(
retrieve_best_run, base_image=BASE_IMAGE)
evaluate_model_op = func_to_container_op(
evaluate_model, base_image=EVALUATE_IMAGE)
それでは、ここからそれぞれのコンポーネントに必要なファイルを記述します。今回は、事前定義されたGoogle Cloudコンポーネントを2つ、軽量なPythonコンポーネントを3つ作成したので、以下では5つのステップに分けて説明します。最後に、5つのコンポーネントからパイプラインの作成をします。
データ抽出〜保存
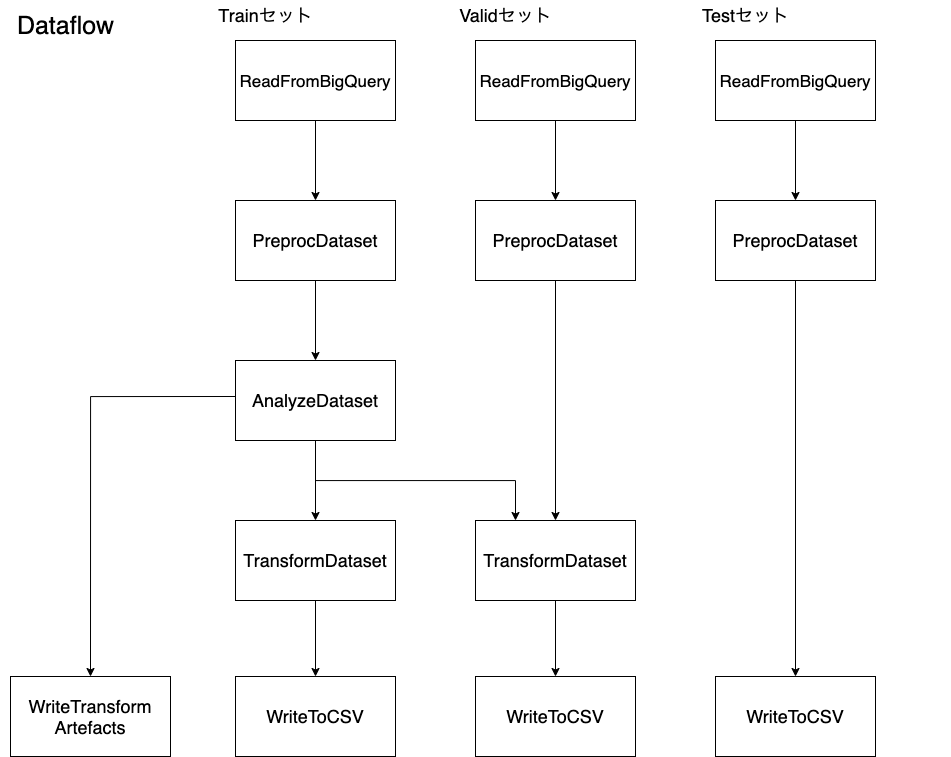
使用ファイル:
1番目のステップです。ここでは、データセットの作成と変換を行うrun_transform_pipeline_opで使用するファイルを作成し、Dataflowを用いて以下のフローを実行します。
- BigQueryからのデータ抽出
- Tensorflow Transformでの前処理
- Cloud Storageへの保存
それぞれの処理をApache Beamのプログラミングモデルを用いて記述し、最後に一連の処理を行うApache Beamパイプラインを作成します。このステップで実行されるrun_transformation_pipeline関数は、こちらから確認できます。
データ抽出

まず、BigQueryのテーブルからデータの抽出を行い、Train,Valid,Testの3つのデータセットを作成します。後述しますが、1日1回のスクレイピングでテーブルにレコードを自動追加されます。そのため、プログラムの実行タイミングによって、3つのデータセットにおけるデータ量の比率が変わらないよう、動的に変化するクエリを記述します。ここではUNIX時間を使って、最初のレコードのDate(2011-01-01 01:00:00)からプログラム実行までの経過時間を80:10:10の割合で分割し、テンプレートクエリ中のstartとendの値を定めます。
# Generating the query
# train, valid, testセットのデータ量の比率が常に一定であるように、UNIX時間を使ってクエリを変化させる
def generate_sampling_query(source_table_name, step):
# Setting timestamp division
start = datetime(2011, 1, 1, 1, 0, 0)
end = datetime.now()
diff = end.timestamp() - start.timestamp()
train_start = start.timestamp()
train_end = train_start + diff * 0.8
valid_end = train_end + diff * 0.1
test_end = valid_end + diff * 0.1
train_start = datetime.fromtimestamp(train_start)
train_end = datetime.fromtimestamp(train_end)
valid_end = datetime.fromtimestamp(valid_end)
test_end = datetime.fromtimestamp(test_end)
valid_start = train_end
test_start = valid_end
# Template query
sampling_query_template="""
SELECT
*
FROM
`{{source_table}}`
WHERE
Date BETWEEN '{{start}}' AND '{{end}}'
ORDER BY
Date
"""
# Changing query dependging on steps
if step == "Train":
start, end = train_start, train_end
elif step == "Valid":
start, end = valid_start, valid_end
else:
start, end = test_start, test_end
query = Template(sampling_query_template).render(
source_table=source_table_name, start=start, end=end)
return query
次に、読み込み前のデータ形式の変換を行います。まず、Datetime形式のデータは読み取れないので、Date列をtimestamp形式に変換します。また後の処理のために、window_direction列を文字列から、360°表記に変換します。後述するTensorFlow Transformの前処理関数で処理を完結させようとしましたが、DataFrame→ndarray→Tensorという形式変換の際にエラーが出てしまったので、prep_bq_row関数で読み込み前の処理を行いました。
def prep_bq_row(bq_row):
result = {}
for feature_name in bq_row.keys():
result[feature_name] = bq_row[feature_name]
date_time = pd.to_datetime(bq_row["Date"])
time_stamp = pd.Timestamp(date_time)
result["Date"] = time_stamp.timestamp()
wind_direction = tf.strings.regex_replace(bq_row["wind_direction"], "[\s+)]", "")
wind_direction = tf.strings.regex_replace(wind_direction, "[x]", u"静穏")
direction_list = [
"北", "北北東", "北東", "東北東", "東", "東南東", "南東", "南南東",
"南", "南南西", "南西", "西南西", "西", "西北西", "北西", "北北西", "静穏"
]
degree_list = [
0.0, 22.5, 45.0, 67.5, 90.0, 112.5, 135.0, 157.5,
180.0, 202.5, 225.0, 247.5, 270.0, 292.5, 315.0, 337.5, 0.0
]
def direction_to_degree(direction):
if direction in direction_list:
index = direction_list.index(direction)
return degree_list[index]
else:
return 0.0
result["wind_direction"] = direction_to_degree(wind_direction)
return result
最後に、Apache BeamのI/Oコネクターを用いて、BigQueryからデータの読み込みを行います。
def read_from_bq(pipeline, source_table_name, step):
query = generate_sampling_query(source_table_name, step)
# Read data from Bigquery
raw_data = (
pipeline
| 'Read{}DatafromBigQuery'.format(step) >> beam.io.Read(beam.io.ReadFromBigQuery(query=query, use_standard_sql=True))
| 'Preproc{}Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
前処理
ここからは、前項で抽出したデータにTensorFlow Transformを用いて前処理を加えます。
TensorFlow Transform
tf.Transform ライブラリは全走査を必要とする変換に役立ちます。tf.Transform の出力は、インスタンス レベルの変換ロジックだけでなく全走査変換から計算された統計値も表す TensorFlow グラフとしてエクスポートされ、トレーニングおよびサービス提供に利用されます。トレーニングとサービス提供の両方に同じグラフを使用すると、両方の段階で同じ変換が適用されるため、スキューを防止できます。また、tf.Transform は Dataflow のバッチ処理パイプラインで大規模に実行できるため、トレーニング データを事前に準備してトレーニングの効率を改善できます。
Tensorflow Transformの変換には、AnalyzeフェーズとTransformフェーズとがあります。前者で、未加工のTrainデータを全走査し、変換に必要な数値を取得します。そして、後者でデータの変換を行います。Trainデータから計算された統計量(平均・分散、最小・最大値など)を用いてTrain、Validデータを変換します。また、同じ変換プロセスをサービング後の予測に用いることで、Training-Serving skewを防ぐことができます。
前処理関数の定義
それでは、前処理関数の定義を始めます。こちらのドキュメントを参考にしました。
Date列は周期性を表現できるように、sin波・cos波を使って変換します。また、wind_directionとwind_velocity列を併せてベクトルへと変換します。また、air_pressure_ashoreとair_pressure_afloatの外れ値をクリップします。最後に、変数の正規化・標準化を行います。temperature列の平均・分散は、モデルの評価やサービング時の予測後のリスケーリングに使用するので、それぞれを1つの特徴量として一緒に書き込みます。(参照:https://github.com/tensorflow/transform/issues/185)
def preprocess_fn(inputs):
outputs = {}
# Date
timestamp_s = inputs["Date"]
day = 24 * 60 * 60
year = 365.2425 * day
outputs["day_sin"] = tf.sin(timestamp_s * 2 * math.pi / day)
outputs["day_cos"] = tf.cos(timestamp_s * 2 * math.pi / day)
outputs["year_sin"] = tf.sin(timestamp_s * 2 * math.pi / year)
outputs["year_cos"] = tf.cos(timestamp_s * 2 * math.pi / year)
# Air pressure
STANDARDIZED_FEATURES_LIST = ["air_pressure_ashore", "air_pressure_afloat"]
for feature in STANDARDIZED_FEATURES_LIST:
outputs[feature] = tft.scale_to_0_1(tf.clip_by_value(inputs[feature], 860.0, 1100.0)) # 外れ値のクリップ
outputs["diff_air_pressure"] = outputs["air_pressure_ashore"] - outputs["air_pressure_afloat"] # 特徴量の作成
# Wind
wind_direction_rad = inputs["wind_direction"] * math.pi / 180.0
outputs["wind_vector_x"] = inputs["wind_velocity"] * tf.cos(wind_direction_rad)
outputs["wind_vector_y"] = inputs["wind_velocity"] * tf.sin(wind_direction_rad)
# Others
# Normalizing numerical features
NORMALIZED_FEATURES_LIST = ["precipitation", "temperature", "humidity", "hours_of_daylight", "global_solar_radiation"]
for feature in NORMALIZED_FEATURES_LIST:
outputs[feature] = tft.scale_to_z_score(inputs[feature])
# Calcurating stats of Temperature and Converting to feature
# preprocess_fn()で変換したデータに、trainセットのtemperature列の平均と分散が追加される
def feature_from_scalar(value):
batch_size = tf.shape(input=inputs["temperature"])[0]
return tf.tile(tf.expand_dims(value, 0), multiples=[batch_size])
outputs["temp_mean"] = feature_from_scalar(tft.mean(inputs['temperature']))
outputs["temp_var"] = feature_from_scalar(tft.var(inputs['temperature']))
return outputs
上記の前処理関数をTrainセットに適用します。tft_beam.AnalyzeAndTransformDataset関数で、Analyze・Transformの両フェイズを一度に実行します。
# Analyze and transform train dataset
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| tft_beam.AnalyzeAndTransformDataset(preprocess_fn)
)
return transformed_dataset, transform_fn
続いて、Validデータに同様の前処理関数を用いて変換を行います。繰り返しになりますが、ここでの変換には、Trainセットから作成された統計量が使用されます。※Testセットには前処理を行いません。
# Transform valid and test dataset
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{}Transform'.format(step) >> tft_beam.TransformDataset()
)
return transformed_dataset
保存
最後に、データセットをカンマ区切りのCSV形式に変換し、Apache BeamのI/OコネクターでCloud Storageへと保存します。
def to_train_csv(rawdata):
# 変換後の特徴量
TRAIN_CSV_COLUMNS = [
'day_sin', 'day_cos', 'year_sin', 'year_cos', 'air_pressure_ashore', 'air_pressure_afloat', 'diff_air_pressure',
'precipitation', 'temperature', 'humidity', 'wind_vector_x', 'wind_vector_y',
'hours_of_daylight', 'global_solar_radiation', 'temp_mean', 'temp_var'
]
data = ','.join([str(rawdata[k]) for k in TRAIN_CSV_COLUMNS])
yield str(data)
def to_test_csv(rawdata):
# 未変換の特徴量
TEST_CSV_COLUMNS = [
'Date', 'air_pressure_ashore', 'air_pressure_afloat', 'precipitation', 'temperature',
'humidity', 'wind_direction', 'wind_velocity', 'hours_of_daylight', 'global_solar_radiation'
]
data = ','.join([str(rawdata[k]) for k in TEST_CSV_COLUMNS])
yield str(data)
# Cloud storageへの書き込み
def write_csv(transformed_dataset, location, step):
transformed_data, _ = transformed_dataset
(
transformed_data
| '{}Csv'.format(step) >> beam.FlatMap(to_csv)
| '{}Out'.format(step) >> beam.io.Write(beam.io.WriteToText(location))
)
前処理関数と変換に必要な統計量を含んだ変換プロセスを保存します。
# 変換プロセスの保存
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'WriteTransformArtefacts' >> tft_beam.WriteTransformFn(location)
)
Dataflowジョブの実行
以上で、データの分割・前処理・保存を行う関数の定義が終了しました。それでは、以上のプロセスを実行するApache Beamパイプラインを作成し、DataflowRunnerで実行します。
Kubeflow pipelinesの事前定義されたGoogle Cloudコンポーネントを利用して、Dataflowのジョブを実行できますが、このコンポーネントは呼び出し時に、指定したpythonファイルを1つだけtmpディレクトリにダウンロードして実行するような設定になっているようです[参考]。そのため、Apache Beamパイプラインのoptionsでsetup_fileを指定したとしても、set_up.pyはtmpディレクトリへとダウンロードされず、Dataflowジョブの実行時に、tensorflow-transformについて、"module not found error"が起きてしまいます。そこで今回は、軽量のPythonコンポーネントを使用します。
それでは上記の関数定義を使って、Dataflowジョブを実行するためのrun_transformation_pipeline関数の定義をしましょう。
from typing import NamedTuple
def run_transformation_pipeline(
source_table_name:str, job_name:str, gcs_root:str, project_id:str, region:str, dataset_location:str
) -> NamedTuple('Outputs', [('training_file_path', str), ('validation_file_path', str), ('testing_file_path', str)]):
from datetime import datetime
import os
import tempfile
import copy
import tensorflow as tf
import tensorflow_transform as tft
import tensorflow_transform.beam as tft_beam
from tfx_bsl.public import tfxio
import apache_beam as beam
from jinja2 import Template
#-------------------------------------------------------------------------------------
# 上記の関数定義
#-------------------------------------------------------------------------------------
TRAINING_FILE_PATH = 'training/data.csv'
VALIDATION_FILE_PATH = 'validation/data.csv'
TESTING_FILE_PATH = 'testing/data.csv'
options = {
'staging_location': os.path.join(gcs_root, 'tmp', 'staging'),
'temp_location': os.path.join(gcs_root, 'tmp'),
'job_name': job_name,
'project': project_id,
'max_num_workers': 3,
'save_main_session': True,
'region': region,
'setup_file': './setup.py', # pipeline内でtensorflow-transformを使えるようにsetup_fileの設定をする
}
opts = beam.pipeline.PipelineOptions(flags=[], **options)
RUNNER = 'DataflowRunner'
with beam.Pipeline(RUNNER, options=opts) as pipeline:
with tft_beam.Context(temp_dir=tempfile.mkdtemp()):
# Create training set
step = "Train"
training_file_path = '{}/{}'.format(dataset_location, TRAINING_FILE_PATH)
tf_record_file_path = dataset_location
raw_train_dataset = read_from_bq(pipeline, source_table_name, step)
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
write_csv(transformed_train_dataset, training_file_path, step)
# Create validation set
step = "Valid"
validation_file_path = '{}/{}'.format(dataset_location, VALIDATION_FILE_PATH)
raw_eval_dataset = read_from_bq(pipeline, source_table_name, step)
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
write_csv(transformed_eval_dataset, validation_file_path, step)
# Create testing set
step = "Test"
testing_file_path = '{}/{}'.format(dataset_location, TESTING_FILE_PATH)
raw_test_dataset = read_from_bq(pipeline, source_table_name, step)
write_csv(raw_test_dataset, testing_file_path, step)
# Sarving artefacts
transform_artefacts_dir = os.path.join(gcs_root,'transform')
write_transform_artefacts(transform_fn, transform_artefacts_dir)
return (training_file_path, validation_file_path, testing_file_path, transform_artefacts_dir)
以上で、このステップは終了です。BigQueryのテーブルから、Cloud Storageに3つのCSVファイルが作成されました。
データセットのwindow処理~モデルの保存
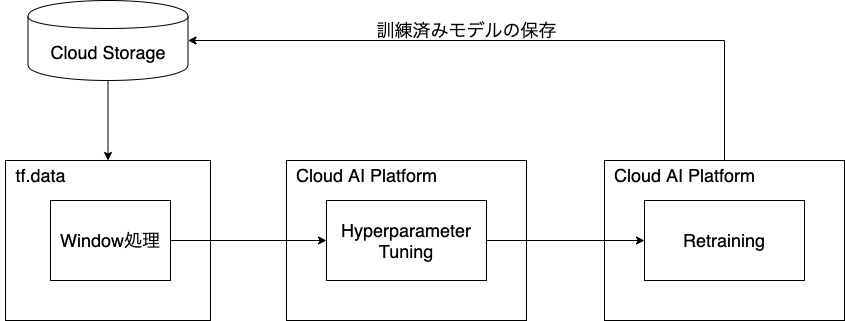
2番目のステップです。ここでは、モデルの訓練を行うmlengine_train_opで使用するファイルを作成し、以下のフローを実行します。
- データセットのwindow処理
- seq2seqモデルの作成
- AI PlatformでのHyperparameter Tuningと再トレーニング
- モデルの保存
tf.dataを用いてデータセットのwindow処理を行い、TensorFlow Addonsを利用してseq2seqモデルを作成します。そして、AI Platformの訓練ジョブでモデルのHyperparameter Tuningを行い、最もパフォーマンスの良いハイパーパラメーターをセットして、再トレーニングを行います。訓練が終わったら、Cloud Storageへとモデルを保存します。
seq2seqモデル
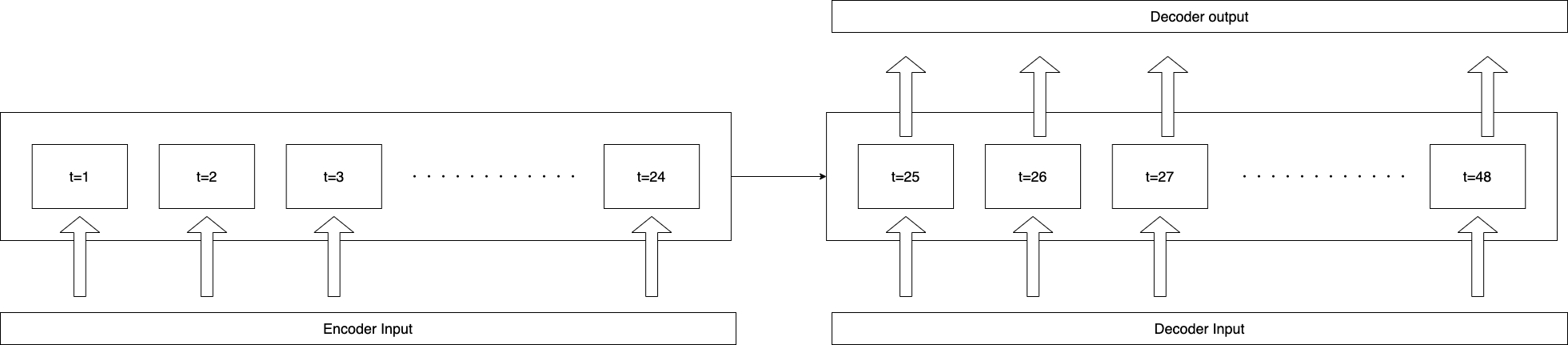
今回使用するモデルはseq2seqです。こちらの記事を参考にしました。このモデルを使って、24時間分の気象データの入力から、翌日の1時間ごとの気温の予測をします。 seq2seqモデルは、EncoderとDecoderからなるモデルです。Decoderの入力として、前時点での実現値(実際の気温)を使用する方法と、モデルの前時点での予測値を使用する方法とがあります。Teacher forcingでは、訓練時に前時点の実現値、予測時に前時点でのモデルの予測値をを使用します。これは、訓練の収束を速めるために有効ですが、訓練時と予測時でモデルの評価指標に大きな差が出る恐れがあります。今回は、前者の方法から後者の方法へと段階的に切り替えるScheduled Samplingを使用します。まずは、このサンプリング方法に併せてデータセットの処理を行いましょう。
window処理
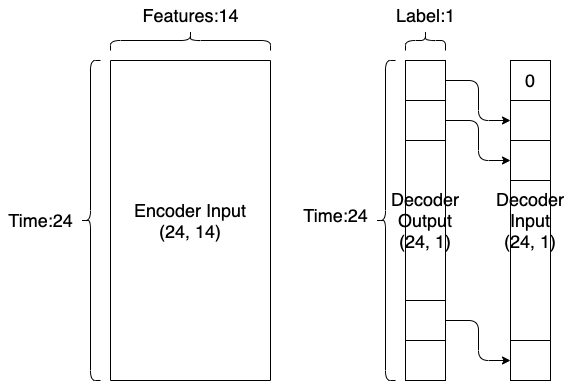
使用ファイル:
まず、train, validセットへのwindow処理を行うwindowed_dataset関数の定義をします。ここでは、こちらの記事を参考にしました。まず、48時点のデータを1まとめにして、前半の24時点をEncoderのインプットとします。後半の24時点はDecoderのインプットとアウトプットの作成に使います。訓練時のDecoderのインプットは、図のように最初の要素が0で、以降は前時点のDecoderアウトプットと同じ値を使います。*testセットへの処理は、モデル評価のステップで定義します。
from functools import partial
import tensorflow as tf
# Setting defaults
CSV_COLUMNS = [
'day_sin', 'day_cos', 'year_sin', 'year_cos', 'air_pressure_ashore', 'air_pressure_afloat', 'diff_air_pressure',
'precipitation', 'temperature', 'humidity', 'wind_vector_x', "wind_vector_y",
'hours_of_daylight', 'global_solar_radiation', 'temp_mean', 'temp_var'
]
SELECT_COLUMNS = [
'day_sin', 'day_cos', 'year_sin', 'year_cos', 'air_pressure_ashore', 'air_pressure_afloat', 'diff_air_pressure',
'precipitation', 'temperature', 'humidity', 'wind_vector_x', "wind_vector_y", 'hours_of_daylight', 'global_solar_radiation'
]
DEFAULTS = [[0.0] for _ in range(len(SELECT_COLUMNS))]
# Packing features
def pack(features):
packed_features = tf.stack(list(features.values()), axis=1)
return tf.reshape(packed_features, [-1])
@tf.function
def marshal(x, feature_keys):
features = {
k: x[:, feature_keys.index(k)] for k in feature_keys #pack時失われたkeyを付け直す
}
return features
# Window processing
def windowed_dataset(dataset, batch_size, mode):
marshal_fn_partial = partial(marshal, feature_keys=SELECT_COLUMNS)
dataset = dataset.map(pack)
dataset = dataset.window(size=48, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(48))
if mode == "train":
dataset.shuffle(1000)
encoder_input = dataset.map(lambda window: window[:24]).map(marshal_fn_partial)
decoder_input = dataset.map(lambda window: tf.concat((tf.zeros((1)), window[24:-1, 8]), axis=0)) #Teacher Forcingのため、decoder_inputの先頭は、0にする
decoder_output = dataset.map(lambda window: window[24:, 8])
inputs = tf.data.Dataset.zip((encoder_input, decoder_input))
dataset = tf.data.Dataset.zip((inputs, decoder_output)).cache()
dataset = dataset.batch(batch_size, drop_remainder=True).repeat(1).prefetch(1)
return dataset
tf.data.experimental.make_csv_dataset関数でロードしたデータに、window処理を施します。この際、select_columnsを設定して、temperature列の平均・分散であるtemp_mean/temp_varを省きます。
# Loading dataset
def load_dataset(filename, batch_size, mode):
dataset = tf.data.experimental.make_csv_dataset(
file_pattern=filename,
column_names=CSV_COLUMNS,
column_defaults=DEFAULTS,
select_columns=SELECT_COLUMNS,
batch_size=1,
shuffle=False,
header=False,
num_epochs=1)
dataset = windowed_dataset(dataset, batch_size, mode)
return dataset
モデルの訓練に使用するデータセットへのwindow処理が終わりました。データの形状は、次の通りです。
- Encoder Input: (batch_size, 24, 14)
- Decoder Input: (batch_size, 24, 1)
- Decoder Output: (batch_size, 24, 1)
※Encoder Inputは、厳密には14のkeyを持ち格要素が(24,)の辞書となっています。
モデルの作成
使用ファイル:
ここでは、訓練時のモデルを作成するtrain_model関数と、予測時のモデルを作成するpredict_model関数を、tf.kerasとTensorFlow Addonsを使って作成します。まず、訓練時に使用するモデルです。TensorFlow AddonsのScheduledOutputTrainingSamplerを利用してScheduled Smaplingを実装しています。後述しますが、optimizerのlearning_rateとDropout層のDropoutする割合(dropout_rate)はチューニングの対象となっています。
import tensorflow as tf
import tensorflow_addons as tfa
# Creating model for training and evaluating
def train_model(num_units=128, learning_rate=0.001, dropout_rate=0.35):
SELECT_COLUMNS = [
'day_sin', 'day_cos', 'year_sin', 'year_cos', 'air_pressure_ashore', 'air_pressure_afloat', 'diff_air_pressure',
'precipitation', 'temperature', 'humidity', 'wind_vector_x', "wind_vector_y", 'hours_of_daylight', 'global_solar_radiation'
]
# Input layer
# tf.keras.experimental.SequenceFeaturesによる入力層は、モデルの保存ができず断念
encoder_input_layers = {
colname: tf.keras.layers.Input(name=colname, shape=(24, 1), dtype=tf.float32)
for colname in SELECT_COLUMNS
}
pre_model_input = tf.keras.layers.Concatenate(axis=-1, name="concatenate")(encoder_input_layers.values())
# Encoder
encoder_lstm = tf.keras.layers.LSTM(num_units, return_sequences=True, name="encoder_lstm1")(pre_model_input)
encoder_dropout = tf.keras.layers.Dropout(dropout_rate, name="encoder_dropout")(encoder_lstm)
encoder_output, state_h, state_c = tf.keras.layers.LSTM(num_units, return_state=True, name="encoder_lstm2")(encoder_dropout)
encoder_state = [state_h, state_c]
# Scheduled Sampler
sampler = tfa.seq2seq.sampler.ScheduledOutputTrainingSampler(
sampling_probability=0.,
next_inputs_fn=lambda outputs: tf.reshape(outputs, shape=(1, 1))
)
sampler.sampling_probability = tf.Variable(0.)
# Decoder
decoder_input = tf.keras.layers.Input(shape=(24, 1), name="decoder_input")
decoder_cell = tf.keras.layers.LSTMCell(num_units, name="decoder_lstm")
output_layer = tf.keras.layers.Dense(1, name="decoder_output")
decoder = tfa.seq2seq.basic_decoder.BasicDecoder(decoder_cell, sampler, output_layer=output_layer)
decoder_output, _, _ = decoder(decoder_input, initial_state=encoder_state, sequence_length=[24])
final_output = decoder_output.rnn_output
# Creating model
model = tf.keras.Model(
inputs=[encoder_input_layers, decoder_input], outputs=[final_output])
optimizer = tf.keras.optimizers.RMSprop(learning_rate)
model.compile(loss="mse", optimizer=optimizer)
return model, encoder_input_layers, encoder_state, decoder_cell, output_layer, sampler
かなり見にくいですが、モデルは次のような構造になっています。

次に、上記のモデルの学習済み層を利用して、予測用のモデルを作成します。Functional APIを使用して作成したモデルの保存を試みましたが、エラーの解消ができなかったため、サブクラス化しています。samplerには、Inference Samplerを使用して、予測を次の時点での入力に使用します。trainセットのtemp_mean、temp_var列を使用して、モデルの出力を元のスケールに直し、最終的なアウトプットとしましょう。後述しますが、データセットにTensorFlow Transformの前処理関数を使用すると、変換後のデータには、trainセットのtemperature列の平均・分散を表すtemp_mean・temp_var列が追加されるので、リスケーリングにはこれらを利用できます。
# Creating model for prediction
# Functional APIではモデルの保存時にエラーが出るので、サブクラス化する
def predict_model(encoder_input_layers, encoder_state, decoder_cell, output_layer):
# Encoder Layer Class
class Inference_Encoder(tf.keras.layers.Layer):
def __init__(self, encoder_input_layers, encoder_state):
super().__init__()
self.model = tf.keras.models.Model(inputs=[encoder_input_layers], outputs=encoder_state)
@tf.function
def call(self, inputs):
return self.model(inputs)
# Decoder Layer Class
class Inference_Decoder(tf.keras.layers.Layer):
def __init__(self, decoder_cell, output_layer):
super().__init__()
# Inference sampler
self.sampler = tfa.seq2seq.sampler.InferenceSampler(
sample_fn = lambda outputs: tf.reshape(outputs, (1, 1)),
sample_shape = [1],
sample_dtype = tf.float32,
end_fn = lambda sample_ids : False,
)
self.decoder = tfa.seq2seq.basic_decoder.BasicDecoder(
decoder_cell, self.sampler, output_layer=output_layer, maximum_iterations=24
)
@tf.function
def call(self, initial_state):
start_inputs = tf.zeros(shape=(1, 1))
decoder_output, _, _ = self.decoder(start_inputs, initial_state=initial_state)
final_output = decoder_output.rnn_output
return final_output
# Inference Model Class
class Inference_Model(tf.keras.Model):
def __init__(self, encoder_input_layers, encoder_state, decoder_cell, output_layer):
super().__init__()
self.encoder = Inference_Encoder(encoder_input_layers, encoder_state)
self.decoder = Inference_Decoder(decoder_cell, output_layer)
@tf.function
def call(self, inputs):
inputs_copy = inputs.copy()
# inputsは、transform_fnで処理したデータで、訓練セットのtemperature列の平均・分散が含まれている
# rescaleのために、それらの統計量を取り出しておく
temp_mean = inputs_copy.pop('temp_mean')[0][0]
temp_var = inputs_copy.pop('temp_var')[0][0]
initial_state = self.encoder(inputs_copy)
outputs = self.decoder(initial_state)
outputs_rescaled = outputs * tf.sqrt(temp_var) + temp_mean
return outputs_rescaled
inference_model = Inference_Model(encoder_input_layers, encoder_state, decoder_cell, output_layer)
return inference_model
モデルの保存
使用ファイル:
ここでは、モデルをCloud Storageへと保存します。サービング時、TensorFlow Transformの前処理関数を適用できるようにモデルにpreprocessing_layerを追加します。(参考:https://github.com/tensorflow/tfx/issues/2199)
import tensorflow as tf
def export_serving_model(model, tf_transform_output, out_dir):
TRANSFORM_FEATURE_COLUMNS = [
'Date', 'air_pressure_ashore', 'air_pressure_afloat', 'precipitation', 'temperature',
'humidity', 'wind_direction', 'wind_velocity', 'hours_of_daylight', 'global_solar_radiation'
]
SELECT_COLUMNS = [
'day_sin', 'day_cos', 'year_sin', 'year_cos', 'air_pressure_ashore', 'air_pressure_afloat',
'diff_air_pressure', 'precipitation', 'temperature', 'humidity', 'wind_vector_x', "wind_vector_y",
'hours_of_daylight', 'global_solar_radiation', 'temp_mean', 'temp_var'
]
# Building Model
example = {
x: tf.random.uniform(shape=(1, 24), name=x)
for x in SELECT_COLUMNS
}
ex = model(example)
# Transform raw features
def get_apply_tft_layer(tf_transform_output):
tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def apply_tf_transform(raw_features_dict):
unbatched_raw_features = {
k: tf.squeeze(tf.reshape(v, (1, -1)))
for k, v in raw_features_dict.items()
}
transformed_dataset = tft_layer(unbatched_raw_features)
expanded_dims = {
k: tf.reshape(v, (-1, 24))
for k, v in transformed_dataset.items()
}
return expanded_dims
return apply_tf_transform
def get_serve_raw_fn(model, tf_transform_output):
model.preprocessing_layer = get_apply_tft_layer(tf_transform_output)
@tf.function
def serve_raw_fn(features):
preprocessed_features = model.preprocessing_layer(features)
return preprocessed_features
return serve_raw_fn
serving_raw_entry = get_serve_raw_fn(model, tf_transform_output)
serving_transform_signature_tensorspecs = {
x: tf.TensorSpec(shape=[None, 24], dtype=tf.float32, name=x)
for x in TRANSFORM_FEATURE_COLUMNS
}
serving_signature_tensorspecs = {
x: tf.TensorSpec(shape=[None, 24], dtype=tf.float32, name=x)
for x in SELECT_COLUMNS
}
# Signatures
signatures = {'serving_default': model.call.get_concrete_function(serving_signature_tensorspecs),
'transform': serving_raw_entry.get_concrete_function(serving_transform_signature_tensorspecs)}
tf.keras.models.save_model(model=model, filepath=out_dir, signatures=signatures)
モデルの訓練
使用ファイル:
ここでは、上述のcreate_dataset.pyとcreate_model.py、saved_model.pyを使って、seq2seqモデルの訓練と保存を行うtrain_evaluate関数を定義します。Hyperparameter Tuningを行う際には、evalセットでのmseを用いてモデルの性能を評価します。チューニング後に再訓練をしたら、学習済み層を用いて予測モデルを作成し、モデルを保存します。
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
import tensorflow_transform as tft
import fire
import hypertune
from create_dataset import load_dataset
from create_model import train_model
from create_model import predict_model
from save_model import export_serving_model
# Training and evaluating the model
def train_evaluate(job_dir, training_dataset_path, validation_dataset_path, num_epochs, num_units, learning_rate, dropout_rate, hptune, transform_artefacts_dir):
training_dataset = load_dataset(training_dataset_path + "*", 256, "train")
validation_dataset = load_dataset(validation_dataset_path + "*", 128, "eval")
print('Starting training: learning_rate={}, dropout_rate={}'.format(learning_rate, dropout_rate))
tf_transform_output = tft.TFTransformOutput(transform_artefacts_dir)
model, encoder_input_layers, encoder_state, decoder_cell, output_layer, sampler = train_model(
num_units=num_units, learning_rate=learning_rate, dropout_rate=dropout_rate
)
def update_sampling_probability(epoch, logs):
eps = 1e-16
proba = max(0.0, min(1.0, epoch / (num_epochs - 10 + eps)))
sampler.sampling_probability.assign(proba)
sampling_probability_cb = tf.keras.callbacks.LambdaCallback(on_epoch_begin=update_sampling_probability)
history = model.fit(training_dataset,
epochs=num_epochs,
validation_data=validation_dataset,
callbacks=[sampling_probability_cb]
)
# Hyperparameter tuning
if hptune:
val_loss = history.history["val_loss"]
print("val_loss: {}".format(val_loss))
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='val_loss',
metric_value=val_loss[-1])
# Saving the model
if not hptune:
inference_model_dir = '{}/predict'.format(job_dir)
inference_model = predict_model(encoder_input_layers, encoder_state, decoder_cell, output_layer)
export_serving_model(inference_model, tf_transform_output, inference_model_dir)
print('Inference model saved in: {}'.format(inference_model_dir))
# Execution
if __name__ == '__main__':
fire.Fire(train_evaluate)
チューニング結果の取得
使用ファイル:
3つ目のステップです。Hyperparameter Tuningの終了後に、最もパフォーマンスが良かったパラメーターの組み合わせを取得するretrieve_best_run_opで使用するファイルを作成します。訓練ジョブの結果には、REST APIから取得できます。
ベストパフォーマンスのlearning_rateとdropout_rateの値を取得し、再訓練時に使用します。
from typing import NamedTuple
def retrieve_best_run(
project_id:str, job_id:str
) -> NamedTuple('Outputs', [('metric_value', float), ('learning_rate', float), ('dropout_rate', float)]):
from googleapiclient import discovery
from googleapiclient import errors
ml = discovery.build('ml', 'v1')
job_name = 'projects/{}/jobs/{}'.format(project_id, job_id)
request = ml.projects().jobs().get(name=job_name)
try:
response = request.execute()
print(response)
except errors.HttpError as err:
print(err)
except:
print('Unexpected error')
best_trial = response['trainingOutput']['trials'][0]
print("best_trial:", best_trial)
metric_value = best_trial['finalMetric']['objectiveValue']
learning_rate = float(best_trial['hyperparameters']['learning_rate'])
dropout_rate = float(best_trial['hyperparameters']['dropout_rate'])
return (metric_value, learning_rate, dropout_rate)
モデルの評価
使用ファイル:
4つ目のステップです。ここでは、モデルの評価を行うevaluate_model_opで使用するファイルを作成します。 まずは評価に使用するデータセットの作成についてです。訓練時とは違いDecoderへのインプットはありません。その他は、訓練時と同様です。
import tensorflow as tf
from functools import partial
# Loading dataset
def load_test_dataset(filename, batch_size):
CSV_COLUMNS = [
'Date', 'air_pressure_ashore', 'air_pressure_afloat', 'precipitation', 'temperature',
'humidity', 'wind_direction', 'wind_velocity', 'hours_of_daylight', 'global_solar_radiation',
'weather', 'cloud cover'
]
SELECT_COLUMNS = [
'Date', 'air_pressure_ashore', 'air_pressure_afloat', 'precipitation', 'temperature',
'humidity', 'wind_direction', 'wind_velocity', 'hours_of_daylight', 'global_solar_radiation'
]
DEFAULTS = [[0.0] for i in SELECT_COLUMNS]
# Packing features
def pack(features):
packed_features = tf.stack(list(features.values()), axis=1)
return tf.reshape(packed_features, [-1])
@tf.function
def marshal(x, feature_keys):
features = {
k: x[:, feature_keys.index(k)] for k in feature_keys
}
return features
# Window processing
def windowed_dataset(dataset, batch_size):
marshal_fn_partial = partial(marshal, feature_keys=SELECT_COLUMNS)
dataset = dataset.map(pack)
dataset = dataset.window(size=48, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(48))
x_test = dataset.map(lambda window: window[:24]).map(marshal_fn_partial).batch(batch_size, drop_remainder=True).repeat(1).prefetch(1)
y_true = dataset.map(lambda window: window[24:, 4]).batch(batch_size, drop_remainder=True).repeat(1).prefetch(1)
return x_test, y_true
dataset = tf.data.experimental.make_csv_dataset(
file_pattern=filename,
column_names=CSV_COLUMNS,
column_defaults=DEFAULTS,
select_columns=SELECT_COLUMNS,
header=False,
batch_size=1,
shuffle=False,
num_epochs=1
)
x_test, y_true = windowed_dataset(dataset, batch_size)
return x_test, y_true
ロードしたデータを、モデルのpreprocessing_layerで前処理します。その後、予測値(y_pred)と実際の気温(y_true)とを用いてmseを計算します。
# モデルの予測値と、実現値を使ってモデルの評価を行う
def evaluate_model(
dataset_path: str, model_path: str, transform_artefacts_dir: str, metric_name: str
) -> NamedTuple('Outputs', [('metric_name', str), ('metric_value', float), ('mlpipeline_metrics', 'Metrics')]):
import json
import tensorflow as tf
import numpy as np
from create_dataset import load_test_dataset
def calculate_loss(y_pred, y_true):
mse = tf.keras.losses.MeanSquaredError()
return mse(y_true, y_pred).numpy().astype(np.float64)
model_path = '{}/predict'.format(model_path)
model = tf.keras.models.load_model(model_path)
x_test, y_true = load_test_dataset(dataset_path + "*", 256)
x_test_transformed = x_test.map(model.preprocessing_layer)
prediction = []
for item in x_test_transformed:
prediction.append(model.predict(item))
y_pred = np.array(prediction).reshape(-1, 24)
y_true = np.array(list(tf.data.Dataset.as_numpy_iterator(y_true))).reshape(-1, 24)
if metric_name == "mse":
metric_value = calculate_loss(y_pred, y_true)
print("metric_value:", metric_value)
else:
metric_name = 'N/A'
metric_value = 0
metrics = {
'metrics': [{
'name': metric_name,
'numberValue': metric_value
}]
}
return (metric_name, metric_value, json.dumps(metrics))
モデルのデプロイ
使用ファイル:
- kfp-pipeline/custom_prediction/predictor.py
- kfp-pipeline/custom_prediction/preprpcess.py
- kfp-pipeline/custom_prediction/setup.py
5つ目のステップです。ここでは、モデルのデプロイを行うmlengine_deploy_opで使用するファイルを作成します。今回は、カスタム予測ルーチンを作成します。
データの抽出・前処理を行ったのと同様の変換を行います。生のデータのDate列をtimestamp型へ、wind_direction列を数値型へと変換します。さらに、モデルに保存した前処理層を適用します。変換後の特徴量をモデルへとインプットすることで、予測が返されます。
import os
import pickle
import numpy as np
import tensorflow as tf
import preprocess
class MyPredictor(object):
def __init__(self, model):
self._model = model
def predict(self, instances, **kwargs):
preprocessed_inputs = {}
for i in instances:
for k, v in i.items():
if k not in preprocessed_inputs.keys():
preprocessed_inputs[k] = [v]
else:
preprocessed_inputs[k].append(v)
preprocessed_inputs["Date"] = [preprocess.convert_to_timestamp(i) for i in preprocessed_inputs["Date"]]
preprocessed_inputs["wind_direction"] = [preprocess.direction_to_degree(i) for i in preprocessed_inputs["wind_direction"]]
preprocessed_inputs = {
k: tf.reshape(np.array(v, dtype=np.float32), shape=(-1, 24))
for k, v in preprocessed_inputs.items()
}
transformed_inputs = self._model.preprocessing_layer(preprocessed_inputs)
outputs = self._model.predict(transformed_inputs, steps=1).reshape(-1, 24)
return outputs.tolist()
@classmethod
def from_path(cls, model_dir):
model = tf.keras.models.load_model(model_dir)
return cls(model)
カスタム予測ルーチンの作成方法は以下の通りです。
このページで説明しているカスタムコードの例をパッケージ化してアップロードするには、次の操作を行います。
- 前のセクションで説明した preprocess.py、predictor.py、setup.py ファイルをすべて同じディレクトリに作成します。シェルで、このディレクトリに移動します。
- python setup.py sdist --formats=gztar を実行して、dist/my_custom_code-0.1.tar.gz を作成します。
- この tarball を Cloud Storage のステージング ロケーションにアップロードします。
ファイルを保存したディレクトリに移動し、シェルで次のコマンドを実行します。
python setup.py sdist --formats=gztar
gsutil cp dist/my_custom_code-0.1.tar.gz gs://YOUR_BUCKET/PATH_TO_STAGING_DIR/
以上で、5つのステップ全てが完了しました。これらをパイプラインにまとめて実行しましょう。
Pipelineの定義
使用ファイル:
パイプライン全体はこちらのファイルからご覧ください。ここまでの記述内容と重複する部分もありますが、順を追って説明します。まずは、コンポーネントの作成です。今回は、事前定義されたGoogle Cloudコンポーネントを2つ、軽量のPythonコンポーネントを3つ作成しました。それぞれのコンポーネントで使用するDockerfileはこちらからご覧ください。
import os
import kfp
from kfp.components import func_to_container_op
from helper_components import retrieve_best_run
from helper_components import evaluate_model
from preprocess_dataflow_pipeline import run_transformation_pipeline
# Setting defaults
BASE_IMAGE = os.getenv('BASE_IMAGE') # docker_images/base_image/Dockerfile
TRANSFORM_IMAGE = os.getenv('TRANSFORM_IMAGE') # docker_images/transform_image/Dockerfile
TRAINER_IMAGE = os.getenv('TRAINER_IMAGE') # docker_images/trainer_image/Dockerfile
EVALUATE_IMAGE = os.getenv('EVALUATE_IMAGE') # docker_images/evaluate_image/Dockerfile
COMPONENT_URL_SEARCH_PREFIX = os.getenv('COMPONENT_URL_SEARCH_PREFIX')
# Create component factories
component_store = kfp.components.ComponentStore(
local_search_paths=None, url_search_prefixes=[COMPONENT_URL_SEARCH_PREFIX])
# Pre-build components
mlengine_train_op = component_store.load_component('ml_engine/train')
mlengine_deploy_op = component_store.load_component('ml_engine/deploy')
# Lightweight components
run_transform_pipeline_op = func_to_container_op(
run_transformation_pipeline, base_image=TRANSFORM_IMAGE)
retrieve_best_run_op = func_to_container_op(
retrieve_best_run, base_image=BASE_IMAGE)
evaluate_model_op = func_to_container_op(
evaluate_model, base_image=EVALUATE_IMAGE)
次に、パイプラインの定義です。weather_forecast_train関数内で、コンポーネントを呼び出しタスクを実行していきます。関数の引数はそれぞれコンポーネントへと渡されます。
import datetime
from kfp.gcp import use_gcp_secret
RUNTIME_VERSION = os.getenv('RUNTIME_VERSION')
PYTHON_VERSION = os.getenv('PYTHON_VERSION')
# Defining the pipeline
@kfp.dsl.pipeline(
name='Weather-forecast Model Training',
description='The pipeline training and deploying the Weather-forecast pipeline'
)
def weather_forecast_train(project_id,
gcs_root,
region,
source_table_name,
num_epochs_hypertune,
num_epochs_retrain,
num_units,
evaluation_metric_name,
evaluation_metric_threshold,
model_id,
version_id,
replace_existing_version,
hypertune_settings=HYPERTUNE_SETTINGS):
# Creating datasets
job_name = 'preprocess-weather-features' + '-' + datetime.datetime.now().strftime('%y%m%d-%H%M%S')
dataset_location = '{}/{}/{}'.format(gcs_root, 'datasets', kfp.dsl.RUN_ID_PLACEHOLDER)
create_dataset = run_transform_pipeline_op(
source_table_name, job_name, gcs_root, project_id, region, dataset_location)
# Tune hyperparameters
tune_args = [
'--training_dataset_path', create_dataset.outputs["training_file_path"],
'--validation_dataset_path', create_dataset.outputs["validation_file_path"],
'--num_epochs', num_epochs_hypertune,
'--num_units', num_units,
'--hptune', 'True',
'--transform_artefacts_dir', create_dataset.outputs["transform_artefacts_dir"]
]
job_dir = '{}/{}/{}'.format(gcs_root, 'jobdir/hypertune', kfp.dsl.RUN_ID_PLACEHOLDER)
hypertune = mlengine_train_op(
project_id=project_id,
region=region,
master_image_uri=TRAINER_IMAGE,
job_dir=job_dir,
args=tune_args,
training_input=hypertune_settings).apply(use_gcp_secret()) # Kubernetesシークレットを使用しないと、長時間の訓練が途中で停止します。
#Retrive the best trial
get_best_trial = retrieve_best_run_op(
project_id, hypertune.outputs['job_id'])
# Re-training the model
job_dir = '{}/{}/{}'.format(gcs_root, 'jobdir', kfp.dsl.RUN_ID_PLACEHOLDER)
train_args = [
'--training_dataset_path', create_dataset.outputs["training_file_path"],
'--validation_dataset_path', create_dataset.outputs["validation_file_path"],
'--num_epochs', num_epochs_retrain,
'--num_units', num_units,
'--learning_rate', get_best_trial.outputs['learning_rate'],
'--dropout_rate', get_best_trial.outputs['dropout_rate'],
'--hptune', 'False',
'--transform_artefacts_dir', create_dataset.outputs["transform_artefacts_dir"]
]
train_model = mlengine_train_op(
project_id=project_id,
region=region,
master_image_uri=TRAINER_IMAGE,
job_dir=job_dir,
args=train_args).apply(use_gcp_secret())
# Evaluating the model
eval_model = evaluate_model_op(
dataset_path=create_dataset.outputs['testing_file_path'],
model_path=str(train_model.outputs['job_dir']),
transform_artefacts_dir=create_dataset.outputs['transform_artefacts_dir'],
metric_name=evaluation_metric_name)
# Deploying the model
with kfp.dsl.Condition(eval_model.outputs['metric_value'] < evaluation_metric_threshold):
model_uri = '{}/predict'.format(train_model.outputs["job_dir"])
deploy_model = mlengine_deploy_op(
model_uri=model_uri,
project_id=project_id,
model_id=model_id,
version_id=version_id,
model = {"regions": [region],
# "onlinePredictionLogging": True, # 同名のモデルがあると、デプロイ時にエラーが出るので、コメントアウトします。
"onlinePredictionConsoleLogging": True},
version = {"packageUris": ["gs://[your_bucket]/staging/dist/my_custom_code-0.1.tar.gz"], # change your code
"predictionClass": "predictor.MyPredictor"},
runtime_version=RUNTIME_VERSION,
python_version=PYTHON_VERSION,
replace_existing_version=replace_existing_version)
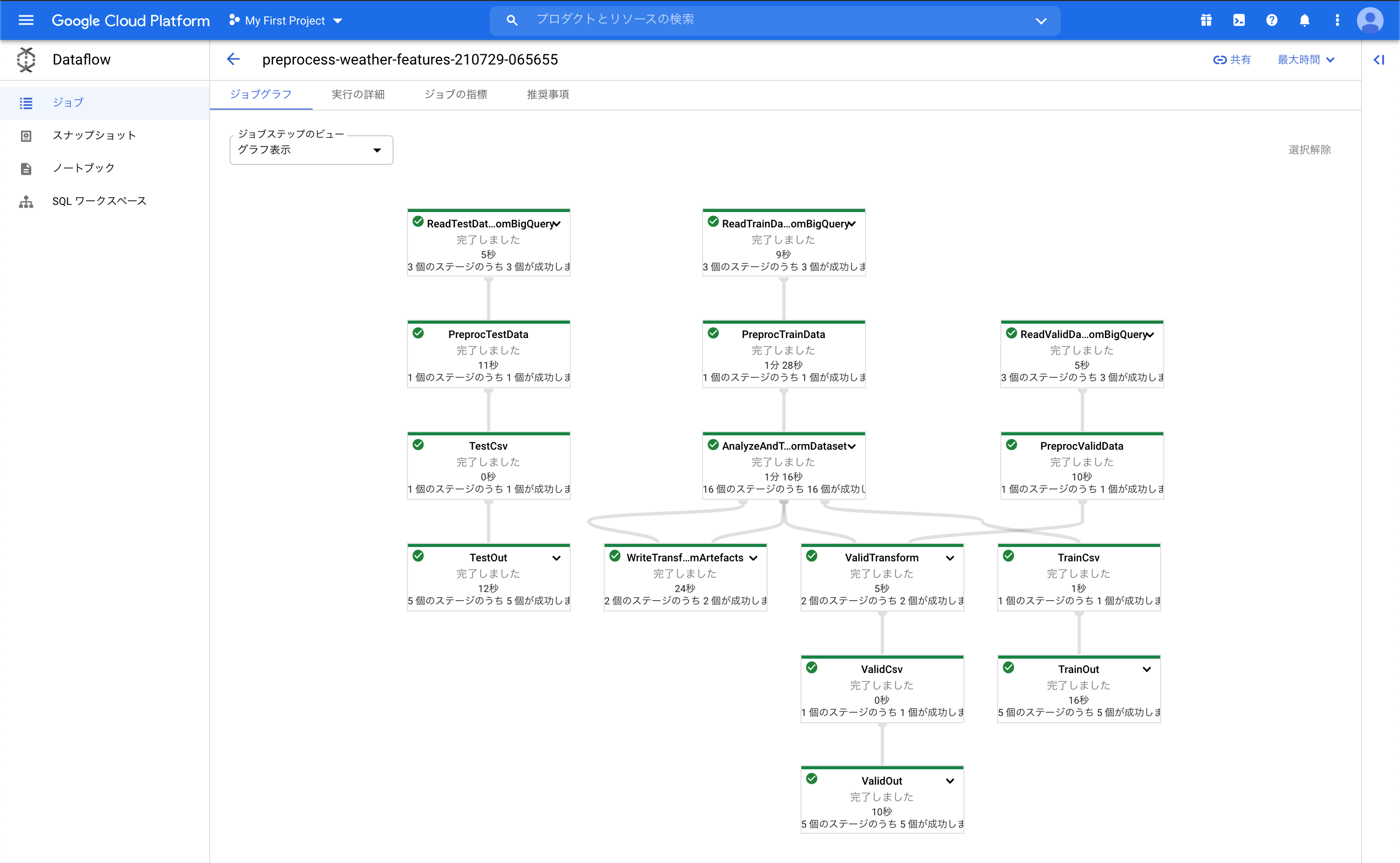
まず初めに、run_transform_pipeline_opを実行します。Dataflowジョブが実行され、Cloud Storageにデータセットが保存されます。ジョブの実行結果は次の通りです。
次に、mlengine_train_opでHyperparameter Tuningを実行します。Optimizerのlearning_rateとDropoutの割合(dropout_rate)をチューニングします。以下がチューニングの設定です。設定については、こちらが参考になります。前述した通り、use_gcp_secretを使用して実行しなければ、長時間の訓練ジョブが途中で停止する場合があります。
そして、retrieve_best_run_opで最良のハイパーパラメーターを取得し、mlengine_train_opで再度トレーニングを行い、モデルを保存します。evaluate_model_opでモデルの評価指標を計算したら、それが事前設定した閾値よりも良い場合に、mlengin_deploy_opを実行します。model, versionの2つの引数の設定には、こちらを参照ください。onlinePredictionConsoleLoggingをTrueにすることで、ログエクスプローラーからログを確認できるようになります。また、version引数で、カスタム予測ルーチンの設定をしています。
Pipelineの実行
使用ファイル:
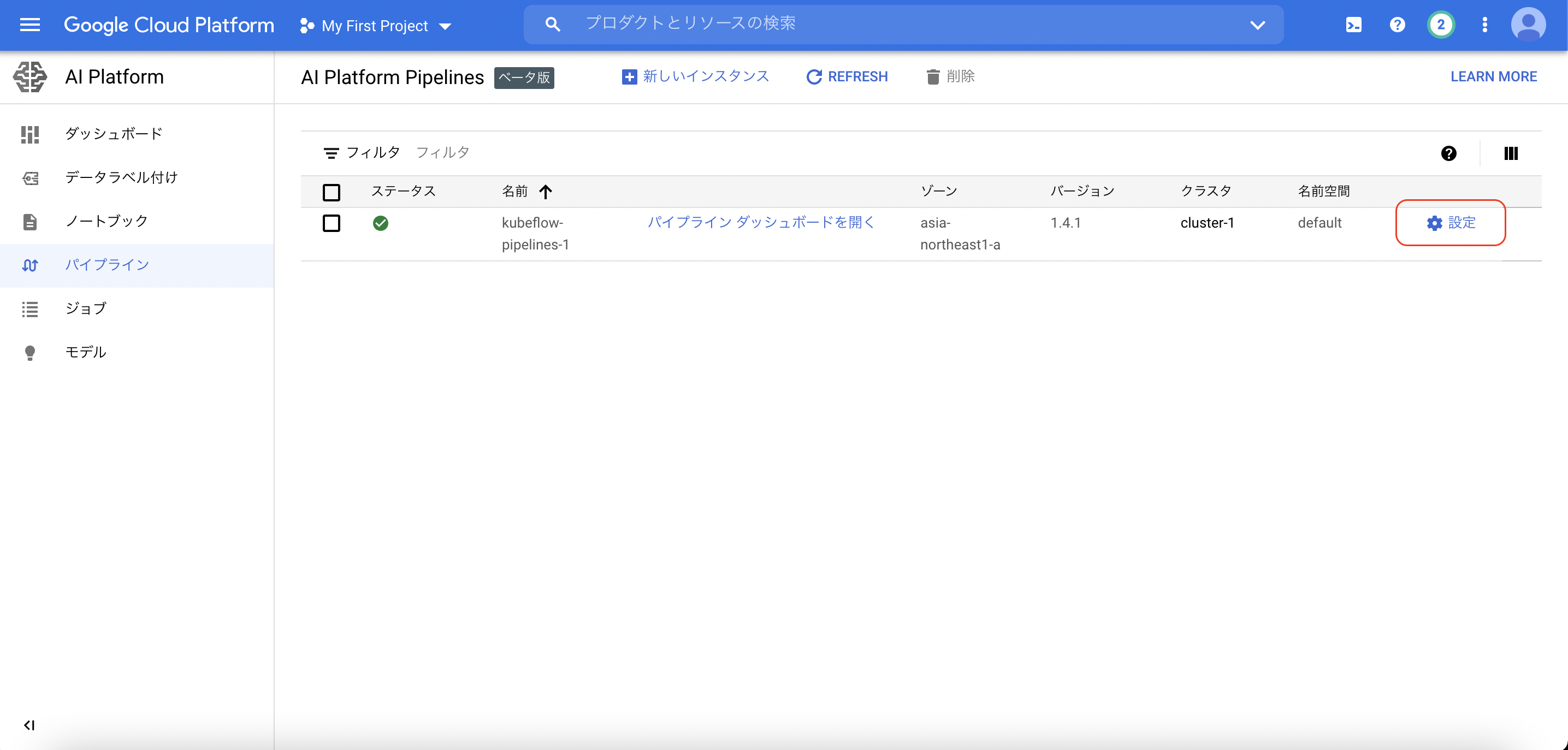
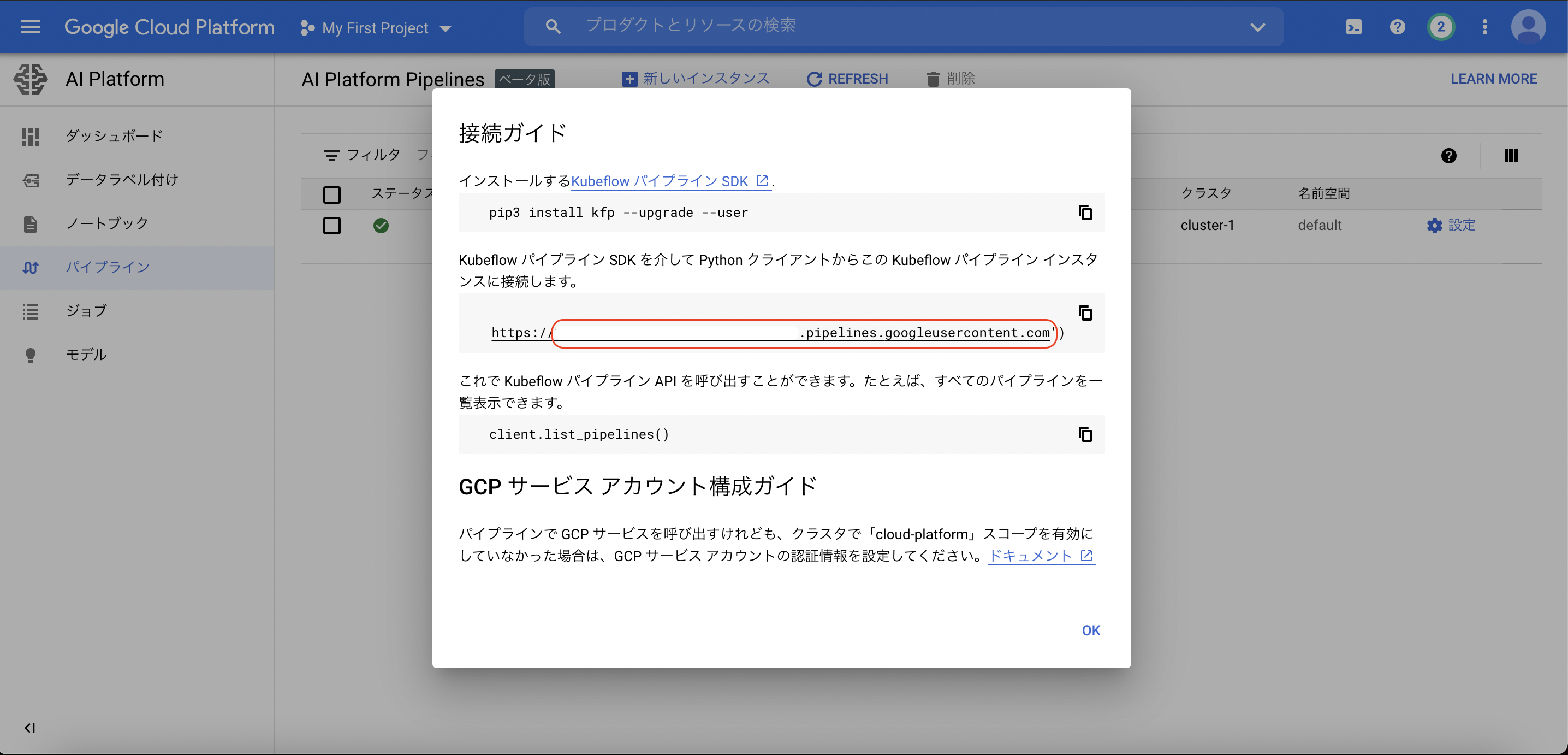
それでは、上記のパイプラインをAI Platformのノートブックから手動で実行をします。ノートブックはこちらをご覧ください。ENDPOINTは画像のようにして確認できます。ARTIFACT_STORE_URIは、クラスターの作成時に自動で作成されるバケットを設定します。
REGION = 'XXXXXXXXXXX' #change your code
ENDPOINT = 'XXXXXXXXXX.pipelines.googleusercontent.com' #change your code
ARTIFACT_STORE_URI = 'gs://XXXXXX-kubeflowpipelines-default' #change your code
PROJECT_ID = !(gcloud config get-value core/project)
PROJECT_ID = PROJECT_ID[0]
上述のノートブックのセルを順に実行することで、パイプラインが実行されます。学習が終了してモデルが保存されたら、saved_model_cliコマンドを使って、モデルの入出力の形状などを確認できます。saved_modelの扱いに関してはこちら。
%%bash
saved_model_cli show --dir gs://model_dir --all
また、オンライン予測ジョブを送信して、デプロイしたモデルが求める予測が返すかを確かめます。
from oauth2client.client import GoogleCredentials
from googleapiclient import discovery
from googleapiclient import errors
service = discovery.build('ml', 'v1')
def predict_json(project, model, instances, version=None):
name = 'projects/{}/models/{}'.format(project, model)
if version is not None:
name += '/versions/{}'.format(version)
response = service.projects().predict(
name=name,
body={'instances': instances}
).execute()
if 'error' in response:
raise RuntimeError(response['error'])
return response['predictions']
インプットには、こちらのサンプルデータを使います。24個の数字のリストが返されます。
import json
VERSION_ID = "v01"
instances = {}
with open("daily_data.json", mode="r") as f:
instances = json.load(f)
predict_json(PROJECT_ID, MODEL_ID, instances, VERSION_ID)
```
https://cloud.google.com/ai-platform/prediction/docs/online-predict?hl=ja
# CI/CDの設定
使用ファイル:
- [kfp-pipeline.ipynb](https://github.com/yaginu/weather-app/blob/main/kfp-pipeline.ipynb)
- [cloudbuild.yaml](https://github.com/yaginu/weather-app/blob/main/cloudbuild.yaml)
ここでは、リモートレポジトリへの新しいタグのpushをトリガーとして、パイプラインを自動実行するための設定を行います。前項において手動で実行していたDockerfileのビルド等の作業をyamlファイルに記述します。build構成ファイルの記述は[こちら](https://cloud.google.com/build/docs/build-config?hl=ja)が参考になります。 "_"から始まる変数は、ユーザー定義の変数で、後から置換するものを表します。**$PROJECT_ID**や**$TAG_NAME**といった変数は自動で置換されます。
https://cloud.google.com/build/docs/build-config?hl=ja
https://cloud.google.com/build/docs/configuring-builds/substitute-variable-values?hl=ja
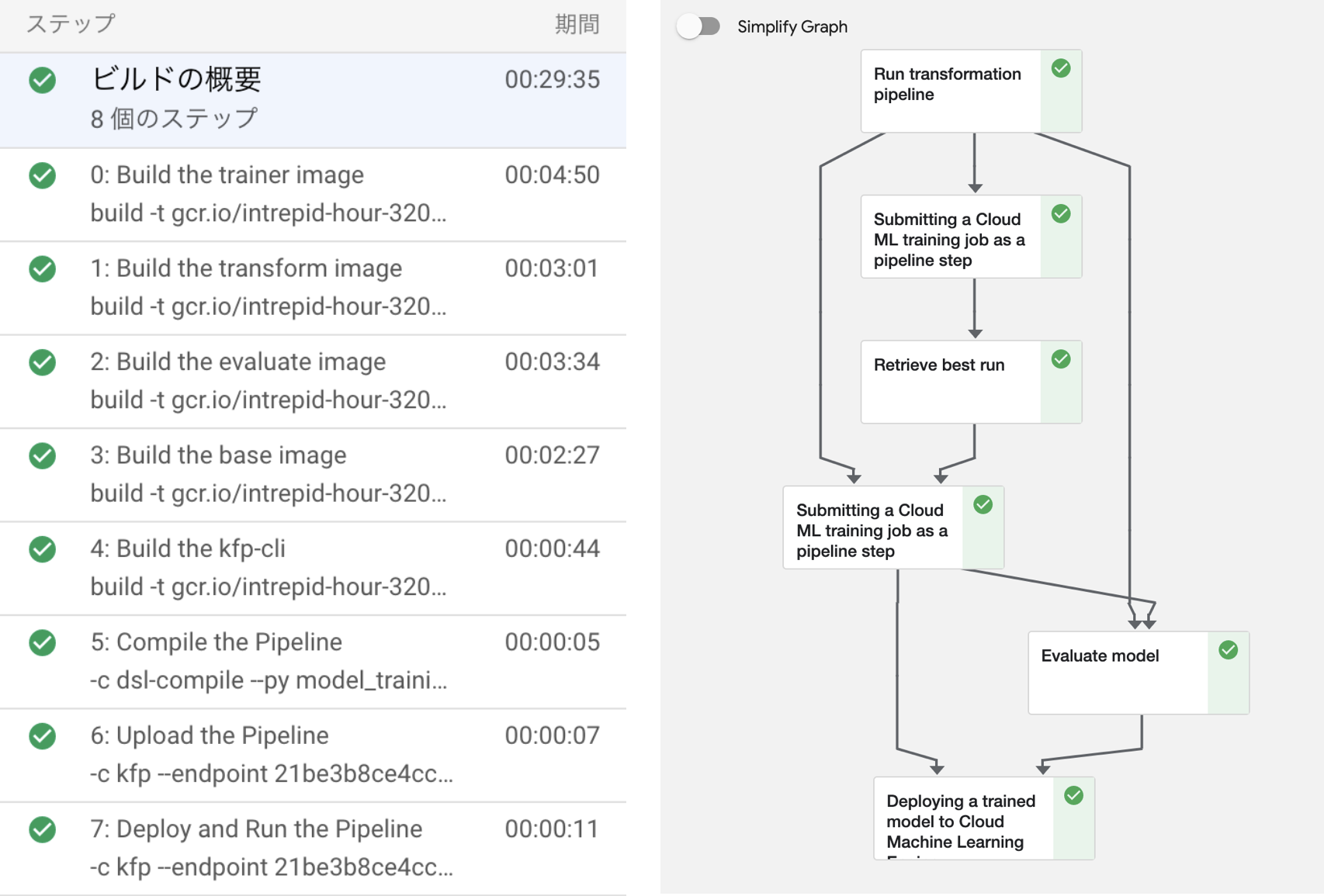
以下の通り、5つのDockerfileのビルドに続いて、パイプラインのコンパイル・アップロード・ランが行われます。
```yaml:cloudbuild.yaml
steps:
# Build the trainer image
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/$_TRAINER_IMAGE_NAME:$TAG_NAME', '.']
dir: $_PIPELINE_FOLDER/docker_images/trainer_image
id: 'Build the trainer image'
# Build the transform image
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/$_TRANSFORM_IMAGE_NAME:$TAG_NAME', '.']
dir: $_PIPELINE_FOLDER/docker_images/transform_image
id: 'Build the transform image'
# Build the evaluate image
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/$_EVALUATE_IMAGE_NAME:$TAG_NAME', '.']
dir: $_PIPELINE_FOLDER/docker_images/evaluate_image
id: 'Build the evaluate image'
# Build the base image for lightweight components
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/$_BASE_IMAGE_NAME:$TAG_NAME', '.']
dir: $_PIPELINE_FOLDER/docker_images/base_image
id: 'Build the base image'
# Build the base image for lightweight components
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/kfp-cli:latest', '.']
dir: $_PIPELINE_FOLDER/docker_images/kfp-cli
id: 'Build the kfp-cli'
# Compile the pipeline
- name: 'gcr.io/$PROJECT_ID/kfp-cli'
args:
- '-c'
- |
dsl-compile --py $_PIPELINE_DSL --output $_PIPELINE_PACKAGE
env:
- 'BASE_IMAGE=gcr.io/$PROJECT_ID/$_BASE_IMAGE_NAME:$TAG_NAME'
- 'TRAINER_IMAGE=gcr.io/$PROJECT_ID/$_TRAINER_IMAGE_NAME:$TAG_NAME'
- 'TRANSFORM_IMAGE=gcr.io/$PROJECT_ID/$_TRANSFORM_IMAGE_NAME:$TAG_NAME'
- 'EVALUATE_IMAGE=gcr.io/$PROJECT_ID/$_EVALUATE_IMAGE_NAME:$TAG_NAME'
- 'RUNTIME_VERSION=$_RUNTIME_VERSION'
- 'PYTHON_VERSION=$_PYTHON_VERSION'
- 'COMPONENT_URL_SEARCH_PREFIX=$_COMPONENT_URL_SEARCH_PREFIX'
dir: $_PIPELINE_FOLDER/pipeline
id: 'Compile the Pipeline'
# Upload the pipeline
- name: 'gcr.io/$PROJECT_ID/kfp-cli'
args:
- '-c'
- |
kfp --endpoint $_ENDPOINT pipeline upload -p ${_PIPELINE_NAME}_$TAG_NAME $_PIPELINE_PACKAGE
dir: $_PIPELINE_FOLDER/pipeline
id: 'Upload the Pipeline'
# Deploy the pipeline in KFP
- name: 'gcr.io/$PROJECT_ID/kfp-cli'
args:
- '-c'
- |
kfp --endpoint $_ENDPOINT run submit \
-e $_EXPERIMENT_NAME \
-r $_RUN_ID \
-p `kfp --endpoint $_ENDPOINT pipeline list | grep -w ${_PIPELINE_NAME}_$TAG_NAME | grep -E -o -e "([a-z0-9]){8}-([a-z0-9]){4}-([a-z0-9]){4}-([a-z0-9]){4}-([a-z0-9]){12}"` \
project_id=$PROJECT_ID \
gcs_root=$_GCS_STAGING_PATH \
region=$_REGION \
source_table_name=$_SOURCE_TABLE \
num_epochs_hypertune=$_NUM_EPOCHS_HYPERTUNE \
num_epochs_retrain=$_NUM_EPOCHS_RETRAIN \
num_units=$_NUM_UNITS \
evaluation_metric_name=$_EVALUATION_METRIC \
evaluation_metric_threshold=$_EVALUATION_METRIC_THRESHOLD \
model_id=$_MODEL_ID \
version_id=$TAG_NAME \
replace_existing_version=$_REPLACE_EXISTING_VERSION
dir: $_PIPELINE_FOLDER/pipeline
id: 'Deploy and Run the Pipeline'
waitFor: ['Upload the Pipeline']
# Push the images to Container Registry
images:
- gcr.io/$PROJECT_ID/$_TRAINER_IMAGE_NAME:$TAG_NAME
- gcr.io/$PROJECT_ID/$_TRANSFORM_IMAGE_NAME:$TAG_NAME
- gcr.io/$PROJECT_ID/$_EVALUATE_IMAGE_NAME:$TAG_NAME
- gcr.io/$PROJECT_ID/$_BASE_IMAGE_NAME:$TAG_NAME
# Changing the timeout threshold
timeout: 3600s
```
それでは、手動でのビルドを実行してみましょう。yamlファイル内の変数値の置換は、subsutitutionsで指定します。
```python:kfp-pipeline.ipynb
SUBSTITUTIONS="""
_ENDPOINT={},\
_TRAINER_IMAGE_NAME=trainer_image,\
_TRANSFORM_IMAGE_NAME=transform_image,\
_EVALUATE_IMAGE_NAME=evaluate_image,\
_BASE_IMAGE_NAME=base_image,\
TAG_NAME=v01,\
_PIPELINE_FOLDER=.,\
_PIPELINE_DSL=model_training_pipeline.py,\
_PIPELINE_PACKAGE=model_training_pipeline.yaml,\
_PIPELINE_NAME=weather_forecast_continuous_training,\
_RUNTIME_VERSION=2.5,\
_PYTHON_VERSION=3.7,\
_COMPONENT_URL_SEARCH_PREFIX=https://raw.githubusercontent.com/kubeflow/pipelines/1.6.0/components/gcp/,\
\
_EXPERIMENT_NAME=Weather_Forecast_Training,\
_RUN_ID=Run_001,\
_GCS_STAGING_PATH=gs://##########-kubeflowpipelines-default/staging,\
_REGION=asia-northeast1,\
_SOURCE_TABLE=weather_data.tokyo,\
_NUM_EPOCHS_HYPERTUNE=1,\
_NUM_EPOCHS_RETRAIN=1,\
_NUM_UNITS=128,\
_EVALUATION_METRIC=mse,\
_EVALUATION_METRIC_THRESHOLD=10.0,\
_MODEL_ID=weather_forecast,\
_REPLACE_EXISTING_VERSION=True
""".format(ENDPOINT).strip()
# 手動ビルド
!gcloud builds submit . --config cloudbuild.yaml --substitutions {SUBSTITUTIONS}
```
それでは、Cloud Buildの設定を行い、パイプラインの実行の自動化を実現します。[こちら](https://cloud.google.com/build/docs/automating-builds/create-github-app-triggers?hl=ja#creating_github_app_triggers)のドキュメントを参考に進めます。今回は、リポジトリへの新しいタグのpushをトリガーとして、cloudbuild.yamlファイルが読み込まれ、タスクが実行されます。


最後に、cloudbuild.yamlへの代入変数をリストアップします。


シェルで以下のコマンドを実施すると、パイプラインの実行が始まります。 Cloud Buildの履歴から実行のログが確認できます。
```bash
git tag (tag name)
git push origin main --tag
```
# 自動スクレイピング
使用ファイル:
- [scheduled_scrayper/main.py](https://github.com/yaginu/weather-app/tree/main/scheduled_scrayper)
- [scheduled_scrayper/requirements.txt](https://github.com/yaginu/weather-app/tree/main/scheduled_scrayper)
[こちら](https://github.com/yaginu/weather-app/tree/main/scheduled_scrayper)のプログラムによって、BigQueryのテーブルに1日1回のレコードの追加が行われます。また同時に、翌日の気温の予測を行うためのオンライン予測ジョブをが実行され、予測値はCloud Storageへと保存されます。※カスタム予測ルーチンを含むモデルでは、バッチ予測ができません。
ここでは、このプログラムが定期実行されるように**Cloud Functions**と**Cloud Scheduler**の設定を行います。[こちら](https://cloud.google.com/scheduler/docs/tut-pub-sub?hl=ja)のドキュメントに倣い設定します。Cloud Schedulerの設定で頻度を次のように指定します。これは、実行を1日1回午前2時にスケジュールすることを意味します。
https://cloud.google.com/scheduler/docs/tut-pub-sub?hl=ja

BigQueryのテーブルへの書き込みやCloud Storageへのアップロードについては、以下が参考になります。
https://cloud.google.com/bigquery/docs/samples/bigquery-table-insert-rows?hl=ja#bigquery_table_insert_rows-python
https://cloud.google.com/storage/docs/uploading-objects?hl=ja#storage-upload-object-code-sample
# 終わりに
今回は、Kubeflow Pipelinesを用いた機械学習パイプラインの自動化を実践しました。完全なパイプラインには程遠い部分もありますが、新しい要素の追加も比較的容易に行えるようになっていると思います。 今後は、TensorFlow Data Validationなど新たなコンポーネントの導入をしたいと考えています。
実務未経験者の記事なので間違いなどがございましたら、ご指摘いただけると幸いです。ご覧いただきありがとうございました。
【追記:2021/08/14】
モデルのデプロイ時に、訓練したモデルとデフォルトのモデルとを同じテストセットで評価してから、訓練指標の良い方をデプロイする様に変更しました。
また、新しいモデルがデプロイされると自動的にデフォルトに設定されます。
GitHubレポジトリは更新済みです。当記事は、後ほど変更します。